
 java基础02
java基础02
# MySQL高级主题-Java面试题
之前两篇文章带你了解了 MySQL 的基础语法和 MySQL 的进阶内容,那么这篇文章我们来了解一下 MySQL 中的高级内容。
事务控制和锁定语句
我们知道,MyISAM 和 MEMORY 存储引擎支持表级锁定(table-level locking),InnoDB 存储引擎支持行级锁定(row-level locking),BDB 存储引擎支持页级锁定(page-level locking)。各个锁定级别的特点如下
页级锁:销和加锁时间界于表锁和行锁之间;会出现死锁;锁定粒度界于表锁和行锁之间,并发度一般
表级锁:表级锁是对整张表进行加锁,MyISAM 和 MEMORY 主要支持表级锁,表级锁加锁快,不会出现死锁,锁的粒度比较粗,并发度最低
行级锁:行级锁可以说是 MySQL 中粒度最细的一种锁了,InnoDB 支持行级锁,行级锁容易发生死锁,并发度比较好,同时锁的开销也比较大。
MySQL 默认情况下支持表级锁定和行级锁定。但是在某些情况下需要手动控制事务以确保整个事务的完整性,下面我们就来探讨一下事务控制。但是在探讨事务控制之前我们先来认识一下两个锁定语句
锁定语句
MySQL 的锁定语句主要有两个 Lock 和 unLock,Lock Tables 可用于锁定当前线程的表,就跟 Java 语法中的 Lock 锁的用法是一样的,如果表锁定,意味着其他线程不能再操作表,直到锁定被释放为止。如下图所示
lock table cxuan005 read;

我们锁定了 cxuan005 的 read 锁,然后这时我们再进行一次查询,看看是否能够执行这条语句
select * from cxuan005 where id = 111;

可以看到,在进行 read 锁定了,我们仍旧能够执行查询语句。
现在我们另外起一个窗口,相当于另起了一个线程来进行查询操作。
select * from cxuan005;

这是第二个窗口执行查询的结果,可以看到,在一个线程执行 read 锁定后,其他线程仍然可以进行表的查询操作。
那么第二个线程能否执行更新操作呢?我们来看一下
update cxuan005 set info='cxuan' where id = 111;

发生了什么?怎么没有提示结果呢?其实这个情况下表示 cxuan005 已经被加上了 read 锁,由于当前线程不是持有锁的线程,所以当前线程无法执行更新。
解锁语句
现在我们把窗口切换成持有 read 锁的线程,来进行 read 锁的解锁
unlock tables;

在解锁完成前,进行更新的线程会一直等待,直到解锁完成后,才会进行更新。我们可以看一下更新线程的结果。

可以看到,线程已经更新完毕,我们看一下更新的结果
select * from cxuan005 where id = 111;
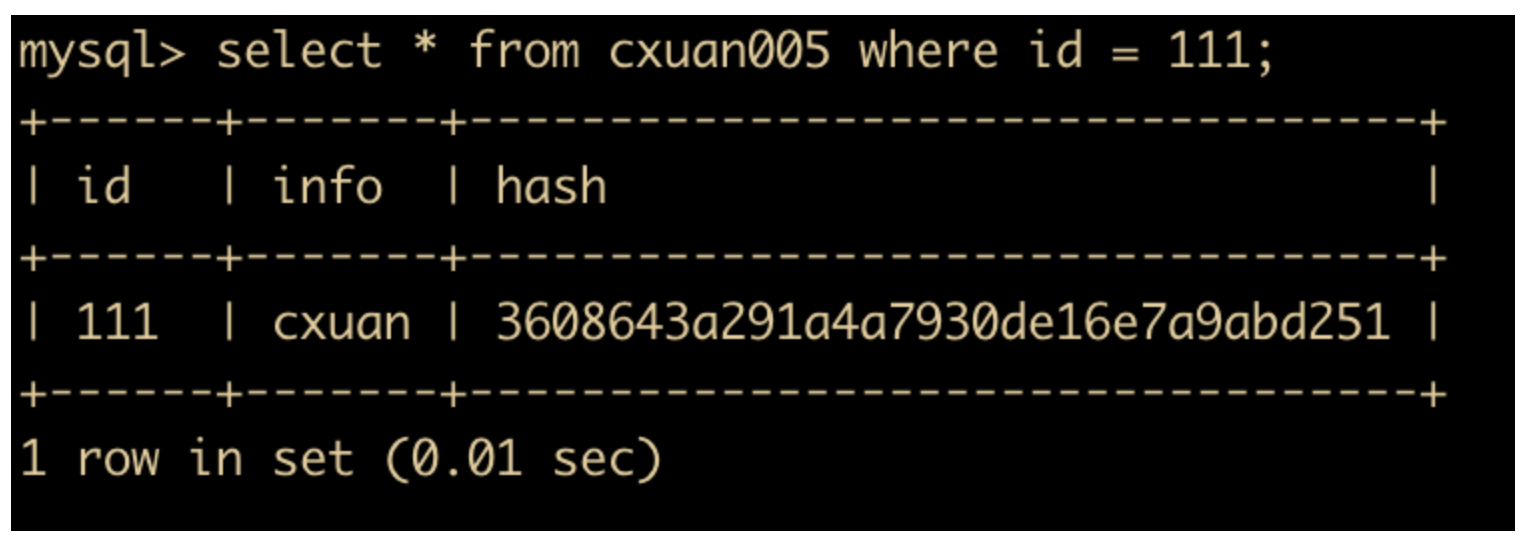
如上图所示,id = 111 的值已经被更新成了 cxuan。
事务控制
事务(Transaction) 是访问和更新数据库的基本执行单元,一个事务中可能会包含多个 SQL 语句,事务中的这些 SQL 语句要么都执行,要么都不执行,而 MySQL 它是一个关系型数据库,它自然也是支持事务的。事务同时也是区分关系型数据库和非关系型数据库的一个重要的方面。
在 MySQL 事务中,主要涉及的语法包含 SET AUTOCOMMIT、START TRANSACTION、COMMIT 和 ROLLBACK 等。
自动提交
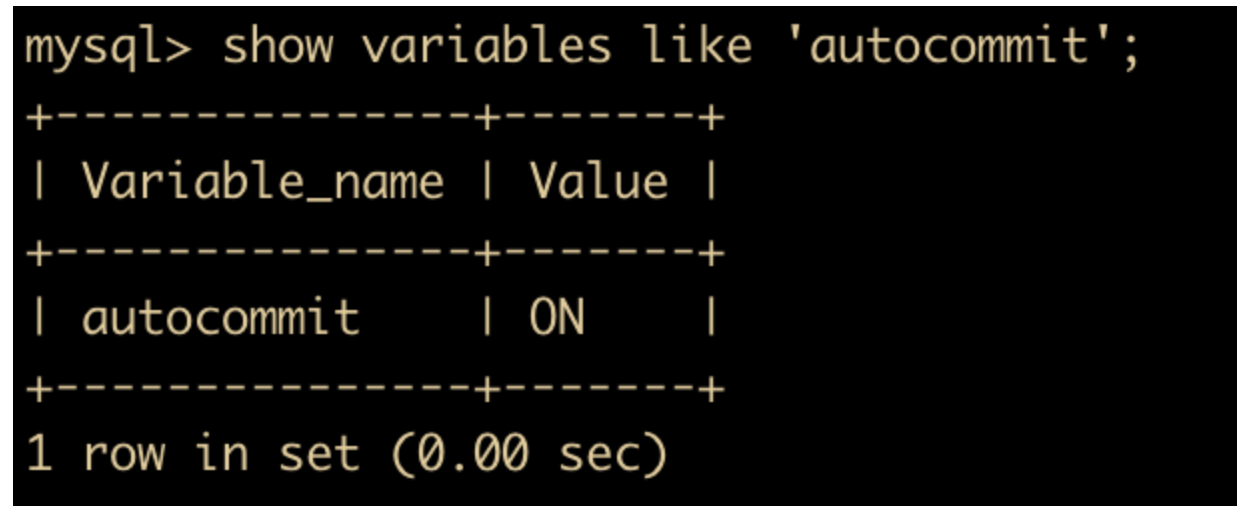
在 MySQL 中,事务默认是自动提交(Autocommit)的,如下所示
show variables like 'autocommit';
在自动提交的模式下,每个 SQL 语句都会当作一个事务执行提交操作,例如我们上面使用的更新语句
update cxuan005 set info='cxuan' where id = 111;
如果想要关闭数据库的自动提交应该怎么做呢?
其实,MySQL 是可以关闭自动提交的,你可以执行
set autocommit = 0;

然后我们再看一下自动提交是否关闭了,再次执行一下 show variables like ‘autocommit’ 语句
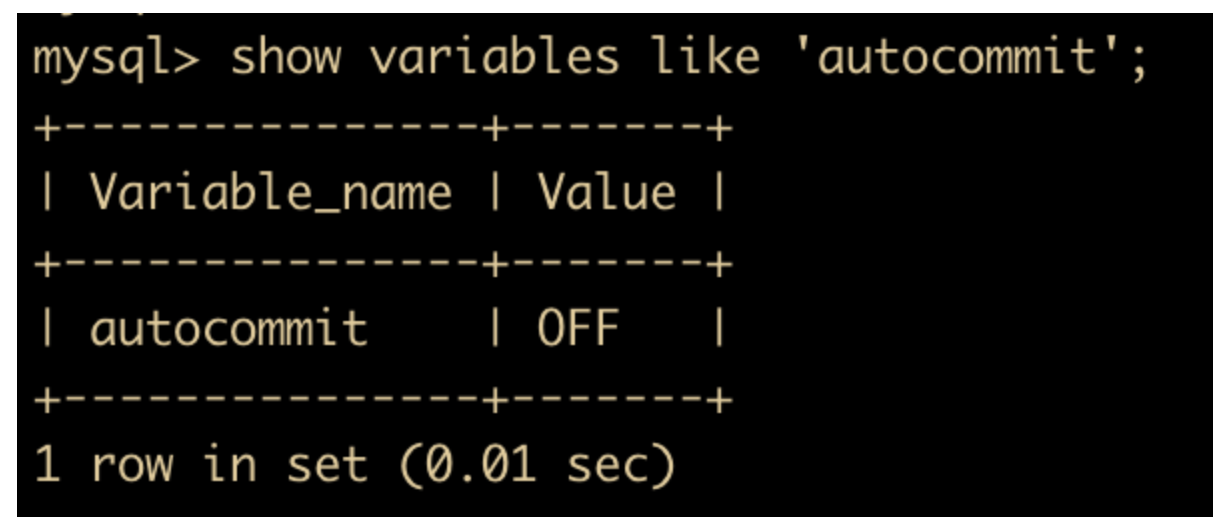
可以看到,自动提交已经关闭了,再次执行
set autocommit = 1;
会再次开启自动提交。
这里注意一下特殊操作。
在 MySQL 中,存在一些特殊的命令,如果在事务中执行了这些命令,会马上强制执行 commit 提交事务;比如 DDL 语句(create table/drop table/alter/table)、lock tables 语句等等。
不过,常用的 select、insert、update 和 delete命令,都不会强制提交事务。
手动提交
如果需要手动 commit 和 rollback 的话,就需要明确的事务控制语句了。
典型的 MySQL 事务操作如下
start transaction; ... # 一条或者多条语句 commit;
上面代码中的 start transaction 就是事务的开始语句,编写 SQL 后会调用 commit 提交事务,然后将事务统一执行,如果 SQL 语句出现错误会自动调用 Rollback 进行回滚。
下面我们就通过示例来演示一下 MySQL 的事务,同样的,我们需要启动两个窗口来演示,为了便于区分,我们使用 mysql01 和 mysql02 来命名。

我们用 start transaction 命令启动一个事务,然后再 cxuan005 表中插入一条数据,此时 mysql02 不做任何操作。涉及的 SQL 语句如下。
start transaction;

然后执行
select * from cxuan005;
查询一下 cxuan005 中的数据

嗯。。。很多长度太长了,现在我们把所有的 info 数据都更新为 cxuan 。
update cxuan005 set info='cxuan';

更新完毕后,我们先不提交事务,分别在 mysql01 和 mysql02 中进行查询,发现只有 mysql01 窗口中的查询已经生效,而 mysql02 中还是更新前的数据
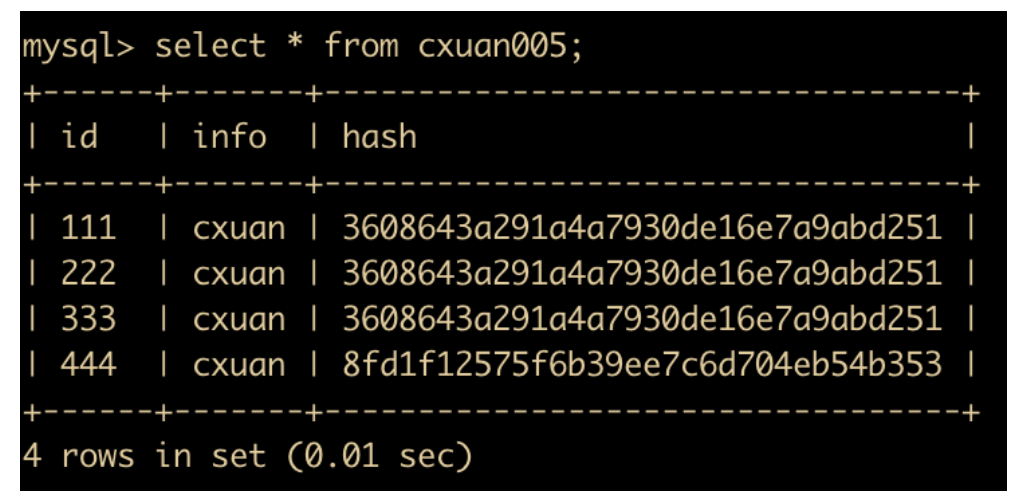
现在我们在 mysql01 中 commit 当前事务,然后在 mysql02 中查询,发现数据已经被修改了。
除了 commit 之外,MySQL 中还有 commit and chain 命令,这个命令会提交当前事务并且重新开启一个新的事务。如下代码所示
start transaction; # 开启一个新的事务 insert into cxuan005(id,info) values (555,'cxuan005'); # 插入一条数据 commit and chain; # 提交当前事务并重新开启一个事务
上面是一个事务操作,在 commit and chain 键入后,我们可以再次执行 SQL 语句
update cxuan005 set info = 'cxuan' where id = 555; commit;
然后再次查询
select * from cxuan005;
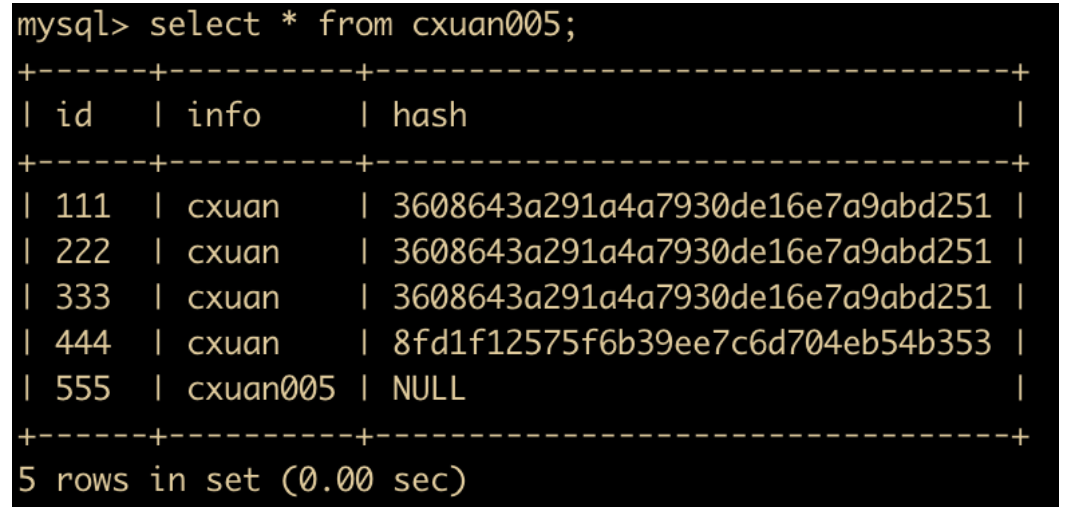
执行后,可以发现,我们仅仅使用了一个 start transaction 命令就执行了两次事务操作。
如果在手动提交的事务中,你发现有一条 SQL 语句写的不正确或者有其他原因需要回滚,那么此时你就会用到 rollback 语句,它会回滚当前事务,相当于什么也没发生。如下代码所示。
start transaction; delete from cxuan005 where id = 555; rollback;
这里
切忌一点:delete 删除语句一定要加 where ,不加 where 语句的删除就是耍流氓。
在同一个事务操作中,最好使用相同存储引擎的表,如果使用不同存储引擎的表后,rollback 语句会对非事务类型的表进行特别处理,因此 commit 、rollback 只能对事务类型的表进行提交和回滚。
我们提交的事务一般都会被记录到二进制的日志中,但是如果一个事务中包含非事务类型的表,那么回滚操作也会被记录到二进制日志中,以确保非事务类型的表可以被复制到从数据库中。
这里解释一下什么是事务表和非事务表
事务表和非事务表
事务表故名思义就是支持事务的表,支不支持事务和 MySQL 的存储类型有关,一般情况下,InnoDB 存储引擎的表是支持事务的,关于 InnoDB 的知识,我们会在后面详细介绍。
非事务表相应的就是不支持事务的表,在 MySQL 中,存储引擎 MyISAM 是不支持事务的,非事务表的特点是不支持回滚。
对于回滚的话,还要讲一点就是 SAVEPOINT,它能指定事务回滚的一部分,但是不能指定事务提交的一部分。 SAVEPOINT 可以指定多个,在满足不同条件的同时,回滚不同的 SAVEPOINT。需要注意的是,如果定义了两个相同名称的 SAVEPOINT,则后面定义的 SAVEPOINT 会覆盖之前的定义。如果 SAVEPOINT 不再需要的话,可以通过 RELEASE SAVEPOINT 来进行删除。删除后的 SAVEPOINT 不能再执行 ROLLBACK TO SAVEPOINT 命令。
我们通过一个示例来进行模拟不同的 SAVEPOINT
首先先启动一个事务 ,向 cxuan005 中插入一条数据,然后进行查询,那么是可以查询到这条记录的
start transaction; insert into cxuan005(id,info) values(666,'cxuan666'); select * from cxuan005 where id = 666;
查询之后的记录如下
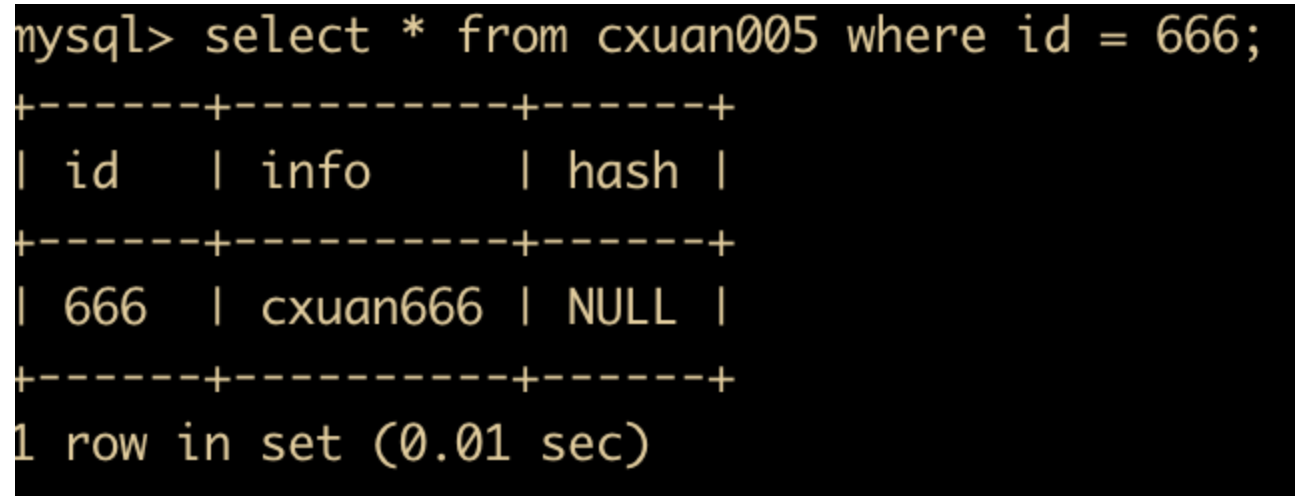
然后我们定义一个 SAVEPOINT,如下所示
savepoint test;
然后继续插入一条记录
insert into cxuan005(id,info) values(777,'cxuan777');
此时就可以查询到两条新增记录了,id 是 666 和 777 的记录。
select * from cxuan005 where id = 777;
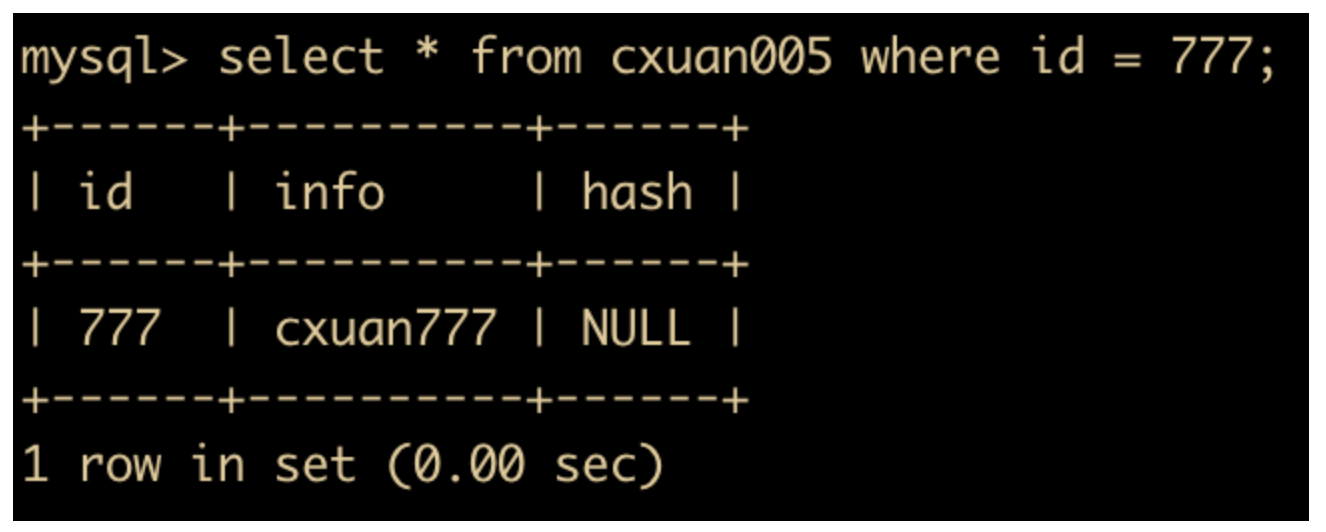
那么我们可以回滚到刚刚定义的 SAVEPOINT
rollback to savepoint test;
再次查询 cxuan005 这个表,可以看到,只有 id=666 的这条记录插入进来了,说明 id=777 这条记录已经被回滚了。
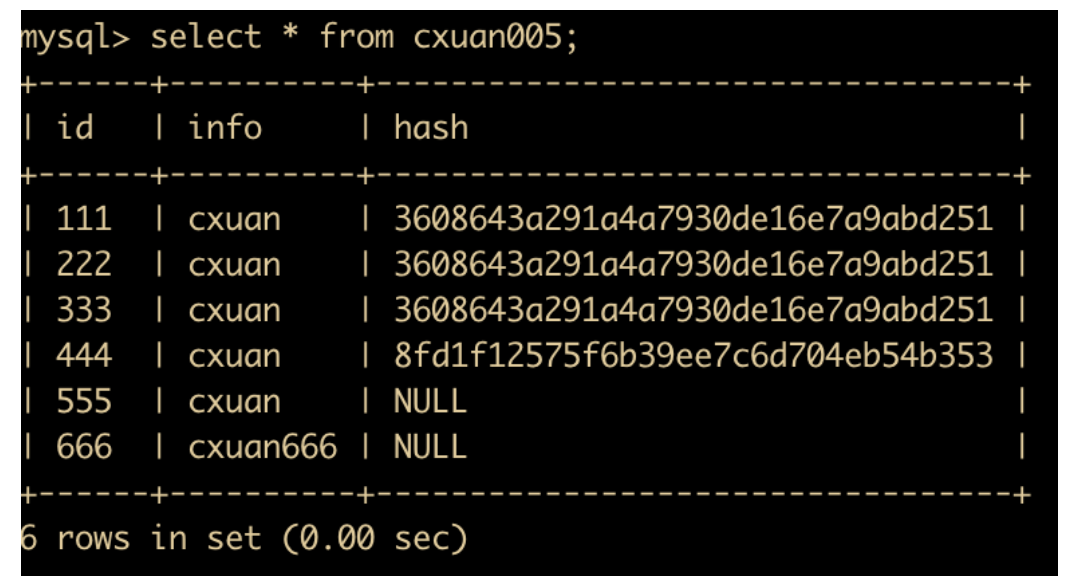
此时我们看到的都是 mysql01 中事务还没有提交前的状态,所以这时候 mysql02 中执行查询操作是看不到 666 这条记录的。
然后我们在 mysql01 中执行 commit 操作,那么此时在 mysql02 中就可以查询到这条记录了。
SQL 安全问题
SQL 安全问题应该是我们程序员比较忽视的一个地方了。日常开发中,我们一般只会关心 SQL 能不能解决我们的业务问题,能不能把数据查出来,而对于 SQL 问题,我们一般都认为这是 DBA 的活,其实我们 CRUD 程序员也应该了解一下 SQL 的安全问题。
SQL 注入简介
SQL 注入就是利用某些数据库的外部接口将用户数据插入到实际的 SQL 中,从而达到入侵数据库的目的。SQL 注入是一种常见的网络攻击的方式,它不是利用操作系统的 BUG 来实现攻击的。SQL 主要是针对程序员编写时的疏忽来入侵的。
SQL 注入攻击有很大的危害,攻击者可以利用它读取、修改或者删除数据库内的数据,获取数据库中的用户名和密码,甚至获得数据库管理员的权限。并且 SQL 注入一般比较难以防范。
SQL Mode
MySQL 可以运行在不同的 SQL Mode 模式下,不同的 SQL Mode 定义了不同的 SQL 语法,数据校验规则,这样就能够在不同的环境中使用 MySQL ,下面我们就来介绍一下 SQL Mode。
SQL Mode 解决问题
SQL Mode 可以解决下面这几种问题
- 通过设置 SQL Mode,可以完成不同严格程度的数据校验,有效保障数据的准确性。
- 设置 SQL Mode 为
ANSI模式,来保证大多数 SQL 符合标准的 SQL 语法,这样应用在不同数据库的迁移中,不需要对 SQL 进行较大的改变 - 数据在不同数据库的迁移中,通过改变 SQL Mode 能够更方便的进行迁移。
下面我们就通过示例来演示一下 SQL Mode 用法
我们可以通过
select @@sql_mode;
来查看默认的 SQL Mode,如下是我的数据库所支持的 SQL Mode

涉及到很多 SQL Mode,下面是这些 SQL Mode 的解释
ONLY_FULL_GROUP_BY:这个模式会对 GROUP BY 进行合法性检查,对于 GROUP BY 操作,如果在SELECT 中的列,没有在 GROUP BY 中出现,那么将认为这个 SQL 是不合法的,因为列不在 GROUP BY 从句中
同样举个例子,我们现在查询一下 cxuan005 的 id 和 info 字段。
select id,info from cxuan005;
这样是可以运行的
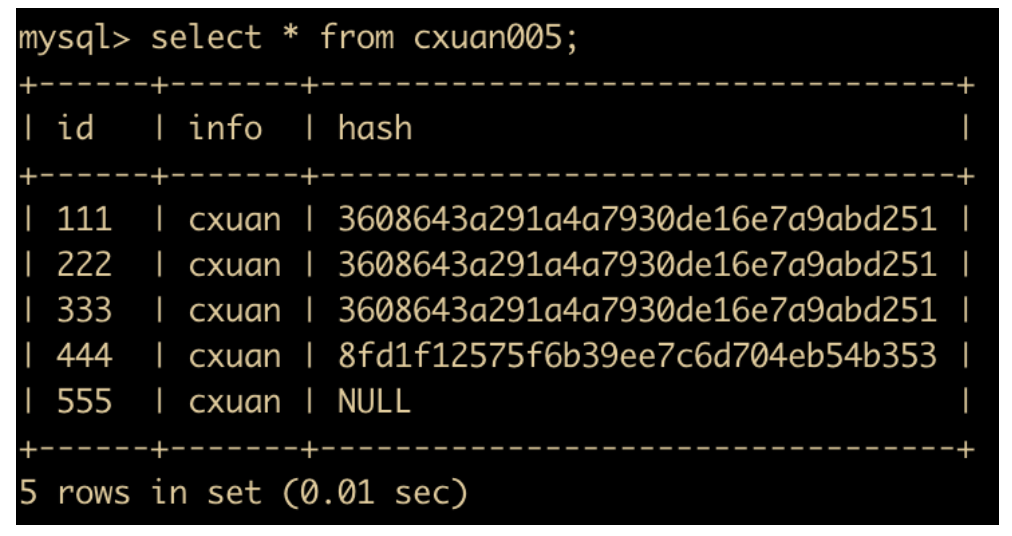
然后我们使用 GROUP BY 字句进行分组,这里只对 info 进行分组,我们看一下会出现什么情况
select id,info from cxuan005 group by info;

我们可以从错误原因中看到,这条 SQL 语句是不符合 ONLY_FULL_GROUP_BY 的这条 SQL Mode 的。因为我们只对 info 进行分组了,没有对 id 进行分组,我们把 SQL 语句改成如下形式
select id,info from cxuan005 group by id,info;
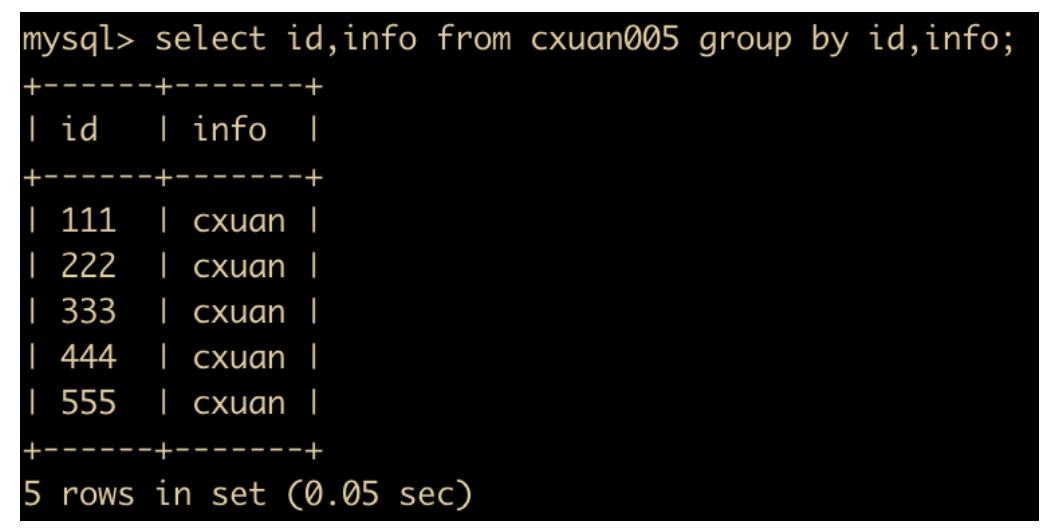
这样 SQL 就能正确执行了。
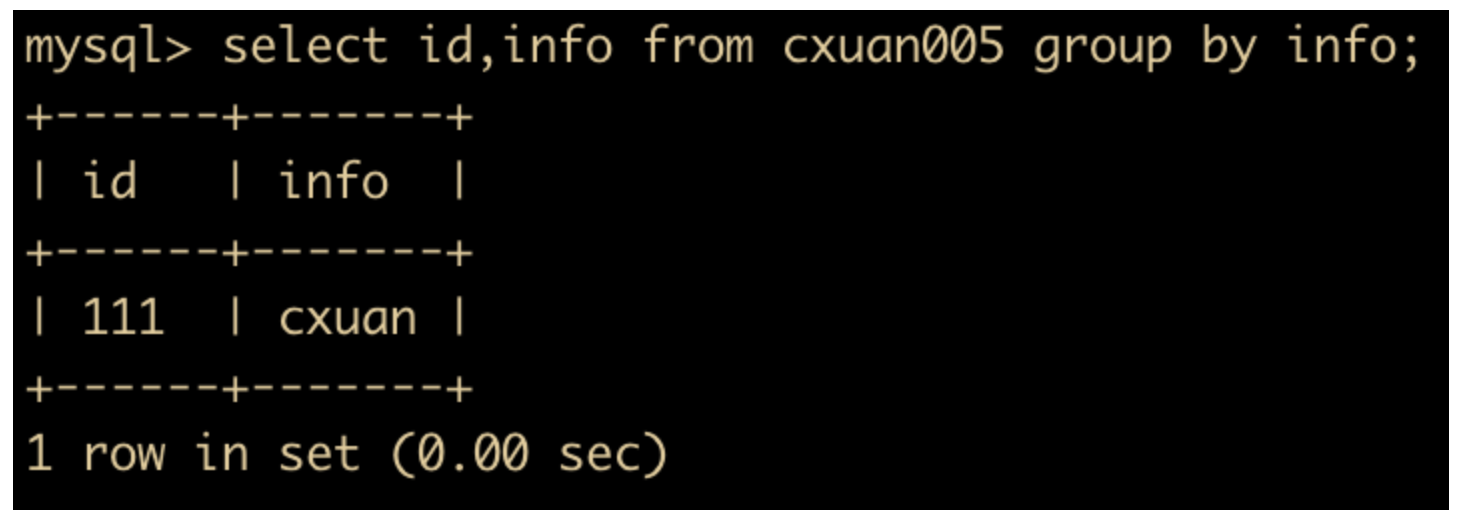
当然,我们也可以删除 sql_mode = ONLY_FULL_GROUP_BY 的这条 Mode,可以使用
SET sql_mode=(SELECT REPLACE(@@sql_mode,'ONLY_FULL_GROUP_BY',''));
来进行删除,删除后我们使用分组语句就可以放飞自我了。
select id,info from cxuan005 group by info;
但是这种做法只是暂时的修改,我们可以修改配置文件 my.ini 中的 sql_mode= STRICT_TRANS_TABLES,NO_ZERO_IN_DATE,NO_ZERO_DATE,ERROR_FOR_DIVISION_BY_ZERO,NO_AUTO_CREATE_USER,NO_ENGINE_SUBSTITUTION
STRICT_TRANS_TABLES:这就是严格模式,在这个模式下会对数据进行严格的校验,错误数据不能插入,报error 错误。如果不能将给定的值插入到事务表中,则放弃该语句。对于非事务表,如果值出现在单行语句或多行语句的第1行,则放弃该语句。
当使用 innodb 存储引擎表时,考虑使用 innodb_strict_mode 模式的 sql_mode,它能增量额外的错误检测功能。
NO_ZERO_IN_DATE:这个模式影响着日期中的月份和天数是否可以为 0(注意年份是非 0 的),这个模式也取决于严格模式是否被启用。如果这个模式未启用,那么日期中的零部分被允许并且插入没有警告。如果这个模式启用,那么日期中的零部分插入被作为 0000-00-00 并且产生一个警告。
这个模式需要注意下,如果启用的话,需要 STRICT_TRANS_TABLES 和 NO_ZERO_IN_DATE 同时启用,否则不起作用,也就是
set session sql_mode='STRICT_TRANS_TABLES,NO_ZERO_IN_DATE';
然后我们换表了,使用 cxuan003 这张表,表结构如下
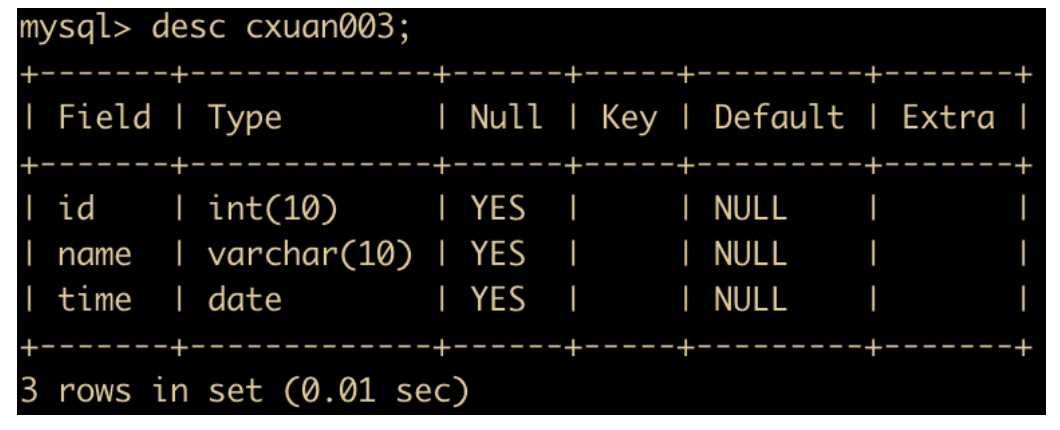
我们主要测试日期的使用,在 cxuan003 中插入一条日期为 0000-00-00 的数据
insert into cxuan003 values(111,'study','0000-00-00');
发现能够执行成功,但是把年月日各自变为 0 之后再进行插入,则会插入失败。
insert into cxuan003 values(111,'study','2021-00-00');

insert into cxuan003 values(111,'study','2021-01-00');

这些组合有很多,我这里就不再细致演示了,读者可以自行测试。
如果要插入 0000-00-00 这样的数据,必须设置 NO_ZERO_IN_DATE 和 NO_ZERO_DATE。
ERROR_FOR_DIVISION_BY_ZERO:如果这个模式未启用,那么零除操作将会插入空值并且不会产生警告;如果这个模式启用,零除操作插入空值并产生警告;如果这个模式和严格模式都启用,零除从操作将会产生一个错误。
NO_AUTO_CREATE_USER:禁止使用 grant 语句自动创建用户,除非认证信息被指定。
NO_ENGINE_SUBSTITUTION:此模式指定当执行 create 语句或者 alter 语句指定的存储引擎没有启用或者没有编译时,控制默认存储引擎的自动切换。默认是启用状态的。
SQL Mode 三种作用域
SQL Mode 按作用区域和时间可分为 3。个级别,分别是会话级别,全局级别,配置(永久生效)级别。
我们上面使用的 SQL Mode 都是 会话级别,会话级别就是当前窗口域有效。它的设置方式是
set @@session.sql_mode='xx_mode' set session sql_mode='xx_mode'
全局域就是当前会话关闭不失效,但是在 MySQL 重启后失效。它的设置方式是
set global sql_mode='xx_mode'; set @@global.sql_mode='xx_mode';
配置域就是在 vi /etc/my.cnf 里面添加
[mysqld] sql-mode = "xx_mode"
配置域在保存退出后,重启服务器,即可永久生效。
SQL 正则表达式
正则表达式相信大家应该都用过,不过你在 MySQL 中用过正则表达式吗?下面我们就来聊一聊 SQL 中的正则表达式。
正则表达式(Regular Expression) 是指一个用来描述或者匹配字符串的句法规则。正则表达式通常用来检索和替换某个文本中的文本内容。很多语言都支持正则表达式,MySQL 同样也不例外,MySQL 利用 REGEXP 命令提供给用户扩展的正则表达式功能。下面是 MySQL 中正则表达式的一些规则。
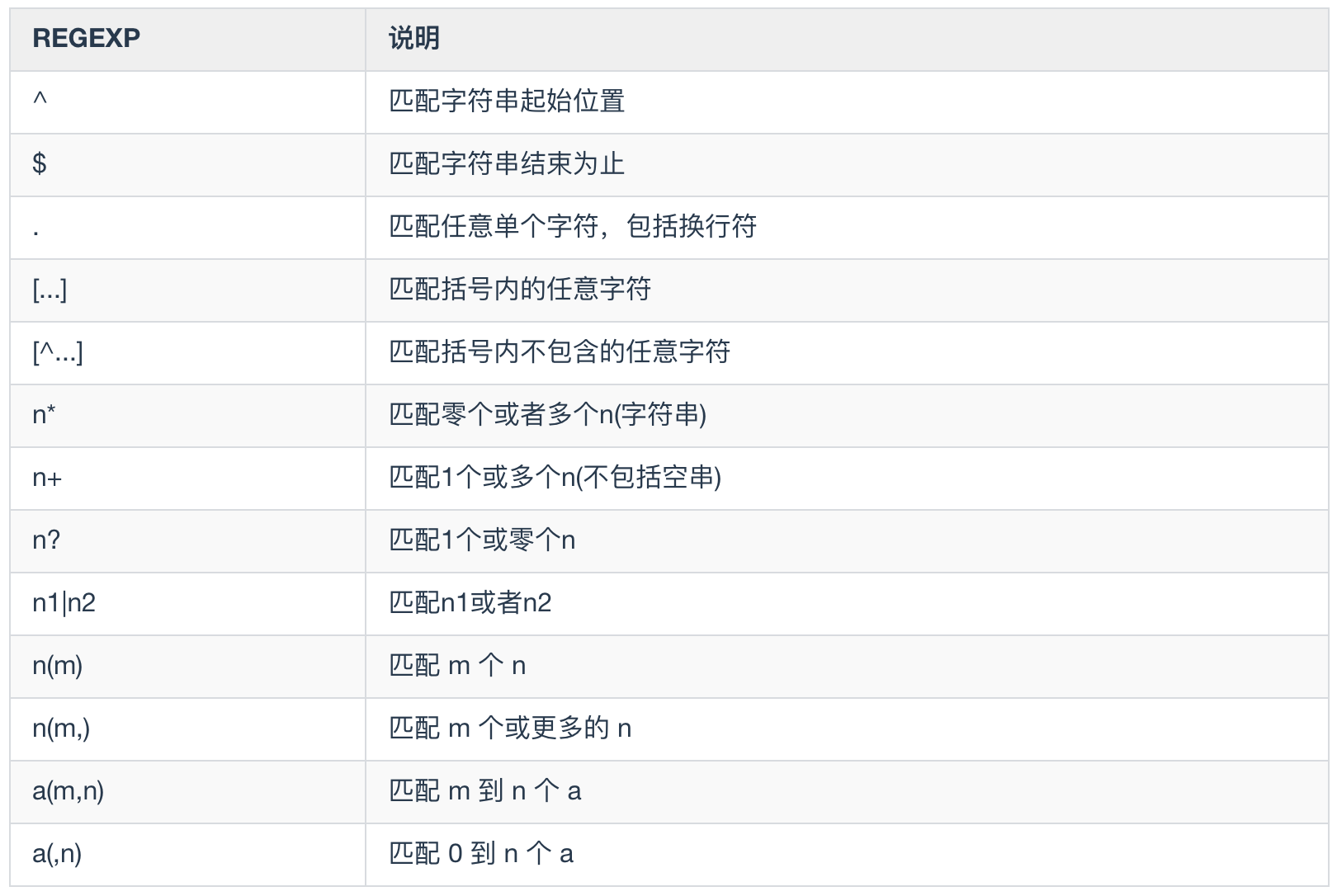
下面来演示一下正则表达式的用法
^在字符串的开始进行匹配,根据返回的结果来判断是否匹配,1 = 匹配,0 = 不匹配。下面尝试匹配字符串aaaabbbccc是否以字符串a为开始select 'aaaabbbccc' regexp '^a';
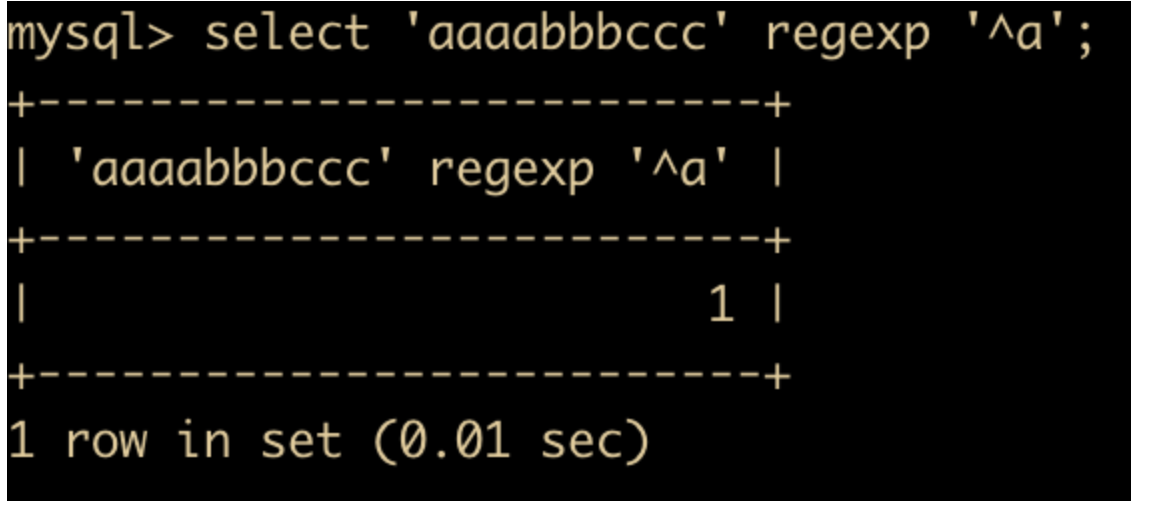
同样的,
$会在末尾处进行匹配,如下所示select 'aaaabbbccc' regexp 'c$';
.匹配单个任意字符select 'berska' regexp '.s', 'zara' regexp '.a';

[...]表示匹配括号内的任意字符,示例如下select 'whosyourdaddy' regexp '[abc]';

[^...]匹配括号内不包含的任意字符,和[...]是相反的,如果有任何匹配不上,返回 0 ,全部匹配上返回 1。select 'x' regexp '[^xyz]';

n*表示匹配零个或者多个 n 字符串,如下select 'aabbcc' regexp 'd*';

没有 d 出现也可以返回 1 ,因为 * 表示 0 或者多个。
n+表示匹配 1 个或者 n 个字符串select 'aabbcc' regexp 'd+';

n?的用法和 n+ 类似,只不过 n? 可以匹配空串
常见 SQL 技巧
RAND() 函数
大多数数据库都会提供产生随机数的函数,通过这些函数可以产生随机数,也可以使用从数据库表中抽取随机产生的记录,这对统计分析来说很有用。
在 MySQL 中,通常使用 RAND() 函数来产生随机数。RAND() 和 ORDER BY 组合完成数据抽取功能,如下所示。
我们新建一张表用于数据检索。
CREATE TABLE `clerk_Info` ( `id` int(11) NOT NULL, `name` varchar(255) DEFAULT NULL, `salary` decimal(10,2) DEFAULT NULL, `companyId` int(10) DEFAULT NULL, PRIMARY KEY (`id`) ) ENGINE=InnoDB DEFAULT CHARSET=latin1
然后插入一些数据,插入完成后的数据如下。

然后我们可以使用 RAND() 函数进行随机检索数据行
select * from clerk_info order by rand();
检索完成后的数据如下

多次查询后发现每次检索的数据顺序都是随机的。
这个函数多用于随机抽样,比如选取一定数量的样本在进行随机排序,需要用到 limit 关键字。
GROUP BY + WITH ROLLUP
我们经常使用 GROUP BY 语句,但是你用过 GROUP BY 和 WITH ROLLUP 一起使用的吗?使用 GROUP BY 和 WITH ROLLUP 字句可以检索出更多的分组集合信息。
我们仍旧对 clerk_info 表进行操作,我们对 name 和 salary 进行分组统计工资总数。
select name,sum(salary) from clerk_info group by name with rollup;

可以看到上面的表按照 name 进行分组,然后再对 money 进行统计。
也就是说 GROUP BY 语句执行完成后可以满足用户想要的任何一个分组以及分组组合的聚合信息值。
这里需要注意一点,不能同时使用 ORDER BY 字句对结果进行排序,ROLLUP 和 ORDER BY 是互斥的。
数据库名、表名大小写问题
在 MySQL 中,数据库中的每个表至少对应数据库目录中的一个文件,当然这取决于存储引擎的实现了。不同的操作系统对大小写的敏感性决定了数据库和表名的大小写的敏感性。在 UNIX 操作系统中是对大小写敏感的,因此数据库名和表名也是具有敏感性的,而到了 Windows 则不存在敏感性问题,因为 Windows 操作系统本身对大小写不敏感。列、索引、触发器在任何平台上都对大小写不敏感。
在 MySQL 中,数据库名和表名是由 lower_case_tables_name 系统变量决定的。可以在启动 mysqld 时设置这个系统变量。下面是 lower_case_tables_name 的值。

如果只在一个平台上使用 MySQL 的话,通常不需要修改 lower_case_tables_name 变量。如果想要在不同系统系统之间迁移表就会涉及到大小写问题,因为 UNIX 中 clerk_info 和 CLERK_INFO 被认为是两个不同的表,而 Windows 中则认为是一个。在 UNIX 中使用 lower_case_tables_name=0, 而在 Windows 中使用lower_case_tables_name=2,这样可以保留数据库名和表名的大小写,但是不能保证所有的 SQL 查询中使用的表名和数据库名的大小写相同。如果 SQL 语句中没有正确引用数据库名和表名的大小写,那么虽然在 Windows 中能正确执行,但是如果将查询转移到 UNIX 中,大小写不正确,将会导致查询失败。
外键问题
这里需要注意一个问题,InnoDB 存储引擎是支持外键的,而 MyISAM 存储引擎是不支持外键的,因此在 MyISAM 中设置外键会不起作用。
MySQL 常用函数
下面我们来了解一下 MySQL 函数,MySQL 函数也是我们日常开发过程中经常使用的,选用合适的函数能够提高我们的开发效率,下面我们就来一起认识一下这些函数
字符串函数
字符串函数是最常用的一种函数了,MySQL 也是支持很多种字符串函数,下面是 MySQL 支持的字符串函数表
| 函数 | 功能 |
|---|---|
| LOWER | 将字符串所有字符变为小写 |
| UPPER | 将字符串所有字符变为大写 |
| CONCAT | 进行字符串拼接 |
| LEFT | 返回字符串最左边的字符 |
| RIGHT | 返回字符串最右边的字符 |
| INSERT | 字符串替换 |
| LTRIM | 去掉字符串左边的空格 |
| RTRIM | 去掉字符串右边的空格 |
| REPEAT | 返回重复的结果 |
| TRIM | 去掉字符串行尾和行头的空格 |
| SUBSTRING | 返回指定的字符串 |
| LPAD | 用字符串对最左边进行填充 |
| RPAD | 用字符串对最右边进行填充 |
| STRCMP | 比较字符串 s1 和 s2 |
| REPLACE | 进行字符串替换 |
下面通过具体的示例演示一下每个函数的用法
- LOWER(str) 和 UPPER(str) 函数:用于转换大小写

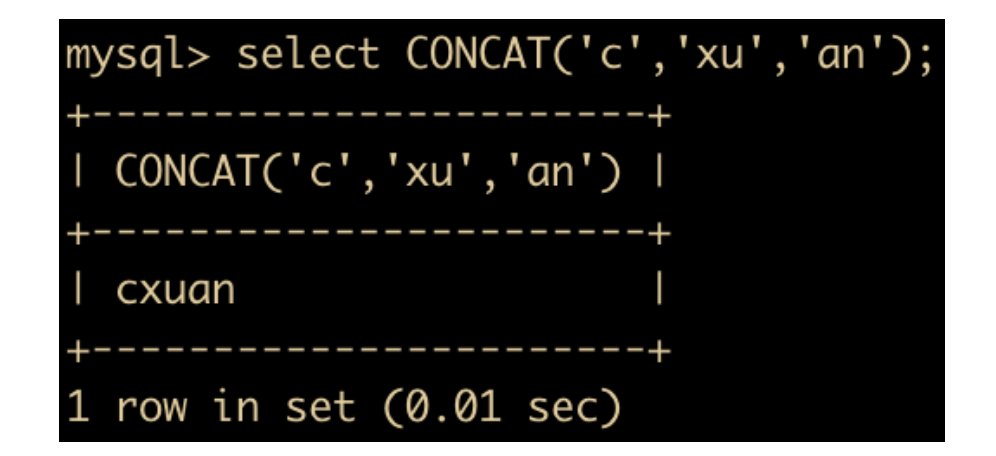
- CONCAT(s1,s2 … sn) :把传入的参数拼接成一个字符串

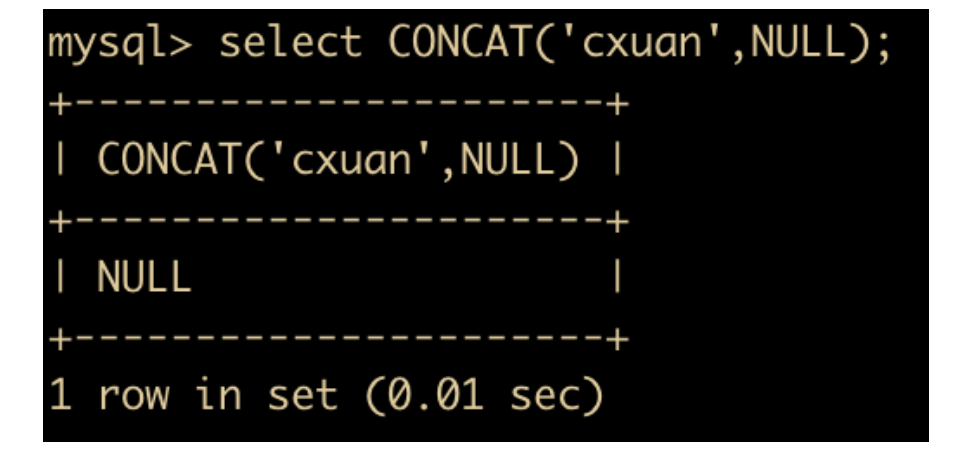
上面把 c xu an 拼接成为了一个字符串,另外需要注意一点,任何和 NULL 进行字符串拼接的结果都是 NULL。

- LEFT(str,x) 和 RIGHT(str,x) 函数:分别返回字符串最左边的 x 个字符和最右边的 x 个字符。如果第二个参数是 NULL,那么将不会返回任何字符串

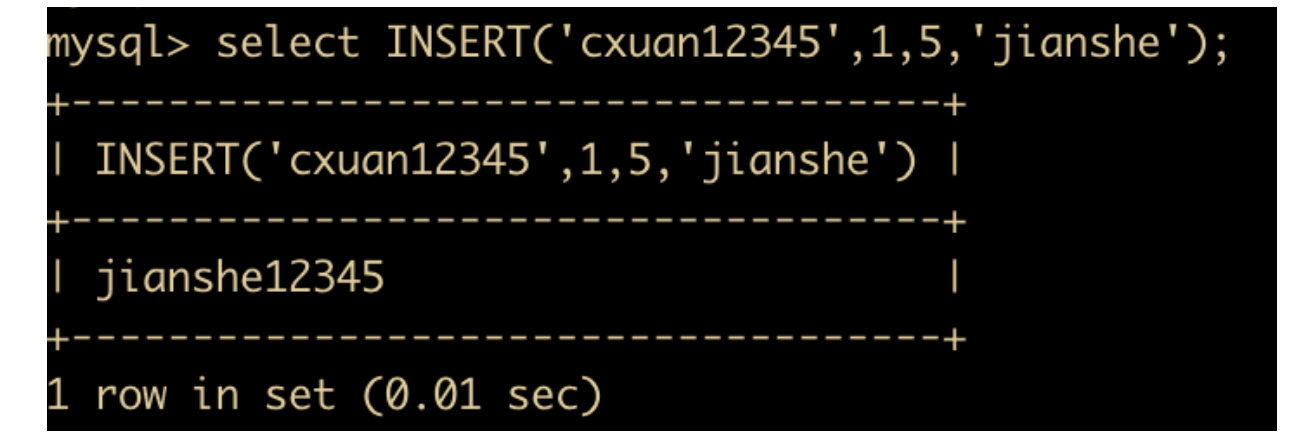
- INSERT(str,x,y,instr) : 将字符串 str 从指定 x 的位置开始, 取 y 个长度的字串替换为 instr。

- LTRIM(str) 和 RTRIM(str) 分别表示去掉字符串 str 左侧和右侧的空格

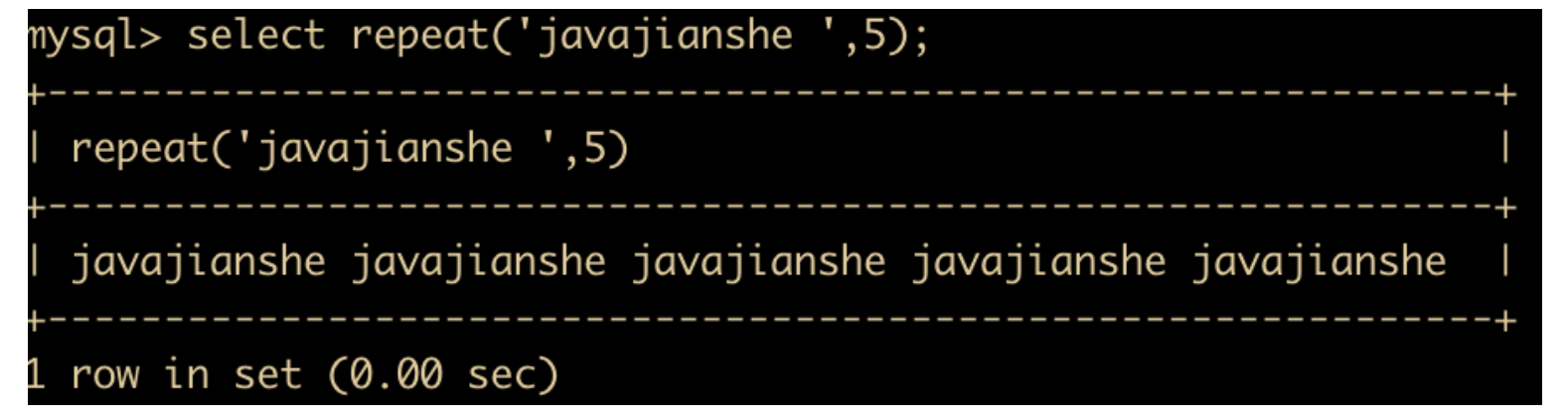
- REPEAT(str,x) 函数:返回 str 重复 x 次的结果

- TRIM(str) 函数:用于去掉目标字符串的空格

- SUBSTRING(str,x,y) 函数:返回从字符串 str 中第 x 位置起 y 个字符长度的字符串

- LPAD(str,n,pad) 和 RPAD(str,n,pad) 函数:用字符串 pad 对 str 左边和右边进行填充,直到长度为 n 个字符长度

- STRCMP(s1,s2) 用于比较字符串 s1 和 s2 的 ASCII 值大小。如果 s1 < s2,则返回 -1;如果 s1 = s2 ,返回 0 ;如果 s1 > s2 ,返回 1。

- REPLACE(str,a,b) : 用字符串 b 替换字符串 str 种所有出现的字符串 a

数值函数
MySQL 支持数值函数,这些函数能够处理很多数值运算。下面我们一起来学习一下 MySQL 中的数值函数,下面是所有的数值函数
| 函数 | 功能 |
|---|---|
| ABS | 返回绝对值 |
| CEIL | 返回大于某个值的最大整数值 |
| MOD | 返回模 |
| ROUND | 四舍五入 |
| FLOOR | 返回小于某个值的最大整数值 |
| TRUNCATE | 返回数字截断小数的结果 |
| RAND | 返回 0 – 1 的随机值 |
下面我们还是以实践为主来聊一聊这些用法
- ABS(x) 函数:返回 x 的绝对值

- CEIL(x) 函数: 返回大于 x 的整数

- MOD(x,y),对 x 和 y 进行取模操作

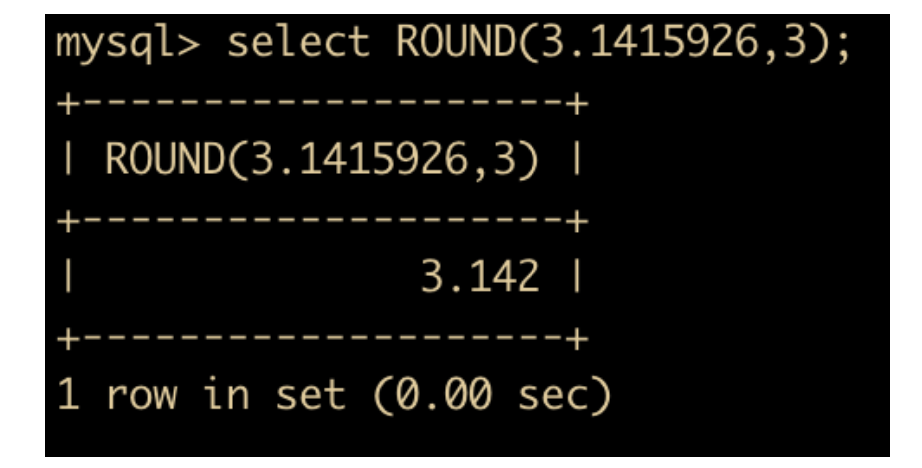
- ROUND(x,y) 返回 x 四舍五入后保留 y 位小数的值;如果是整数,那么 y 位就是 0 ;如果不指定 y ,那么 y 默认也是 0 。

- FLOOR(x) : 返回小于 x 的最大整数,用法与 CEIL 相反

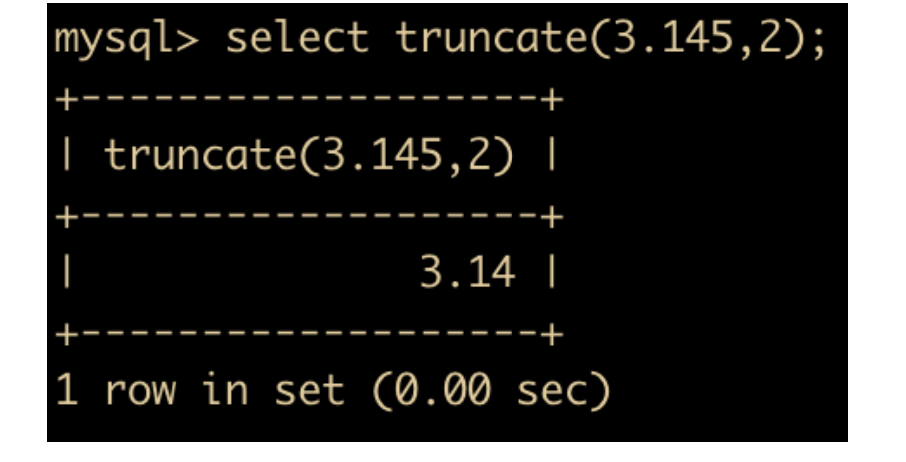
- TRUNCATE(x,y): 返回数字 x 截断为 y 位小数的结果, TRUNCATE 知识截断,并不是四舍五入。

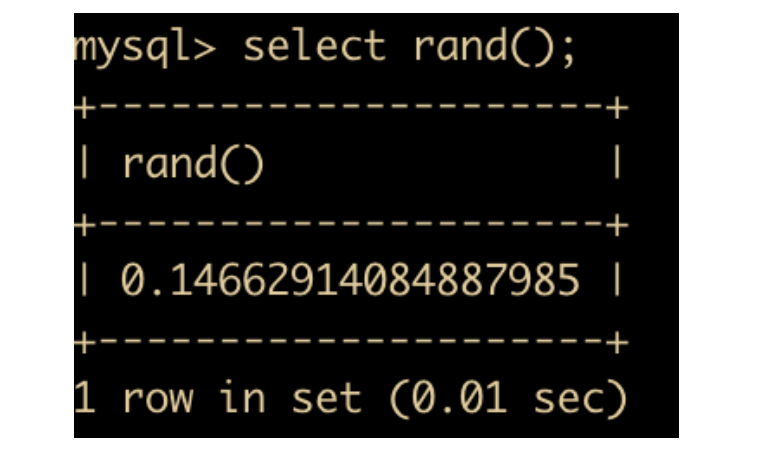
- RAND() :返回 0 到 1 的随机值

日期和时间函数
日期和时间函数也是 MySQL 中非常重要的一部分,下面我们就来一起认识一下这些函数
| 函数 | 功能 |
|---|---|
| NOW | 返回当前的日期和时间 |
| WEEK | 返回一年中的第几周 |
| YEAR | 返回日期的年份 |
| HOUR | 返回小时值 |
| MINUTE | 返回分钟值 |
| MONTHNAME | 返回月份名 |
| CURDATE | 返回当前日期 |
| CURTIME | 返回当前时间 |
| UNIX_TIMESTAMP | 返回日期 UNIX 时间戳 |
| DATE_FORMAT | 返回按照字符串格式化的日期 |
| FROM_UNIXTIME | 返回 UNIX 时间戳的日期值 |
| DATE_ADD | 返回日期时间 + 上一个时间间隔 |
| DATEDIFF | 返回起始时间和结束时间之间的天数 |
下面结合示例来讲解一下每个函数的使用
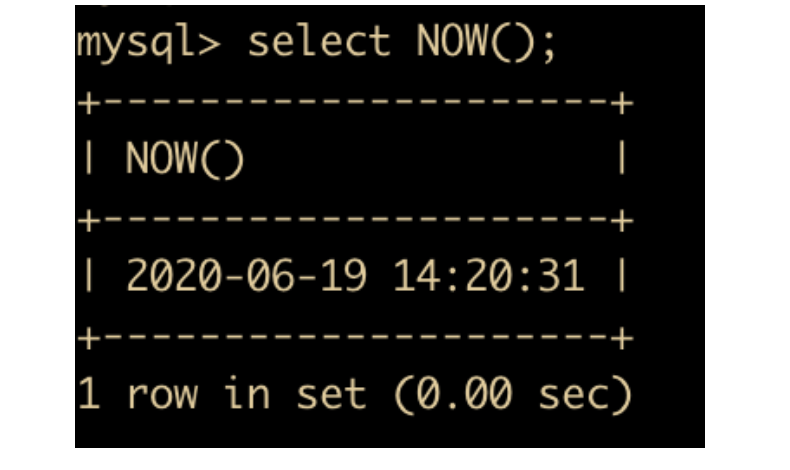
- NOW(): 返回当前的日期和时间

- WEEK(DATE) 和 YEAR(DATE) :前者返回的是一年中的第几周,后者返回的是给定日期的哪一年

- HOUR(time) 和 MINUTE(time) : 返回给定时间的小时,后者返回给定时间的分钟

- MONTHNAME(date) 函数:返回 date 的英文月份

- CURDATE() 函数:返回当前日期,只包含年月日

- CURTIME() 函数:返回当前时间,只包含时分秒

- UNIX_TIMESTAMP(date) : 返回 UNIX 的时间戳

- FROM_UNIXTIME(date) : 返回 UNIXTIME 时间戳的日期值,和 UNIX_TIMESTAMP 相反

- DATE_FORMAT(date,fmt) 函数:按照字符串 fmt 对 date 进行格式化,格式化后按照指定日期格式显示
具体的日期格式可以参考这篇文章 https://blog.csdn.net/weixin_38703170/article/details/82177837
我们演示一下将当前日期显示为年月日的这种形式,使用的日期格式是 %M %D %Y。

- DATE_ADD(date, interval, expr type) 函数:返回与所给日期 date 相差 interval 时间段的日期
interval 表示间隔类型的关键字,expr 是表达式,这个表达式对应后面的类型,type 是间隔类型,MySQL 提供了 13 种时间间隔类型
| 表达式类型 | 描述 | 格式 |
|---|---|---|
| YEAR | 年 | YY |
| MONTH | 月 | MM |
| DAY | 日 | DD |
| HOUR | 小时 | hh |
| MINUTE | 分 | mm |
| SECOND | 秒 | ss |
| YEAR_MONTH | 年和月 | YY-MM |
| DAY_HOUR | 日和小时 | DD hh |
| DAY_MINUTE | 日和分钟 | DD hh : mm |
| DAY_SECOND | 日和秒 | DD hh :mm :ss |
| HOUR_MINUTE | 小时和分 | hh:mm |
| HOUR_SECOND | 小时和秒 | hh:ss |
| MINUTE_SECOND | 分钟和秒 | mm:ss |
- DATE_DIFF(date1, date2) 用来计算两个日期之间相差的天数

查看离 2021 – 01 – 01 还有多少天
流程函数
流程函数也是很常用的一类函数,用户可以使用这类函数在 SQL 中实现条件选择。这样做能够提高查询效率。下表列出了这些流程函数
| 函数 | 功能 |
|---|---|
| IF(value,t f) | 如果 value 是真,返回 t;否则返回 f |
| IFNULL(value1,value2) | 如果 value1 不为 NULL,返回 value1,否则返回 value2。 |
| CASE WHEN[value1] THEN[result1] …ELSE[default] END | 如果 value1 是真,返回 result1,否则返回 default |
| CASE[expr] WHEN[value1] THEN [result1]… ELSE[default] END | 如果 expr 等于 value1, 返回 result1, 否则返回 default |
其他函数
除了我们介绍过的字符串函数、日期和时间函数、流程函数,还有一些函数并不属于上面三类函数,它们是
| 函数 | 功能 |
|---|---|
| VERSION | 返回当前数据库的版本 |
| DATABASE | 返回当前数据库名 |
| USER | 返回当前登陆用户名 |
| PASSWORD | 返回字符串的加密版本 |
| MD5 | 返回 MD5 值 |
| INET_ATON(IP) | 返回 IP 地址的数字表示 |
| INET_NTOA(num) | 返回数字代表的 IP 地址 |
下面来看一下具体的使用
- VERSION: 返回当前数据库版本

- DATABASE: 返回当前的数据库名

- USER : 返回当前登录用户名

- PASSWORD(str) : 返回字符串的加密版本,例如

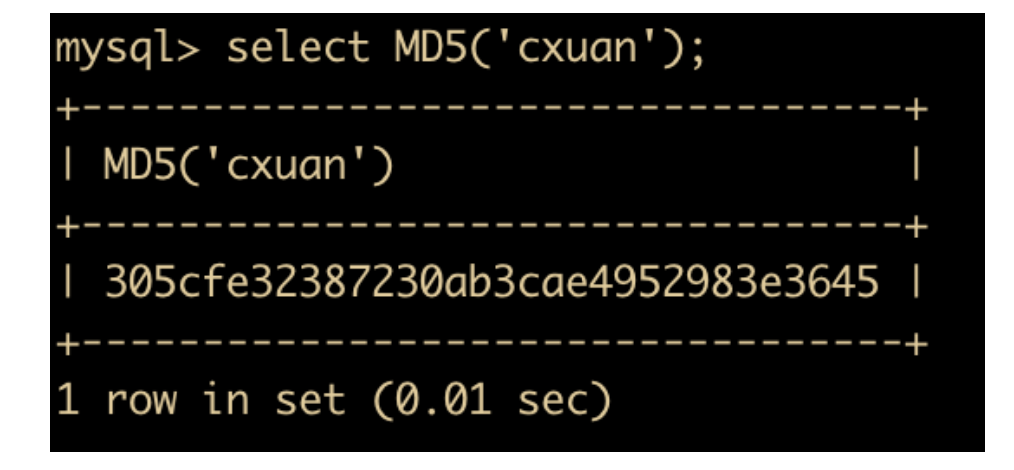
- MD5(str) 函数:返回字符串 str 的 MD5 值

- INET_ATON(IP): 返回 IP 的网络字节序列

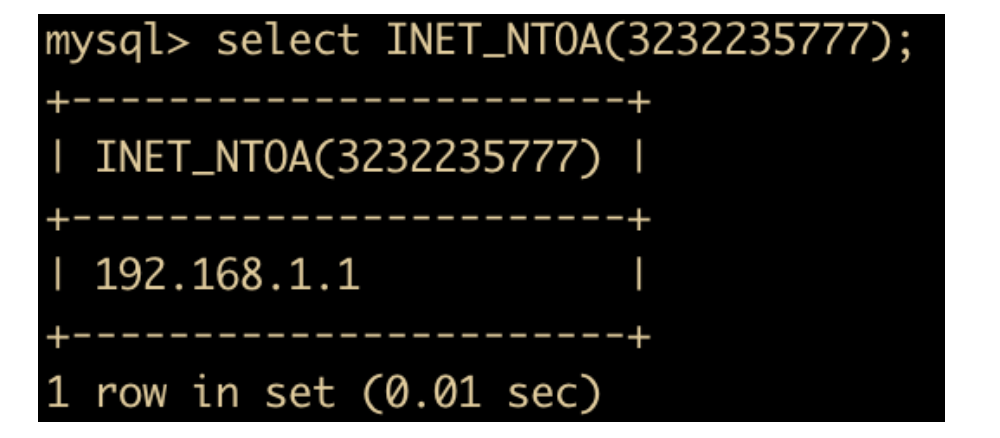
- INET_NTOA(num)函数:返回网络字节序列代表的 IP 地址,与 INET_ATON 相对

总结
这篇文章我带你手把手撸了一波 MySQL 的高级内容,其实说高级也不一定真的高级或者说难,其实就是区分不同梯度的东西。
# MySQL开发-Java面试题
我们在 MySQL 入门篇主要介绍了基本的 SQL 命令、数据类型和函数,在局部以上知识后,你就可以进行 MySQL 的开发工作了,但是如果要成为一个合格的开发人员,你还要具备一些更高级的技能,下面我们就来探讨一下 MySQL 都需要哪些高级的技能
MySQL 存储引擎
存储引擎概述
数据库最核心的一点就是用来存储数据,数据存储就避免不了和磁盘打交道。那么数据以哪种方式进行存储,如何存储是存储的关键所在。所以存储引擎就相当于是数据存储的发动机,来驱动数据在磁盘层面进行存储。
MySQL 的架构可以按照三层模式来理解
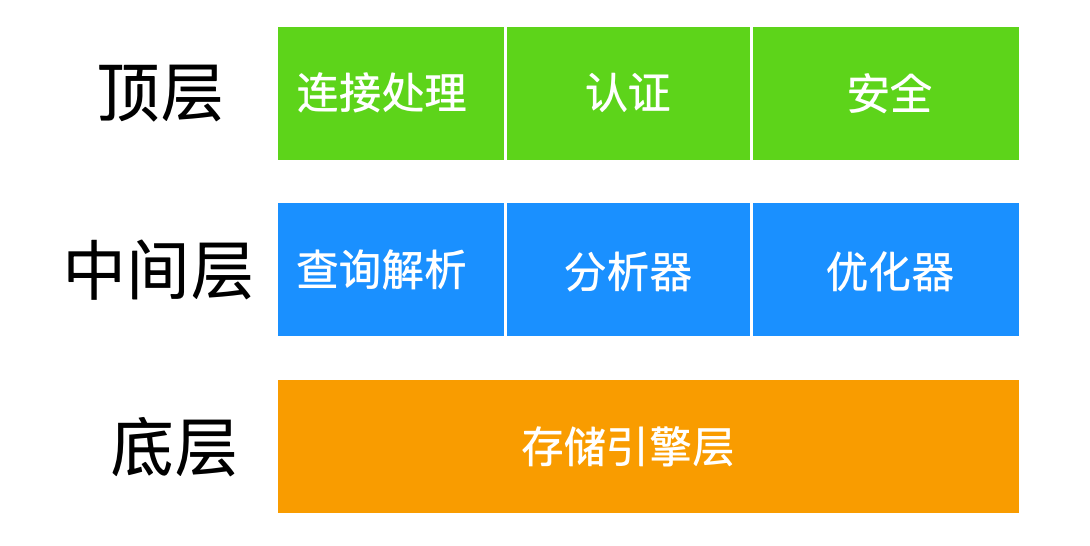
存储引擎也是 MySQL 的组建,它是一种软件,它所能做的和支持的功能主要有
- 并发
- 支持事务
- 完整性约束
- 物理存储
- 支持索引
- 性能帮助
MySQL 默认支持多种存储引擎,来适用不同数据库应用,用户可以根据需要选择合适的存储引擎,下面是 MySQL 支持的存储引擎
- MyISAM
- InnoDB
- BDB
- MEMORY
- MERGE
- EXAMPLE
- NDB Cluster
- ARCHIVE
- CSV
- BLACKHOLE
- FEDERATED
默认情况下,如果创建表不指定存储引擎,会使用默认的存储引擎,如果要修改默认的存储引擎,那么就可以在参数文件中设置 default-table-type,能够查看当前的存储引擎
show variables like 'table_type';

奇怪,为什么没有了呢?网上求证一下,在 5.5.3 取消了这个参数
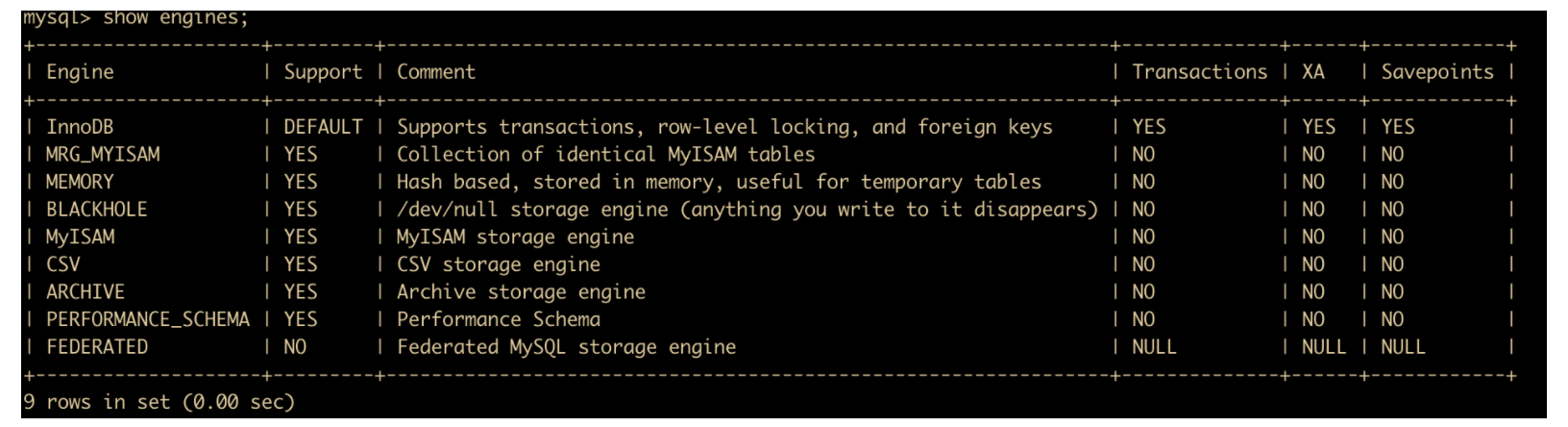
可以通过下面两种方法查询当前数据库支持的存储引擎
show engines \g
在创建新表的时候,可以通过增加 ENGINE 关键字设置新建表的存储引擎。
create table cxuan002(id int(10),name varchar(20)) engine = MyISAM;

上图我们指定了 MyISAM 的存储引擎。
如果你不知道表的存储引擎怎么办?你可以通过 show create table 来查看

如果不指定存储引擎的话,从MySQL 5.1 版本之后,MySQL 的默认内置存储引擎已经是 InnoDB了。建一张表看一下

如上图所示,我们没有指定默认的存储引擎,下面查看一下表
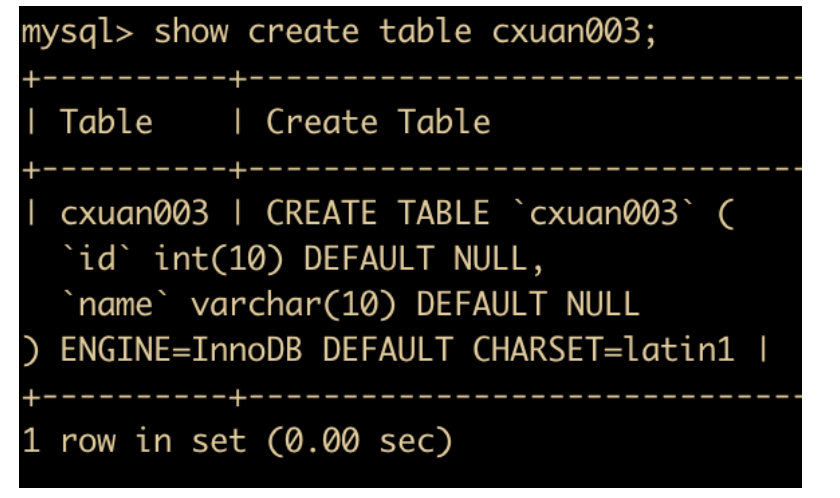
可以看到,默认的存储引擎是 InnoDB。
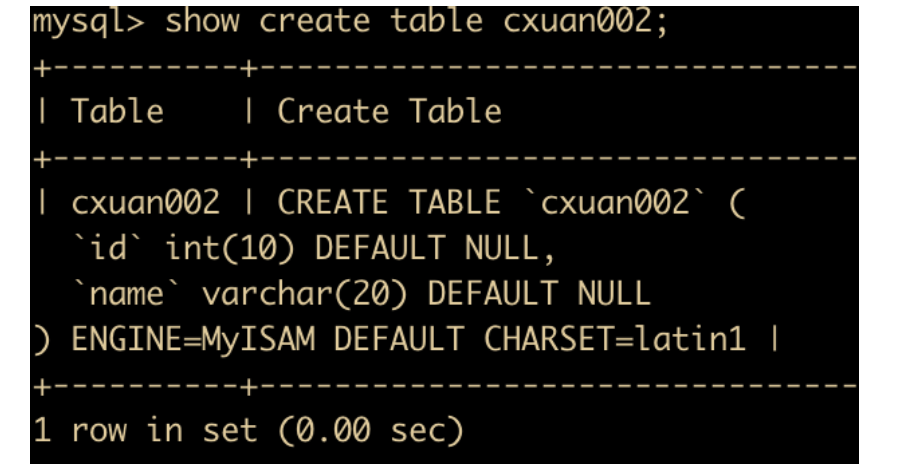
如果你的存储引擎想要更换,可以使用
alter table cxuan003 engine = myisam;
来更换,更换完成后回显示 0 rows affected ,但其实已经操作成功

我们使用 show create table 查看一下表的 sql 就知道
存储引擎特性
下面会介绍几个常用的存储引擎以及它的基本特性,这些存储引擎是 MyISAM、InnoDB、MEMORY 和 MERGE
MyISAM
在 5.1 版本之前,MyISAM 是 MySQL 的默认存储引擎,MyISAM 并发性比较差,使用的场景比较少,主要特点是
不支持
事务操作,ACID 的特性也就不存在了,这一设计是为了性能和效率考虑的。不支持
外键操作,如果强行增加外键,MySQL 不会报错,只不过外键不起作用。MyISAM 默认的锁粒度是
表级锁,所以并发性能比较差,加锁比较快,锁冲突比较少,不太容易发生死锁的情况。MyISAM 会在磁盘上存储三个文件,文件名和表名相同,扩展名分别是
.frm(存储表定义)、.MYD(MYData,存储数据)、MYI(MyIndex,存储索引)。这里需要特别注意的是 MyISAM 只缓存索引文件,并不缓存数据文件。MyISAM 支持的索引类型有
全局索引(Full-Text)、B-Tree 索引、R-Tree 索引Full-Text 索引:它的出现是为了解决针对文本的模糊查询效率较低的问题。
B-Tree 索引:所有的索引节点都按照平衡树的数据结构来存储,所有的索引数据节点都在叶节点
R-Tree索引:它的存储方式和 B-Tree 索引有一些区别,主要设计用于存储空间和多维数据的字段做索引,目前的 MySQL 版本仅支持 geometry 类型的字段作索引,相对于 BTREE,RTREE 的优势在于范围查找。
数据库所在主机如果宕机,MyISAM 的数据文件容易损坏,而且难以恢复。
增删改查性能方面:SELECT 性能较高,适用于查询较多的情况
InnoDB
自从 MySQL 5.1 之后,默认的存储引擎变成了 InnoDB 存储引擎,相对于 MyISAM,InnoDB 存储引擎有了较大的改变,它的主要特点是
- 支持事务操作,具有事务 ACID 隔离特性,默认的隔离级别是
可重复读(repetable-read)、通过MVCC(并发版本控制)来实现的。能够解决脏读和不可重复读的问题。 - InnoDB 支持外键操作。
- InnoDB 默认的锁粒度
行级锁,并发性能比较好,会发生死锁的情况。 - 和 MyISAM 一样的是,InnoDB 存储引擎也有
.frm文件存储表结构定义,但是不同的是,InnoDB 的表数据与索引数据是存储在一起的,都位于 B+ 数的叶子节点上,而 MyISAM 的表数据和索引数据是分开的。 - InnoDB 有安全的日志文件,这个日志文件用于恢复因数据库崩溃或其他情况导致的数据丢失问题,保证数据的一致性。
- InnoDB 和 MyISAM 支持的索引类型相同,但具体实现因为文件结构的不同有很大差异。
- 增删改查性能方面,果执行大量的增删改操作,推荐使用 InnoDB 存储引擎,它在删除操作时是对行删除,不会重建表。
MEMORY
MEMORY 存储引擎使用存在内存中的内容来创建表。每个 MEMORY 表实际只对应一个磁盘文件,格式是 .frm。 MEMORY 类型的表访问速度很快,因为其数据是存放在内存中。默认使用 HASH 索引。
MERGE
MERGE 存储引擎是一组 MyISAM 表的组合,MERGE 表本身没有数据,对 MERGE 类型的表进行查询、更新、删除的操作,实际上是对内部的 MyISAM 表进行的。MERGE 表在磁盘上保留两个文件,一个是 .frm 文件存储表定义、一个是 .MRG 文件存储 MERGE 表的组成等。
选择合适的存储引擎
在实际开发过程中,我们往往会根据应用特点选择合适的存储引擎。
- MyISAM:如果应用程序通常以检索为主,只有少量的插入、更新和删除操作,并且对事物的完整性、并发程度不是很高的话,通常建议选择 MyISAM 存储引擎。
- InnoDB:如果使用到外键、需要并发程度较高,数据一致性要求较高,那么通常选择 InnoDB 引擎,一般互联网大厂对并发和数据完整性要求较高,所以一般都使用 InnoDB 存储引擎。
- MEMORY:MEMORY 存储引擎将所有数据保存在内存中,在需要快速定位下能够提供及其迅速的访问。MEMORY 通常用于更新不太频繁的小表,用于快速访问取得结果。
- MERGE:MERGE 的内部是使用 MyISAM 表,MERGE 表的优点在于可以突破对单个 MyISAM 表大小的限制,并且通过将不同的表分布在多个磁盘上, 可以有效地改善 MERGE 表的访问效率。
选择合适的数据类型
我们会经常遇见的一个问题就是,在建表时如何选择合适的数据类型,通常选择合适的数据类型能够提高性能、减少不必要的麻烦,下面我们就来一起探讨一下,如何选择合适的数据类型。
CHAR 和 VARCHAR 的选择
char 和 varchar 是我们经常要用到的两个存储字符串的数据类型,char 一般存储定长的字符串,它属于固定长度的字符类型,比如下面
| 值 | char(5) | 存储字节 |
|---|---|---|
| ” | ‘ ‘ | 5个字节 |
| ‘cx’ | ‘cx ‘ | 5个字节 |
| ‘cxuan’ | ‘cxuan’ | 5个字节 |
| ‘cxuan007’ | ‘cxuan’ | 5个字节 |
可以看到,不管你的值写的是什么,一旦指定了 char 字符的长度,如果你的字符串长度不够指定字符的长度的话,那么就用空格来填补,如果超过字符串长度的话,只存储指定字符长度的字符。
这里注意一点:如果 MySQL 使用了非
严格模式的话,上面表格最后一行是可以存储的。如果 MySQL 使用了严格模式的话,那么表格上面最后一行存储会报错。
如果使用了 varchar 字符类型,我们来看一下例子
| 值 | varchar(5) | 存储字节 |
|---|---|---|
| ” | ” | 1个字节 |
| ‘cx’ | ‘cx ‘ | 3个字节 |
| ‘cxuan’ | ‘cxuan’ | 6个字节 |
| ‘cxuan007’ | ‘cxuan’ | 6个字节 |
可以看到,如果使用 varchar 的话,那么存储的字节将根据实际的值进行存储。你可能会疑惑为什么 varchar 的长度是 5 ,但是却需要存储 3 个字节或者 6 个字节,这是因为使用 varchar 数据类型进行存储时,默认会在最后增加一个字符串长度,占用1个字节(如果列声明的长度超过255,则使用两个字节)。varchar 不会填充空余的字符串。
一般使用 char 来存储定长的字符串,比如身份证号、手机号、邮箱等;使用 varchar 来存储不定长的字符串。由于 char 长度是固定的,所以它的处理速度要比 VARCHAR 快很多,但是缺点是浪费存储空间,但是随着 MySQL 版本的不断演进,varchar 数据类型的性能也在不断改进和提高,所以在许多应用中,VARCHAR 类型更多的被使用。
在 MySQL 中,不同的存储引擎对 CHAR 和 VARCHAR 的使用原则也有不同
- MyISAM:建议使用固定长度的数据列替代可变长度的数据列,也就是 CHAR
- MEMORY:使用固定长度进行处理、CHAR 和 VARCHAR 都会被当作 CHAR 处理
- InnoDB:建议使用 VARCHAR 类型
TEXT 与 BLOB
一般在保存较少的文本的时候,我们会选择 CHAR 和 VARCHAR,在保存大数据量的文本时,我们往往选择 TEXT 和 BLOB;TEXT 和 BLOB 的主要差别是 BLOB 能够保存二进制数据;而 TEXT 只能保存字符数据,TEXT 往下细分有
- TEXT
- MEDIUMTEXT
- LONGTEXT
BLOB 往下细分有
- BLOB
- MEDIUMBLOB
- LONGBLOB
三种,它们最主要的区别就是存储文本长度不同和存储字节不同,用户应该根据实际情况选择满足需求的最小存储类型,下面主要对 BLOB 和 TEXT 存在一些问题进行介绍
TEXT 和 BLOB 在删除数据后会存在一些性能上的问题,为了提高性能,建议使用 OPTIMIZE TABLE 功能对表进行碎片整理。
也可以使用合成索引来提高文本字段(BLOB 和 TEXT)的查询性能。合成索引就是根据大文本(BLOB 和 TEXT)字段的内容建立一个散列值,把这个值存在对应列中,这样就能够根据散列值查找到对应的数据行。一般使用散列算法比如 md5() 和 SHA1() ,如果散列算法生成的字符串带有尾部空格,就不要把它们存在 CHAR 和 VARCHAR 中,下面我们就来看一下这种使用方式
首先创建一张表,表中记录 blob 字段和 hash 值
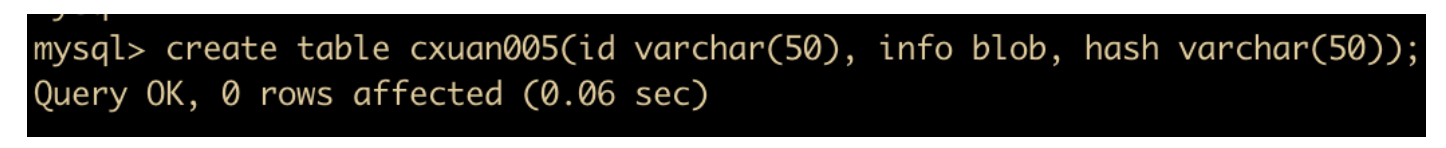
向 cxuan005 中插入数据,其中 hash 值作为 info 的散列值。

然后再插入两条数据

插入一条 info 为 cxuan005 的数据

如果想要查询 info 为 cxuan005 的数据,可以通过查询 hash 列来进行查询

这是合成索引的例子,如果要对 BLOB 进行模糊查询的话,就要使用前缀索引。
其他优化 BLOB 和 TEXT 的方式:
- 非必要的时候不要检索 BLOB 和 TEXT 索引
- 把 BLOB 或 TEXT 列分离到单独的表中。
浮点数和定点数的选择
浮点数指的就是含有小数的值,浮点数插入到指定列中超过指定精度后,浮点数会四舍五入,MySQL 中的浮点数指的就是 float 和 double,定点数指的是 decimal,定点数能够更加精确的保存和显示数据。下面通过一个示例讲解一下浮点数精确性问题
首先创建一个表 cxuan006 ,只为了测试浮点数问题,所以这里我们选择的数据类型是 float

然后分别插入两条数据
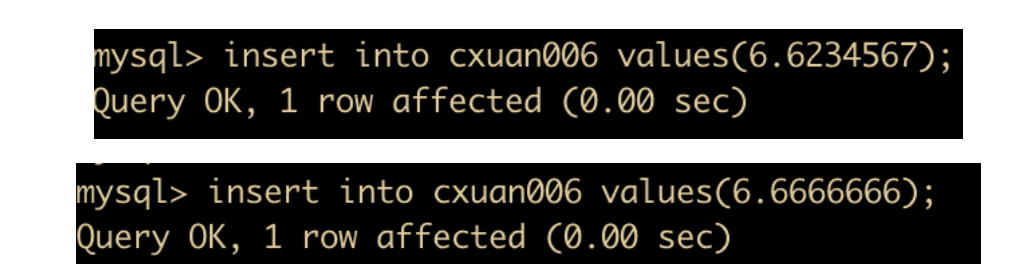
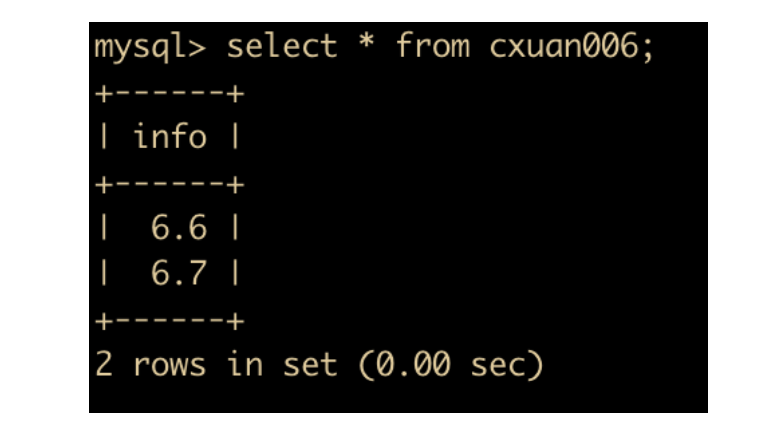
然后执行查询,可以看到查询出来的两条数据执行的舍入不同
为了清晰的看清楚浮点数与定点数的精度问题,再来看一个例子

先修改 cxuan006 的两个字段为相同的长度和小数位数
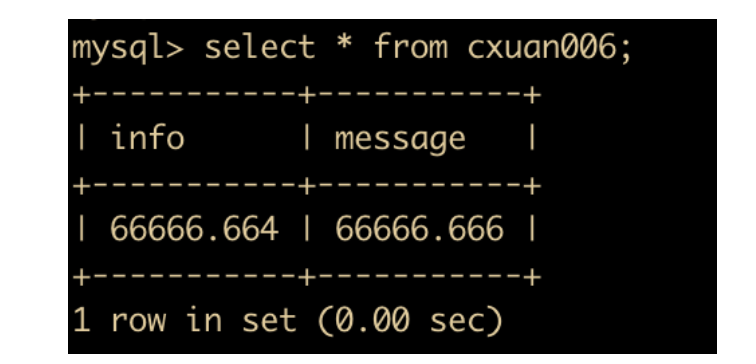
然后插入两条数据

执行查询操作,可以发现,浮点数相较于定点数来说,会产生误差
日期类型选择
在 MySQL 中,用来表示日期类型的有 DATE、TIME、DATETIME、TIMESTAMP,在
这篇文中介绍过了日期类型的区别,我们这里就不再阐述了。下面主要介绍一下选择
- TIMESTAMP 和时区相关,更能反映当前时间,如果记录的日期需要让不同时区的人使用,最好使用 TIMESTAMP。
- DATE 用于表示年月日,如果实际应用值需要保存年月日的话就可以使用 DATE。
- TIME 用于表示时分秒,如果实际应用值需要保存时分秒的话就可以使用 TIME。
- YEAR 用于表示年份,YEAR 有 2 位(最好使用4位)和 4 位格式的年。 默认是4位。如果实际应用只保存年份,那么用 1 bytes 保存 YEAR 类型完全可以。不但能够节约存储空间,还能提高表的操作效率。
MySQL 字符集
下面来认识一下 MySQL 字符集,简单来说字符集就是一套文字符号和编码、比较规则的集合。1960 年美国标准化组织 ANSI 发布了第一个计算机字符集,就是著名的 ASCII(American Standard Code for Information Interchange) 。自从 ASCII 编码后,每个国家、国际组织都研究了一套自己的字符集,比如 ISO-8859-1、GBK 等。
但是每个国家都使用自己的字符集为移植性带来了很大的困难。所以,为了统一字符编码,国际标准化组织(ISO) 指定了统一的字符标准 – Unicode 编码,它容纳了几乎所有的字符编码。下面是一些常见的字符编码
| 字符集 | 是否定长 | 编码方式 |
|---|---|---|
| ASCII | 是 | 单字节 7 位编码 |
| ISO-8859-1 | 是 | 单字节 8 位编码 |
| GBK | 是 | 双字节编码 |
| UTF-8 | 否 | 1 – 4 字节编码 |
| UTF-16 | 否 | 2 字节或 4 字节编码 |
| UTF-32 | 是 | 4 字节编码 |
对数据库来说,字符集是很重要的,因为数据库存储的数据大多数都是各种文字,字符集对数据库的存储、性能、系统的移植来说都非常重要。
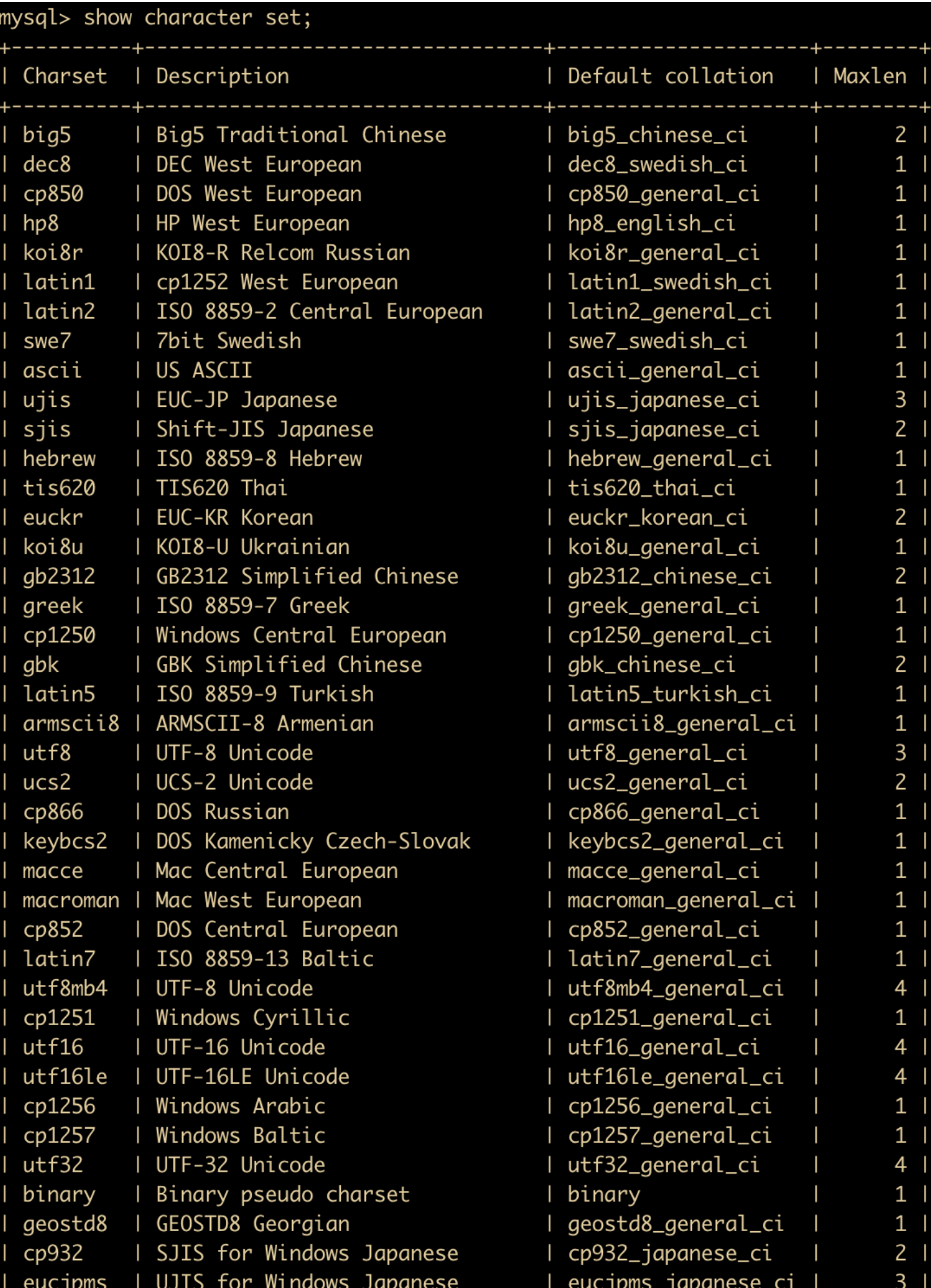
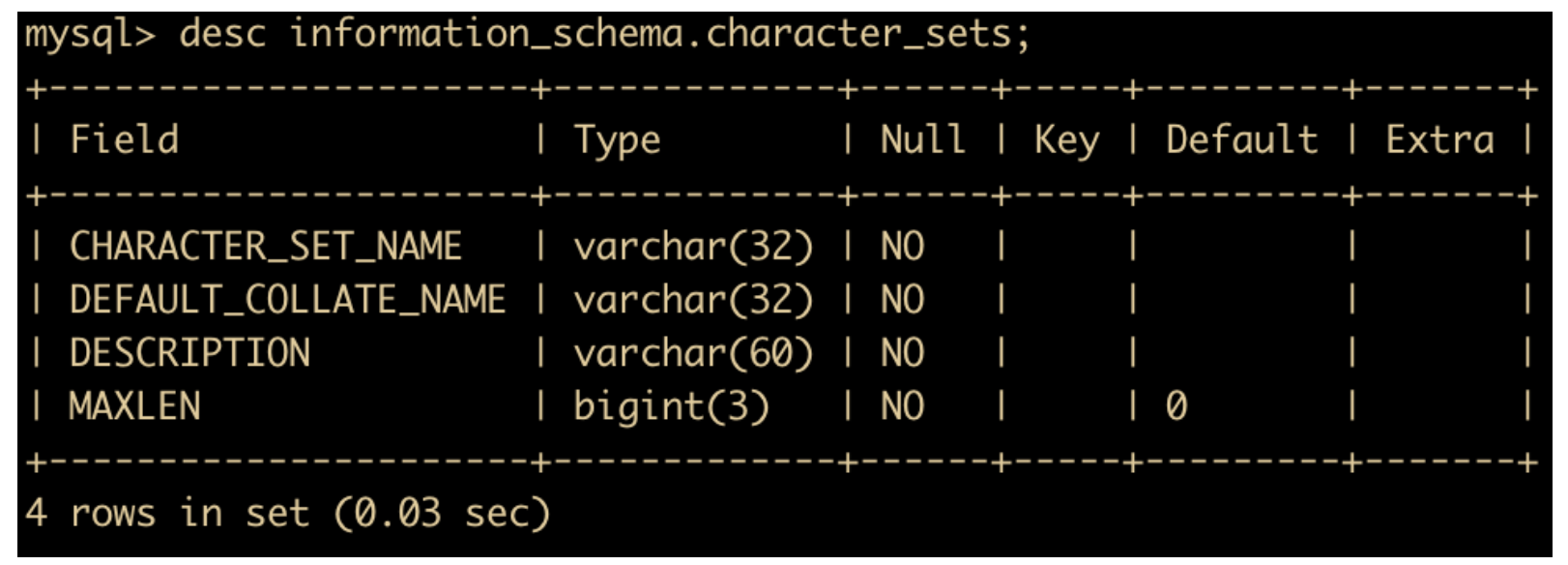
MySQL 支持多种字符集,可以使用 show character set; 来查看所有可用的字符集
或者使用
select character_set_name, default_collate_name, description, maxlen from information_schema.character_sets;
来查看。
使用 information_schema.character_set 来查看字符集和校对规则。
# MySQL优化-Java面试题
一般传统互联网公司很少接触到 SQL 优化问题,其原因是数据量小,大部分厂商的数据库性能能够满足日常的业务需求,所以不需要进行 SQL 优化,但是随着应用程序的不断变大,数据量的激增,数据库自身的性能跟不上了,此时就需要从 SQL 自身角度来进行优化,这也是我们这篇文章所讨论的。
SQL 优化步骤
当面对一个需要优化的 SQL 时,我们有哪几种排查思路呢?
通过 show status 命令了解 SQL 执行次数
首先,我们可以使用 show status 命令查看服务器状态信息。show status 命令会显示每个服务器变量 variable_name 和 value,状态变量是只读的。如果使用 SQL 命令,可以使用 like 或者 where 条件来限制结果。like 可以对变量名做标准模式匹配。
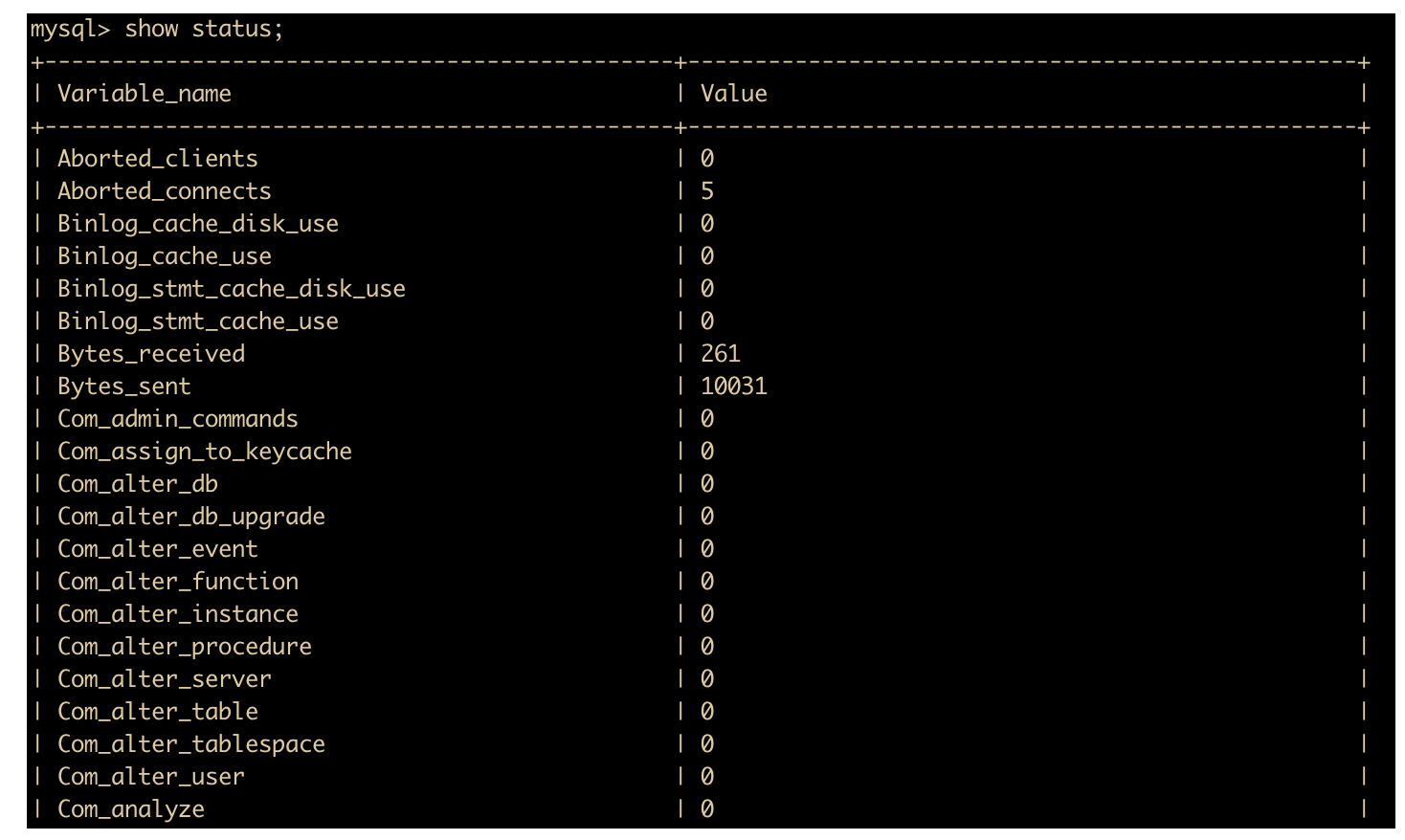
图我没有截全,下面还有很多变量,读者可以自己尝试一下。也可以在操作系统上使用 mysqladmin extended-status 命令来获取这些消息。
但是我执行 mysqladmin extended-status 后,出现这个错误。

应该是我没有输入密码的原因,使用 mysqladmin -P3306 -uroot -p -h127.0.0.1 -r -i 1 extended-status 后,问题解决。
这里需要注意一下 show status 命令中可以添加统计结果的级别,这个级别有两个
- session 级: 默认当前链接的统计结果
- global 级:自数据库上次启动到现在的统计结果
如果不指定统计结果级别的话,默认使用 session 级别。
对于 show status 查询出来的统计结果,有两类参数需要注意下,一类是以 Com_ 为开头的参数,一类是以 Innodb_ 为开头的参数。
下面是 Com_ 为开头的参数,参数很多,我同样没有截全。
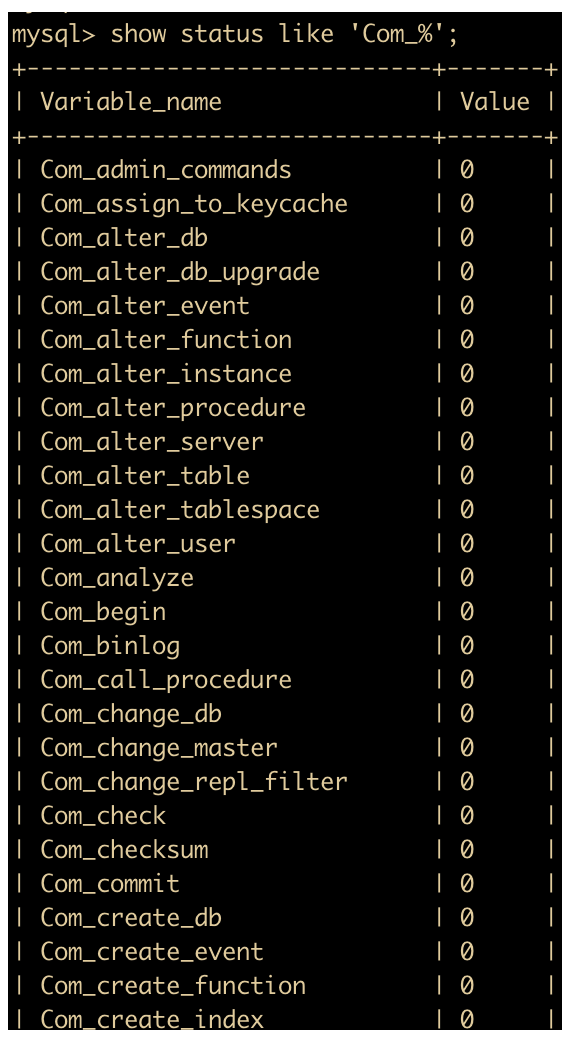
Com_xxx 表示的是每个 xxx 语句执行的次数,我们通常关心的是 select 、insert 、update、delete 语句的执行次数,即
- Com_select:执行 select 操作的次数,一次查询会使结果 + 1。
- Com_insert:执行 INSERT 操作的次数,对于批量插入的 INSERT 操作,只累加一次。
- Com_update:执行 UPDATE 操作的次数。
- Com_delete:执行 DELETE 操作的次数。
以 Innodb_ 为开头的参数主要有
- Innodb_rows_read:执行 select 查询返回的行数。
- Innodb_rows_inserted:执行 INSERT 操作插入的行数。
- Innodb_rows_updated:执行 UPDATE 操作更新的行数。
- Innodb_rows_deleted:执行 DELETE 操作删除的行数。
通过上面这些参数执行结果的统计,我们能够大致了解到当前数据库是以更新(包括插入、删除)为主还是查询为主。
除此之外,还有一些其他参数用于了解数据库的基本情况。
- Connections:查询 MySQL 数据库的连接次数,这个次数是不管连接是否成功都算上。
- Uptime:服务器的工作时间。
- Slow_queries:满查询次数。
- Threads_connected:查看当前打开的连接的数量。
下面这个博客汇总了几乎所有 show status 的参数,可以当作参考手册。
https://blog.csdn.net/ayay_870621/article/details/88633092
定位执行效率较低的 SQL
定位执行效率比较慢的 SQL 语句,一般有两种方式
- 可以通过慢查询日志来定位哪些执行效率较低的 SQL 语句。
MySQL 中提供了一个慢查询的日志记录功能,可以把查询 SQL 语句时间大于多少秒的语句写入慢查询日志,日常维护中可以通过慢查询日志的记录信息快速准确地判断问题所在。用 –log-slow-queries 选项启动时,mysqld 会写一个包含所有执行时间超过 long_query_time 秒的 SQL 语句的日志文件,通过查看这个日志文件定位效率较低的 SQL 。
比如我们可以在 my.cnf 中添加如下代码,然后退出重启 MySQL。
log-slow-queries = /tmp/mysql-slow.log long_query_time = 2
通常我们设置最长的查询时间是 2 秒,表示查询时间超过 2 秒就记录了,通常情况下 2 秒就够了,然而对于很多 WEB 应用来说,2 秒时间还是比较长的。
也可以通过命令来开启:
我们先查询 MySQL 慢查询日志是否开启
show variables like "%slow%";
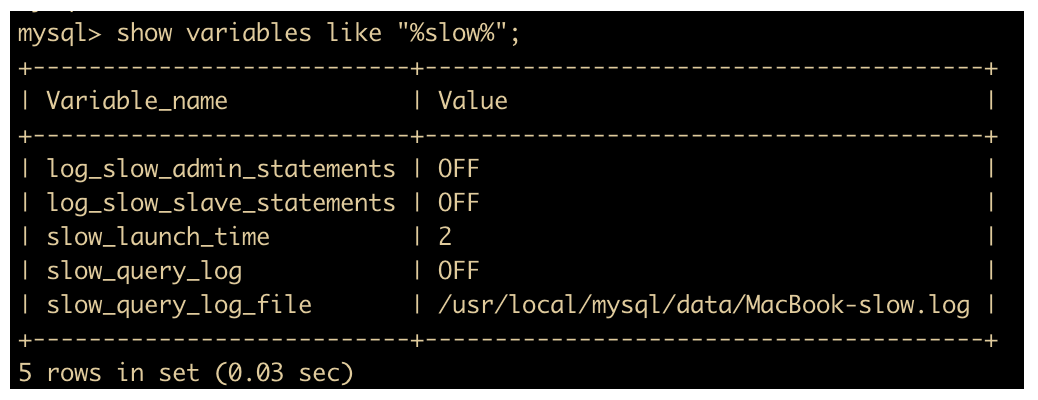
启用慢查询日志
set global slow_query_log='ON';

然后再次查询慢查询是否开启
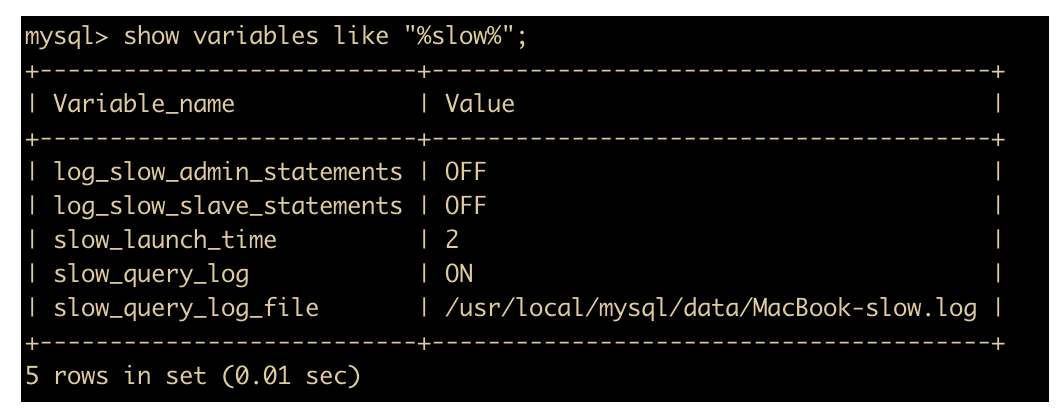
如图所示,我们已经开启了慢查询日志。
慢查询日志会在查询结束以后才记录,所以在应用反应执行效率出现问题的时候慢查询日志并不能定位问题,此时应该使用 show processlist 命令查看当前 MySQL 正在进行的线程。包括线程的状态、是否锁表等,可以实时的查看 SQL 执行情况。同样,使用mysqladmin processlist语句也能得到此信息。
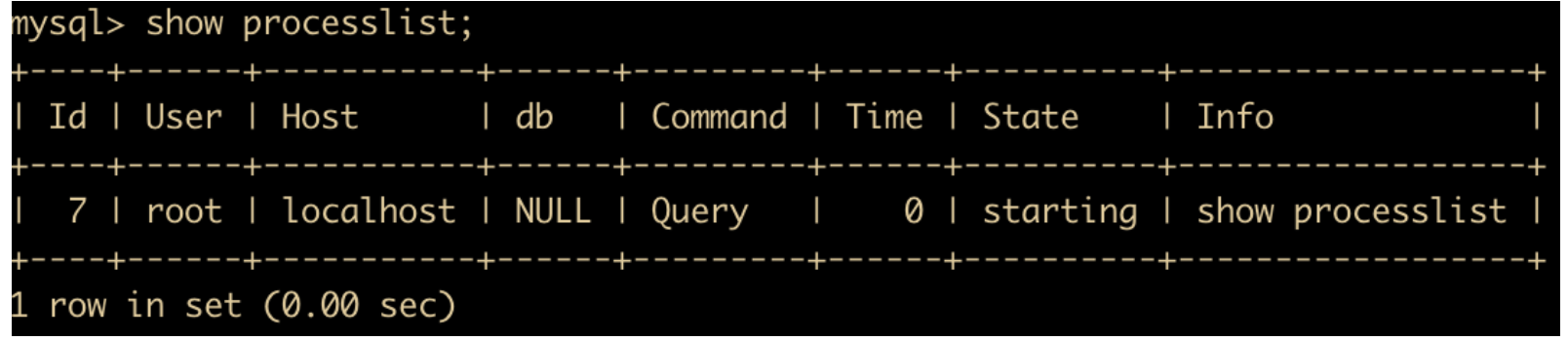
下面就来解释一下各个字段对应的概念
- Id :Id 就是一个标示,在我们使用 kill 命令杀死进程的时候很有用,比如 kill 进程号。
- User:显示当前的用户,如果不是 root,这个命令就只显示你权限范围内的 SQL 语句。
- Host:显示 IP ,用于追踪问题
- Db:显示这个进程目前连接的是哪个数据库,为 null 是还没有 select 数据库。
- Command:显示当前连接锁执行的命令,一般有三种:查询 query,休眠 sleep,连接 connect。
- Time:这个状态持续的时间,单位是秒
- State:显示当前 SQL 语句的状态,非常重要,下面会具体解释。
- Info:显示这个 SQL 语句。
State 列非常重要,关于这个列的内容比较多,读者可以参考一下这篇文章
https://blog.csdn.net/weixin_34357436/article/details/91768402
这里面涉及线程的状态、是否锁表等选项,可以实时的查看 SQL 的执行情况,同时对一些锁表进行优化。
通过 EXPLAIN 命令分析 SQL 的执行计划
通过以上步骤查询到效率低的 SQL 语句后,可以通过 EXPLAIN 或者 DESC 命令获取 MySQL 如何执行 SELECT 语句的信息,包括在 SELECT 语句执行过程中表如何连接和连接的顺序。
比如我们使用下面这条 SQL 语句来分析一下执行计划
explain select * from test1;

上表中涉及内容如下
- select_type:表示常见的 SELECT 类型,常见的有 SIMPLE,SIMPLE 表示的是简单的 SQL 语句,不包括 UNION 或者子查询操作,比如下面这段就是 SIMPLE 类型。

PRIMARY ,查询中最外层的 SELECT(如两表做 UNION 或者存在子查询的外层的表操作为 PRIMARY,内层的操作为 UNION),比如下面这段子查询。

UNION,在 UNION 操作中,查询中处于内层的 SELECT(内层的 SELECT 语句与外层的 SELECT 语句没有依赖关系时)。
SUBQUERY:子查询中首个SELECT(如果有多个子查询存在),如我们上面的查询语句,子查询第一个是 sr(sys_role)表,所以它的 select_type 是 SUBQUERY。
table ,这个选项表示输出结果集的表。
type,这个选项表示表的连接类型,这个选项很有深入研究的价值,因为很多 SQL 的调优都是围绕 type 来讲的,但是这篇文章我们主要围绕优化方式来展开的,type 这个字段我们暂时作为了解,这篇文章不过多深入。
type 这个字段会牵扯到连接的性能,它的不同类型的性能由好到差分别是
system :表中仅有一条数据时,该表的查询就像查询常量表一样。
const :当表中只有一条记录匹配时,比如使用了表主键(primary key)或者表唯一索引(unique index)进行查询。
eq-ref :表示多表连接时使用表主键或者表唯一索引,比如
select A.text, B.text where A.ID = B.ID
这个查询语句,对于 A 表中的每一个 ID 行,B 表中都只能有唯一的 B.Id 来进行匹配时。
ref :这个类型不如上面的 eq-ref 快,因为它表示的是因为对于表 A 中扫描的每一行,表 C 中有几个可能的行,C.ID 不是唯一的。
ref_or_null :与 ref 类似,只不过这个选项包含对 NULL 的查询。
index_merge :查询语句使用了两个以上的索引,比如经常在有 and 和 or 关键字出现的场景,但是在由于读取索引过多导致其性能有可能还不如 range(后面说)。
unique_subquery :这个选项经常用在 in 关键字后面,子查询带有 where 关键字的子查询中,用 sql 来表示就是这样
value IN (SELECT primary_key FROM single_table WHERE some_expr)
range :索引范围查询,常见于使用 =,<>,>,>=,<,<=,IS NULL,<=>,BETWEEN,IN() 或者 like 等运算符的查询中。
index :索引全表扫描,把索引从头到尾扫一遍。
all : 这个我们接触的最多了,就是全表查询,select * from xxx ,性能最差。
上面就是 type 内容的大致解释,关于 type 我们经常会在 SQL 调优的环节使用 explain 分析其类型,然后改进查询方式,越靠近 system 其查询效率越高,越靠近 all 其查询效率越低。

- possible_keys :表示查询时,可能使用的索引。
- key :表示实际使用的索引。
- key_len :索引字段的长度。
- rows :扫描行的数量。
- filtered :通过查询条件查询出来的 SQL 数量占用总行数的比例。
- extra :执行情况的描述。
通过上面的分析,我们可以大致确定 SQL 效率低的原因,一种非常有效的提升 SQL 查询效率的方式就是使用索引,接下来我会讲解一下如何使用索引提高查询效率。
索引
索引是数据库优化中最常用也是最重要的手段,通过使用不同的索引可以解决大多数 SQL 性能问题,也是面试经常会问到的优化方式,围绕着索引,面试官能让你造出火箭来,所以总结一点就是索引非常非常重!要!不只是使用,你还要懂其原!理!
索引介绍
索引的目的就是用于快速查找某一列的数据,对相关数据列使用索引能够大大提高查询操作的性能。不使用索引,MySQL 必须从第一条记录开始读完整个表,直到找出相关的行,表越大查询数据所花费的时间就越多。如果表中查询的列有索引,MySQL 能够快速到达一个位置去搜索数据文件,而不必查看所有数据,那么将会节省很大一部分时间。
索引分类
先来了解一下索引都有哪些分类。
全局索引(FULLTEXT):全局索引,目前只有 MyISAM 引擎支持全局索引,它的出现是为了解决针对文本的模糊查询效率较低的问题,并且只限于 CHAR、VARCHAR 和 TEXT 列。哈希索引(HASH):哈希索引是 MySQL 中用到的唯一 key-value 键值对的数据结构,很适合作为索引。HASH 索引具有一次定位的好处,不需要像树那样逐个节点查找,但是这种查找适合应用于查找单个键的情况,对于范围查找,HASH 索引的性能就会很低。默认情况下,MEMORY 存储引擎使用 HASH 索引,但也支持 BTREE 索引。B-Tree 索引:B 就是 Balance 的意思,BTree 是一种平衡树,它有很多变种,最常见的就是 B+ Tree,它被 MySQL 广泛使用。R-Tree 索引:R-Tree 在 MySQL 很少使用,仅支持 geometry 数据类型,支持该类型的存储引擎只有MyISAM、BDb、InnoDb、NDb、Archive几种,相对于 B-Tree 来说,R-Tree 的优势在于范围查找。
从逻辑上来对 MySQL 进行分类,主要分为下面这几种
普通索引:普通索引是最基础的索引类型,它没有任何限制 。创建方式如下
create index normal_index on cxuan003(id);

删除方式
drop index normal_index on cxuan003;

唯一索引:唯一索引列的值必须唯一,允许有空值,如果是组合索引,则列值的组合必须唯一,创建方式如下
create unique index normal_index on cxuan003(id);

主键索引:是一种特殊的索引,一个表只能有一个主键,不允许有空值。一般是在建表的时候同时创建主键索引。
CREATE TABLE
table(idint(11) NOT NULL AUTO_INCREMENT ,titlechar(255) NOT NULL , PRIMARY KEY (id) )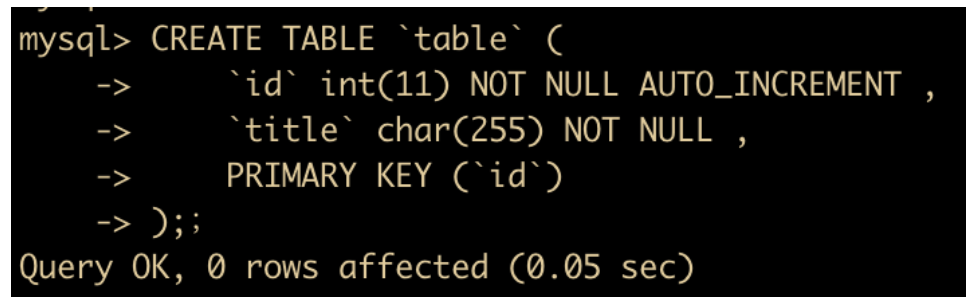
组合索引:指多个字段上创建的索引,只有在查询条件中使用了创建索引时的第一个字段,索引才会被使用。使用组合索引时遵循最左前缀原则,下面我们就会创建组合索引。
全文索引:主要用来查找文本中的关键字,而不是直接与索引中的值相比较,目前只有 char、varchar,text 列上可以创建全文索引,创建表的适合添加全文索引
CREATE TABLE
table(idint(11) NOT NULL AUTO_INCREMENT ,titlechar(255) CHARACTER NOT NULL ,contenttext CHARACTER NULL ,timeint(10) NULL DEFAULT NULL , PRIMARY KEY (id), FULLTEXT (content) );当然也可以直接创建全局索引
CREATE FULLTEXT INDEX index_content ON article(content)
索引使用
索引可以在创建表的时候进行创建,也可以单独创建,下面我们采用单独创建的方式,我们在 cxuan004 上创建前缀索引

我们使用 explain 进行分析,可以看到 cxuan004 使用索引的情况

如果不想使用索引,可以删除索引,索引的删除语法是

索引使用细则
我们在 cxuan005 上根据 id 和 hash 创建一个复合索引,如下所示
create index id_hash_index on cxuan005(id,hash);

然后根据 id 进行执行计划的分析
explain select * from cxuan005 where id = '333';

可以发现,即使 where 条件中使用的不是复合索引(Id 、hash),索引仍然能够使用,这就是索引的前缀特性。但是如果只按照 hash 进行查询的话,索引就不会用到。
explain select * from cxuan005 where hash='8fd1f12575f6b39ee7c6d704eb54b353';

如果 where 条件使用了 like 查询,并且 % 不在第一个字符,索引才可能被使用。
对于复合索引来说,只能使用 id 进行 like 查询,因为 hash 列不管怎么查询都不会走索引。
explain select * from cxuan005 where id like '%1';

可以看到,如果第一个字符是 % ,则没有使用索引。
explain select * from cxuan005 where id like '1%';

如果使用了 % 号,就会触发索引。
如果列名是索引的话,那么对列名进行 NULL 查询,将会触发索引。
explain select * from cxuan005 where id is null;

还有一些情况是存在索引但是 MySQL 并不会使用的情况。
最简单的,如果使用索引后比不使用索引的效率还差,那么 MySQL 就不会使用索引。
如果 SQL 中使用了 OR 条件,OR 前的条件列有索引,而后面的列没有索引的话,那么涉及到的索引都不会使用,比如 cxuan005 表中,只有 id 和 hash 字段有索引,而 info 字段没有索引,那么我们使用 or 进行查询。
explain select * from cxuan005 where id = 111 and info = 'cxuan';

我们从 explain 的执行结果可以看到,虽然 possible_keys 选项上仍然有 id_hash_index 索引,但是从 key、key_len 可以得知,这条 SQL 语句并未使用索引。
在带有复合索引的列上查询不是第一列的数据,也不会使用索引。
explain select * from cxuan005 where hash = '8fd1f12575f6b39ee7c6d704eb54b353';

如果 where 条件的列参与了计算,那么也不会使用索引
explain select * from cxuan005 where id + '111' = '666';

索引列使用函数,一样也不会使用索引
explain select * from cxuan005 where concat(id,'111') = '666';

索引列使用了 like ,并且
%位于第一个字符,则不会使用索引。在 order by 操作中,排序的列同时也在 where 语句中,将不会使用索引。
当数据类型出现隐式转换时,比如 varchar 不加单引号可能转换为 int 类型时,会使索引无效,触发全表扫描。比如下面这两个例子能够显而易见的说明这一点

在索引列上使用 IS NOT NULL 操作

在索引字段上使用 <>,!=。不等于操作符是永远不会用到索引的,因此对它的处理只会产生全表扫描。
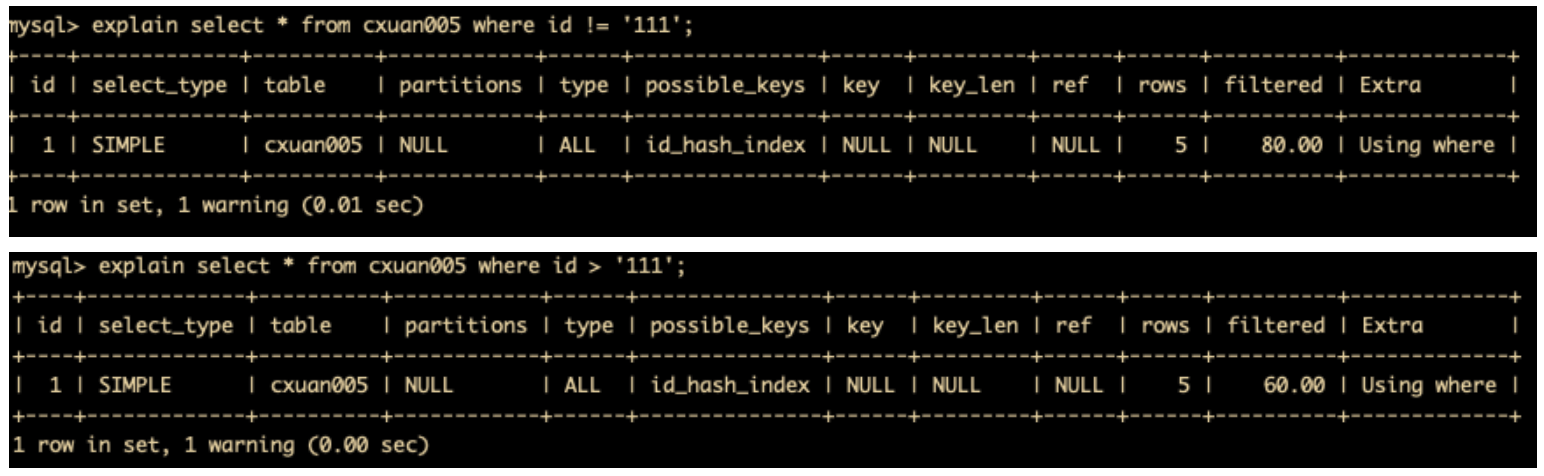
关于设置索引但是索引没有生效的场景还有很多,这个需要小伙伴们工作中不断总结和完善,不过我上面总结的这些索引失效的情景,能够覆盖大多数索引失效的场景了。
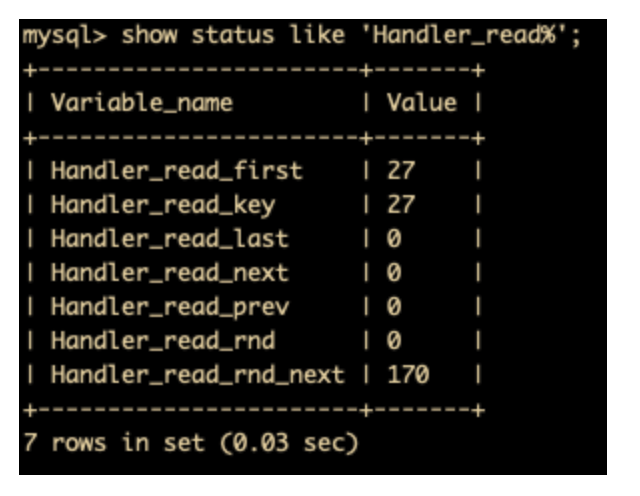
查看索引的使用情况
在 MySQL 索引的使用过程中,有一个 Handler_read_key 值,这个值表示了某一行被索引值读的次数。 Handler_read_key 的值比较低的话,则表明增加索引得到的性能改善不是很理想,可能索引使用的频率不高。
还有一个值是 Handler_read_rnd_next,这个值高则意味着查询运行效率不高,应该建立索引来进行抢救。这个值的含义是在数据文件中读下一行的请求数。如果正在进行大量的表扫描,Handler_read_rnd_next 的值比较高,就说明表索引不正确或写入的查询没有利用索引。
MySQL 分析表、检查表和优化表
对于大多数开发者来说,他们更倾向于解决简单 SQL的优化,而复杂 SQL 的优化交给了公司的 DBA 来做。
下面就从普通程序员的角度和你聊几个简单的优化方式。
MySQL 分析表
分析表用于分析和存储表的关键字分布,分析的结果可以使得系统得到准确的统计信息,使得 SQL 生成正确的执行计划。如果用于感觉实际执行计划与预期不符,可以执行分析表来解决问题,分析表语法如下
analyze table cxuan005;
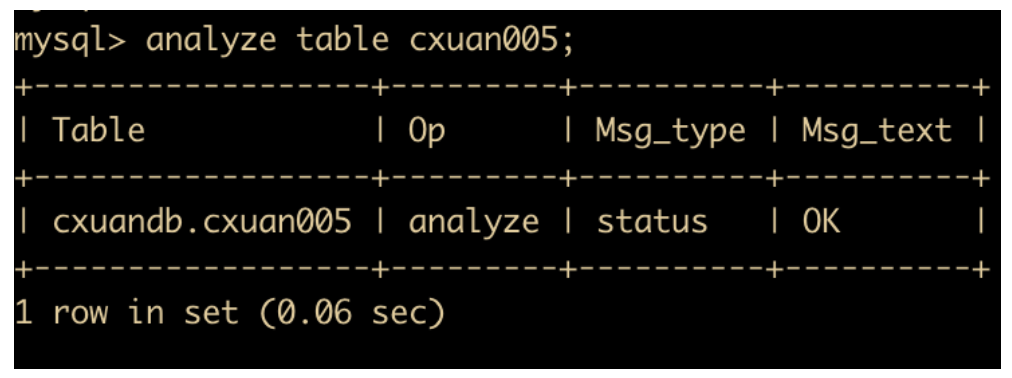
分析结果涉及到的字段属性如下
Table:表示表的名称;
Op:表示执行的操作,analyze 表示进行分析操作,check 表示进行检查查找,optimize 表示进行优化操作;
Msg_type:表示信息类型,其显示的值通常是状态、警告、错误和信息这四者之一;
Msg_text:显示信息。
对表的定期分析可以改善性能,应该成为日常工作的一部分。因为通过更新表的索引信息对表进行分析,可改善数据库性能。
MySQL 检查表
数据库经常可能遇到错误,比如数据写入磁盘时发生错误,或是索引没有同步更新,或是数据库未关闭 MySQL 就停止了。遇到这些情况,数据就可能发生错误: Incorrect key file for table: ‘ ‘. Try to repair it. 此时,我们可以使用 Check Table 语句来检查表及其对应的索引。
check table cxuan005;
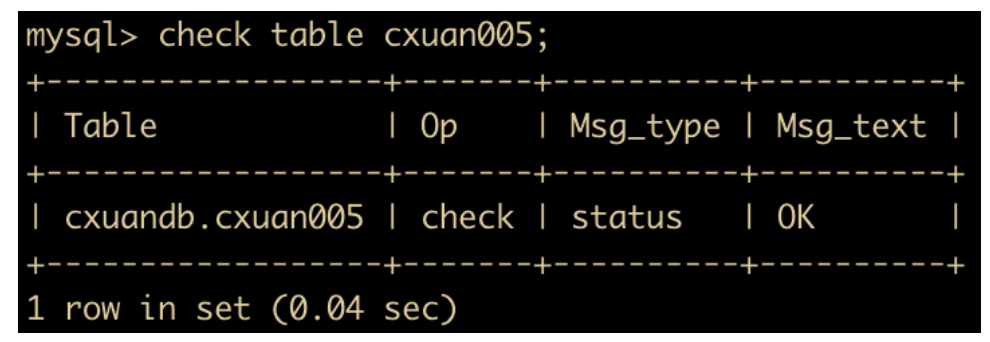
检查表的主要目的就是检查一个或者多个表是否有错误。Check Table 对 MyISAM 和 InnoDB 表有作用。Check Table 也可以检查视图的错误。
MySQL 优化表
MySQL 优化表适用于删除了大量的表数据,或者对包含 VARCHAR、BLOB 或则 TEXT 命令进行大量修改的情况。MySQL 优化表可以将大量的空间碎片进行合并,消除由于删除或者更新造成的空间浪费情况。它的命令如下
optimize table cxuan005;
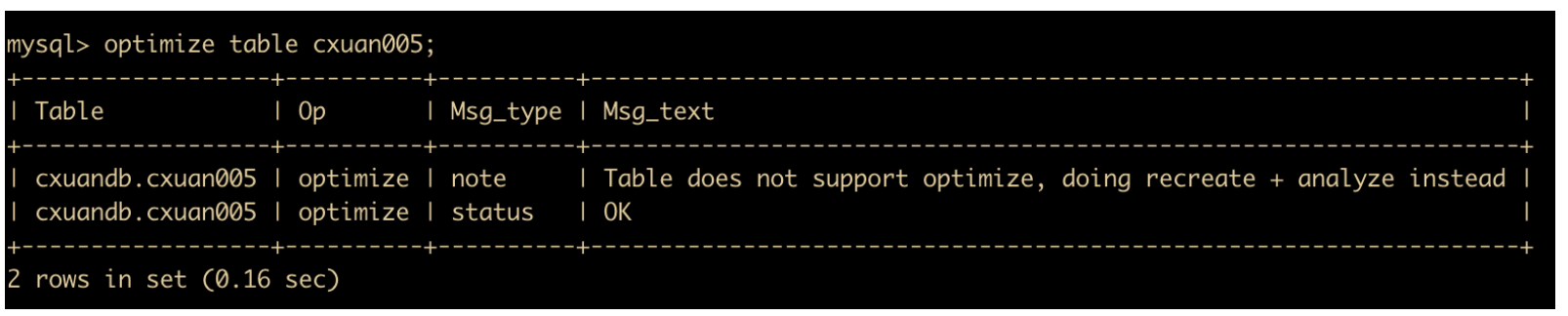
我的存储引擎是 InnoDB 引擎,但是从图可以知道,InnoDB 不支持使用 optimize 优化,建议使用 recreate + analyze 进行优化。optimize 命令只对 MyISAM 、BDB 表起作用。
常用 SQL 优化
前面我们介绍了使用索引来优化 MySQL ,那么对于 SQL 的各种语法,句法来说,应该怎样优化呢?下面,我会从 SQL 命令的角度来聊一波 SQL 优化。
导入的优化
对于 MyISAM 类型的表,可以通过下面这种方式导入大量的数据
ALTER TABLE tblname DISABLE KEYS; loading the data ALTER TABLE tblname ENABLE KEYS;
这两个命令用来打开或者关闭 MyISAM 表非唯一索引的更新。在导入大量的数据到一个非空的 MyISAM 表时,通过设置这两个命令,可以提高导入的效率。对于导入大量数据到一个空的 MyISAM 表,默认就是先导入数据然后才创建索引,所以不用进行设置。
但是对于 InnoDB 搜索引擎的表来说,这样做不能提高导入效率,我们有以下几种方式可以提高导入的效率:
- 因为 InnoDB 类型的表是按照主键的顺序保存的,所以将导入的数据按照主键的顺序排列,可以有效的提高导入数据的效率。如果 InnoDB 表没有主键,那么系统会默认创建一个内部列作为主键,所以如果可以给表创建一个主键,将可以利用这个优势提高导入数据的效率。
- 在导入数据前执行 SET UNIQUE_CHECKS = 0,关闭唯一性校验,在导入结束后执行SETUNIQUE_CHECKS = 1,恢复唯一性校验,可以提高导入的效率。
- 如果应用使用自动提交的方式,建议在导入前执行 SET AUTOCOMMIT = 0,关闭自动提交,导入结束后再执行 SET AUTOCOMMIT = 1,打开自动提交,也可以提高导入的效率。
insert 的优化
当进行插入语句的时候,可以考虑采用下面这几种方式进行优化
- 如果向同一张表插入多条数据的话,最好一次性插入,这样可以减少数据库建立连接 -> 断开连接的时间,如下所示
insert into test values(1,2),(1,3),(1,4)
- 如果向不同的表插入多条数据,可以使用 insert delayed 语句提高执行效率。delayed 的含义是让 insert 语句马上执行,要么数据都会放在内存的队列中,并没有真正写入磁盘。
- 对于 MyISAM 表来说,可以增加 bulk_insert_buffer_size 的值提高插入效率。
- 最好将索引和数据文件在不同的磁盘上存放。
group by 的优化
在使用分组和排序的场景下,如果先进行 Group By 再进行 Order By 的话,可以指定 order by null 禁止排序,因为 order by null 可以避免 filesort ,filesort 往往很耗费时间。如下所示
explain select id,sum(moneys) from sales2 group by id order by null;
order by 的优化
在执行计划中,经常可以看到 Extra 列出现了 filesort,filesort 是一种文件排序,这种排序方式比较慢,我们认为是不好的排序,需要进行优化。

优化的方式是要使用索引。
我们在 cxuan005 上创建一个索引。
create index idx on cxuan005(id);

然后我们使用查询字段和排序相同的顺序进行查询。
explain select id from cxuan005 where id > '111' order by id;

可以看到,在这次查询中,使用的是 Using index。这表明我们使用的是索引。
如果创建索引和 order by 的顺序不一致,将会使用 Using filesort。
explain select id from cxuan005 where id > '111' order by info;

MySQL 支持两种方式的排序,filesort 和 index,Using index 是指 MySQL 扫描索引本身完成排序。index 效率高,filesort 效率低。
order by 在满足下面这些情况下才会使用 index
- order by 语句使用索引最左前列。
- 使用 where 子句与 order by 子句条件列组合满足索引最左前列。
优化嵌套查询
嵌套查询是我们经常使用的一种查询方式,这种查询方式可以使用 SELECT 语句来创建一个单独的查询结果,然后把这个结果当作嵌套语句的查询范围用在另一个查询语句中。使用时子查询可以将一个复杂的查询拆分成一个个独立的部分,逻辑上更易于理解以及代码的维护和重复使用。
但是某些情况下,子查询的效率不高,一般使用 join 来替代子查询。
使用嵌套查询的 SQL 语句进行 explain 分析如下
explain select c05.id from cxuan005 c05 where id not in (select id from cxuan003);

从 explain 的结果可以看出,主表的查询是 index ,子查询是 index_subquery ,这两个执行效率都不高。我们使用 join 来优化后的分析计划如下。
explain select c05.id from cxuan005 c05 left join cxuan003 c03 on c05.id = c03.id;

从 explain 分析结果可以看到,主表查询和子查询分别是 index 和 ref,而 ref 的执行效率相对较高,一般 type 的效率由高到低是 System–>const–>eq_ref–>ref–> fulltext–>ref_or_null–>index_merge–>unique_subquery–>index_subquery–>range–>index–>all 。
count 的优化
count 我们大家用的太多了,一般都用来统计某一列结果集的行数,当 MySQL 确认括号内的表达式不可能为空时,实际上就是在统计行数。
其实 count 还有另一层统计方式:统计某个列值的数量,在统计列值数量的时候,它默认不会统计 NULL 值。
我们经常犯的一个错误就是,在括号内指定一个列但是却希望统计结果集的行数。如果想要知道结果集行数的话,最好使用 count(*)。
limit 分页的优化
通常我们的系统会进行分页,一般情况下我们会使用 limit 加上偏移量来实现。同时还会加上 order by 语句进行排序。如果使用索引的情况下,效率一般不会有什么问题,如果没有使用索引的话,MySQL 就可能会做大量的文件排序操作。
通常我们可能会遇到比如 limit 1000 , 50 这种情况,抛弃 1000 条,只取 50 条,这样的代价非常高,如果所有页面被访问的频率相同,那么这样的查询平均需要访问半个表的数据。
要优化这种查询,要么限制分页的数量,要么优化大偏移量的性能。
SQL 中 IN 包含的值不应该太多
MySQL 中对 IN 做了相应的优化,MySQL 会将全部的常量存储在一个数组里面,如果数值较多,产生的消耗也会变大,比如
select name from dual where num in(4,5,6)
像这种 SQL 语句的话,能用 between 使用就不要再使用 in 了。
只需要一条数据的情况
如果只需要一条数据的情况下,推荐使用 limit 1,这样会使执行计划中的 type 变为 const。
如果没有使用索引,就尽量减少排序
尽量用 union all 来代替 union
union 和 union all 的差异主要是前者需要将结果集合并后再进行唯一性过滤操作,这就会涉及到排序,增加大量的 CPU 运算,加大资源消耗及延迟。当然,union all 的前提条件是两个结果集没有重复数据。
where 条件优化
避免在 WHERE 字句中对字段进行 NULL 判断
避免在 WHERE 中使用 != 或 <> 操作符
不建议使用 % 前缀模糊查询,例如 LIKE “%name”或者LIKE “%name%”,这种查询会导致索引失效而进行全表扫描。但是可以使用LIKE “name%”。
避免在 where 中对字段进行表达式操作,比如 *select user_id,user_project from table_name where age2=36 就是一种表达式操作,建议改为 select user_id,user_project from table_name where age=36/2 **
建议在 where 子句中确定 column 的类型,避免 column 字段的类型和传入的参数类型不一致的时候发生的类型转换。
查询时,尽量指定查询的字段名
我们在日常使用 select 查询时,尽量使用 select 字段名 这种方式,避免直接 *select **,这样增加很多不必要的消耗(cpu、io、内存、网络带宽);而且查询效率比较低。
# MySQL入门大全-Java面试题
SQL 基础使用
MySQL 是一种关系型数据库,说到关系,那么就离不开表与表之间的关系,而最能体现这种关系的其实就是我们接下来需要介绍的主角 SQL,SQL 的全称是 Structure Query Language ,结构化的查询语言,它是一种针对表关联关系所设计的一门语言,也就是说,学好 MySQL,SQL 是基础和重中之重。SQL 不只是 MySQL 中特有的一门语言,大多数关系型数据库都支持这门语言。
下面我们就来一起学习一下这门非常重要的语言。
查询语言分类
在了解 SQL 之前我们需要知道下面这几个概念
数据定义语言: 简称
DDL(Data Definition Language),用来定义数据库对象:数据库、表、列等;数据操作语言: 简称
DML(Data Manipulation Language),用来对数据库中表的记录进行更新。关键字: insert、update、delete等数据控制语言: 简称
DCL(Data Control Language),用来定义数据库访问权限和安全级别,创建用户等。关键字: grant等数据查询语言: 简称
DQL(Data Query Language),用来查询数据库中表的记录,关键字: select from where等
DDL 语句
创建数据库
下面就开始我们的 SQL 语句学习之旅,首先你需要启动 MySQL 服务,我这里是 mac 电脑,所以我直接可以启动
然后我们使用命令行的方式连接数据库,打开 iterm,输入下面
MacBook:~ mr.l$ mysql -uroot -p
就可以连接到数据库了
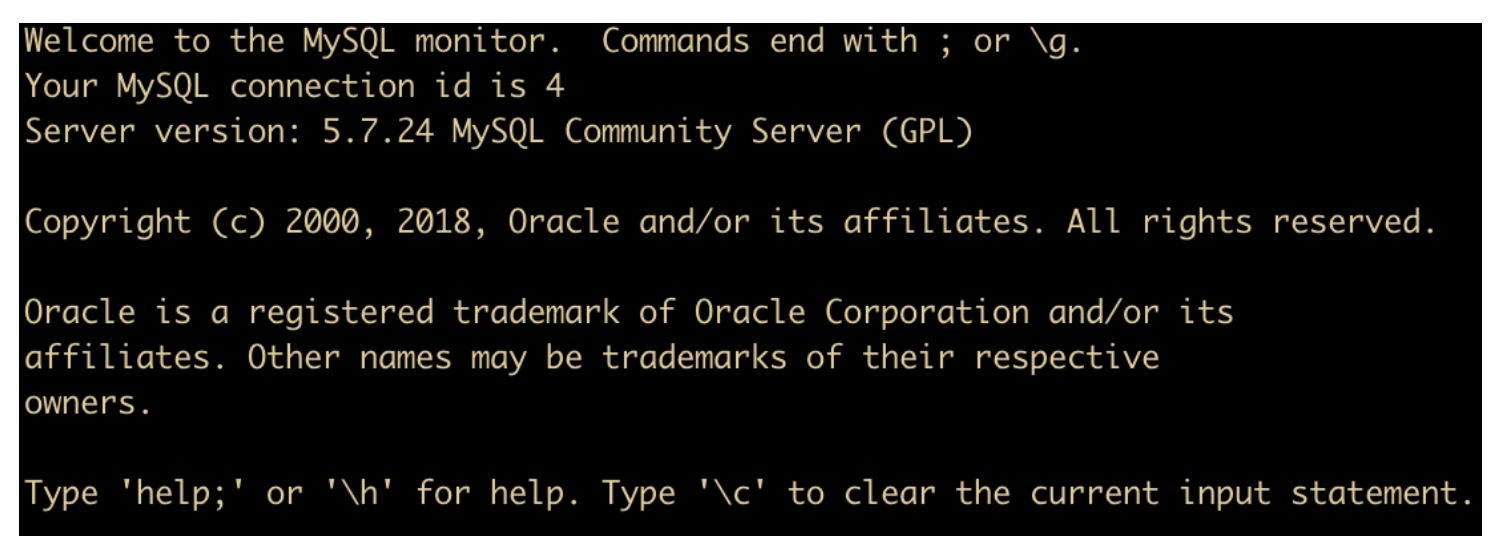
在上面命令中,mysql 代表客户端命令,- u 表示后面需要连接的用户,-p 表示需要输入此用户的密码。在你输入用户名和密码后,如果成功登陆,会显示一个欢迎界面(如上图 )和 mysql> 提示符。
欢迎界面主要描述了这些东西
- 每一行的结束符,这里用
;或者\g来表示每一行的结束 - Your MySQL connection id is 4,这个记录了 MySQL 服务到目前为止的连接数,每个新链接都会自动增加 1 ,上面显示的连接次数是 4 ,说明我们只连接了四次
- 然后下面是 MySQL 的版本,我们使用的是 5.7
- 通过
help或者\h命令来显示帮助内容,通过\c命令来清除命令行 buffer。
然后需要做的事情是什么?我们最终想要学习 SQL 语句,SQL 语句肯定是要查询数据,通过数据来体现出来表的关联关系,所以我们需要数据,那么数据存在哪里呢?数据存储的位置被称为 表(table),表存储的位置被称为 数据库(database),所以我们需要先建数据库后面再建表然后插入数据,再进行查询。

所以我们首先要做的就是创建数据库,创建数据库可以直接使用指令
CREATE DATABASE dbname;
进行创建,比如我们创建数据库 cxuandb
create database cxuandb;
注意最后的 ; 结束语法一定不要丢掉,否则 MySQL 会认为你的命令没有输出完,敲 enter 后会直接换行输出

创建完成后,会提示 Query OK, 1 row affected,这段语句什么意思呢? Query OK 表示的就是查询完成,为什么会显示这个?因为所有的 DDL 和 DML 操作执行完成后都会提示这个, 也可以理解为操作成功。后面跟着的 1 row affected 表示的是影响的行数,() 内显示的是你执行这条命令所耗费的时间,也就是 0.03 秒。
上图我们成功创建了一个 cxuandb 的数据库,此时我们还想创建一个数据库,我们再执行相同的指令,结果提示

提示我们不能再创建数据库了,数据库已经存在。这时候我就有疑问了,我怎么知道都有哪些数据库呢?别我再想创建一个数据库又告诉我已经存在,这时候可以使用 show databases 命令来查看你的 MySQL 已有的数据库
show databases;
执行完成后的结果如下
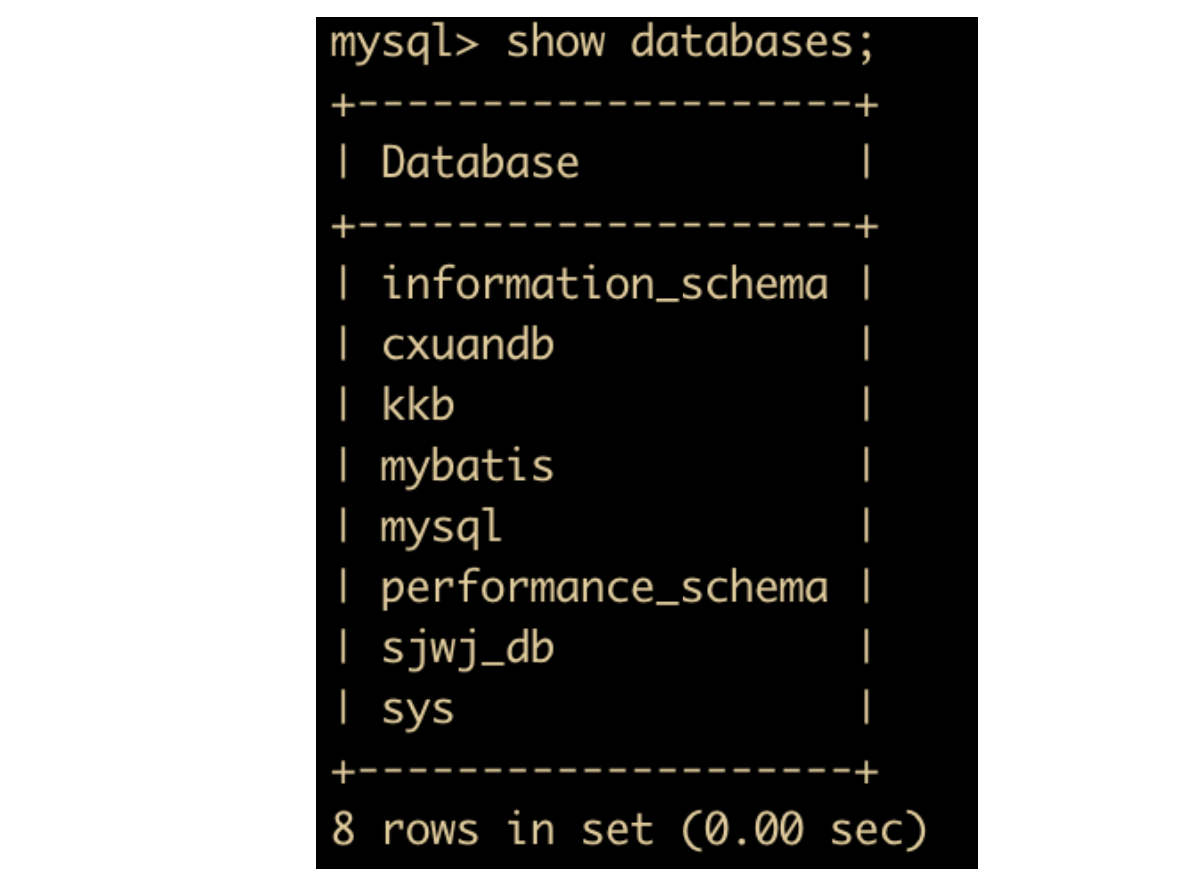
因为数据库我之前已经使用过,这里就需要解释一下,除了刚刚新创建成功的 cxuandb 外,informationn_schema 、performannce_schema 和 sys 都是系统自带的数据库,是安装 MySQL 默认创建的数据库。它们各自表示
- informationn_schema: 主要存储一些数据库对象信息,比如用户表信息、权限信息、分区信息等
- performannce_schema: MySQL 5.5 之后新增加的数据库,主要用于收集数据库服务器性能参数。
- sys: MySQL 5.7 提供的数据库,sys 数据库里面包含了一系列的存储过程、自定义函数以及视图来帮助我们快速的了解系统的元数据信息。
其他所有的数据库都是作者自己创建的,可以忽略他们。
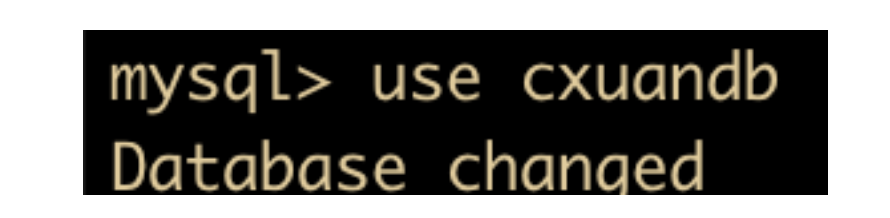
在创建完数据库之后,可以用如下命令选择要操作的数据库
use cxuandb
这样就成功切换为了 cxuandb 数据库,我们可以在此数据库下进行建表、查看基本信息等操作。
比如想要看康康我们新建的数据库里面有没有其他表
show tables;
果然,我们新建的数据库下面没有任何表,但是现在,我们还不进行建表操作,我们还是先来认识一下数据库层面的命令,也就是其他 DDL 指令
删除数据库
如果一个数据库我们不想要了,那么该怎么办呢?直接删掉数据库不就好了吗?删表语句是
drop database dbname;
比如 cxuandb 我们不想要他了,可以通过使用
drop database cxuandb;
进行删除,这里我们就不进行演示了,因为 cxuandb 我们后面还会使用。
但是这里注意一点,你删除数据库成功后会出现 0 rows affected,这个可以不用理会,因为在 MySQL 中,drop 语句操作的结果都是 0 rows affected。
创建表
下面我们就可以对表进行操作了,我们刚刚 show tables 发现还没有任何表,所以我们现在进行建表语句
CREATE TABLE 表名称 ( 列名称1 数据类型 约束, 列名称2 数据类型 约束, 列名称3 数据类型 约束, .... )
这样就很清楚了吧,列名称就是列的名字,紧跟着列名后面就是数据类型,然后是约束,为什么要这么设计?举个例子你就清楚了,比如 cxuan 刚被生出来就被打印上了标签

比如我们创建一个表,里面有 5 个字段,姓名(name)、性别(sex)、年龄(age)、何时雇佣(hiredate)、薪资待遇(wage),建表语句如下
create table job(name varchar(20), sex varchar(2), age int(2), hiredate date, wage decimal(10,2));
事实证明这条建表语句还是没问题的,建表完成后可以使用 DESC tablename 查看表的基本信息
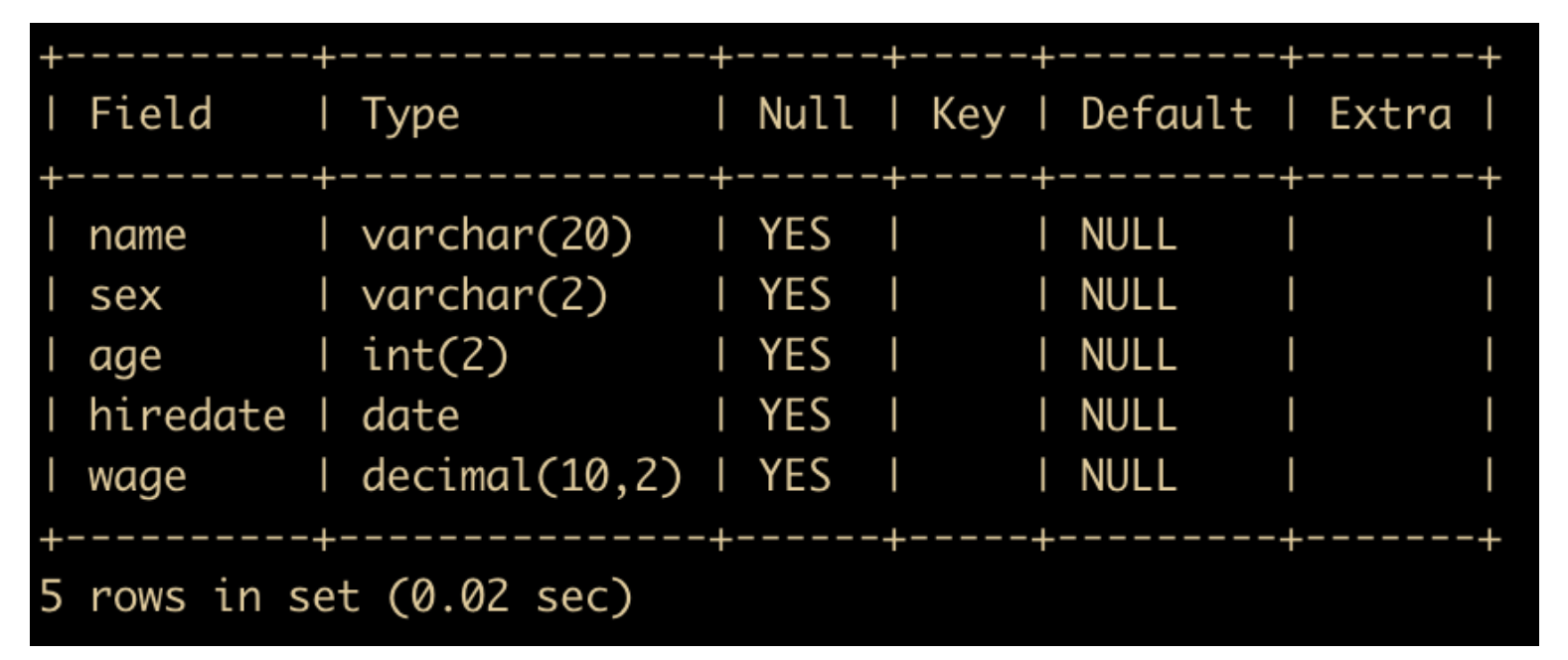
DESC 命令会查看表的定义,但是输出的信息还不够全面,所以,如果想要查看更全的信息,还要通过查看表的创建语句的 SQL 来得到
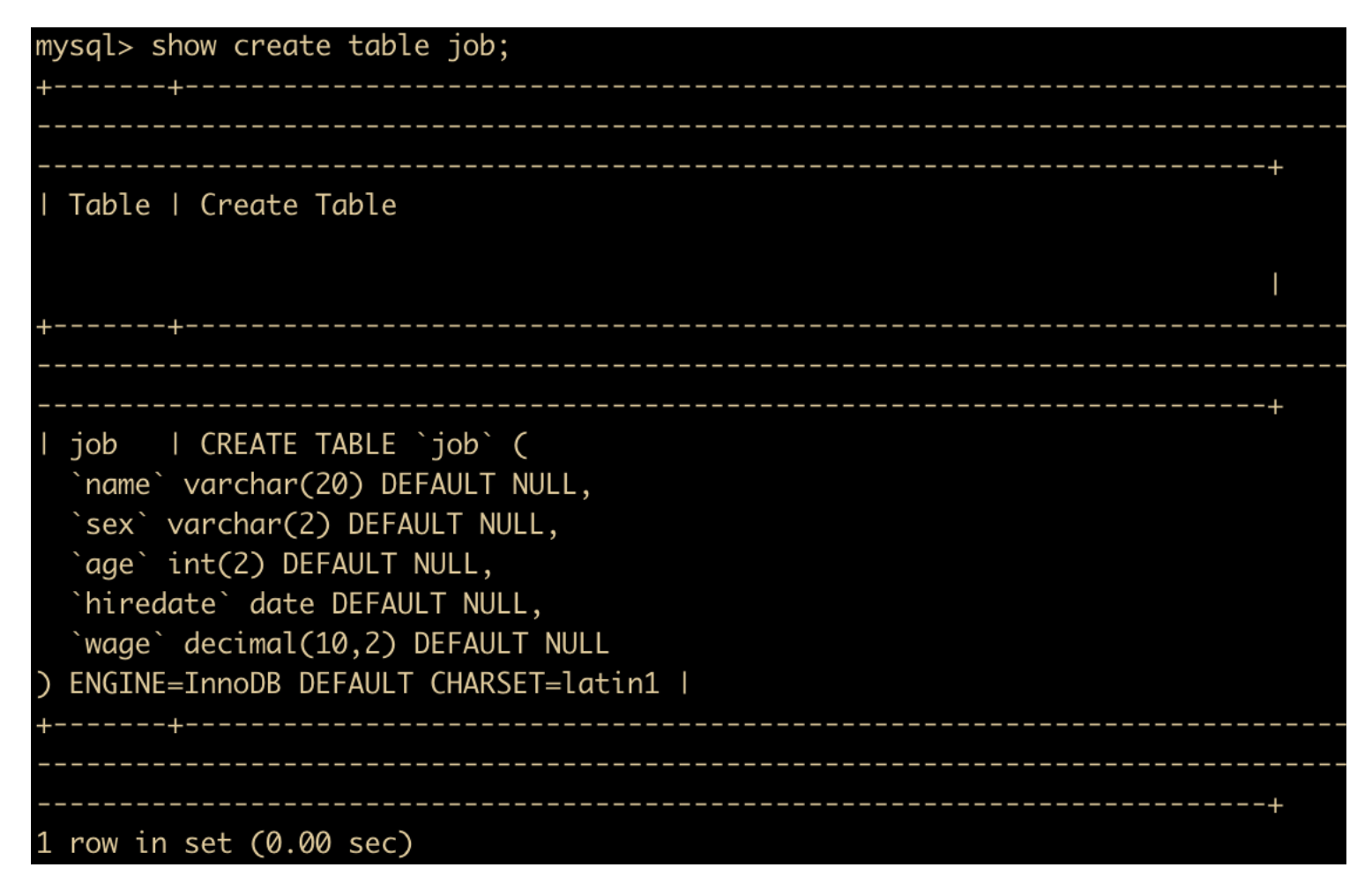
show create table job \G;

可以看到,除了看到表定义之外,还看到了表的 engine(存储引擎) 为 InnoDB 存储引擎,\G 使得记录能够竖着排列,如果不用 \G 的话,效果如下
删除表
表的删除语句有两种,一种是 drop 语句,SQL 语句如下
drop table job
一种是 truncate 语句,SQL 语句如下
truncate table job
这两者的区别简单理解就是 drop 语句删除表之后,可以通过日志进行回复,而 truncate 删除表之后永远恢复不了,所以,一般不使用 truncate 进行表的删除。‘
修改表
对于已经创建好的表,尤其是有大量数据的表,如果需要对表做结构上的改变,可以将表删除然后重新创建表,但是这种效率会产生一些额外的工作,数据会重新加载近来,如果此时有服务正在访问的话,也会影响服务读取表中数据,所以此时,我们需要表的修改语句来对已经创建好的表的定义进行修改。
修改表结构一般使用 alter table 语句,下面是常用的命令
ALTER TABLE tb MODIFY [COLUMN] column_definition [FIRST | AFTER col_name];
比如我们想要将 job 表中的 name 由 varchar(20) 改为 varchar(25),可以使用如下语句
alter table job modify name varchar(25);

也可以对表结构进行修改,比如增加一个字段
alter table job add home varchar(30);

将新添加的表的字段进行删除
alter table job drop column home;

可以对表中字段的名称进行修改,比如吧 wage 改为 salary
alter table job change wage salary decimal(10,2);

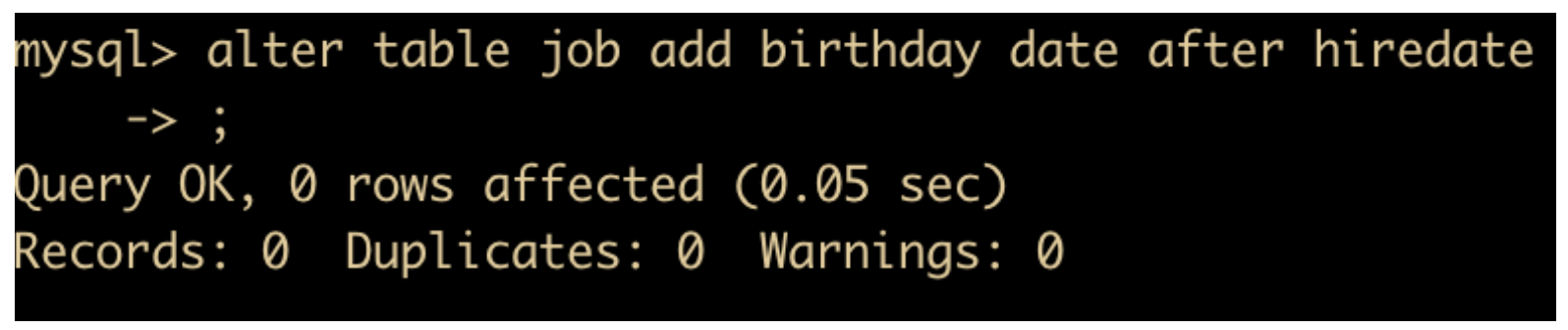
修改字段的排列顺序,我们前面介绍过修改语法涉及到一个顺序问题,都有一个可选项 first | after column_name,这个选项可以用来修改表中字段的位置,默认 ADD 是在添加为表中最后一个字段,而 CHANGE/MODIFY 不会改变字段位置。比如
alter table job add birthday after hiredate;
可以对表名进行修改,例如将 job 表改为 worker
alter table job rename worker;
DML 语句
有的地方把 DML 语句(增删改)和 DQL 语句(查询)统称为 DML 语句,有的地方分开,我们目前使用分开称呼的方式
插入
表创建好之后,我们就可以向表里插入数据了,插入记录的基本语法如下
INSERT INTO tablename (field1,field2) VALUES(value1,value2);
例如,向中插入以下记录
insert into job(name,sex,age,hiredate,birthday,salary) values("cxuan","男",24,"2020-04-27","1995-08-22",8000);
也可以不用指定要插入的字段,直接插入数据即可
insert into job values("cxuan02","男",25,"2020-06-01","1995-04-23",12000);
这里就有一个问题,如果插入的顺序不一致的话会怎么样呢?
对于含可空字段、非空但是含有默认值的字段、自增字段可以不用在 insert 后的字段列表出现,values 后面只需要写对应字段名称的 value 即可,没有写的字段可以自动的设置为 NULL、默认值或者自增的下一个值,这样可以缩短要插入 SQL 语句的长度和复杂性。
比如我们设置一下 hiredate、age 可以为 null,来试一下
insert into job(name,sex,birthday,salary) values("cxuan03","男","1992-08-23",15000);

我们看一下实际插入的数据
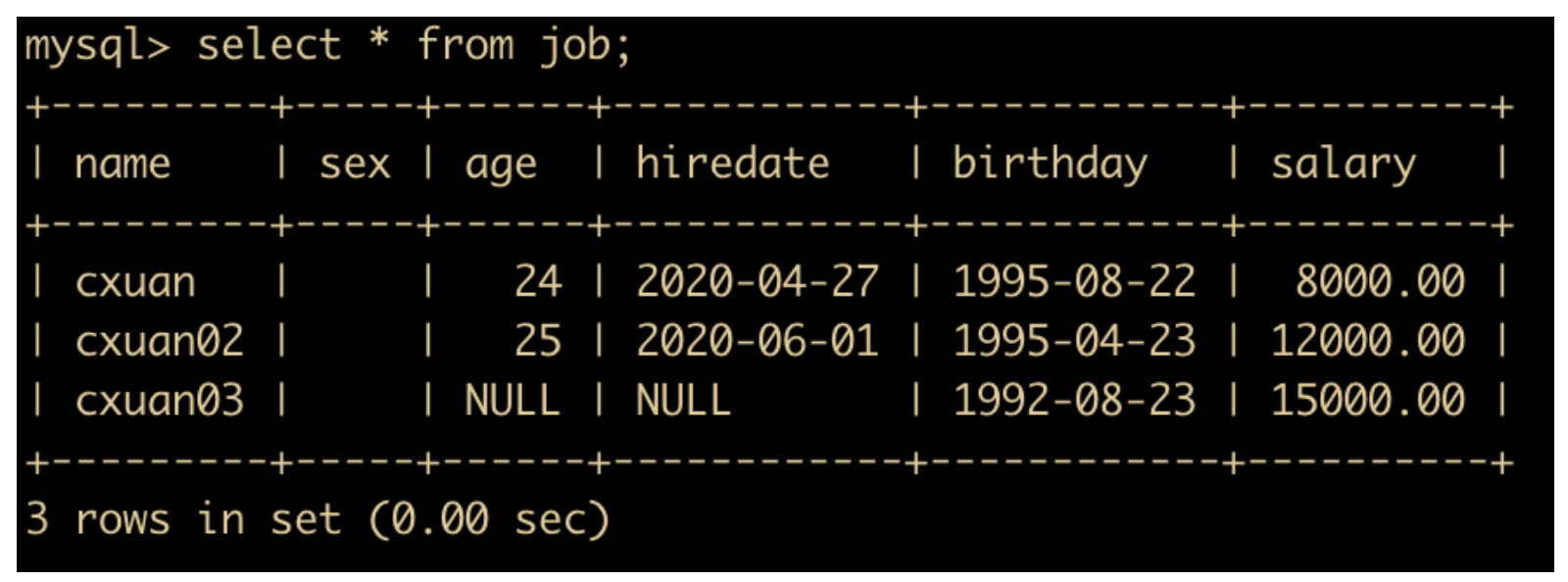
我们可以看到有一行两个字段显示 NULL。在 MySQL 中,insert 语句还有一个很好的特性,就是一次可以插入多条记录
INSERT INTO tablename (field1,field2) VALUES (value1,value2), (value1,value2), (value1,value2), ...;
可以看出,每条记录之间都用逗号进行分割,这个特性可以使得 MySQL 在插入大量记录时,节省很多的网络开销,大大提高插入效率。
更新记录
对于表中已经存在的数据,可以通过 update 命令对其进行修改,语法如下
UPDATE tablename SET field1 = value1, field2 = value2 ;
例如,将 job 表中的 cxuan03 中 age 的 NULL 改为 26,SQL 语句如下
update job set age = 26 where name = 'cxuan03';
SQL 语句中出现了一个 where 条件,我们会在后面说到 where 条件,这里简单理解一下它的概念就是根据哪条记录进行更新,如果不写 where 的话,会对整个表进行更新
删除记录
如果记录不再需要,可以使用 delete 命令进行删除
DELETE FROM tablename [WHERE CONDITION]
例如,在 job 中删除名字是 cxuan03 的记录
delete from job where name = 'cxuan03';

在 MySQL 中,删除语句也可以不指定 where 条件,直接使用
delete from job
这种删除方式相当于是清楚表的操作,表中所有的记录都会被清除。
DQL 语句
下面我们一起来认识一下 DQL 语句,数据被插入到 MySQL 中,就可以使用 SELECT 命令进行查询,来得到我们想要的结果。
SELECT 查询语句可以说是最复杂的语句了,这里我们只介绍一下基本语法
一种最简单的方式就是从某个表中查询出所有的字段和数据,简单粗暴,直接使用 SELECT *
SELECT * FROM tablename;
例如我们将 job 表中的所有数据查出来
select * from job;
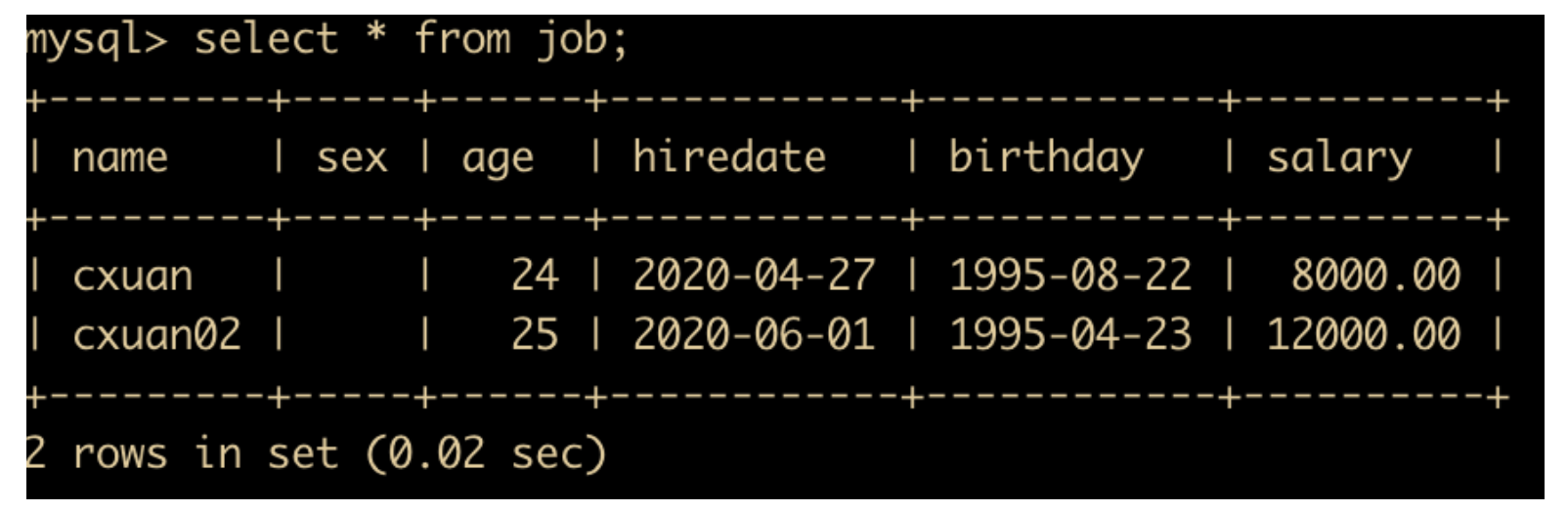
其中 * 是查询出所有的数据,当然,你也可以查询出指定的数据项
select name,sex,age,hiredate,birthday,salary from job;
上面这条 SQL 语句和 select * from job 表是等价的,但是这种直接查询指定字段的 SQL 语句效率要高。
上面我们介绍了基本的 SQL 查询语句,但是实际的使用场景会会比简单查询复杂太多,一般都会使用各种 SQL 的函数和查询条件等,下面我们就来一起认识一下。
去重
使用非常广泛的场景之一就是 去重,去重可以使用 distinct 关键字来实现
为了演示效果,我们先向数据库中插入批量数据,插入完成后的表结构如下
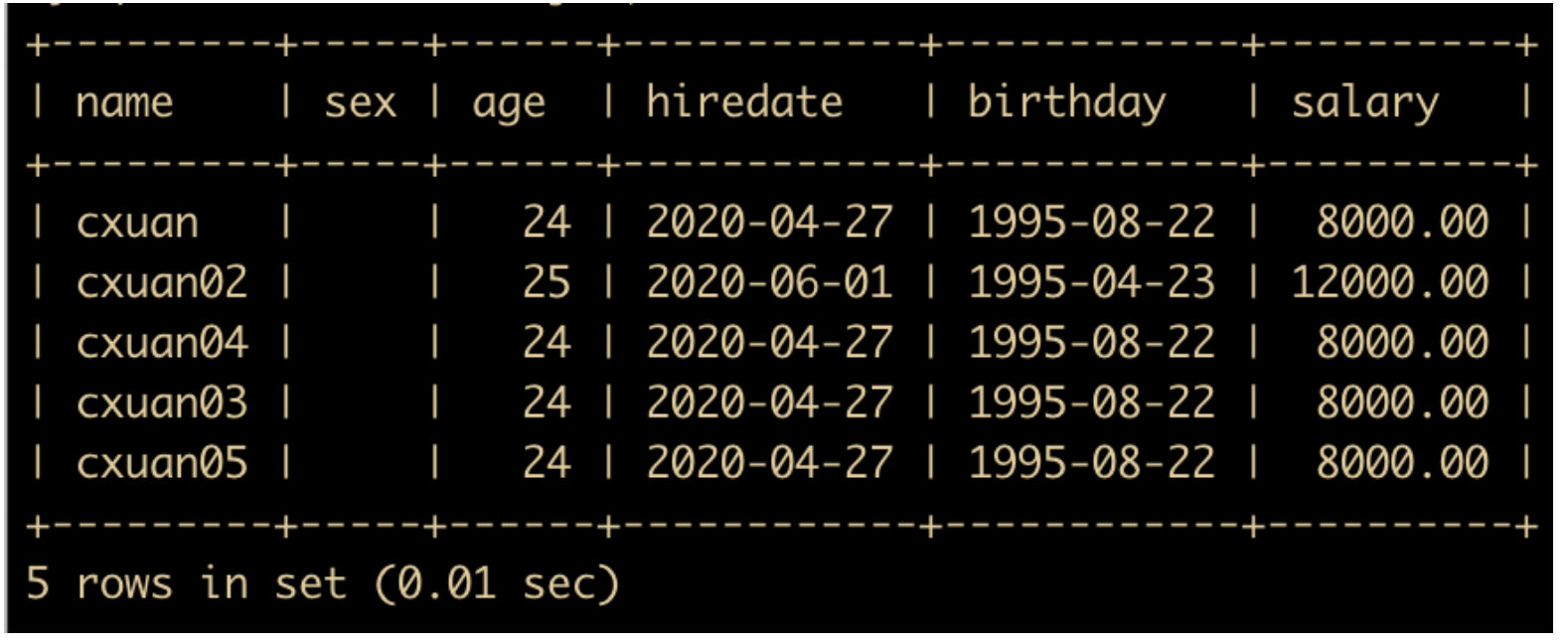
下面我们使用 distinct 来对 age 去重来看一下效果
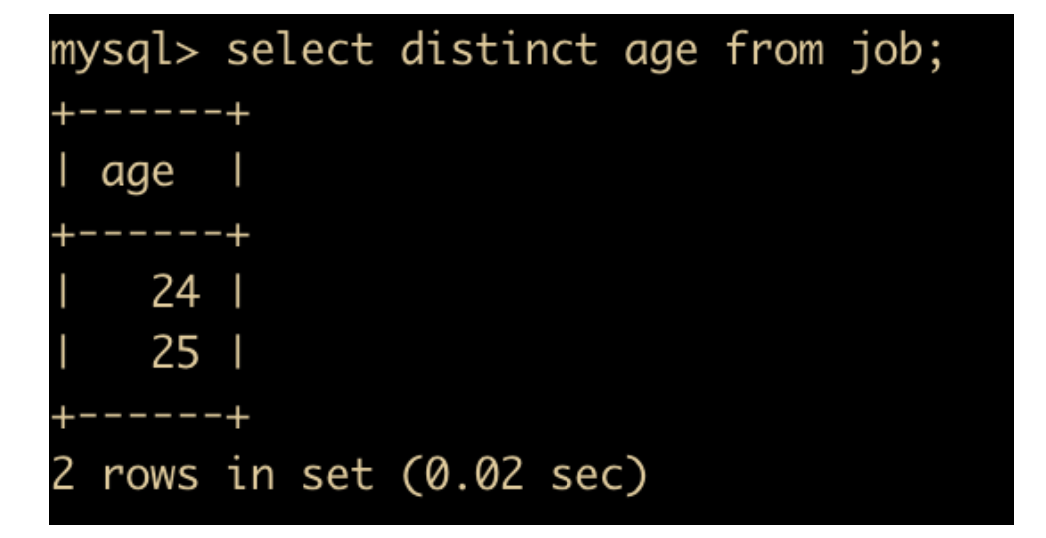
你会发现只有两个不同的值,其他和 25 重复的值被过滤掉了,所以我们使用 distinct 来进行去重
条件查询
我们之前的所有例子都是查询全部的记录,如果我们只想查询指定的记录呢?这里就会用到 where 条件查询语句,条件查询可以对指定的字段进行查询,比如我们想查询所有年龄为 24 的记录,如下
select * from job where age = 24;

where 条件语句后面会跟一个判断的运算符 =,除了 = 号比较外,还可以使用 >、<、>=、<=、!= 等比较运算符;例如
select * from job where age >= 24;
就会从 job 表中查询出 age 年龄大于或等于 24 的记录
除此之外,在 where 条件查询中还可以有多个并列的查询条件,比如我们可以查询年龄大于等于 24,并且薪资大雨 8000 的记录
select * from job where age >= 24 and salary > 8000;
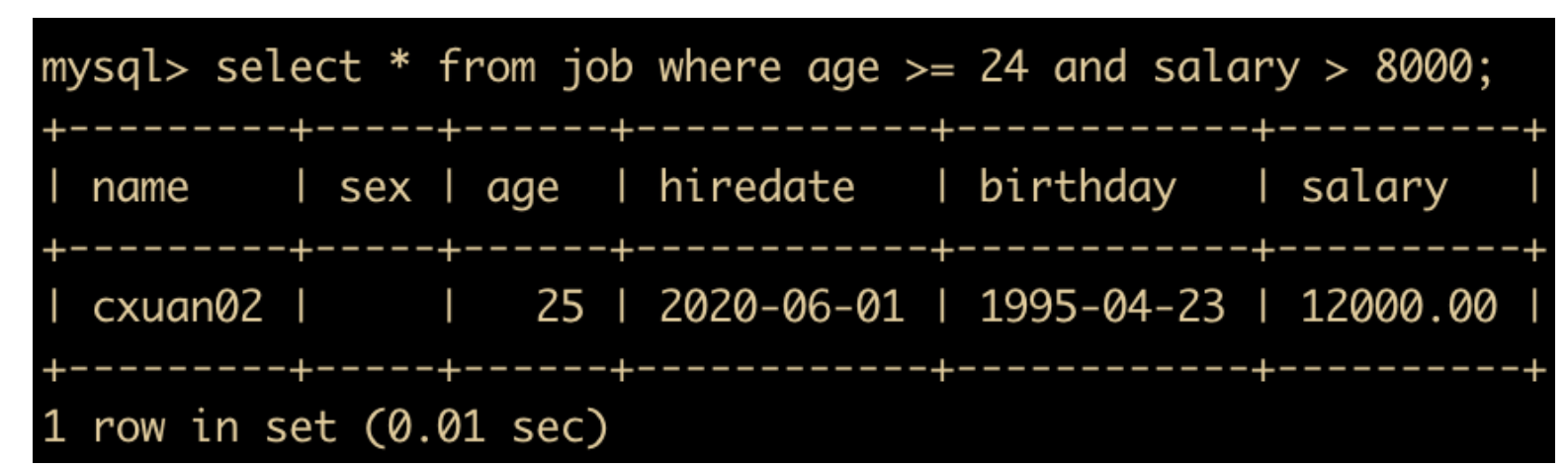
多个条件之间还可以使用 or、and 等逻辑运算符进行多条件联合查询,运算符会在以后章节中详细讲解。
排序
我们会经常有这样的需求,按照某个字段进行排序,这就用到了数据库的排序功能,使用关键字 order by 来实现,语法如下
SELECT * FROM tablename [WHERE CONDITION] [ORDER BY field1 [DESC|ASC] , field2 [DESC|ASC],……fieldn [DESC|ASC]]
其中 DESC 和 ASC 就是顺序排序的关键字,DESC 会按照字段进行降序排列,ASC 会按照字段进行升序排列,默认会使用升序排列,也就是说,你不写 order by 具体的排序的话,默认会使用升序排列。order by 后面可以跟多个排序字段,并且每个排序字段可以有不同的排序顺序。
为了演示功能,我们先把表中的 salary 工资列进行修改,修改完成后的表记录如下
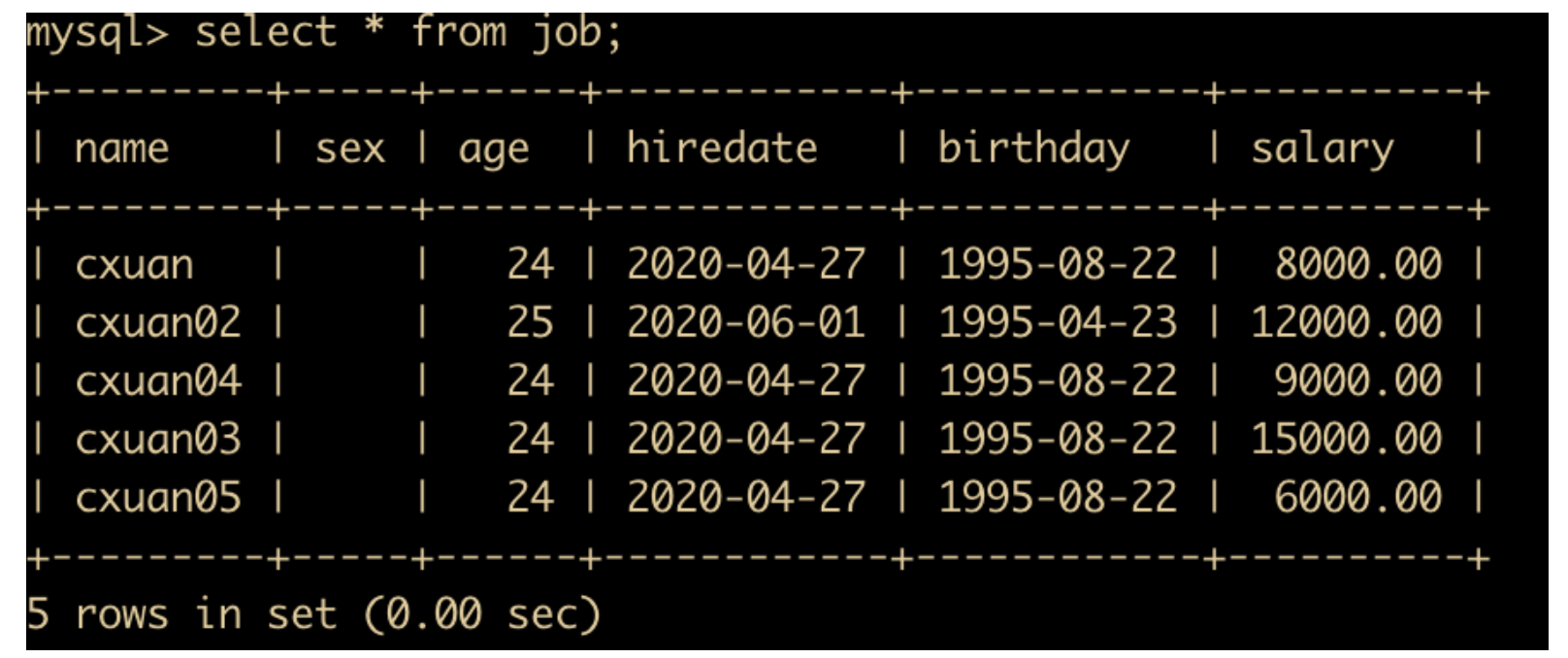
下面我们按照工资进行排序,SQL 语句如下
select * from job order by salary desc;
语句执行完成后的结果如下
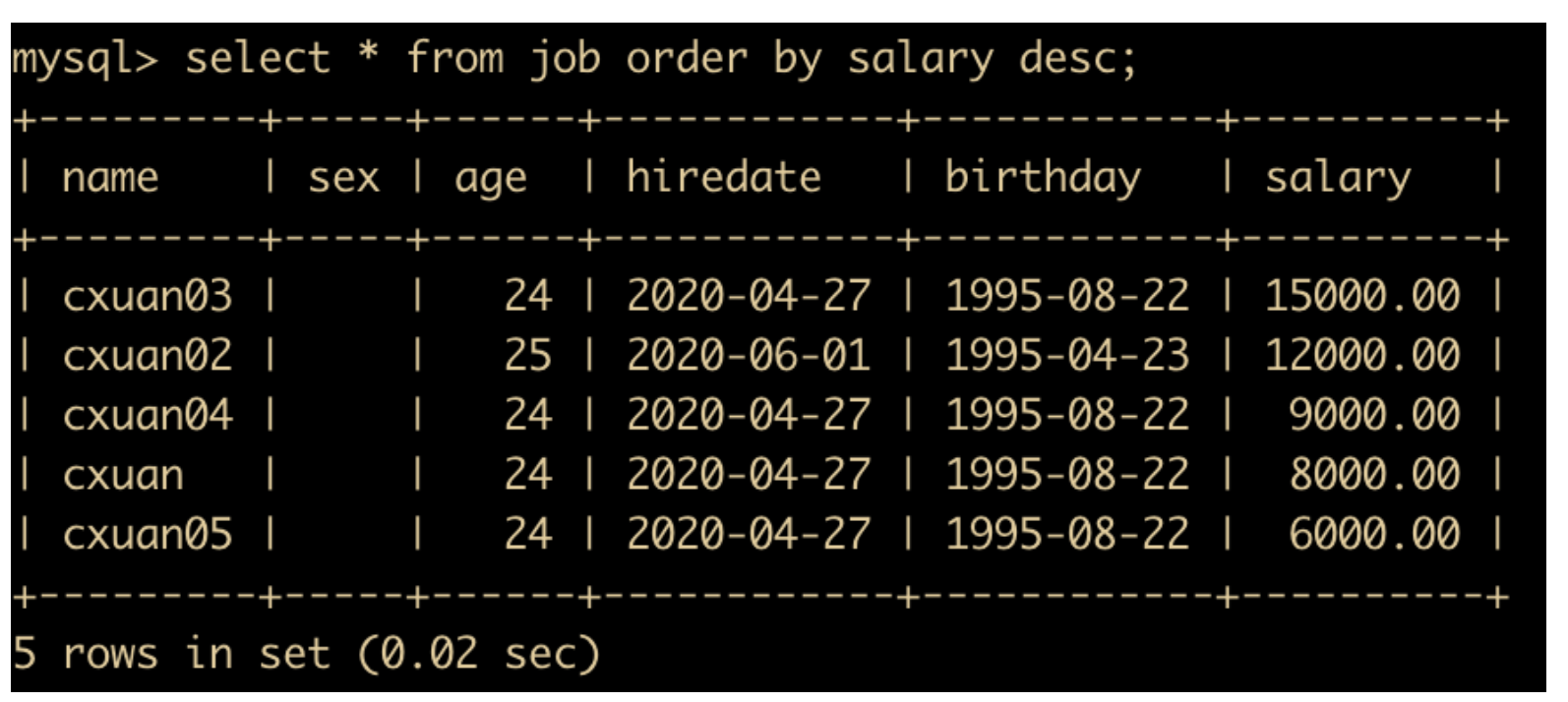
这是对一个字段进行排序的结果,也可以对多个字段进行排序,但是需要注意一点
根据 order by 后面声名的顺序进行排序,如果有三个排序字段 A、B、C 的话,如果 A 字段排序字段的值一样,则会根据第二个字段进行排序,以此类推。
如果只有一个排序字段,那么这些字段相同的记录将会无序排列。
限制
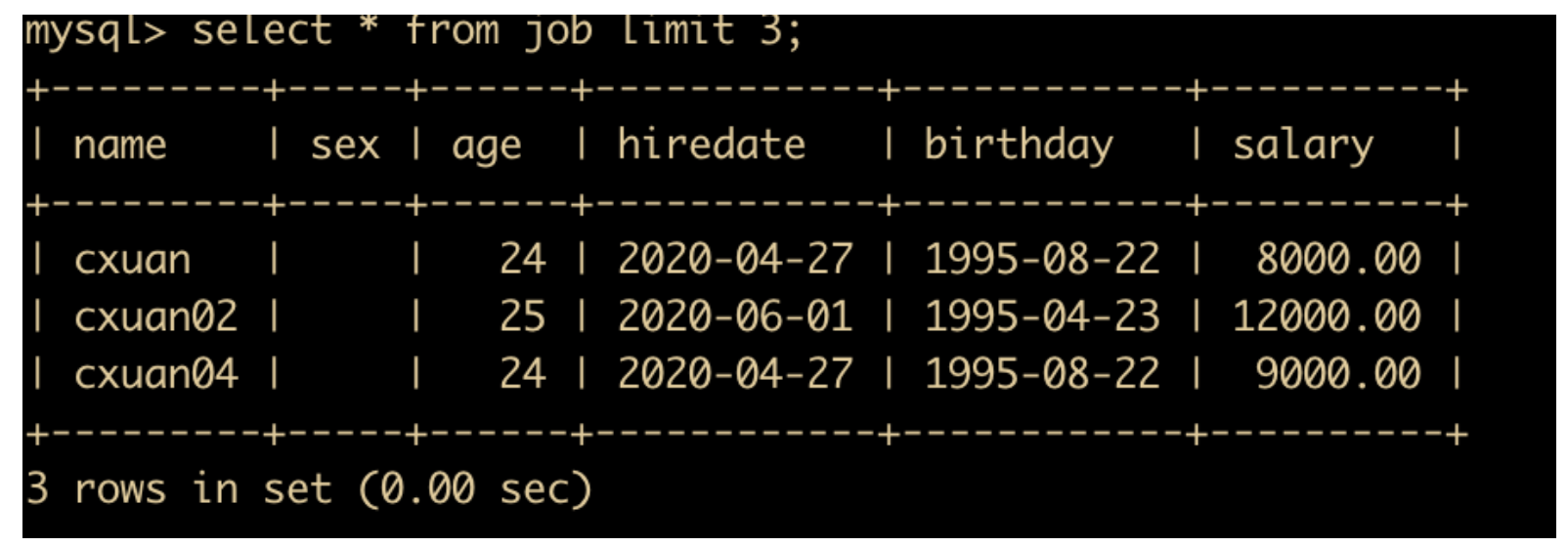
对于排序后的字段,或者不排序的字段,如果只希望显示一部分的话,就会使用 LIMIT 关键字来实现,比如我们只想取前三条记录
select * from job limit 3;
或者我们对排序后的字段取前三条记录
select * from job order by salary limit 3;

上面这种 limit 是从表记录的第 0 条开始取,如果从指定记录开始取,比如从第二条开始取,取三条记录,SQL 如下
select * from job order by salary desc limit 2,3;
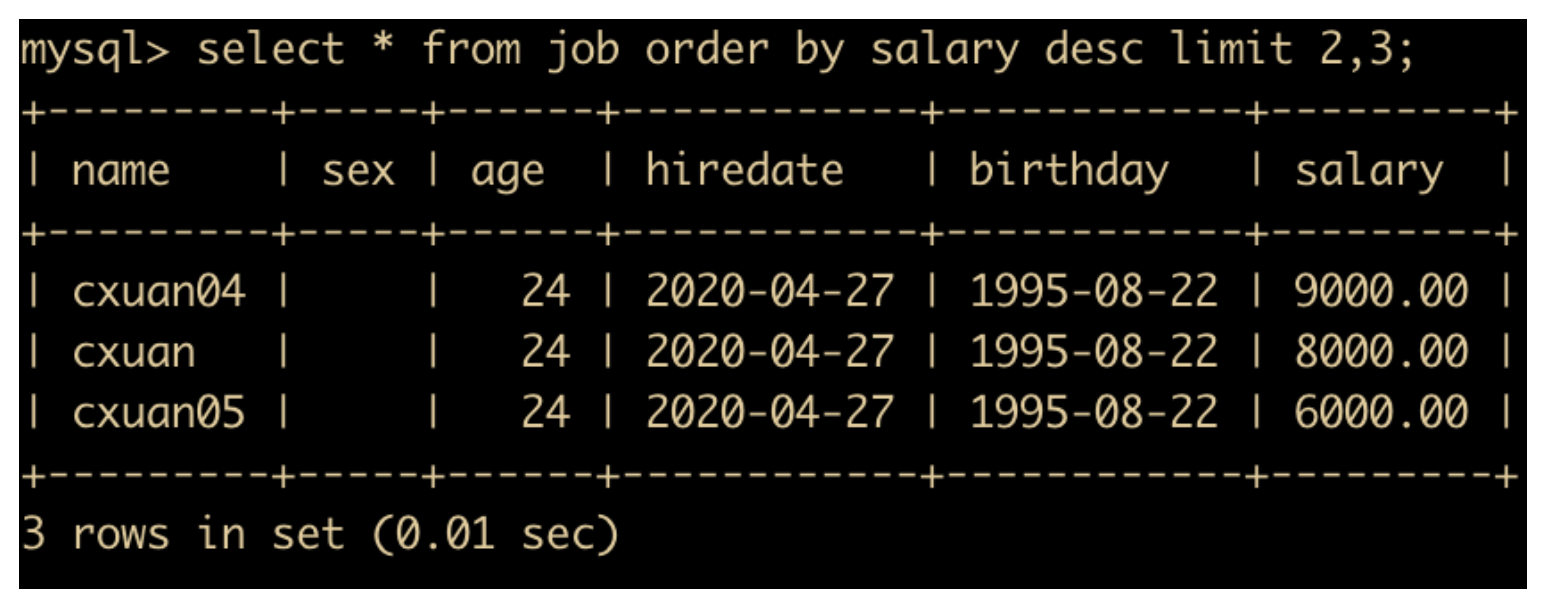
limit 一般经常和 order by 语法一起实现分页查询。
注意:limit 是 MySQL 扩展 SQL92 之后的语法,在其他数据库比如 Oracle 上就不通用,我犯过一个白痴的行为就是在 Oracle 中使用 limit 查询语句。。。
聚合
下面我们来看一下对记录进行汇总的操作,这类操作主要有
汇总函数,比如 sum 求和、count 统计数量、max 最大值、min 最小值等group by,关键字表示对分类聚合的字段进行分组,比如按照部门统计员工的数量,那么 group by 后面就应该跟上部门with是可选的语法,它表示对汇总之后的记录进行再次汇总having关键字表示对分类后的结果再进行条件的过滤。
看起来 where 和 having 意思差不多,不过它们用法不一样,where 是使用在统计之前,对统计前的记录进行过滤,having 是用在统计之后,是对聚合之后的结果进行过滤。也就是说 where 永远用在 having 之前,我们应该先对筛选的记录进行过滤,然后再对分组的记录进行过滤。
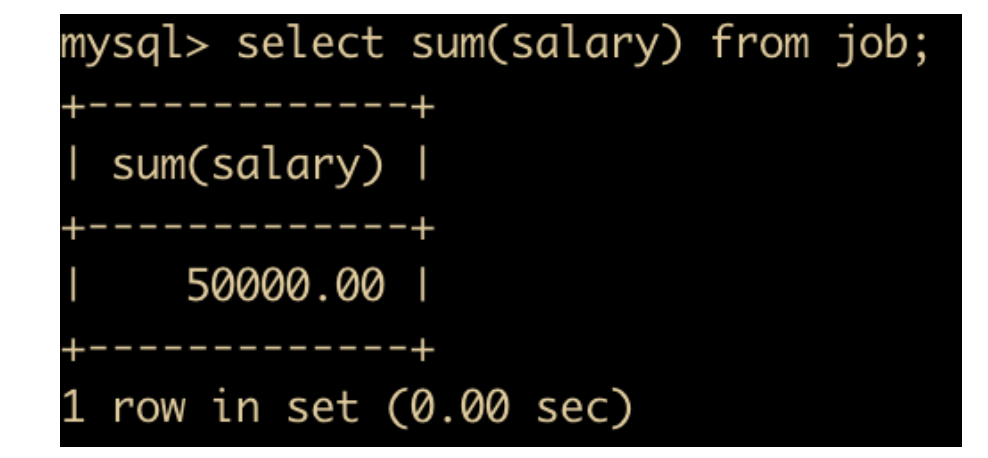
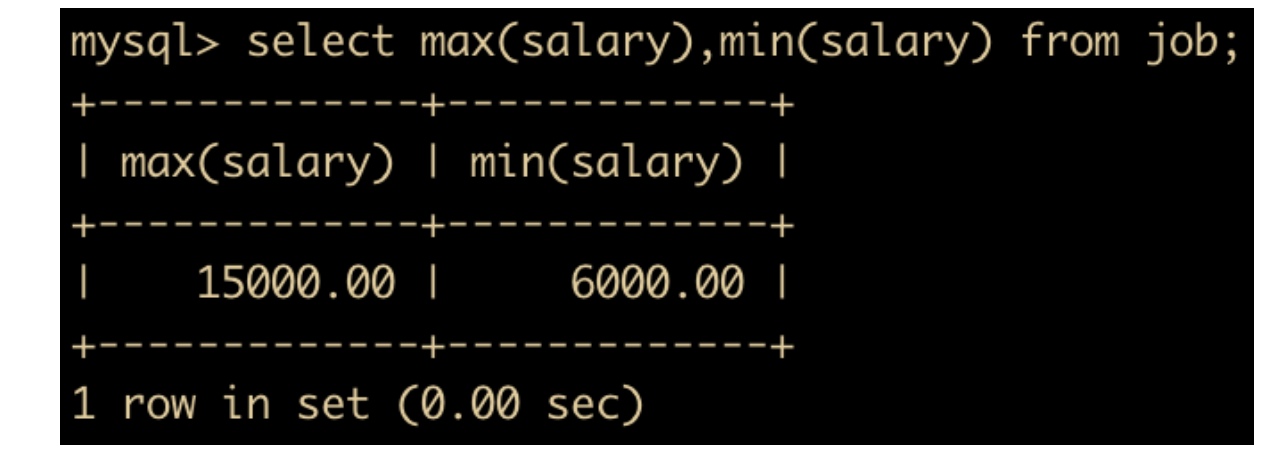
可以对 job 表中员工薪水进行统计,选出总共的薪水、最大薪水、最小薪水
select sum(salary) from job;
select max(salary),min(salary) from job;
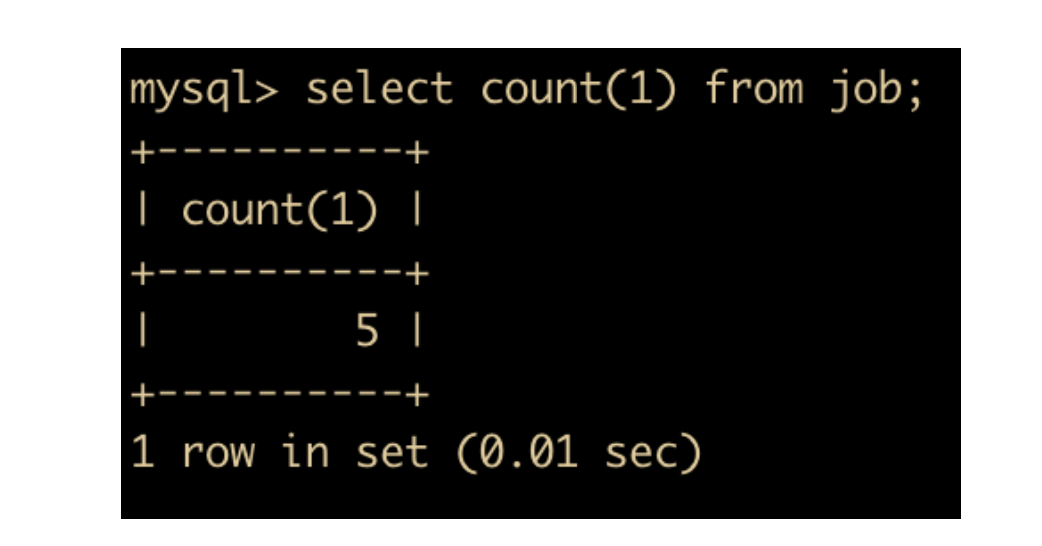
比如我们要统计 job 表中人员的数量
select count(1) from job;
统计完成后的结果如下
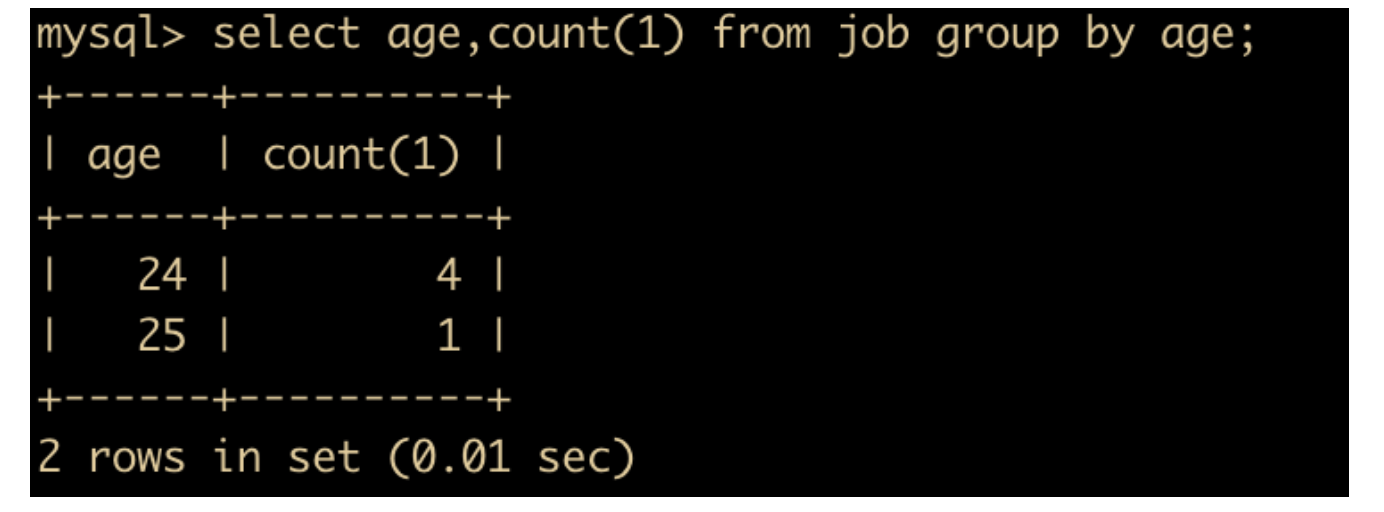
我们可以按照 job 表中的年龄来进行对应的统计
select age,count(1) from job group by age;
既要统计各年龄段的人数,又要统计总人数
select age,count(1) from job group by age with rollup;
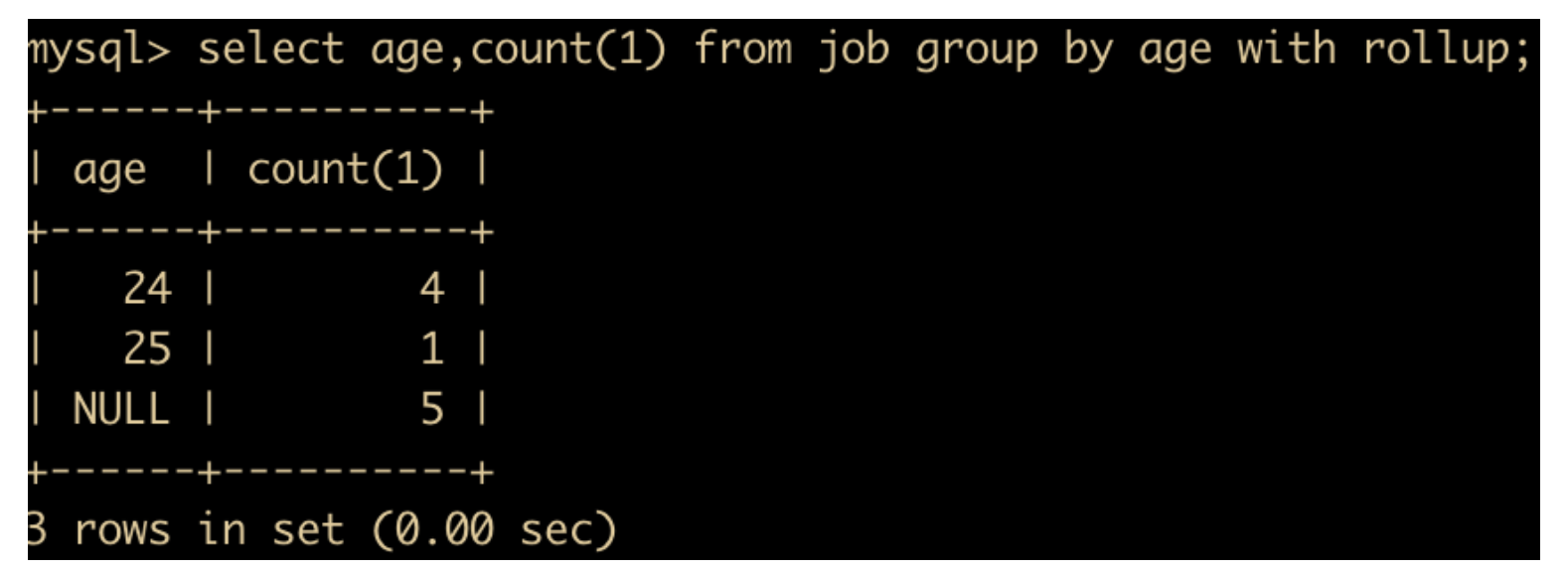
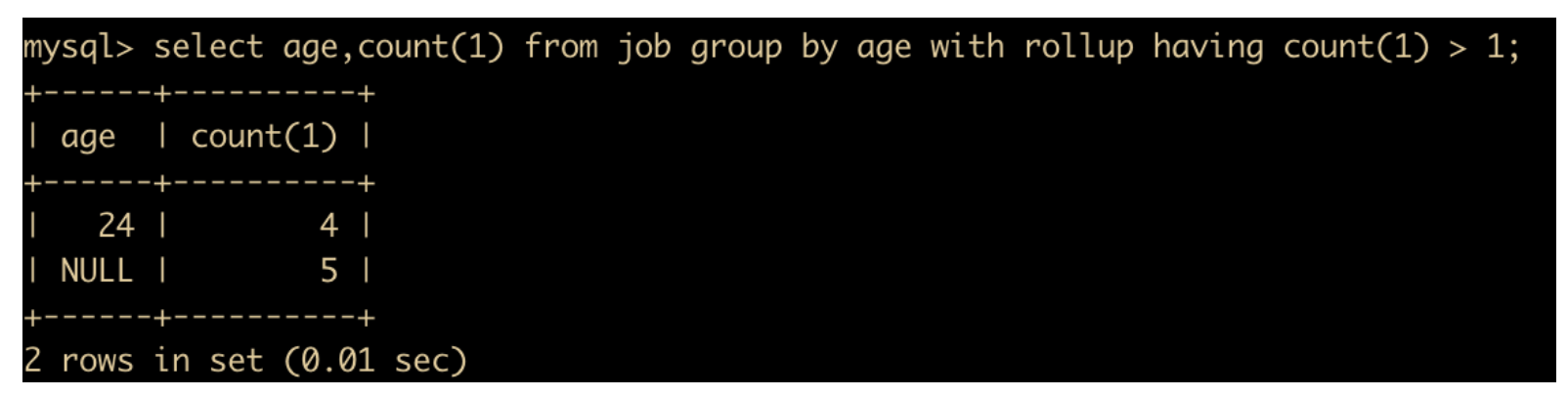
在此基础上进行分组,统计数量大于 1 的记录
select age,count(1) from job group by age with rollup having count(1) > 1;
表连接
表连接一直是笔者比较痛苦的地方,曾经因为一个表连接挂了面试,现在来认真撸一遍。
表连接一般体现在表之间的关系上。当需要同时显示多个表中的字段时,就可以用表连接来实现。
为了演示表连接的功能,我们为 job 表加一个 type 字段表示工作类型,增加一个 job_type 表表示具体的工作种类,如下所示
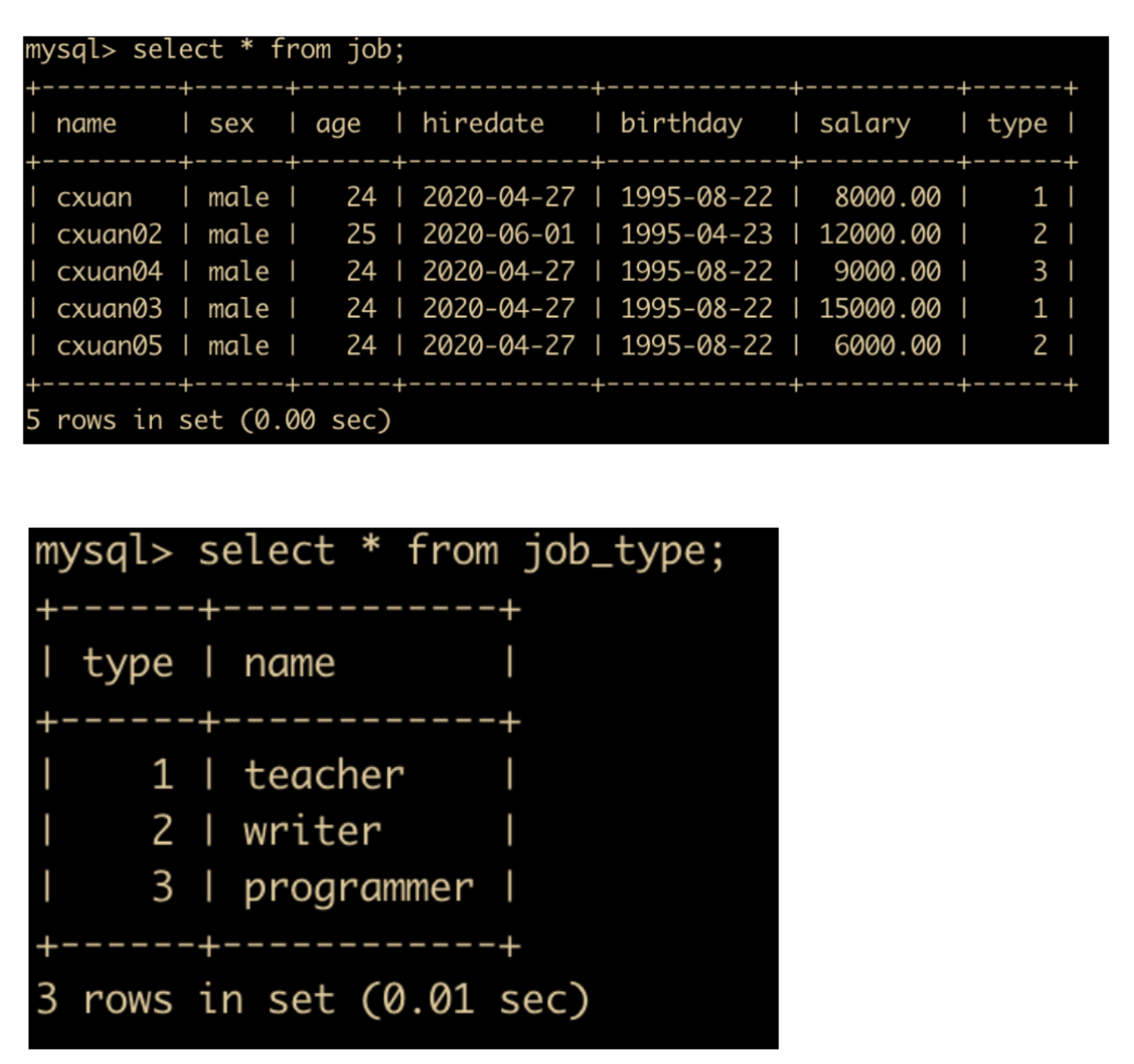
下面开始我们的演示
查询出 job 表中的 type 和 job_type 表中的 type 匹配的姓名和工作类型
select job.name,job_type.name from job,job_type where job.type = job_type.type;

上面这种连接使用的是内连接,除此之外,还有外连接。那么它们之间的区别是啥呢?
内连接:选出两张表中互相匹配的记录;
外连接:不仅选出匹配的记录,也会选出不匹配的记录;
外连接分为两种
- 左外连接:筛选出包含左表的记录并且右表没有和它匹配的记录
- 右外连接:筛选出包含右表的记录甚至左表没有和它匹配的记录
为了演示效果我们在 job 表和 job_type 表中分别添加记录,添加完成后的两表如下

下面我们进行左外连接查询:查询出 job 表中的 type 和 job_type 表中的 type 匹配的姓名和工作类型
select job.name,job_type.name from job left join job_type on job.type = job_type.type;
查询出来的结果如下
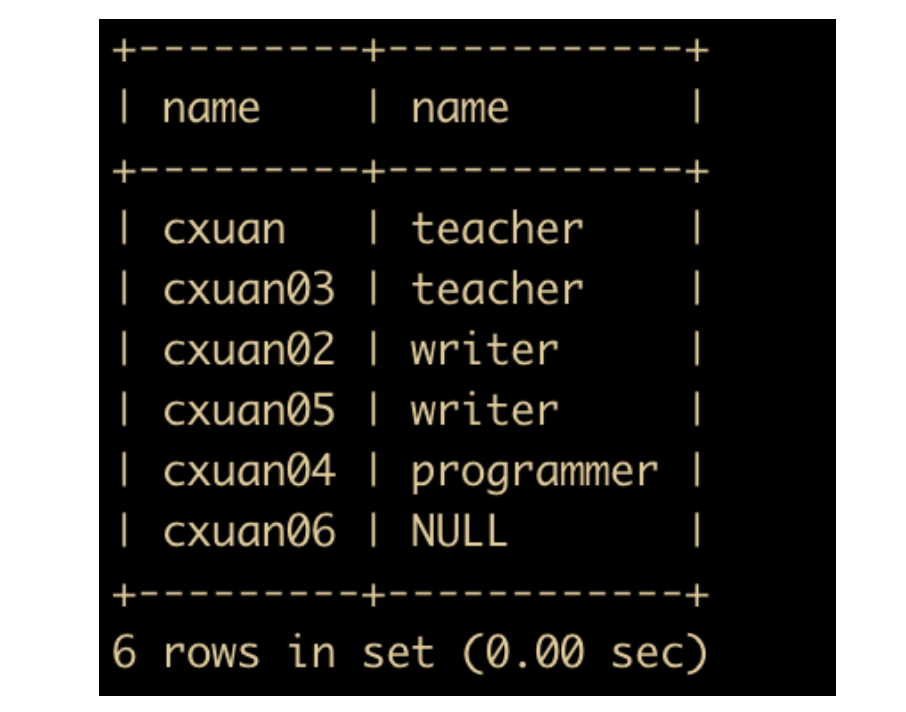
可以看出 cxuan06 也被查询出来了,而 cxuan06 他没有具体的工作类型。
使用右外连接查询
select job.name,job_type.name from job right join job_type on job.type = job_type.type;
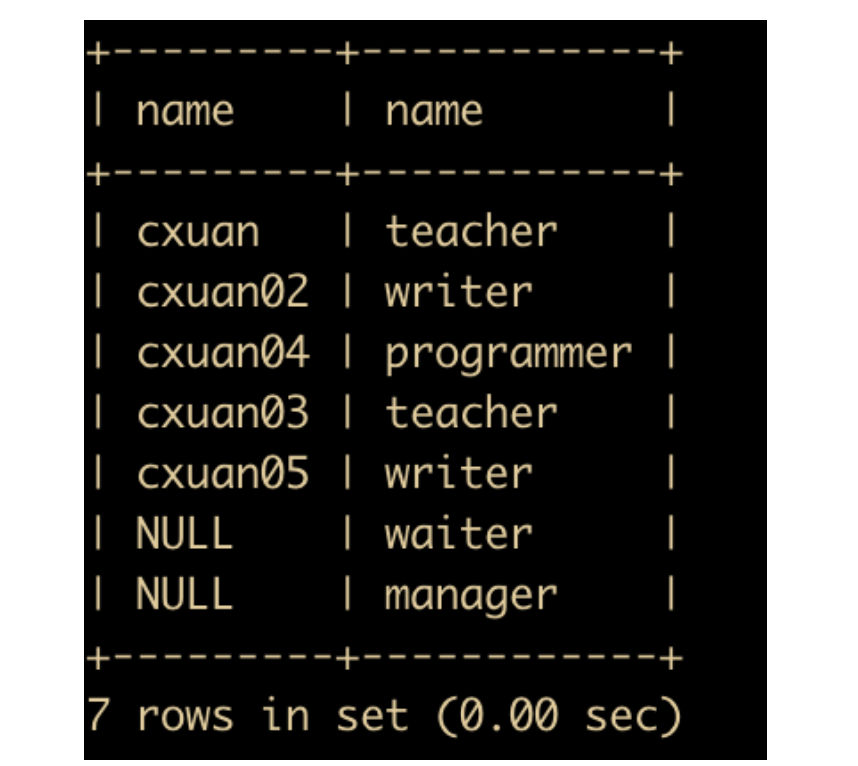
可以看出,job 表中并没有 waiter 和 manager 的角色,但是也被查询出来了。
子查询
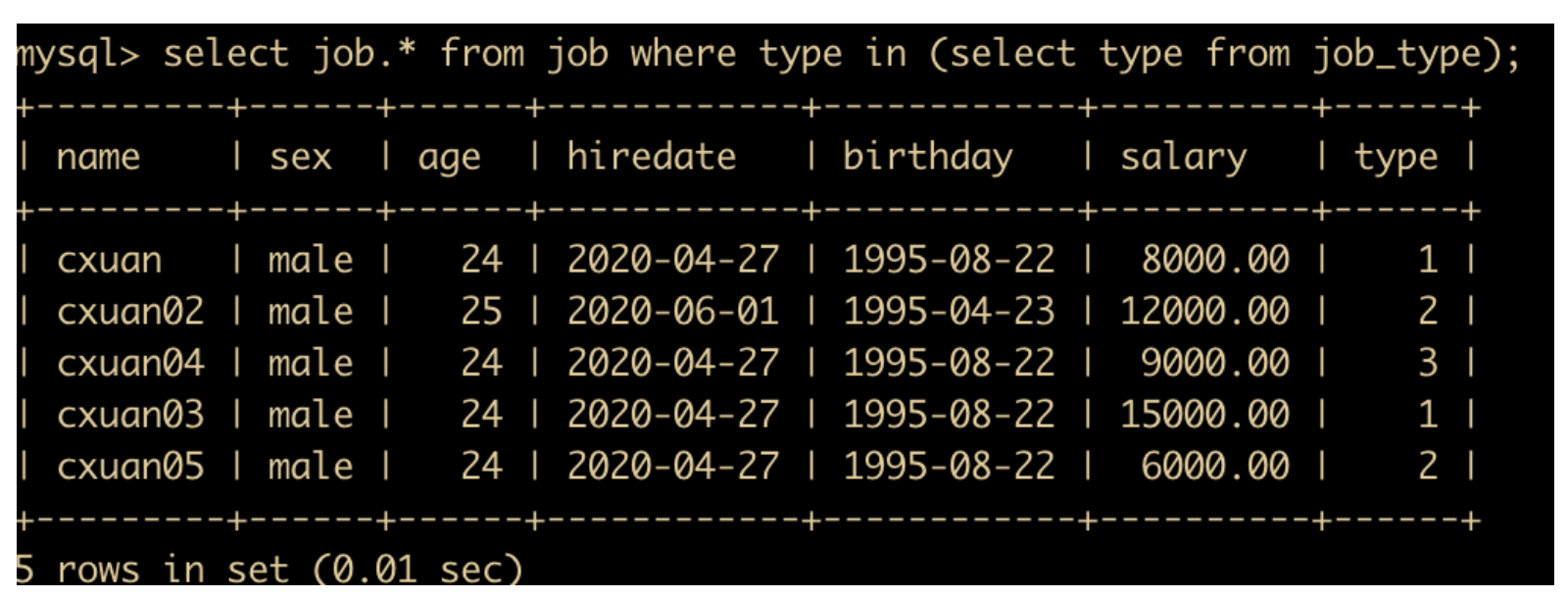
有一些情况,我们需要的查询条件是另一个 SQL 语句的查询结果,这种查询方式就是子查询,子查询有一些关键字比如 in、not in、=、!=、exists、not exists 等,例如我们可以通过子查询查询出每个人的工作类型
select job.* from job where type in (select type from job_type);
如果自查询数量唯一的话,还可以用 = 来替换 in
select * from job where type = (select type from job_type);

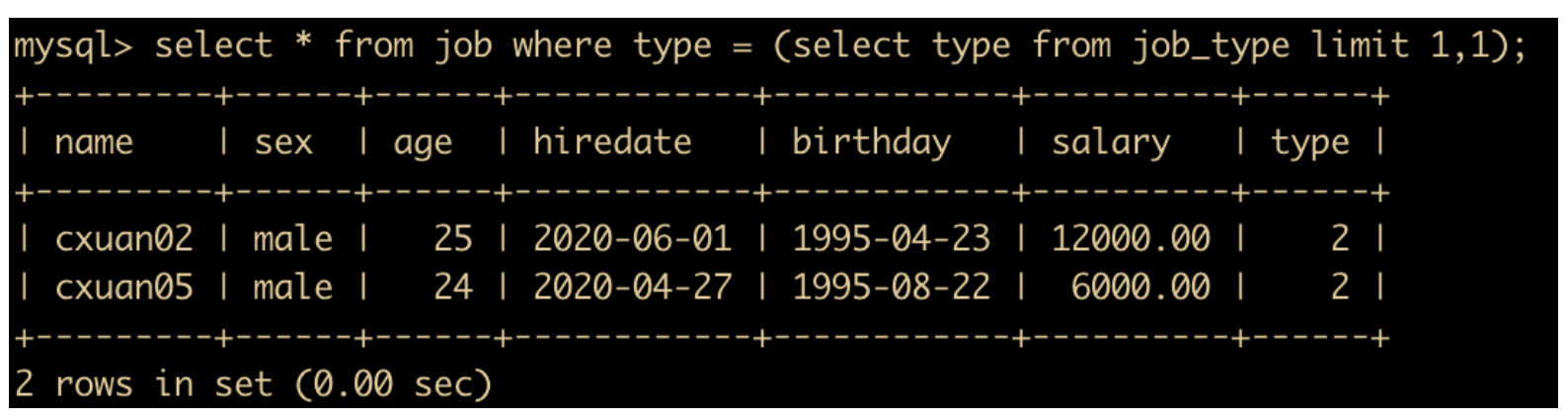
意思是自查询不唯一,我们使用 limit 限制一下返回的记录数
select * from job where type = (select type from job_type limit 1,1);
在某些情况下,子查询可以转换为表连接
联合查询
我们还经常会遇到这样的场景,将两个表的数据单独查询出来之后,将结果合并到一起进行显示,这个时候就需要 UNION 和 UNION ALL 这两个关键字来实现这样的功能,UNION 和 UNION ALL 的主要区别是 UNION ALL 是把结果集直接合并在一起,而 UNION 是将 UNION ALL 后的结果进行一次 DISTINCT 去除掉重复数据。
比如
select type from job union all select type from job_type;
它的结果如下
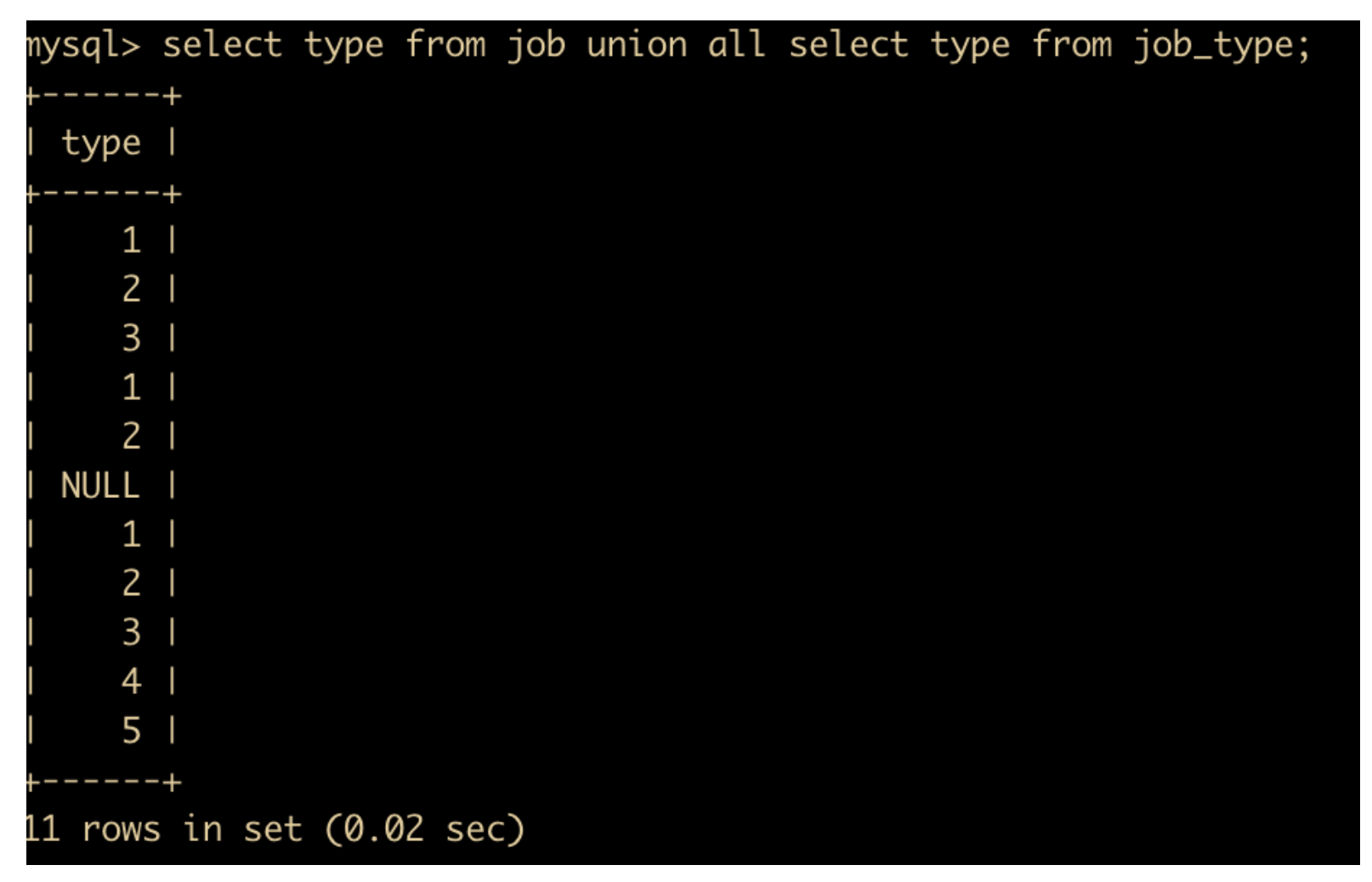
上述结果是查询 job 表中的 type 字段和 job_type 表中的 type 字段,并把它们进行汇总,可以看出 UNION ALL 只是把所有的结果都列出来了
使用 UNION 的 SQL 语句如下
select type from job union select type from job_type;
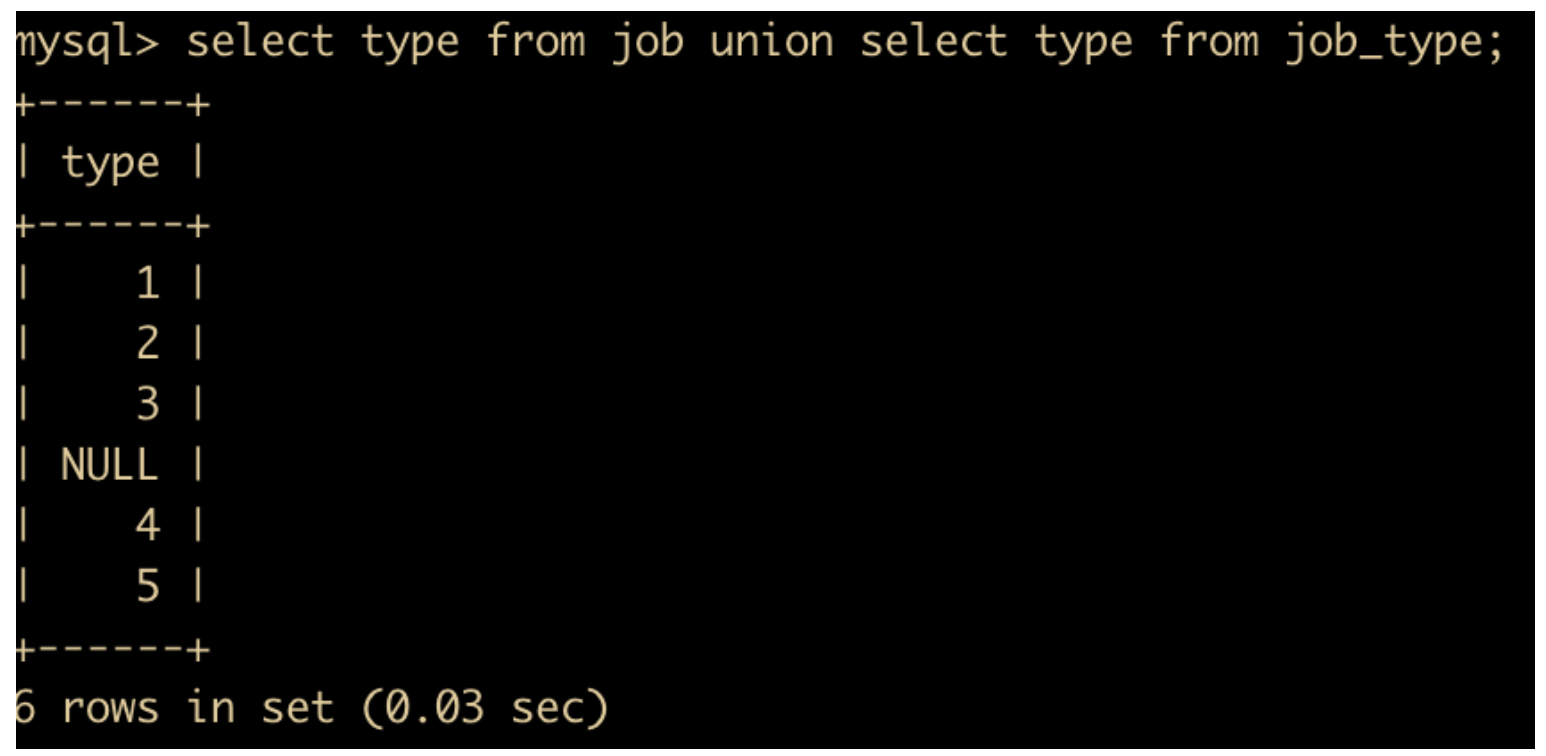
可以看出 UNION 是对 UNION ALL 使用了 distinct 去重处理。
DCL 语句
DCL 语句主要是管理数据库权限的时候使用,这类操作一般是 DBA 使用的,开发人员不会使用 DCL 语句。
关于帮助文档的使用
我们一般使用 MySQL 遇到不会的或者有疑问的东西经常要去查阅网上资料,甚至可能需要去查 MySQL 官发文档,这样会耗费大量的时间和精力。
下面教你一下在 MySQL 命令行就能直接查询资料的语句
按照层次查询
可以使用 ? contents 来查询所有可供查询的分类,如下所示
? contents;
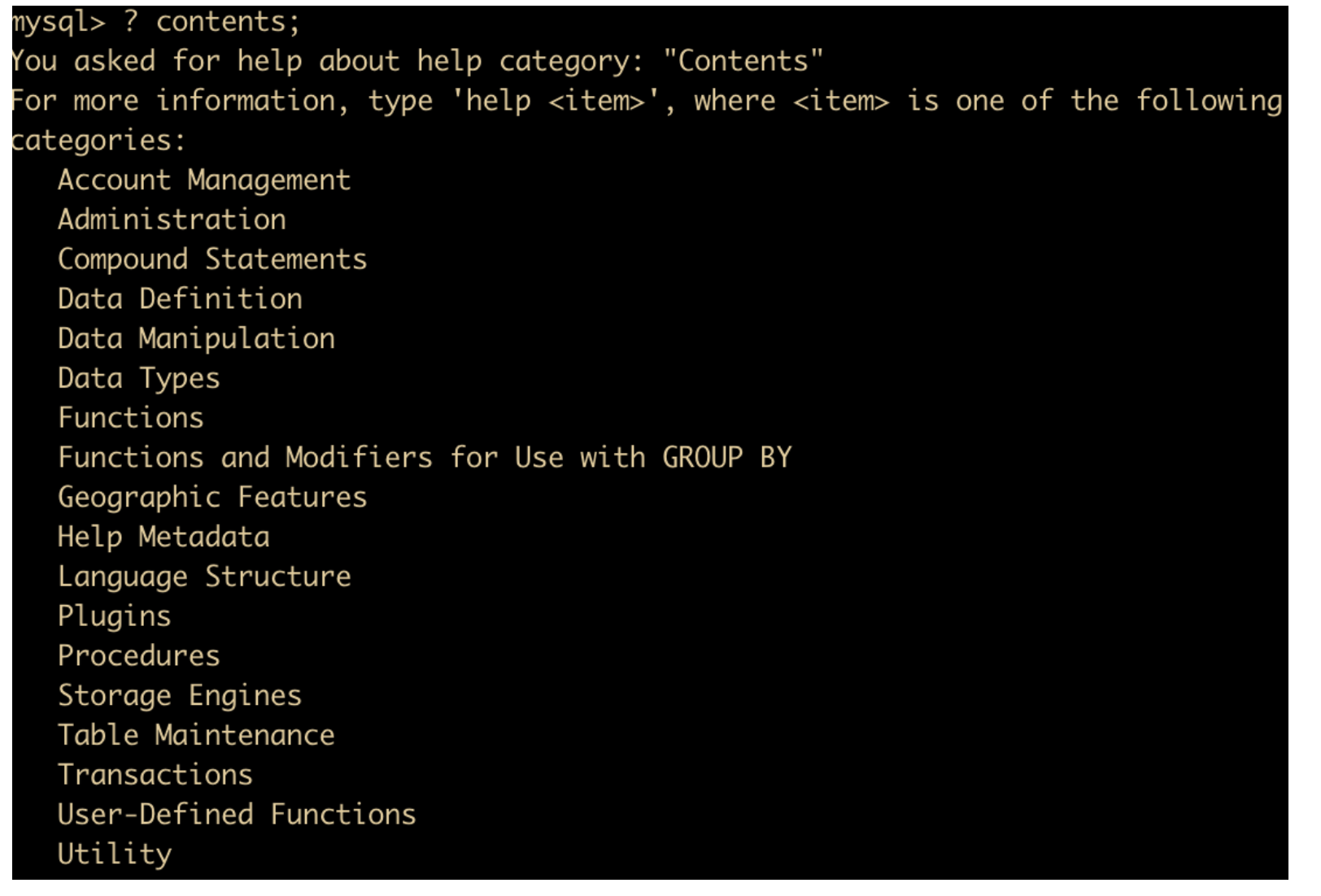
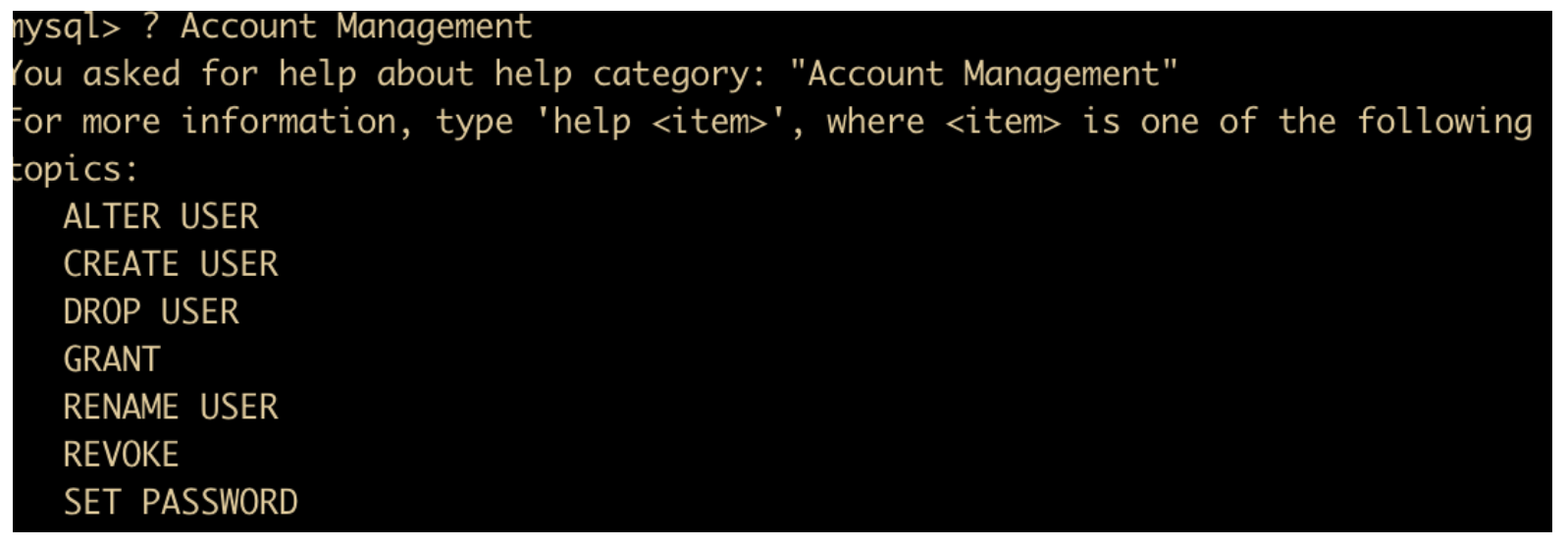
我们输入
? Account Management
可以查询具体关于权限管理的命令
比如我们想了解一下数据类型
? Data Types
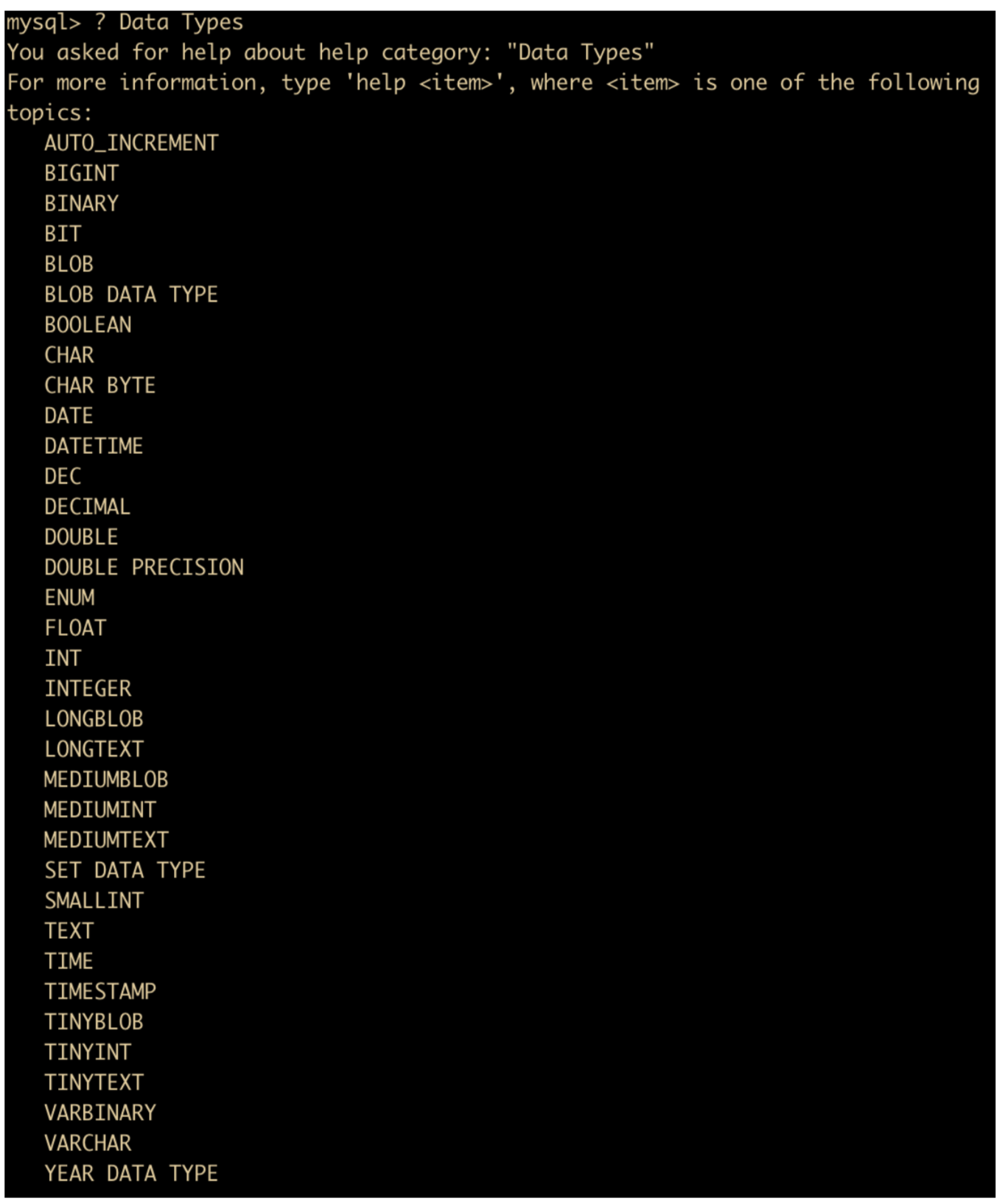
然后我们想了解一下 VARCHAR 的基本定义,可以直接使用
? VARCHAR
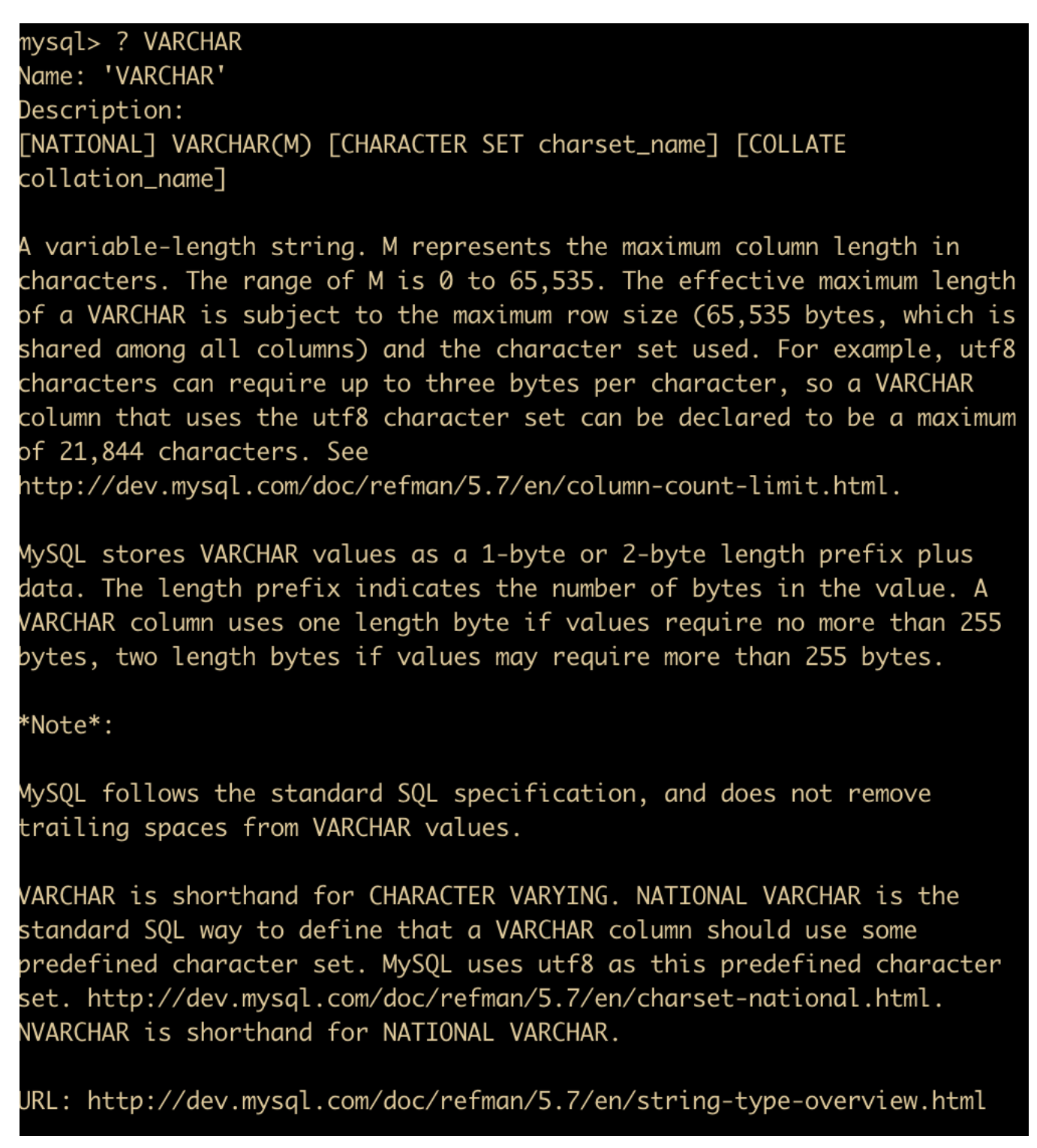
可以看到有关于 VARCHAR 数据类型的详细信息,然后在最下面还有 MySQL 的官方文档,方便我们快速查阅。
快速查阅
在实际应用过程中,如果要快速查询某个语法时,可以使用关键字进行快速查询,比如我们使用
? show
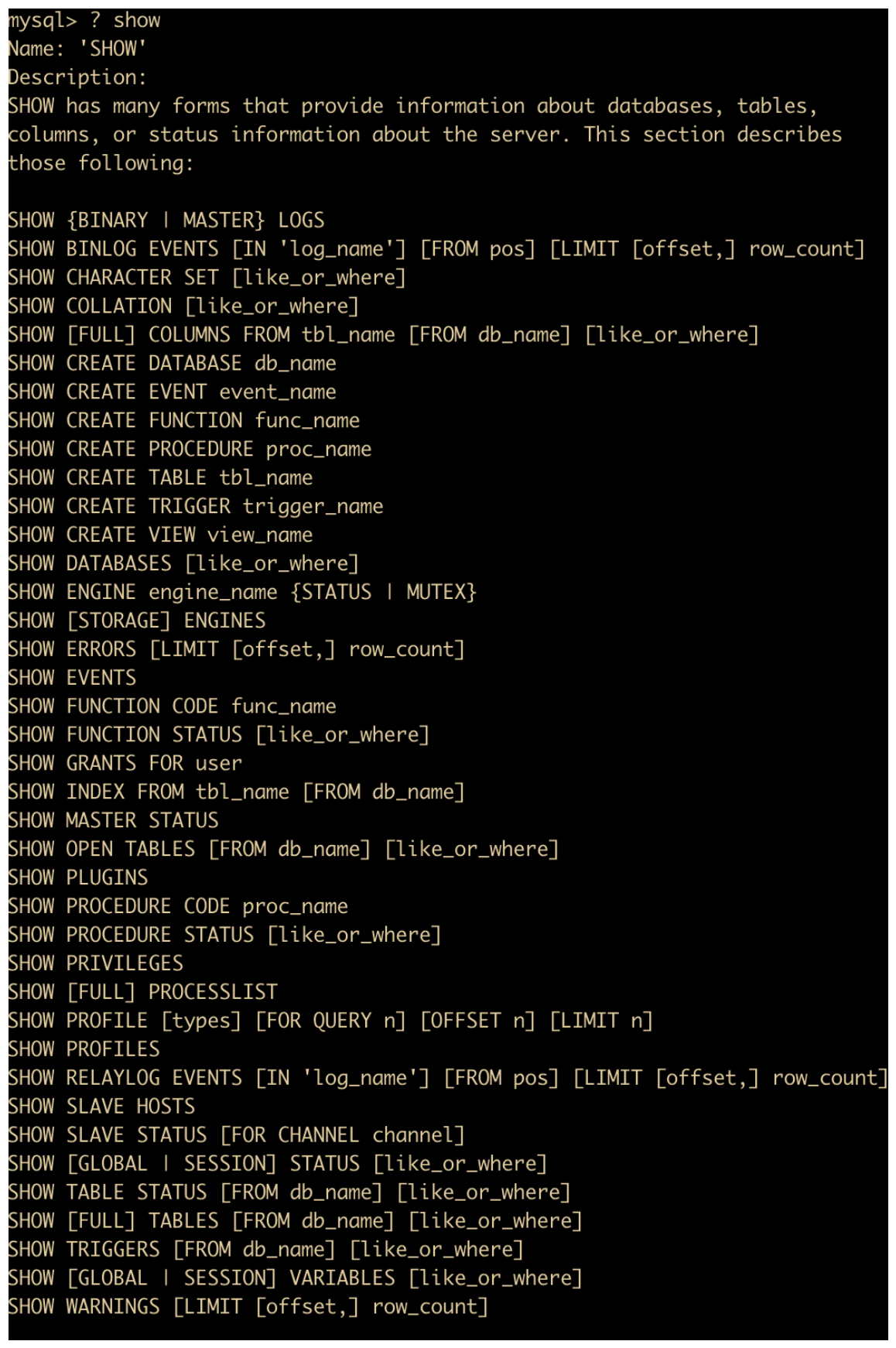
能够快速列出一些命令
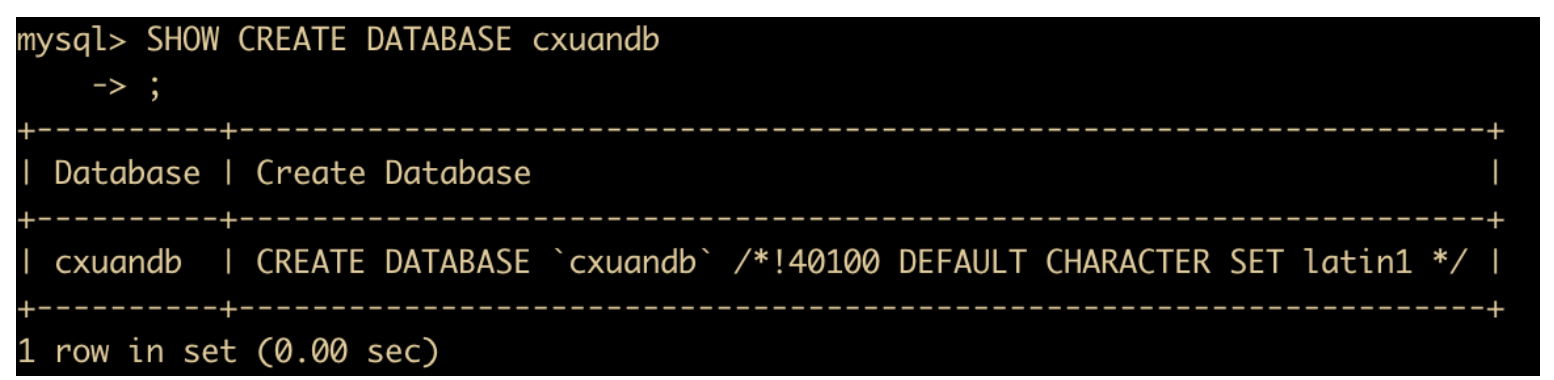
比如我们想要查阅 database 的信息,使用
SHOW CREATE DATABASE cxuandb;
MySQL 数据类型
MySQL 提供很多种数据类型来对不同的常量、变量进行区分,MySQL 中的数据类型主要是 数值类型、日期和时间类型、字符串类型 选择合适的数据类型进行数据的存储非常重要,在实际开发过程中,选择合适的数据类型也能够提高 SQL 性能,所以有必要认识一下这些数据类型。
数值类型
MySQL 支持所有标准的 SQL 数据类型,这些数据类型包括严格数据类型的严格数值类型,这些数据类型有
- INTEGER
- SMALLINT
- DECIMAL
- NUMERIC。
近似数值数据类型 并不用严格按照指定的数据类型进行存储,这些有
- FLOAT
- REAL
- DOUBLE PRECISION
还有经过扩展之后的数据类型,它们是
- TINYINT
- MEDIUMINT
- BIGINT
- BIT
其中 INT 是 INTEGER 的缩写,DEC 是 DECIMAL 的缩写。
下面是所有数据类型的汇总

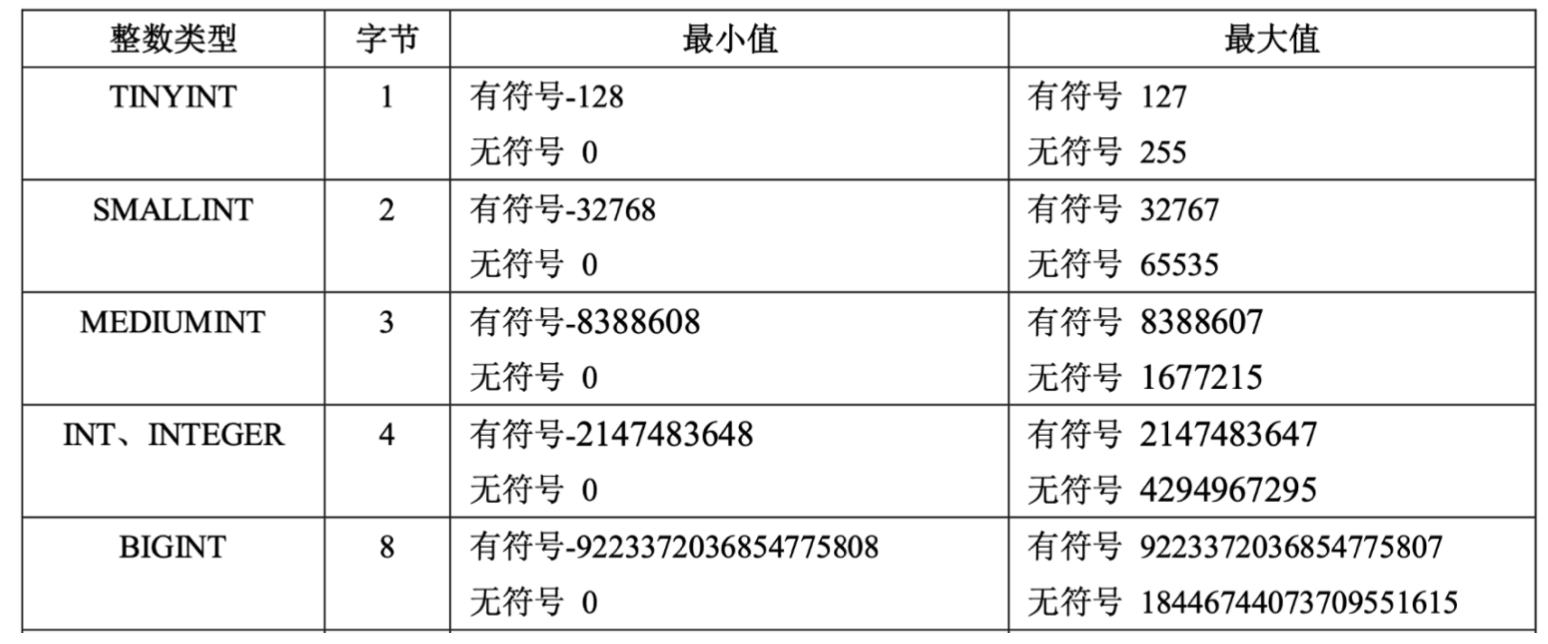
整数
在整数类型中,按照取值范围和存储方式的不同,分为

- TINYINT ,占用 1 字节
- SMALLINT,占用 2 字节
- MEDIUMINT,占用 3 字节
- INT、INTEGER,占用 4 字节
- BIGINT,占用 8 字节
五个数据类型,如果超出类型范围的操作,会发生错误提示,所以选择合适的数据类型非常重要。
还记得我们上面的建表语句么
我们一般会在 SQL 语句的数据类型后面加上指定长度来表示数据类型许可的范围,例如
int(7)
表示 int 类型的数据最大长度为 7,如果填充不满的话会自动填满,如果不指定 int 数据类型的长度的话,默认是 int(11)。
我们创建一张表来演示一下
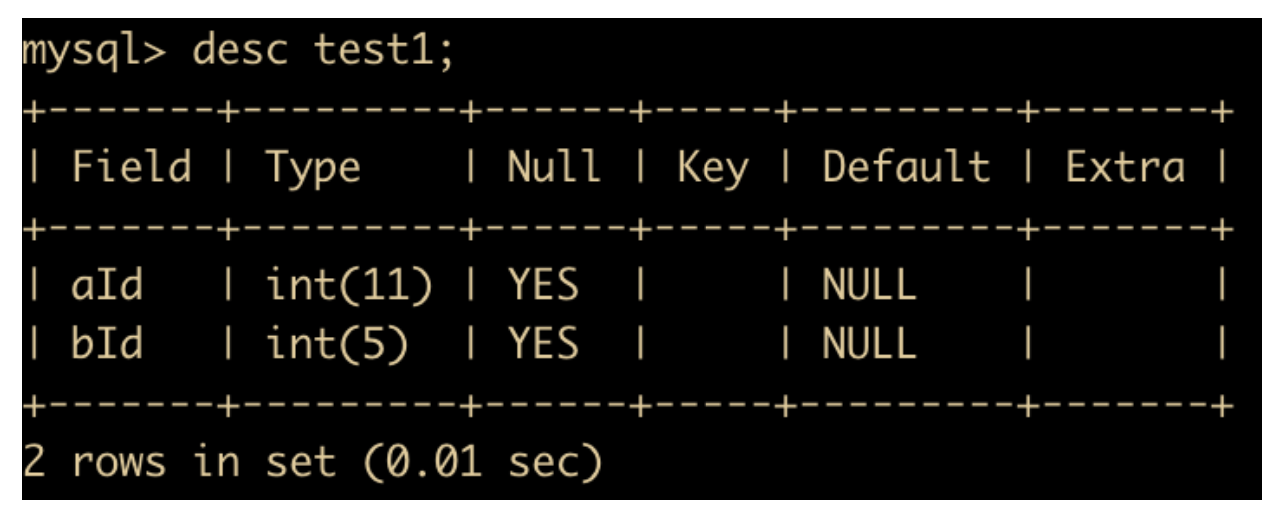
create table test1(aId int, bId int(5));
/* 然后我们查看一下表结构 */ desc test1;
整数类型一般配合 zerofill 来使用,顾名思义,就是用 0 进行填充,也就是数字位数不够的空间使用 0 进行填充。
分别修改 test1 表中的两个字段
alter table test1 modify aId int zerofill;
alter table test1 modify bId int(5) zerofill;
然后插入两条数据,执行查询操作
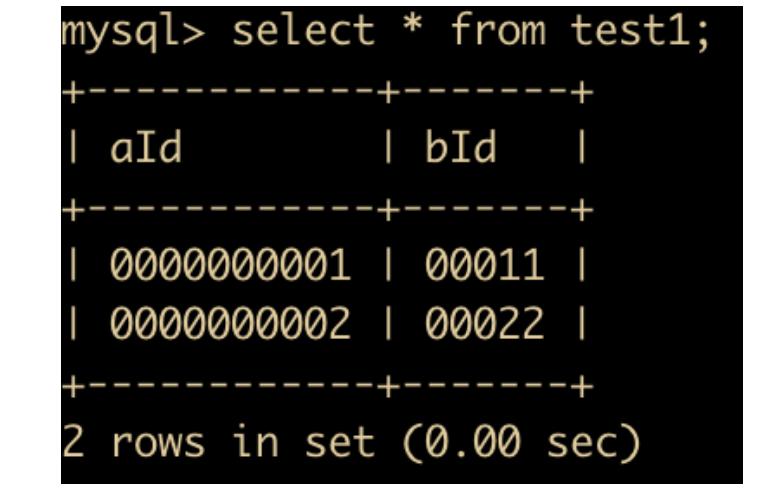
如上图所示,使用zerofill 可以在数字前面使用 0 来进行填充,那么如果宽度超过指定长度后会如何显示?我们来试验一下,向 aId 和 bId 分别插入超过字符限制的数字

会发现 aId 已经超出了指定范围,那么我们对 aId 插入一个在其允许范围之内的数据

会发现,aId 已经插进去了,bId 也插进去了,为什么 bId 显示的是 int(5) 却能够插入 7 位长度的数值呢?
所有的整数都有一个可选属性 UNSIGNED(无符号),如果需要在字段里面保存非负数或者是需要较大上限值时,可以使用此选项,它的取值范围是正常值的下限取 0 ,上限取原值的 2 倍。如果一个列为 zerofill ,会自动为该列添加 UNSIGNED 属性。
除此之外,整数还有一个类型就是 AUTO_INCREMENT,在需要产生唯一标识符或者顺序值时,可利用此属性,这个属性只用于整数字符。一个表中最多只有一个 AUTO_INCREMENT 属性,一般用于自增主键,而且 NOT NULL,并且是 PRIMARY KEY 和 UNIQUE 的,主键必须保证唯一性而且不为空。
小数
小数说的是啥?它其实有两种类型;一种是浮点数类型,一种是定点数类型;

浮点数有两种
- 单精度浮点型 – float 型
- 双精度浮点型 – double 型
定点数只有一种 decimal。定点数在 MySQL 内部中以字符串的形式存在,比浮点数更为准确,适合用来表示精度特别高的数据。
浮点数和定点数都可以使用 (M,D) 的方式来表示,M 表示的就是 整数位 + 小数位 的数字,D 表示位于 . 后面的小数。M 也被称为精度 ,D 被称为标度。
下面通过示例来演示一下
首先建立一个 test2 表
CREATE TABLE test2 (aId float(6,2) default NULL, bId double(6,2) default NULL,cId decimal(6,2) default NULL)
然后向表中插入几条数据
insert into test2 values(1234.12,1234.12,1234.12);
这个时候显示的数据就是

然后再向表中插入一些约束之外的数据
insert into test2 values(1234.123,1234.123,1234.123);
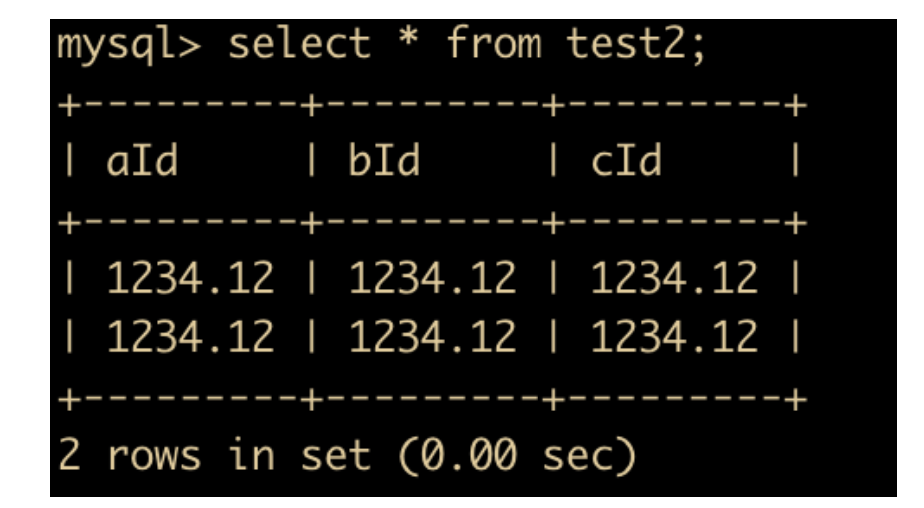
发现插入完成后还显示的是 1234.12,小数位第三位的值被舍去了。
现在我们把 test2 表中的精度全部去掉,再次插入
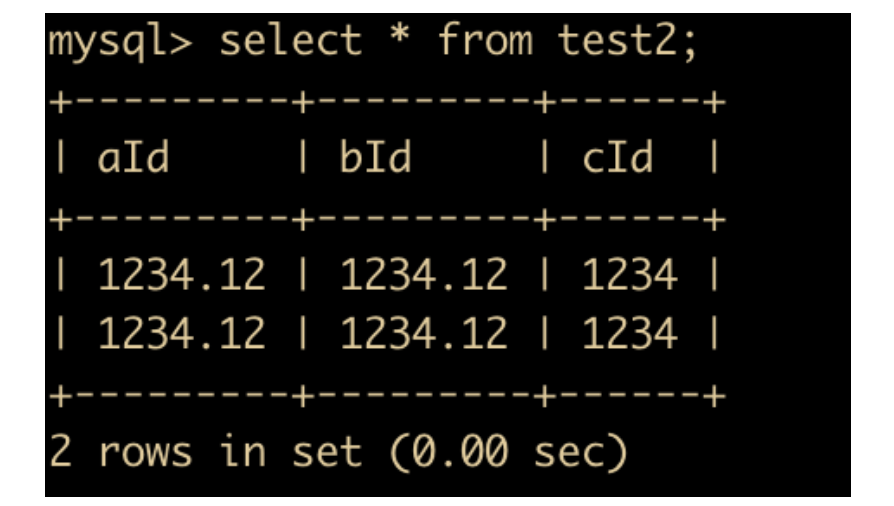
alter table test2 modify aId float;
alter table test2 modify bId double;
alter table test2 modify cId decimal;
先查询一下,发现 cId 舍去了小数位。
然后再次插入 1.23,SQL 语句如下
insert into test2 values(1.23,1.23,1.23);
结果如下
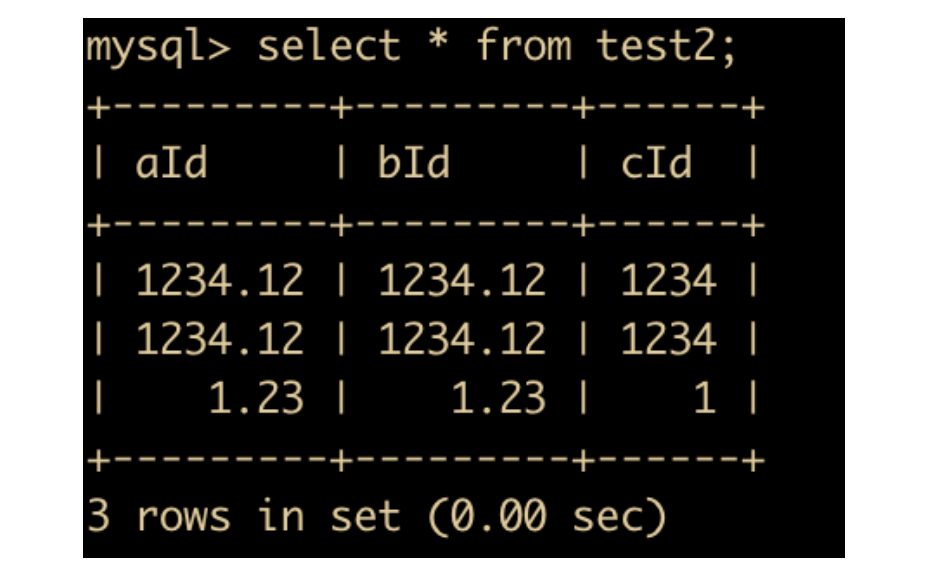
这个时候可以验证
- 浮点数如果不写精度和标度,会按照实际的精度值进行显示
- 定点数如果不写精度和标度,会按照
decimal(10,0)来进行操作,如果数据超过了精度和标题,MySQL 会报错
位类型
对于位类型,用于存放字段值,BIT(M) 可以用来存放多位二进制数,M 的范围是 1 – 64,如果不写的话默认为 1 位。
下面我们来掩饰一下位类型
新建一个 test3 表,表中只有一个位类型的字段
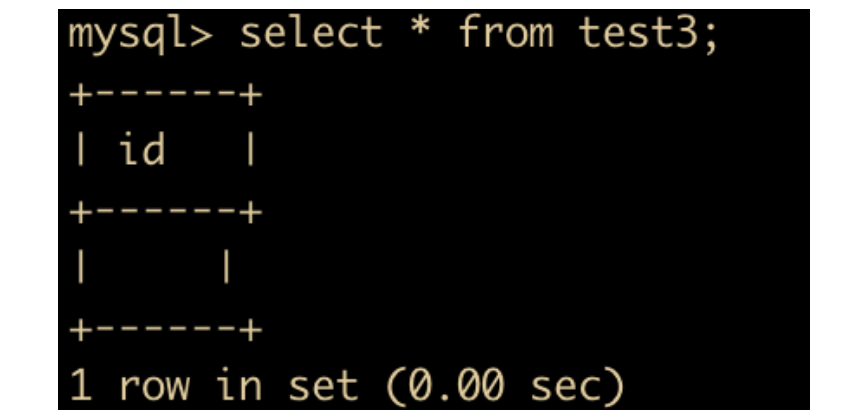
create table test3(id bit(1));
然后随意插入一条数据
insert into test3 values(1);
发现无法查询出对应结果。
然后我们使用 hex() 和 bin() 函数进行查询
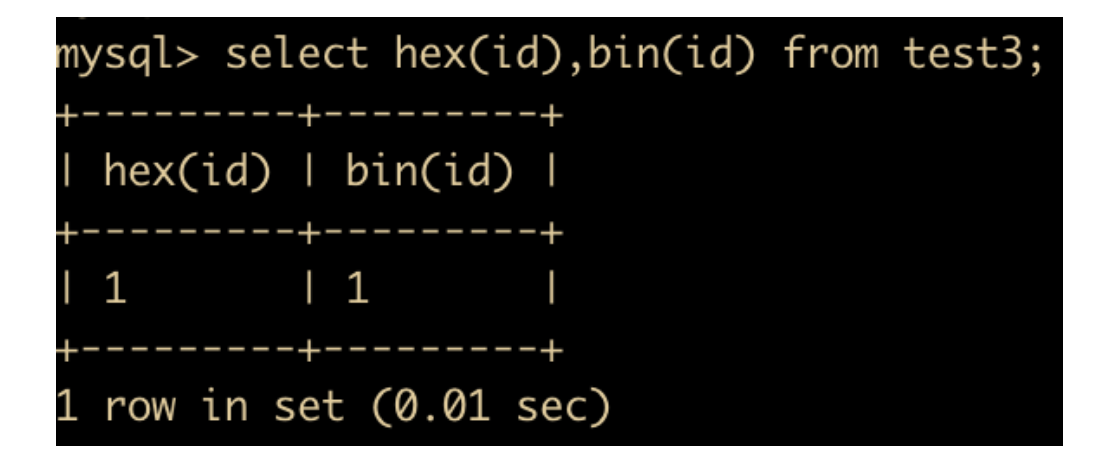
发现能够查询出对应结果。
也就是说当数据插入 test3 时,会首先把数据转换成为二进制数,如果位数允许,则将成功插入;如果位数小于实际定义的位数,则插入失败。如果我们像表中插入数据 2
insert into test3 values(2);
那么会报错

因为 2 的二进制数表示是 10,而表中定义的是 bit(1) ,所以无法插入。
那么我们将表字段修改一下
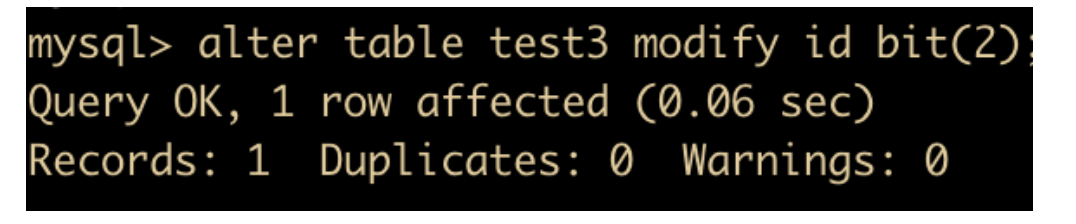
然后再进行插入,发现已经能够插入了

日期时间类型
MySQL 中的日期与时间类型,主要包括:YEAR、TIME、DATE、DATETIME、TIMESTAMP,每个版本可能不同。下表中列出了这几种类型的属性。
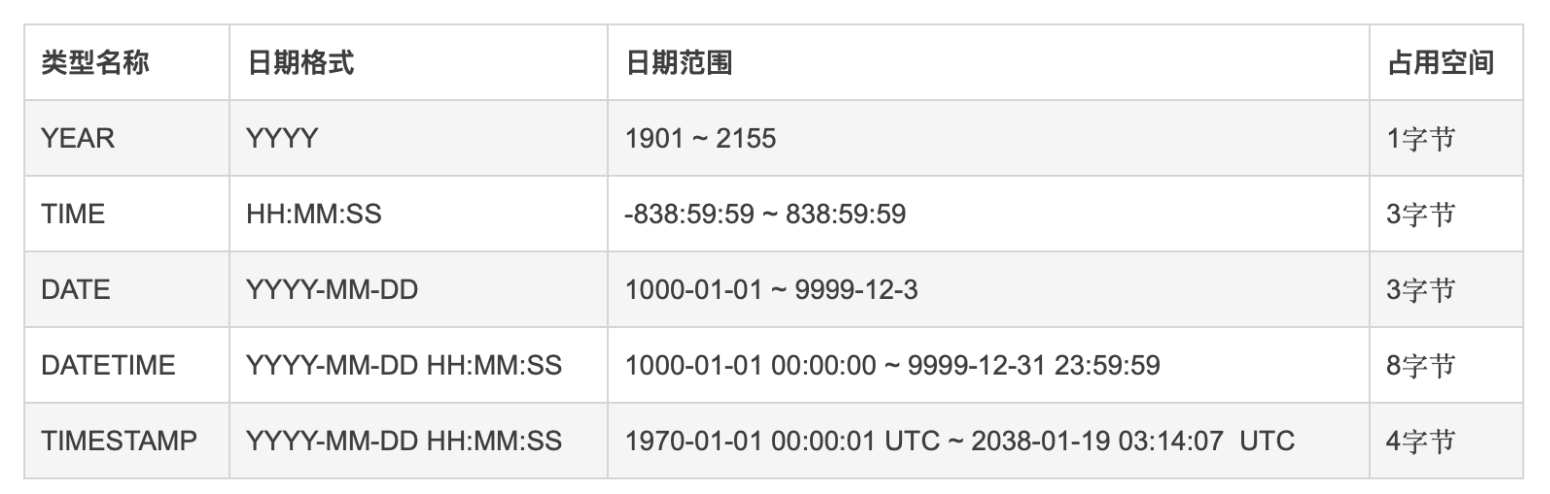
下面分别来介绍一下
YEAR
YEAR 可以使用三种方式来表示
- 用 4 位的数字或者字符串表示,两者效果相同,表示范围 1901 – 2155,插入超出范围的数据会报错。
- 以 2 位字符串格式表示,范围为 ‘00’~‘99’。‘00’~‘69’ 表示 2000~2069,‘70’~‘99’ 表示1970~1999。‘0’ 和 ‘00’ 都会被识别为 2000,超出范围的数据也会被识别为 2000。
- 以 2 位数字格式表示,范围为 1~99。1~69 表示 2001~2069, 70~99 表示 1970~1999。但 0 值会被识别为0000,这和 2 位字符串被识别为 2000 有所不同
下面我们来演示一下 YEAR 的用法,创建一个 test4 表
create table test4(id year);
然后我们看一下 test4 的表结构
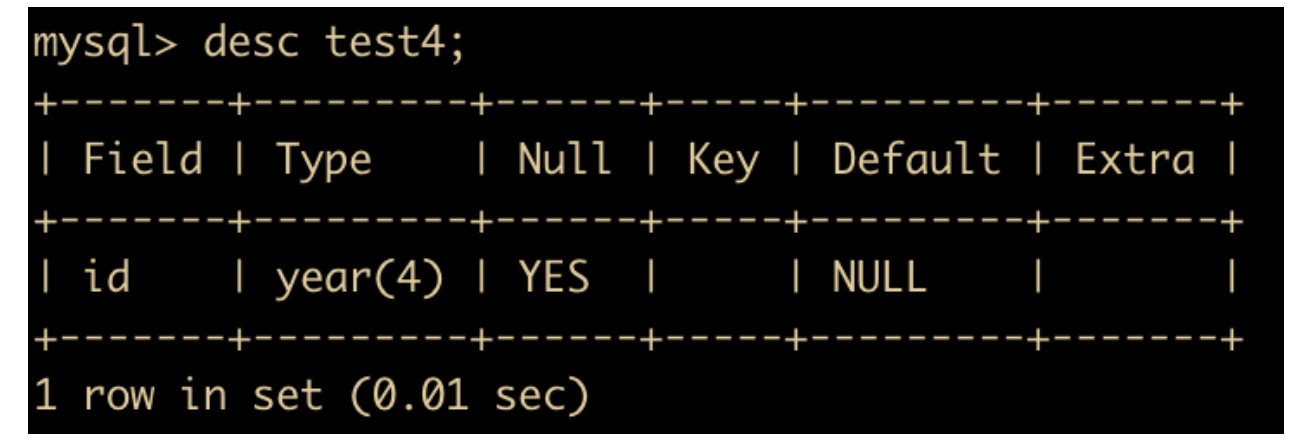
默认创建的 year 就是 4 位,下面我们向 test4 中插入数据
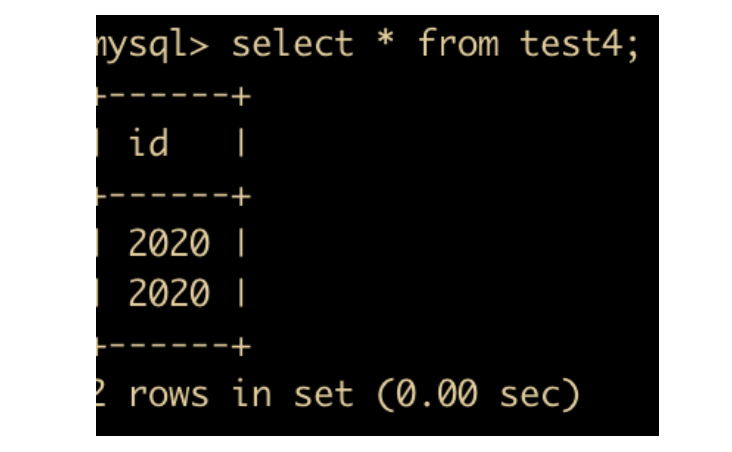
insert into test4 values(2020),('2020');
然后进行查询,发现表示形式是一样的
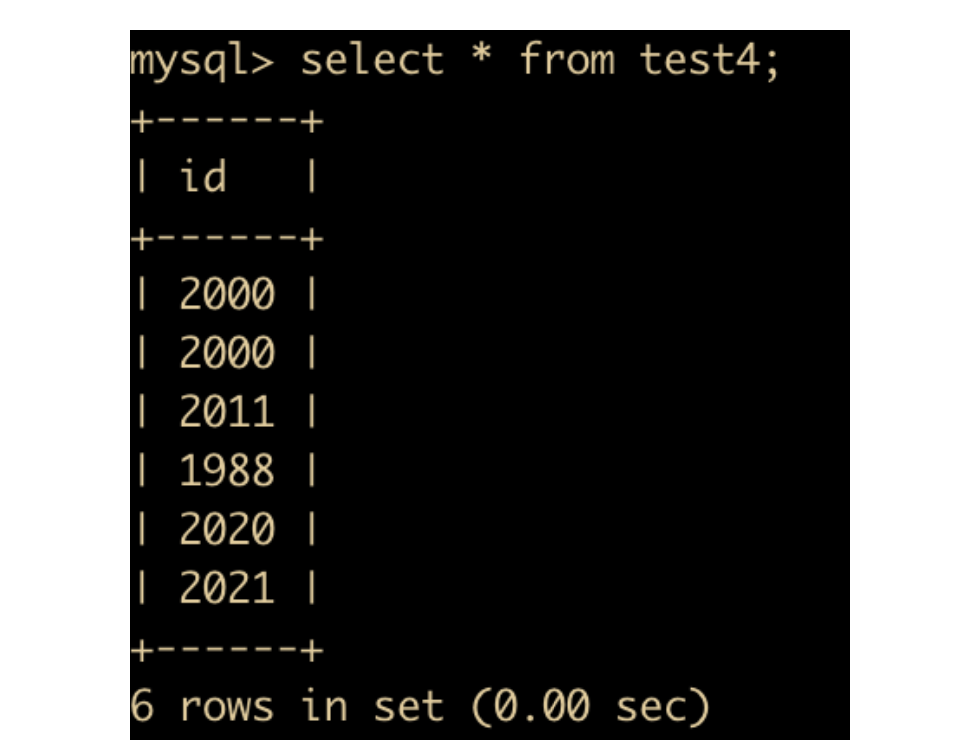
使用两位字符串来表示
delete from test4;
insert into test4 values ('0'),('00'),('11'),('88'),('20'),('21');
使用两位数字来表示
delete from test4;
insert into test4 values (0),(00),(11),(88),(20),(21);
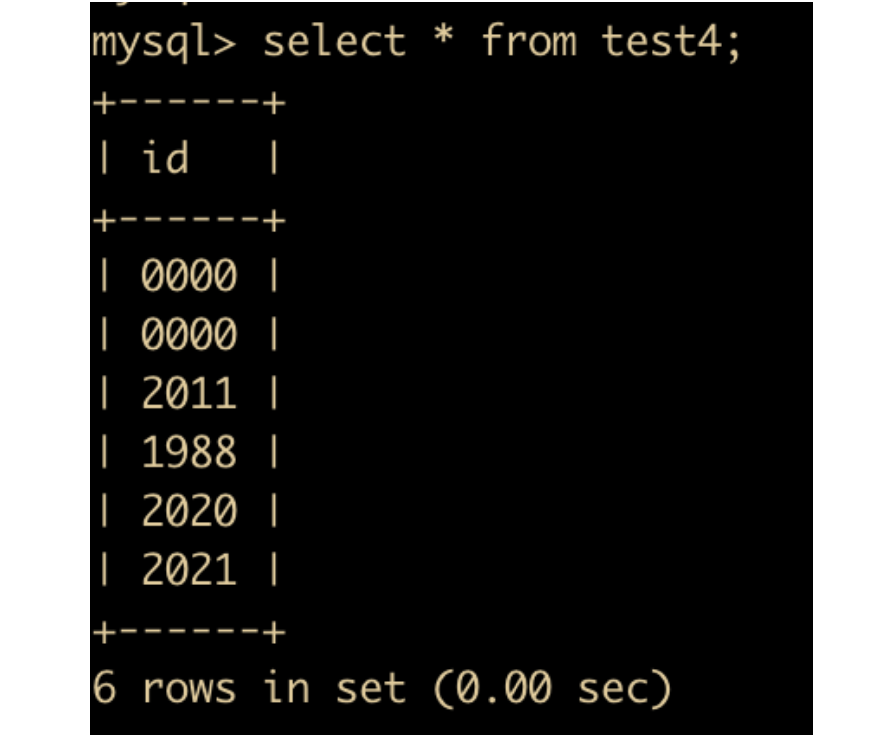
发现只有前两项不一样。
TIME
TIME 所表示的范围和我们预想的不一样
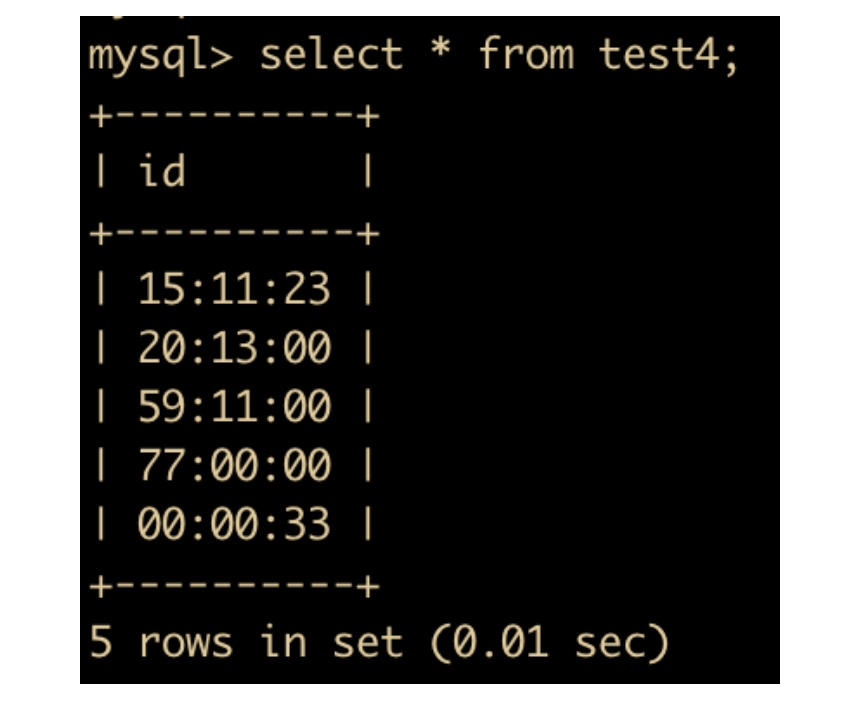
我们把 test4 改为 TIME 类型,下面是 TIME 的示例
alter table test4 modify id TIME;
insert into test4 values ('15:11:23'),('20:13'),('2 11:11'),('3 05'),('33');
结果如下
DATE
DATE 表示的类型有很多种,下面是 DATE 的几个示例
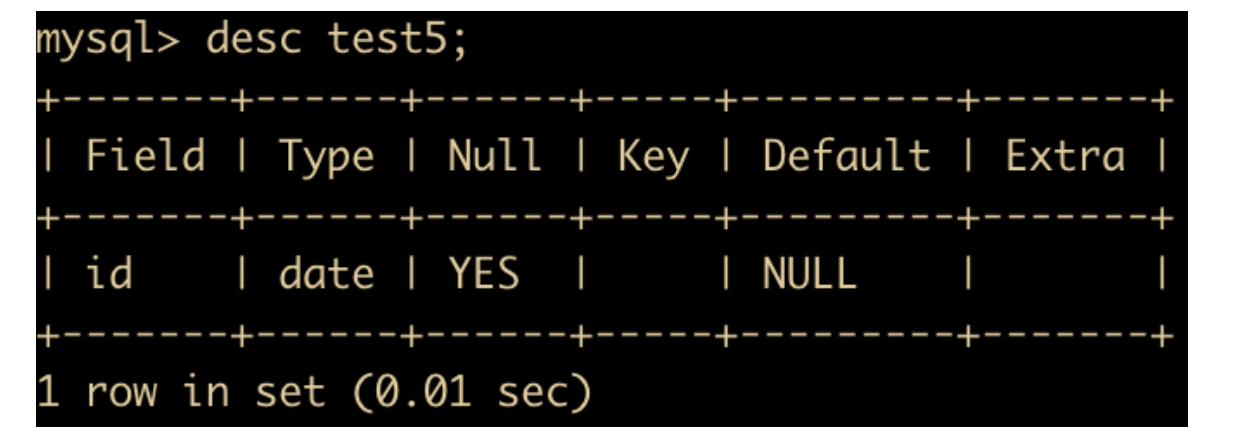
create table test5 (id date);
查看一下 test5 表
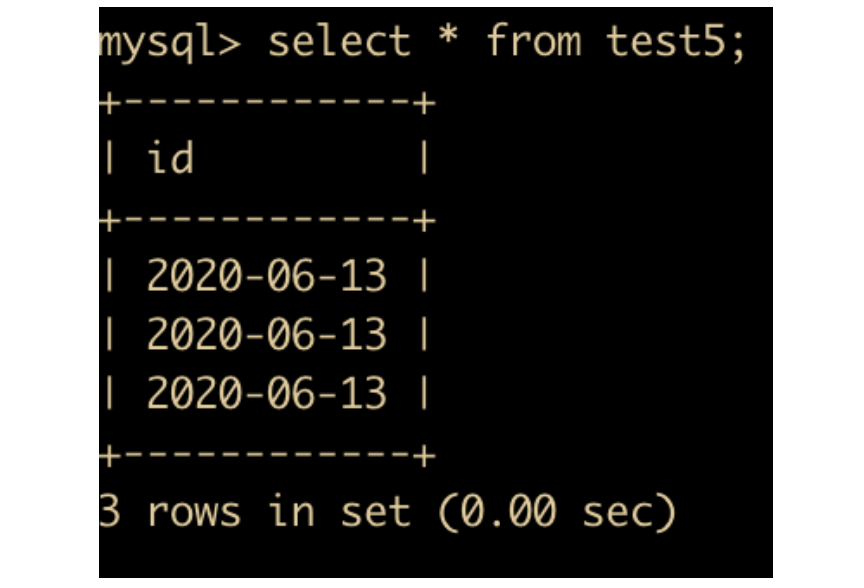
然后插入部分数据
insert into test5 values ('2020-06-13'),('20200613'),(20200613);
DATE 的表示一般很多种,如下所示 DATE 的所有形式
- ‘YYYY-MM-DD’
- ‘YYYYMMDD’
- YYYYMMDD
- ‘YY-MM-DD’
- ‘YYMMDD’
- YYMMDD
DATETIME
DATETIME 类型,包含日期和时间部分,可以使用引用字符串或者数字,年份可以是 4 位也可以是 2 位。
下面是 DATETIME 的示例
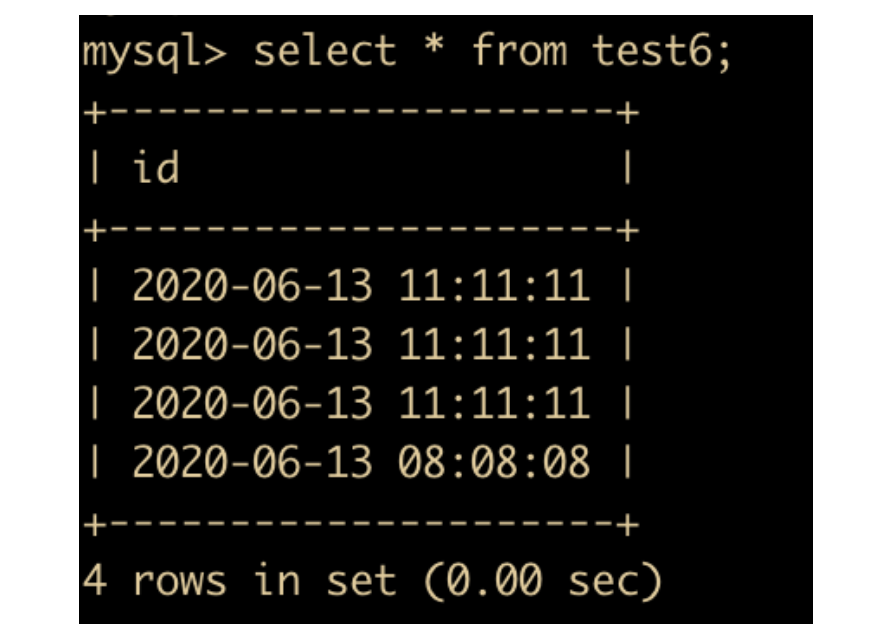
create table test6 (id datetime);
insert into test4 values ('2020-06-13 11:11:11'),(20200613111111),('20200613111111'),(20200613080808);
TIMESTAMP
TIMESTAMP 类型和 DATETIME 类型的格式相同,存储 4 个字节(比DATETIME少),取值范围比 DATETIME 小。
下面来说一下各个时间类型的使用场景
一般表示
年月日,通常用DATE类型;用来表示
时分秒,通常用TIME表示;年月日时分秒,通常用DATETIME来表示;如果需要插入的是当前时间,通常使用
TIMESTAMP来表示,TIMESTAMP 值返回后显示为YYYY-MM-DD HH:MM:SS格式的字符串,如果只表示年份、则应该使用 YEAR,它比 DATE 类型需要更小的空间。
每种日期类型都有一个范围,如果超出这个范围,在默认的 SQLMode 下,系统会提示错误,并进行零值存储。
下面来解释一下 SQLMode 是什么
MySQL 中有一个环境变量是 sql_mode ,sql_mode 支持了 MySQL 的语法、数据校验,我们可以通过下面这种方式来查看当前数据库使用的 sql_mode
select @@sql_mode;
一共有下面这几种模式

来源于 https://www.cnblogs.com/Zender/p/8270833.html
字符串类型
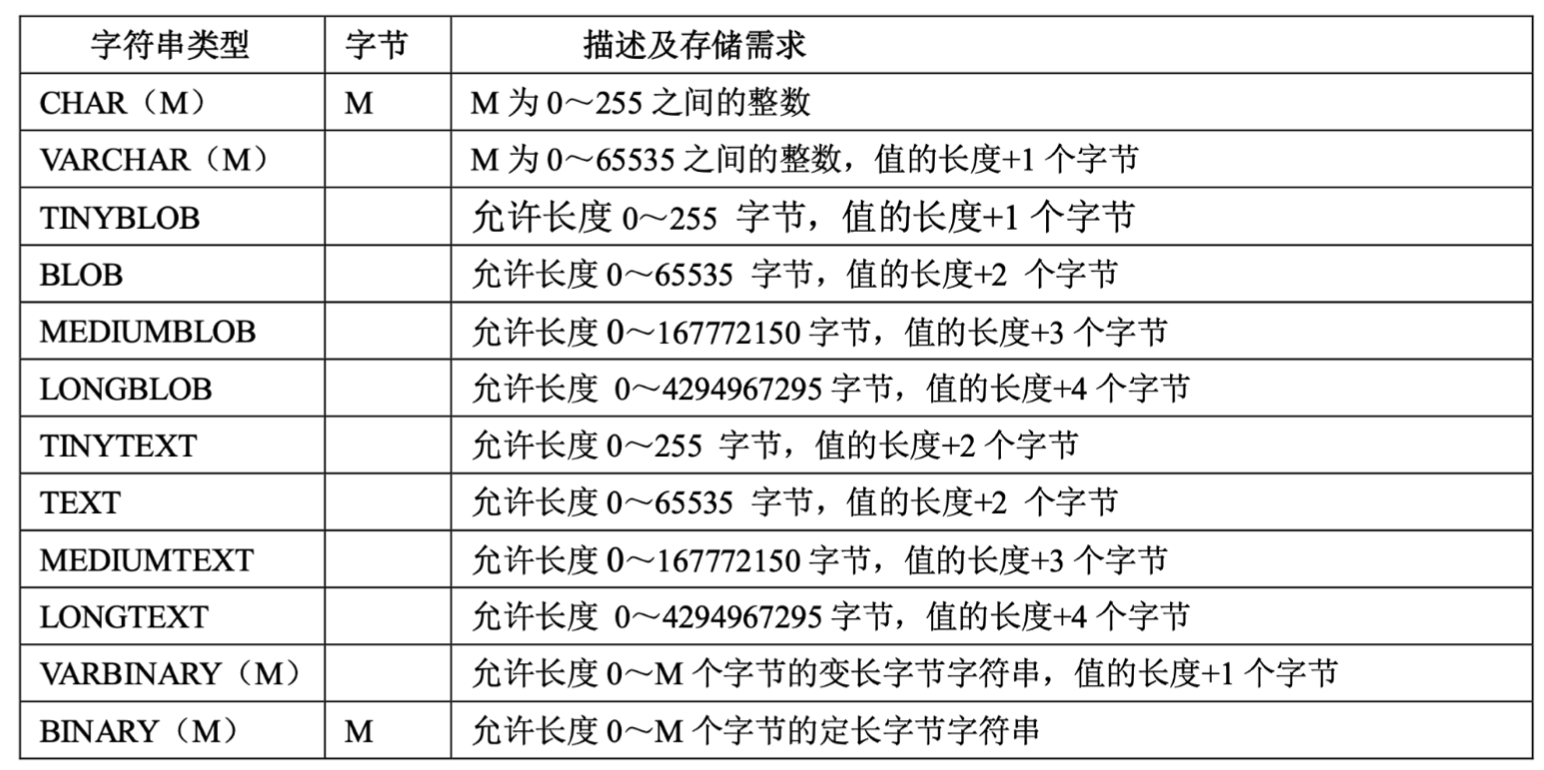
MySQL 提供了很多种字符串类型,下面是字符串类型的汇总
下面我们对这些数据类型做一个详细的介绍
CHAR 和 VARCHAR 类型
CHAR 和 VARCHAR 类型很相似,导致很多同学都会忽略他们之间的差别,首先他俩都是用来保存字符串的数据类型,他俩的主要区别在于存储方式不同。CHAR 类型的长度就是你定义多少显示多少。占用 M 字节,比如你声明一个 CHAR(20) 的字符串类型,那么每个字符串占用 20 字节,M 的取值范围时 0 – 255。VARCHAR 是可变长的字符串,范围是 0 – 65535,在字符串检索的时候,CHAR 会去掉尾部的空格,而 VARCHAR 会保留这些空格。下面是演示例子
create table vctest1 (vc varchar(6),ch char(6));
insert into vctest1 values("abc ","abc ");
select length(vc),length(ch) from vctest1;
结果如下
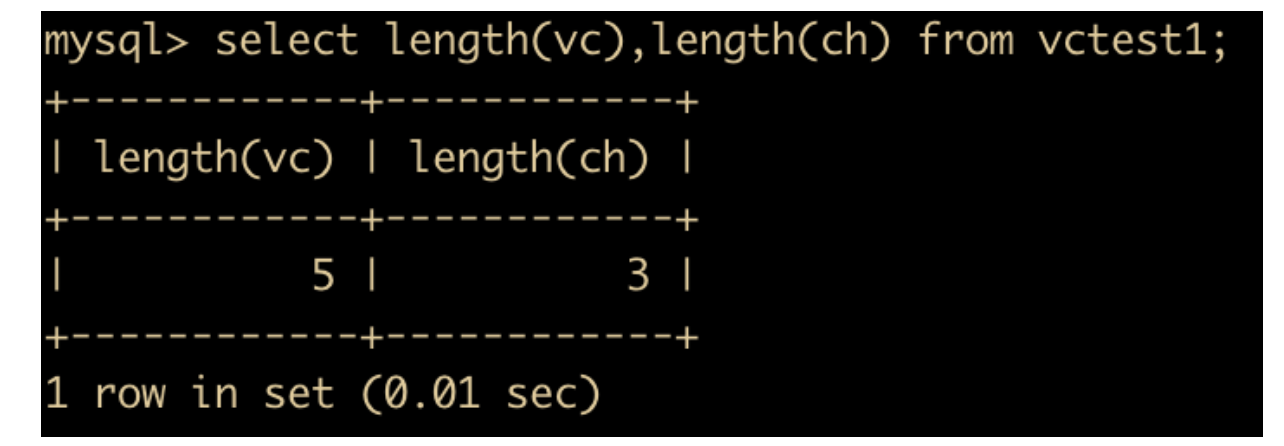
可以看到 vc 的字符串类型是 varchar ,长度是 5,ch 的字符串类型是 char,长度是 3。可以得出结论,varchar 会保留最后的空格,char 会去掉最后的空格。
BINARY 和 VARBINARY 类型
BINARY 和 VARBINARY 与 CHAR 和 VARCHAR 非常类似,不同的是它们包含二进制字符串而不包含非二进制字符串。BINARY 与 VARBINARY 的最大长度和 CHAR 与 VARCHAR 是一样的,只不过他们是定义字节长度,而 CHAR 和 VARCHAR 对应的是字符长度。
BLOB 类型
BLOB 是一个二进制大对象,可以容纳可变数量的数据。有 4 种 BLOB 类型:TINYBLOB、BLOB、MEDIUMBLOB 和 LONGBLOB。它们区别在于可容纳存储范围不同。
TEXT 类型
有 4 种 TEXT 类型:TINYTEXT、TEXT、MEDIUMTEXT 和 LONGTEXT。对应的这 4 种 BLOB 类型,可存储的最大长度不同,可根据实际情况选择。
ENUM 类型
ENUM 我们在 Java 中经常会用到,它表示的是枚举类型。它的范围需要在创建表时显示指定,对 1 – 255 的枚举需要 1 个字节存储;对于 255 – 65535 的枚举需要 2 个字节存储。ENUM 会忽略大小写,在存储时都会转换为大写。
SET 类型
SET 类型和 ENUM 类型有两处不同
- 存储方式
SET 对于每 0 – 8 个成员,分别占用 1 个字节,最大到 64 ,占用 8 个字节
- Set 和 ENUM 除了存储之外,最主要的区别在于 Set 类型一次可以选取多个成员,而 ENUM 则只能选一个。
MySQL 运算符
MySQL 中有多种运算符,下面对 MySQL 运算符进行分类
- 算术运算符
- 比较运算符
- 逻辑运算符
- 位运算符
下面那我们对各个运算符进行介绍
算术运算符
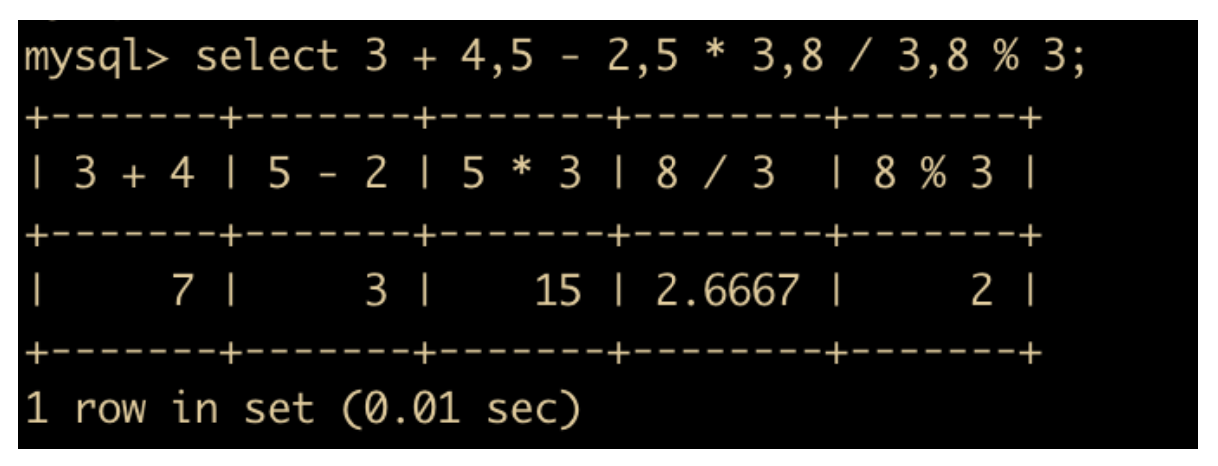
MySQL 支持的算术运算符包括加、减、乘、除和取余,这类运算符的使用频率比较高
下面是运算符的分类
| 运算符 | 作用 |
|---|---|
| + | 加法 |
| – | 减法 |
| x | 乘法 |
| /, DIV | 除法,返回商 |
| %, MOD | 除法,返回余数 |
下面简单描述了这些运算符的使用方法
+用于获得一个或多个值的和-用于从一个值减去另一个值x用于两数相乘,得到两个或多个值的乘积/用一个值除以另一个值得到商%用于一个值除以另一个值得到余数
在除法和取余需要注意一点,如果除数是 0 ,将是非法除数,返回结果为 NULL。
比较运算符
熟悉了运算符,下面来聊一聊比较运算符,使用 SELECT 语句进行查询时,MySQL 允许用户对表达式的两侧的操作数进行比较,比较结果为真,返回 1, 比较结果为假,返回 0 ,比较结果不确定返回 NULL。下面是所有的比较运算符
| 运算符 | 描述 |
|---|---|
| = | 等于 |
| <> 或者是 != | 不等于 |
| <=> | NULL 安全的等于,也就是 NULL-safe |
| < | 小于 |
| <= | 小于等于 |
| > | 大于 |
| >= | 大于等于 |
| BETWEEN | 在指定范围内 |
| IS NULL | 是否为 NULL |
| IS NOT NULL | 是否为 NULL |
| IN | 存在于指定集合 |
| LIKE | 通配符匹配 |
| REGEXP 或 RLIKE | 正则表达式匹配 |
比较运算符可以用来比较数字、字符串或者表达式。数字作为浮点数进行比较,字符串以不区分大小写的方式进行比较。
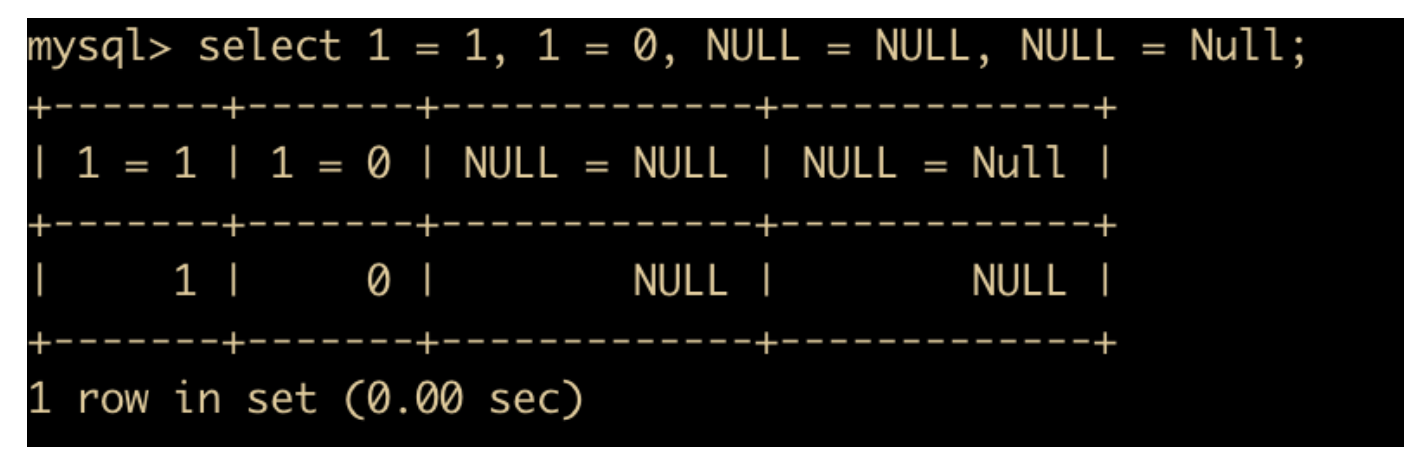
- = 号运算符,用于比较运算符两侧的操作数是否相等,如果相等则返回 1, 如果不相等则返回 0 ,下面是具体的示例,NULL 不能用于比较,会直接返回 NULL
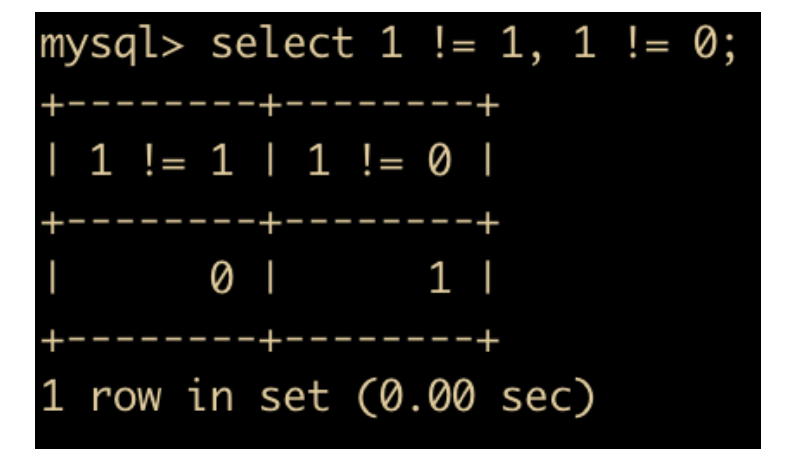
<>号用于表示不等于,和=号相反,示例如下
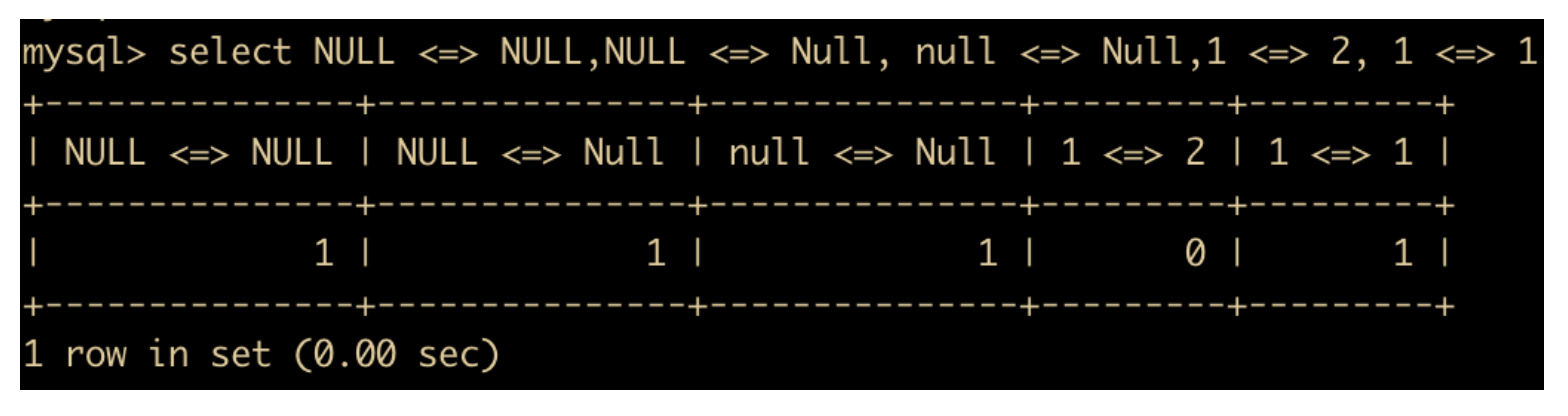
<=>NULL-safe 的等于运算符,与 = 号最大的区别在于可以比较 NULL 值
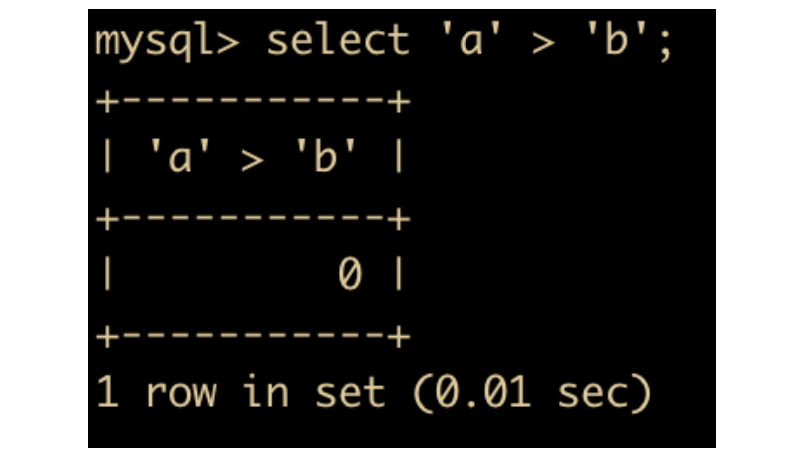
<号运算符,当左侧操作数小于右侧操作数时,返回值为 1, 否则其返回值为 0。
- 和上面同理,只不过是满足 <= 的时候返回 1 ,否则 > 返回 0。这里我有个疑问,为什么
select 'a' <= 'b'; /* 返回 1 */
/而/
select 'a' >= 'b'; /* 返回 0 呢*/
关于
>和>=是同理BETWEEN运算符的使用格式是 a BETWEEN min AND max ,当 a 大于等于 min 并且小于等于 max 时,返回 1,否则返回 0 。操作数类型不同的时候,会转换成相同的数据类型再进行处理。比如

IS NULL和IS NOT NULL表示的是是否为 NULL,ISNULL 为 true 返回 1,否则返回 0 ;IS NOT NULL 同理
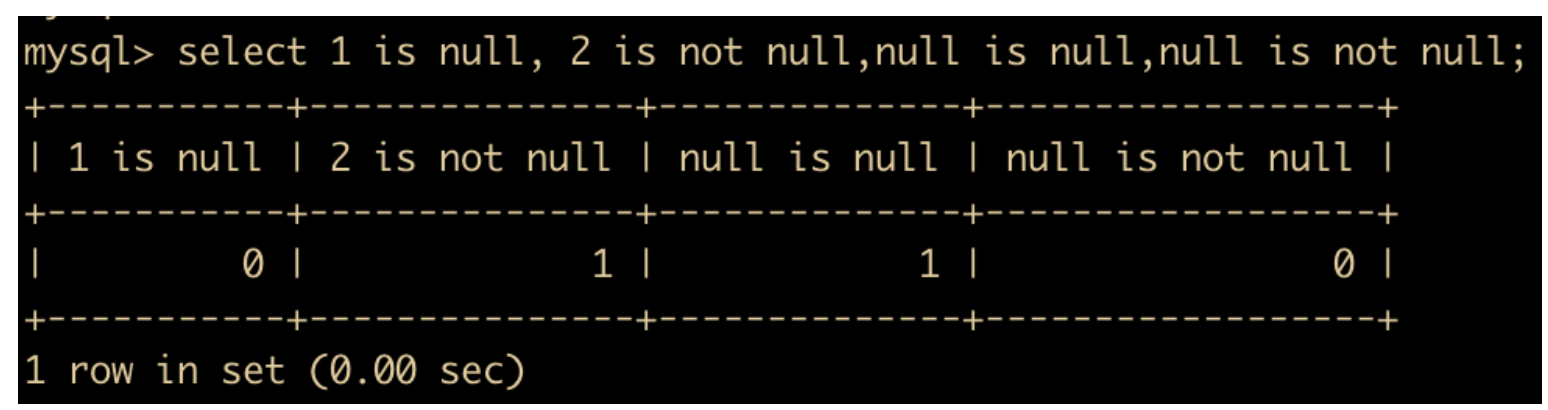
IN这个比较操作符判断某个值是否在一个集合中,使用方式是 xxx in (value1,value2,value3)

LIKE运算符的格式是xxx LIKE %123%,比如如下
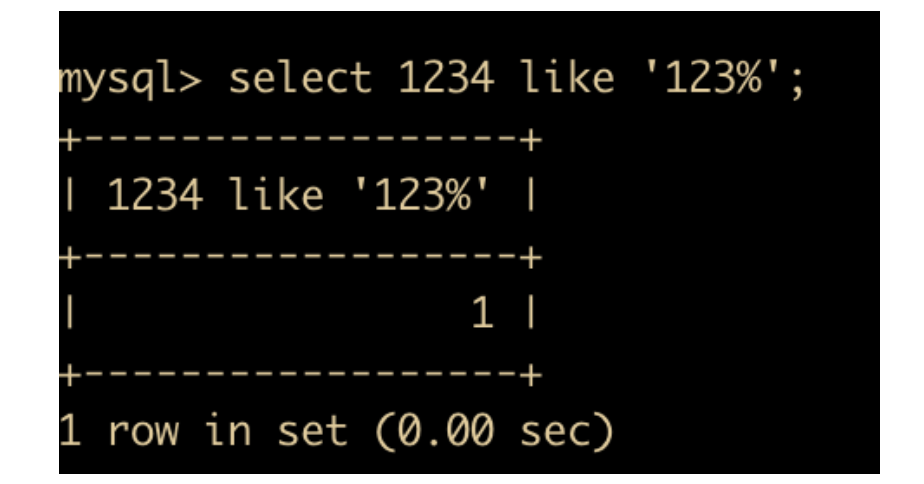
当 like 后面跟的是 123% 的时候, xxx 如果是 123 则返回 1,如果是 123xxx 也返回 1,如果是 12 或者 1 就返回 0 。123 是一个整体。

REGEX运算符的格式是s REGEXP str,匹配时返回值为 1,否则返回 0 。
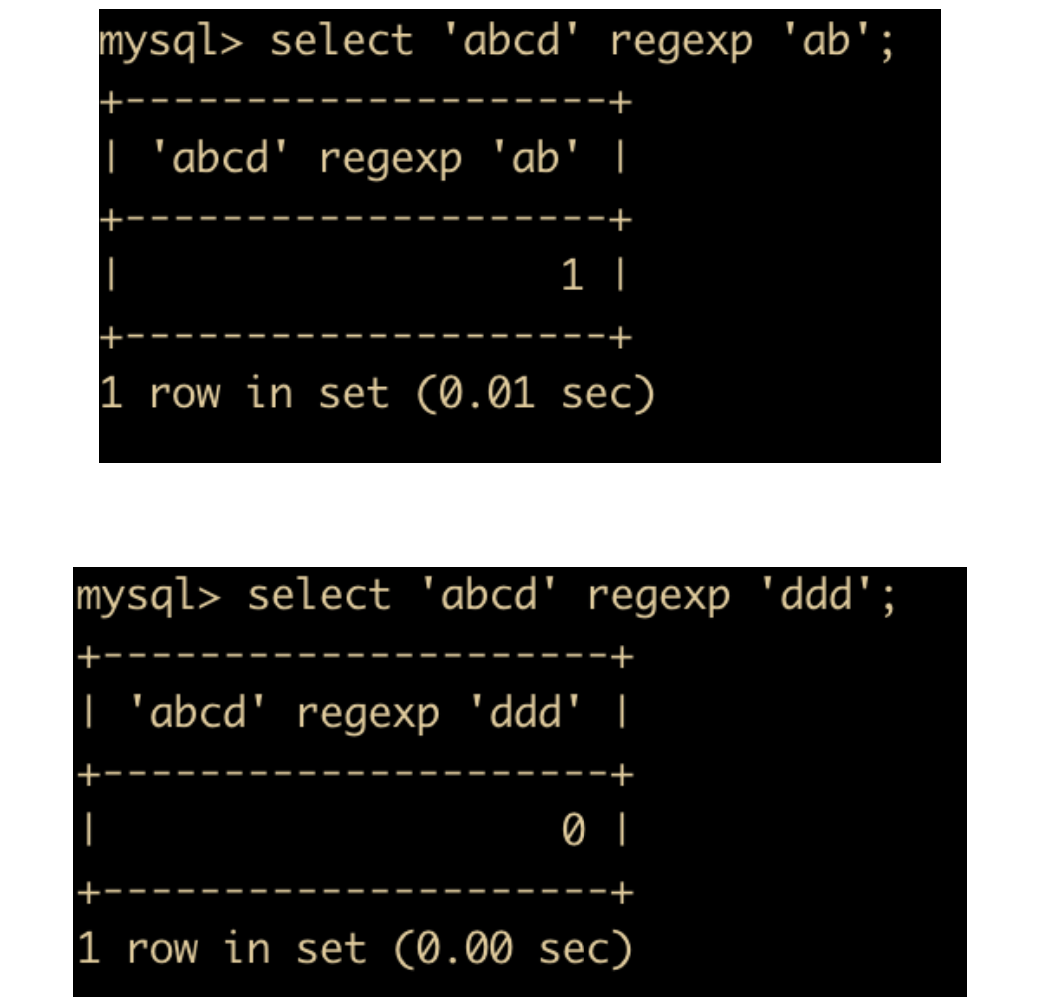
后面会详细介绍 regexp 的用法。
逻辑运算符
逻辑运算符指的就是布尔运算符,布尔运算符指返回真和假。MySQL 支持四种逻辑运算符
| 运算符 | 作用 |
|---|---|
| NOT 或 ! | 逻辑非 |
| AND 或者是 && | 逻辑与 |
| OR 或者是 || | 逻辑或 |
| XOR | 逻辑异或 |
下面分别来介绍一下
NOT或者是!表示的是逻辑非,当操作数为 0(假) ,则返回值为 1,否则值为 0。但是有一点除外,那就是 NOT NULL 的返回值为 NULL

AND和&&表示的是逻辑与的逻辑,当所有操作数为非零值并且不为 NULL 时,结果为 1,但凡是有一个 0 则返回 0,操作数中有一个 null 则返回 null
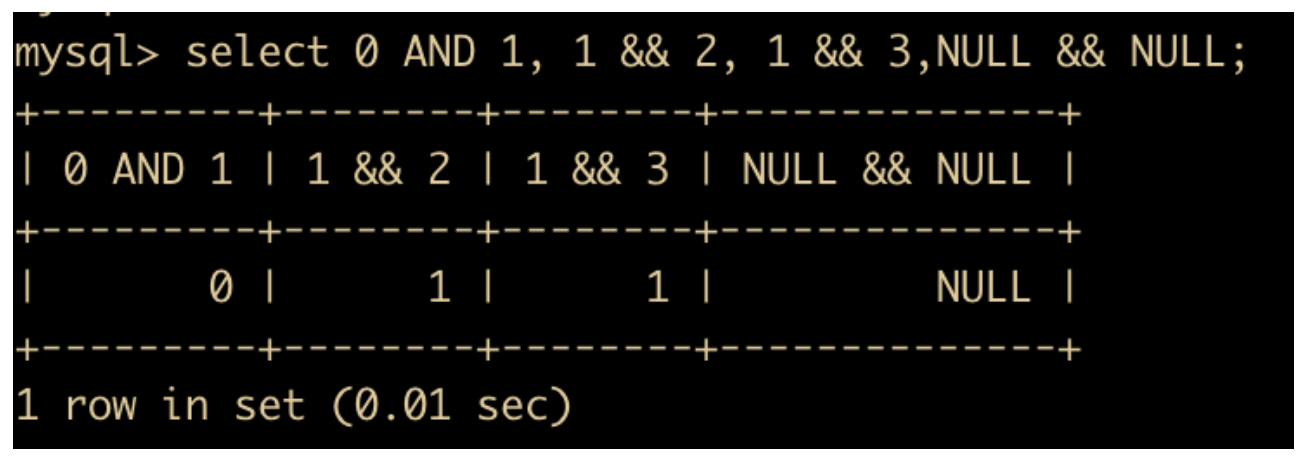
OR和||表示的是逻辑或,当两个操作数均为非 NULL 值时,如有任意一个操作数为非零值,则结果为 1,否则结果为 0。

XOR表示逻辑异或,当任意一个操作数为 NULL 时,返回值为 NULL。对于非 NULL 的操作数,如果两个的逻辑真假值相异,则返回结果 1;否则返回 0。
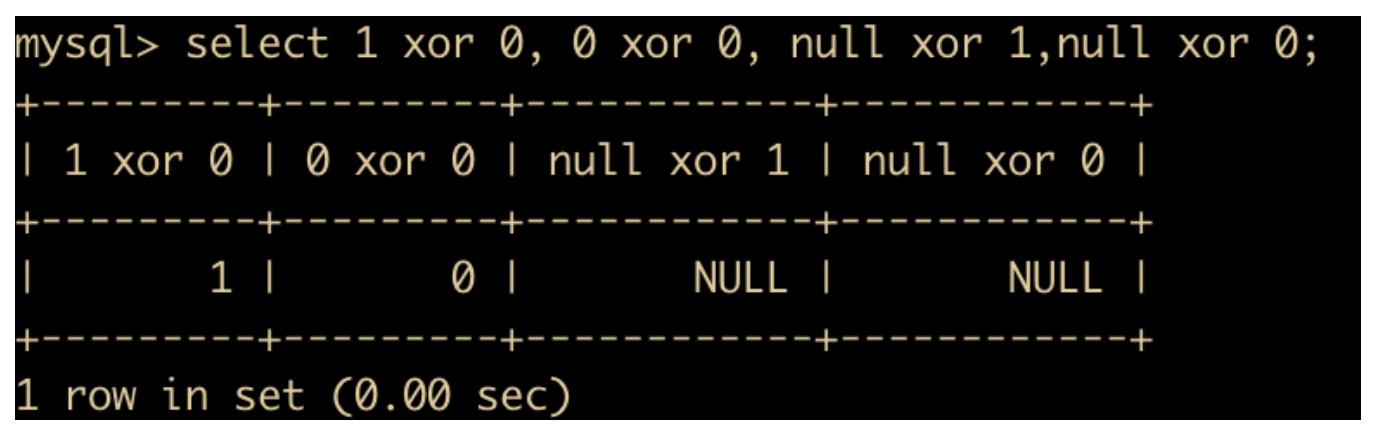
位运算符
一听说位运算,就知道是和二进制有关的运算符了,位运算就是将给定的操作数转换为二进制后,对各个操作数的每一位都进行指定的逻辑运算,得到的二进制结果转换为十进制后就说是位运算的结果,下面是所有的位运算。
| 运算符 | 作用 |
|---|---|
| & | 位与 |
| | | 位或 |
| ^ | 位异或 |
| ~ | 位取反 |
| >> | 位右移 |
| << | 位左移 |
下面分别来演示一下这些例子
位与指的就是按位与,把 & 双方转换为二进制再进行 & 操作

按位与是一个数值减小的操作
位或指的就是按位或,把 | 双方转换为二进制再进行 | 操作
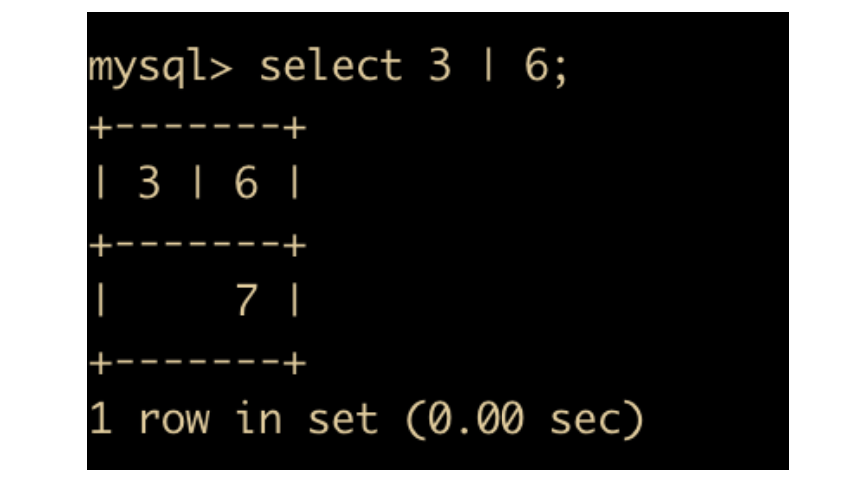
位或是一个数值增大的操作
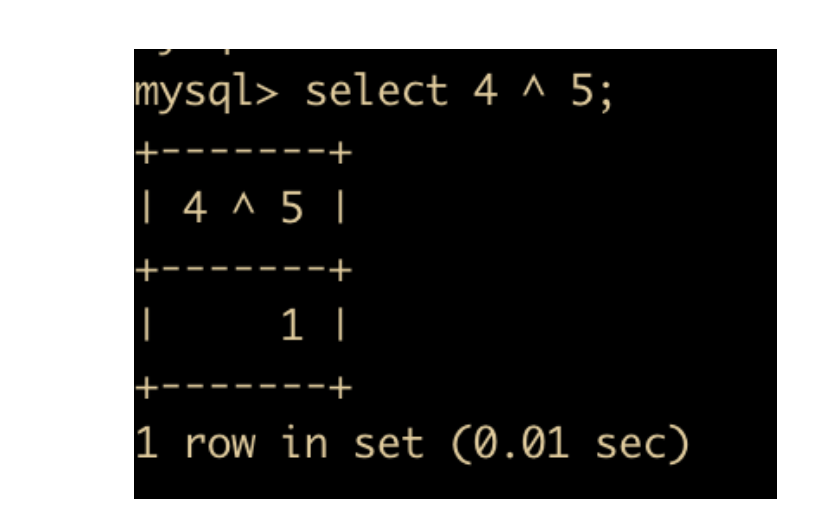
位异或指的就是对操作数的二进制位做异或操作
位取反指的就是对操作数的二进制位做NOT操作,这里的操作数只能是一位,下面看一个经典的取反例子:对 1 做位取反,具体如下所示:
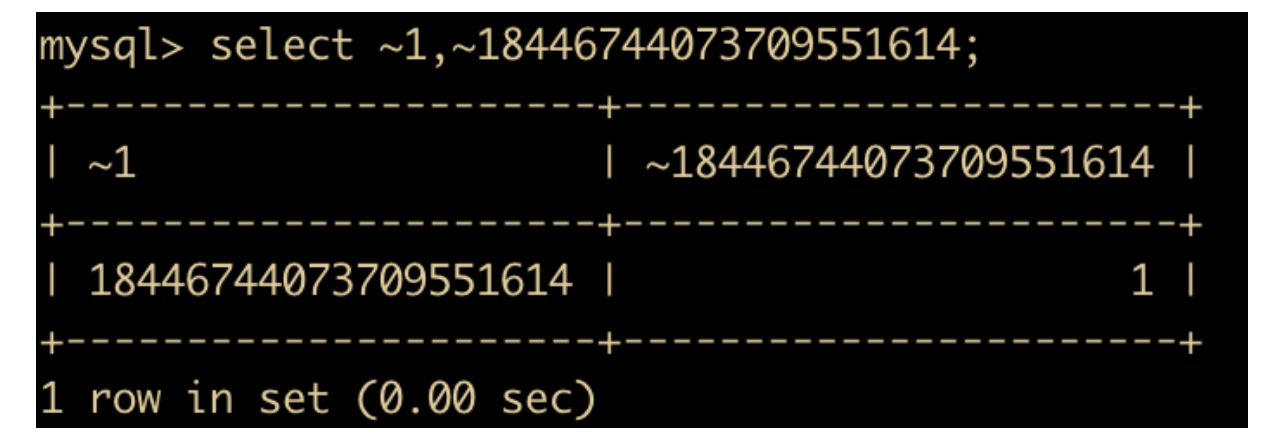
为什么会有这种现象,因为在 MySQL 中,常量数字默认会以 8 个字节来显示,8 个字节就是 64 位,常量 1 的二进制表示 63 个 0,加 1 个 1 , 位取反后就是 63 个 1 加一个 0 , 转换为二进制后就是 18446744073709551614,我们可以使用 select bin() 查看一下
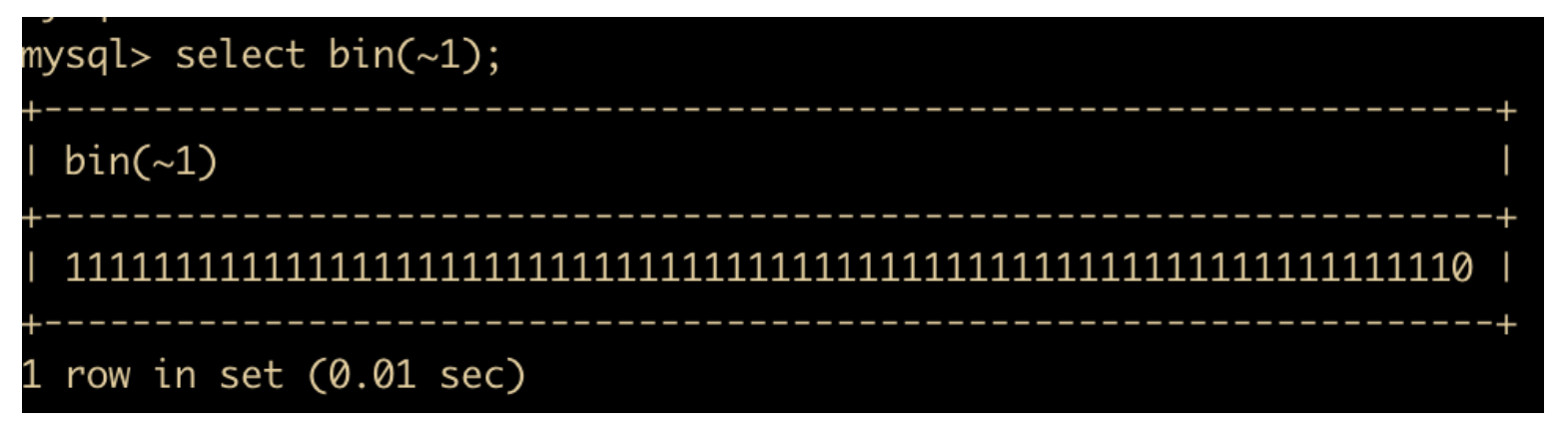
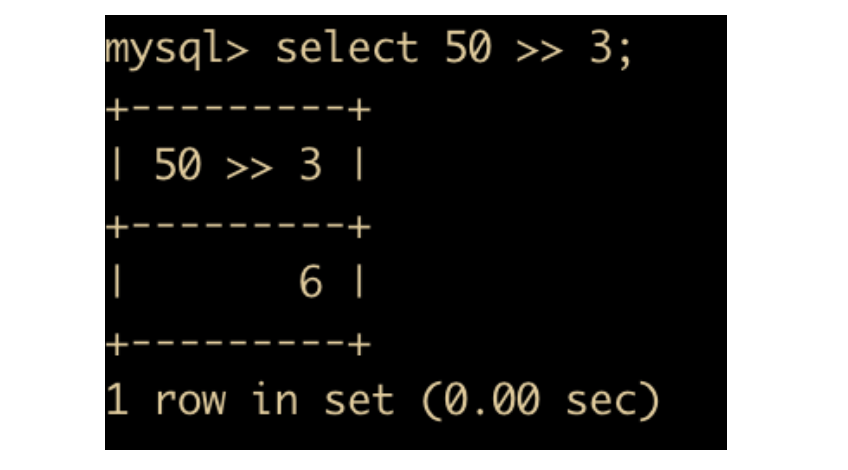
位右移是对左操作数向右移动指定位数,例如 50 >> 3,就是对 50 取其二进制然后向右移三位,左边补上 0 ,转换结果如下
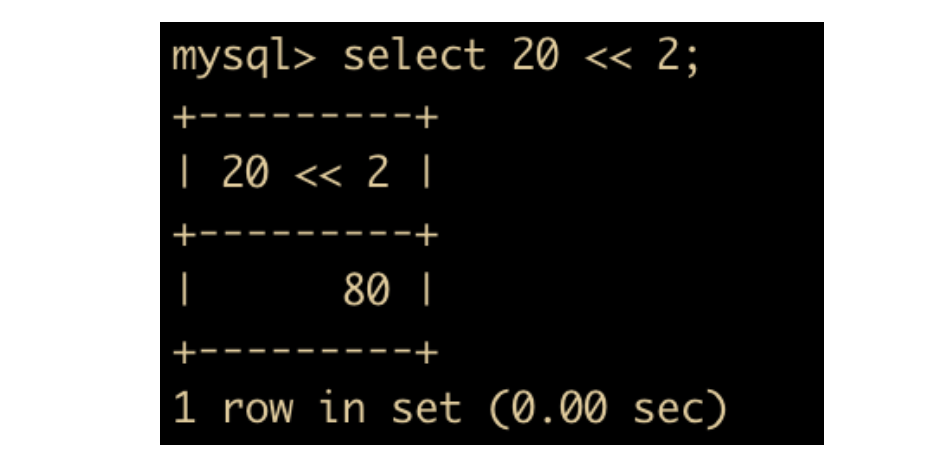
位左移与位右移相反,是对左操作数向左移动指定位数,例如 20 << 2
MySQL 常用函数
下面我们来了解一下 MySQL 函数,MySQL 函数也是我们日常开发过程中经常使用的,选用合适的函数能够提高我们的开发效率,下面我们就来一起认识一下这些函数
字符串函数
字符串函数是最常用的一种函数了,MySQL 也是支持很多种字符串函数,下面是 MySQL 支持的字符串函数表
| 函数 | 功能 |
|---|---|
| LOWER | 将字符串所有字符变为小写 |
| UPPER | 将字符串所有字符变为大写 |
| CONCAT | 进行字符串拼接 |
| LEFT | 返回字符串最左边的字符 |
| RIGHT | 返回字符串最右边的字符 |
| INSERT | 字符串替换 |
| LTRIM | 去掉字符串左边的空格 |
| RTRIM | 去掉字符串右边的空格 |
| REPEAT | 返回重复的结果 |
| TRIM | 去掉字符串行尾和行头的空格 |
| SUBSTRING | 返回指定的字符串 |
| LPAD | 用字符串对最左边进行填充 |
| RPAD | 用字符串对最右边进行填充 |
| STRCMP | 比较字符串 s1 和 s2 |
| REPLACE | 进行字符串替换 |
下面通过具体的示例演示一下每个函数的用法
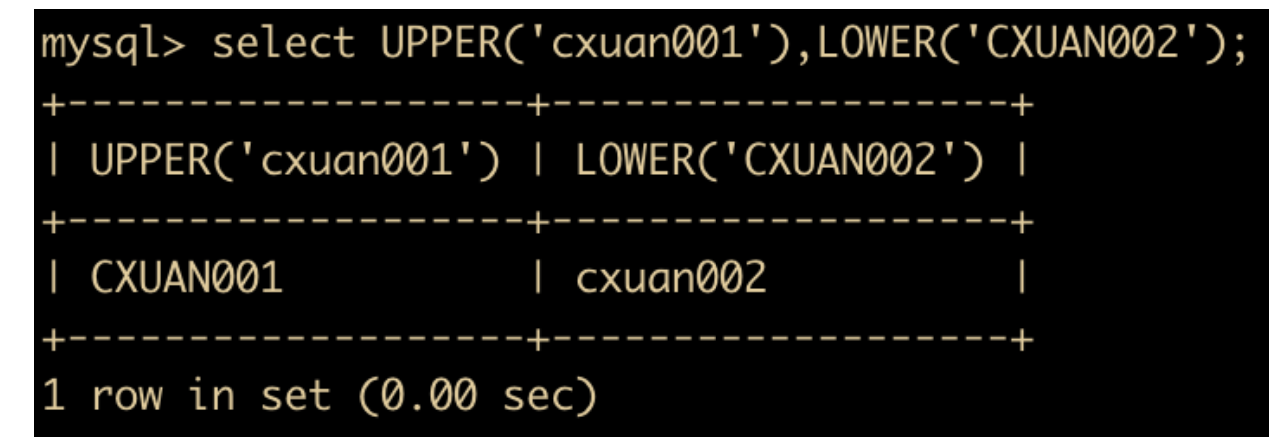
- LOWER(str) 和 UPPER(str) 函数:用于转换大小写
- CONCAT(s1,s2 … sn) :把传入的参数拼接成一个字符串
上面把 c xu an 拼接成为了一个字符串,另外需要注意一点,任何和 NULL 进行字符串拼接的结果都是 NULL。
- LEFT(str,x) 和 RIGHT(str,x) 函数:分别返回字符串最左边的 x 个字符和最右边的 x 个字符。如果第二个参数是 NULL,那么将不会返回任何字符串

- INSERT(str,x,y,instr) : 将字符串 str 从指定 x 的位置开始, 取 y 个长度的字串替换为 instr。
- LTRIM(str) 和 RTRIM(str) 分别表示去掉字符串 str 左侧和右侧的空格

- REPEAT(str,x) 函数:返回 str 重复 x 次的结果
- TRIM(str) 函数:用于去掉目标字符串的空格
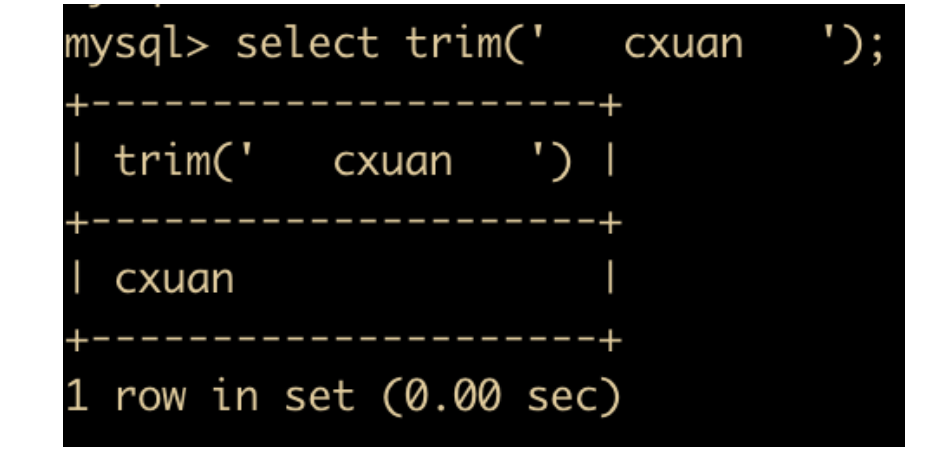
- SUBSTRING(str,x,y) 函数:返回从字符串 str 中第 x 位置起 y 个字符长度的字符串

- LPAD(str,n,pad) 和 RPAD(str,n,pad) 函数:用字符串 pad 对 str 左边和右边进行填充,直到长度为 n 个字符长度

- STRCMP(s1,s2) 用于比较字符串 s1 和 s2 的 ASCII 值大小。如果 s1 < s2,则返回 -1;如果 s1 = s2 ,返回 0 ;如果 s1 > s2 ,返回 1。

- REPLACE(str,a,b) : 用字符串 b 替换字符串 str 种所有出现的字符串 a

数值函数
MySQL 支持数值函数,这些函数能够处理很多数值运算。下面我们一起来学习一下 MySQL 中的数值函数,下面是所有的数值函数
| 函数 | 功能 |
|---|---|
| ABS | 返回绝对值 |
| CEIL | 返回大于某个值的最大整数值 |
| MOD | 返回模 |
| ROUND | 四舍五入 |
| FLOOR | 返回小于某个值的最大整数值 |
| TRUNCATE | 返回数字截断小数的结果 |
| RAND | 返回 0 – 1 的随机值 |
下面我们还是以实践为主来聊一聊这些用法
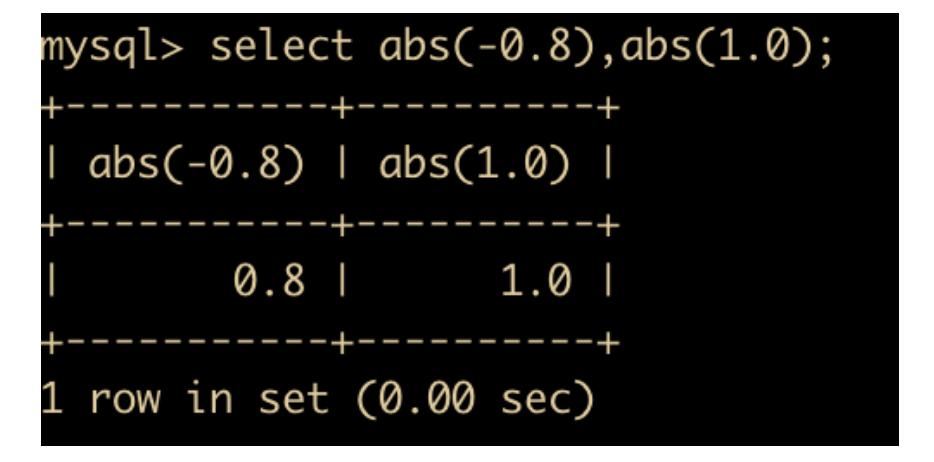
- ABS(x) 函数:返回 x 的绝对值
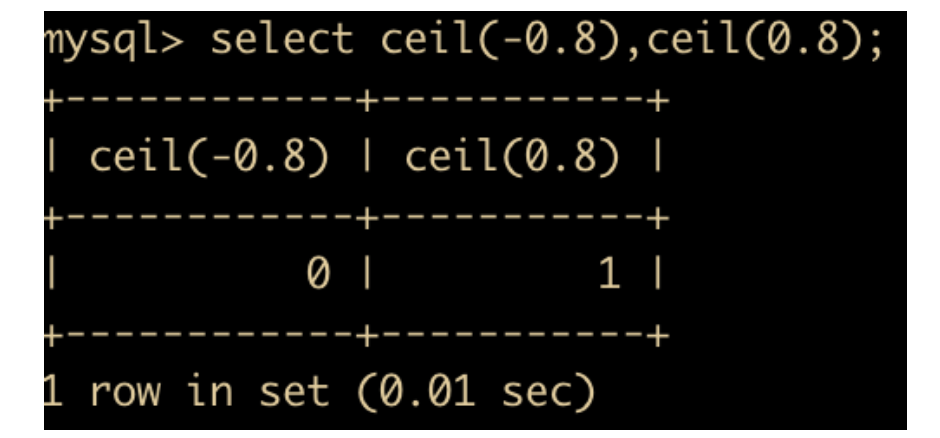
- CEIL(x) 函数: 返回大于 x 的整数
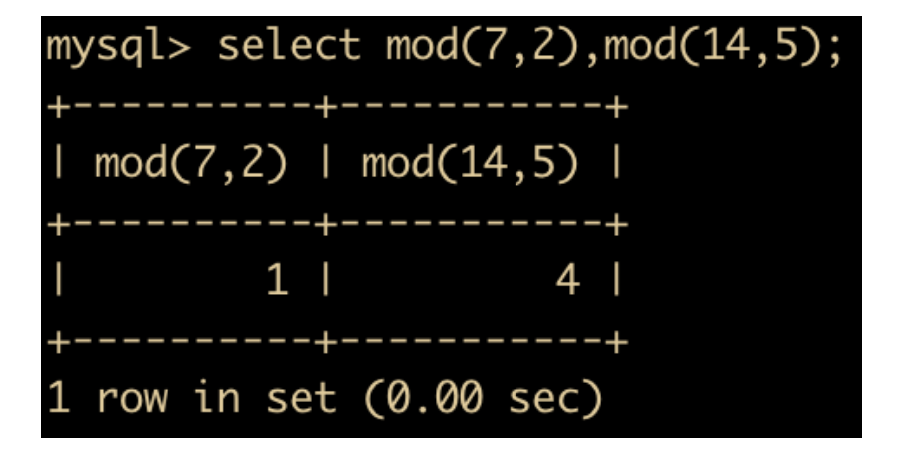
- MOD(x,y),对 x 和 y 进行取模操作
- ROUND(x,y) 返回 x 四舍五入后保留 y 位小数的值;如果是整数,那么 y 位就是 0 ;如果不指定 y ,那么 y 默认也是 0 。
- FLOOR(x) : 返回小于 x 的最大整数,用法与 CEIL 相反

- TRUNCATE(x,y): 返回数字 x 截断为 y 位小数的结果, TRUNCATE 知识截断,并不是四舍五入。
- RAND() :返回 0 到 1 的随机值
日期和时间函数
日期和时间函数也是 MySQL 中非常重要的一部分,下面我们就来一起认识一下这些函数
| 函数 | 功能 |
|---|---|
| NOW | 返回当前的日期和时间 |
| WEEK | 返回一年中的第几周 |
| YEAR | 返回日期的年份 |
| HOUR | 返回小时值 |
| MINUTE | 返回分钟值 |
| MONTHNAME | 返回月份名 |
| CURDATE | 返回当前日期 |
| CURTIME | 返回当前时间 |
| UNIX_TIMESTAMP | 返回日期 UNIX 时间戳 |
| DATE_FORMAT | 返回按照字符串格式化的日期 |
| FROM_UNIXTIME | 返回 UNIX 时间戳的日期值 |
| DATE_ADD | 返回日期时间 + 上一个时间间隔 |
| DATEDIFF | 返回起始时间和结束时间之间的天数 |
下面结合示例来讲解一下每个函数的使用
- NOW(): 返回当前的日期和时间
- WEEK(DATE) 和 YEAR(DATE) :前者返回的是一年中的第几周,后者返回的是给定日期的哪一年
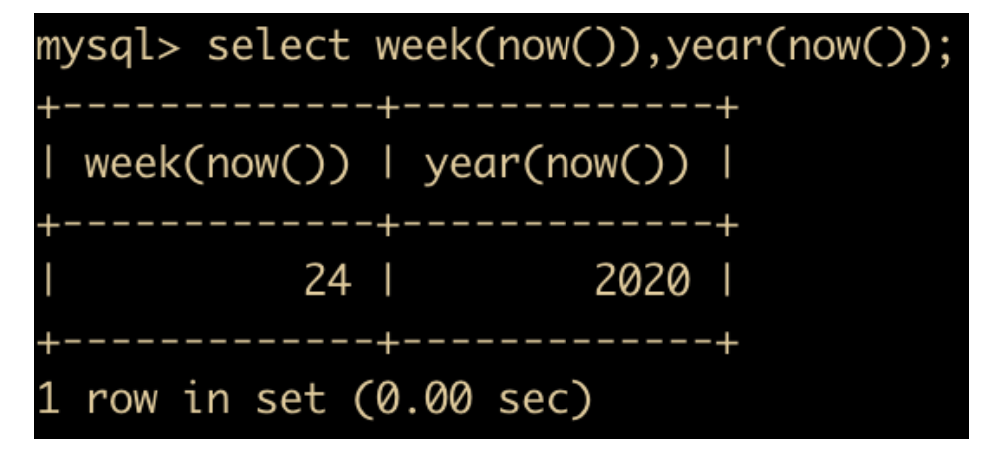
- HOUR(time) 和 MINUTE(time) : 返回给定时间的小时,后者返回给定时间的分钟
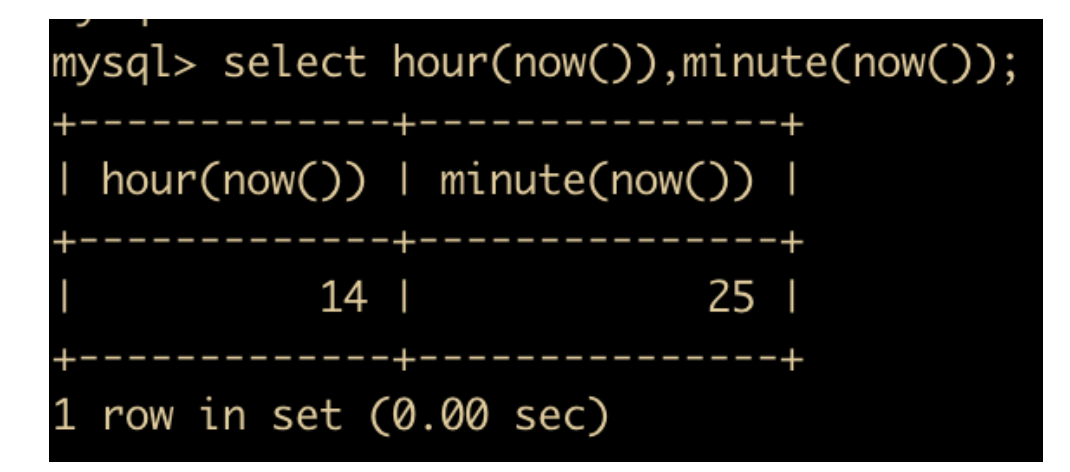
- MONTHNAME(date) 函数:返回 date 的英文月份
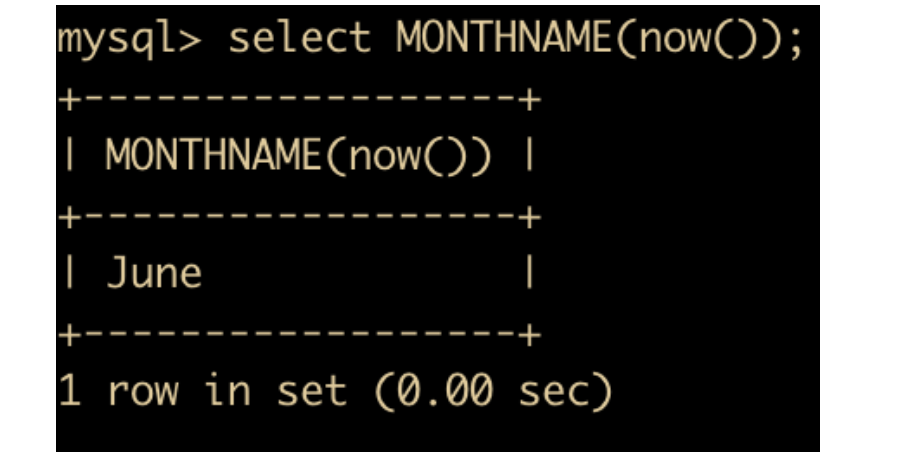
- CURDATE() 函数:返回当前日期,只包含年月日
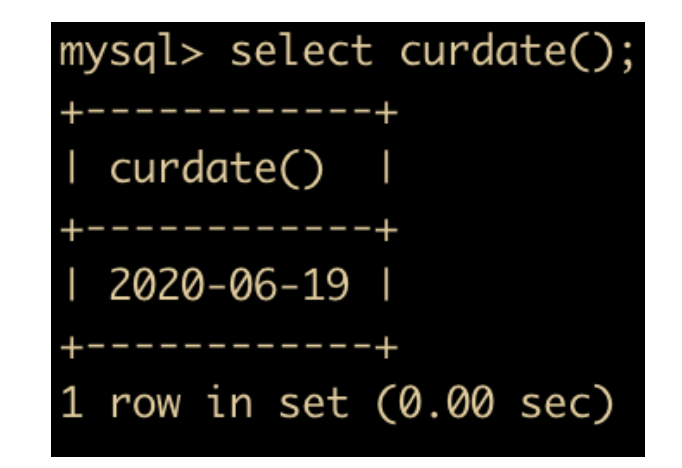
- CURTIME() 函数:返回当前时间,只包含时分秒
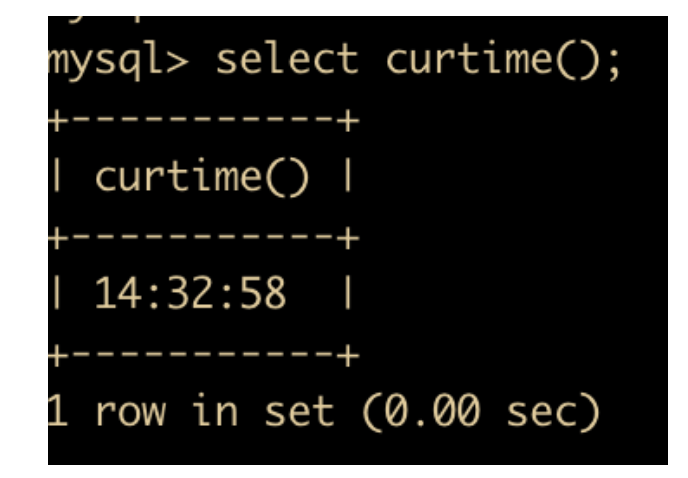
- UNIX_TIMESTAMP(date) : 返回 UNIX 的时间戳
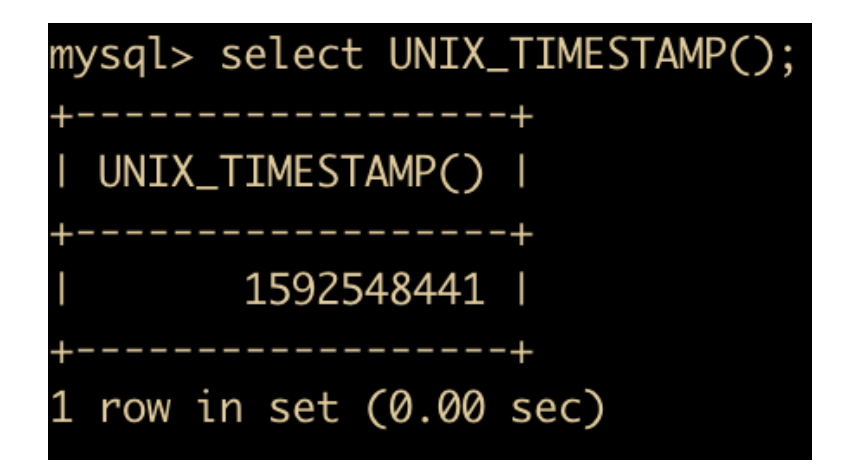
- FROM_UNIXTIME(date) : 返回 UNIXTIME 时间戳的日期值,和 UNIX_TIMESTAMP 相反

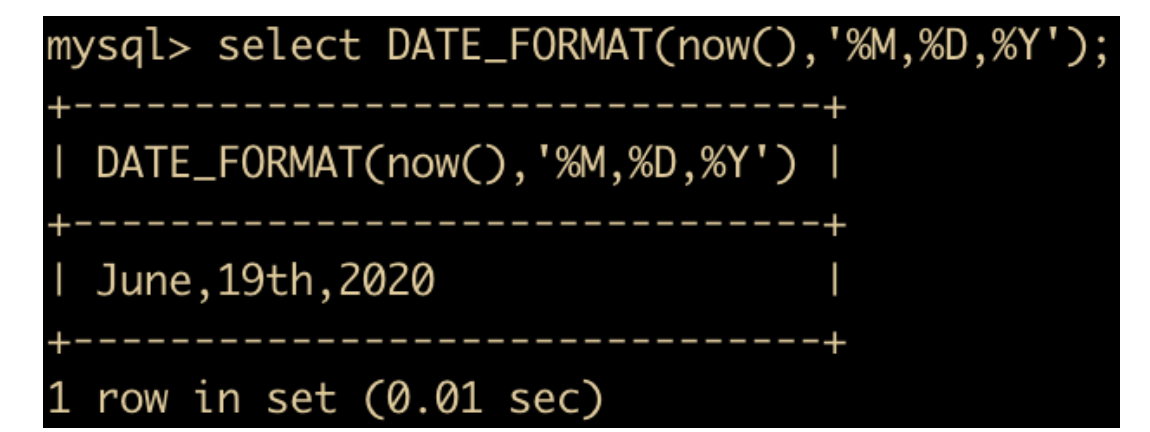
- DATE_FORMAT(date,fmt) 函数:按照字符串 fmt 对 date 进行格式化,格式化后按照指定日期格式显示
具体的日期格式可以参考这篇文章 https://blog.csdn.net/weixin_38703170/article/details/82177837
我们演示一下将当前日期显示为年月日的这种形式,使用的日期格式是 %M %D %Y。
- DATE_ADD(date, interval, expr type) 函数:返回与所给日期 date 相差 interval 时间段的日期
interval 表示间隔类型的关键字,expr 是表达式,这个表达式对应后面的类型,type 是间隔类型,MySQL 提供了 13 种时间间隔类型
| 表达式类型 | 描述 | 格式 |
|---|---|---|
| YEAR | 年 | YY |
| MONTH | 月 | MM |
| DAY | 日 | DD |
| HOUR | 小时 | hh |
| MINUTE | 分 | mm |
| SECOND | 秒 | ss |
| YEAR_MONTH | 年和月 | YY-MM |
| DAY_HOUR | 日和小时 | DD hh |
| DAY_MINUTE | 日和分钟 | DD hh : mm |
| DAY_SECOND | 日和秒 | DD hh :mm :ss |
| HOUR_MINUTE | 小时和分 | hh:mm |
| HOUR_SECOND | 小时和秒 | hh:ss |
| MINUTE_SECOND | 分钟和秒 | mm:ss |
- DATE_DIFF(date1, date2) 用来计算两个日期之间相差的天数
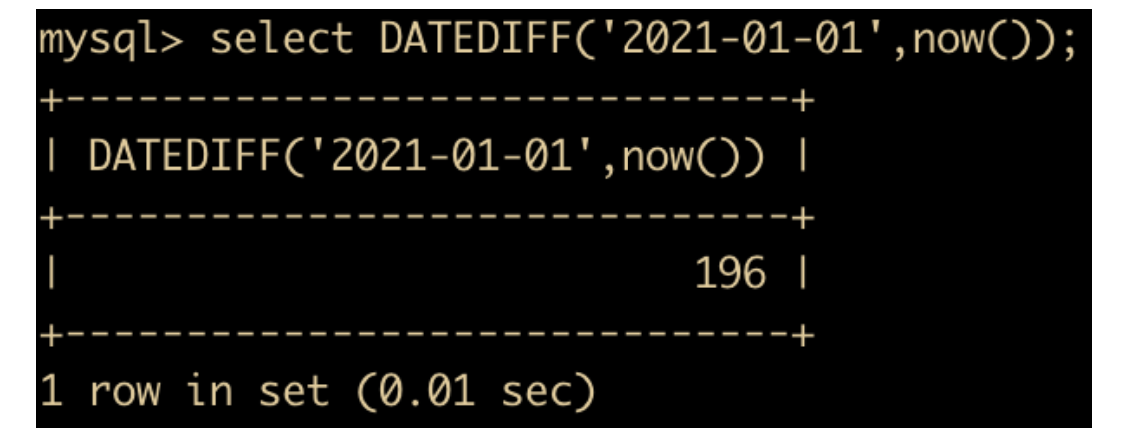
查看离 2021 – 01 – 01 还有多少天
流程函数
流程函数也是很常用的一类函数,用户可以使用这类函数在 SQL 中实现条件选择。这样做能够提高查询效率。下表列出了这些流程函数
| 函数 | 功能 |
|---|---|
| IF(value,t f) | 如果 value 是真,返回 t;否则返回 f |
| IFNULL(value1,value2) | 如果 value1 不为 NULL,返回 value1,否则返回 value2。 |
| CASE WHEN[value1] THEN[result1] …ELSE[default] END | 如果 value1 是真,返回 result1,否则返回 default |
| CASE[expr] WHEN[value1] THEN [result1]… ELSE[default] END | 如果 expr 等于 value1, 返回 result1, 否则返回 default |
其他函数
除了我们介绍过的字符串函数、日期和时间函数、流程函数,还有一些函数并不属于上面三类函数,它们是
| 函数 | 功能 |
|---|---|
| VERSION | 返回当前数据库的版本 |
| DATABASE | 返回当前数据库名 |
| USER | 返回当前登陆用户名 |
| PASSWORD | 返回字符串的加密版本 |
| MD5 | 返回 MD5 值 |
| INET_ATON(IP) | 返回 IP 地址的数字表示 |
| INET_NTOA(num) | 返回数字代表的 IP 地址 |
下面来看一下具体的使用
- VERSION: 返回当前数据库版本
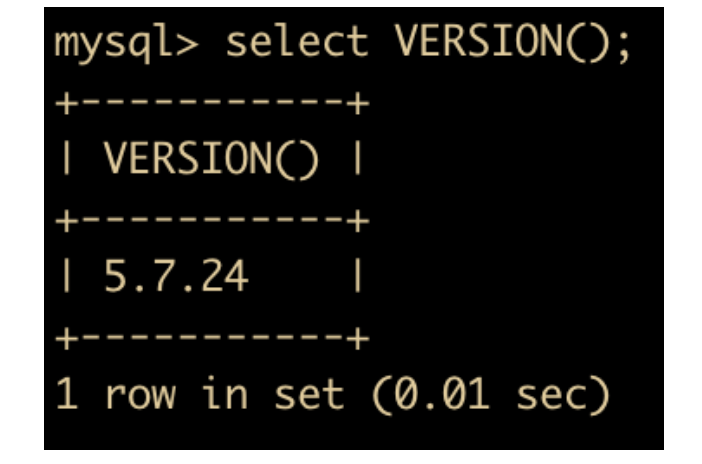
- DATABASE: 返回当前的数据库名
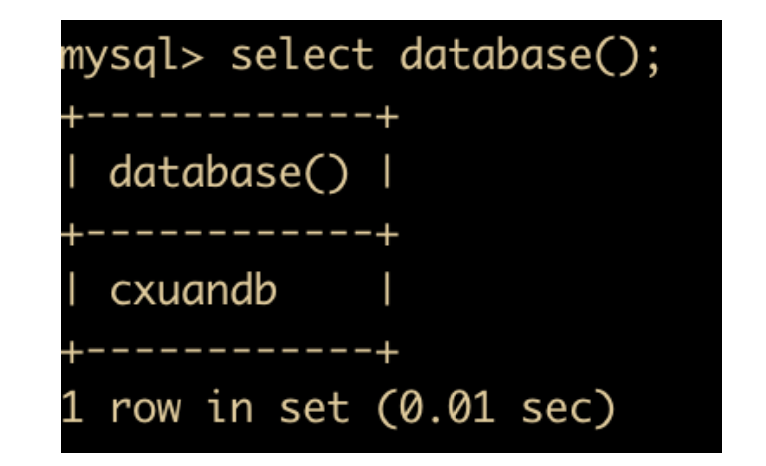
- USER : 返回当前登录用户名
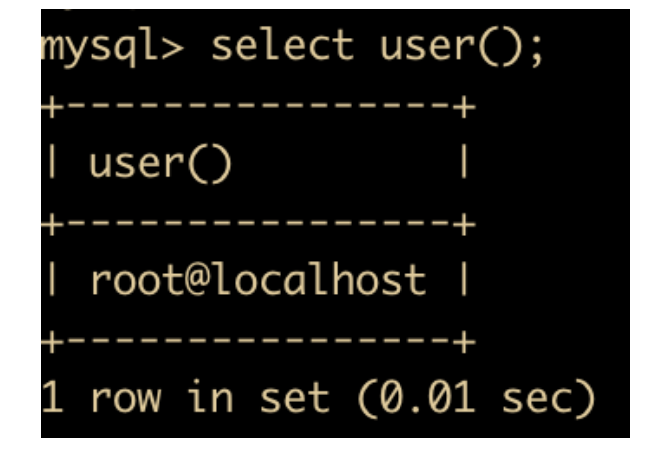
- PASSWORD(str) : 返回字符串的加密版本,例如
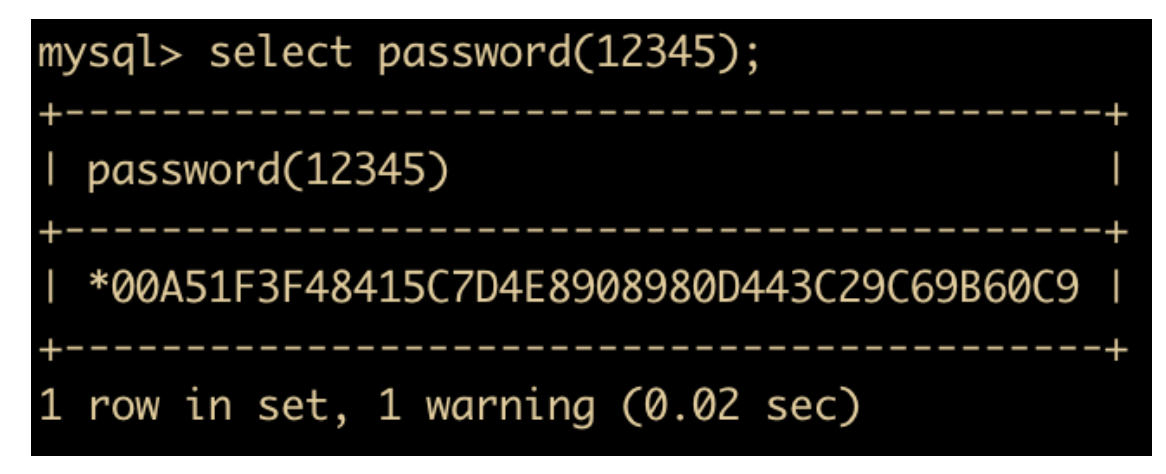
- MD5(str) 函数:返回字符串 str 的 MD5 值
- INET_ATON(IP): 返回 IP 的网络字节序列

- INET_NTOA(num)函数:返回网络字节序列代表的 IP 地址,与 INET_ATON 相对
# MyBatis二级缓存全详解-Java面试题
MyBatis 二级缓存介绍
上一篇文章中我们介绍到了 MyBatis 一级缓存其实就是 SqlSession 级别的缓存,什么是 SqlSession 级别的缓存呢?一级缓存的本质是什么呢? 以及一级缓存失效的原因?我希望你在看下文之前能够回想起来这些内容。
MyBatis 一级缓存最大的共享范围就是一个SqlSession内部,那么如果多个 SqlSession 需要共享缓存,则需要开启二级缓存,开启二级缓存后,会使用 CachingExecutor 装饰 Executor,进入一级缓存的查询流程前,先在CachingExecutor 进行二级缓存的查询,具体的工作流程如下所示

当二级缓存开启后,同一个命名空间(namespace) 所有的操作语句,都影响着一个共同的 cache,也就是二级缓存被多个 SqlSession 共享,是一个全局的变量。当开启缓存后,数据的查询执行的流程就是 二级缓存 -> 一级缓存 -> 数据库。
二级缓存开启条件
二级缓存默认是不开启的,需要手动开启二级缓存,实现二级缓存的时候,MyBatis要求返回的POJO必须是可序列化的。开启二级缓存的条件也是比较简单,通过直接在 MyBatis 配置文件中通过
<settings> <setting name = "cacheEnabled" value = "true" /> </settings>
来开启二级缓存,还需要在 Mapper 的xml 配置文件中加入 <cache> 标签
设置 cache 标签的属性
cache 标签有多个属性,一起来看一些这些属性分别代表什么意义
eviction: 缓存回收策略,有这几种回收策略- LRU – 最近最少回收,移除最长时间不被使用的对象
- FIFO – 先进先出,按照缓存进入的顺序来移除它们
- SOFT – 软引用,移除基于垃圾回收器状态和软引用规则的对象
- WEAK – 弱引用,更积极的移除基于垃圾收集器和弱引用规则的对象
默认是 LRU 最近最少回收策略
flushinterval缓存刷新间隔,缓存多长时间刷新一次,默认不清空,设置一个毫秒值readOnly: 是否只读;true 只读,MyBatis 认为所有从缓存中获取数据的操作都是只读操作,不会修改数据。MyBatis 为了加快获取数据,直接就会将数据在缓存中的引用交给用户。不安全,速度快。读写(默认):MyBatis 觉得数据可能会被修改size: 缓存存放多少个元素type: 指定自定义缓存的全类名(实现Cache 接口即可)blocking: 若缓存中找不到对应的key,是否会一直blocking,直到有对应的数据进入缓存。
探究二级缓存
我们继续以 MyBatis 一级缓存文章中的例子为基础,搭建一个满足二级缓存的例子,来对二级缓存进行探究,例子如下(对 一级缓存的例子部分源码进行修改):
Dept.java
//存放在共享缓存中数据进行序列化操作和反序列化操作 //因此数据对应实体类必须实现【序列化接口】 public class Dept implements Serializable {
private Integer deptNo;
private String dname;
private String loc;
public Dept() {}
public Dept(Integer deptNo, String dname, String loc) {
this.deptNo = deptNo;
this.dname = dname;
this.loc = loc;
}
get and set... @Override public String toString() { return "Dept{" + "deptNo=" + deptNo + ", dname='" + dname + ''' + ", loc='" + loc + ''' + '}'; } }
myBatis-config.xml
在myBatis-config 中添加开启二级缓存的条件
<!-- 通知 MyBatis 框架开启二级缓存 --> <settings> <setting name="cacheEnabled" value="true"/> </settings>
DeptDao.xml
还需要在 Mapper 对应的xml中添加 cache 标签,表示对哪个mapper 开启缓存
<!-- 表示DEPT表查询结果保存到二级缓存(共享缓存) --> <cache/>
对应的二级缓存测试类如下:
public class MyBatisSecondCacheTest {
private SqlSession sqlSession;
SqlSessionFactory factory;
@Before
public void start() throws IOException {
InputStream is = Resources.getResourceAsStream("myBatis-config.xml");
SqlSessionFactoryBuilder builderObj = new SqlSessionFactoryBuilder();
factory = builderObj.build(is);
sqlSession = factory.openSession();
}
@After
public void destory(){
if(sqlSession!=null){
sqlSession.close();
}
}
@Test
public void testSecondCache(){
//会话过程中第一次发送请求,从数据库中得到结果
//得到结果之后,mybatis自动将这个查询结果放入到当前用户的一级缓存
DeptDao dao = sqlSession.getMapper(DeptDao.class);
Dept dept = dao.findByDeptNo(1);
System.out.println("第一次查询得到部门对象 = "+dept);
//触发MyBatis框架从当前一级缓存中将Dept对象保存到二级缓存
sqlSession.commit();
// 改成 sqlSession.close(); 效果相同
SqlSession session2 = factory.openSession();
DeptDao dao2 = session2.getMapper(DeptDao.class);
Dept dept2 = dao2.findByDeptNo(1);
System.out.println("第二次查询得到部门对象 = "+dept2);
}
}
测试二级缓存效果,提交事务,
sqlSession查询完数据后,sqlSession2相同的查询是否会从缓存中获取数据。
测试结果如下:

通过结果可以得知,首次执行的SQL语句是从数据库中查询得到的结果,然后第一个 SqlSession 执行提交,第二个 SqlSession 执行相同的查询后是从缓存中查取的。
用一下这幅图能够比较直观的反映两次 SqlSession 的缓存命中

二级缓存失效的条件
与一级缓存一样,二级缓存也会存在失效的条件的,下面我们就来探究一下哪些情况会造成二级缓存失效
第一次SqlSession 未提交
SqlSession 在未提交的时候,SQL 语句产生的查询结果还没有放入二级缓存中,这个时候 SqlSession2 在查询的时候是感受不到二级缓存的存在的,修改对应的测试类,结果如下:
@Test public void testSqlSessionUnCommit(){ //会话过程中第一次发送请求,从数据库中得到结果 //得到结果之后,mybatis自动将这个查询结果放入到当前用户的一级缓存 DeptDao dao = sqlSession.getMapper(DeptDao.class); Dept dept = dao.findByDeptNo(1); System.out.println("第一次查询得到部门对象 = "+dept); //触发MyBatis框架从当前一级缓存中将Dept对象保存到二级缓存
SqlSession session2 = factory.openSession(); DeptDao dao2 = session2.getMapper(DeptDao.class); Dept dept2 = dao2.findByDeptNo(1); System.out.println("第二次查询得到部门对象 = "+dept2); }
产生的输出结果:

更新对二级缓存影响
与一级缓存一样,更新操作很可能对二级缓存造成影响,下面用三个 SqlSession来进行模拟,第一个 SqlSession 只是单纯的提交,第二个 SqlSession 用于检验二级缓存所产生的影响,第三个 SqlSession 用于执行更新操作,测试如下:
@Test public void testSqlSessionUpdate(){ SqlSession sqlSession = factory.openSession(); SqlSession sqlSession2 = factory.openSession(); SqlSession sqlSession3 = factory.openSession();
// 第一个 SqlSession 执行更新操作 DeptDao deptDao = sqlSession.getMapper(DeptDao.class); Dept dept = deptDao.findByDeptNo(1); System.out.println("dept = " + dept); sqlSession.commit();
// 判断第二个 SqlSession 是否从缓存中读取 DeptDao deptDao2 = sqlSession2.getMapper(DeptDao.class); Dept dept2 = deptDao2.findByDeptNo(1); System.out.println("dept2 = " + dept2);
// 第三个 SqlSession 执行更新操作 DeptDao deptDao3 = sqlSession3.getMapper(DeptDao.class); deptDao3.updateDept(new Dept(1,"ali","hz")); sqlSession3.commit();
// 判断第二个 SqlSession 是否从缓存中读取 dept2 = deptDao2.findByDeptNo(1); System.out.println("dept2 = " + dept2); }
对应的输出结果如下

探究多表操作对二级缓存的影响
现有这样一个场景,有两个表,部门表dept(deptNo,dname,loc)和 部门数量表deptNum(id,name,num),其中部门表的名称和部门数量表的名称相同,通过名称能够联查两个表可以知道其坐标(loc)和数量(num),现在我要对部门数量表的 num 进行更新,然后我再次关联dept 和 deptNum 进行查询,你认为这个 SQL 语句能够查询到的 num 的数量是多少?来看一下代码探究一下
DeptNum.java
public class DeptNum {
private int id;
private String name;
private int num;
get and set...
}
DeptVo.java
public class DeptVo {
private Integer deptNo;
private String dname;
private String loc;
private Integer num;
public DeptVo(Integer deptNo, String dname, String loc, Integer num) {
this.deptNo = deptNo;
this.dname = dname;
this.loc = loc;
this.num = num;
}
public DeptVo(String dname, Integer num) {
this.dname = dname;
this.num = num;
}
get and set
@Override
public String toString() {
return "DeptVo{" +
"deptNo=" + deptNo +
", dname='" + dname + '\'' +
", loc='" + loc + '\'' +
", num=" + num +
'}';
}
}
DeptDao.java
public interface DeptDao {
...
DeptVo selectByDeptVo(String name);
DeptVo selectByDeptVoName(String name);
int updateDeptVoNum(DeptVo deptVo);
}
DeptDao.xml
<select id="selectByDeptVo" resultType="com.mybatis.beans.DeptVo"> select d.deptno,d.dname,d.loc,dn.num from dept d,deptNum dn where dn.name = d.dname and d.dname = #{name} </select>
<select id="selectByDeptVoName" resultType="com.mybatis.beans.DeptVo"> select * from deptNum where name = #{name} </select>
<update id="updateDeptVoNum" parameterType="com.mybatis.beans.DeptVo"> update deptNum set num = #{num} where name = #{dname} </update>
DeptNum 数据库初始值:

测试类对应如下:
/** * 探究多表操作对二级缓存的影响 */ @Test public void testOtherMapper(){
// 第一个mapper 先执行联查操作 SqlSession sqlSession = factory.openSession(); DeptDao deptDao = sqlSession.getMapper(DeptDao.class); DeptVo deptVo = deptDao.selectByDeptVo("ali"); System.out.println("deptVo = " + deptVo); // 第二个mapper 执行更新操作 并提交 SqlSession sqlSession2 = factory.openSession(); DeptDao deptDao2 = sqlSession2.getMapper(DeptDao.class); deptDao2.updateDeptVoNum(new DeptVo("ali",1000)); sqlSession2.commit(); sqlSession2.close(); // 第一个mapper 再次进行查询,观察查询结果 deptVo = deptDao.selectByDeptVo("ali"); System.out.println("deptVo = " + deptVo); }
测试结果如下:

在对DeptNum 表执行了一次更新后,再次进行联查,发现数据库中查询出的还是 num 为 1050 的值,也就是说,实际上 1050 -> 1000 ,最后一次联查实际上查询的是第一次查询结果的缓存,而不是从数据库中查询得到的值,这样就读到了脏数据。
解决办法
如果是两个mapper命名空间的话,可以使用 <cache-ref>来把一个命名空间指向另外一个命名空间,从而消除上述的影响,再次执行,就可以查询到正确的数据
二级缓存源码解析
源码模块主要分为两个部分:二级缓存的创建和二级缓存的使用,首先先对二级缓存的创建进行分析:
二级缓存的创建
二级缓存的创建是使用 Resource 读取 XML 配置文件开始的
InputStream is = Resources.getResourceAsStream("myBatis-config.xml"); SqlSessionFactoryBuilder builder = new SqlSessionFactoryBuilder(); factory = builder.build(is);
读取配置文件后,需要对XML创建 Configuration并初始化
XMLConfigBuilder parser = new XMLConfigBuilder(inputStream, environment, properties); return build(parser.parse());
调用 parser.parse() 解析根目录 /configuration 下面的标签,依次进行解析
public Configuration parse() { if (parsed) { throw new BuilderException("Each XMLConfigBuilder can only be used once."); } parsed = true; parseConfiguration(parser.evalNode("/configuration")); return configuration; }
private void parseConfiguration(XNode root) { try { //issue #117 read properties first propertiesElement(root.evalNode("properties")); Properties settings = settingsAsProperties(root.evalNode("settings")); loadCustomVfs(settings); typeAliasesElement(root.evalNode("typeAliases")); pluginElement(root.evalNode("plugins")); objectFactoryElement(root.evalNode("objectFactory")); objectWrapperFactoryElement(root.evalNode("objectWrapperFactory")); reflectorFactoryElement(root.evalNode("reflectorFactory")); settingsElement(settings); // read it after objectFactory and objectWrapperFactory issue #631 environmentsElement(root.evalNode("environments")); databaseIdProviderElement(root.evalNode("databaseIdProvider")); typeHandlerElement(root.evalNode("typeHandlers")); mapperElement(root.evalNode("mappers")); } catch (Exception e) { throw new BuilderException("Error parsing SQL Mapper Configuration. Cause: " + e, e); } }
其中有一个二级缓存的解析就是
mapperElement(root.evalNode("mappers"));
然后进去 mapperElement 方法中
XMLMapperBuilder mapperParser = new XMLMapperBuilder(inputStream, configuration, resource, configuration.getSqlFragments()); mapperParser.parse();
继续跟 mapperParser.parse() 方法
public void parse() { if (!configuration.isResourceLoaded(resource)) { configurationElement(parser.evalNode("/mapper")); configuration.addLoadedResource(resource); bindMapperForNamespace(); }
parsePendingResultMaps(); parsePendingCacheRefs(); parsePendingStatements(); }
这其中有一个 configurationElement 方法,它是对二级缓存进行创建,如下
private void configurationElement(XNode context) { try { String namespace = context.getStringAttribute("namespace"); if (namespace == null || namespace.equals("")) { throw new BuilderException("Mapper's namespace cannot be empty"); } builderAssistant.setCurrentNamespace(namespace); cacheRefElement(context.evalNode("cache-ref")); cacheElement(context.evalNode("cache")); parameterMapElement(context.evalNodes("/mapper/parameterMap")); resultMapElements(context.evalNodes("/mapper/resultMap")); sqlElement(context.evalNodes("/mapper/sql")); buildStatementFromContext(context.evalNodes("select|insert|update|delete")); } catch (Exception e) { throw new BuilderException("Error parsing Mapper XML. Cause: " + e, e); } }
有两个二级缓存的关键点
cacheRefElement(context.evalNode("cache-ref")); cacheElement(context.evalNode("cache"));
也就是说,mybatis 首先进行解析的是 cache-ref 标签,其次进行解析的是 cache 标签。
根据上面我们的 — 多表操作对二级缓存的影响 一节中提到的解决办法,采用 cache-ref 来进行命名空间的依赖能够避免二级缓存,但是总不能每次写一个 XML 配置都会采用这种方式吧,最有效的方式还是避免多表操作使用二级缓存
然后我们再来看一下cacheElement(context.evalNode("cache")) 这个方法
private void cacheElement(XNode context) throws Exception { if (context != null) { String type = context.getStringAttribute("type", "PERPETUAL"); Class<? extends Cache> typeClass = typeAliasRegistry.resolveAlias(type); String eviction = context.getStringAttribute("eviction", "LRU"); Class<? extends Cache> evictionClass = typeAliasRegistry.resolveAlias(eviction); Long flushInterval = context.getLongAttribute("flushInterval"); Integer size = context.getIntAttribute("size"); boolean readWrite = !context.getBooleanAttribute("readOnly", false); boolean blocking = context.getBooleanAttribute("blocking", false); Properties props = context.getChildrenAsProperties(); builderAssistant.useNewCache(typeClass, evictionClass, flushInterval, size, readWrite, blocking, props); } }
认真看一下其中的属性的解析,是不是感觉很熟悉?这不就是对 cache 标签属性的解析吗?!!!
上述最后一句代码
builderAssistant.useNewCache(typeClass, evictionClass, flushInterval, size, readWrite, blocking, props);
public Cache useNewCache(Class<? extends Cache> typeClass, Class<? extends Cache> evictionClass, Long flushInterval, Integer size, boolean readWrite, boolean blocking, Properties props) { Cache cache = new CacheBuilder(currentNamespace) .implementation(valueOrDefault(typeClass, PerpetualCache.class)) .addDecorator(valueOrDefault(evictionClass, LruCache.class)) .clearInterval(flushInterval) .size(size) .readWrite(readWrite) .blocking(blocking) .properties(props) .build(); configuration.addCache(cache); currentCache = cache; return cache; }
这段代码使用了构建器模式,一步一步构建Cache 标签的所有属性,最终把 cache 返回。
二级缓存的使用
在 mybatis 中,使用 Cache 的地方在 CachingExecutor中,来看一下 CachingExecutor 中缓存做了什么工作,我们以查询为例
@Override public <E> List<E> query(MappedStatement ms, Object parameterObject, RowBounds rowBounds, ResultHandler resultHandler, CacheKey key, BoundSql boundSql) throws SQLException { // 得到缓存 Cache cache = ms.getCache(); if (cache != null) { // 如果需要的话刷新缓存 flushCacheIfRequired(ms); if (ms.isUseCache() && resultHandler == null) { ensureNoOutParams(ms, parameterObject, boundSql); @SuppressWarnings("unchecked") List<E> list = (List<E>) tcm.getObject(cache, key); if (list == null) { list = delegate.<E> query(ms, parameterObject, rowBounds, resultHandler, key, boundSql); tcm.putObject(cache, key, list); // issue #578 and #116 } return list; } } // 委托模式,交给SimpleExecutor等实现类去实现方法。 return delegate.<E> query(ms, parameterObject, rowBounds, resultHandler, key, boundSql); }
其中,先从 MapperStatement 取出缓存。只有通过<cache/>,<cache-ref/>或@CacheNamespace,@CacheNamespaceRef标记使用缓存的Mapper.xml或Mapper接口(同一个namespace,不能同时使用)才会有二级缓存。
如果缓存不为空,说明是存在缓存。如果cache存在,那么会根据sql配置(<insert>,<select>,<update>,<delete>的flushCache属性来确定是否清空缓存。
flushCacheIfRequired(ms);
然后根据xml配置的属性useCache来判断是否使用缓存(resultHandler一般使用的默认值,很少会null)。
if (ms.isUseCache() && resultHandler == null)
确保方法没有Out类型的参数,mybatis不支持存储过程的缓存,所以如果是存储过程,这里就会报错。
private void ensureNoOutParams(MappedStatement ms, Object parameter, BoundSql boundSql) { if (ms.getStatementType() == StatementType.CALLABLE) { for (ParameterMapping parameterMapping : boundSql.getParameterMappings()) { if (parameterMapping.getMode() != ParameterMode.IN) { throw new ExecutorException("Caching stored procedures with OUT params is not supported. Please configure useCache=false in " + ms.getId() + " statement."); } } } }
然后根据在 TransactionalCacheManager 中根据 key 取出缓存,如果没有缓存,就会执行查询,并且将查询结果放到缓存中并返回取出结果,否则就执行真正的查询方法。
List<E> list = (List<E>) tcm.getObject(cache, key); if (list == null) { list = delegate.<E> query(ms, parameterObject, rowBounds, resultHandler, key, boundSql); tcm.putObject(cache, key, list); // issue #578 and #116 } return list;
是否应该使用二级缓存?
那么究竟应该不应该使用二级缓存呢?先来看一下二级缓存的注意事项:
- 缓存是以
namespace为单位的,不同namespace下的操作互不影响。 - insert,update,delete操作会清空所在
namespace下的全部缓存。 - 通常使用MyBatis Generator生成的代码中,都是各个表独立的,每个表都有自己的
namespace。 - 多表操作一定不要使用二级缓存,因为多表操作进行更新操作,一定会产生脏数据。
如果你遵守二级缓存的注意事项,那么你就可以使用二级缓存。
但是,如果不能使用多表操作,二级缓存不就可以用一级缓存来替换掉吗?而且二级缓存是表级缓存,开销大,没有一级缓存直接使用 HashMap 来存储的效率更高,所以二级缓存并不推荐使用。
# MyBatis核心配置综述之Executor-Java面试题
上一篇我们对SqlSession和SqlSessionFactory的创建过程有了一个详细的了解,但上述的创建过程只是为SQL执行和SQL映射做了基础的铺垫而已,就和我们Spring源码为Bean容器的加载进行许多初始化的工作相同,那么做好前期的准备工作接下来该做什么了?该做数据库连接驱动管理和SQL解析工作了!那么本篇本章就来讨论一下数据库驱动连接管理和SQL解析的管理组件之 Executor执行器。
MyBatis四大组件之 Executor执行器
每一个SqlSession都会拥有一个Executor对象,这个对象负责增删改查的具体操作,我们可以简单的将它理解为JDBC中Statement的封装版。
Executor的继承结构

如图所示,位于继承体系最顶层的是Executor执行器,它有两个实现类,分别是BaseExecutor和 CachingExecutor。
BaseExecutor 是一个抽象类,这种通过抽象的实现接口的方式是适配器设计模式之接口适配的体现,是Executor的默认实现,实现了大部分Executor接口定义的功能,降低了接口实现的难度。BaseExecutor的子类有三个,分别是SimpleExecutor、ReuseExecutor和BatchExecutor。
SimpleExecutor: 简单执行器,是MyBatis中默认使用的执行器,每执行一次update或select,就开启一个Statement对象,用完就直接关闭Statement对象(可以是Statement或者是PreparedStatment对象)
ReuseExecutor: 可重用执行器,这里的重用指的是重复使用Statement,它会在内部使用一个Map把创建的Statement都缓存起来,每次执行SQL命令的时候,都会去判断是否存在基于该SQL的Statement对象,如果存在Statement对象并且对应的connection还没有关闭的情况下就继续使用之前的Statement对象,并将其缓存起来。因为每一个SqlSession都有一个新的Executor对象,所以我们缓存在ReuseExecutor上的Statement作用域是同一个SqlSession。
BatchExecutor: 批处理执行器,用于将多个SQL一次性输出到数据库
CachingExecutor: 缓存执行器,先从缓存中查询结果,如果存在,就返回;如果不存在,再委托给Executor delegate 去数据库中取,delegate可以是上面任何一个执行器
Executor创建过程以及源码分析
上面我们分析完SqlSessionFactory的创建过程的准备工作后,我们下面就开始分析会话的创建以及Executor的执行过程。
在创建完SqlSessionFactory之后,调用其openSession方法:
SqlSession sqlSession = factory.openSession();
SqlSessionFactory的默认实现是DefaultSqlSessionFactory,所以我们需要关心的就是DefaultSqlSessionFactory中的openSession()方法
openSession调用的是openSessionFromDataSource方法,传递执行器的类型,方法传播级别,是否自动提交,然后在openSessionFromDataSource方法中会创建一个执行器
public SqlSession openSession() { return openSessionFromDataSource(configuration.getDefaultExecutorType(), null, false); }
private SqlSession openSessionFromDataSource(ExecutorType execType, TransactionIsolationLevel level, boolean autoCommit) { Transaction tx = null; try { // 得到configuration 中的environment final Environment environment = configuration.getEnvironment(); // 得到configuration 中的事务工厂 final TransactionFactory transactionFactory = getTransactionFactoryFromEnvironment(environment); tx = transactionFactory.newTransaction(environment.getDataSource(), level, autoCommit); // 获取执行器 final Executor executor = configuration.newExecutor(tx, execType); // 返回默认的SqlSession return new DefaultSqlSession(configuration, executor, autoCommit); } catch (Exception e) { closeTransaction(tx); // may have fetched a connection so lets call close() throw ExceptionFactory.wrapException("Error opening session. Cause: " + e, e); } finally { ErrorContext.instance().reset(); } }
调用newExecutor方法,根据传入的ExecutorType类型来判断是哪种执行器,然后执行相应的逻辑
public Executor newExecutor(Transaction transaction, ExecutorType executorType) { // defaultExecutorType默认是简单执行器, 如果不传executorType的话,默认使用简单执行器 executorType = executorType == null ? defaultExecutorType : executorType; executorType = executorType == null ? ExecutorType.SIMPLE : executorType; Executor executor; // 根据执行器类型生成对应的执行器逻辑 if (ExecutorType.BATCH == executorType) { executor = new BatchExecutor(this, transaction); } else if (ExecutorType.REUSE == executorType) { executor = new ReuseExecutor(this, transaction); } else { executor = new SimpleExecutor(this, transaction); } // 如果允许缓存,则使用缓存执行器 // 默认是true,如果不允许缓存的话,需要手动设置 if (cacheEnabled) { executor = new CachingExecutor(executor); } // 插件开发。 executor = (Executor) interceptorChain.pluginAll(executor); return executor; }
ExecutorType的选择:
ExecutorType来决定Configuration对象创建何种类型的执行器,它的赋值可以通过两个地方进行赋值:
- 可以通过
标签来设置当前工程中所有的SqlSession对象使用默认的Executor
- 另外一种直接通过Java对方法赋值的方式
session = factory.openSession(ExecutorType.BATCH);
ExecutorType是一个枚举,它只有三个值SIMPLE, REUSE, BATCH
创建完成Executor之后,会把Executor执行器放入一个DefaultSqlSession对象中来对四个属性进行赋值,他们分别是 configuration、executor、 dirty、autoCommit。
Executor接口的主要方法
Executor接口的方法还是比较多的,这里我们就几个主要的方法和调用流程来做一个简单的描述
大致流程
Executor中的大部分方法的调用链其实是差不多的,下面都是深入源码分析执行过程,如果你没有时间或者暂时不想深入研究的话,给你下面的执行流程图作为参考。

query()方法
query方法有两种形式,一种是直接查询;一种是从缓存中查询,下面来看一下源码
<E> List<E> query(MappedStatement ms, Object parameter, RowBounds rowBounds, ResultHandler resultHandler, CacheKey cacheKey, BoundSql boundSql) throws SQLException;
<E> List<E> query(MappedStatement ms, Object parameter, RowBounds rowBounds, ResultHandler resultHandler) throws SQLException;
当有一个查询请求访问的时候,首先会经过Executor的实现类CachingExecutor,先从缓存中查询SQL是否是第一次执行,如果是第一次执行的话,那么就直接执行SQL语句,并创建缓存,如果第二次访问相同的SQL语句的话,那么就会直接从缓存中提取
CachingExecutor.j
// 第一次查询,并创建缓存 public <E> List<E> query(MappedStatement ms, Object parameterObject, RowBounds rowBounds, ResultHandler resultHandler) throws SQLException { BoundSql boundSql = ms.getBoundSql(parameterObject); CacheKey key = createCacheKey(ms, parameterObject, rowBounds, boundSql); return query(ms, parameterObject, rowBounds, resultHandler, key, boundSql); }
MapperStatement维护了一条<select|update|delete|insert>节点的封装,包括资源(resource),配置(configuration),SqlSource(sql源文件)等。使用Configuration的getMappedStatement方法来获取MappedStatement对象
BoundSql这个类包括SQL的基本信息,基本的SQL语句,参数映射,参数类型等
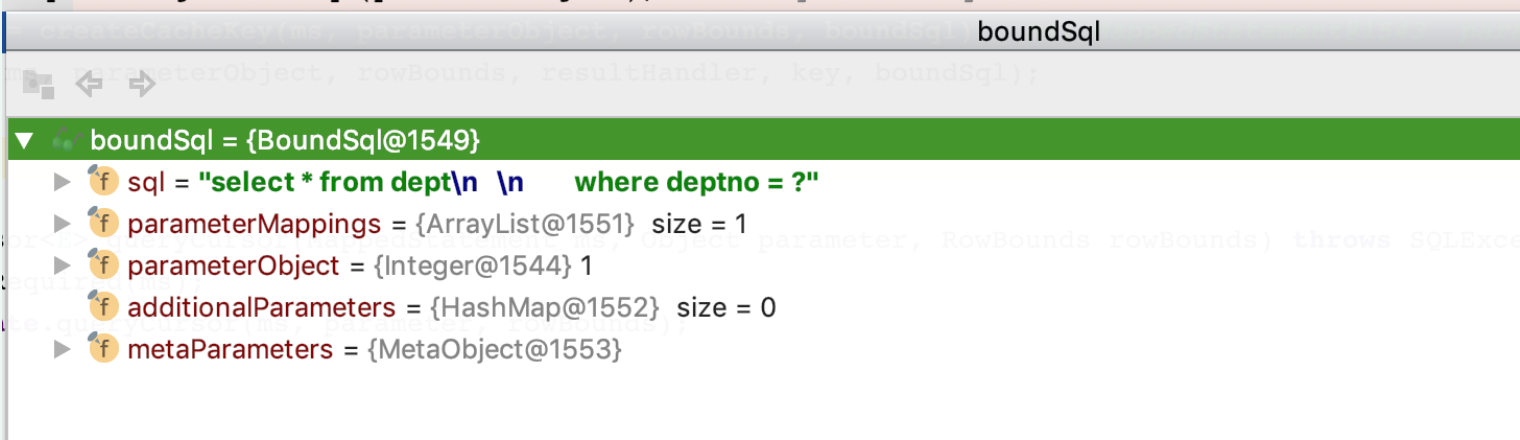
上述的query方法会调用到CachingExecutor类中的query查询缓存的方法
public <E> List<E> query(MappedStatement ms, Object parameterObject, RowBounds rowBounds, ResultHandler resultHandler, CacheKey key, BoundSql boundSql) throws SQLException { // 得到缓存 Cache cache = ms.getCache(); if (cache != null) { // 如果需要的话刷新缓存 flushCacheIfRequired(ms); if (ms.isUseCache() && resultHandler == null) { ensureNoOutParams(ms, boundSql); @SuppressWarnings("unchecked") List<E> list = (List<E>) tcm.getObject(cache, key); if (list == null) { list = delegate.<E> query(ms, parameterObject, rowBounds, resultHandler, key, boundSql); tcm.putObject(cache, key, list); } return list; } } // 委托模式,交给SimpleExecutor等实现类去实现方法。 return delegate.<E> query(ms, parameterObject, rowBounds, resultHandler, key, boundSql); }
由delegate执行query方法,delegate即是BaseExecutor,然后由具体的执行器去真正执行query方法
注意:源码中一般以do** 开头的方法都是真正加载执行的方法
// 经过一系列的调用,会调用到下面的方法(与主流程无关,故省略) // 以SimpleExecutor简单执行器为例 public <E> List<E> doQuery(MappedStatement ms, Object parameter, RowBounds rowBounds, ResultHandler resultHandler, BoundSql boundSql) throws SQLException { Statement stmt = null; try { // 获取环境配置 Configuration configuration = ms.getConfiguration(); // 创建StatementHandler,解析SQL语句 StatementHandler handler = configuration.newStatementHandler(wrapper, ms, parameter, rowBounds, resultHandler, boundSql); stmt = prepareStatement(handler, ms.getStatementLog()); // 由handler来对SQL语句执行解析工作 return handler.<E>query(stmt, resultHandler); } finally { closeStatement(stmt); } }
由上面的源码可以看出,Executor执行器所起的作用相当于是管理StatementHandler 的整个生命周期的工作,包括创建、初始化、解析、关闭。
ReuseExecutor完成的doQuery 工作:几乎和SimpleExecutor完成的工作一样,其内部不过是使用一个Map来存储每次执行的查询语句,为后面的SQL重用作准备。
BatchExecutor完成的doQuery 工作:和SimpleExecutor完成的工作一样。
update() 方法
在分析完上面的查询方法后,我们再来聊一下update()方法,update()方法不仅仅指的是update()方法,它是一条update链,什么意思呢?就是*insert、update、delete在语义上其实都是更新的意思,而查询在语义上仅仅只是表示的查询,那么我们来偷窥一下update方法的执行流程,与select的主要执行流程很相似,所以一次性贴出。
// 首先在顶级接口中定义update 方法,交由子类或者抽象子类去实现
// 也是首先去缓存中查询是否具有已经执行过的相同的update语句 public int update(MappedStatement ms, Object parameterObject) throws SQLException { flushCacheIfRequired(ms); return delegate.update(ms, parameterObject); }
// 然后再交由BaseExecutor 执行update 方法 public int update(MappedStatement ms, Object parameter) throws SQLException { ErrorContext.instance().resource(ms.getResource()).activity("executing an update").object(ms.getId()); if (closed) { throw new ExecutorException("Executor was closed."); } clearLocalCache(); return doUpdate(ms, parameter); }
// 往往do* 开头的都是真正执行解析的方法,所以doUpdate 应该就是真正要执行update链的解析方法了 // 交给具体的执行器去执行 public int doUpdate(MappedStatement ms, Object parameter) throws SQLException { Statement stmt = null; try { Configuration configuration = ms.getConfiguration(); StatementHandler handler = configuration.newStatementHandler(this, ms, parameter, RowBounds.DEFAULT, null, null); stmt = prepareStatement(handler, ms.getStatementLog()); return handler.update(stmt); } finally { closeStatement(stmt); } }
ReuseExecutor完成的doUpdate 工作:几乎和SimpleExecutor完成的工作一样,其内部不过是使用一个Map来存储每次执行的更新语句,为后面的SQL重用作准备。
BatchExecutor完成的doUpdate 工作:和SimpleExecutor完成的工作相似,只是其内部有一个List列表来一次行的存储多个Statement,用于将多个sql语句一次性输送到数据库执行.
queryCursor()方法
我们查阅其源码的时候,在执行器的执行过程中并没有发现其与query方法有任何不同之处,但是在doQueryCursor 方法中我们可以看到它返回了一个cursor对象,网上搜索cursor的相关资料并查阅其基本结构,得出来的结论是:用于逐条读取SQL语句,应对数据量
// 查询可以返回Cursor<T>类型的数据,类似于JDBC里的ResultSet类, // 当查询百万级的数据的时候,使用游标可以节省内存的消耗,不需要一次性取出所有数据,可以进行逐条处理或逐条取出部分批量处理。 public interface Cursor<T> extends Closeable, Iterable<T> {
boolean isOpen();
boolean isConsumed();
int getCurrentIndex();
}
flushStatements() 方法
flushStatement()的主要执行流程和query,update 的执行流程差不多,我们这里就不再详细贴代码了,简单说一下flushStatement()的主要作用,flushStatement()主要用来释放statement,或者用于ReuseExecutor和BatchExecutor来刷新缓存
createCacheKey() 方法
createCacheKey()方法主要由BaseExecutor来执行并创建缓存,MyBatis中的缓存分为一级缓存和二级缓存,关于缓存的讨论我们将在Mybatis系列的缓存章节
Executor 中的其他方法
Executor 中还有其他方法,提交commit,回滚rollback,判断是否时候缓存isCached,关闭close,获取事务getTransaction一级清除本地缓存clearLocalCache等
Executor 的现实抽象
在上面的分析过程中我们了解到,Executor执行器是MyBatis中很重要的一个组件,Executor相当于是外包的boss,它定义了甲方(SQL)需要干的活(Executor的主要方法),这个外包公司是个小公司,没多少人,每个人都需要干很多工作,boss接到开发任务的话,一般都找项目经理(CachingExecutor),项目经理几乎不懂技术,它主要和技术leader(BaseExecutor)打交道,技术leader主要负责框架的搭建,具体的工作都会交给下面的程序员来做,程序员的技术也有优劣,高级程序员(BatchExecutor)、中级程序员(ReuseExecutor)、初级程序员(SimpleExecutor),它们干的活也不一样。一般有新的项目需求传达到项目经理这里,项目经理先判断自己手里有没有现成的类库或者项目直接套用(Cache),有的话就直接让技术leader拿来直接套用就好,没有的话就需要搭建框架,再把框架存入本地类库中,再进行解析。
# MyBatis一级缓存-Java面试题
什么是缓存
缓存就是内存中的一个对象,用于对数据库查询结果的保存,用于减少与数据库的交互次数从而降低数据库的压力,进而提高响应速度。
什么是MyBatis中的缓存
MyBatis 中的缓存就是说 MyBatis 在执行一次SQL查询或者SQL更新之后,这条SQL语句并不会消失,而是被MyBatis 缓存起来,当再次执行相同SQL语句的时候,就会直接从缓存中进行提取,而不是再次执行SQL命令。
MyBatis中的缓存分为一级缓存和二级缓存,一级缓存又被称为 SqlSession 级别的缓存,二级缓存又被称为表级缓存。
SqlSession是什么?SqlSession 是SqlSessionFactory会话工厂创建出来的一个会话的对象,这个SqlSession对象用于执行具体的SQL语句并返回给用户请求的结果。
SqlSession级别的缓存是什么意思?SqlSession级别的缓存表示的就是每当执行一条SQL语句后,默认就会把该SQL语句缓存起来,也被称为会话缓存
MyBatis 中的一级缓存
一级缓存是 SqlSession级别 的缓存。在操作数据库时需要构造 sqlSession 对象,在对象中有一个(内存区域)数据结构(HashMap)用于存储缓存数据。不同的 sqlSession 之间的缓存数据区域(HashMap)是互相不影响的。用一张图来表示一下一级缓存,其中每一个 SqlSession 的内部都会有一个一级缓存对象。

在应用运行过程中,我们有可能在一次数据库会话中,执行多次查询条件完全相同的SQL,MyBatis 提供了一级缓存的方案优化这部分场景,如果是相同的SQL语句,会优先命中一级缓存,避免直接对数据库进行查询,提高性能。
初探一级缓存
我们继续使用 MyBatis基础搭建以及配置详解中的例子(https://mp.weixin.qq.com/s/Ys03zaTSaOakdGU4RlLJ1A)进行 一级缓存的探究。
在对应的 resources 根目录下加上日志的输出信息 log4j.properties
##define an appender named console log4j.appender.console=org.apache.log4j.ConsoleAppender #The Target value is System.out or System.err log4j.appender.console.Target=System.out #set the layout type of the apperder log4j.appender.console.layout=org.apache.log4j.PatternLayout #set the layout format pattern log4j.appender.console.layout.ConversionPattern=[%-5p] %m%n
##define a logger log4j.rootLogger=debug,console
模拟思路: 既然每个 SqlSession 都会有自己的一个缓存,那么我们用同一个 SqlSession 是不是就能感受到一级缓存的存在呢?调用多次 getMapper 方法,生成对应的SQL语句,判断每次SQL语句是从缓存中取还是对数据库进行操作,下面的例子来证明一下
@Test public void test(){ DeptDao deptDao = sqlSession.getMapper(DeptDao.class); Dept dept = deptDao.findByDeptNo(1); System.out.println(dept);
DeptDao deptDao2 = sqlSession.getMapper(DeptDao.class); Dept dept2 = deptDao2.findByDeptNo(1); System.out.println(dept2); System.out.println(deptDao2.findByDeptNo(1)); }
输出:

可以看到,上面代码执行了三条相同的SQL语句,但是只有一条SQL语句进行了输出,其他两条SQL语句都是从缓存中查询的,所以它们生成了相同的 Dept 对象。
探究一级缓存是如何失效的
上面的一级缓存初探让我们感受到了 MyBatis 中一级缓存的存在,那么现在你或许就会有疑问了,那么什么时候缓存失效呢? 这个问题也就是我们接下来需要详细讨论的议题之一。
探究更新对一级缓存失效的影响
上面的代码执行了三次相同的查询操作,返回了相同的结果,那么,如果我在第一条和第二条SQL语句之前插入更新的SQL语句,是否会对一级缓存产生影响呢?代码如下:
@Test public void testCacheLose(){ DeptDao deptDao = sqlSession.getMapper(DeptDao.class); Dept dept = deptDao.findByDeptNo(1); System.out.println(dept);
// 在两次查询之间使用 更新 操作,是否会对一级缓存产生影响 deptDao.insertDept(new Dept(7,"tengxun","shenzhen")); // deptDao.updateDept(new Dept(1,"zhongke","sjz")); // deptDao.deleteByDeptNo(7);
DeptDao deptDao2 = sqlSession.getMapper(DeptDao.class); Dept dept2 = deptDao2.findByDeptNo(1); System.out.println(dept2); }
为了演示效果,就不贴出 insertDept 的代码了,就是一条简单的插入语句。
分别放开不同的更新语句,发现执行效果如下
输出结果:

如图所示,在两次查询语句中使用插入,会对一级缓存进行刷新,会导致一级缓存失效。
探究不同的 SqlSession 对一级缓存的影响
如果你看到这里了,那么你应该知道一级缓存就是 SqlSession 级别的缓存,而同一个 SqlSession 会有相同的一级缓存,那么使用不同的 SqlSession 是不是会对一级缓存产生影响呢? 显而易见是的,那么下面就来演示并且证明一下
private SqlSessionFactory factory; // 把factory设置为全局变量
@Test public void testCacheLoseWithSqlSession(){ DeptDao deptDao = sqlSession.getMapper(DeptDao.class); Dept dept = deptDao.findByDeptNo(1); System.out.println(dept);
SqlSession sqlSession2 = factory.openSession(); DeptDao deptDao2 = sqlSession2.getMapper(DeptDao.class); Dept dept2 = deptDao2.findByDeptNo(1); System.out.println(dept2);
}
输出:

上面代码使用了不同的 SqlSession 对同一个SQL语句执行了相同的查询操作,却对数据库执行了两次相同的查询操作,生成了不同的 dept 对象,由此可见,不同的 SqlSession 是肯定会对一级缓存产生影响的。
同一个 SqlSession 使用不同的查询操作
使用不同的查询条件是否会对一级缓存产生影响呢?可能在你心里已经有这个答案了,再来看一下代码吧
@Test public void testWithDifferentParam(){ DeptDao deptDao = sqlSession.getMapper(DeptDao.class); Dept dept = deptDao.findByDeptNo(1); System.out.println(dept);
DeptDao deptDao2 = sqlSession.getMapper(DeptDao.class); Dept dept2 = deptDao2.findByDeptNo(5); System.out.println(dept2); }
输出结果

我们在两次查询SQL分别使用了不同的查询条件,查询出来的数据不一致,那就肯定会对一级缓存产生影响了。
手动清理缓存对一级缓存的影响
我们在两次查询的SQL语句之间使用 clearCache 是否会对一级缓存产生影响呢?下面例子证实了这一点
@Test public void testClearCache(){ DeptDao deptDao = sqlSession.getMapper(DeptDao.class); Dept dept = deptDao.findByDeptNo(1); System.out.println(dept);
//在两次相同的SQL语句之间使用查询操作,对一级缓存的影响。
sqlSession.clearCache();
DeptDao deptDao2 = sqlSession.getMapper(DeptDao.class); Dept dept2 = deptDao2.findByDeptNo(1); System.out.println(dept2); }
输出:

我们在两次查询操作之间,使用了 sqlSession 的 clearCache() 方法清除了一级缓存,所以使用 clearCache 也会对一级缓存产生影响。
一级缓存原理探究
一级缓存到底是什么?一级缓存的工作流程是怎样的?一级缓存何时消失?相信你现在应该会有这几个疑问,那么我们本节就来研究一下一级缓存的本质
嗯。。。。。。该从何处入手呢?
你可以这样想,上面我们一直提到一级缓存,那么提到一级缓存就绕不开 SqlSession,所以索性我们就直接从 SqlSession ,看看有没有创建缓存或者与缓存有关的属性或者方法

调研了一圈,发现上述所有方法中,好像只有 clearCache() 和缓存沾点关系,那么就直接从这个方法入手吧,分析源码时,我们要看它(此类)是谁,它的父类和子类分别又是谁,对如上关系了解了,你才会对这个类有更深的认识,分析了一圈,你可能会得到如下这个流程图

再深入分析,流程走到Perpetualcache 中的 clear() 方法之后,会调用其 cache.clear() 方法,那么这个cache 是什么东西呢? 点进去发现,cache 其实就是 private Map<Object, Object> cache = new HashMap<Object, Object>(); 也就是一个Map,所以说 cache.clear() 其实就是 map.clear() ,也就是说,缓存其实就是本地存放的一个 map 对象,每一个SqlSession 都会存放一个 map 对象的引用,那么这个 cache 是何时创建的呢?
你觉得最有可能创建缓存的地方是哪里呢? 我觉得是 Executor,为什么这么认为? 因为 Executor 是执行器,用来执行SQL请求,而且清除缓存的方法也在 Executor 中执行,所以很可能缓存的创建也很有可能在 Executor 中,看了一圈发现 Executor 中有一个 createCacheKey 方法,这个方法很像是创建缓存的方法啊,跟进去看看,你发现 createCacheKey 方法是由 BaseExecutor 执行的,代码如下
CacheKey cacheKey = new CacheKey(); //MappedStatement的id // id 就是Sql语句的所在位置 包名 + 类名 + SQL名称 cacheKey.update(ms.getId()); // offset 就是 0 cacheKey.update(rowBounds.getOffset()); // limit 就是 Integer.MAXVALUE cacheKey.update(rowBounds.getLimit()); // 具体的SQL语句 cacheKey.update(boundSql.getSql()); //后面是update了sql中带的参数 cacheKey.update(value); ... if (configuration.getEnvironment() != null) { // issue #176 cacheKey.update(configuration.getEnvironment().getId()); }
创建缓存key会经过一系列的 update 方法,update 方法由一个 CacheKey 这个对象来执行的,这个 update 方法最终由 updateList 的 list 来把五个值存进去,对照上面的代码和下面的图示,你应该能理解这五个值都是什么了

这里需要注意一下最后一个值, configuration.getEnvironment().getId() 这是什么,这其实就是定义在
mybatis-config.xml中的标签,见如下。
那么我们回归正题,那么创建完缓存之后该用在何处呢?总不会凭空创建一个缓存不使用吧?绝对不会的,经过我们对一级缓存的探究之后,我们发现一级缓存更多是用于查询操作,毕竟一级缓存也叫做查询缓存吧,为什么叫查询缓存我们一会儿说。我们先来看一下这个缓存到底用在哪了,我们跟踪到 query 方法如下:
@Override public <E> List<E> query(MappedStatement ms, Object parameter, RowBounds rowBounds, ResultHandler resultHandler) throws SQLException { BoundSql boundSql = ms.getBoundSql(parameter); // 创建缓存 CacheKey key = createCacheKey(ms, parameter, rowBounds, boundSql); return query(ms, parameter, rowBounds, resultHandler, key, boundSql); }
@SuppressWarnings("unchecked") @Override public <E> List<E> query(MappedStatement ms, Object parameter, RowBounds rowBounds, ResultHandler resultHandler, CacheKey key, BoundSql boundSql) throws SQLException { ... list = resultHandler == null ? (List<E>) localCache.getObject(key) : null; if (list != null) { // 这个主要是处理存储过程用的。 handleLocallyCachedOutputParameters(ms, key, parameter, boundSql); } else { list = queryFromDatabase(ms, parameter, rowBounds, resultHandler, key, boundSql); } ... }
// queryFromDatabase 方法 private <E> List<E> queryFromDatabase(MappedStatement ms, Object parameter, RowBounds rowBounds, ResultHandler resultHandler, CacheKey key, BoundSql boundSql) throws SQLException { List<E> list; localCache.putObject(key, EXECUTION_PLACEHOLDER); try { list = doQuery(ms, parameter, rowBounds, resultHandler, boundSql); } finally { localCache.removeObject(key); } localCache.putObject(key, list); if (ms.getStatementType() == StatementType.CALLABLE) { localOutputParameterCache.putObject(key, parameter); } return list; }
如果查不到的话,就从数据库查,在queryFromDatabase中,会对localcache进行写入。localcache 对象的put 方法最终交给 Map 进行存放
private Map<Object, Object> cache = new HashMap<Object, Object>();
@Override public void putObject(Object key, Object value) { cache.put(key, value); }
那么再说一下为什么一级缓存也叫做查询缓存呢?
我们先来看一下 update 更新方法,先来看一下 update 的源码
@Override public int update(MappedStatement ms, Object parameter) throws SQLException { ErrorContext.instance().resource(ms.getResource()).activity("executing an update").object(ms.getId()); if (closed) { throw new ExecutorException("Executor was closed."); } clearLocalCache(); return doUpdate(ms, parameter); }
由 BaseExecutor 在每次执行 update 方法的时候,都会先 clearLocalCache() ,所以更新方法并不会有缓存,这也就是说为什么一级缓存也叫做查询缓存了,这也就是为什么我们没有探究多次执行更新方法对一级缓存的影响了。
还有其他要补充的吗?
我们上面分析了一级缓存的执行流程,为什么一级缓存要叫查询缓存以及一级缓存组成条件
那么,你可能看到这感觉这些知识还是不够连贯,那么我就帮你把 一级缓存的探究 小结中的原理说一下吧,为什么一级缓存会失效
- 探究更新对一级缓存失效的影响: 由上面的分析结论可知,我们每次执行 update 方法时,都会先刷新一级缓存,因为是同一个 SqlSession, 所以是由同一个 Map 进行存储的,所以此时一级缓存会失效
- 探究不同的 SqlSession 对一级缓存的影响: 这个也就比较好理解了,因为不同的 SqlSession 会有不同的Map 存储一级缓存,然而 SqlSession 之间也不会共享,所以此时也就不存在相同的一级缓存
- 同一个 SqlSession 使用不同的查询操作: 这个论点就需要从缓存的构成角度来讲了,我们通过 cacheKey 可知,一级缓存命中的必要条件是两个 cacheKey 相同,要使得 cacheKey 相同,就需要使 cacheKey 里面的值相同,也就是


看出差别了吗?第一个SQL 我们查询的是部门编号为1的值,而第二个SQL我们查询的是编号为5的值,两个缓存对象不相同,所以也就不存在缓存。
- 手动清理缓存对一级缓存的影响: 由程序员自己去调用
clearCache方法,这个方法就是清除缓存的方法,所以也就不存在缓存了。
总结
所以此文章到底写了点什么呢?抛给你几个问题了解一下
- 什么是缓存?什么是 MyBatis 缓存?
- 认识MyBatis缓存,MyBatis 一级缓存的失效方式
- MyBatis 一级缓存的执行流程,MyBatis 一级缓存究竟是什么?
# 672.final, finally, finalize 的区别?-Java面试题
final:修饰符(关键字)有三种用法:如果一个类被声明为 final,意味着它不能再派生出新的子类,即不能被继承,因此它和 abstract 是反义词。将变量声明为 final,可以保证它们在使用中不被改变,被声明为 final 的变量必须在声明时给定初值,而在以后的引用中只能读取不可修改。被声明为 final 的方法也同样只能使用,不能在子类中被重写。finally:通常放在 try…catch 的后面构造总是执行代码块,这就意味着程序无论正常执行还是发生异常,这里的代码只要 JVM 不关闭都能执行,可以将释放外部资源的代码写在 finally 块中。finalize:Object 类中定义的方法,Java 中允许使用 finalize() 方法在垃圾收集器将对象从内存中清除出去之前做必要的清理工作。这个方法是由垃圾收集器在销毁对象时调用的,通过重写 finalize() 方法可以整理系统资源或者执行其他清理工作。
VM 内存可简单分为三个区:
- 堆区(heap):用于存放所有对象,是线程共享的(注:数组也属于对象)
- 栈区(stack):用于存放基本数据类型的数据和对象的引用,是线程私有的(分为:虚拟机栈和本地方法栈)
- 方法区(method):用于存放类信息、常量、静态变量、编译后的字节码等,是线程共享的(也被称为非堆,即 None-Heap)
Java 的垃圾回收器(GC)主要针对堆区
# 671.列出一些你常见的运行时异常?-Java面试题
ArithmeticException(算术异常)
ClassCastException (类转换异常)
IllegalArgumentException (非法参数异常)
IndexOutOfBoundsException (下表越界异常)
NullPointerException (空指针异常)
SecurityException (安全异常)
# 670.运行时异常与受检异常有何异同?-Java面试题
异常表示程序运行过程中可能出现的非正常状态,运行时异常表示虚拟机的通常操作中可能遇到的异常,是一种常见运行错误,只要程序设计得没有问题通常就不会发生。受检异常跟程序运行的上下文环境有关,即使程序设计无误,仍然可能因使用的问题而引发。Java 编译器要求方法必须声明抛出可能发生的受检异常,但是并不要求必须声明抛出未被捕获的运行时异常。异常和继承一样,是面向对象程序设计中经常被滥用的东西,神作《Effective Java》中对异常的使用给出了以下指导原则:
- 不要将异常处理用于正常的控制流(设计良好的 API 不应该强迫它的调用者为了正常的控制流而使用异常)
- 对可以恢复的情况使用受检异常,对编程错误使用运行时异常
- 避免不必要的使用受检异常(可以通过一些状态检测手段来避免异常的发生)
- 优先使用标准的异常
- 每个方法抛出的异常都要有文档
- 保持异常的原子性
- 不要在 catch 中忽略掉捕获到的异常
# 669.Java 语言如何进行异常处理,关键字:throws、throw、try、catch、f inally 分别如何使用-Java面试题
Java 通过面向对象的方法进行异常处理,把各种不同的异常进行分类,并提供了良好的接口。在 Java 中,每个异常都是一个对象,它是 Throwable 类或其子类的实例。当一个方法出现异常后便抛出一个异常对象,该对象中包含有异常信息,调用这个对象的方法可以捕获到这个异常并进行处理。Java 的异常处理是通过 5 个关键词来实现的:try、catch、throw、throws 和 finally。
一般情况下是用 try 来执行一段程序,如果出现异常,系统会抛出(throw)一个异常,这时候你可以通过它的类型来捕捉(catch)它,或最后(finally)由缺省处理器来处理;try 用来指定一块预防所有“异常”的程序;catch 子句紧跟在 try 块后面,用来指定你想要捕捉的“异常”的类型;throw 语句用来明确地抛出一个“异常”;throws 用来标明一个成员函数可能抛出的各种“异常”;finally 为确保一段代码不管发生什么“异常”都被执行一段代码;可以在一个成员函数调用的外面写一个 try 语句,在这个成员函数内部写另一个 try 语句保护其他代码。每当遇到一个 try 语句,“异常”的框架就放到栈上面,直到所有的try 语句都完成。如果下一级的 try 语句没有对某种“异常”进行处理,栈就会展开,直到遇到有处理这种“异常”的 try 语句
# 668.try{}里有一个 return 语句,那么紧跟在这个 try 后的 finally{}里的 code 会不会被执行,什么时候被执行,在 return 前还是后?-Java面试题
会执行,在方法返回调用者前执行。Java 允许在 finally 中改变返回值的做法是不好的,因为如果存在 finally 代码块,try 中的 return 语句不会立马返回调用者,而是记录下返回值待 finally 代码块执行完毕之后再向调用者返回其值,然后如果在 finally 中修改了返回值,这会对程序造成很大的困扰,C#中就从语法上规定不能做这样的事。
# 667.Error 和 Exception 有什么区别-Java面试题
Error 表示系统级的错误和程序不必处理的异常,是恢复不是不可能但很困难的情况下的一种严重问题;比如内存溢出,不可能指望程序能处理这样的情况;Exception 表示需要捕捉或者需要程序进行处理的异常,是一种设计或实现问题;也就是说,它表示如果程序运行正常,从不会发生的情况。
# 666.什么时候用 assert?-Java面试题
assertion(断言)在软件开发中是一种常用的调试方式,很多开发语言中都支持这种机制。一般来说,assertion 用于保证程序最基本、关键的正确性。assertion 检查通常在开发和测试时开启。为了提高性能,在软件发布后, assertion 检查通常是关闭的。在实现中,断言是一个包含布尔表达式的语句,在执行这个语句时假定该表达式为 true;如果表达式计算为 false,那么系统会报告一个AssertionError。
断言用于调试目的:
assert(a > 0); // throws an AssertionError if a <= 0
断言可以有两种形式:
assert Expression1; assert Expression1 : Expression2 ;
Expression1 应该总是产生一个布尔值。
Expression2 可以是得出一个值的任意表达式;这个值用于生成显示更多调试信息的字符串消息。
断言在默认情况下是禁用的,要在编译时启用断言,需使用 source 1.4 标记:
javac -source 1.4 Test.java
要在运行时启用断言,可使用-enableassertions 或者-ea 标记。
要在运行时选择禁用断言,可使用-da 或者-disableassertions 标记。
要在系统类中启用断言,可使用-esa 或者-dsa 标记。还可以在包的基础上启用或者禁用断言。可以在预计正常情况下不会到达的任何位置上放置断言。断言可以用于验证传递给私有方法的参数。不过,断言不应该用于验证传递给公有方法的参数,因为不管是否启用了断言,公有方法都必须检查其参数。不过,既可以在公有方法中,也可以在非公有方法中利用断言测试后置条件。另外,断言不应该以任何方式改变程序的状态。
# 665.比较一下 Java 和 JavaSciprt-Java面试题
JavaScript 与 Java 是两个公司开发的不同的两个产品。Java 是原 Sun公司推出的面向对象的程序设计语言,特别适合于互联网应用程序开发;而 JavaScript 是 Netscape 公司的产品,为了扩展 Netscape 浏览器的功能而开发的一种可以嵌入 Web 页面中运行的基于对象和事件驱动的解释性语言,它的前身是 LiveScript;而 Java 的前身是 Oak 语言。下面对两种语言间的异同作如下比较:
- 基于对象和面向对象:Java 是一种真正的面向对象的语言,即使是开发简单的程序,必须设计对象;JavaScript 是种脚本语言,它可以用来制作与网络无关的,与用户交互作用的复杂软件。它是一种基于对象(Object-Based)和事件驱动(Event-Driven)的编程语言。因而它本身提供了非常丰富的内部对象供设计人员使用;
- 解释和编译:Java 的源代码在执行之前,必须经过编译;JavaScript 是一种解释性编程语言,其源代码不需经过编译,由浏览器解释执行;
- 强类型变量和类型弱变量:Java 采用强类型变量检查,即所有变量在编译之前必须作声明;JavaScript 中变量声明,采用其弱类型。即变量在使用前不需作声明,而是解释器在运行时检查其数据类型;
- 代码格式不一样。
补充:上面列出的四点是原来所谓的标准答案中给出的。其实 Java 和 JavaScript 最重要的区别是一个是静态语言,一个是动态语言。目前的编程语言的发展趋势是函数式语言和动态语言。在 Java 中类(class)是一等公民,而 JavaScript 中函数(function)是一等公民。对于这种问题,在面试时还是用自己的语言回答会更加靠谱。
# 664.打印昨天的当前时刻。-Java面试题

# 663.日期和时间-Java面试题
- 如何取得年月日、小时分钟秒?
- 如何取得从 1970 年 1 月 1 日 0 时 0 分 0 秒到现在的毫秒数?
- 如何取得某月的最后一天?
- 如何格式化日期?
答:操作方法如下所示:
- 创建 java.util.Calendar 实例,调用其 get()方法传入不同的参数即可获得参数所对应的值
- 以下方法均可获得该毫秒数:

- 示例代码如下:

- 利用 java.text.DataFormat 的子类(如 SimpleDateFormat 类)中的 format(Date)方法可将日期格式化。
# MyBatis启动流程-Java面试题
初识 MyBatis
MyBatis 是第一个支持自定义 SQL、存储过程和高级映射的类持久框架。MyBatis 消除了大部分 JDBC 的样板代码、手动设置参数以及检索结果。MyBatis 能够支持简单的 XML 和注解配置规则。使 Map 接口和 POJO 类映射到数据库字段和记录。
MyBatis 的特点
那么 MyBatis 具有什么特点呢?或许我们可以从如下几个方面来描述
- MyBatis 中的 SQL 语句和主要业务代码分离,我们一般会把 MyBatis 中的 SQL 语句统一放在 XML 配置文件中,便于统一维护。

- 解除 SQL 与程序代码的耦合,通过提供 DAO 层,将业务逻辑和数据访问逻辑分离,使系统的设计更清晰,更易维护,更易单元测试。SQL 和代码的分离,提高了可维护性。

- MyBatis 比较简单和轻量
本身就很小且简单。没有任何第三方依赖,只要通过配置 jar 包,或者如果你使用 Maven 项目的话只需要配置 Maven 以来就可以。易于使用,通过文档和源代码,可以比较完全的掌握它的设计思路和实现。
- 屏蔽样板代码
MyBatis 回屏蔽原始的 JDBC 样板代码,让你把更多的精力专注于 SQL 的书写和属性-字段映射上。
- 编写原生 SQL,支持多表关联

MyBatis 最主要的特点就是你可以手动编写 SQL 语句,能够支持多表关联查询。
- 提供映射标签,支持对象与数据库的 ORM 字段关系映射
ORM 是什么?
对象关系映射(Object Relational Mapping,简称ORM),是通过使用描述对象和数据库之间映射的元数据,将面向对象语言程序中的对象自动持久化到关系数据库中。本质上就是将数据从一种形式转换到另外一种形式。
- 提供 XML 标签,支持编写动态 SQL。
你可以使用 MyBatis XML 标签,起到 SQL 模版的效果,减少繁杂的 SQL 语句,便于维护。
MyBatis 整体架构
MyBatis 最上面是接口层,接口层就是开发人员在 Mapper 或者是 Dao 接口中的接口定义,是查询、新增、更新还是删除操作;中间层是数据处理层,主要是配置 Mapper -> XML 层级之间的参数映射,SQL 解析,SQL 执行,结果映射的过程。上述两种流程都由基础支持层来提供功能支撑,基础支持层包括连接管理,事务管理,配置加载,缓存处理等。

接口层
在不与Spring 集成的情况下,使用 MyBatis 执行数据库的操作主要如下:
InputStream is = Resources.getResourceAsStream("myBatis-config.xml"); SqlSessionFactoryBuilder builder = new SqlSessionFactoryBuilder(); SqlSessionFactory factory = builder.build(is); sqlSession = factory.openSession();
其中的SqlSessionFactory,SqlSession是 MyBatis 接口的核心类,尤其是 SqlSession,这个接口是MyBatis 中最重要的接口,这个接口能够让你执行命令,获取映射,管理事务。
数据处理层
- 配置解析
在 Mybatis 初始化过程中,会加载 mybatis-config.xml 配置文件、映射配置文件以及 Mapper 接口中的注解信息,解析后的配置信息会形成相应的对象并保存到 Configration 对象中。之后,根据该对象创建SqlSessionFactory 对象。待 Mybatis 初始化完成后,可以通过 SqlSessionFactory 创建 SqlSession 对象并开始数据库操作。
- SQL 解析与 scripting 模块
Mybatis 实现的动态 SQL 语句,几乎可以编写出所有满足需要的 SQL。
Mybatis 中 scripting 模块会根据用户传入的参数,解析映射文件中定义的动态 SQL 节点,形成数据库能执行的SQL 语句。
- SQL 执行
SQL 语句的执行涉及多个组件,包括 MyBatis 的四大核心,它们是: Executor、StatementHandler、ParameterHandler、ResultSetHandler。SQL 的执行过程可以用下面这幅图来表示

MyBatis 层级结构各个组件的介绍(这里只是简单介绍,具体介绍在后面):
SqlSession: ,它是 MyBatis 核心 API,主要用来执行命令,获取映射,管理事务。接收开发人员提供 Statement Id 和参数。并返回操作结果。Executor:执行器,是 MyBatis 调度的核心,负责 SQL 语句的生成以及查询缓存的维护。StatementHandler: 封装了JDBC Statement 操作,负责对 JDBC Statement 的操作,如设置参数、将Statement 结果集转换成 List 集合。ParameterHandler: 负责对用户传递的参数转换成 JDBC Statement 所需要的参数。ResultSetHandler: 负责将 JDBC 返回的 ResultSet 结果集对象转换成 List 类型的集合。TypeHandler: 用于 Java 类型和 JDBC 类型之间的转换。MappedStatement: 动态 SQL 的封装SqlSource: 表示从 XML 文件或注释读取的映射语句的内容,它创建将从用户接收的输入参数传递给数据库的 SQL。Configuration: MyBatis 所有的配置信息都维持在 Configuration 对象之中。
基础支持层
- 反射模块
Mybatis 中的反射模块,对 Java 反射进行了很好的封装,提供了简易的 API,方便上层调用,并且对反射操作进行了一系列的优化,比如,缓存了类的 元数据(MetaClass)和对象的元数据(MetaObject),提高了反射操作的性能。
- 类型转换模块
Mybatis 的别名机制,能够简化配置文件,该机制是类型转换模块的主要功能之一。类型转换模块的另一个功能是实现 JDBC 类型与 Java 类型的转换。在 SQL 语句绑定参数时,会将数据由 Java 类型转换成 JDBC 类型;在映射结果集时,会将数据由 JDBC 类型转换成 Java 类型。
- 日志模块
在 Java 中,有很多优秀的日志框架,如 Log4j、Log4j2、slf4j 等。Mybatis 除了提供了详细的日志输出信息,还能够集成多种日志框架,其日志模块的主要功能就是集成第三方日志框架。
- 资源加载模块
该模块主要封装了类加载器,确定了类加载器的使用顺序,并提供了加载类文件和其它资源文件的功能。
- 解析器模块
该模块有两个主要功能:一个是封装了 XPath,为 Mybatis 初始化时解析 mybatis-config.xml 配置文件以及映射配置文件提供支持;另一个为处理动态 SQL 语句中的占位符提供支持。
- 数据源模块
Mybatis 自身提供了相应的数据源实现,也提供了与第三方数据源集成的接口。数据源是开发中的常用组件之一,很多开源的数据源都提供了丰富的功能,如连接池、检测连接状态等,选择性能优秀的数据源组件,对于提供ORM 框架以及整个应用的性能都是非常重要的。
- 事务管理模块
一般地,Mybatis 与 Spring 框架集成,由 Spring 框架管理事务。但 Mybatis 自身对数据库事务进行了抽象,提供了相应的事务接口和简单实现。
- 缓存模块
Mybatis 中有一级缓存和二级缓存,这两级缓存都依赖于缓存模块中的实现。但是需要注意,这两级缓存与Mybatis 以及整个应用是运行在同一个 JVM 中的,共享同一块内存,如果这两级缓存中的数据量较大,则可能影响系统中其它功能,所以需要缓存大量数据时,优先考虑使用 Redis、Memcache 等缓存产品。
- Binding 模块
在调用 SqlSession 相应方法执行数据库操作时,需要制定映射文件中定义的 SQL 节点,如果 SQL 中出现了拼写错误,那就只能在运行时才能发现。为了能尽早发现这种错误,Mybatis 通过 Binding 模块将用户自定义的Mapper 接口与映射文件关联起来,系统可以通过调用自定义 Mapper 接口中的方法执行相应的 SQL 语句完成数据库操作,从而避免上述问题。注意,在开发中,我们只是创建了 Mapper 接口,而并没有编写实现类,这是因为 Mybatis 自动为 Mapper 接口创建了动态代理对象。
MyBatis 核心组件
在认识了 MyBatis 并了解其基础架构之后,下面我们来看一下 MyBatis 的核心组件,就是这些组件实现了从 SQL 语句到映射到 JDBC 再到数据库字段之间的转换,执行 SQL 语句并输出结果集。首先来认识 MyBatis 的第一个核心组件
SqlSessionFactory
对于任何框架而言,在使用该框架之前都要经历过一系列的初始化流程,MyBatis 也不例外。MyBatis 的初始化流程如下
String resource = "org/mybatis/example/mybatis-config.xml"; InputStream inputStream = Resources.getResourceAsStream(resource); SqlSessionFactory sqlSessionFactory = new SqlSessionFactoryBuilder().build(inputStream); sqlSessionFactory.openSession();
上述流程中比较重要的一个对象就是SqlSessionFactory,SqlSessionFactory 是 MyBatis 框架中的一个接口,它主要负责的是
- MyBatis 框架初始化操作
- 为开发人员提供
SqlSession对象

SqlSessionFactory 有两个实现类,一个是 SqlSessionManager 类,一个是 DefaultSqlSessionFactory 类
DefaultSqlSessionFactory: SqlSessionFactory 的默认实现类,是真正生产会话的工厂类,这个类的实例的生命周期是全局的,它只会在首次调用时生成一个实例(单例模式),就一直存在直到服务器关闭。SqlSessionManager : 已被废弃,原因大概是: SqlSessionManager 中需要维护一个自己的线程池,而使用MyBatis 更多的是要与 Spring 进行集成,并不会单独使用,所以维护自己的 ThreadLocal 并没有什么意义,所以 SqlSessionManager 已经不再使用。
SqlSessionFactory 的执行流程
下面来对 SqlSessionFactory 的执行流程来做一个分析
首先第一步是 SqlSessionFactory 的创建
SqlSessionFactory sqlSessionFactory = new SqlSessionFactoryBuilder().build(inputStream);
从这行代码入手,首先创建了一个 SqlSessionFactoryBuilder 工厂,这是一个建造者模式的设计思想,由 builder 建造者来创建 SqlSessionFactory 工厂
然后调用 SqlSessionFactoryBuilder 中的 build 方法传递一个InputStream 输入流,Inputstream 输入流中就是你传过来的配置文件 mybatis-config.xml,SqlSessionFactoryBuilder 根据传入的 InputStream 输入流和environment、properties属性创建一个XMLConfigBuilder对象。SqlSessionFactoryBuilder 对象调用XMLConfigBuilder 的parse()方法,流程如下。

XMLConfigBuilder 会解析/configuration标签,configuration 是 MyBatis 中最重要的一个标签,下面流程会介绍 Configuration 标签。
MyBatis 默认使用 XPath 来解析标签,关于 XPath 的使用,参见 https://www.w3school.com.cn/xpath/index.asp
在 parseConfiguration 方法中,会对各个在 /configuration 中的标签进行解析

重要配置
说一下这些标签都是什么意思吧
properties,外部属性,这些属性都是可外部配置且可动态替换的,既可以在典型的 Java 属性文件中配置,亦可通过 properties 元素的子元素来传递。
<properties> <property name="driver" value="com.mysql.jdbc.Driver" /> <property name="url" value="jdbc:mysql://localhost:3306/test" /> <property name="username" value="root" /> <property name="password" value="root" /> </properties>
一般用来给 environment 标签中的 dataSource 赋值
<environment id="development"> <transactionManager type="JDBC" /> <dataSource type="POOLED"> <property name="driver" value="${driver}" /> <property name="url" value="${url}" /> <property name="username" value="${username}" /> <property name="password" value="${password}" /> </dataSource> </environment>
还可以通过外部属性进行配置,但是我们这篇文章以原理为主,不会介绍太多应用层面的操作。
settings,MyBatis 中极其重要的配置,它们会改变 MyBatis 的运行时行为。
settings 中配置有很多,具体可以参考 https://mybatis.org/mybatis-3/zh/configuration.html#settings 详细了解。这里介绍几个平常使用过程中比较重要的配置
| 属性 | 描述 |
|---|---|
| cacheEnabled | 全局地开启或关闭配置文件中的所有映射器已经配置的任何缓存。 |
| useGeneratedKeys | 允许 JDBC 支持自动生成主键,需要驱动支持。 如果设置为 true 则这个设置强制使用自动生成主键。 |
| lazyLoadingEnabled | 延迟加载的全局开关。当开启时,所有关联对象都会延迟加载。 |
| jdbcTypeForNull | 当没有为参数提供特定的 JDBC 类型时,为空值指定 JDBC 类型。 某些驱动需要指定列的 JDBC 类型,多数情况直接用一般类型即可,比如 NULL、VARCHAR 或 OTHER。 |
| defaultExecutorType | 配置默认的执行器。SIMPLE 就是普通的执行器;REUSE 执行器会重用预处理语句(prepared statements); BATCH 执行器将重用语句并执行批量更新。 |
| localCacheScope | MyBatis 利用本地缓存机制(Local Cache)防止循环引用(circular references)和加速重复嵌套查询。 默认值为 SESSION,这种情况下会缓存一个会话中执行的所有查询。 若设置值为 STATEMENT,本地会话仅用在语句执行上,对相同 SqlSession 的不同调用将不会共享数据 |
| proxyFactory | 指定 Mybatis 创建具有延迟加载能力的对象所用到的代理工具。 |
| mapUnderscoreToCamelCase | 是否开启自动驼峰命名规则(camel case)映射,即从经典数据库列名 A_COLUMN 到经典 Java 属性名 aColumn 的类似映射。 |
一般使用如下配置
<settings> <setting name="cacheEnabled" value="true"/> <setting name="lazyLoadingEnabled" value="true"/> </settings>
typeAliases,类型别名,类型别名是为 Java 类型设置的一个名字。 它只和 XML 配置有关。
<typeAliases> <typeAlias alias="Blog" type="domain.blog.Blog"/> </typeAliases>
当这样配置时,Blog 可以用在任何使用 domain.blog.Blog 的地方。
typeHandlers,类型处理器,无论是 MyBatis 在预处理语句(PreparedStatement)中设置一个参数时,还是从结果集中取出一个值时, 都会用类型处理器将获取的值以合适的方式转换成 Java 类型。
在 org.apache.ibatis.type 包下有很多已经实现好的 TypeHandler,可以参考如下

你可以重写类型处理器或创建你自己的类型处理器来处理不支持的或非标准的类型。
具体做法为:实现 org.apache.ibatis.type.TypeHandler 接口, 或继承一个很方便的类 org.apache.ibatis.type.BaseTypeHandler, 然后可以选择性地将它映射到一个 JDBC 类型。
objectFactory,对象工厂,MyBatis 每次创建结果对象的新实例时,它都会使用一个对象工厂(ObjectFactory)实例来完成。默认的对象工厂需要做的仅仅是实例化目标类,要么通过默认构造方法,要么在参数映射存在的时候通过参数构造方法来实例化。如果想覆盖对象工厂的默认行为,则可以通过创建自己的对象工厂来实现。
public class ExampleObjectFactory extends DefaultObjectFactory { public Object create(Class type) { return super.create(type); } public Object create(Class type, List<Class> constructorArgTypes, List<Object> constructorArgs) { return super.create(type, constructorArgTypes, constructorArgs); } public void setProperties(Properties properties) { super.setProperties(properties); } public <T> boolean isCollection(Class<T> type) { return Collection.class.isAssignableFrom(type); } }
然后需要在 XML 中配置此对象工厂
<objectFactory type="org.mybatis.example.ExampleObjectFactory"> <property name="someProperty" value="100"/> </objectFactory>
plugins,插件开发,插件开发是 MyBatis 设计人员给开发人员留给自行开发的接口,MyBatis 允许你在已映射语句执行过程中的某一点进行拦截调用。MyBatis 允许使用插件来拦截的方法调用包括:Executor、ParameterHandler、ResultSetHandler、StatementHandler 接口,这几个接口也是 MyBatis 中非常重要的接口,我们下面会详细介绍这几个接口。environments,MyBatis 环境配置,MyBatis 可以配置成适应多种环境,这种机制有助于将 SQL 映射应用于多种数据库之中。例如,开发、测试和生产环境需要有不同的配置;或者想在具有相同 Schema 的多个生产数据库中 使用相同的 SQL 映射。这里注意一点,虽然 environments 可以指定多个环境,但是 SqlSessionFactory 只能有一个,为了指定创建哪种环境,只要将它作为可选的参数传递给 SqlSessionFactoryBuilder 即可。
SqlSessionFactory factory = new SqlSessionFactoryBuilder().build(reader, environment); SqlSessionFactory factory = new SqlSessionFactoryBuilder().build(reader, environment, properties);
环境配置如下
databaseIdProvider,数据库厂商标示,MyBatis 可以根据不同的数据库厂商执行不同的语句,这种多厂商的支持是基于映射语句中的databaseId属性。
<!-- 使用相对于类路径的资源引用 -->
<mappers>
<mapper resource="org/mybatis/builder/AuthorMapper.xml" />
<mapper resource="org/mybatis/builder/BlogMapper.xml" />
<mapper resource="org/mybatis/builder/PostMapper.xml" />
</mappers>
<!-- 使用完全限定资源定位符(URL) -->
<mappers>
<mapper url="file:///var/mappers/AuthorMapper.xml" />
<mapper url="file:///var/mappers/BlogMapper.xml" />
<mapper url="file:///var/mappers/PostMapper.xml" />
</mappers>
<!-- 使用映射器接口实现类的完全限定类名 -->
<mappers>
<mapper class="org.mybatis.builder.AuthorMapper" />
<mapper class="org.mybatis.builder.BlogMapper" />
<mapper class="org.mybatis.builder.PostMapper" />
</mappers>
<!-- 将包内的映射器接口实现全部注册为映射器 -->
<mappers>
<package name="org.mybatis.builder" />
</mappers></p> </li>
上面的一个个属性都对应着一个解析方法,都是使用 XPath 把标签进行解析,解析完成后返回一个 DefaultSqlSessionFactory 对象,它是 SqlSessionFactory 的默认实现类。这就是 SqlSessionFactoryBuilder 的初始化流程,通过流程我们可以看到,初始化流程就是对一个个 /configuration 标签下子标签的解析过程。
SqlSession
在 MyBatis 初始化流程结束,也就是 SqlSessionFactoryBuilder -> SqlSessionFactory 的获取流程后,我们就可以通过 SqlSessionFactory 对象得到 SqlSession 然后执行 SQL 语句了。具体来看一下这个过程

在 SqlSessionFactory.openSession 过程中我们可以看到,会调用到 DefaultSqlSessionFactory 中的 openSessionFromDataSource 方法,这个方法主要创建了两个与我们分析执行流程重要的对象,一个是 Executor 执行器对象,一个是 SqlSession 对象。执行器我们下面会说,现在来说一下 SqlSession 对象
SqlSession 对象是 MyBatis 中最重要的一个对象,这个接口能够让你执行命令,获取映射,管理事务。SqlSession 中定义了一系列模版方法,让你能够执行简单的 CRUD 操作,也可以通过 getMapper 获取 Mapper 层,执行自定义 SQL 语句,因为 SqlSession 在执行 SQL 语句之前是需要先开启一个会话,涉及到事务操作,所以还会有 commit、 rollback、close 等方法。这也是模版设计模式的一种应用。
MapperProxy
MapperProxy 是 Mapper 映射 SQL 语句的关键对象,我们写的 Dao 层或者 Mapper 层都是通过 MapperProxy 来和对应的 SQL 语句进行绑定的。下面我们就来解释一下绑定过程

这就是 MyBatis 的核心绑定流程,我们可以看到 SqlSession 首先调用 getMapper 方法,我们刚才说到 SqlSession 是大哥级别的人物,只定义标准(有一句话是怎么说的来着,一流的企业做标准,二流的企业做品牌,三流的企业做产品)。
SqlSession 不愿意做的事情交给 Configuration 这个手下去做,但是 Configuration 也是有小弟的,它不愿意做的事情直接甩给小弟去做,这个小弟是谁呢?它就是 MapperRegistry,马上就到核心部分了。MapperRegistry 相当于项目经理,项目经理只从大面上把握项目进度,不需要知道手下的小弟是如何工作的,把任务完成了就好。最终真正干活的还是 MapperProxyFactory。看到这段代码 Proxy.newProxyInstance ,你是不是有一种恍然大悟的感觉,如果你没有的话,建议查阅一下动态代理的文章,这里推荐一篇 (https://www.jianshu.com/p/95970b089360)
也就是说,MyBatis 中 Mapper 和 SQL 语句的绑定正是通过动态代理来完成的。
通过动态代理,我们就可以方便的在 Dao 层或者 Mapper 层定义接口,实现自定义的增删改查操作了。那么具体的执行过程是怎么样呢?上面只是绑定过程,别着急,下面就来探讨一下 SQL 语句的执行过程。

有一部分代码被遮挡,代码有些多,不过不影响我们看主要流程
MapperProxyFactory 会生成代理对象,这个对象就是 MapperProxy,最终会调用到 mapperMethod.execute 方法,execute 方法比较长,其实逻辑比较简单,就是判断是 插入、更新、删除 还是 查询 语句,其中如果是查询的话,还会判断返回值的类型,我们可以点进去看一下都是怎么设计的。

很多代码其实可以忽略,只看我标出来的重点就好了,我们可以看到,不管你前面经过多少道关卡处理,最终都逃不过 SqlSession 这个老大制定的标准。
我们以 selectList 为例,来看一下下面的执行过程。

这是 DefaultSqlSession 中 selectList 的代码,我们可以看到出现了 executor,这是什么呢?我们下面来解释。
Executor
还记得我们之前的流程中提到了 Executor(执行器) 这个概念吗?我们来回顾一下它第一次出现的位置。

由 Configuration 对象创建了一个 Executor 对象,这个 Executor 是干嘛的呢?下面我们就来认识一下
Executor 的继承结构
每一个 SqlSession 都会拥有一个 Executor 对象,这个对象负责增删改查的具体操作,我们可以简单的将它理解为 JDBC 中 Statement 的封装版。 也可以理解为 SQL 的执行引擎,要干活总得有一个发起人吧,可以把 Executor 理解为发起人的角色。
首先先从 Executor 的继承体系来认识一下

如上图所示,位于继承体系最顶层的是 Executor 执行器,它有两个实现类,分别是BaseExecutor和 CachingExecutor。
BaseExecutor 是一个抽象类,这种通过抽象的实现接口的方式是适配器设计模式之接口适配 的体现,是Executor 的默认实现,实现了大部分 Executor 接口定义的功能,降低了接口实现的难度。BaseExecutor 的子类有三个,分别是 SimpleExecutor、ReuseExecutor 和 BatchExecutor。
SimpleExecutor : 简单执行器,是 MyBatis 中默认使用的执行器,每执行一次 update 或 select,就开启一个Statement 对象,用完就直接关闭 Statement 对象(可以是 Statement 或者是 PreparedStatment 对象)
ReuseExecutor : 可重用执行器,这里的重用指的是重复使用 Statement,它会在内部使用一个 Map 把创建的Statement 都缓存起来,每次执行 SQL 命令的时候,都会去判断是否存在基于该 SQL 的 Statement 对象,如果存在 Statement 对象并且对应的 connection 还没有关闭的情况下就继续使用之前的 Statement 对象,并将其缓存起来。因为每一个 SqlSession 都有一个新的 Executor 对象,所以我们缓存在 ReuseExecutor 上的 Statement作用域是同一个 SqlSession。
BatchExecutor : 批处理执行器,用于将多个 SQL 一次性输出到数据库
CachingExecutor: 缓存执行器,先从缓存中查询结果,如果存在就返回之前的结果;如果不存在,再委托给Executor delegate 去数据库中取,delegate 可以是上面任何一个执行器。
Executor 的创建和选择
我们上面提到 Executor 是由 Configuration 创建的,Configuration 会根据执行器的类型创建,如下

这一步就是执行器的创建过程,根据传入的 ExecutorType 类型来判断是哪种执行器,如果不指定 ExecutorType ,默认创建的是简单执行器。它的赋值可以通过两个地方进行赋值:
- 可以通过
<settings>标签来设置当前工程中所有的 SqlSession 对象使用默认的 Executor
<settings> <!--取值范围 SIMPLE, REUSE, BATCH --> <setting name="defaultExecutorType" value="SIMPLE"/> </settings>
- 另外一种直接通过Java对方法赋值的方式
session = factory.openSession(ExecutorType.BATCH);
Executor 的具体执行过程
Executor 中的大部分方法的调用链其实是差不多的,下面是深入源码分析执行过程,如果你没有时间或者暂时不想深入研究的话,给你下面的执行流程图作为参考。

我们紧跟着上面的 selectList 继续分析,它会调用到 executor.query 方法。
当有一个查询请求访问的时候,首先会经过 Executor 的实现类 CachingExecutor ,先从缓存中查询 SQL 是否是第一次执行,如果是第一次执行的话,那么就直接执行 SQL 语句,并创建缓存,如果第二次访问相同的 SQL 语句的话,那么就会直接从缓存中提取。

上面这段代码是从 selectList -> 从缓存中 query 的具体过程。可能你看到这里有些觉得类都是什么东西,我想鼓励你一下,把握重点,不用每段代码都看,从找到 SQL 的调用链路,其他代码想看的时候在看,看源码就是很容易发蒙,容易烦躁,但是切记一点,把握重点。

上面代码会判断缓存中是否有这条 SQL 语句的执行结果,如果没有的话,就再重新创建 Executor 执行器执行 SQL 语句,注意, list = doQuery 是真正执行 SQL 语句的过程,这个过程中会创建我们上面提到的三种执行器,这里我们使用的是简单执行器。
到这里,执行器所做的工作就完事了,Executor 会把后续的工作交给 StatementHandler 继续执行。下面我们来认识一下 StatementHandler
StatementHandler
StatementHandler 是四大组件中最重要的一个对象,负责操作 Statement 对象与数据库进行交互,在工作时还会使用 ParameterHandler 和 ResultSetHandler对参数进行映射,对结果进行实体类的绑定,这两个组件我们后面说。
我们在搭建原生 JDBC 的时候,会有这样一行代码
Statement stmt = conn.createStatement(); //也可以使用PreparedStatement来做
这行代码创建的 Statement 对象或者是 PreparedStatement 对象就是由 StatementHandler 进行管理的。
StatementHandler 的继承结构

有没有感觉和 Executor 的继承体系很相似呢?最顶级接口是四大组件对象,分别有两个实现类 BaseStatementHandler 和 RoutingStatementHandler ,BaseStatementHandler 有三个实现类, 他们分别是 SimpleStatementHandler、PreparedStatementHandler 和 CallableStatementHandler。
RoutingStatementHandler : RoutingStatementHandler 并没有对 Statement 对象进行使用,只是根据StatementType 来创建一个代理,代理的就是对应Handler的三种实现类。在MyBatis工作时,使用的StatementHandler 接口对象实际上就是 RoutingStatementHandler 对象。
BaseStatementHandler : 是 StatementHandler 接口的另一个实现类,它本身是一个抽象类,用于简化StatementHandler 接口实现的难度,属于适配器设计模式体现,它主要有三个实现类
- SimpleStatementHandler: 管理 Statement 对象并向数据库中推送不需要预编译的SQL语句。
- PreparedStatementHandler: 管理 Statement 对象并向数据中推送需要预编译的SQL语句。
- CallableStatementHandler:管理 Statement 对象并调用数据库中的存储过程。
这里注意一下,SimpleStatementHandler 和 PreparedStatementHandler 的区别是 SQL 语句是否包含变量,是否通过外部进行参数传入。
SimpleStatementHandler 用于执行没有任何参数传入的 SQL
PreparedStatementHandler 需要对外部传入的变量和参数进行提前参数绑定和赋值。
StatementHandler 的创建和源码分析
我们继续来分析上面 query 的调用链路,StatementHandler 的创建过程如下

MyBatis 会根据 SQL 语句的类型进行对应 StatementHandler 的创建。我们以预处理 StatementHandler 为例来讲解一下

执行器不仅掌管着 StatementHandler 的创建,还掌管着创建 Statement 对象,设置参数等,在创建完 PreparedStatement 之后,我们需要对参数进行处理了。
如果用一副图来表示一下这个执行流程的话我想是这样

这里我们先暂停一下,来认识一下第三个核心组件 ParameterHandler
ParameterHandler
ParameterHandler 介绍
ParameterHandler 相比于其他的组件就简单很多了,ParameterHandler 译为参数处理器,负责为 PreparedStatement 的 sql 语句参数动态赋值,这个接口很简单只有两个方法

ParameterHandler 只有一个实现类 DefaultParameterHandler , 它实现了这两个方法。
- getParameterObject: 用于读取参数
- setParameters: 用于对 PreparedStatement 的参数赋值
ParameterHandler 的解析过程
上面我们讨论过了 ParameterHandler 的创建过程,下面我们继续上面 parameterSize 流程

这就是具体参数的解析过程了,下面我们来描述一下
public void setParameters(PreparedStatement ps) { ErrorContext.instance().activity("setting parameters").object(mappedStatement.getParameterMap().getId()); // parameterMappings 就是对 #{} 或者 ${} 里面参数的封装 List<ParameterMapping> parameterMappings = boundSql.getParameterMappings(); if (parameterMappings != null) { // 如果是参数化的SQL,便需要循环取出并设置参数的值 for (int i = 0; i < parameterMappings.size(); i++) { ParameterMapping parameterMapping = parameterMappings.get(i); // 如果参数类型不是 OUT ,这个类型与 CallableStatementHandler 有关 // 因为存储过程不存在输出参数,所以参数不是输出参数的时候,就需要设置。 if (parameterMapping.getMode() != ParameterMode.OUT) { Object value; // 得到 #{} 中的属性名 String propertyName = parameterMapping.getProperty(); // 如果 propertyName 是 Map 中的key if (boundSql.hasAdditionalParameter(propertyName)) { // issue #448 ask first for additional params // 通过key 来得到 additionalParameter 中的value值 value = boundSql.getAdditionalParameter(propertyName); } // 如果不是 additionalParameters 中的key,而且传入参数是 null, 则value 就是null else if (parameterObject == null) { value = null; } // 如果 typeHandlerRegistry 中已经注册了这个参数的 Class 对象,即它是 Primitive 或者是String 的话 else if (typeHandlerRegistry.hasTypeHandler(parameterObject.getClass())) { value = parameterObject; } else { // 否则就是 Map MetaObject metaObject = configuration.newMetaObject(parameterObject); value = metaObject.getValue(propertyName); } // 在通过 SqlSource 的parse 方法得到parameterMappings 的具体实现中,我们会得到parameterMappings 的 typeHandler TypeHandler typeHandler = parameterMapping.getTypeHandler(); // 获取 typeHandler 的jdbc type JdbcType jdbcType = parameterMapping.getJdbcType(); if (value == null && jdbcType == null) { jdbcType = configuration.getJdbcTypeForNull(); } try { typeHandler.setParameter(ps, i + 1, value, jdbcType); } catch (TypeException e) { throw new TypeException("Could not set parameters for mapping: " + parameterMapping + ". Cause: " + e, e); } catch (SQLException e) { throw new TypeException("Could not set parameters for mapping: " + parameterMapping + ". Cause: " + e, e); } } } } }
下面用一个流程图表示一下 ParameterHandler 的解析过程,以简单执行器为例

我们在完成 ParameterHandler 对 SQL 参数的预处理后,回到 SimpleExecutor 中的 doQuery 方法

上面又引出来了一个重要的组件那就是 ResultSetHandler,下面我们来认识一下这个组件
ResultSetHandler
ResultSetHandler 简介
ResultSetHandler 也是一个非常简单的接口

ResultSetHandler 是一个接口,它只有一个默认的实现类,像是 ParameterHandler 一样,它的默认实现类是DefaultResultSetHandler
ResultSetHandler 解析过程
MyBatis 只有一个默认的实现类就是 DefaultResultSetHandler,DefaultResultSetHandler 主要负责处理两件事
处理 Statement 执行后产生的结果集,生成结果列表
处理存储过程执行后的输出参数
按照 Mapper 文件中配置的 ResultType 或 ResultMap 来封装成对应的对象,最后将封装的对象返回即可。
public List<Object> handleResultSets(Statement stmt) throws SQLException { ErrorContext.instance().activity("handling results").object(mappedStatement.getId());
final List<Object> multipleResults = new ArrayList<Object>();
int resultSetCount = 0; // 获取第一个结果集 ResultSetWrapper rsw = getFirstResultSet(stmt); // 获取结果映射 List<ResultMap> resultMaps = mappedStatement.getResultMaps(); // 结果映射的大小 int resultMapCount = resultMaps.size(); // 校验结果映射的数量 validateResultMapsCount(rsw, resultMapCount); // 如果ResultSet 包装器不是null, 并且 resultmap 的数量 > resultSet 的数量的话 // 因为 resultSetCount 第一次肯定是0,所以直接判断 ResultSetWrapper 是否为 0 即可 while (rsw != null && resultMapCount > resultSetCount) { // 从 resultMap 中取出 resultSet 数量 ResultMap resultMap = resultMaps.get(resultSetCount); // 处理结果集, 关闭结果集 handleResultSet(rsw, resultMap, multipleResults, null); rsw = getNextResultSet(stmt); cleanUpAfterHandlingResultSet(); resultSetCount++; }
// 从 mappedStatement 取出结果集 String[] resultSets = mappedStatement.getResultSets(); if (resultSets != null) { while (rsw != null && resultSetCount < resultSets.length) { ResultMapping parentMapping = nextResultMaps.get(resultSets[resultSetCount]); if (parentMapping != null) { String nestedResultMapId = parentMapping.getNestedResultMapId(); ResultMap resultMap = configuration.getResultMap(nestedResultMapId); handleResultSet(rsw, resultMap, null, parentMapping); } rsw = getNextResultSet(stmt); cleanUpAfterHandlingResultSet(); resultSetCount++; } }
return collapseSingleResultList(multipleResults); }
其中涉及的主要对象有:
ResultSetWrapper : 结果集的包装器,主要针对结果集进行的一层包装,它的主要属性有
ResultSet: Java JDBC ResultSet 接口表示数据库查询的结果。 有关查询的文本显示了如何将查询结果作为java.sql.ResultSet 返回。 然后迭代此ResultSet以检查结果。TypeHandlerRegistry: 类型注册器,TypeHandlerRegistry 在初始化的时候会把所有的 Java类型和类型转换器进行注册。ColumnNames: 字段的名称,也就是查询操作需要返回的字段名称ClassNames: 字段的类型名称,也就是 ColumnNames 每个字段名称的类型JdbcTypes: JDBC 的类型,也就是 java.sql.Types 类型ResultMap: 负责处理更复杂的映射关系
在 DefaultResultSetHandler 中处理完结果映射,并把上述结构返回给调用的客户端,从而执行完成一条完整的SQL语句。
# MyBatis核心配置综述之StatementHandler-Java面试题
MyBatis 四大组件之StatementHandler
StatementHandler 是四大组件中最重要的一个对象,负责操作 Statement 对象与数据库进行交流,在工作时还会使用 ParameterHandler 和 ResultSetHandler 对参数进行映射,对结果进行实体类的绑定
我们在搭建原生JDBC的时候,会有这样一行代码
Statement stmt = conn.createStatement(); //也可以使用PreparedStatement来做
这行代码创建的 Statement 对象或者是 PreparedStatement 对象就是由StatementHandler进行管理的。
StatementHandler 的基本构成
来看一下StatementHandler中的主要方法:

- prepare: 用于创建一个具体的 Statement 对象的实现类或者是 Statement 对象
- parametersize: 用于初始化 Statement 对象以及对sql的占位符进行赋值
- update: 用于通知 Statement 对象将 insert、update、delete 操作推送到数据库
- query: 用于通知 Statement 对象将 select 操作推送数据库并返回对应的查询结果
StatementHandler的继承结构

有没有感觉和 Executor 的继承体系很相似呢?最顶级接口是四大组件对象,分别有两个实现类 BaseStatementHandler 和 RoutingStatementHandler ,BaseStatementHandler 有三个实现类, 他们分别是 SimpleStatementHandler、PreparedStatementHandler 和 CallableStatementHandler。
RoutingStatementHandler: RoutingStatementHandler 并没有对 Statement 对象进行使用,只是根据StatementType 来创建一个代理,代理的就是对应Handler的三种实现类。在MyBatis工作时,使用的StatementHandler 接口对象实际上就是 RoutingStatementHandler 对象.我们可以理解为
StatementHandler statmentHandler = new RountingStatementHandler();
public RoutingStatementHandler(Executor executor, MappedStatement ms, Object parameter, RowBounds rowBounds, ResultHandler resultHandler, BoundSql boundSql) {
// 根据 statementType 创建对应的 Statement 对象 switch (ms.getStatementType()) { case STATEMENT: delegate = new SimpleStatementHandler(executor, ms, parameter, rowBounds, resultHandler, boundSql); break; case PREPARED: delegate = new PreparedStatementHandler(executor, ms, parameter, rowBounds, resultHandler, boundSql); break; case CALLABLE: delegate = new CallableStatementHandler(executor, ms, parameter, rowBounds, resultHandler, boundSql); break; default: throw new ExecutorException("Unknown statement type: " + ms.getStatementType()); }
}
BaseStatementHandler: 是 StatementHandler 接口的另一个实现类.本身是一个抽象类.用于简化StatementHandler 接口实现的难度,属于适配器设计模式体现,它主要有三个实现类
- SimpleStatementHandler: 管理 Statement 对象并向数据库中推送不需要预编译的SQL语句
- PreparedStatementHandler: 管理 Statement 对象并向数据中推送需要预编译的SQL语句,
- CallableStatementHandler:管理 Statement 对象并调用数据库中的存储过程
StatementHandler 对象创建以及源码分析
StatementHandler 对象是在 SqlSession 对象接收到命令操作时,由 Configuration 对象中的newStatementHandler 负责调用的,也就是说 Configuration 中的 newStatementHandler 是由执行器中的查询、更新(插入、更新、删除)方法来提供的,StatementHandler 其实就是由 Executor 负责管理和创建的。
SimpleExecutor.java
public <E> List<E> doQuery(MappedStatement ms, Object parameter, RowBounds rowBounds, ResultHandler resultHandler, BoundSql boundSql) throws SQLException { Statement stmt = null; try { // 获取环境配置 Configuration configuration = ms.getConfiguration(); // 创建StatementHandler,解析SQL语句 StatementHandler handler = configuration.newStatementHandler(wrapper, ms, parameter, rowBounds, resultHandler, boundSql); stmt = prepareStatement(handler, ms.getStatementLog()); // 由handler来对SQL语句执行解析工作 return handler.<E>query(stmt, resultHandler); } finally { closeStatement(stmt); } }

由图中可以看出,StatementHandler 默认创建一个 RoutingStatementHandler ,这也就是 StatementHandler 的默认实现,由 RoutingStatementHandler 负责根据 StatementType 创建对应的StatementHandler 来处理调用。
prepare方法调用流程分析
prepare 方法的调用过程是这样的,在上面的源码分析过程中,我们分析到了执行器 Executor 在执行SQL语句的时候会创建 StatementHandler 对象,进而经过一系列的 StatementHandler 类型的判断并初始化。再拿到StatementHandler 返回的 statementhandler 对象的时候,会调用其prepareStatement()方法,下面就来一起看一下 preparedStatement() 方法(我们以简单执行器为例,因为创建其 StatementHandler 对象的流程和执行 preparedStatement() 方法的流程是差不多的):
SimpleExecutor.java
public <E> List<E> doQuery(MappedStatement ms, Object parameter, RowBounds rowBounds, ResultHandler resultHandler, BoundSql boundSql) throws SQLException { Statement stmt = null; try { // 获取环境配置 Configuration configuration = ms.getConfiguration(); // 创建StatementHandler,解析SQL语句 StatementHandler handler = configuration.newStatementHandler(wrapper, ms, parameter, rowBounds, resultHandler, boundSql);
stmt = prepareStatement(handler, ms.getStatementLog());
// 由handler来对SQL语句执行解析工作
return handler.<E>query(stmt, resultHandler);
} finally { closeStatement(stmt); } }
private Statement prepareStatement(StatementHandler handler, Log statementLog) throws SQLException { Statement stmt; Connection connection = getConnection(statementLog);
stmt = handler.prepare(connection, transaction.getTimeout());
handler.parameterize(stmt); return stmt; }
// prepare方法调用到 StatementHandler 的实现类RoutingStatementHandler,再由RoutingStatementHandler调用BaseStatementHandler中的prepare 方法
// RoutingStatementHandler.java @Override public Statement prepare(Connection connection, Integer transactionTimeout) throws SQLException { return delegate.prepare(connection, transactionTimeout); }
// BaseStatementHandler.java @Override public Statement prepare(Connection connection, Integer transactionTimeout) throws SQLException { ErrorContext.instance().sql(boundSql.getSql()); Statement statement = null; try { statement = instantiateStatement(connection); setStatementTimeout(statement, transactionTimeout); setFetchSize(statement); return statement; } ...
其中最重要的方法就是 instantiateStatement() 方法了,在得到数据库连接 connection 的对象的时候,会去调用 instantiateStatement() 方法,instantiateStatement 方法位于 StatementHandler 中,是一个抽象方法由子类去实现,实际执行的是三种 StatementHandler 中的一种,我们还以 SimpleStatementHandler 为例
protected Statement instantiateStatement(Connection connection) throws SQLException { if (mappedStatement.getResultSetType() != null) { return connection.createStatement(mappedStatement.getResultSetType().getValue(), ResultSet.CONCUR_READ_ONLY); } else { return connection.createStatement(); } }
从上面代码我们可以看到,instantiateStatement() 最终返回的也是Statement对象,经过一系列的调用会把statement 对象返回到 SimpleExecutor 简单执行器中,为 parametersize 方法所用。也就是说,prepare 方法负责生成 Statement 实例对象,而 parameterize 方法用于处理 Statement 实例多对应的参数。
parametersize 方法调用流程分析
parametersize 方法看的就比较畅快了,也是经由执行器来管理 parametersize 的方法调用,这次我们还想以SimpleStatementHandler 为例但是却不行了?为什么呢?因为 SimpleStatementHandler 是个空实现了,为什么是null呢?因为 SimpleStatementHandler 只负责处理简单SQL,能够直接查询得到结果的SQL,例如:
select studenname from Student
而 SimpleStatementHandler 又不涉及到参数的赋值问题,那么参数赋值该在哪里进行呢?实际上为参数赋值这步操作是在 PreparedStatementHandler 中进行的,因此我们的主要关注点在 PreparedStatementHandler 中的parameterize 方法
public void parameterize(Statement statement) throws SQLException { parameterHandler.setParameters((PreparedStatement) statement); }
我们可以看到,为参数赋值的工作是由一个叫做 parameterHandler 对象完成的,都是这样的吗?来看一下CallableStatementHandler
public void parameterize(Statement statement) throws SQLException { registerOutputParameters((CallableStatement) statement); parameterHandler.setParameters((CallableStatement) statement); }
上面代码可以看到,CallableStatementHandler 也是由 parameterHandler 进行参数赋值的。
那么这个 parameterHandler 到底是什么呢?这个问题能想到说明老兄你已经上道了,这也就是我们执行器的第三个组件。这个组件我们在下一节进行分析
update 方法调用流程分析
用一幅流程图来表示一下这个调用过程:

简单描述一下update 方法的执行过程:
- MyBatis 接收到 update 请求后会先找到 CachingExecutor 缓存执行器查询是否需要刷新缓存,然后找到BaseExecutor 执行 update 方法;
- BaseExecutor 基础执行器会清空一级缓存,然后交给再根据执行器的类型找到对应的执行器,继续执行 update 方法;
- 具体的执行器会先创建 Configuration 对象,根据 Configuration 对象调用 newStatementHandler 方法,返回 statementHandler 的句柄;
- 具体的执行器会调用 prepareStatement 方法,找到本类的 prepareStatement 方法后,再有prepareStatement 方法调用 StatementHandler 的子类 BaseStatementHandler 中的 prepare 方法
- BaseStatementHandler 中的 prepare 方法会调用 instantiateStatement 实例化具体的 Statement 对象并返回给具体的执行器对象
- 由具体的执行器对象调用 parameterize 方法给参数进行赋值。
续上上面的 parameter方法,具体交给 ParameterHandler 进行进一步的赋值处理
Query 查询方法几乎和 update 方法相同,这里就不再详细的举例说明了
# MyBatis核心配置综述之ResultSetHandler-Java面试题
我们之前介绍过了MyBatis 四大核心配置之 Executor、StatementHandler、 ParameterHandler,今天本文的主题是介绍一下 MyBatis 最后一个神器也就是 ResultSetHandler。那么开始我们的讨论
ResultSetHandler 简介
回想一下,一条 SQL 的请求过程会经过哪几个步骤? 首先会经过 Executor 执行器,它主要负责管理创建 StatementHandler 对象,然后由 StatementHandler 对象做数据库的连接以及生成 Statement 对象,并解析 SQL 参数,由 ParameterHandler 对象负责把 Mapper 方法中的参数映射到 XML 中的 SQL 语句中,那么是不是还少了一个步骤,就能完成一个完整的 SQL 请求了?没错,这最后一步就是 SQL 结果集的处理工作,也就是 ResultSetHandler 的主要工作
要了解 ResultSetHandler 之前,首先需要了解 ResultSetHandler的继承关系以及基本方法
public interface ResultSetHandler {
// 处理结果集 <E> List<E> handleResultSets(Statement stmt) throws SQLException;
// 批量处理结果集 <E> Cursor<E> handleCursorResultSets(Statement stmt) throws SQLException;
// 处理存储过程的结果集 void handleOutputParameters(CallableStatement cs) throws SQLException;
}
ResultSetHandler是一个接口,它只有一个默认的实现类,像是 ParameterHandler 一样,它的默认实现类是DefaultResultSetHandler
ResultSetHandler 创建
ResultSetHandler 是在处理查询请求的时候由 Configuration 对象负责创建,示例如下
protected BaseStatementHandler(Executor executor, MappedStatement mappedStatement, Object parameterObject, RowBounds rowBounds, ResultHandler resultHandler, BoundSql boundSql) { this.configuration = mappedStatement.getConfiguration(); this.executor = executor; this.mappedStatement = mappedStatement; this.rowBounds = rowBounds;
this.typeHandlerRegistry = configuration.getTypeHandlerRegistry(); this.objectFactory = configuration.getObjectFactory();
if (boundSql == null) { // issue #435, get the key before calculating the statement generateKeys(parameterObject); boundSql = mappedStatement.getBoundSql(parameterObject); }
this.boundSql = boundSql;
// 创建参数处理器 this.parameterHandler = configuration.newParameterHandler(mappedStatement, parameterObject, boundSql); // 创建结果映射器 this.resultSetHandler = configuration.newResultSetHandler(executor, mappedStatement, rowBounds, parameterHandler, resultHandler, boundSql); }
public ResultSetHandler newResultSetHandler(Executor executor, MappedStatement mappedStatement, RowBounds rowBounds, ParameterHandler parameterHandler, ResultHandler resultHandler, BoundSql boundSql) { // 由 DefaultResultSetHandler 进行初始化 ResultSetHandler resultSetHandler = new DefaultResultSetHandler(executor, mappedStatement, parameterHandler, resultHandler, boundSql, rowBounds); resultSetHandler = (ResultSetHandler) interceptorChain.pluginAll(resultSetHandler); return resultSetHandler; }
上述的创建过程是对 ResultSetHandler 创建过程以及初始化的简单解释,下面是对具体的查询请求进行分析
ResultSetHandler 处理结果映射
回想一下,我们在进行传统crud操作的时候,哪些方法是需要返回值的?当然我们说的返回值指的是从数据库中查询出来的值,而不是标识符,应该只有查询方法吧?所以 MyBatis 只针对 query 方法做了返回值的映射,代码如下:
PreparedStatementHandler.java
@Override public <E> List<E> query(Statement statement, ResultHandler resultHandler) throws SQLException { PreparedStatement ps = (PreparedStatement) statement; ps.execute(); // 处理结果集 return resultSetHandler.<E> handleResultSets(ps); }
@Override public <E> Cursor<E> queryCursor(Statement statement) throws SQLException { PreparedStatement ps = (PreparedStatement) statement; ps.execute(); // 批量处理结果集 return resultSetHandler.<E> handleCursorResultSets(ps); }
CallableStatementHandler.java 处理存储过程的SQL
@Override public <E> List<E> query(Statement statement, ResultHandler resultHandler) throws SQLException { CallableStatement cs = (CallableStatement) statement; cs.execute(); List<E> resultList = resultSetHandler.<E>handleResultSets(cs); resultSetHandler.handleOutputParameters(cs); return resultList; }
@Override public <E> Cursor<E> queryCursor(Statement statement) throws SQLException { CallableStatement cs = (CallableStatement) statement; cs.execute(); Cursor<E> resultList = resultSetHandler.<E>handleCursorResultSets(cs); resultSetHandler.handleOutputParameters(cs); return resultList; }
DefaultResultSetHandler 源码解析
MyBatis 只有一个默认的实现类就是 DefaultResultSetHandler,ResultSetHandler 主要负责处理两件事
- 处理 Statement 执行后产生的结果集,生成结果列表
- 处理存储过程执行后的输出参数
按照 Mapper 文件中配置的 ResultType 或 ResultMap 来封装成对应的对象,最后将封装的对象返回即可。
来看一下主要的源码:
@Override public List<Object> handleResultSets(Statement stmt) throws SQLException { ErrorContext.instance().activity("handling results").object(mappedStatement.getId());
final List<Object> multipleResults = new ArrayList<Object>();
int resultSetCount = 0; // 获取第一个结果集 ResultSetWrapper rsw = getFirstResultSet(stmt); // 获取结果映射 List<ResultMap> resultMaps = mappedStatement.getResultMaps(); // 结果映射的大小 int resultMapCount = resultMaps.size(); // 校验结果映射的数量 validateResultMapsCount(rsw, resultMapCount); // 如果ResultSet 包装器不是null, 并且 resultmap 的数量 > resultSet 的数量的话 // 因为 resultSetCount 第一次肯定是0,所以直接判断 ResultSetWrapper 是否为 0 即可 while (rsw != null && resultMapCount > resultSetCount) { // 从 resultMap 中取出 resultSet 数量 ResultMap resultMap = resultMaps.get(resultSetCount); // 处理结果集, 关闭结果集 handleResultSet(rsw, resultMap, multipleResults, null); rsw = getNextResultSet(stmt); cleanUpAfterHandlingResultSet(); resultSetCount++; }
// 从 mappedStatement 取出结果集 String[] resultSets = mappedStatement.getResultSets(); if (resultSets != null) { while (rsw != null && resultSetCount < resultSets.length) { ResultMapping parentMapping = nextResultMaps.get(resultSets[resultSetCount]); if (parentMapping != null) { String nestedResultMapId = parentMapping.getNestedResultMapId(); ResultMap resultMap = configuration.getResultMap(nestedResultMapId); handleResultSet(rsw, resultMap, null, parentMapping); } rsw = getNextResultSet(stmt); cleanUpAfterHandlingResultSet(); resultSetCount++; } }
return collapseSingleResultList(multipleResults); }
其中涉及的主要对象有:
ResultSetWrapper : 结果集的包装器,主要针对结果集进行的一层包装,它的主要属性有
- ResultSet : Java JDBC ResultSet接口表示数据库查询的结果。 有关查询的文本显示了如何将查询结果作为java.sql.ResultSet返回。 然后迭代此ResultSet以检查结果。
- TypeHandlerRegistry: 类型注册器,TypeHandlerRegistry 在初始化的时候会把所有的 Java类型和类型转换器进行注册。
- ColumnNames: 字段的名称,也就是查询操作需要返回的字段名称
- ClassNames: 字段的类型名称,也就是 ColumnNames 每个字段名称的类型
- JdbcTypes: JDBC 的类型,也就是java.sql.Types 类型
ResultMap: 负责处理更复杂的映射关系
multipleResults:
其中的主要方法是 handleResultSet
private void handleResultSet(ResultSetWrapper rsw, ResultMap resultMap, List<Object> multipleResults, ResultMapping parentMapping) throws SQLException { try { if (parentMapping != null) { // 处理多行结果的值 handleRowValues(rsw, resultMap, null, RowBounds.DEFAULT, parentMapping); } else { if (resultHandler == null) { DefaultResultHandler defaultResultHandler = new DefaultResultHandler(objectFactory); handleRowValues(rsw, resultMap, defaultResultHandler, rowBounds, null); multipleResults.add(defaultResultHandler.getResultList()); } else { handleRowValues(rsw, resultMap, resultHandler, rowBounds, null); } } } finally { // issue #228 (close resultsets) closeResultSet(rsw.getResultSet()); } }
// 如果有嵌套的ResultMap 的话 // 确保没有行绑定 // 检查结果处理器 // 如果没有的话,直接处理简单的ResultMap public void handleRowValues(ResultSetWrapper rsw, ResultMap resultMap, ResultHandler<?> resultHandler, RowBounds rowBounds, ResultMapping parentMapping) throws SQLException { if (resultMap.hasNestedResultMaps()) { ensureNoRowBounds(); checkResultHandler(); handleRowValuesForNestedResultMap(rsw, resultMap, resultHandler, rowBounds, parentMapping); } else { handleRowValuesForSimpleResultMap(rsw, resultMap, resultHandler, rowBounds, parentMapping); } }
handleResultSets 方法返回的是 collapseSingleResultList(multipleResults) ,它是什么呢?
private List<Object> collapseSingleResultList(List<Object> multipleResults) { return multipleResults.size() == 1 ? (List<Object>) multipleResults.get(0) : multipleResults; }
它是判断的 multipleResults 的数量,如果数量是 1 ,就直接取位置为0的元素,如果不是1,那就返回 multipleResults 的真实数量
那么 multipleResults 的数量是哪来的呢?
它的值其实是处理结果集中传递进去的
handleResultSet(rsw, resultMap, multipleResults, null);
然后在处理结果集的方法中对 multipleResults 进行添加
multipleResults.add(defaultResultHandler.getResultList());
下面我们来看一下返回的真实实现类 DefaultResultSetHandler 中的结构组成

在 DefaultResultSetHandler 中处理完结果映射,并把上述结构返回给调用的客户端,从而执行完成一条完整的SQL语句。
# MyBatis想启动?得先问问它同不同意-Java面试题
话说,我最近一直在研究 MyBatis ,研究 MyBatis ,必然逃不了研究 Configuration 对象,这个对象简直是太重要了,它是 MyBatis 起步的核心环境配置,下面我们来一起看一下 Configuration 类
Configuration 的创建
如果你喜欢一个妹子,你是不是闲得问清楚妹子住在哪?只加微信那就只能望梅止渴,主动出击才是硬道理。否则,就算你租了一辆玛莎拉蒂,你都不知道在哪装B。
想要了解 Configuration,得先问清楚它是如何创建的。
在这之前,我先告诉你一个 MyBatis 的入口类,那就是 SqlSessionFactoryBuilder, 为什么要介绍这个类哦?因为这个类可以创建 SqlSession,想要孩子?没有Builder 的功能怎么行?它的创建在这里

SqlSessionFactoryBuilder 在创建完成 XMLConfigBuilder 之后,会完成 Configuration 的创建工作,也就是说Configuration 对象的创建是在 XMLConfigBuilder 中完成的 ,如下图

看到这里,你是不是有点跃跃欲试想要按住 control 键点进去?如你所愿,看一下 new Configuration 到底生出个什么东西

这就是初始化 Configuration 完成的工作了,图中还有一个很关键的类就是 TypeAliasRegistry, 想要注册?你得先知道 "我" 是谁 。
TypeAliasRegistry 在Configuration 创建的时候就被初始化了
protected final TypeAliasRegistry typeAliasRegistry = new TypeAliasRegistry();
so? 看一下 new 都做了一些什么事情
public TypeAliasRegistry() { registerAlias("string", String.class);
registerAlias("byte", Byte.class); registerAlias("long", Long.class); registerAlias("short", Short.class); registerAlias("int", Integer.class); registerAlias("integer", Integer.class); registerAlias("double", Double.class); registerAlias("float", Float.class); registerAlias("boolean", Boolean.class);
registerAlias("byte[]", Byte[].class); registerAlias("long[]", Long[].class); registerAlias("short[]", Short[].class); registerAlias("int[]", Integer[].class); registerAlias("integer[]", Integer[].class); registerAlias("double[]", Double[].class); registerAlias("float[]", Float[].class); registerAlias("boolean[]", Boolean[].class);
registerAlias("_byte", byte.class); registerAlias("_long", long.class); registerAlias("_short", short.class); registerAlias("_int", int.class); registerAlias("_integer", int.class); registerAlias("_double", double.class); registerAlias("_float", float.class); registerAlias("_boolean", boolean.class);
registerAlias("_byte[]", byte[].class); registerAlias("_long[]", long[].class); registerAlias("_short[]", short[].class); registerAlias("_int[]", int[].class); registerAlias("_integer[]", int[].class); registerAlias("_double[]", double[].class); registerAlias("_float[]", float[].class); registerAlias("_boolean[]", boolean[].class);
registerAlias("date", Date.class); registerAlias("decimal", BigDecimal.class); registerAlias("bigdecimal", BigDecimal.class); registerAlias("biginteger", BigInteger.class); registerAlias("object", Object.class);
registerAlias("date[]", Date[].class); registerAlias("decimal[]", BigDecimal[].class); registerAlias("bigdecimal[]", BigDecimal[].class); registerAlias("biginteger[]", BigInteger[].class); registerAlias("object[]", Object[].class);
registerAlias("map", Map.class); registerAlias("hashmap", HashMap.class); registerAlias("list", List.class); registerAlias("arraylist", ArrayList.class); registerAlias("collection", Collection.class); registerAlias("iterator", Iterator.class);
registerAlias("ResultSet", ResultSet.class); }
好刺激啊,这么一大段代码,不过看起来还是比较清晰明了的,这不就是 MyBatis 常用类型么,并给它们都起了一个各自的别名存起来,用来解析的时候使用。
Configuration 的标签以及使用
说完了 Configuration 的创建,我们不直接切入初始化的主题,先来吃点甜点
还记得你是如何搭建一个 MyBatis 项目么?其中很关键的是不是有一个叫做 mybatis-config.xml的这么一个配置?
这个配置就是 <configuration> 标签存在的意义了。

我在最外侧写了一个 configuration 标签,然后 dtd 语言约束就给我提示这么多属性可以设置,它们都是属于 Configuration 内的标签,那么这些标签都是啥呢?别急,慢慢来,掌握好频率和节奏还有力度,别太猛,年轻人要沉稳。
我不想按着标签的顺序来了,请跟好我的节奏。
首先很重要的两个属性就是 properties 和 environments ,properties 就是外部属性配置,你可以这么配置它
<properties resource="config.properties" />
导入外部配置文件,config.properties 文件中是一系列关于数据库的配置,给你举个例子吧,看你着急的
jdbc.driver=com.mysql.jdbc.Driver jdbc.url=jdbc:mysql://localhost:3306/kkb jdbc.username=root jdbc.password=123456
载入外部属性配置后,需要配置 environments 标签,它可以配置事务管理、数据源、读取配置文件等
<environments default="development"> <environment id="development"> <transactionManager type="JDBC"/> <dataSource type="POOLED"> <property name="driver" value="${jdbc.driver}"/> <property name="url" value="${jdbc.url}"/> <property name="username" value="${jdbc.username}"/> <property name="password" value="${jdbc.password}"/> </dataSource> </environment> </environments>
明白否?
还有一个很关键的配置就是 mapper 标签,你可以把它理解为 ComponentScan ,ComponentScan 完成的是 Bean 定义的查找,而 mapper 完成的是 接口的查找,该接口要与对应的 XML 命名空间相匹配才可以。例如
<mappers> <package name="com.mybatis.dao"/> </mappers>
再继续深入,来看一下 <setting> 都需要哪些内容,你可以设置下面这些,下面这些配置有些多,你可以查看(http://www.mybatis.org/mybatis-3/zh/configuration.html#settings) 来具体查看这些配置。
<settings> // 全局地开启或关闭配置文件中的所有映射器已经配置的任何缓存。 <setting name="cacheEnabled" value="true"/>
// 延迟加载的全局开关。当开启时,所有关联对象都会延迟加载。 特定关联关系中可通过设置 fetchType 属性来覆盖该项的开关状态。 <setting name="lazyLoadingEnabled" value="true"/>
// 是否允许单一语句返回多结果集(需要驱动支持)。 <setting name="multipleResultSetsEnabled" value="true"/>
// 使用列标签代替列名。不同的驱动在这方面会有不同的表现,具体可参考相关驱动文档或通过测试这两种不同的模式来观察所用驱动的结果。 <setting name="useColumnLabel" value="true"/>
// 允许 JDBC 支持自动生成主键,需要驱动支持。 如果设置为 true 则这个设置强制使用自动生成主键,尽管一些驱动不能支持但仍可正常工作(比如 Derby)。 <setting name="useGeneratedKeys" value="false"/>
// 指定 MyBatis 应如何自动映射列到字段或属性。 NONE 表示取消自动映射;PARTIAL 只会自动映射没有定义嵌套结果集映射的结果集。 FULL 会自动映射任意复杂的结果集(无论是否嵌套)。 <setting name="autoMappingBehavior" value="PARTIAL"/>
// 指定发现自动映射目标未知列(或者未知属性类型)的行为。 // NONE: 不做任何反应 // WARNING: 输出提醒日志 ('org.apache.ibatis.session.AutoMappingUnknownColumnBehavior' 的日志等级必须设置为 WARN) // FAILING: 映射失败 (抛出 SqlSessionException) <setting name="autoMappingUnknownColumnBehavior" value="WARNING"/>
// 配置默认的执行器。SIMPLE 就是普通的执行器;REUSE 执行器会重用预处理语句(prepared statements); BATCH 执行器将重用语句并执行批量更新。 <setting name="defaultExecutorType" value="SIMPLE"/>
// 设置超时时间,它决定驱动等待数据库响应的秒数。 <setting name="defaultStatementTimeout" value="25"/>
// 为驱动的结果集获取数量(fetchSize)设置一个提示值。此参数只可以在查询设置中被覆盖。 <setting name="defaultFetchSize" value="100"/>
// 允许在嵌套语句中使用分页(RowBounds)。如果允许使用则设置为 false <setting name="safeRowBoundsEnabled" value="false"/>
// 是否开启自动驼峰命名规则(camel case)映射,即从经典数据库列名 A_COLUMN 到经典 Java 属性名 aColumn 的类似映射。 <setting name="mapUnderscoreToCamelCase" value="false"/>
// MyBatis 利用本地缓存机制(Local Cache)防止循环引用(circular references)和加速重复嵌套查询。 默认值为 SESSION,这种情况下会缓存一个会话中执行的所有查询。 若设置值为 STATEMENT,本地会话仅用在语句执行上,对相同 SqlSession 的不同调用将不会共享数据 <setting name="localCacheScope" value="SESSION"/>
// 当没有为参数提供特定的 JDBC 类型时,为空值指定 JDBC 类型。 某些驱动需要指定列的 JDBC 类型,多数情况直接用一般类型即可,比如 NULL、VARCHAR 或 OTHER。 <setting name="jdbcTypeForNull" value="OTHER"/>
// 指定哪个对象的方法触发一次延迟加载。 <setting name="lazyLoadTriggerMethods" value="equals,clone,hashCode,toString"/> </settings>
你知道 Oracle 和 MySQL 都可以对表,字段设置别名吗?MyBatis 也可以设置别名,采用的是 typeAliases 属性,比如
<!-- 为每一个实体类设置一个具体别名 --> <typeAliases> <typeAlias type="com.kaikeba.beans.Dept" alias="Dept"/> </typeAliases>
<!-- 为当前包下的每一个类设置一个默认别名 --> <typeAliases> <package name="com.mybatis.beans"/> </typeAliases>
MyBatis 可以根据不同的数据库厂商执行不同的语句,这种多厂商的支持是基于映射语句中的 databaseId 属性。 MyBatis 会加载不带 databaseId 属性和带有匹配当前数据库 databaseId 属性的所有语句。 如果同时找到带有 databaseId 和不带 databaseId 的相同语句,则后者会被舍弃。 为支持多厂商特性只要像下面这样在 mybatis-config.xml 文件中加入 databaseIdProvider 即可:
<databaseIdProvider type="DB_VENDOR" />
DB_VENDOR 对应的 databaseIdProvider 实现会将 databaseId 设置为 DatabaseMetaData#getDatabaseProductName() 返回的字符串。 由于通常情况下这些字符串都非常长而且相同产品的不同版本会返回不同的值,所以你可能想通过设置属性别名来使其变短,如下:
<databaseIdProvider type="DB_VENDOR"> <property name="SQL Server" value="sqlserver"/> <property name="DB2" value="db2"/> <property name="Oracle" value="oracle" /> </databaseIdProvider>
MyBatis 每次创建结果对象的新实例时,它都会使用一个对象工厂(ObjectFactory)实例来完成。 默认的对象工厂需要做的仅仅是实例化目标类,要么通过默认构造方法,要么在参数映射存在的时候通过参数构造方法来实例化。 如果想覆盖对象工厂的默认行为,则可以通过创建自己的对象工厂来实现。比如:
// ExampleObjectFactory.java public class ExampleObjectFactory extends DefaultObjectFactory { public Object create(Class type) { return super.create(type); } public Object create(Class type, List<Class> constructorArgTypes, List<Object> constructorArgs) { return super.create(type, constructorArgTypes, constructorArgs); } public void setProperties(Properties properties) { super.setProperties(properties); } public <T> boolean isCollection(Class<T> type) { return Collection.class.isAssignableFrom(type); } }
<!-- mybatis-config.xml --> <objectFactory type="org.mybatis.example.ExampleObjectFactory"> <property name="someProperty" value="100"/> </objectFactory>
ObjectFactory 的作用就很像是 Spring 中的 FactoryBean ,如果不是很了解关于 FactoryBean 的讲解,请移步至
(https://mp.weixin.qq.com/s/aCFzCopCX1mK6Zg-dT_KgA) 进行了解
MyBatis 留给开发人员的后门是可以进行插件开发的,插件开发在何处体现呢?其实 MyBatis 四大组件都会有体现, MyBatis 的插件开发其实也是代理的一种应用,如图
Configuration.java

这是 Executor 插件开发的调用位置,那么 StatementHandler, ParameterHandler, ResultSetHandler 的调用和 Executor 基本一致,如图

过 MyBatis 提供的强大机制,使用插件是非常简单的,只需实现 Interceptor 接口,并指定想要拦截的方法签名即可。例如官网的这个例子
// ExamplePlugin.java @Intercepts({@Signature( type= Executor.class, method = "update", args = {MappedStatement.class,Object.class})}) public class ExamplePlugin implements Interceptor { private Properties properties = new Properties(); public Object intercept(Invocation invocation) throws Throwable { // implement pre processing if need Object returnObject = invocation.proceed(); // implement post processing if need return returnObject; } public void setProperties(Properties properties) { this.properties = properties; } }
只需要再把这个插件告诉 MyBatis, 这里有个插件拦截器,记得用奥
<!-- mybatis-config.xml --> <plugins> <plugin interceptor="org.mybatis.example.ExamplePlugin"> <property name="someProperty" value="100"/> </plugin> </plugins>
typeHandlers 也叫做类型转换器,主要用在参数转换的地方,哪里进行参数转换呢?其实有两点:
- PreparedStatementHandler 在解析 SQL 参数,进行参数设置的时候,需要把 Java Type 转换为 JDBC 类型
- ResultSetHandler 返回的结果集,需要把 JDBC 类型转换为 Java Type
可以编写自己的类型转换器,如下:
// ExampleTypeHandler.java @MappedJdbcTypes(JdbcType.VARCHAR) public class ExampleTypeHandler extends BaseTypeHandler<String> {
@Override public void setNonNullParameter(PreparedStatement ps, int i, String parameter, JdbcType jdbcType) throws SQLException { ps.setString(i, parameter); }
@Override public String getNullableResult(ResultSet rs, String columnName) throws SQLException { return rs.getString(columnName); }
@Override public String getNullableResult(ResultSet rs, int columnIndex) throws SQLException { return rs.getString(columnIndex); }
@Override public String getNullableResult(CallableStatement cs, int columnIndex) throws SQLException { return cs.getString(columnIndex); } }
也需要告诉 MyBatis ,这里面有个参数转换器,别忘了转换!
<!-- mybatis-config.xml --> <typeHandlers> <typeHandler handler="org.mybatis.example.ExampleTypeHandler"/> </typeHandlers>
Configuration 标签的解析
现在有了上面的这些标签的定义,应该在哪解析呢?就好比合适的人在合适的岗位才能创造出最大的价值一样。
现在就需要续上 SqlSessionFactoryBuilder 的第三步了, Configuration 的解析工作
在 XMLConfigBuilder 中

这是不是就和上面的标签对应起来了?解析工作是在这里进行的,这也是一种好的编码习惯,一个方法只做一件事情,应该多多借鉴这种写法。
Configuration 子标签的源码分析
假如你能从上向下看到这里,就说明你对这篇文章产生了浓厚的兴趣,恭喜你,你的段位又升级了。我不打王者荣耀,我之前一直打魔兽solo,solo是很需要手速的,同时也需要考虑到各种因素:比如你是 ORC(兽族),你的 BM(剑圣) 开 W(疾风步) 抢怪的时间要掌握好,你骚扰 NE (暗夜精灵) 采木材的时间要掌握好,抢宝的时间要掌握好,比如你玩的是 Turtle Rock(龟岛),你单刷蓝胖的时间也要算好,等等等等。
你既要sky的中规中矩,你也要MOON的不羁,你还要fly100%的沉稳,你也需要TED的坚持。也就印证了一句话,小孩子才做选择,成年人都要!
所以你不仅仅要知其果,还要懂其因。
第一步:Properties 解析
第一个方法: propertiesElement(root.evalNode("properties")),点进去可以看到其源码,我这里已经做了注释,方便你去理解
// 其实一个个 <> 的标签就是 一个个的XNode节点 private void propertiesElement(XNode context) throws Exception { if (context != null) { // 首先判断要解析的属性是否有无子节点 Properties defaults = context.getChildrenAsProperties();
// 解析<properties resource=""/> 解析完成就变为配置文件的 SimpleName
String resource = context.getStringAttribute("resource");
// 解析<properties url=""/>
String url = context.getStringAttribute("url");
// 如果都为空,抛出异常
if (resource != null && url != null) {
throw new BuilderException("The properties element cannot specify both a URL and a resource based property file reference. Please specify one or the other.");
}
// 如果不为空的话,就把配置文件的内容都放到 Resources 类中
if (resource != null) {
defaults.putAll(Resources.getResourceAsProperties(resource));
} else if (url != null) {
defaults.putAll(Resources.getUrlAsProperties(url));
}
// 这块应该是判断有无之前的配置
Properties vars = configuration.getVariables();
if (vars != null) {
defaults.putAll(vars);
}
parser.setVariables(defaults);
// 最后放入 configuration 属性中
configuration.setVariables(defaults);
}
}
第二步:Settings 解析
在这里我们以二级缓存的开启为例来做解析
<!-- 通知 MyBatis 框架开启二级缓存 --> <settings> <setting name="cacheEnabled" value="true"/> </settings>
那么它在settingsAsProperties(root.evalNode("settings")) 中是如何解析的呢?
// XNode 就是一个个的 标签 private Properties settingsAsProperties(XNode context) { if (context == null) { return new Properties(); } // 获取字标签,字标签也就是 <settings> 中的 <setting> Properties props = context.getChildrenAsProperties(); // Check that all settings are known to the configuration class // 用反射确保所有的设置都在 Configuration 类中。 MetaClass metaConfig = MetaClass.forClass(Configuration.class, localReflectorFactory); for (Object key : props.keySet()) { // 如果反射没有确保这个key 在类中,就抛出异常 if (!metaConfig.hasSetter(String.valueOf(key))) { throw new BuilderException("The setting " + key + " is not known. Make sure you spelled it correctly (case sensitive)."); } } return props; }
解析完成后的 settings 对象,底层是用 Hashtable 存储了一个个的 entry 对象。

第三步:TypeAliases 解析
TypeAliases 用于别名注册,你可以为实体类指定它的别名,源码如下
private void typeAliasesElement(XNode parent) { if (parent != null) { // 也是首先判断有无子标签 for (XNode child : parent.getChildren()) { // 如果有字标签,那么取出字标签的属性名,如果是 package if ("package".equals(child.getName())) { // 那么取出 字标签 的name属性 String typeAliasPackage = child.getStringAttribute("name"); configuration.getTypeAliasRegistry().registerAliases(typeAliasPackage); } else {
// typeAliases 下面有两个标签,一个是 package 一个是 TypeAlias
String alias = child.getStringAttribute("alias");
String type = child.getStringAttribute("type");
try {
Class<?> clazz = Resources.classForName(type);
if (alias == null) {
typeAliasRegistry.registerAlias(clazz);
} else {
typeAliasRegistry.registerAlias(alias, clazz);
}
} catch (ClassNotFoundException e) {
throw new BuilderException("Error registering typeAlias for '" + alias + "'. Cause: " + e, e);
}
}
}
} }
第四步:Plugins 解析
MyBatis 中的插件都在这一步进行解析注册
private void pluginElement(XNode parent) throws Exception { if (parent != null) { for (XNode child : parent.getChildren()) { // 取出 interceptor 的名称 String interceptor = child.getStringAttribute("interceptor"); Properties properties = child.getChildrenAsProperties(); // 生成新实例,设置属性名 Interceptor interceptorInstance = (Interceptor) resolveClass(interceptor).newInstance(); interceptorInstance.setProperties(properties); // 添加到 configuration 中 configuration.addInterceptor(interceptorInstance); } } }
其他步骤
其实后面的源码分析步骤都差不多,大体上都是判断有无此 XNode 节点,然后判断它的子节点标签,得到标签的属性,放入 Configuration 对象中,这样就完成了 Configuration 对象的初始化,其实你可以看出,MyBatis 中的 Configuration 也是一个大的容器,来为后面的SQL语句解析和初始化提供保障。
总结
本文主要概括了
- Configuration 的创建过程
SqlSessionFactoryBuilder 创建 XMLConfigBuilder ,XMLConfigBuilder 再创建 Configuration , Configuration 的创建会装载一些基本属性,如事务,数据源,缓存,日志,代理等,它们由 TypeAliasRegistry 进行注册,而TypeAliasRegistry 初始化也注册了一些基本数据类型,map,list,collection等,Configuration 还初始化了其他很多属性,由此完成 Configuration 的创建。
- Configuration 的标签以及使用
此步骤分析了 Configuration 中的标签以及使用,此部分不用去记忆,只知道有哪几个比较重要的标签就可以了,比如: properties, environment,mappers,settings,typeHandler,如果有开发需求直接查找官网就好
(http://www.mybatis.org/mybatis-3/zh/configuration.html)
- Configuration 对标签的解析
此步骤分析了 XMLConfigBuilder 对 Configuration 类下所有标签的解析工作,解析工作大部分模式都差不多
大体上都是判断有无此 XNode 节点,然后判断它的子节点标签,得到标签的属性,放入 Configuration 对象中。
# MyBatis核心配置综述之ParameterHandler-Java面试题
MyBatis 四大核心组件我们已经了解到了两种,一个是 Executor ,它是MyBatis 解析SQL请求首先会经过的第一道关卡,它的主要作用在于创建缓存,管理 StatementHandler 的调用,为 StatementHandler 提供 Configuration 环境等。StatementHandler 组件最主要的作用在于创建 Statement 对象与数据库进行交流,还会使用 ParameterHandler 进行参数配置,使用 ResultSetHandler 把查询结果与实体类进行绑定。那么本篇就来了解一下第三个组件 ParameterHandler。
ParameterHandler 简介
ParameterHandler 相比于其他的组件就简单很多了,ParameterHandler 译为参数处理器,负责为 PreparedStatement 的 sql 语句参数动态赋值,这个接口很简单只有两个方法
/** * A parameter handler sets the parameters of the {@code PreparedStatement} * 参数处理器为 PreparedStatement 设置参数 */ public interface ParameterHandler {
Object getParameterObject();
void setParameters(PreparedStatement ps) throws SQLException;
}
ParameterHandler 只有一个实现类 DefaultParameterHandler , 它实现了这两个方法。
- getParameterObject: 用于读取参数
- setParameters: 用于对 PreparedStatement 的参数赋值
ParameterHandler 创建
参数处理器对象是在创建 StatementHandler 对象的同时被创建的,由 Configuration 对象负责创建
BaseStatementHandler.java
protected BaseStatementHandler(Executor executor, MappedStatement mappedStatement, Object parameterObject, RowBounds rowBounds, ResultHandler resultHandler, BoundSql boundSql) { this.configuration = mappedStatement.getConfiguration(); this.executor = executor; this.mappedStatement = mappedStatement; this.rowBounds = rowBounds;
this.typeHandlerRegistry = configuration.getTypeHandlerRegistry(); this.objectFactory = configuration.getObjectFactory();
if (boundSql == null) { // issue #435, get the key before calculating the statement generateKeys(parameterObject); boundSql = mappedStatement.getBoundSql(parameterObject); }
this.boundSql = boundSql;
// 创建参数处理器 this.parameterHandler = configuration.newParameterHandler(mappedStatement, parameterObject, boundSql); // 创建结果映射器 this.resultSetHandler = configuration.newResultSetHandler(executor, mappedStatement, rowBounds, parameterHandler, resultHandler, boundSql); }
在创建 ParameterHandler 时,需要传入SQL的mappedStatement 对象,读取的参数和SQL语句
注意:一个 BoundSql 对象,就代表了一次sql语句的实际执行,而 SqlSource 对象的责任,就是根据传入的参数对象,动态计算这个 BoundSql, 也就是 Mapper 文件中节点的计算,是由 SqlSource 完成的,SqlSource 最常用的实现类是 DynamicSqlSource
Configuration.java
public ParameterHandler newParameterHandler(MappedStatement mappedStatement, Object parameterObject, BoundSql boundSql) { // 创建ParameterHandler ParameterHandler parameterHandler = mappedStatement.getLang().createParameterHandler(mappedStatement, parameterObject, boundSql); parameterHandler = (ParameterHandler) interceptorChain.pluginAll(parameterHandler); return parameterHandler; }
上面是 Configuration 创建 ParameterHandler 的过程,它实际上是交由 LanguageDriver 来创建具体的参数处理器,LanguageDriver 默认的实现类是 XMLLanguageDriver,由它调用 DefaultParameterHandler 中的构造方法完成 ParameterHandler 的创建工作
public ParameterHandler createParameterHandler(MappedStatement mappedStatement, Object parameterObject, BoundSql boundSql) { return new DefaultParameterHandler(mappedStatement, parameterObject, boundSql); }
public DefaultParameterHandler(MappedStatement mappedStatement, Object parameterObject, BoundSql boundSql) { this.mappedStatement = mappedStatement; this.configuration = mappedStatement.getConfiguration(); // 获取 TypeHandlerRegistry 注册 this.typeHandlerRegistry = mappedStatement.getConfiguration().getTypeHandlerRegistry(); this.parameterObject = parameterObject; this.boundSql = boundSql; }
上面的流程是创建 ParameterHandler 的过程,创建完成之后,该进行具体的解析工作,那么 ParameterHandler 如何解析SQL中的参数呢?SQL中的参数从哪里来的?
ParameterHandler 中的参数从何而来
你可能知道 Parameter 中的参数是怎么来的,无非就是从 Mapper 配置文件中映射过去的啊,就比如如下例子

参数肯定就是图中标红的 1 ,然后再传到XML对应的 SQL 语句中,用 #{} 或者 ${} 来进行赋值啊,

嗯,你讲的没错,可是你知道这个参数是如何映射过来的吗?或者说你知道 Parameter 的解析过程吗?或许你不是很清晰了,我们下面就来探讨一下 ParameterHandler 对参数的解析,这其中涉及到 MyBatis 中的动态代理模式
在MyBatis 中,当 deptDao.findByDeptNo(1) 将要执行的时候,会被 JVM 进行拦截,交给 MyBatis 中的代理实现类 MapperProxy 的 invoke 方法中,这也是执行 SQL 语句的主流程。

然后交给 Executor 、StatementHandler进行对应的参数解析和执行,因为是带参数的 SQL 语句,最终会创建 PreparedStatement 对象并创建参数解析器进行参数解析
SimpleExecutor.java

handler.parameterize(stmt) 最终会调用到 DefaultParameterHandler 中的 setParameters 方法,我在源码上做了注释,为了方便拷贝,我没有采用截图的形式
public void setParameters(PreparedStatement ps) { ErrorContext.instance().activity("setting parameters").object(mappedStatement.getParameterMap().getId()); // parameterMappings 就是对 #{} 或者 ${} 里面参数的封装 List<ParameterMapping> parameterMappings = boundSql.getParameterMappings(); if (parameterMappings != null) { // 如果是参数化的SQL,便需要循环取出并设置参数的值 for (int i = 0; i < parameterMappings.size(); i++) { ParameterMapping parameterMapping = parameterMappings.get(i); // 如果参数类型不是 OUT ,这个类型与 CallableStatementHandler 有关 // 因为存储过程不存在输出参数,所以参数不是输出参数的时候,就需要设置。 if (parameterMapping.getMode() != ParameterMode.OUT) { Object value; // 得到#{} 中的属性名 String propertyName = parameterMapping.getProperty(); // 如果 propertyName 是 Map 中的key if (boundSql.hasAdditionalParameter(propertyName)) { // issue #448 ask first for additional params // 通过key 来得到 additionalParameter 中的value值 value = boundSql.getAdditionalParameter(propertyName); } // 如果不是 additionalParameters 中的key,而且传入参数是 null, 则value 就是null else if (parameterObject == null) { value = null; } // 如果 typeHandlerRegistry 中已经注册了这个参数的 Class对象,即它是Primitive 或者是String 的话 else if (typeHandlerRegistry.hasTypeHandler(parameterObject.getClass())) { value = parameterObject; } else { // 否则就是 Map MetaObject metaObject = configuration.newMetaObject(parameterObject); value = metaObject.getValue(propertyName); } // 在通过SqlSource 的parse 方法得到parameterMappings 的具体实现中,我们会得到parameterMappings的typeHandler TypeHandler typeHandler = parameterMapping.getTypeHandler(); // 获取typeHandler 的jdbc type JdbcType jdbcType = parameterMapping.getJdbcType(); if (value == null && jdbcType == null) { jdbcType = configuration.getJdbcTypeForNull(); } try { typeHandler.setParameter(ps, i + 1, value, jdbcType); } catch (TypeException e) { throw new TypeException("Could not set parameters for mapping: " + parameterMapping + ". Cause: " + e, e); } catch (SQLException e) { throw new TypeException("Could not set parameters for mapping: " + parameterMapping + ". Cause: " + e, e); } } } } }
ParameterHandler 解析
我们在 MyBatis 核心配置综述之 StatementHandler 一文中了解到 Executor 管理的是 StatementHandler 对象的创建以及参数赋值,那么我们的主要入口还是 Executor 执行器
下面用一个流程图表示一下 ParameterHandler 的解析过程,以简单执行器为例

像是 doQuery,doUpdate,doQueryCursor等方法都会先调用到
// 生成 preparedStatement 并调用 prepare 方法,并为参数赋值 private Statement prepareStatement(StatementHandler handler, Log statementLog) throws SQLException { Statement stmt; Connection connection = getConnection(statementLog); stmt = handler.prepare(connection, transaction.getTimeout()); handler.parameterize(stmt); return stmt; }
然后在生成 preparedStatement 调用DefaultParameterHandler进行参数赋值。
# MyBatis基础搭建及架构概述-Java面试题
MyBatis 是什么?
MyBatis是第一个支持自定义SQL、存储过程和高级映射的类持久框架。MyBatis消除了大部分JDBC的样板代码、手动设置参数以及检索结果。MyBatis能够支持简单的XML和注解配置规则。使Map接口和POJO类映射到数据库字段和记录。
下面我们通过一个简单的项目搭建来带你认识一下MyBatis的使用和一些核心组件的讲解。
MyBatis 项目构建
为了快速构建一个MyBatis项目,我们采用SpringBoot快速搭建的方式。搭建好后在对应的pom.xml下添加如下的maven依赖,主要作用在于引入mybatis一些jar包和类库
主要分为四个步骤:
- 快速构建项目,引入核心maven dependency依赖
- 构建POJO类和接口式编程的 Mapper类,编写SQL语句
- 编写
config.properties数据库驱动等配置 - 构建Mybatis核心配置文件即
mybatis-config.xml,引入数据库驱动,映射Mapper类 - 编写Junit单元测试类
<!-- mybatis 核心依赖--> <dependency> <groupId>org.mybatis</groupId> <artifactId>mybatis</artifactId> <version>3.4.6</version> </dependency> <!-- 数据库驱动包 --> <dependency> <groupId>mysql</groupId> <artifactId>mysql-connector-java</artifactId> <version>5.1.25</version> </dependency> <!-- 单元测试包--> <dependency> <groupId>junit</groupId> <artifactId>junit</artifactId> <version>4.12</version> <scope>test</scope> </dependency>
为了便于更好的说明文章的主旨,这里就不贴出全部代码了,会贴出核心代码部分
编写对应的POJO类和接口式编程Mapper类,这里我们以部门业务逻辑为例,构建一个部门类,有三个属性即部门编号、部门名称、位置,下面是部分代码:
Dept.java
package com.mybatis.beans; public class Dept {
private Integer deptNo;
private String dname;
private String loc;
public Dept() {}
public Dept(Integer deptNo, String dname, String loc) {
this.deptNo = deptNo;
this.dname = dname;
this.loc = loc;
}
get and set...
}
MyBatis最核心的功能之一就是接口式编程,它可以让我们编写Mapper接口和XML文件,从而把参数和返回结果映射到对应的字段中。
DeptDao.java
package com.mybatis.dao; public interface DeptDao {
// 通过部门名称查询
public Dept findByDname(String Dname);
// 通过部门编号查询
public Dept findByDeptNo(Integer deptno);
}
在/resources 下新建com.mybatis.dao 包,在其内编写对应的XML配置文件,此XML配置文件和Mapper互为映射关系。
<mapper namespace="com.mybatis.dao.DeptDao" >
<sql id="DeptFindSql">
select * from dept
</sql>
<select id="findByDeptNo" resultType="com.mybatis.beans.Dept">
<include refid="DeptFindSql"></include>
where deptno = #{deptNo}
</select>
<select id="findByDname" resultType="com.mybatis.beans.Dept">
<include refid="DeptFindSql"></include>
where dname = #{dname}
</select>
</mapper>
上述的
就是映射到Mapper接口类的命名空间
<select>标签用于编写查询语句,查询完成之后需要把结果映射到对象或者map集合等,需要用到resultType属性指定对应的结果集。上述采用了
和 的标签写法,为了方便的映射到实体类,需要修改的话统一修改即可,降低耦合性。
构建完成基础的SQL语句和映射之后,下面来构建MySQL数据库驱动,在/resources 下创建config.properties类
jdbc.driver=com.mysql.jdbc.Driver jdbc.url=jdbc:mysql://localhost:3306/test jdbc.username=root jdbc.password=123456
在/resources 下编写MyBatis核心配置文件myBatis-config.xml,引入数据库驱动,映射Mapper类
<configuration> <!-- 设置导入外部properties文件位置 --> <properties resource="config.properties"></properties>
<environments default="development">
<environment id="development">
<transactionManager type="JDBC"/>
<dataSource type="POOLED">
<property name="driver" value="${jdbc.driver}"/>
<property name="url" value="${jdbc.url}"/>
<property name="username" value="${jdbc.username}"/>
<property name="password" value="${jdbc.password}"/>
</dataSource>
</environment>
</environments>
<mappers>
<package name="com.mybatis.dao"/>
</mappers>
</configuration>
configuration 标签很像是Spring 中的 beans 标签或者是基于注解的配置@Configuration,也就是MyBatis的核心配置环境,使用 properties 标签引入外部属性环境,也就是数据库驱动配置,使用 mappers 映射到Mapper所在的包,这里指的就是DeptDao.java所在的包。
在test包下面新建一个Junit单元测试类,主要流程如下:

MyBatisTest.java 代码如下:
public class MyBatisTest {
private SqlSession sqlSession;
/**
* 读取配置文件,创建SQL工厂,打开会话
* @throws Exception
*/
@Before
public void start() throws Exception{
InputStream is = Resources.getResourceAsStream("myBatis-config.xml");
SqlSessionFactoryBuilder builder = new SqlSessionFactoryBuilder();
SqlSessionFactory factory = builder.build(is);
sqlSession = factory.openSession();
}
/**
* 销毁会话
*/
@After
public void destroy() {
if(sqlSession != null){
sqlSession.close();
}
}
@Test
public void test(){
DeptDao deptDao = sqlSession.getMapper(DeptDao.class);
Dept dept = deptDao.findByDeptNo(1);
System.out.println(dept.getDname());
}
}
@Before 和 @After 是junit工具包中的类,@Before在执行@Test 测试其主要业务之前加载,@After 在执行@Test 测试完成之后加载。
整体结构如下:

MyBatis 整体架构
MyBatis的架构大概是这样的,最上面是接口层,接口层就是开发人员在Mapper或者是Dao接口中的接口定义,是查询、新增、更新还是删除操作;中间层是数据处理层,主要是配置Mapper -> xml层级之间的参数映射,SQL解析,SQL执行,结果映射的过程。上述两种流程都由基础支持层来提供功能支撑,基础支持层包括连接管理,事务管理,配置加载,缓存处理。

接口层
在不与Spring 集成的情况下,使用MyBatis执行数据库的操作主要如下:
InputStream is = Resources.getResourceAsStream("myBatis-config.xml"); SqlSessionFactoryBuilder builder = new SqlSessionFactoryBuilder(); SqlSessionFactory factory = builder.build(is); sqlSession = factory.openSession();
其中的SqlSessionFactory,SqlSession是MyBatis接口的核心类,尤其是SqlSession,这个接口是MyBatis中最重要的接口,这个接口能够让你执行命令,获取映射,管理事务。
数据处理层
- 配置解析
在Mybatis初始化过程中,会加载mybatis-config.xml配置文件、映射配置文件以及Mapper接口中的注解信息,解析后的配置信息会形成相应的对象并保存到Configration对象中。之后,根据该对象创建SqlSessionFactory对象。待Mybatis初始化完成后,可以通过SqlSessionFactory创建SqlSession对象并开始数据库操作。
- SQL解析与scripting模块
Mybatis实现的动态SQL语句,几乎可以编写出所有满足需要的SQL。
Mybatis中scripting模块会根据用户传入的参数,解析映射文件中定义的动态SQL节点,形成数据库能执行的sql语句。
- SQL执行
SQL语句的执行涉及多个组件,包括MyBatis的四大神器,它们是: Executor、StatementHandler、ParameterHandler、ResultSetHandler。SQL的执行过程可以
用下面这幅图来表示

MyBatis层级结构各个组件的介绍(这里只是简单介绍,具体介绍在后面):
- SqlSession: MyBatis核心API,主要用来执行命令,获取映射,管理事务。接收开发人员提供Statement Id 和参数.并返回操作结果
- Executor: 执行器,是MyBatis调度的核心,负责SQL语句的生成以及查询缓存的维护
- StatementHandler: 封装了JDBC Statement操作,负责对JDBC statement 的操作,如设置参数、将Statement结果集转换成List集合。
- ParameterHandler: 负责对用户传递的参数转换成JDBC Statement 所需要的参数
- ResultSetHandler: 负责将JDBC返回的ResultSet结果集对象转换成List类型的集合
- TypeHandler: 用于Java类型和jdbc类型之间的转换
- MappedStatement: 动态SQL的封装
- SqlSource: 表示从XML文件或注释读取的映射语句的内容,它创建将从用户接收的输入参数传递给数据库的SQL。
- Configuration: MyBatis所有的配置信息都维持在Configuration对象之中
基础支持层
该层保护mybatis的基础模块,它们为核心处理层提供了良好的支撑。
(1)反射模块
Mybatis中的反射模块,对Java原生的反射进行了很好的封装,提供了简易的API,方便上层调用,并且对反射操作进行了一系列的优化,比如,缓存了类的元数据(MetaClass)和对象的元数据(MetaObject),提高了反射操作的性能。
(2)类型转换模块
Mybatis的别名机制,是为了简化配置文件的,该机制是类型转换模块的主要功能之一。类型转换模块的另一个功能是实现JDBC类型与Java类型间的转换。该功能在SQL语句绑定实参和映射查询结果集时都会涉及。在SQL语句绑定实参时,会将数据有Java类型转换成JDBC类型;在映射结果集时,会将数据有JDBC类型转换成Java类型。
(3)日志模块
Java世界里,有很多优秀的日志框架,如Log4j、Log4j2、slf4j等。Mybatis除了提供了详细的日志输出信息,还能够集成多种日志框架,其日志模块的主要功能就是集成第三方日志框架。
(4)资源加载模块
该模块主要封装了类加载器,确定了类加载器的使用顺序,并提供了加载类文件和其它资源文件的功能。
(5) 解析器模块
该模块有两个主要功能:一个是封装了XPath,为Mybatis初始化时解析mybatis-config.xml配置文件以及映射配置文件提供支持;另一个为处理动态SQL语句中的占位符提供支持。
(6)数据源模块
在数据源模块中,Mybatis自身提供了相应的数据源实现,也提供了与第三方数据源集成的接口。数据源是开发中的常用组件之一,很多开源的数据源都提供了丰富的功能,如,连接池、检测连接状态等,选择性能优秀的数据源组件,对于提供ORM框架以及整个应用的性能都是非常重要的。
(7)事务管理模块
一般地,Mybatis与Spring框架集成,由Spring框架管理事务。但Mybatis自身对数据库事务进行了抽象,提供了相应的事务接口和简单实现。
(8)缓存模块
Mybatis中有一级缓存和二级缓存,这两级缓存都依赖于缓存模块中的实现。但是,需要注意,这两级缓存与Mybatis以及整个应用是运行在同一个JVM中的,共享同一块内存,如果这两级缓存中的数据量较大,则可能影响系统中其它功能,所以需要缓存大量数据时,优先考虑使用Redis、Memcache等缓存产品。
(9)Binding模块
在调用SqlSession相应方法执行数据库操作时,需要制定映射文件中定义的SQL节点,如果sql中出现了拼写错误,那就只能在运行时才能发现。为了能尽早发现这种错误,Mybatis通过Binding模块将用户自定义的Mapper接口与映射文件关联起来,系统可以通过调用自定义Mapper接口中的方法执行相应的SQL语句完成数据库操作,从而避免上述问题。注意,在开发中,我们只是创建了Mapper接口,而并没有编写实现类,这是因为Mybatis自动为Mapper接口创建了动态代理对象。有时,自定义的Mapper接口可以完全代替映射配置文件,但比如动态SQL语句啊等,还是写在映射配置文件中更好。
# Linux开篇!!!-Java面试题
此篇文章主要会带你介绍 Linux 操作系统,包括 Linux 本身、Linux 如何使用、以及系统调用和 Linux 是如何工作的。
Linux 简介
UNIX 是一个交互式系统,用于同时处理多进程和多用户同时在线。为什么要说 UNIX,那是因为 Linux 是由 UNIX 发展而来的,UNIX 是由程序员设计,它的主要服务对象也是程序员。Linux 继承了 UNIX 的设计目标。从智能手机到汽车,超级计算机和家用电器,从家用台式机到企业服务器,Linux 操作系统无处不在。
大多数程序员都喜欢让系统尽量简单,优雅并具有一致性。举个例子,从最底层的角度来讲,一个文件应该只是一个字节集合。为了实现顺序存取、随机存取、按键存取、远程存取只能是妨碍你的工作。相同的,如果命令
ls A*
意味着只列出以 A 为开头的所有文件,那么命令
rm A*
应该会移除所有以 A 为开头的文件而不是只删除文件名是 A* 的文件。这个特性也是最小吃惊原则(principle of least surprise)
最小吃惊原则一半常用于用户界面和软件设计。它的原型是:该功能或者特征应该符合用户的预期,不应该使用户感到惊讶和震惊。
一些有经验的程序员通常希望系统具有较强的功能性和灵活性。设计 Linux 的一个基本目标是每个应用程序只做一件事情并把他做好。所以编译器只负责编译的工作,编译器不会产生列表,因为有其他应用比编译器做的更好。
很多人都不喜欢冗余,为什么在 cp 就能描述清楚你想干什么时候还使用 copy?这完全是在浪费宝贵的 hacking time。为了从文件中提取所有包含字符串 ard 的行,Linux 程序员应该输入
grep ard f
Linux 接口
Linux 系统是一种金字塔模型的系统,如下所示

应用程序发起系统调用把参数放在寄存器中(有时候放在栈中),并发出 trap 系统陷入指令切换用户态至内核态。因为不能直接在 C 中编写 trap 指令,因此 C 提供了一个库,库中的函数对应着系统调用。有些函数是使用汇编编写的,但是能够从 C 中调用。每个函数首先把参数放在合适的位置然后执行系统调用指令。因此如果你想要执行 read 系统调用的话,C 程序会调用 read 函数库来执行。这里顺便提一下,是由 POSIX 指定的库接口而不是系统调用接口。也就是说,POSIX 会告诉一个标准系统应该提供哪些库过程,它们的参数是什么,它们必须做什么以及它们必须返回什么结果。
除了操作系统和系统调用库外,Linux 操作系统还要提供一些标准程序,比如文本编辑器、编译器、文件操作工具等。直接和用户打交道的是上面这些应用程序。因此我们可以说 Linux 具有三种不同的接口:系统调用接口、库函数接口和应用程序接口
Linux 中的 GUI(Graphical User Interface) 和 UNIX 中的非常相似,这种 GUI 创建一个桌面环境,包括窗口、目标和文件夹、工具栏和文件拖拽功能。一个完整的 GUI 还包括窗口管理器以及各种应用程序。

Linux 上的 GUI 由 X 窗口支持,主要组成部分是 X 服务器、控制键盘、鼠标、显示器等。当在 Linux 上使用图形界面时,用户可以通过鼠标点击运行程序或者打开文件,通过拖拽将文件进行复制等。
Linux 组成部分
事实上,Linux 操作系统可以由下面这几部分构成
引导程序(Bootloader):引导程序是管理计算机启动过程的软件,对于大多数用户而言,只是弹出一个屏幕,但其实内部操作系统做了很多事情内核(Kernel):内核是操作系统的核心,负责管理 CPU、内存和外围设备等。初始化系统(Init System):这是一个引导用户空间并负责控制守护程序的子系统。一旦从引导加载程序移交了初始引导,它就是用于管理引导过程的初始化系统。后台进程(Daemon):后台进程顾名思义就是在后台运行的程序,比如打印、声音、调度等,它们可以在引导过程中启动,也可以在登录桌面后启动图形服务器(Graphical server):这是在监视器上显示图形的子系统。通常将其称为 X 服务器或 X。桌面环境(Desktop environment):这是用户与之实际交互的部分,有很多桌面环境可供选择,每个桌面环境都包含内置应用程序,比如文件管理器、Web 浏览器、游戏等应用程序(Applications):桌面环境不提供完整的应用程序,就像 Windows 和 macOS 一样,Linux 提供了成千上万个可以轻松找到并安装的高质量软件。
Shell
尽管 Linux 应用程序提供了 GUI ,但是大部分程序员仍偏好于使用命令行(command-line interface),称为shell。用户通常在 GUI 中启动一个 shell 窗口然后就在 shell 窗口下进行工作。

shell 命令行使用速度快、功能更强大、而且易于扩展、并且不会带来肢体重复性劳损(RSI)。
下面会介绍一些最简单的 bash shell。当 shell 启动时,它首先进行初始化,在屏幕上输出一个 提示符(prompt),通常是一个百分号或者美元符号,等待用户输入

等用户输入一个命令后,shell 提取其中的第一个词,这里的词指的是被空格或制表符分隔开的一连串字符。假定这个词是将要运行程序的程序名,那么就会搜索这个程序,如果找到了这个程序就会运行它。然后 shell 会将自己挂起直到程序运行完毕,之后再尝试读入下一条指令。shell 也是一个普通的用户程序。它的主要功能就是读取用户的输入和显示计算的输出。shell 命令中可以包含参数,它们作为字符串传递给所调用的程序。比如
cp src dest
会调用 cp 应用程序并包含两个参数 src 和 dest。这个程序会解释第一个参数是一个已经存在的文件名,然后创建一个该文件的副本,名称为 dest。
并不是所有的参数都是文件名,比如下面
head -20 file
第一个参数 -20,会告诉 head 应用程序打印文件的前 20 行,而不是默认的 10 行。控制命令操作或者指定可选值的参数称为标志(flag),按照惯例标志应该使用 - 来表示。这个符号是必要的,比如
head 20 file
是一个完全合法的命令,它会告诉 head 程序输出文件名为 20 的文件的前 10 行,然后输出文件名为 file 文件的前 10 行。Linux 操作系统可以接受一个或多个参数。
为了更容易的指定多个文件名,shell 支持 魔法字符(magic character),也被称为通配符(wild cards)。比如,* 可以匹配一个或者多个可能的字符串
ls *.c
告诉 ls 列举出所有文件名以 .c 结束的文件。如果同时存在多个文件,则会在后面进行并列。
另一个通配符是问号,负责匹配任意一个字符。一组在中括号中的字符可以表示其中任意一个,因此
ls [abc]*
会列举出所有以 a、b 或者 c 开头的文件。
shell 应用程序不一定通过终端进行输入和输出。shell 启动时,就会获取 标准输入、标准输出、标准错误文件进行访问的能力。
标准输出是从键盘输入的,标准输出或者标准错误是输出到显示器的。许多 Linux 程序默认是从标准输入进行输入并从标准输出进行输出。比如
sort
会调用 sort 程序,会从终端读取数据(直到用户输入 ctrl-d 结束),根据字母顺序进行排序,然后将结果输出到屏幕上。
通常还可以重定向标准输入和标准输出,重定向标准输入使用 < 后面跟文件名。标准输出可以通过一个大于号 > 进行重定向。允许一个命令中重定向标准输入和输出。例如命令
sort <in >out
会使 sort 从文件 in 中得到输入,并把结果输出到 out 文件中。由于标准错误没有重定向,所以错误信息会直接打印到屏幕上。从标准输入读入,对其进行处理并将其写入到标准输出的程序称为 过滤器。
考虑下面由三个分开的命令组成的指令
sort <in >temp;head -30 <temp;rm temp
首先会调用 sort 应用程序,从标准输入 in 中进行读取,并通过标准输出到 temp。当程序运行完毕后,shell 会运行 head ,告诉它打印前 30 行,并在标准输出(默认为终端)上打印。最后,temp 临时文件被删除。轻轻的,你走了,你挥一挥衣袖,不带走一片云彩。
命令行中的第一个程序通常会产生输出,在上面的例子中,产生的输出都不 temp 文件接收。然而,Linux 还提供了一个简单的命令来做这件事,例如下面
sort <in | head -30
上面 | 称为竖线符号,它的意思是从 sort 应用程序产生的排序输出会直接作为输入显示,无需创建、使用和移除临时文件。由管道符号连接的命令集合称为管道(pipeline)。例如如下
grep cxuan *.c | sort | head -30 | tail -5 >f00
对任意以 .t 结尾的文件中包含 cxuan 的行被写到标准输出中,然后进行排序。这些内容中的前 30 行被 head 出来并传给 tail ,它又将最后 5 行传递给 foo。这个例子提供了一个管道将多个命令连接起来。
可以把一系列 shell 命令放在一个文件中,然后将此文件作为输入来运行。shell 会按照顺序对他们进行处理,就像在键盘上键入命令一样。包含 shell 命令的文件被称为 shell 脚本(shell scripts)。
推荐一个 shell 命令的学习网站:https://www.shellscript.sh/
shell 脚本其实也是一段程序,shell 脚本中可以对变量进行赋值,也包含循环控制语句比如 if、for、while 等,shell 的设计目标是让其看起来和 C 相似(There is no doubt that C is father)。由于 shell 也是一个用户程序,所以用户可以选择不同的 shell。
Linux 应用程序
Linux 的命令行也就是 shell,它由大量标准应用程序组成。这些应用程序主要有下面六种
- 文件和目录操作命令
- 过滤器
- 文本程序
- 系统管理
- 程序开发工具,例如编辑器和编译器
- 其他
除了这些标准应用程序外,还有其他应用程序比如 Web 浏览器、多媒体播放器、图片浏览器、办公软件和游戏程序等。
我们在上面的例子中已经见过了几个 Linux 的应用程序,比如 sort、cp、ls、head,下面我们再来认识一下其他 Linux 的应用程序。
我们先从几个例子开始讲起,比如
cp a b
是将 a 复制一个副本为 b ,而
mv a b
是将 a 移动到 b ,但是删除原文件。
上面这两个命令有一些区别,cp 是将文件进行复制,复制完成后会有两个文件 a 和 b;而 mv 相当于是文件的移动,移动完成后就不再有 a 文件。cat 命令可以把多个文件内容进行连接。使用 rm 可以删除文件;使用 chmod 可以允许所有者改变访问权限;文件目录的的创建和删除可以使用 mkdir 和 rmdir 命令;使用 ls 可以查看目录文件,ls 可以显示很多属性,比如大小、用户、创建日期等;sort 决定文件的显示顺序
Linux 应用程序还包括过滤器 grep,grep 从标准输入或者一个或多个输入文件中提取特定模式的行;sort 将输入进行排序并输出到标准输出;head 提取输入的前几行;tail 提取输入的后面几行;除此之外的过滤器还有 cut 和 paste,允许对文本行的剪切和复制;od 将输入转换为 ASCII ;tr 实现字符大小写转换;pr 为格式化打印输出等。
程序编译工具使用 gcc ;
make 命令用于自动编译,这是一个很强大的命令,它用于维护一个大的程序,往往这类程序的源码由许多文件构成。典型的,有一些是 header files 头文件,源文件通常使用 include 指令包含这些文件,make 的作用就是跟踪哪些文件属于头文件,然后安排自动编译的过程。
下面列出了 POSIX 的标准应用程序
| 程序 | 应用 |
|---|---|
| ls | 列出目录 |
| cp | 复制文件 |
| head | 显示文件的前几行 |
| make | 编译文件生成二进制文件 |
| cd | 切换目录 |
| mkdir | 创建目录 |
| chmod | 修改文件访问权限 |
| ps | 列出文件进程 |
| pr | 格式化打印 |
| rm | 删除一个文件 |
| rmdir | 删除文件目录 |
| tail | 提取文件最后几行 |
| tr | 字符集转换 |
| grep | 分组 |
| cat | 将多个文件连续标准输出 |
| od | 以八进制显示文件 |
| cut | 从文件中剪切 |
| paste | 从文件中粘贴 |
Linux 内核结构
在上面我们看到了 Linux 的整体结构,下面我们从整体的角度来看一下 Linux 的内核结构

内核直接坐落在硬件上,内核的主要作用就是 I/O 交互、内存管理和控制 CPU 访问。上图中还包括了 中断 和 调度器,中断是与设备交互的主要方式。中断出现时调度器就会发挥作用。这里的低级代码停止正在运行的进程,将其状态保存在内核进程结构中,并启动驱动程序。进程调度也会发生在内核完成一些操作并且启动用户进程的时候。图中的调度器是 dispatcher。
注意这里的调度器是
dispatcher而不是scheduler,这两者是有区别的scheduler 和 dispatcher 都是和进程调度相关的概念,不同的是 scheduler 会从几个进程中随意选取一个进程;而 dispatcher 会给 scheduler 选择的进程分配 CPU。
然后,我们把内核系统分为三部分。
- I/O 部分负责与设备进行交互以及执行网络和存储 I/O 操作的所有内核部分。
从图中可以看出 I/O 层次的关系,最高层是一个虚拟文件系统,也就是说不管文件是来自内存还是磁盘中,都是经过虚拟文件系统中的。从底层看,所有的驱动都是字符驱动或者块设备驱动。二者的主要区别就是是否允许随机访问。网络驱动设备并不是一种独立的驱动设备,它实际上是一种字符设备,不过网络设备的处理方式和字符设备不同。
上面的设备驱动程序中,每个设备类型的内核代码都不同。字符设备有两种使用方式,有一键式的比如 vi 或者 emacs ,需要每一个键盘输入。其他的比如 shell ,是需要输入一行按回车键将字符串发送给程序进行编辑。
网络软件通常是模块化的,由不同的设备和协议来支持。大多数 Linux 系统在内核中包含一个完整的硬件路由器的功能,但是这个不能和外部路由器相比,路由器上面是协议栈,包括 TCP/IP 协议,协议栈上面是 socket 接口,socket 负责与外部进行通信,充当了门的作用。
磁盘驱动上面是 I/O 调度器,它负责排序和分配磁盘读写操作,以尽可能减少磁头的无用移动。
I/O 右边的是内存部件,程序被装载进内存,由 CPU 执行,这里会涉及到虚拟内存的部件,页面的换入和换出是如何进行的,坏页面的替换和经常使用的页面会进行缓存。
进程模块负责进程的创建和终止、进程的调度、Linux 把进程和线程看作是可运行的实体,并使用统一的调度策略来进行调度。
在内核最顶层的是系统调用接口,所有的系统调用都是经过这里,系统调用会触发一个 trap,将系统从用户态转换为内核态,然后将控制权移交给上面的内核部件。
# Linux内存管理-Java面试题
Linux 内存管理模型非常直接明了,因为 Linux 的这种机制使其具有可移植性并且能够在内存管理单元相差不大的机器下实现 Linux,下面我们就来认识一下 Linux 内存管理是如何实现的。
基本概念
每个 Linux 进程都会有地址空间,这些地址空间由三个段区域组成:text 段、data 段、stack 段。下面是进程地址空间的示例。

数据段(data segment) 包含了程序的变量、字符串、数组和其他数据的存储。数据段分为两部分,已经初始化的数据和尚未初始化的数据。其中尚未初始化的数据就是我们说的 BSS。数据段部分的初始化需要编译就期确定的常量以及程序启动就需要一个初始值的变量。所有 BSS 部分中的变量在加载后被初始化为 0 。
和 代码段(Text segment) 不一样,data segment 数据段可以改变。程序总是修改它的变量。而且,许多程序需要在执行时动态分配空间。Linux 允许数据段随着内存的分配和回收从而增大或者减小。为了分配内存,程序可以增加数据段的大小。在 C 语言中有一套标准库 malloc 经常用于分配内存。进程地址空间描述符包含动态分配的内存区域称为 堆(heap)。
第三部分段是 栈段(stack segment)。在大部分机器上,栈段会在虚拟内存地址顶部地址位置处,并向低位置处(向地址空间为 0 处)拓展。举个例子来说,在 32 位 x86 架构的机器上,栈开始于 0xC0000000,这是用户模式下进程允许可见的 3GB 虚拟地址限制。如果栈一直增大到超过栈段后,就会发生硬件故障并把页面下降一个页面。
当程序启动时,栈区域并不是空的,相反,它会包含所有的 shell 环境变量以及为了调用它而向 shell 输入的命令行。举个例子,当你输入
cp cxuan lx
时,cp 程序会运行并在栈中带着字符串 cp cxuan lx ,这样就能够找出源文件和目标文件的名称。
当两个用户运行在相同程序中,例如编辑器(editor),那么就会在内存中保持编辑器程序代码的两个副本,但是这种方式并不高效。Linux 系统支持共享文本段作为替代。下面图中我们会看到 A 和 B 两个进程,它们有着相同的文本区域。

数据段和栈段只有在 fork 之后才会共享,共享也是共享未修改过的页面。如果任何一个都需要变大但是没有相邻空间容纳的话,也不会有问题,因为相邻的虚拟页面不必映射到相邻的物理页面上。
除了动态分配更多的内存,Linux 中的进程可以通过内存映射文件来访问文件数据。这个特性可以使我们把一个文件映射到进程空间的一部分而该文件就可以像位于内存中的字节数组一样被读写。把一个文件映射进来使得随机读写比使用 read 和 write 之类的 I/O 系统调用要容易得多。共享库的访问就是使用了这种机制。如下所示

我们可以看到两个相同文件会被映射到相同的物理地址上,但是它们属于不同的地址空间。
映射文件的优点是,两个或多个进程可以同时映射到同一文件中,任意一个进程对文件的写操作对其他文件可见。通过使用映射临时文件的方式,可以为多线程共享内存提供高带宽,临时文件在进程退出后消失。但是实际上,并没有两个相同的地址空间,因为每个进程维护的打开文件和信号不同。
Linux 内存管理系统调用
下面我们探讨一下关于内存管理的系统调用方式。事实上,POSIX 并没有给内存管理指定任何的系统调用。然而,Linux 却有自己的内存系统调用,主要系统调用如下
| 系统调用 | 描述 |
|---|---|
| s = brk(addr) | 改变数据段大小 |
| a = mmap(addr,len,prot,flags,fd,offset) | 进行映射 |
| s = unmap(addr,len) | 取消映射 |
如果遇到错误,那么 s 的返回值是 -1,a 和 addr 是内存地址,len 表示的是长度,prot 表示的是控制保护位,flags 是其他标志位,fd 是文件描述符,offset 是文件偏移量。
brk 通过给出超过数据段之外的第一个字节地址来指定数据段的大小。如果新的值要比原来的大,那么数据区会变得越来越大,反之会越来越小。
mmap 和 unmap 系统调用会控制映射文件。mmp 的第一个参数 addr 决定了文件映射的地址。它必须是页面大小的倍数。如果参数是 0,系统会分配地址并返回 a。第二个参数是长度,它告诉了需要映射多少字节。它也是页面大小的倍数。prot 决定了映射文件的保护位,保护位可以标记为 可读、可写、可执行或者这些的结合。第四个参数 flags 能够控制文件是私有的还是可读的以及 addr 是必须的还是只是进行提示。第五个参数 fd 是要映射的文件描述符。只有打开的文件是可以被映射的,因此如果想要进行文件映射,必须打开文件;最后一个参数 offset 会指示文件从什么时候开始,并不一定每次都要从零开始。
Linux 内存管理实现
内存管理系统是操作系统最重要的部分之一。从计算机早期开始,我们实际使用的内存都要比系统中实际存在的内存多。内存分配策略克服了这一限制,并且其中最有名的就是 虚拟内存(virtual memory)。通过在多个竞争的进程之间共享虚拟内存,虚拟内存得以让系统有更多的内存。虚拟内存子系统主要包括下面这些概念。
大地址空间
操作系统使系统使用起来好像比实际的物理内存要大很多,那是因为虚拟内存要比物理内存大很多倍。
保护
系统中的每个进程都会有自己的虚拟地址空间。这些虚拟地址空间彼此完全分开,因此运行一个应用程序的进程不会影响另一个。并且,硬件虚拟内存机制允许内存保护关键内存区域。
内存映射
内存映射用来向进程地址空间映射图像和数据文件。在内存映射中,文件的内容直接映射到进程的虚拟空间中。
公平的物理内存分配
内存管理子系统允许系统中的每个正在运行的进程公平分配系统的物理内存。
共享虚拟内存
尽管虚拟内存让进程有自己的内存空间,但是有的时候你是需要共享内存的。例如几个进程同时在 shell 中运行,这会涉及到 IPC 的进程间通信问题,这个时候你需要的是共享内存来进行信息传递而不是通过拷贝每个进程的副本独立运行。
下面我们就正式探讨一下什么是 虚拟内存
虚拟内存的抽象模型
在考虑 Linux 用于支持虚拟内存的方法之前,考虑一个不会被太多细节困扰的抽象模型是很有用的。
处理器在执行指令时,会从内存中读取指令并将其解码(decode),在指令解码时会获取某个位置的内容并将他存到内存中。然后处理器继续执行下一条指令。这样,处理器总是在访问存储器以获取指令和存储数据。
在虚拟内存系统中,所有的地址空间都是虚拟的而不是物理的。但是实际存储和提取指令的是物理地址,所以需要让处理器根据操作系统维护的一张表将虚拟地址转换为物理地址。
为了简单的完成转换,虚拟地址和物理地址会被分为固定大小的块,称为 页(page)。这些页有相同大小,如果页面大小不一样的话,那么操作系统将很难管理。Alpha AXP系统上的 Linux 使用 8 KB 页面,而 Intel x86 系统上的 Linux 使用 4 KB 页面。每个页面都有一个唯一的编号,即页面框架号(PFN)。

上面就是 Linux 内存映射模型了,在这个页模型中,虚拟地址由两部分组成:偏移量和虚拟页框号。每次处理器遇到虚拟地址时都会提取偏移量和虚拟页框号。处理器必须将虚拟页框号转换为物理页号,然后以正确的偏移量的位置访问物理页。
上图中展示了两个进程 A 和 B 的虚拟地址空间,每个进程都有自己的页表。这些页表将进程中的虚拟页映射到内存中的物理页中。页表中每一项均包含
有效标志(valid flag): 表明此页表条目是否有效- 该条目描述的物理页框号
- 访问控制信息,页面使用方式,是否可写以及是否可以执行代码
要将处理器的虚拟地址映射为内存的物理地址,首先需要计算虚拟地址的页框号和偏移量。页面大小为 2 的次幂,可以通过移位完成操作。
如果当前进程尝试访问虚拟地址,但是访问不到的话,这种情况称为 缺页异常,此时虚拟操作系统的错误地址和页面错误的原因将通知操作系统。
通过以这种方式将虚拟地址映射到物理地址,虚拟内存可以以任何顺序映射到系统的物理页面。
按需分页
由于物理内存要比虚拟内存少很多,因此操作系统需要注意尽量避免直接使用低效的物理内存。节省物理内存的一种方式是仅加载执行程序当前使用的页面(这何尝不是一种懒加载的思想呢?)。例如,可以运行数据库来查询数据库,在这种情况下,不是所有的数据都装入内存,只装载需要检查的数据。这种仅仅在需要时才将虚拟页面加载进内中的技术称为按需分页。
交换
如果某个进程需要将虚拟页面传入内存,但是此时没有可用的物理页面,那么操作系统必须丢弃物理内存中的另一个页面来为该页面腾出空间。
如果页面已经修改过,那么操作系统必须保留该页面的内容,以便以后可以访问它。这种类型的页面被称为脏页,当将其从内存中移除时,它会保存在称为交换文件的特殊文件中。相对于处理器和物理内存的速度,对交换文件的访问非常慢,并且操作系统需要兼顾将页面写到磁盘的以及将它们保留在内存中以便再次使用。
Linux 使用最近最少使用(LRU)页面老化技术来公平的选择可能会从系统中删除的页面,这个方案涉及系统中的每个页面,页面的年龄随着访问次数的变化而变化,如果某个页面访问次数多,那么该页就表示越 年轻,如果某个呃页面访问次数太少,那么该页越容易被换出。
物理和虚拟寻址模式
大多数多功能处理器都支持 物理地址模式和虚拟地址模式的概念。物理寻址模式不需要页表,并且处理器不会在此模式下尝试执行任何地址转换。 Linux 内核被链接在物理地址空间中运行。
Alpha AXP 处理器没有物理寻址模式。相反,它将内存空间划分为几个区域,并将其中两个指定为物理映射的地址。此内核地址空间称为 KSEG 地址空间,它包含从 0xfffffc0000000000 向上的所有地址。为了从 KSEG 中链接的代码(按照定义,内核代码)执行或访问其中的数据,该代码必须在内核模式下执行。链接到 Alpha 上的 Linux内核以从地址 0xfffffc0000310000 执行。
访问控制
页面表的每一项还包含访问控制信息,访问控制信息主要检查进程是否应该访问内存。
必要时需要对内存进行访问限制。 例如包含可执行代码的内存,自然是只读内存; 操作系统不应允许进程通过其可执行代码写入数据。 相比之下,包含数据的页面可以被写入,但是尝试执行该内存的指令将失败。 大多数处理器至少具有两种执行模式:内核态和用户态。 你不希望访问用户执行内核代码或内核数据结构,除非处理器以内核模式运行。

访问控制信息被保存在上面的 Page Table Entry ,页表项中,上面这幅图是 Alpha AXP的 PTE。位字段具有以下含义
- V
表示 valid ,是否有效位
- FOR
读取时故障,在尝试读取此页面时出现故障
- FOW
写入时错误,在尝试写入时发生错误
- FOE
执行时发生错误,在尝试执行此页面中的指令时,处理器都会报告页面错误并将控制权传递给操作系统,
- ASM
地址空间匹配,当操作系统希望清除转换缓冲区中的某些条目时,将使用此选项。
- GH
当在使用单个转换缓冲区条目而不是多个转换缓冲区条目映射整个块时使用的提示。
- KRE
内核模式运行下的代码可以读取页面
- URE
用户模式下的代码可以读取页面
- KWE
以内核模式运行的代码可以写入页面
- UWE
以用户模式运行的代码可以写入页面
- 页框号
对于设置了 V 位的 PTE,此字段包含此 PTE 的物理页面帧号(页面帧号)。对于无效的 PTE,如果此字段不为零,则包含有关页面在交换文件中的位置的信息。
除此之外,Linux 还使用了两个位
- _PAGE_DIRTY
如果已设置,则需要将页面写出到交换文件中
- _PAGE_ACCESSED
Linux 用来将页面标记为已访问。
缓存
上面的虚拟内存抽象模型可以用来实施,但是效率不会太高。操作系统和处理器设计人员都尝试提高性能。 但是除了提高处理器,内存等的速度之外,最好的方法就是维护有用信息和数据的高速缓存,从而使某些操作更快。在 Linux 中,使用很多和内存管理有关的缓冲区,使用缓冲区来提高效率。
缓冲区缓存
缓冲区高速缓存包含块设备驱动程序使用的数据缓冲区。
还记得什么是块设备么?这里回顾下
块设备是一个能存储固定大小块信息的设备,它支持以固定大小的块,扇区或群集读取和(可选)写入数据。每个块都有自己的物理地址。通常块的大小在 512 – 65536 之间。所有传输的信息都会以连续的块为单位。块设备的基本特征是每个块都较为对立,能够独立的进行读写。常见的块设备有 硬盘、蓝光光盘、USB 盘
与字符设备相比,块设备通常需要较少的引脚。

缓冲区高速缓存通过设备标识符和块编号用于快速查找数据块。 如果可以在缓冲区高速缓存中找到数据,则无需从物理块设备中读取数据,这种访问方式要快得多。
页缓存
页缓存用于加快对磁盘上图像和数据的访问
它用于一次一页地缓存文件中的内容,并且可以通过文件和文件中的偏移量进行访问。当页面从磁盘读入内存时,它们被缓存在页面缓存中。
交换区缓存
仅仅已修改(脏页)被保存在交换文件中
只要这些页面在写入交换文件后没有修改,则下次交换该页面时,无需将其写入交换文件,因为该页面已在交换文件中。 可以直接丢弃。 在大量交换的系统中,这节省了许多不必要的和昂贵的磁盘操作。
硬件缓存
处理器中通常使用一种硬件缓存。页表条目的缓存。在这种情况下,处理器并不总是直接读取页表,而是根据需要缓存页的翻译。 这些是转换后备缓冲区 也被称为 TLB,包含来自系统中一个或多个进程的页表项的缓存副本。
引用虚拟地址后,处理器将尝试查找匹配的 TLB 条目。 如果找到,则可以将虚拟地址直接转换为物理地址,并对数据执行正确的操作。 如果处理器找不到匹配的 TLB 条目, 它通过向操作系统发信号通知已发生 TLB 丢失获得操作系统的支持和帮助。系统特定的机制用于将该异常传递给可以修复问题的操作系统代码。 操作系统为地址映射生成一个新的 TLB 条目。 清除异常后,处理器将再次尝试转换虚拟地址。这次能够执行成功。
使用缓存也存在缺点,为了节省精力,Linux 必须使用更多的时间和空间来维护这些缓存,并且如果缓存损坏,系统将会崩溃。
Linux 页表
Linux 假定页表分为三个级别。访问的每个页表都包含下一级页表

图中的 PDG 表示全局页表,当创建一个新的进程时,都要为新进程创建一个新的页面目录,即 PGD。
要将虚拟地址转换为物理地址,处理器必须获取每个级别字段的内容,将其转换为包含页表的物理页的偏移量,并读取下一级页表的页框号。这样重复三次,直到找到包含虚拟地址的物理页面的页框号为止。
Linux 运行的每个平台都必须提供翻译宏,这些宏允许内核遍历特定进程的页表。这样,内核无需知道页表条目的格式或它们的排列方式。
页分配和取消分配
对系统中物理页面有很多需求。例如,当图像加载到内存中时,操作系统需要分配页面。
系统中所有物理页面均由 mem_map 数据结构描述,这个数据结构是 mem_map_t 的列表。它包括一些重要的属性
- count :这是页面的用户数计数,当页面在多个进程之间共享时,计数大于 1
- age:这是描述页面的年龄,用于确定页面是否适合丢弃或交换
- map_nr :这是此mem_map_t描述的物理页框号。
页面分配代码使用 free_area向量查找和释放页面,free_area 的每个元素都包含有关页面块的信息。
页面分配
Linux 的页面分配使用一种著名的伙伴算法来进行页面的分配和取消分配。页面以 2 的幂为单位进行块分配。这就意味着它可以分配 1页、2 页、4页等等,只要系统中有足够可用的页面来满足需求就可以。判断的标准是nr_free_pages> min_free_pages,如果满足,就会在 free_area 中搜索所需大小的页面块完成分配。free_area 的每个元素都有该大小的块的已分配页面和空闲页面块的映射。
分配算法会搜索请求大小的页面块。如果没有任何请求大小的页面块可用的话,会搜寻一个是请求大小二倍的页面块,然后重复,直到一直搜寻完 free_area 找到一个页面块为止。如果找到的页面块要比请求的页面块大,就会对找到的页面块进行细分,直到找到合适的大小块为止。
因为每个块都是 2 的次幂,所以拆分过程很容易,因为你只需将块分成两半即可。空闲块在适当的队列中排队,分配的页面块返回给调用者。

如果请求一个 2 个页的块,则 4 页的第一个块(从第 4 页的框架开始)将被分成两个 2 页的块。第一个页面(从第 4 页的帧开始)将作为分配的页面返回给调用方,第二个块(从第 6 页的页面开始)将作为 2 页的空闲块排队到 free_area 数组的元素 1 上。
页面取消分配
上面的这种内存方式最造成一种后果,那就是内存的碎片化,会将较大的空闲页面分成较小的页面。页面解除分配代码会尽可能将页面重新组合成为更大的空闲块。每释放一个页面,都会检查相同大小的相邻的块,以查看是否空闲。如果是,则将其与新释放的页面块组合以形成下一个页面大小块的新的自由页面块。 每次将两个页面块重新组合为更大的空闲页面块时,页面释放代码就会尝试将该页面块重新组合为更大的空闲页面。 通过这种方式,可用页面的块将尽可能多地使用内存。
例如上图,如果要释放第 1 页的页面,则将其与已经空闲的第 0 页页面框架组合在一起,并作为大小为 2页的空闲块排队到 free_area 的元素 1 中
内存映射
内核有两种类型的内存映射:共享型(shared) 和私有型(private)。私有型是当进程为了只读文件,而不写文件时使用,这时,私有映射更加高效。 但是,任何对私有映射页的写操作都会导致内核停止映射该文件中的页。所以,写操作既不会改变磁盘上的文件,对访问该文件的其它进程也是不可见的。
按需分页
一旦可执行映像被内存映射到虚拟内存后,它就可以被执行了。因为只将映像的开头部分物理的拉入到内存中,因此它将很快访问物理内存尚未存在的虚拟内存区域。当进程访问没有有效页表的虚拟地址时,操作系统会报告这项错误。
页面错误描述页面出错的虚拟地址和引起的内存访问(RAM)类型。
Linux 必须找到代表发生页面错误的内存区域的 vm_area_struct 结构。由于搜索 vm_area_struct 数据结构对于有效处理页面错误至关重要,因此它们以 AVL(Adelson-Velskii和Landis)树结构链接在一起。如果引起故障的虚拟地址没有 vm_area_struct 结构,则此进程已经访问了非法地址,Linux 会向进程发出 SIGSEGV 信号,如果进程没有用于该信号的处理程序,那么进程将会终止。
然后,Linux 会针对此虚拟内存区域所允许的访问类型,检查发生的页面错误类型。 如果该进程以非法方式访问内存,例如写入仅允许读的区域,则还会发出内存访问错误信号。
现在,Linux 已确定页面错误是合法的,因此必须对其进行处理。
# Linux进程和线程-Java面试题
上一篇文章
https://github.com/crisxuan/bestJavaer/blob/master/linux/linux-first.md
只是简单的描述了一下 Linux 基本概念,通过几个例子来说明 Linux 基本应用程序,然后以 Linux 基本内核构造来结尾。那么本篇文章我们就深入理解一下 Linux 内核来理解 Linux 的基本概念之进程和线程。系统调用是操作系统本身的接口,它对于创建进程和线程,内存分配,共享文件和 I/O 来说都很重要。
我们将从各个版本的共性出发来进行探讨。
基本概念
Linux 一个非常重要的概念就是进程,Linux 进程和我们在现代操作系统中探讨的进程模型非常相似。每个进程都会运行一段独立的程序,并且在初始化的时候拥有一个独立的控制线程。换句话说,每个进程都会有一个自己的程序计数器,这个程序计数器用来记录下一个需要被执行的指令。Linux 允许进程在运行时创建额外的线程。

Linux 是一个多道程序设计系统,因此系统中存在彼此相互独立的进程同时运行。此外,每个用户都会同时有几个活动的进程。因为如果是一个大型系统,可能有数百上千的进程在同时运行。
在某些用户空间中,即使用户退出登录,仍然会有一些后台进程在运行,这些进程被称为 守护进程(daemon)。
Linux 中有一种特殊的守护进程被称为 计划守护进程(Cron daemon) ,计划守护进程可以每分钟醒来一次检查是否有工作要做,做完会继续回到睡眠状态等待下一次唤醒。

Cron 是一个守护程序,可以做任何你想做的事情,比如说你可以定期进行系统维护、定期进行系统备份等。在其他操作系统上也有类似的程序,比如 Mac OS X 上 Cron 守护程序被称为
launchd的守护进程。在 Windows 上可以被称为计划任务(Task Scheduler)。
在 Linux 系统中,进程通过非常简单的方式来创建,fork 系统调用会创建一个源进程的拷贝(副本)。调用 fork 函数的进程被称为 父进程(parent process),使用 fork 函数创建出来的进程被称为 子进程(child process)。父进程和子进程都有自己的内存映像。如果在子进程创建出来后,父进程修改了一些变量等,那么子进程是看不到这些变化的,也就是 fork 后,父进程和子进程相互独立。
虽然父进程和子进程保持相互独立,但是它们却能够共享相同的文件,如果在 fork 之前,父进程已经打开了某个文件,那么 fork 后,父进程和子进程仍然共享这个打开的文件。对共享文件的修改会对父进程和子进程同时可见。
那么该如何区分父进程和子进程呢?子进程只是父进程的拷贝,所以它们几乎所有的情况都一样,包括内存映像、变量、寄存器等。区分的关键在于 fork 函数调用后的返回值,如果 fork 后返回一个非零值,这个非零值即是子进程的 进程标识符(Process Identiier, PID),而会给子进程返回一个零值,可以用下面代码来进行表示
pid = fork(); // 调用 fork 函数创建进程 if(pid < 0){ error() // pid < 0,创建失败 } else if(pid > 0){ parent_handle() // 父进程代码 } else { child_handle() // 子进程代码 }
父进程在 fork 后会得到子进程的 PID,这个 PID 即能代表这个子进程的唯一标识符也就是 PID。如果子进程想要知道自己的 PID,可以调用 getpid 方法。当子进程结束运行时,父进程会得到子进程的 PID,因为一个进程会 fork 很多子进程,子进程也会 fork 子进程,所以 PID 是非常重要的。我们把第一次调用 fork 后的进程称为 原始进程,一个原始进程可以生成一颗继承树

Linux 进程间通信
Linux 进程间的通信机制通常被称为 Internel-Process communication,IPC 下面我们来说一说 Linux 进程间通信的机制,大致来说,Linux 进程间的通信机制可以分为 6 种

下面我们分别对其进行概述
信号 signal
信号是 UNIX 系统最先开始使用的进程间通信机制,因为 Linux 是继承于 UNIX 的,所以 Linux 也支持信号机制,通过向一个或多个进程发送异步事件信号来实现,信号可以从键盘或者访问不存在的位置等地方产生;信号通过 shell 将任务发送给子进程。
你可以在 Linux 系统上输入 kill -l 来列出系统使用的信号,下面是我提供的一些信号

进程可以选择忽略发送过来的信号,但是有两个是不能忽略的:SIGSTOP 和 SIGKILL 信号。SIGSTOP 信号会通知当前正在运行的进程执行关闭操作,SIGKILL 信号会通知当前进程应该被杀死。除此之外,进程可以选择它想要处理的信号,进程也可以选择阻止信号,如果不阻止,可以选择自行处理,也可以选择进行内核处理。如果选择交给内核进行处理,那么就执行默认处理。
操作系统会中断目标程序的进程来向其发送信号、在任何非原子指令中,执行都可以中断,如果进程已经注册了新号处理程序,那么就执行进程,如果没有注册,将采用默认处理的方式。
例如:当进程收到 SIGFPE 浮点异常的信号后,默认操作是对其进行 dump(转储)和退出。信号没有优先级的说法。如果同时为某个进程产生了两个信号,则可以将它们呈现给进程或者以任意的顺序进行处理。
下面我们就来看一下这些信号是干什么用的
- SIGABRT 和 SIGIOT
SIGABRT 和 SIGIOT 信号发送给进程,告诉其进行终止,这个 信号通常在调用 C标准库的abort()函数时由进程本身启动
- SIGALRM 、 SIGVTALRM、SIGPROF
当设置的时钟功能超时时会将 SIGALRM 、 SIGVTALRM、SIGPROF 发送给进程。当实际时间或时钟时间超时时,发送 SIGALRM。 当进程使用的 CPU 时间超时时,将发送 SIGVTALRM。 当进程和系统代表进程使用的CPU 时间超时时,将发送 SIGPROF。
- SIGBUS
SIGBUS 将造成总线中断错误时发送给进程
- SIGCHLD
当子进程终止、被中断或者被中断恢复,将 SIGCHLD 发送给进程。此信号的一种常见用法是指示操作系统在子进程终止后清除其使用的资源。
- SIGCONT
SIGCONT 信号指示操作系统继续执行先前由 SIGSTOP 或 SIGTSTP 信号暂停的进程。该信号的一个重要用途是在 Unix shell 中的作业控制中。
- SIGFPE
SIGFPE 信号在执行错误的算术运算(例如除以零)时将被发送到进程。

- SIGUP
当 SIGUP 信号控制的终端关闭时,会发送给进程。许多守护程序将重新加载其配置文件并重新打开其日志文件,而不是在收到此信号时退出。
- SIGILL
SIGILL 信号在尝试执行非法、格式错误、未知或者特权指令时发出
- SIGINT
当用户希望中断进程时,操作系统会向进程发送 SIGINT 信号。用户输入 ctrl – c 就是希望中断进程。
- SIGKILL
SIGKILL 信号发送到进程以使其马上进行终止。 与 SIGTERM 和 SIGINT 相比,这个信号无法捕获和忽略执行,并且进程在接收到此信号后无法执行任何清理操作,下面是一些例外情况
僵尸进程无法杀死,因为僵尸进程已经死了,它在等待父进程对其进行捕获
处于阻塞状态的进程只有再次唤醒后才会被 kill 掉
init 进程是 Linux 的初始化进程,这个进程会忽略任何信号。
SIGKILL 通常是作为最后杀死进程的信号、它通常作用于 SIGTERM 没有响应时发送给进程。
- SIGPIPE
SIGPIPE 尝试写入进程管道时发现管道未连接无法写入时发送到进程
- SIGPOLL
当在明确监视的文件描述符上发生事件时,将发送 SIGPOLL 信号。
- SIGRTMIN 至 SIGRTMAX
SIGRTMIN 至 SIGRTMAX 是实时信号
- SIGQUIT
当用户请求退出进程并执行核心转储时,SIGQUIT 信号将由其控制终端发送给进程。
- SIGSEGV
当 SIGSEGV 信号做出无效的虚拟内存引用或分段错误时,即在执行分段违规时,将其发送到进程。
- SIGSTOP
SIGSTOP 指示操作系统终止以便以后进行恢复时
- SIGSYS
当 SIGSYS 信号将错误参数传递给系统调用时,该信号将发送到进程。
- SYSTERM
我们上面简单提到过了 SYSTERM 这个名词,这个信号发送给进程以请求终止。与 SIGKILL 信号不同,该信号可以被过程捕获或忽略。这允许进程执行良好的终止,从而释放资源并在适当时保存状态。 SIGINT 与SIGTERM 几乎相同。
- SIGTSIP
SIGTSTP 信号由其控制终端发送到进程,以请求终端停止。
- SIGTTIN 和 SIGTTOU
当 SIGTTIN 和SIGTTOU 信号分别在后台尝试从 tty 读取或写入时,信号将发送到该进程。
- SIGTRAP
在发生异常或者 trap 时,将 SIGTRAP 信号发送到进程
- SIGURG
当套接字具有可读取的紧急或带外数据时,将 SIGURG 信号发送到进程。
- SIGUSR1 和 SIGUSR2
SIGUSR1 和 SIGUSR2 信号被发送到进程以指示用户定义的条件。
- SIGXCPU
当 SIGXCPU 信号耗尽 CPU 的时间超过某个用户可设置的预定值时,将其发送到进程
- SIGXFSZ
当 SIGXFSZ 信号增长超过最大允许大小的文件时,该信号将发送到该进程。
- SIGWINCH
SIGWINCH 信号在其控制终端更改其大小(窗口更改)时发送给进程。
管道 pipe
Linux 系统中的进程可以通过建立管道 pipe 进行通信

在两个进程之间,可以建立一个通道,一个进程向这个通道里写入字节流,另一个进程从这个管道中读取字节流。管道是同步的,当进程尝试从空管道读取数据时,该进程会被阻塞,直到有可用数据为止。shell 中的管线 pipelines 就是用管道实现的,当 shell 发现输出
sort <f | head
它会创建两个进程,一个是 sort,一个是 head,sort,会在这两个应用程序之间建立一个管道使得 sort 进程的标准输出作为 head 程序的标准输入。sort 进程产生的输出就不用写到文件中了,如果管道满了系统会停止 sort 以等待 head 读出数据

管道实际上就是 |,两个应用程序不知道有管道的存在,一切都是由 shell 管理和控制的。
共享内存 shared memory
两个进程之间还可以通过共享内存进行进程间通信,其中两个或者多个进程可以访问公共内存空间。两个进程的共享工作是通过共享内存完成的,一个进程所作的修改可以对另一个进程可见(很像线程间的通信)。

在使用共享内存前,需要经过一系列的调用流程,流程如下
- 创建共享内存段或者使用已创建的共享内存段
(shmget()) - 将进程附加到已经创建的内存段中
(shmat()) - 从已连接的共享内存段分离进程
(shmdt()) - 对共享内存段执行控制操作
(shmctl())
先入先出队列 FIFO
先入先出队列 FIFO 通常被称为 命名管道(Named Pipes),命名管道的工作方式与常规管道非常相似,但是确实有一些明显的区别。未命名的管道没有备份文件:操作系统负责维护内存中的缓冲区,用来将字节从写入器传输到读取器。一旦写入或者输出终止的话,缓冲区将被回收,传输的数据会丢失。相比之下,命名管道具有支持文件和独特 API ,命名管道在文件系统中作为设备的专用文件存在。当所有的进程通信完成后,命名管道将保留在文件系统中以备后用。命名管道具有严格的 FIFO 行为

写入的第一个字节是读取的第一个字节,写入的第二个字节是读取的第二个字节,依此类推。
消息队列 Message Queue
一听到消息队列这个名词你可能不知道是什么意思,消息队列是用来描述内核寻址空间内的内部链接列表。可以按几种不同的方式将消息按顺序发送到队列并从队列中检索消息。每个消息队列由 IPC 标识符唯一标识。消息队列有两种模式,一种是严格模式, 严格模式就像是 FIFO 先入先出队列似的,消息顺序发送,顺序读取。还有一种模式是 非严格模式,消息的顺序性不是非常重要。
套接字 Socket
还有一种管理两个进程间通信的是使用 socket,socket 提供端到端的双相通信。一个套接字可以与一个或多个进程关联。就像管道有命令管道和未命名管道一样,套接字也有两种模式,套接字一般用于两个进程之间的网络通信,网络套接字需要来自诸如TCP(传输控制协议)或较低级别UDP(用户数据报协议)等基础协议的支持。
套接字有以下几种分类
顺序包套接字(Sequential Packet Socket): 此类套接字为最大长度固定的数据报提供可靠的连接。此连接是双向的并且是顺序的。数据报套接字(Datagram Socket):数据包套接字支持双向数据流。数据包套接字接受消息的顺序与发送者可能不同。流式套接字(Stream Socket):流套接字的工作方式类似于电话对话,提供双向可靠的数据流。原始套接字(Raw Socket): 可以使用原始套接字访问基础通信协议。
Linux 中进程管理系统调用
现在关注一下 Linux 系统中与进程管理相关的系统调用。在了解之前你需要先知道一下什么是系统调用。
操作系统为我们屏蔽了硬件和软件的差异,它的最主要功能就是为用户提供一种抽象,隐藏内部实现,让用户只关心在 GUI 图形界面下如何使用即可。操作系统可以分为两种模式
- 内核态:操作系统内核使用的模式
- 用户态:用户应用程序所使用的模式
我们常说的上下文切换 指的就是内核态模式和用户态模式的频繁切换。而系统调用指的就是引起内核态和用户态切换的一种方式,系统调用通常在后台静默运行,表示计算机程序向其操作系统内核请求服务。
系统调用指令有很多,下面是一些与进程管理相关的最主要的系统调用
fork
fork 调用用于创建一个与父进程相同的子进程,创建完进程后的子进程拥有和父进程一样的程序计数器、相同的 CPU 寄存器、相同的打开文件。
exec
exec 系统调用用于执行驻留在活动进程中的文件,调用 exec 后,新的可执行文件会替换先前的可执行文件并获得执行。也就是说,调用 exec 后,会将旧文件或程序替换为新文件或执行,然后执行文件或程序。新的执行程序被加载到相同的执行空间中,因此进程的 PID 不会修改,因为我们没有创建新进程,只是替换旧进程。但是进程的数据、代码、堆栈都已经被修改。如果当前要被替换的进程包含多个线程,那么所有的线程将被终止,新的进程映像被加载执行。
这里需要解释一下进程映像(Process image) 的概念
什么是进程映像呢?进程映像是执行程序时所需要的可执行文件,通常会包括下面这些东西
- 代码段(codesegment/textsegment)
又称文本段,用来存放指令,运行代码的一块内存空间
此空间大小在代码运行前就已经确定
内存空间一般属于只读,某些架构的代码也允许可写
在代码段中,也有可能包含一些只读的常数变量,例如字符串常量等。
- 数据段(datasegment)
可读可写
存储初始化的全局变量和初始化的 static 变量
数据段中数据的生存期是随程序持续性(随进程持续性)
随进程持续性:进程创建就存在,进程死亡就消失
- bss 段(bsssegment):
可读可写
存储未初始化的全局变量和未初始化的 static 变量
bss 段中的数据一般默认为 0
- Data 段
是可读写的,因为变量的值可以在运行时更改。此段的大小也固定。
- 栈(stack):
可读可写
存储的是函数或代码中的局部变量(非 static 变量)
栈的生存期随代码块持续性,代码块运行就给你分配空间,代码块结束,就自动回收空间
- 堆(heap):
可读可写
存储的是程序运行期间动态分配的 malloc/realloc 的空间
堆的生存期随进程持续性,从 malloc/realloc 到 free 一直存在
下面是这些区域的构成图

exec 系统调用是一些函数的集合,这些函数是
- execl
- execle
- execlp
- execv
- execve
- execvp
下面来看一下 exec 的工作原理
- 当前进程映像被替换为新的进程映像
- 新的进程映像是你做为 exec 传递的灿睡
- 结束当前正在运行的进程
- 新的进程映像有 PID,相同的环境和一些文件描述符(因为未替换进程,只是替换了进程映像)
- CPU 状态和虚拟内存受到影响,当前进程映像的虚拟内存映射被新进程映像的虚拟内存代替。
waitpid
等待子进程结束或终止
exit
在许多计算机操作系统上,计算机进程的终止是通过执行 exit 系统调用命令执行的。0 表示进程能够正常结束,其他值表示进程以非正常的行为结束。
其他一些常见的系统调用如下
| 系统调用指令 | 描述 |
|---|---|
| pause | 挂起信号 |
| nice | 改变分时进程的优先级 |
| ptrace | 进程跟踪 |
| kill | 向进程发送信号 |
| pipe | 创建管道 |
| mkfifo | 创建 fifo 的特殊文件(命名管道) |
| sigaction | 设置对指定信号的处理方法 |
| msgctl | 消息控制操作 |
| semctl | 信号量控制 |
Linux 进程和线程的实现
Linux 进程
Linux 进程就像一座冰山,你看到的只是冰山一角。

在 Linux 内核结构中,进程会被表示为 任务,通过结构体 structure 来创建。不像其他的操作系统会区分进程、轻量级进程和线程,Linux 统一使用任务结构来代表执行上下文。因此,对于每个单线程进程来说,单线程进程将用一个任务结构表示,对于多线程进程来说,将为每一个用户级线程分配一个任务结构。Linux 内核是多线程的,并且内核级线程不与任何用户级线程相关联。
对于每个进程来说,在内存中都会有一个 task_struct 进程描述符与之对应。进程描述符包含了内核管理进程所有有用的信息,包括 调度参数、打开文件描述符等等。进程描述符从进程创建开始就一直存在于内核堆栈中。
Linux 和 Unix 一样,都是通过 PID 来区分不同的进程,内核会将所有进程的任务结构组成为一个双向链表。PID 能够直接被映射称为进程的任务结构所在的地址,从而不需要遍历双向链表直接访问。
我们上面提到了进程描述符,这是一个非常重要的概念,我们上面还提到了进程描述符是位于内存中的,这里我们省略了一句话,那就是进程描述符是存在用户的任务结构中,当进程位于内存并开始运行时,进程描述符才会被调入内存。
进程位于内存被称为PIM(Process In Memory),这是冯诺伊曼体系架构的一种体现,加载到内存中并执行的程序称为进程。简单来说,一个进程就是正在执行的程序。
进程描述符可以归为下面这几类
调度参数(scheduling parameters):进程优先级、最近消耗 CPU 的时间、最近睡眠时间一起决定了下一个需要运行的进程内存映像(memory image):我们上面说到,进程映像是执行程序时所需要的可执行文件,它由数据和代码组成。信号(signals):显示哪些信号被捕获、哪些信号被执行寄存器:当发生内核陷入 (trap) 时,寄存器的内容会被保存下来。系统调用状态(system call state):当前系统调用的信息,包括参数和结果文件描述符表(file descriptor table):有关文件描述符的系统被调用时,文件描述符作为索引在文件描述符表中定位相关文件的 i-node 数据结构统计数据(accounting):记录用户、进程占用系统 CPU 时间表的指针,一些操作系统还保存进程最多占用的 CPU 时间、进程拥有的最大堆栈空间、进程可以消耗的页面数等。内核堆栈(kernel stack):进程的内核部分可以使用的固定堆栈其他: 当前进程状态、事件等待时间、距离警报的超时时间、PID、父进程的 PID 以及用户标识符等
有了上面这些信息,现在就很容易描述在 Linux 中是如何创建这些进程的了,创建新流程实际上非常简单。为子进程开辟一块新的用户空间的进程描述符,然后从父进程复制大量的内容。为这个子进程分配一个 PID,设置其内存映射,赋予它访问父进程文件的权限,注册并启动。
当执行 fork 系统调用时,调用进程会陷入内核并创建一些和任务相关的数据结构,比如内核堆栈(kernel stack) 和 thread_info 结构。
关于 thread_info 结构可以参考
这个结构中包含进程描述符,进程描述符位于固定的位置,使得 Linux 系统只需要很小的开销就可以定位到一个运行中进程的数据结构。
进程描述符的主要内容是根据父进程的描述符来填充。Linux 操作系统会寻找一个可用的 PID,并且此 PID 没有被任何进程使用,更新进程标示符使其指向一个新的数据结构即可。为了减少 hash table 的碰撞,进程描述符会形成链表。它还将 task_struct 的字段设置为指向任务数组上相应的上一个/下一个进程。
task_struct : Linux 进程描述符,内部涉及到众多 C++ 源码,我们会在后面进行讲解。
从原则上来说,为子进程开辟内存区域并为子进程分配数据段、堆栈段,并且对父进程的内容进行复制,但是实际上 fork 完成后,子进程和父进程没有共享内存,所以需要复制技术来实现同步,但是复制开销比较大,因此 Linux 操作系统使用了一种 欺骗 方式。即为子进程分配页表,然后新分配的页表指向父进程的页面,同时这些页面是只读的。当进程向这些页面进行写入的时候,会开启保护错误。内核发现写入操作后,会为进程分配一个副本,使得写入时把数据复制到这个副本上,这个副本是共享的,这种方式称为 写入时复制(copy on write),这种方式避免了在同一块内存区域维护两个副本的必要,节省内存空间。
在子进程开始运行后,操作系统会调用 exec 系统调用,内核会进行查找验证可执行文件,把参数和环境变量复制到内核,释放旧的地址空间。
现在新的地址空间需要被创建和填充。如果系统支持映射文件,就像 Unix 系统一样,那么新的页表就会创建,表明内存中没有任何页,除非所使用的页面是堆栈页,其地址空间由磁盘上的可执行文件支持。新进程开始运行时,立刻会收到一个缺页异常(page fault),这会使具有代码的页面加载进入内存。最后,参数和环境变量被复制到新的堆栈中,重置信号,寄存器全部清零。新的命令开始运行。
下面是一个示例,用户输出 ls,shell 会调用 fork 函数复制一个新进程,shell 进程会调用 exec 函数用可执行文件 ls 的内容覆盖它的内存。

Linux 线程
现在我们来讨论一下 Linux 中的线程,线程是轻量级的进程,想必这句话你已经听过很多次了,轻量级体现在所有的进程切换都需要清除所有的表、进程间的共享信息也比较麻烦,一般来说通过管道或者共享内存,如果是 fork 函数后的父子进程则使用共享文件,然而线程切换不需要像进程一样具有昂贵的开销,而且线程通信起来也更方便。线程分为两种:用户级线程和内核级线程
用户级线程
用户级线程避免使用内核,通常,每个线程会显示调用开关,发送信号或者执行某种切换操作来放弃 CPU,同样,计时器可以强制进行开关,用户线程的切换速度通常比内核线程快很多。在用户级别实现线程会有一个问题,即单个线程可能会垄断 CPU 时间片,导致其他线程无法执行从而 饿死。如果执行一个 I/O 操作,那么 I/O 会阻塞,其他线程也无法运行。

一种解决方案是,一些用户级的线程包解决了这个问题。可以使用时钟周期的监视器来控制第一时间时间片独占。然后,一些库通过特殊的包装来解决系统调用的 I/O 阻塞问题,或者可以为非阻塞 I/O 编写任务。
内核级线程
内核级线程通常使用几个进程表在内核中实现,每个任务都会对应一个进程表。在这种情况下,内核会在每个进程的时间片内调度每个线程。

所有能够阻塞的调用都会通过系统调用的方式来实现,当一个线程阻塞时,内核可以进行选择,是运行在同一个进程中的另一个线程(如果有就绪线程的话)还是运行一个另一个进程中的线程。
从用户空间 -> 内核空间 -> 用户空间的开销比较大,但是线程初始化的时间损耗可以忽略不计。这种实现的好处是由时钟决定线程切换时间,因此不太可能将时间片与任务中的其他线程占用时间绑定到一起。同样,I/O 阻塞也不是问题。
混合实现
结合用户空间和内核空间的优点,设计人员采用了一种内核级线程的方式,然后将用户级线程与某些或者全部内核线程多路复用起来

在这种模型中,编程人员可以自由控制用户线程和内核线程的数量,具有很大的灵活度。采用这种方法,内核只识别内核级线程,并对其进行调度。其中一些内核级线程会被多个用户级线程多路复用。
Linux 调度
下面我们来关注一下 Linux 系统的调度算法,首先需要认识到,Linux 系统的线程是内核线程,所以 Linux 系统是基于线程的,而不是基于进程的。
为了进行调度,Linux 系统将线程分为三类
- 实时先入先出
- 实时轮询
- 分时
实时先入先出线程具有最高优先级,它不会被其他线程所抢占,除非那是一个刚刚准备好的,拥有更高优先级的线程进入。实时轮转线程与实时先入先出线程基本相同,只是每个实时轮转线程都有一个时间量,时间到了之后就可以被抢占。如果多个实时线程准备完毕,那么每个线程运行它时间量所规定的时间,然后插入到实时轮转线程末尾。
注意这个实时只是相对的,无法做到绝对的实时,因为线程的运行时间无法确定。它们相对分时系统来说,更加具有实时性
Linux 系统会给每个线程分配一个 nice 值,这个值代表了优先级的概念。nice 值默认值是 0 ,但是可以通过系统调用 nice 值来修改。修改值的范围从 -20 – +19。nice 值决定了线程的静态优先级。一般系统管理员的 nice 值会比一般线程的优先级高,它的范围是 -20 – -1。
下面我们更详细的讨论一下 Linux 系统的两个调度算法,它们的内部与调度队列(runqueue) 的设计很相似。运行队列有一个数据结构用来监视系统中所有可运行的任务并选择下一个可以运行的任务。每个运行队列和系统中的每个 CPU 有关。
Linux O(1) 调度器是历史上很流行的一个调度器。这个名字的由来是因为它能够在常数时间内执行任务调度。在 O(1) 调度器里,调度队列被组织成两个数组,一个是任务正在活动的数组,一个是任务过期失效的数组。如下图所示,每个数组都包含了 140 个链表头,每个链表头具有不同的优先级。

大致流程如下:
调度器从正在活动数组中选择一个优先级最高的任务。如果这个任务的时间片过期失效了,就把它移动到过期失效数组中。如果这个任务阻塞了,比如说正在等待 I/O 事件,那么在它的时间片过期失效之前,一旦 I/O 操作完成,那么这个任务将会继续运行,它将被放回到之前正在活动的数组中,因为这个任务之前已经消耗一部分 CPU 时间片,所以它将运行剩下的时间片。当这个任务运行完它的时间片后,它就会被放到过期失效数组中。一旦正在活动的任务数组中没有其他任务后,调度器将会交换指针,使得正在活动的数组变为过期失效数组,过期失效数组变为正在活动的数组。使用这种方式可以保证每个优先级的任务都能够得到执行,不会导致线程饥饿。
在这种调度方式中,不同优先级的任务所得到 CPU 分配的时间片也是不同的,高优先级进程往往能得到较长的时间片,低优先级的任务得到较少的时间片。
这种方式为了保证能够更好的提供服务,通常会为 交互式进程 赋予较高的优先级,交互式进程就是用户进程。
Linux 系统不知道一个任务究竟是 I/O 密集型的还是 CPU 密集型的,它只是依赖于交互式的方式,Linux 系统会区分是静态优先级 还是 动态优先级。动态优先级是采用一种奖励机制来实现的。奖励机制有两种方式:奖励交互式线程、惩罚占用 CPU 的线程。在 Linux O(1) 调度器中,最高的优先级奖励是 -5,注意这个优先级越低越容易被线程调度器接受,所以最高惩罚的优先级是 +5。具体体现就是操作系统维护一个名为 sleep_avg 的变量,任务唤醒会增加 sleep_avg 变量的值,当任务被抢占或者时间量过期会减少这个变量的值,反映在奖励机制上。
O(1) 调度算法是 2.6 内核版本的调度器,最初引入这个调度算法的是不稳定的 2.5 版本。早期的调度算法在多处理器环境中说明了通过访问正在活动数组就可以做出调度的决定。使调度可以在固定的时间 O(1) 完成。
O(1) 调度器使用了一种 启发式 的方式,这是什么意思?
在计算机科学中,启发式是一种当传统方式解决问题很慢时用来快速解决问题的方式,或者找到一个在传统方法无法找到任何精确解的情况下找到近似解。
O(1) 使用启发式的这种方式,会使任务的优先级变得复杂并且不完善,从而导致在处理交互任务时性能很糟糕。
为了改进这个缺点,O(1) 调度器的开发者又提出了一个新的方案,即 公平调度器(Completely Fair Scheduler, CFS)。 CFS 的主要思想是使用一颗红黑树作为调度队列。
数据结构太重要了。
CFS 会根据任务在 CPU 上的运行时间长短而将其有序地排列在树中,时间精确到纳秒级。下面是 CFS 的构造模型

CFS 的调度过程如下:
CFS 算法总是优先调度哪些使用 CPU 时间最少的任务。最小的任务一般都是在最左边的位置。当有一个新的任务需要运行时,CFS 会把这个任务和最左边的数值进行对比,如果此任务具有最小时间值,那么它将进行运行,否则它会进行比较,找到合适的位置进行插入。然后 CPU 运行红黑树上当前比较的最左边的任务。
在红黑树中选择一个节点来运行的时间可以是常数时间,但是插入一个任务的时间是 O(loog(N)),其中 N 是系统中的任务数。考虑到当前系统的负载水平,这是可以接受的。
调度器只需要考虑可运行的任务即可。这些任务被放在适当的调度队列中。不可运行的任务和正在等待的各种 I/O 操作或内核事件的任务被放入一个等待队列中。等待队列头包含一个指向任务链表的指针和一个自旋锁。自旋锁对于并发处理场景下用处很大。
Linux 系统中的同步
下面来聊一下 Linux 中的同步机制。早期的 Linux 内核只有一个 大内核锁(Big Kernel Lock,BKL) 。它阻止了不同处理器并发处理的能力。因此,需要引入一些粒度更细的锁机制。
Linux 提供了若干不同类型的同步变量,这些变量既能够在内核中使用,也能够在用户应用程序中使用。在地层中,Linux 通过使用 atomic_set 和 atomic_read 这样的操作为硬件支持的原子指令提供封装。硬件提供内存重排序,这是 Linux 屏障的机制。
具有高级别的同步像是自旋锁的描述是这样的,当两个进程同时对资源进行访问,在一个进程获得资源后,另一个进程不想被阻塞,所以它就会自旋,等待一会儿再对资源进行访问。Linux 也提供互斥量或信号量这样的机制,也支持像是 mutex_tryLock 和 mutex_tryWait 这样的非阻塞调用。也支持中断处理事务,也可以通过动态禁用和启用相应的中断来实现。
Linux 启动
下面来聊一聊 Linux 是如何启动的。
当计算机电源通电后,BIOS会进行开机自检(Power-On-Self-Test, POST),对硬件进行检测和初始化。因为操作系统的启动会使用到磁盘、屏幕、键盘、鼠标等设备。下一步,磁盘中的第一个分区,也被称为 MBR(Master Boot Record) 主引导记录,被读入到一个固定的内存区域并执行。这个分区中有一个非常小的,只有 512 字节的程序。程序从磁盘中调入 boot 独立程序,boot 程序将自身复制到高位地址的内存从而为操作系统释放低位地址的内存。
复制完成后,boot 程序读取启动设备的根目录。boot 程序要理解文件系统和目录格式。然后 boot 程序被调入内核,把控制权移交给内核。直到这里,boot 完成了它的工作。系统内核开始运行。
内核启动代码是使用汇编语言完成的,主要包括创建内核堆栈、识别 CPU 类型、计算内存、禁用中断、启动内存管理单元等,然后调用 C 语言的 main 函数执行操作系统部分。
这部分也会做很多事情,首先会分配一个消息缓冲区来存放调试出现的问题,调试信息会写入缓冲区。如果调试出现错误,这些信息可以通过诊断程序调出来。
然后操作系统会进行自动配置,检测设备,加载配置文件,被检测设备如果做出响应,就会被添加到已链接的设备表中,如果没有相应,就归为未连接直接忽略。
配置完所有硬件后,接下来要做的就是仔细手工处理进程0,设置其堆栈,然后运行它,执行初始化、配置时钟、挂载文件系统。创建 init 进程(进程 1 ) 和 守护进程(进程 2)。
init 进程会检测它的标志以确定它是否为单用户还是多用户服务。在前一种情况中,它会调用 fork 函数创建一个 shell 进程,并且等待这个进程结束。后一种情况调用 fork 函数创建一个运行系统初始化的 shell 脚本(即 /etc/rc)的进程,这个进程可以进行文件系统一致性检测、挂载文件系统、开启守护进程等。
然后 /etc/rc 这个进程会从 /etc/ttys 中读取数据,/etc/ttys 列出了所有的终端和属性。对于每一个启用的终端,这个进程调用 fork 函数创建一个自身的副本,进行内部处理并运行一个名为 getty 的程序。
getty 程序会在终端上输入
login:
等待用户输入用户名,在输入用户名后,getty 程序结束,登陆程序 /bin/login 开始运行。login 程序需要输入密码,并与保存在 /etc/passwd 中的密码进行对比,如果输入正确,login 程序以用户 shell 程序替换自身,等待第一个命令。如果不正确,login 程序要求输入另一个用户名。
整个系统启动过程如下

# Linux文件系统-Java面试题
在 Linux 中,最直观、最可见的部分就是 文件系统(file system)。下面我们就来一起探讨一下关于 Linux 中国的文件系统,系统调用以及文件系统实现背后的原理和思想。这些思想中有一些来源于 MULTICS,现在已经被 Windows 等其他操作系统使用。Linux 的设计理念就是 小的就是好的(Small is Beautiful) 。虽然 Linux 只是使用了最简单的机制和少量的系统调用,但是 Linux 却提供了强大而优雅的文件系统。
Linux 文件系统基本概念
Linux 在最初的设计是 MINIX1 文件系统,它只支持 14 字节的文件名,它的最大文件只支持到 64 MB。在 MINIX 1 之后的文件系统是 ext 文件系统。ext 系统相较于 MINIX 1 来说,在支持字节大小和文件大小上均有很大提升,但是 ext 的速度仍没有 MINIX 1 快,于是,ext 2 被开发出来,它能够支持长文件名和大文件,而且具有比 MINIX 1 更好的性能。这使他成为 Linux 的主要文件系统。只不过 Linux 会使用 VFS 曾支持多种文件系统。在 Linux 链接时,用户可以动态的将不同的文件系统挂载倒 VFS 上。
Linux 中的文件是一个任意长度的字节序列,Linux 中的文件可以包含任意信息,比如 ASCII 码、二进制文件和其他类型的文件是不加区分的。
为了方便起见,文件可以被组织在一个目录中,目录存储成文件的形式在很大程度上可以作为文件处理。目录可以有子目录,这样形成有层次的文件系统,Linux 系统下面的根目录是 / ,它通常包含了多个子目录。字符 / 还用于对目录名进行区分,例如 /usr/cxuan 表示的就是根目录下面的 usr 目录,其中有一个叫做 cxuan 的子目录。
下面我们介绍一下 Linux 系统根目录下面的目录名
/bin,它是重要的二进制应用程序,包含二进制文件,系统的所有用户使用的命令都在这里/boot,启动包含引导加载程序的相关文件/dev,包含设备文件,终端文件,USB 或者连接到系统的任何设备/etc,配置文件,启动脚本等,包含所有程序所需要的配置文件,也包含了启动/停止单个应用程序的启动和关闭 shell 脚本/home,本地主要路径,所有用户用 home 目录存储个人信息/lib,系统库文件,包含支持位于 /bin 和 /sbin 下的二进制库文件/lost+found,在根目录下提供一个遗失+查找系统,必须在 root 用户下才能查看当前目录下的内容/media,挂载可移动介质/mnt,挂载文件系统/opt,提供一个可选的应用程序安装目录/proc,特殊的动态目录,用于维护系统信息和状态,包括当前运行中进程信息/root,root 用户的主要目录文件夹/sbin,重要的二进制系统文件/tmp, 系统和用户创建的临时文件,系统重启时,这个目录下的文件都会被删除/usr,包含绝大多数用户都能访问的应用程序和文件/var,经常变化的文件,诸如日志文件或数据库等
在 Linux 中,有两种路径,一种是 绝对路径(absolute path) ,绝对路径告诉你从根目录下查找文件,绝对路径的缺点是太长而且不太方便。还有一种是 相对路径(relative path) ,相对路径所在的目录也叫做工作目录(working directory)。
如果 /usr/local/books 是工作目录,那么 shell 命令
cp books books-replica
就表示的是相对路径,而
cp /usr/local/books/books /usr/local/books/books-replica
则表示的是绝对路径。
在 Linux 中经常出现一个用户使用另一个用户的文件或者使用文件树结构中的文件。两个用户共享同一个文件,这个文件位于某个用户的目录结构中,另一个用户需要使用这个文件时,必须通过绝对路径才能引用到他。如果绝对路径很长,那么每次输入起来会变的非常麻烦,所以 Linux 提供了一种 链接(link) 机制。
举个例子,下面是一个使用链接之前的图

以上所示,比如有两个工作账户 jianshe 和 cxuan,jianshe 想要使用 cxuan 账户下的 A 目录,那么它可能会输入 /usr/cxuan/A ,这是一种未使用链接之后的图。
使用链接后的示意如下

现在,jianshe 可以创建一个链接来使用 cxuan 下面的目录了。‘
当一个目录被创建出来后,有两个目录项也同时被创建出来,它们就是 . 和 .. ,前者代表工作目录自身,后者代表该目录的父目录,也就是该目录所在的目录。这样一来,在 /usr/jianshe 中访问 cxuan 中的目录就是 ../cxuan/xxx
Linux 文件系统不区分磁盘的,这是什么意思呢?一般来说,一个磁盘中的文件系统相互之间保持独立,如果一个文件系统目录想要访问另一个磁盘中的文件系统,在 Windows 中你可以像下面这样。

两个文件系统分别在不同的磁盘中,彼此保持独立。
而在 Linux 中,是支持挂载的,它允许一个磁盘挂在到另外一个磁盘上,那么上面的关系会变成下面这样

挂在之后,两个文件系统就不再需要关心文件系统在哪个磁盘上了,两个文件系统彼此可见。
Linux 文件系统的另外一个特性是支持 加锁(locking)。在一些应用中会出现两个或者更多的进程同时使用同一个文件的情况,这样很可能会导致竞争条件(race condition)。一种解决方法是对其进行加不同粒度的锁,就是为了防止某一个进程只修改某一行记录从而导致整个文件都不能使用的情况。
POSIX 提供了一种灵活的、不同粒度级别的锁机制,允许一个进程使用一个不可分割的操作对一个字节或者整个文件进行加锁。加锁机制要求尝试加锁的进程指定其 要加锁的文件,开始位置以及要加锁的字节
Linux 系统提供了两种锁:共享锁和互斥锁。如果文件的一部分已经加上了共享锁,那么再加排他锁是不会成功的;如果文件系统的一部分已经被加了互斥锁,那么在互斥锁解除之前的任何加锁都不会成功。为了成功加锁、请求加锁的部分的所有字节都必须是可用的。
在加锁阶段,进程需要设计好加锁失败后的情况,也就是判断加锁失败后是否选择阻塞,如果选择阻塞式,那么当已经加锁的进程中的锁被删除时,这个进程会解除阻塞并替换锁。如果进程选择非阻塞式的,那么就不会替换这个锁,会立刻从系统调用中返回,标记状态码表示是否加锁成功,然后进程会选择下一个时间再次尝试。
加锁区域是可以重叠的。下面我们演示了三种不同条件的加锁区域。

如上图所示,A 的共享锁在第四字节到第八字节进行加锁

如上图所示,进程在 A 和 B 上同时加了共享锁,其中 6 – 8 字节是重叠锁

如上图所示,进程 A 和 B 和 C 同时加了共享锁,那么第六字节和第七字节是共享锁。
如果此时一个进程尝试在第 6 个字节处加锁,此时会设置失败并阻塞,由于该区域被 A B C 同时加锁,那么只有等到 A B C 都释放锁后,进程才能加锁成功。
Linux 文件系统调用
许多系统调用都会和文件与文件系统有关。我们首先先看一下对单个文件的系统调用,然后再来看一下对整个目录和文件的系统调用。
为了创建一个新的文件,会使用到 creat 方法,注意没有 e。
这里说一个小插曲,曾经有人问 UNIX 创始人 Ken Thompson,如果有机会重新写 UNIX ,你会怎么办,他回答自己要把 creat 改成 create ,哈哈哈哈。
这个系统调用的两个参数是文件名和保护模式
fd = creat("aaa",mode);
这段命令会创建一个名为 aaa 的文件,并根据 mode 设置文件的保护位。这些位决定了哪个用户可能访问文件、如何访问。
creat 系统调用不仅仅创建了一个名为 aaa 的文件,还会打开这个文件。为了允许后续的系统调用访问这个文件,这个 creat 系统调用会返回一个 非负整数, 这个就叫做 文件描述符(file descriptor),也就是上面的 fd。
如果在已经存在的文件上调用了 creat 系统调用,那么该文件中的内容会被清除,从 0 开始。通过设置合适的参数,open 系统调用也能够创建文件。
下面让我们看一看主要的系统调用,如下表所示
| 系统调用 | 描述 |
|---|---|
| fd = creat(name,mode) | 一种创建一个新文件的方式 |
| fd = open(file, …) | 打开文件读、写或者读写 |
| s = close(fd) | 关闭一个打开的文件 |
| n = read(fd, buffer, nbytes) | 从文件中向缓存中读入数据 |
| n = write(fd, buffer, nbytes) | 从缓存中向文件中写入数据 |
| position = lseek(fd, offset, whence) | 移动文件指针 |
| s = stat(name, &buf) | 获取文件信息 |
| s = fstat(fd, &buf) | 获取文件信息 |
| s = pipe(&fd[0]) | 创建一个管道 |
| s = fcntl(fd,…) | 文件加锁等其他操作 |
为了对一个文件进行读写的前提是先需要打开文件,必须使用 creat 或者 open 打开,参数是打开文件的方式,是只读、可读写还是只写。open 系统调用也会返回文件描述符。打开文件后,需要使用 close 系统调用进行关闭。close 和 open 返回的 fd 总是未被使用的最小数量。
什么是文件描述符?文件描述符就是一个数字,这个数字标示了计算机操作系统中打开的文件。它描述了数据资源,以及访问资源的方式。
当程序要求打开一个文件时,内核会进行如下操作
- 授予访问权限
- 在
全局文件表(global file table)中创建一个条目(entry) - 向软件提供条目的位置
文件描述符由唯一的非负整数组成,系统上每个打开的文件至少存在一个文件描述符。文件描述符最初在 Unix 中使用,并且被包括 Linux,macOS 和 BSD 在内的现代操作系统所使用。
当一个进程成功访问一个打开的文件时,内核会返回一个文件描述符,这个文件描述符指向全局文件表的 entry 项。这个文件表项包含文件的 inode 信息,字节位移,访问限制等。例如下图所示

默认情况下,前三个文件描述符为 STDIN(标准输入)、STDOUT(标准输出)、STDERR(标准错误)。
标准输入的文件描述符是 0 ,在终端中,默认为用户的键盘输入
标准输出的文件描述符是 1 ,在终端中,默认为用户的屏幕
与错误有关的默认数据流是 2,在终端中,默认为用户的屏幕。
在简单聊了一下文件描述符后,我们继续回到文件系统调用的探讨。
在文件系统调用中,开销最大的就是 read 和 write 了。read 和 write 都有三个参数
文件描述符:告诉需要对哪一个打开文件进行读取和写入缓冲区地址:告诉数据需要从哪里读取和写入哪里统计:告诉需要传输多少字节
这就是所有的参数了,这个设计非常简单轻巧。
虽然几乎所有程序都按顺序读取和写入文件,但是某些程序需要能够随机访问文件的任何部分。与每个文件相关联的是一个指针,该指针指示文件中的当前位置。顺序读取(或写入)时,它通常指向要读取(写入)的下一个字节。如果指针在读取 1024 个字节之前位于 4096 的位置,则它将在成功读取系统调用后自动移至 5120 的位置。
Lseek 系统调用会更改指针位置的值,以便后续对 read 或 write 的调用可以在文件中的任何位置开始,甚至可以超出文件末尾。
lseek = Lseek ,段首大写。
lseek 避免叫做 seek 的原因就是 seek 已经在之前 16 位的计算机上用于搜素功能了。
Lseek 有三个参数:第一个是文件的文件描述符,第二个是文件的位置;第三个告诉文件位置是相对于文件的开头,当前位置还是文件的结尾
lseek(int fildes, off_t offset, int whence);
lseek 的返回值是更改文件指针后文件中的绝对位置。lseek 是唯一从来不会造成真正磁盘查找的系统调用,它只是更新当前的文件位置,这个文件位置就是内存中的数字。
对于每个文件,Linux 都会跟踪文件模式(常规,目录,特殊文件),大小,最后修改时间以及其他信息。程序能够通过 stat 系统调用看到这些信息。第一个参数就是文件名,第二个是指向要放置请求信息结构的指针。这些结构的属性如下图所示。
| 存储文件的设备 |
|---|
| 存储文件的设备 |
| i-node 编号 |
| 文件模式(包括保护位信息) |
| 文件链接的数量 |
| 文件所有者标识 |
| 文件所属的组 |
| 文件大小(字节) |
| 创建时间 |
| 最后一个修改/访问时间 |
fstat 调用和 stat 相同,只有一点区别,fstat 可以对打开文件进行操作,而 stat 只能对路径进行操作。
pipe 文件系统调用被用来创建 shell 管道。它会创建一系列的伪文件,来缓冲和管道组件之间的数据,并且返回读取或者写入缓冲区的文件描述符。在管道中,像是如下操作
sort <in | head –40
sort 进程将会输出到文件描述符1,也就是标准输出,写入管道中,而 head 进程将从管道中读入。在这种方式中,sort 只是从文件描述符 0 中读取并写入到文件描述符 1 (管道)中,甚至不知道它们已经被重定向了。如果没有重定向的话,sort 会自动的从键盘读入并输出到屏幕中。
最后一个系统调用是 fcntl,它用来锁定和解锁文件,应用共享锁和互斥锁,或者是执行一些文件相关的其他操作。
现在我们来关心一下和整体目录和文件系统相关的系统调用,而不是把精力放在单个的文件上,下面列出了这些系统调用,我们一起来看一下。
| 系统调用 | 描述 |
|---|---|
| s = mkdir(path,mode) | 创建一个新的目录 |
| s = rmdir(path) | 移除一个目录 |
| s = link(oldpath,newpath) | 创建指向已有文件的链接 |
| s = unlink(path) | 取消文件的链接 |
| s = chdir(path) | 改变工作目录 |
| dir = opendir(path) | 打开一个目录读取 |
| s = closedir(dir) | 关闭一个目录 |
| dirent = readdir(dir) | 读取一个目录项 |
| rewinddir(dir) | 回转目录使其在此使用 |
可以使用 mkdir 和 rmdir 创建和删除目录。但是需要注意,只有目录为空时才可以删除。
创建一个指向已有文件的链接时会创建一个目录项(directory entry)。系统调用 link 来创建链接,oldpath 代表已有的路径,newpath 代表需要链接的路径,使用 unlink 可以删除目录项。当文件的最后一个链接被删除时,这个文件会被自动删除。
使用 chdir 系统调用可以改变工作目录。
最后四个系统调用是用于读取目录的。和普通文件类似,他们可以被打开、关闭和读取。每次调用 readdir 都会以固定的格式返回一个目录项。用户不能对目录执行写操作,但是可以使用 creat 或者 link 在文件夹中创建一个目录,或使用 unlink 删除一个目录。用户不能在目录中查找某个特定文件,但是可以使用 rewindir 作用于一个打开的目录,使他能在此从头开始读取。
Linux 文件系统的实现
下面我们主要讨论一下 虚拟文件系统(Virtual File System)。 VFS 对高层进程和应用程序隐藏了 Linux 支持的所有文件系统的区别,以及文件系统是存储在本地设备,还是需要通过网络访问远程设备。设备和其他特殊文件和 VFS 层相关联。接下来,我们就会探讨一下第一个 Linux 广泛传播的文件系统: ext2。随后,我们就会探讨 ext4 文件系统所做的改进。各种各样的其他文件系统也正在使用中。 所有 Linux 系统都可以处理多个磁盘分区,每个磁盘分区上都有不同的文件系统。
Linux 虚拟文件系统
为了能够使应用程序能够在不同类型的本地或者远程设备上的文件系统进行交互,因为在 Linux 当中文件系统千奇百种,比较常见的有 EXT3、EXT4,还有基于内存的 ramfs、tmpfs 和基于网络的 nfs,和基于用户态的 fuse,当然 fuse 应该不能完全的文件系统,只能算是一个能把文件系统实现放到用户态的模块,满足了内核文件系统的接口,他们都是文件系统的一种实现。对于这些文件系统,Linux 做了一层抽象就是 VFS 虚拟文件系统,
下表总结了 VFS 支持的四个主要的文件系统结构。
| 对象 | 描述 |
|---|---|
| 超级块 | 特定的文件系统 |
| Dentry | 目录项,路径的一个组成部分 |
| I-node | 特定的文件 |
| File | 跟一个进程相关联的打开文件 |
超级块(superblock) 包含了有关文件系统布局的重要信息,超级块如果遭到破坏那么就会导致整个文件系统不可读。
i-node 索引节点,包含了每一个文件的描述符。
在 Linux 中,目录和设备也表示为文件,因为它们具有对应的 i-node
超级块和索引块所在的文件系统都在磁盘上有对应的结构。
为了便于某些目录操作和路径遍历,比如 /usr/local/cxuan,VFS 支持一个 dentry 数据结构,该数据结构代表着目录项。这个 dentry 数据结构有很多东西(http://books.gigatux.nl/mirror/kerneldevelopment/0672327201/ch12lev1sec7.html)这个数据结构由文件系统动态创建。
目录项被缓存在 dentry_cache 缓存中。例如,缓存条目会缓存 /usr 、 /usr/local 等条目。如果多个进程通过硬连接访问相同的文件,他们的文件对象将指向此缓存中的相同条目。
最后,文件数据结构是代表着打开的文件,也代表着内存表示,它根据 open 系统调用创建。它支持 read、write、sendfile、lock 和其他在我们之前描述的系统调用中。
在 VFS 下实现的实际文件系统不需要在内部使用完全相同的抽象和操作。 但是,它们必须在语义上实现与 VFS 对象指定的文件系统操作相同的文件系统操作。 四个 VFS 对象中每个对象的操作数据结构的元素都是指向基础文件系统中功能的指针。
Linux Ext2 文件系统
现在我们一起看一下 Linux 中最流行的一个磁盘文件系统,那就是 ext2 。Linux 的第一个版本用于 MINIX1 文件系统,它的文件名大小被限制为最大 64 MB。MINIX 1 文件系统被永远的被它的扩展系统 ext 取代,因为 ext 允许更长的文件名和文件大小。由于 ext 的性能低下,ext 被其替代者 ext2 取代,ext2 目前仍在广泛使用。
一个 ext2 Linux 磁盘分区包含了一个文件系统,这个文件系统的布局如下所示

Boot 块也就是第 0 块不是让 Linux 使用的,而是用来加载和引导计算机启动代码的。在块 0 之后,磁盘分区被分成多个组,这些组与磁盘柱面边界所处的位置无关。
第一个块是 超级块(superblock)。它包含有关文件系统布局的信息,包括 i-node、磁盘块数量和以及空闲磁盘块列表的开始。下一个是 组描述符(group descriptor),其中包含有关位图的位置,组中空闲块和 i-node 的数量以及组中的目录数量的信息。这些信息很重要,因为 ext2 会在磁盘上均匀分布目录。
图中的两个位图用来记录空闲块和空闲 i-node,这是从 MINIX 1文件系统继承的选择,大多数 UNIX 文件系统使用位图而不是空闲列表。每个位图的大小是一个块。如果一个块的大小是 1 KB,那么就限制了块组的数量是 8192 个块和 8192 个 i-node。块的大小是一个严格的限制,块组的数量不固定,在 4KB 的块中,块组的数量增大四倍。
在超级块之后分布的是 i-node 它们自己,i-node 取值范围是 1 – 某些最大值。每个 i-node 是 128 字节的 long ,这些字节恰好能够描述一个文件。i-node 包含了统计信息(包含了 stat 系统调用能获得的所有者信息,实际上 stat 就是从 i-node 中读取信息的),以及足够的信息来查找保存文件数据的所有磁盘块。
在 i-node 之后的是 数据块(data blocks)。所有的文件和目录都保存在这。如果一个文件或者目录包含多个块,那么这些块在磁盘中的分布不一定是连续的,也有可能不连续。事实上,大文件块可能会被拆分成很多小块散布在整个磁盘上。
对应于目录的 i-node 分散在整个磁盘组上。如果有足够的空间,ext2 会把普通文件组织到与父目录相同的块组中,而把同一块上的数据文件组织成初始 i-node 节点。位图用来快速确定新文件系统数据的分配位置。在分配新的文件块时,ext2 也会给该文件预分配许多额外的数据块,这样可以减少将来向文件写入数据时产生的文件碎片。这种策略在整个磁盘上实现了文件系统的 负载,后续还有对文件碎片的排列和整理,而且性能也比较好。
为了达到访问的目的,需要首先使用 Linux 系统调用,例如 open,这个系统调用会确定打开文件的路径。路径分为两种,相对路径 和 绝对路径。如果使用相对路径,那么就会从当前目录开始查找,否则就会从根目录进行查找。
目录文件的文件名最高不能超过 255 个字符,它的分配如下图所示

每一个目录都由整数个磁盘块组成,这样目录就可以整体的写入磁盘。在一个目录中,文件和子目录的目录项都是未经排序的,并且一个挨着一个。目录项不能跨越磁盘块,所以通常在每个磁盘块的尾部会有部分未使用的字节。
上图中每个目录项都由四个固定长度的属性和一个长度可变的属性组成。第一个属性是 i-node 节点数量,文件 first 的 i-node 编号是 19 ,文件 second 的编号是 42,目录 third 的 i-node 编号是 88。紧随其后的是 rec_len 域,表明目录项大小是多少字节,名称后面会有一些扩展,当名字以未知长度填充时,这个域被用来寻找下一个目录项,直至最后的未使用。这也是图中箭头的含义。紧随其后的是 类型域:F 表示的是文件,D 表示的是目录,最后是固定长度的文件名,上面的文件名的长度依次是 5、6、5,最后以文件名结束。
rec_len 域是如何扩展的呢?如下图所示

我们可以看到,中间的 second 被移除了,所以将其所在的域变为第一个目录项的填充。当然,这个填充可以作为后续的目录项。
由于目录是按照线性的顺序进行查找的,因此可能需要很长时间才能在大文件末尾找到目录项。因此,系统会为近期的访问目录维护一个缓存。这个缓存用文件名来查找,如果缓存命中,那么就会避免线程搜索这样昂贵的开销。组成路径的每个部分都在目录缓存中保存一个 dentry 对象,并且通过 i-node 找到后续的路径元素的目录项,直到找到真正的文件 i – node。
比如说要使用绝对路径来寻找一个文件,我们暂定这个路径是 /usr/local/file,那么需要经过如下几个步骤:
- 首先,系统会确定根目录,它通常使用 2 号 i -node ,也就是索引 2 节点,因为索引节点 1 是 ext2 /3/4 文件系统上的
坏块索引节点。系统会将一项放在 dentry 缓存中,以应对将来对根目录的查找。 - 然后,在根目录中查找字符串
usr,得到 /usr 目录的 i – node 节点号。/usr 的 i – node 同样也进入 dentry 缓存。然后节点被取出,并从中解析出磁盘块,这样就可以读取 /usr 目录并查找字符串local了。一旦找到这个目录项,目录/usr/local的 i – node 节点就可以从中获得。有了 /usr/local 的 i – node 节点号,就可以读取 i – node 并确定目录所在的磁盘块。最后,从 /usr/local 目录查找 file 并确定其 i – node 节点呢号。
如果文件存在,那么系统会提取 i – node 节点号并把它作为索引在 i – node 节点表中定位相应的 i – node 节点并装入内存。i – node 被存放在 i – node 节点表(i-node table) 中,节点表是一个内核数据结构,它会持有当前打开文件和目录的 i – node 节点号。下面是一些 Linux 文件系统支持的 i – node 数据结构。
| 属性 | 字节 | 描述 |
|---|---|---|
| Mode | 2 | 文件属性、保护位、setuid 和 setgid 位 |
| Nlinks | 2 | 指向 i – node 节点目录项的数目 |
| Uid | 2 | 文件所有者的 UID |
| Gid | 2 | 文件所有者的 GID |
| Size | 4 | 文件字节大小 |
| Addr | 60 | 12 个磁盘块以及后面 3 个间接块的地址 |
| Gen | 1 | 每次重复使用 i – node 时增加的代号 |
| Atime | 4 | 最近访问文件的时间 |
| Mtime | 4 | 最近修改文件的时间 |
| Ctime | 4 | 最近更改 i – node 的时间 |
现在我们来一起探讨一下文件读取过程,还记得 read 函数是如何调用的吗?
n = read(fd,buffer,nbytes);
当内核接管后,它会从这三个参数以及内部表与用户有关的信息开始。内部表的其中一项是文件描述符数组。文件描述符数组用文件描述符 作为索引并为每一个打开文件保存一个表项。
文件是和 i – node 节点号相关的。那么如何通过一个文件描述符找到文件对应的 i – node 节点呢?
这里使用的一种设计思想是在文件描述符表和 i – node 节点表之间插入一个新的表,叫做 打开文件描述符(open-file-description table)。文件的读写位置会在打开文件描述符表中存在,如下图所示

我们使用 shell 、P1 和 P2 来描述一下父进程、子进程、子进程的关系。Shell 首先生成 P1,P1 的数据结构就是 Shell 的一个副本,因此两者都指向相同的打开文件描述符的表项。当 P1 运行完成后,Shell 的文件描述符仍会指向 P1 文件位置的打开文件描述。然后 Shell 生成了 P2,新的子进程自动继承文件的读写位置,甚至 P2 和 Shell 都不知道文件具体的读写位置。
上面描述的是父进程和子进程这两个 相关 进程,如果是一个不相关进程打开文件时,它将得到自己的打开文件描述符表项,以及自己的文件读写位置,这是我们需要的。
因此,打开文件描述符相当于是给相关进程提供同一个读写位置,而给不相关进程提供各自私有的位置。
i – node 包含三个间接块的磁盘地址,它们每个指向磁盘块的地址所能够存储的大小不一样。
Linux Ext4 文件系统
为了防止由于系统崩溃和电源故障造成的数据丢失,ext2 系统必须在每个数据块创建之后立即将其写入到磁盘上,磁盘磁头寻道操作导致的延迟是无法让人忍受的。为了增强文件系统的健壮性,Linux 依靠日志文件系统,ext3 是一个日志文件系统,它在 ext2 文件系统的基础之上做了改进,ext4 也是 ext3 的改进,ext4 也是一个日志文件系统。ext4 改变了 ext3 的块寻址方案,从而支持更大的文件和更大的文件系统大小。下面我们就来描述一下 ext4 文件系统的特性。
具有记录的文件系统最基本的功能就是记录日志,这个日志记录了按照顺序描述所有文件系统的操作。通过顺序写出文件系统数据或元数据的更改,操作不受磁盘访问期间磁盘头移动的开销。最终,这个变更会写入并提交到合适的磁盘位置上。如果这个变更在提交到磁盘前文件系统宕机了,那么在重启期间,系统会检测到文件系统未正确卸载,那么就会遍历日志并应用日志的记录来对文件系统进行更改。
Ext4 文件系统被设计用来高度匹配 ext2 和 ext3 文件系统的,尽管 ext4 文件系统在内核数据结构和磁盘布局上都做了变更。尽管如此,一个文件系统能够从 ext2 文件系统上卸载后成功的挂载到 ext4 文件系统上,并提供合适的日志记录。
日志是作为循环缓冲区管理的文件。日志可以存储在与主文件系统相同或者不同的设备上。日志记录的读写操作会由单独的 JBD(Journaling Block Device) 来扮演。
JBD 中有三个主要的数据结构,分别是 log record(日志记录)、原子操作和事务。一个日志记录描述了一个低级别的文件系统操作,这个操作通常导致块内的变化。因为像是 write 这种系统调用会包含多个地方的改动 — i – node 节点,现有的文件块,新的文件块和空闲列表等。相关的日志记录会以原子性的方式分组。ext4 会通知系统调用进程的开始和结束,以此使 JBD 能够确保原子操作的记录都能被应用,或者一个也不被应用。最后,主要从效率方面考虑,JBD 会视原子操作的集合为事务。一个事务中的日志记录是连续存储的。只有在所有的变更一起应用到磁盘后,日志记录才能够被丢弃。
由于为每个磁盘写出日志的开销会很大,所以 ext4 可以配置为保留所有磁盘更改的日志,或者仅仅保留与文件系统元数据相关的日志更改。仅仅记录元数据可以减少系统开销,提升性能,但不能保证不会损坏文件数据。其他的几个日志系统维护着一系列元数据操作的日志,例如 SGI 的 XFS。
/proc 文件系统
另外一个 Linux 文件系统是 /proc (process) 文件系统
它的主要思想来源于贝尔实验室开发的第 8 版的 UNIX,后来被 BSD 和 System V 采用。
然而,Linux 在一些方面上对这个想法进行了扩充。它的基本概念是为系统中的每个进程在 /proc 中创建一个目录。目录的名字就是进程 PID,以十进制数进行表示。例如,/proc/1024 就是一个进程号为 1024 的目录。在该目录下是进程信息相关的文件,比如进程的命令行、环境变量和信号掩码等。事实上,这些文件在磁盘上并不存在磁盘中。当需要这些信息的时候,系统会按需从进程中读取,并以标准格式返回给用户。
许多 Linux 扩展与 /proc 中的其他文件和目录有关。它们包含各种各样的关于 CPU、磁盘分区、设备、中断向量、内核计数器、文件系统、已加载模块等信息。非特权用户可以读取很多这样的信息,于是就可以通过一种安全的方式了解系统情况。
NFS 网络文件系统
从一开始,网络就在 Linux 中扮演了很重要的作用。下面我们会探讨一下 NFS(Network File System) 网络文件系统,它在现代 Linux 操作系统的作用是将不同计算机上的不同文件系统链接成一个逻辑整体。
NFS 架构
NFS 最基本的思想是允许任意选定的一些客户端和服务器共享一个公共文件系统。在许多情况下,所有的客户端和服务器都会在同一个 LAN(Local Area Network) 局域网内共享,但是这并不是必须的。也可能是下面这样的情况:如果客户端和服务器距离较远,那么它们也可以在广域网上运行。客户端可以是服务器,服务器可以是客户端,但是为了简单起见,我们说的客户端就是消费服务,而服务器就是提供服务的角度来聊。
每一个 NFS 服务都会导出一个或者多个目录供远程客户端访问。当一个目录可用时,它的所有子目录也可用。因此,通常整个目录树都会作为一个整体导出。服务器导出的目录列表会用一个文件来维护,这个文件是 /etc/exports,当服务器启动后,这些目录可以自动的被导出。客户端通过挂载这些导出的目录来访问它们。当一个客户端挂载了一个远程目录,这个目录就成为客户端目录层次的一部分,如下图所示。

在这个示例中,一号客户机挂载到服务器的 bin 目录下,因此它现在可以使用 shell 访问 /bin/cat 或者其他任何一个目录。同样,客户机 1 也可以挂载到 二号服务器上从而访问 /usr/local/projects/proj1 或者其他目录。二号客户机同样可以挂载到二号服务器上,访问路径是 /mnt/projects/proj2。
从上面可以看到,由于不同的客户端将文件挂载到各自目录树的不同位置,同一个文件在不同的客户端有不同的访问路径和不同的名字。挂载点一般通常在客户端本地,服务器不知道任何一个挂载点的存在。
NFS 协议
由于 NFS 的协议之一是支持 异构 系统,客户端和服务器可能在不同的硬件上运行不同的操作系统,因此有必要在服务器和客户端之间进行接口定义。这样才能让任何写一个新客户端能够和现有的服务器一起正常工作,反之亦然。
NFS 就通过定义两个客户端 – 服务器协议从而实现了这个目标。协议就是客户端发送给服务器的一连串的请求,以及服务器发送回客户端的相应答复。
第一个 NFS 协议是处理挂载。客户端可以向服务器发送路径名并且请求服务器是否能够将服务器的目录挂载到自己目录层次上。因为服务器不关心挂载到哪里,因此请求不会包含挂载地址。如果路径名是合法的并且指定的目录已经被导出,那么服务器会将文件 句柄 返回给客户端。
文件句柄包含唯一标识文件系统类型,磁盘,目录的i节点号和安全性信息的字段。
随后调用读取和写入已安装目录或其任何子目录中的文件,都将使用文件句柄。
当 Linux 启动时会在多用户之前运行 shell 脚本 /etc/rc 。可以将挂载远程文件系统的命令写入该脚本中,这样就可以在允许用户登陆之前自动挂载必要的远程文件系统。大部分 Linux 版本是支持自动挂载的。这个特性会支持将远程目录和本地目录进行关联。
相对于手动挂载到 /etc/rc 目录下,自动挂载具有以下优势
- 如果列出的 /etc/rc 目录下出现了某种故障,那么客户端将无法启动,或者启动会很困难、延迟或者伴随一些出错信息,如果客户根本不需要这个服务器,那么手动做了这些工作就白费了。
- 允许客户端并行的尝试一组服务器,可以实现一定程度的容错率,并且性能也可以得到提高。
另一方面,我们默认在自动挂载时所有可选的文件系统都是相同的。由于 NFS 不提供对文件或目录复制的支持,用户需要自己确保这些所有的文件系统都是相同的。因此,大部分的自动挂载都只应用于二进制文件和很少改动的只读的文件系统。
第二个 NFS 协议是为文件和目录的访问而设计的。客户端能够通过向服务器发送消息来操作目录和读写文件。客户端也可以访问文件属性,比如文件模式、大小、上次修改时间。NFS 支持大多数的 Linux 系统调用,但是 open 和 close 系统调用却不支持。
不支持 open 和 close 并不是一种疏忽,而是一种刻意的设计,完全没有必要在读一个文件之前对其进行打开,也没有必要在读完时对其进行关闭。
NFS 使用了标准的 UNIX 保护机制,使用 rwx 位来标示所有者(owner)、组(groups)、其他用户 。最初,每个请求消息都会携带调用者的 groupId 和 userId,NFS 会对其进行验证。事实上,它会信任客户端不会发生欺骗行为。可以使用公钥密码来创建一个安全密钥,在每次请求和应答中使用它验证客户端和服务器。
NFS 实现
即使客户端和服务器的代码实现是独立于 NFS 协议的,大部分的 Linux 系统会使用一个下图的三层实现,顶层是系统调用层,系统调用层能够处理 open 、 read 、 close 这类的系统调用。在解析和参数检查结束后调用第二层,虚拟文件系统 (VFS) 层。

VFS 层的任务是维护一个表,每个已经打开的文件都在表中有一个表项。VFS 层为每一个打开的文件维护着一个虚拟i节点 ,简称为 v – node。v 节点用来说明文件是本地文件还是远程文件。如果是远程文件的话,那么 v – node 会提供足够的信息使客户端能够访问它们。对于本地文件,会记录其所在的文件系统和文件的 i-node ,因为现代操作系统能够支持多文件系统。虽然 VFS 是为了支持 NFS 而设计的,但是现代操作系统都会使用 VFS,而不管有没有 NFS。
# LinuxIO管理-Java面试题
我们之前了解过了 Linux 的进程和线程、Linux 内存管理,那么下面我们就来认识一下 Linux 中的 I/O 管理。
Linux 系统和其他 UNIX 系统一样,IO 管理比较直接和简洁。所有 IO 设备都被当作文件,通过在系统内部使用相同的 read 和 write 一样进行读写。
Linux IO 基本概念
Linux 中也有磁盘、打印机、网络等 I/O 设备,Linux 把这些设备当作一种 特殊文件 整合到文件系统中,一般通常位于 /dev 目录下。可以使用与普通文件相同的方式来对待这些特殊文件。
特殊文件一般分为两种:
块特殊文件是一个能存储固定大小块信息的设备,它支持以固定大小的块,扇区或群集读取和(可选)写入数据。每个块都有自己的物理地址。通常块的大小在 512 – 65536 之间。所有传输的信息都会以连续的块为单位。块设备的基本特征是每个块都较为对立,能够独立的进行读写。常见的块设备有 硬盘、蓝光光盘、USB 盘与字符设备相比,块设备通常需要较少的引脚。

块特殊文件的缺点基于给定固态存储器的块设备比基于相同类型的存储器的字节寻址要慢一些,因为必须在块的开头开始读取或写入。所以,要读取该块的任何部分,必须寻找到该块的开始,读取整个块,如果不使用该块,则将其丢弃。要写入块的一部分,必须寻找到块的开始,将整个块读入内存,修改数据,再次寻找到块的开头处,然后将整个块写回设备。
另一类 I/O 设备是字符特殊文件。字符设备以字符为单位发送或接收一个字符流,而不考虑任何块结构。字符设备是不可寻址的,也没有任何寻道操作。常见的字符设备有 打印机、网络设备、鼠标、以及大多数与磁盘不同的设备。

每个设备特殊文件都会和 设备驱动 相关联。每个驱动程序都通过一个 主设备号 来标识。如果一个驱动支持多个设备的话,此时会在主设备的后面新加一个 次设备号 来标识。主设备号和次设备号共同确定了唯一的驱动设备。
我们知道,在计算机系统中,CPU 并不直接和设备打交道,它们中间有一个叫作 设备控制器(Device Control Unit)的组件,例如硬盘有磁盘控制器、USB 有 USB 控制器、显示器有视频控制器等。这些控制器就像代理商一样,它们知道如何应对硬盘、鼠标、键盘、显示器的行为。
绝大多数字符特殊文件都不能随机访问,因为他们需要使用和块特殊文件不同的方式来控制。比如,你在键盘上输入了一些字符,但是你发现输错了一个,这时有一些人喜欢使用 backspace 来删除,有人喜欢用 del 来删除。为了中断正在运行的设备,一些系统使用 ctrl-u 来结束,但是现在一般使用 ctrl-c 来结束。
网络
I/O 的另外一个概念是网络, 也是由 UNIX 引入,网络中一个很关键的概念就是 套接字(socket)。套接字允许用户连接到网络,正如邮筒允许用户连接到邮政系统,套接字的示意图如下

套接字的位置如上图所示,套接字可以动态创建和销毁。成功创建一个套接字后,系统会返回一个文件描述符(file descriptor),在后面的创建链接、读数据、写数据、解除连接时都需要使用到这个文件描述符。每个套接字都支持一种特定类型的网络类型,在创建时指定。一般最常用的几种
- 可靠的面向连接的字节流
- 可靠的面向连接的数据包
- 不可靠的数据包传输
可靠的面向连接的字节流会使用管道 在两台机器之间建立连接。能够保证字节从一台机器按照顺序到达另一台机器,系统能够保证所有字节都能到达。
除了数据包之间的分界之外,第二种类型和第一种类型是类似的。如果发送了 3 次写操作,那么使用第一种方式的接受者会直接接收到所有字节;第二种方式的接受者会分 3 次接受所有字节。除此之外,用户还可以使用第三种即不可靠的数据包来传输,使用这种传输方式的优点在于高性能,有的时候它比可靠性更加重要,比如在流媒体中,性能就尤其重要。
以上涉及两种形式的传输协议,即 TCP 和 UDP,TCP 是 传输控制协议,它能够传输可靠的字节流。UDP 是 用户数据报协议,它只能够传输不可靠的字节流。它们都属于 TCP/IP 协议簇中的协议,下面是网络协议分层

可以看到,TCP 、UDP 都位于网络层上,可见它们都把 IP 协议 即 互联网协议 作为基础。
一旦套接字在源计算机和目的计算机建立成功,那么两个计算机之间就可以建立一个链接。通信一方在本地套接字上使用 listen 系统调用,它就会创建一个缓冲区,然后阻塞直到数据到来。另一方使用 connect 系统调用,如果另一方接受 connect 系统调用后,则系统会在两个套接字之间建立连接。
socket 连接建立成功后就像是一个管道,一个进程可以使用本地套接字的文件描述符从中读写数据,当连接不再需要的时候使用 close 系统调用来关闭。
Linux I/O 系统调用
Linux 系统中的每个 I/O 设备都有一个特殊文件(special file)与之关联,什么是特殊文件呢?
在操作系统中,特殊文件是一种在文件系统中与硬件设备相关联的文件。特殊文件也被称为
设备文件(device file)。特殊文件的目的是将设备作为文件系统中的文件进行公开。特殊文件为硬件设备提供了借口,用于文件 I/O 的工具可以进行访问。因为设备有两种类型,同样特殊文件也有两种,即字符特殊文件和块特殊文件
对于大部分 I/O 操作来说,只用合适的文件就可以完成,并不需要特殊的系统调用。然后,有时需要一些设备专用的处理。在 POSIX 之前,大多数 UNIX 系统会有一个叫做 ioctl 的系统调用,它用于执行大量的系统调用。随着时间的发展,POSIX 对其进行了整理,把 ioctl 的功能划分为面向终端设备的独立功能调用,现在已经变成独立的系统调用了。
下面是几个管理终端的系统调用
| 系统调用 | 描述 |
|---|---|
| tcgetattr | 获取属性 |
| tcsetattr | 设置属性 |
| cfgetispeed | 获取输入速率 |
| cfgetospeed | 获取输出速率 |
| cfsetispeed | 设置输入速率 |
| cfsetospeed | 设置输出速率 |
Linux IO 实现
Linux 中的 IO 是通过一系列设备驱动实现的,每个设备类型对应一个设备驱动。设备驱动为操作系统和硬件分别预留接口,通过设备驱动来屏蔽操作系统和硬件的差异。
当用户访问一个特殊的文件时,由文件系统提供此特殊文件的主设备号和次设备号,并判断它是一个块特殊文件还是字符特殊文件。主设备号用于标识字符设备还是块设备,次设备号用于参数传递。
每个驱动程序 都有两部分:这两部分都是属于 Linux 内核,也都运行在内核态下。上半部分运行在调用者上下文并且与 Linux 其他部分交互。下半部分运行在内核上下文并且与设备进行交互。驱动程序可以调用内存分配、定时器管理、DMA 控制等内核过程。可被调用的内核功能都位于 驱动程序 - 内核接口 的文档中。
I/O 实现指的就是对字符设备和块设备的实现
块设备实现
系统中处理块特殊文件 I/O 部分的目标是为了使传输次数尽可能的小。为了实现这个目标,Linux 系统在磁盘驱动程序和文件系统之间设置了一个 高速缓存(cache) ,如下图所示

在 Linux 内核 2.2 之前,Linux 系统维护着两个缓存:页面缓存(page cache) 和 缓冲区缓存(buffer cache),因此,存储在一个磁盘块中的文件可能会在两个缓存中。2.2 版本以后 Linux 内核只有一个统一的缓存一个 通用数据块层(generic block layer) 把这些融合在一起,实现了磁盘、数据块、缓冲区和数据页之间必要的转换。那么什么是通用数据块层?
通用数据块层是一个内核的组成部分,用于处理对系统中所有块设备的请求。通用数据块主要有以下几个功能
将数据缓冲区放在内存高位处,当 CPU 访问数据时,页面才会映射到内核线性地址中,并且此后取消映射
实现
零拷贝机制,磁盘数据可以直接放入用户模式的地址空间,而无需先复制到内核内存中管理磁盘卷,会把不同块设备上的多个磁盘分区视为一个分区。
利用最新的磁盘控制器的高级功能,例如 DMA 等。
cache 是提升性能的利器,不管以什么样的目的需要一个数据块,都会先从 cache 中查找,如果找到直接返回,避免一次磁盘访问,能够极大的提升系统性能。
如果页面 cache 中没有这个块,操作系统就会把页面从磁盘中调入内存,然后读入 cache 进行缓存。
cache 除了支持读操作外,也支持写操作,一个程序要写回一个块,首先把它写到 cache 中,而不是直接写入到磁盘中,等到磁盘中缓存达到一定数量值时再被写入到 cache 中。
Linux 系统中使用 IO 调度器 来保证减少磁头的反复移动从而减少损失。I/O 调度器的作用是对块设备的读写操作进行排序,对读写请求进行合并。Linux 有许多调度器的变体,从而满足不同的工作需要。最基本的 Linux 调度器是基于传统的 Linux 电梯调度器(Linux elevator scheduler)。Linux 电梯调度器的主要工作流程就是按照磁盘扇区的地址排序并存储在一个双向链表 中。新的请求将会以链表的形式插入。这种方法可以有效的防止磁头重复移动。因为电梯调度器会容易产生饥饿现象。因此,Linux 在原基础上进行了修改,维护了两个链表,在 最后日期(deadline) 内维护了排序后的读写操作。默认的读操作耗时 0.5s,默认写操作耗时 5s。如果在最后期限内等待时间最长的链表没有获得服务,那么它将优先获得服务。
字符设备实现
和字符设备的交互是比较简单的。由于字符设备会产生并使用字符流、字节数据,因此对随机访问的支持意义不大。一个例外是使用 行规则(line disciplines)。一个行规可以和终端设备相关联,使用 tty_struct 结构来表示,它表示与终端设备交换数据的解释器,当然这也属于内核的一部分。例如:行规可以对行进行编辑,映射回车为换行等一系列其他操作。
什么是行规则?
行规是某些类 UNIX 系统中的一层,终端子系统通常由三层组成:上层提供字符设备接口,下层硬件驱动程序与硬件或伪终端进行交互,中层规则用于实现终端设备共有的行为。

网络设备实现
网络设备的交互是不一样的,虽然 网络设备(network devices) 也会产生字符流,因为它们的异步(asynchronous) 特性是他们不易与其他字符设备在同一接口下集成。网络设备驱动程序会产生很多数据包,经由网络协议到达用户应用程序中。
Linux 中的模块
UNIX 设备驱动程序是被静态加载到内核中的。因此,只要系统启动后,设备驱动程序都会被加载到内存中。随着个人电脑 Linux 的出现,这种静态链接完成后会使用一段时间的模式被打破。相对于小型机上的 I/O 设备,PC 上可用的 I/O 设备有了数量级的增长。绝大多数用户没有能力去添加一个新的应用程序、更新设备驱动、重新连接内核,然后进行安装。
Linux 为了解决这个问题,引入了 可加载(loadable module) 机制。可加载是在系统运行时添加到内核中的代码块。
当一个模块被加载到内核时,会发生下面几件事情:第一,在加载的过程中,模块会被动态的重新部署。第二,系统会检查程序程序所需的资源是否可用。如果可用,则把这些资源标记为正在使用。第三步,设置所需的中断向量。第四,更新驱动转换表使其能够处理新的主设备类型。最后再来运行设备驱动程序。
在完成上述工作后,驱动程序就会安装完成,其他现代 UNIX 系统也支持可加载机制。
# 深入Kafka-Java面试题
如果只是为了开发 Kafka 应用程序,或者只是在生产环境使用 Kafka,那么了解 Kafka 的内部工作原理不是必须的。不过,了解 Kafka 的内部工作原理有助于理解 Kafka 的行为,也利用快速诊断问题。下面我们来探讨一下这三个问题
- Kafka 是如何进行复制的
- Kafka 是如何处理来自生产者和消费者的请求的
- Kafka 的存储细节是怎样的
如果感兴趣的话,就请花费你一些时间,耐心看完这篇文章。
集群成员间的关系
我们知道,Kafka 是运行在 ZooKeeper 之上的,因为 ZooKeeper 是以集群形式出现的,所以 Kafka 也可以以集群形式出现。这也就涉及到多个生产者和多个消费者如何协调的问题,这个维护集群间的关系也是由 ZooKeeper 来完成的。如果你看过我之前的文章(真的,关于 Kafka 入门看这一篇就够了),你应该会知道,Kafka 集群间会有多个 主机(broker),每个 broker 都会有一个 broker.id,每个 broker.id 都有一个唯一的标识符用来区分,这个标识符可以在配置文件里手动指定,也可以自动生成。
Kafka 可以通过 broker.id.generation.enable 和 reserved.broker.max.id 来配合生成新的 broker.id。
broker.id.generation.enable参数是用来配置是否开启自动生成 broker.id 的功能,默认情况下为true,即开启此功能。自动生成的broker.id有一个默认值,默认值为1000,也就是说默认情况下自动生成的 broker.id 从1001开始。
Kafka 在启动时会在 ZooKeeper 中 /brokers/ids 路径下注册一个与当前 broker 的 id 相同的临时节点。Kafka 的健康状态检查就依赖于此节点。当有 broker 加入集群或者退出集群时,这些组件就会获得通知。
- 如果你要启动另外一个具有相同 ID 的 broker,那么就会得到一个错误 —— 新的 broker 会试着进行注册,但不会成功,因为 ZooKeeper 里面已经有一个相同 ID 的 broker。
- 在 broker 停机、出现分区或者长时间垃圾回收停顿时,broker 会从 ZooKeeper 上断开连接,此时 broker 在启动时创建的临时节点会从 ZooKeeper 中移除。监听 broker 列表的 Kafka 组件会被告知该 broker 已移除。
- 在关闭 broker 时,它对应的节点也会消失,不过它的 ID 会继续存在其他数据结构中,例如主题的副本列表中,副本列表复制我们下面再说。在完全关闭一个 broker 之后,如果使用相同的 ID 启动另一个全新的 broker,它会立刻加入集群,并拥有一个与旧 broker 相同的分区和主题。
Broker Controller 的作用
我们之前在讲 Kafka Rebalance 重平衡的时候,提过一个群组协调器,负责协调群组间的关系,那么 broker 之间也有一个控制器组件(Controller),它是 Kafka 的核心组件。它的主要作用是在 ZooKeeper 的帮助下管理和协调整个 Kafka 集群,集群中的每个 broker 都可以称为 controller,但是在 Kafka 集群启动后,只有一个 broker 会成为 Controller 。既然 Kafka 集群是依赖于 ZooKeeper 集群的,所以有必要先介绍一下 ZooKeeper 是什么,可以参考作者的这一篇文章(ZooKeeper不仅仅是注册中心,你还知道有哪些?)详细了解,在这里就简单提一下 znode 节点的问题。
ZooKeeper 的数据是保存在节点上的,每个节点也被称为znode,znode 节点是一种树形的文件结构,它很像 Linux 操作系统的文件路径,ZooKeeper 的根节点是 /。

znode 根据数据的持久化方式可分为临时节点和持久性节点。持久性节点不会因为 ZooKeeper 状态的变化而消失,但是临时节点会随着 ZooKeeper 的重启而自动消失。
znode 节点有一个 Watcher 机制:当数据发生变化的时候, ZooKeeper 会产生一个 Watcher 事件,并且会发送到客户端。Watcher 监听机制是 Zookeeper 中非常重要的特性,我们基于 Zookeeper 上创建的节点,可以对这些节点绑定监听事件,比如可以监听节点数据变更、节点删除、子节点状态变更等事件,通过这个事件机制,可以基于 ZooKeeper 实现分布式锁、集群管理等功能。
控制器的选举
Kafka 当前选举控制器的规则是:Kafka 集群中第一个启动的 broker 通过在 ZooKeeper 里创建一个临时节点 /controller 让自己成为 controller 控制器。其他 broker 在启动时也会尝试创建这个节点,但是由于这个节点已存在,所以后面想要创建 /controller 节点时就会收到一个 节点已存在 的异常。然后其他 broker 会在这个控制器上注册一个 ZooKeeper 的 watch 对象,/controller 节点发生变化时,其他 broker 就会收到节点变更通知。这种方式可以确保只有一个控制器存在。那么只有单独的节点一定是有个问题的,那就是单点问题。

如果控制器关闭或者与 ZooKeeper 断开链接,ZooKeeper 上的临时节点就会消失。集群中的其他节点收到 watch 对象发送控制器下线的消息后,其他 broker 节点都会尝试让自己去成为新的控制器。其他节点的创建规则和第一个节点的创建原则一致,都是第一个在 ZooKeeper 里成功创建控制器节点的 broker 会成为新的控制器,那么其他节点就会收到节点已存在的异常,然后在新的控制器节点上再次创建 watch 对象进行监听。

控制器的作用
那么说了这么多,控制是什么呢?控制器的作用是什么呢?或者说控制器的这么一个组件被设计用来干什么?别着急,接下来我们就要说一说。
Kafka 被设计为一种模拟状态机的多线程控制器,它可以作用有下面这几点
控制器相当于部门(集群)中的部门经理(broker controller),用于管理部门中的部门成员(broker)
控制器是所有 broker 的一个监视器,用于监控 broker 的上线和下线
在 broker 宕机后,控制器能够选举新的分区 Leader
控制器能够和 broker 新选取的 Leader 发送消息
再细分一下可以具体分为如下 5 点
主题管理: Kafka Controller 可以帮助我们完成对 Kafka 主题创建、删除和增加分区的操作,简而言之就是对分区拥有最高行使权。
换句话说,当我们执行kafka-topics 脚本时,大部分的后台工作都是控制器来完成的。
分区重分配: 分区重分配主要是指,kafka-reassign-partitions 脚本提供的对已有主题分区进行细粒度的分配功能。这部分功能也是控制器实现的。Prefered 领导者选举: Preferred 领导者选举主要是 Kafka 为了避免部分 Broker 负载过重而提供的一种换 Leader 的方案。集群成员管理: 主要管理 新增 broker、broker 关闭、broker 宕机数据服务: 控制器的最后一大类工作,就是向其他 broker 提供数据服务。控制器上保存了最全的集群元数据信息,其他所有 broker 会定期接收控制器发来的元数据更新请求,从而更新其内存中的缓存数据。这些数据我们会在下面讨论
当控制器发现一个 broker 离开集群(通过观察相关 ZooKeeper 路径),控制器会收到消息:这个 broker 所管理的那些分区需要一个新的 Leader。控制器会依次遍历每个分区,确定谁能够作为新的 Leader,然后向所有包含新 Leader 或现有 Follower 的分区发送消息,该请求消息包含谁是新的 Leader 以及谁是 Follower 的信息。随后,新的 Leader 开始处理来自生产者和消费者的请求,Follower 用于从新的 Leader 那里进行复制。
这就很像外包公司的一个部门,这个部门就是专门出差的,每个人在不同的地方办公,但是中央总部有一个部门经理,现在部门经理突然离职了。公司不打算外聘人员,决定从部门内部选一个能力强的人当领导,然后当上领导的人需要向自己的组员发送消息,这条消息就是任命消息和明确他管理了哪些人,大家都知道了,然后再各自给部门干活。
当控制器发现一个 broker 加入集群时,它会使用 broker ID 来检查新加入的 broker 是否包含现有分区的副本。如果有控制器就会把消息发送给新加入的 broker 和 现有的 broker。
上面这块关于分区复制的内容我们接下来会说到。
broker controller 数据存储
上面我们介绍到 broker controller 会提供数据服务,用于保存大量的 Kafka 集群数据。如下图

可以对上面保存信息归类,主要分为三类
- broker 上的所有信息,包括 broker 中的所有分区,broker 所有分区副本,当前都有哪些运行中的 broker,哪些正在关闭中的 broker 。
- 所有主题信息,包括具体的分区信息,比如领导者副本是谁,ISR 集合中有哪些副本等。
- 所有涉及运维任务的分区。包括当前正在进行 Preferred 领导者选举以及分区重分配的分区列表。
Kafka 是离不开 ZooKeeper的,所以这些数据信息在 ZooKeeper 中也保存了一份。每当控制器初始化时,它都会从 ZooKeeper 上读取对应的元数据并填充到自己的缓存中。
broker controller 故障转移
我们在前面说过,第一个在 ZooKeeper 中的 /brokers/ids下创建节点的 broker 作为 broker controller,也就是说 broker controller 只有一个,那么必然会存在单点失效问题。kafka 为考虑到这种情况提供了故障转移功能,也就是 Fail Over。如下图

最一开始,broker1 会抢先注册成功成为 controller,然后由于网络抖动或者其他原因致使 broker1 掉线,ZooKeeper 通过 Watch 机制觉察到 broker1 的掉线,之后所有存活的 brokers 开始竞争成为 controller,这时 broker3 抢先注册成功,此时 ZooKeeper 存储的 controller 信息由 broker1 -> broker3,之后,broker3 会从 ZooKeeper 中读取元数据信息,并初始化到自己的缓存中。
注意:ZooKeeper 中存储的不是缓存信息,broker 中存储的才是缓存信息。
broker controller 存在的问题
在 Kafka 0.11 版本之前,控制器的设计是相当繁琐的。我们上面提到过一句话:Kafka controller 被设计为一种模拟状态机的多线程控制器,这种设计其实是存在一些问题的
- controller 状态的更改由不同的监听器并罚执行,因此需要进行很复杂的同步,并且容易出错而且难以调试。
- 状态传播不同步,broker 可能在时间不确定的情况下出现多种状态,这会导致不必要的额外的数据丢失
- controller 控制器还会为主题删除创建额外的 I/O 线程,导致性能损耗
- controller 的多线程设计还会访问共享数据,我们知道,多线程访问共享数据是线程同步最麻烦的地方,为了保护数据安全性,控制器不得不在代码中大量使用ReentrantLock 同步机制,这就进一步拖慢了整个控制器的处理速度。
broker controller 内部设计原理
在 Kafka 0.11 之后,Kafka controller 采用了新的设计,把多线程的方案改成了单线程加事件队列的方案。如下图所示

主要所做的改变有下面这几点
第一个改进是增加了一个 Event Executor Thread,事件执行线程,从图中可以看出,不管是 Event Queue 事件队列还是 Controller context 控制器上下文都会交给事件执行线程进行处理。将原来执行的操作全部建模成一个个独立的事件,发送到专属的事件队列中,供此线程消费。
第二个改进是将之前同步的 ZooKeeper 全部改为异步操作。ZooKeeper API 提供了两种读写的方式:同步和异步。之前控制器操作 ZooKeeper 都是采用的同步方式,这次把同步方式改为异步,据测试,效率提升了10倍。
第三个改进是根据优先级处理请求,之前的设计是 broker 会公平性的处理所有 controller 发送的请求。什么意思呢?公平性难道还不好吗?在某些情况下是的,比如 broker 在排队处理 produce 请求,这时候 controller 发出了一个 StopReplica 的请求,你会怎么办?还在继续处理 produce 请求吗?这个 produce 请求还有用吗?此时最合理的处理顺序应该是,赋予 StopReplica 请求更高的优先级,使它能够得到抢占式的处理。
副本机制
复制功能是 Kafka 架构的核心功能,在 Kafka 文档里面 Kafka 把自己描述为 一个分布式的、可分区的、可复制的提交日志服务。复制之所以这么关键,是因为消息的持久存储非常重要,这能够保证在主节点宕机后依旧能够保证 Kafka 高可用。副本机制也可以称为备份机制(Replication),通常指分布式系统在多台网络交互的机器上保存有相同的数据备份/拷贝。
Kafka 使用主题来组织数据,每个主题又被分为若干个分区,分区会部署在一到多个 broker 上,每个分区都会有多个副本,所以副本也会被保存在 broker 上,每个 broker 可能会保存成千上万个副本。下图是一个副本复制示意图

如上图所示,为了简单我只画出了两个 broker ,每个 broker 指保存了一个 Topic 的消息,在 broker1 中分区0 是Leader,它负责进行分区的复制工作,把 broker1 中的分区0复制一个副本到 broker2 的主题 A 的分区0。同理,主题 A 的分区1也是一样的道理。
副本类型分为两种:一种是 Leader(领导者) 副本,一种是Follower(跟随者)副本。
Leader 副本
Kafka 在创建分区的时候都要选举一个副本,这个选举出来的副本就是 Leader 领导者副本。
Follower 副本
除了 Leader 副本以外的副本统称为 Follower 副本,Follower 不对外提供服务。下面是 Leader 副本的工作方式

这幅图需要注意以下几点
- Kafka 中,Follower 副本也就是追随者副本是不对外提供服务的。这就是说,任何一个追随者副本都不能响应消费者和生产者的请求。所有的请求都是由领导者副本来处理。或者说,所有的请求都必须发送到 Leader 副本所在的 broker 中,Follower 副本只是用做数据拉取,采用
异步拉取的方式,并写入到自己的提交日志中,从而实现与 Leader 的同步 - 当 Leader 副本所在的 broker 宕机后,Kafka 依托于 ZooKeeper 提供的监控功能能够实时感知到,并开启新一轮的选举,从追随者副本中选一个作为 Leader。如果宕机的 broker 重启完成后,该分区的副本会作为 Follower 重新加入。
首领的另一个任务是搞清楚哪个跟随者的状态与自己是一致的。跟随者为了保证与领导者的状态一致,在有新消息到达之前先尝试从领导者那里复制消息。为了与领导者保持一致,跟随者向领导者发起获取数据的请求,这种请求与消费者为了读取消息而发送的信息是一样的。
跟随者向领导者发送消息的过程是这样的,先请求消息1,然后再接收到消息1,在时候到请求1之后,发送请求2,在收到领导者给发送给跟随者之前,跟随者是不会继续发送消息的。这个过程如下

跟随者副本在收到响应消息前,是不会继续发送消息,这一点很重要。通过查看每个跟随者请求的最新偏移量,首领就会知道每个跟随者复制的进度。如果跟随者在10s 内没有请求任何消息,或者虽然跟随者已经发送请求,但是在10s 内没有收到消息,就会被认为是不同步的。如果一个副本没有与领导者同步,那么在领导者掉线后,这个副本将不会称为领导者,因为这个副本的消息不是全部的。
与之相反的,如果跟随者同步的消息和领导者副本的消息一致,那么这个跟随者副本又被称为同步的副本。也就是说,如果领导者掉线,那么只有同步的副本能够称为领导者。
关于副本机制我们说了这么多,那么副本机制的好处是什么呢?
- 能够立刻看到写入的消息,就是你使用生产者 API 成功向分区写入消息后,马上使用消费者就能读取刚才写入的消息
- 能够实现消息的幂等性,啥意思呢?就是对于生产者产生的消息,在消费者进行消费的时候,它每次都会看到消息存在,并不会存在消息不存在的情况
同步复制和异步复制
我在学习副本机制的时候,有个疑问,既然领导者副本和跟随者副本是发送 - 等待机制的,这是一种同步的复制方式,那么为什么说跟随者副本同步领导者副本的时候是一种异步操作呢?
我认为是这样的,跟随者副本在同步领导者副本后会把消息保存在本地 log 中,这个时候跟随者会给领导者副本一个响应消息,告诉领导者自己已经保存成功了,同步复制的领导者会等待所有的跟随者副本都写入成功后,再返回给 producer 写入成功的消息。而异步复制是领导者副本不需要关心跟随者副本是否写入成功,只要领导者副本自己把消息保存到本地 log ,就会返回给 producer 写入成功的消息。下面是同步复制和异步复制的过程
同步复制
- producer 通知 ZooKeeper 识别领导者
- producer 向领导者写入消息
- 领导者收到消息后会把消息写入到本地 log
- 跟随者会从领导者那里拉取消息
- 跟随者向本地写入 log
- 跟随者向领导者发送写入成功的消息
- 领导者会收到所有的跟随者发送的消息
- 领导者向 producer 发送写入成功的消息
异步复制
和同步复制的区别在于,领导者在写入本地log之后,直接向客户端发送写入成功消息,不需要等待所有跟随者复制完成。
ISR
Kafka动态维护了一个同步状态的副本的集合(a set of In-Sync Replicas),简称ISR,ISR 也是一个很重要的概念,我们之前说过,追随者副本不提供服务,只是定期的异步拉取领导者副本的数据而已,拉取这个操作就相当于是复制,ctrl-c + ctrl-v大家肯定用的熟。那么是不是说 ISR 集合中的副本消息的数量都会与领导者副本消息数量一样呢?那也不一定,判断的依据是 broker 中参数 replica.lag.time.max.ms 的值,这个参数的含义就是跟随者副本能够落后领导者副本最长的时间间隔。
replica.lag.time.max.ms 参数默认的时间是 10秒,如果跟随者副本落后领导者副本的时间不超过 10秒,那么 Kafka 就认为领导者和跟随者是同步的。即使此时跟随者副本中存储的消息要小于领导者副本。如果跟随者副本要落后于领导者副本 10秒以上的话,跟随者副本就会从 ISR 被剔除。倘若该副本后面慢慢地追上了领导者的进度,那么它是能够重新被加回 ISR 的。这也表明,ISR 是一个动态调整的集合,而非静态不变的。
Unclean 领导者选举
既然 ISR 是可以动态调整的,那么必然会出现 ISR 集合中为空的情况,由于领导者副本是一定出现在 ISR 集合中的,那么 ISR 集合为空必然说明领导者副本也挂了,所以此时 Kafka 需要重新选举一个新的领导者,那么该如何选举呢?现在你需要转变一下思路,我们上面说 ISR 集合中一定是与领导者同步的副本,那么不再 ISR 集合中的副本一定是不与领导者同步的副本了,也就是不再 ISR 列表中的跟随者副本会丢失一些消息。如果你开启 broker 端参数 unclean.leader.election.enable的话,下一个领导者就会在这些非同步的副本中选举。这种选举也叫做Unclean 领导者选举。
如果你接触过分布式项目的话你一定知道 CAP 理论,那么这种 Unclean 领导者选举其实是牺牲了数据一致性,保证了 Kafka 的高可用性。
你可以根据你的实际业务场景决定是否开启 Unclean 领导者选举,一般不建议开启这个参数,因为数据的一致性要比可用性重要的多。
Kafka 请求处理流程
broker 的大部分工作是处理客户端、分区副本和控制器发送给分区领导者的请求。这种请求一般都是请求/响应式的,我猜测你接触最早的请求/响应的方式应该就是 HTTP 请求了。事实上,HTTP 请求可以是同步可以是异步的。一般正常的 HTTP 请求都是同步的,同步方式最大的一个特点是提交请求->等待服务器处理->处理完毕返回 这个期间客户端浏览器不能做任何事。而异步方式最大的特点是 请求通过事件触发->服务器处理(这是浏览器仍然可以作其他事情)-> 处理完毕。
那么我也可以说同步请求就是顺序处理的,而异步请求的执行方式则不确定,因为异步需要创建多个执行线程,而每个线程的执行顺序不同。
这里需要注意一点,我们只是使用 HTTP 请求来举例子,而 Kafka 采用的是 TCP 基于 Socket 的方式进行通讯
那么这两种方式有什么缺点呢?
我相信聪明的你应该能马上想到,同步的方式最大的缺点就是吞吐量太差,资源利用率极低,由于只能顺序处理请求,因此,每个请求都必须等待前一个请求处理完毕才能得到处理。这种方式只适用于请求发送非常不频繁的系统。
异步的方式的缺点就是为每个请求都创建线程的做法开销极大,在某些场景下甚至会压垮整个服务。
响应式模型
说了这么半天,Kafka 采用同步还是异步的呢?都不是,Kafka 采用的是一种 响应式(Reactor)模型,那么什么是响应式模型呢?简单的说,Reactor 模式是事件驱动架构的一种实现方式,特别适合应用于处理多个客户端并发向服务器端发送请求的场景,如下图所示

Kafka 的 broker 端有个 SocketServer组件,类似于处理器,SocketServer 是基于 TCP 的 Socket 连接的,它用于接受客户端请求,所有的请求消息都包含一个消息头,消息头中都包含如下信息
- Request type (也就是 API Key)
- Request version(broker 可以处理不同版本的客户端请求,并根据客户版本做出不同的响应)
- Correlation ID — 一个具有唯一性的数字,用于标示请求消息,同时也会出现在响应消息和错误日志中(用于诊断问题)
- Client ID — 用于标示发送请求的客户端
broker 会在它所监听的每一个端口上运行一个 Acceptor 线程,这个线程会创建一个连接,并把它交给 Processor(网络线程池), Processor 的数量可以使用 num.network.threads 进行配置,其默认值是3,表示每台 broker 启动时会创建3个线程,专门处理客户端发送的请求。
Acceptor 线程会采用轮询的方式将入栈请求公平的发送至网络线程池中,因此,在实际使用过程中,这些线程通常具有相同的机率被分配到待处理请求队列中,然后从响应队列获取响应消息,把它们发送给客户端。Processor 网络线程池中的请求 – 响应的处理还是比较复杂的,下面是网络线程池中的处理流程图

Processor 网络线程池接收到客户和其他 broker 发送来的消息后,网络线程池会把消息放到请求队列中,注意这个是共享请求队列,因为网络线程池是多线程机制的,所以请求队列的消息是多线程共享的区域,然后由 IO 线程池进行处理,根据消息的种类判断做何处理,比如 PRODUCE 请求,就会将消息写入到 log 日志中,如果是FETCH请求,则从磁盘或者页缓存中读取消息。也就是说,IO线程池是真正做判断,处理请求的一个组件。在IO 线程池处理完毕后,就会判断是放入响应队列中还是 Purgatory 中,Purgatory 是什么我们下面再说,现在先说一下响应队列,响应队列是每个线程所独有的,因为响应式模型中不会关心请求发往何处,因此把响应回传的事情就交给每个线程了,所以也就不必共享了。
注意:IO 线程池可以通过 broker 端参数
num.io.threads来配置,默认的线程数是8,表示每台 broker 启动后自动创建 8 个IO 处理线程。
请求类型
下面是几种常见的请求类型
生产请求
我在 真的,关于 Kafka 入门看这一篇就够了 文章中提到过 acks 这个配置项的含义
简单来讲就是不同的配置对写入成功的界定是不同的,如果 acks = 1,那么只要领导者收到消息就表示写入成功,如果acks = 0,表示只要领导者发送消息就表示写入成功,根本不用考虑返回值的影响。如果 acks = all,就表示领导者需要收到所有副本的消息后才表示写入成功。
在消息被写入分区的首领后,如果 acks 配置的值是 all,那么这些请求会被保存在 炼狱(Purgatory)的缓冲区中,直到领导者副本发现跟随者副本都复制了消息,响应才会发送给客户端。
获取请求
broker 获取请求的方式与处理生产请求的方式类似,客户端发送请求,向 broker 请求主题分区中特定偏移量的消息,如果偏移量存在,Kafka 会采用 零复制 技术向客户端发送消息,Kafka 会直接把消息从文件中发送到网络通道中,而不需要经过任何的缓冲区,从而获得更好的性能。
客户端可以设置获取请求数据的上限和下限,上限指的是客户端为接受足够消息分配的内存空间,这个限制比较重要,如果上限太大的话,很有可能直接耗尽客户端内存。下限可以理解为攒足了数据包再发送的意思,这就相当于项目经理给程序员分配了 10 个bug,程序员每次改一个 bug 就会向项目经理汇报一下,有的时候改好了有的时候可能还没改好,这样就增加了沟通成本和时间成本,所以下限值得就是程序员你改完10个 bug 再向我汇报!!!如下图所示

如图你可以看到,在拉取消息 —> 消息 之间是有一个等待消息积累这么一个过程的,这个消息积累你可以把它想象成超时时间,不过超时会跑出异常,消息积累超时后会响应回执。延迟时间可以通过 replica.lag.time.max.ms 来配置,它指定了副本在复制消息时可被允许的最大延迟时间。
元数据请求
生产请求和响应请求都必须发送给领导者副本,如果 broker 收到一个针对某个特定分区的请求,而该请求的首领在另外一个 broker 中,那么发送请求的客户端会收到非分区首领的错误响应;如果针对某个分区的请求被发送到不含有领导者的 broker 上,也会出现同样的错误。Kafka 客户端需要把请求和响应发送到正确的 broker 上。这不是废话么?我怎么知道要往哪发送?
事实上,客户端会使用一种 元数据请求 ,这种请求会包含客户端感兴趣的主题列表,服务端的响应消息指明了主题的分区,领导者副本和跟随者副本。元数据请求可以发送给任意一个 broker,因为所有的 broker 都会缓存这些信息。
一般情况下,客户端会把这些信息缓存,并直接向目标 broker 发送生产请求和相应请求,这些缓存需要隔一段时间就进行刷新,使用metadata.max.age.ms 参数来配置,从而知道元数据是否发生了变更。比如,新的 broker 加入后,会触发重平衡,部分副本会移动到新的 broker 上。这时候,如果客户端收到 不是首领的错误,客户端在发送请求之前刷新元数据缓存。
Kafka 重平衡流程
我在 真的,关于 Kafka 入门看这一篇就够了 中关于消费者描述的时候大致说了一下消费者组和重平衡之间的关系,实际上,归纳为一点就是让组内所有的消费者实例就消费哪些主题分区达成一致。
我们知道,一个消费者组中是要有一个群组协调者(Coordinator)的,而重平衡的流程就是由 Coordinator 的帮助下来完成的。
这里需要先声明一下重平衡发生的条件
- 消费者订阅的任何主题发生变化
- 消费者数量发生变化
- 分区数量发生变化
- 如果你订阅了一个还尚未创建的主题,那么重平衡在该主题创建时发生。如果你订阅的主题发生删除那么也会发生重平衡
- 消费者被群组协调器认为是
DEAD状态,这可能是由于消费者崩溃或者长时间处于运行状态下发生的,这意味着在配置合理时间的范围内,消费者没有向群组协调器发送任何心跳,这也会导致重平衡的发生。
在了解重平衡之前,你需要知道这两个角色
群组协调器(Coordinator):群组协调器是一个能够从消费者群组中收到所有消费者发送心跳消息的 broker。在最早期的版本中,元数据信息是保存在 ZooKeeper 中的,但是目前元数据信息存储到了 broker 中。每个消费者组都应该和群组中的群组协调器同步。当所有的决策要在应用程序节点中进行时,群组协调器可以满足 JoinGroup 请求并提供有关消费者组的元数据信息,例如分配和偏移量。群组协调器还有权知道所有消费者的心跳,消费者群组中还有一个角色就是领导者,注意把它和领导者副本和 kafka controller 进行区分。领导者是群组中负责决策的角色,所以如果领导者掉线了,群组协调器有权把所有消费者踢出组。因此,消费者群组的一个很重要的行为是选举领导者,并与协调器读取和写入有关分配和分区的元数据信息。
消费者领导者: 每个消费者群组中都有一个领导者。如果消费者停止发送心跳了,协调者会触发重平衡。
在了解重平衡之前,你需要知道状态机是什么
Kafka 设计了一套消费者组状态机(State Machine) ,来帮助协调者完成整个重平衡流程。消费者状态机主要有五种状态它们分别是 Empty、Dead、PreparingRebalance、CompletingRebalance 和 Stable。

了解了这些状态的含义之后,下面我们用几条路径来表示一下消费者状态的轮转
消费者组一开始处于 Empty 状态,当重平衡开启后,它会被置于 PreparingRebalance 状态等待新消费者的加入,一旦有新的消费者加入后,消费者群组就会处于 CompletingRebalance 状态等待分配,只要有新的消费者加入群组或者离开,就会触发重平衡,消费者的状态处于 PreparingRebalance 状态。等待分配机制指定好后完成分配,那么它的流程图是这样的

在上图的基础上,当消费者群组都到达 Stable 状态后,一旦有新的消费者加入/离开/心跳过期,那么触发重平衡,消费者群组的状态重新处于 PreparingRebalance 状态。那么它的流程图是这样的。

在上图的基础上,消费者群组处于 PreparingRebalance 状态后,很不幸,没人玩儿了,所有消费者都离开了,这时候还可能会保留有消费者消费的位移数据,一旦位移数据过期或者被刷新,那么消费者群组就处于 Dead 状态了。它的流程图是这样的

在上图的基础上,我们分析了消费者的重平衡,在 PreparingRebalance或者 CompletingRebalance 或者 Stable 任意一种状态下发生位移主题分区 Leader 发生变更,群组会直接处于 Dead 状态,它的所有路径如下

这里面需要注意两点:
一般出现 Required xx expired offsets in xxx milliseconds 就表明Kafka 很可能就把该组的位移数据删除了
只有 Empty 状态下的组,才会执行过期位移删除的操作。
重平衡流程
上面我们了解到了消费者群组状态的转化过程,下面我们真正开始介绍 Rebalance 的过程。重平衡过程可以从两个方面去看:消费者端和协调者端,首先我们先看一下消费者端
从消费者看重平衡
从消费者看重平衡有两个步骤:分别是 消费者加入组 和 等待领导者分配方案。这两个步骤后分别对应的请求是 JoinGroup 和 SyncGroup。
新的消费者加入群组时,这个消费者会向协调器发送 JoinGroup 请求。在该请求中,每个消费者成员都需要将自己消费的 topic 进行提交,我们上面描述群组协调器中说过,这么做的目的就是为了让协调器收集足够的元数据信息,来选取消费者组的领导者。通常情况下,第一个发送 JoinGroup 请求的消费者会自动称为领导者。领导者的任务是收集所有成员的订阅信息,然后根据这些信息,制定具体的分区消费分配方案。如图

在所有的消费者都加入进来并把元数据信息提交给领导者后,领导者做出分配方案并发送 SyncGroup 请求给协调者,协调者负责下发群组中的消费策略。下图描述了 SyncGroup 请求的过程

当所有成员都成功接收到分配方案后,消费者组进入到 Stable 状态,即开始正常的消费工作。
从协调者来看重平衡
从协调者角度来看重平衡主要有下面这几种触发条件,
- 新成员加入组
- 组成员主动离开
- 组成员崩溃离开
- 组成员提交位移
我们分别来描述一下,先从新成员加入组开始
新成员加入组
我们讨论的场景消费者集群状态处于Stable 等待分配的过程,这时候如果有新的成员加入组的话,重平衡的过程

从这个角度来看,协调者的过程和消费者类似,只是刚刚从消费者的角度去看,现在从领导者的角度去看
组成员离开
组成员离开消费者群组指的是消费者实例调用 close() 方法主动通知协调者它要退出。这里又会有一个新的请求出现 LeaveGroup()请求 。如下图所示

组成员崩溃
组成员崩溃是指消费者实例出现严重故障,宕机或者一段时间未响应,协调者接收不到消费者的心跳,就会被认为是组成员崩溃,崩溃离组是被动的,协调者通常需要等待一段时间才能感知到,这段时间一般是由消费者端参数 session.timeout.ms 控制的。如下图所示

重平衡时提交位移
这个过程我们就不再用图形来表示了,大致描述一下就是 消费者发送 JoinGroup 请求后,群组中的消费者必须在指定的时间范围内提交各自的位移,然后再开启正常的 JoinGroup/SyncGroup 请求发送。
# Kafka入门一篇文章就够了-Java面试题

初识 Kafka
什么是 Kafka
Kafka 是由 Linkedin 公司开发的,它是一个分布式的,支持多分区、多副本,基于 Zookeeper 的分布式消息流平台,它同时也是一款开源的基于发布订阅模式的消息引擎系统。
Kafka 的基本术语
消息:Kafka 中的数据单元被称为消息,也被称为记录,可以把它看作数据库表中某一行的记录。
批次:为了提高效率, 消息会分批次写入 Kafka,批次就代指的是一组消息。
主题:消息的种类称为 主题(Topic),可以说一个主题代表了一类消息。相当于是对消息进行分类。主题就像是数据库中的表。
分区:主题可以被分为若干个分区(partition),同一个主题中的分区可以不在一个机器上,有可能会部署在多个机器上,由此来实现 kafka 的伸缩性,单一主题中的分区有序,但是无法保证主题中所有的分区有序

生产者: 向主题发布消息的客户端应用程序称为生产者(Producer),生产者用于持续不断的向某个主题发送消息。
消费者:订阅主题消息的客户端程序称为消费者(Consumer),消费者用于处理生产者产生的消息。
消费者群组:生产者与消费者的关系就如同餐厅中的厨师和顾客之间的关系一样,一个厨师对应多个顾客,也就是一个生产者对应多个消费者,消费者群组(Consumer Group)指的就是由一个或多个消费者组成的群体。

偏移量:偏移量(Consumer Offset)是一种元数据,它是一个不断递增的整数值,用来记录消费者发生重平衡时的位置,以便用来恢复数据。
broker: 一个独立的 Kafka 服务器就被称为 broker,broker 接收来自生产者的消息,为消息设置偏移量,并提交消息到磁盘保存。
broker 集群:broker 是集群 的组成部分,broker 集群由一个或多个 broker 组成,每个集群都有一个 broker 同时充当了集群控制器的角色(自动从集群的活跃成员中选举出来)。
副本:Kafka 中消息的备份又叫做 副本(Replica),副本的数量是可以配置的,Kafka 定义了两类副本:领导者副本(Leader Replica) 和 追随者副本(Follower Replica),前者对外提供服务,后者只是被动跟随。
重平衡:Rebalance。消费者组内某个消费者实例挂掉后,其他消费者实例自动重新分配订阅主题分区的过程。Rebalance 是 Kafka 消费者端实现高可用的重要手段。
Kafka 的特性(设计原则)
高吞吐、低延迟:kakfa 最大的特点就是收发消息非常快,kafka 每秒可以处理几十万条消息,它的最低延迟只有几毫秒。高伸缩性: 每个主题(topic) 包含多个分区(partition),主题中的分区可以分布在不同的主机(broker)中。持久性、可靠性: Kafka 能够允许数据的持久化存储,消息被持久化到磁盘,并支持数据备份防止数据丢失,Kafka 底层的数据存储是基于 Zookeeper 存储的,Zookeeper 我们知道它的数据能够持久存储。容错性: 允许集群中的节点失败,某个节点宕机,Kafka 集群能够正常工作高并发: 支持数千个客户端同时读写
Kafka 的使用场景
- 活动跟踪:Kafka 可以用来跟踪用户行为,比如我们经常回去淘宝购物,你打开淘宝的那一刻,你的登陆信息,登陆次数都会作为消息传输到 Kafka ,当你浏览购物的时候,你的浏览信息,你的搜索指数,你的购物爱好都会作为一个个消息传递给 Kafka ,这样就可以生成报告,可以做智能推荐,购买喜好等。
- 传递消息:Kafka 另外一个基本用途是传递消息,应用程序向用户发送通知就是通过传递消息来实现的,这些应用组件可以生成消息,而不需要关心消息的格式,也不需要关心消息是如何发送的。
- 度量指标:Kafka也经常用来记录运营监控数据。包括收集各种分布式应用的数据,生产各种操作的集中反馈,比如报警和报告。
- 日志记录:Kafka 的基本概念来源于提交日志,比如我们可以把数据库的更新发送到 Kafka 上,用来记录数据库的更新时间,通过kafka以统一接口服务的方式开放给各种consumer,例如hadoop、Hbase、Solr等。
- 流式处理:流式处理是有一个能够提供多种应用程序的领域。
- 限流削峰:Kafka 多用于互联网领域某一时刻请求特别多的情况下,可以把请求写入Kafka 中,避免直接请求后端程序导致服务崩溃。
Kafka 的消息队列
Kafka 的消息队列一般分为两种模式:点对点模式和发布订阅模式
Kafka 是支持消费者群组的,也就是说 Kafka 中会有一个或者多个消费者,如果一个生产者生产的消息由一个消费者进行消费的话,那么这种模式就是点对点模式

如果一个生产者或者多个生产者产生的消息能够被多个消费者同时消费的情况,这样的消息队列成为发布订阅模式的消息队列

Kafka 系统架构

如上图所示,一个典型的 Kafka 集群中包含若干Producer(可以是web前端产生的Page View,或者是服务器日志,系统CPU、Memory等),若干broker(Kafka支持水平扩展,一般broker数量越多,集群吞吐率越高),若干Consumer Group,以及一个Zookeeper集群。Kafka通过Zookeeper管理集群配置,选举leader,以及在Consumer Group发生变化时进行rebalance。Producer使用push模式将消息发布到broker,Consumer使用pull模式从broker订阅并消费消息。
核心 API
Kafka 有四个核心API,它们分别是
- Producer API,它允许应用程序向一个或多个 topics 上发送消息记录
- Consumer API,允许应用程序订阅一个或多个 topics 并处理为其生成的记录流
- Streams API,它允许应用程序作为流处理器,从一个或多个主题中消费输入流并为其生成输出流,有效的将输入流转换为输出流。
- Connector API,它允许构建和运行将 Kafka 主题连接到现有应用程序或数据系统的可用生产者和消费者。例如,关系数据库的连接器可能会捕获对表的所有更改

Kafka 为何如此之快
Kafka 实现了零拷贝原理来快速移动数据,避免了内核之间的切换。Kafka 可以将数据记录分批发送,从生产者到文件系统(Kafka 主题日志)到消费者,可以端到端的查看这些批次的数据。
批处理能够进行更有效的数据压缩并减少 I/O 延迟,Kafka 采取顺序写入磁盘的方式,避免了随机磁盘寻址的浪费,更多关于磁盘寻址的了解,请参阅 程序员需要了解的硬核知识之磁盘 。
总结一下其实就是四个要点
- 顺序读写
- 零拷贝
- 消息压缩
- 分批发送
Kafka 安装和重要配置
Kafka 安装我在 Kafka 系列第一篇应该比较详细了,详情见带你涨姿势的认识一下kafka 这篇文章。
那我们还是主要来说一下 Kafka 中的重要参数配置吧,这些参数对 Kafka 来说是非常重要的。
broker 端配置
- broker.id
每个 kafka broker 都有一个唯一的标识来表示,这个唯一的标识符即是 broker.id,它的默认值是 0。这个值在 kafka 集群中必须是唯一的,这个值可以任意设定,
- port
如果使用配置样本来启动 kafka,它会监听 9092 端口。修改 port 配置参数可以把它设置成任意的端口。要注意,如果使用 1024 以下的端口,需要使用 root 权限启动 kakfa。
- zookeeper.connect
用于保存 broker 元数据的 Zookeeper 地址是通过 zookeeper.connect 来指定的。比如我可以这么指定 localhost:2181 表示这个 Zookeeper 是运行在本地 2181 端口上的。我们也可以通过 比如我们可以通过 zk1:2181,zk2:2181,zk3:2181 来指定 zookeeper.connect 的多个参数值。该配置参数是用冒号分割的一组 hostname:port/path 列表,其含义如下
hostname 是 Zookeeper 服务器的机器名或者 ip 地址。
port 是 Zookeeper 客户端的端口号
/path 是可选择的 Zookeeper 路径,Kafka 路径是使用了 chroot 环境,如果不指定默认使用跟路径。
如果你有两套 Kafka 集群,假设分别叫它们 kafka1 和 kafka2,那么两套集群的
zookeeper.connect参数可以这样指定:zk1:2181,zk2:2181,zk3:2181/kafka1和zk1:2181,zk2:2181,zk3:2181/kafka2
- log.dirs
Kafka 把所有的消息都保存到磁盘上,存放这些日志片段的目录是通过 log.dirs 来制定的,它是用一组逗号来分割的本地系统路径,log.dirs 是没有默认值的,你必须手动指定他的默认值。其实还有一个参数是 log.dir,如你所知,这个配置是没有 s 的,默认情况下只用配置 log.dirs 就好了,比如你可以通过 /home/kafka1,/home/kafka2,/home/kafka3 这样来配置这个参数的值。
- num.recovery.threads.per.data.dir
对于如下3种情况,Kafka 会使用可配置的线程池来处理日志片段。
服务器正常启动,用于打开每个分区的日志片段;
服务器崩溃后重启,用于检查和截断每个分区的日志片段;
服务器正常关闭,用于关闭日志片段。
默认情况下,每个日志目录只使用一个线程。因为这些线程只是在服务器启动和关闭时会用到,所以完全可以设置大量的线程来达到井行操作的目的。特别是对于包含大量分区的服务器来说,一旦发生崩愤,在进行恢复时使用井行操作可能会省下数小时的时间。设置此参数时需要注意,所配置的数字对应的是 log.dirs 指定的单个日志目录。也就是说,如果 num.recovery.threads.per.data.dir 被设为 8,并且 log.dir 指定了 3 个路径,那么总共需要 24 个线程。
- auto.create.topics.enable
默认情况下,kafka 会使用三种方式来自动创建主题,下面是三种情况:
当一个生产者开始往主题写入消息时
当一个消费者开始从主题读取消息时
当任意一个客户端向主题发送元数据请求时
auto.create.topics.enable参数我建议最好设置成 false,即不允许自动创建 Topic。在我们的线上环境里面有很多名字稀奇古怪的 Topic,我想大概都是因为该参数被设置成了 true 的缘故。
主题默认配置
Kafka 为新创建的主题提供了很多默认配置参数,下面就来一起认识一下这些参数
- num.partitions
num.partitions 参数指定了新创建的主题需要包含多少个分区。如果启用了主题自动创建功能(该功能是默认启用的),主题分区的个数就是该参数指定的值。该参数的默认值是 1。要注意,我们可以增加主题分区的个数,但不能减少分区的个数。
- default.replication.factor
这个参数比较简单,它表示 kafka保存消息的副本数,如果一个副本失效了,另一个还可以继续提供服务default.replication.factor 的默认值为1,这个参数在你启用了主题自动创建功能后有效。
- log.retention.ms
Kafka 通常根据时间来决定数据可以保留多久。默认使用 log.retention.hours 参数来配置时间,默认是 168 个小时,也就是一周。除此之外,还有两个参数 log.retention.minutes 和 log.retentiion.ms 。这三个参数作用是一样的,都是决定消息多久以后被删除,推荐使用 log.retention.ms。
- log.retention.bytes
另一种保留消息的方式是判断消息是否过期。它的值通过参数 log.retention.bytes 来指定,作用在每一个分区上。也就是说,如果有一个包含 8 个分区的主题,并且 log.retention.bytes 被设置为 1GB,那么这个主题最多可以保留 8GB 数据。所以,当主题的分区个数增加时,整个主题可以保留的数据也随之增加。
- log.segment.bytes
上述的日志都是作用在日志片段上,而不是作用在单个消息上。当消息到达 broker 时,它们被追加到分区的当前日志片段上,当日志片段大小到达 log.segment.bytes 指定上限(默认为 1GB)时,当前日志片段就会被关闭,一个新的日志片段被打开。如果一个日志片段被关闭,就开始等待过期。这个参数的值越小,就越会频繁的关闭和分配新文件,从而降低磁盘写入的整体效率。
- log.segment.ms
上面提到日志片段经关闭后需等待过期,那么 log.segment.ms 这个参数就是指定日志多长时间被关闭的参数和,log.segment.ms 和 log.retention.bytes 也不存在互斥问题。日志片段会在大小或时间到达上限时被关闭,就看哪个条件先得到满足。
- message.max.bytes
broker 通过设置 message.max.bytes 参数来限制单个消息的大小,默认是 1000 000, 也就是 1MB,如果生产者尝试发送的消息超过这个大小,不仅消息不会被接收,还会收到 broker 返回的错误消息。跟其他与字节相关的配置参数一样,该参数指的是压缩后的消息大小,也就是说,只要压缩后的消息小于 mesage.max.bytes,那么消息的实际大小可以大于这个值
这个值对性能有显著的影响。值越大,那么负责处理网络连接和请求的线程就需要花越多的时间来处理这些请求。它还会增加磁盘写入块的大小,从而影响 IO 吞吐量。
- retention.ms
规定了该主题消息被保存的时常,默认是7天,即该主题只能保存7天的消息,一旦设置了这个值,它会覆盖掉 Broker 端的全局参数值。
- retention.bytes
retention.bytes:规定了要为该 Topic 预留多大的磁盘空间。和全局参数作用相似,这个值通常在多租户的 Kafka 集群中会有用武之地。当前默认值是 -1,表示可以无限使用磁盘空间。
JVM 参数配置
JDK 版本一般推荐直接使用 JDK1.8,这个版本也是现在中国大部分程序员的首选版本。
说到 JVM 端设置,就绕不开堆这个话题,业界最推崇的一种设置方式就是直接将 JVM 堆大小设置为 6GB,这样会避免很多 Bug 出现。
JVM 端配置的另一个重要参数就是垃圾回收器的设置,也就是平时常说的 GC 设置。如果你依然在使用 Java 7,那么可以根据以下法则选择合适的垃圾回收器:
- 如果 Broker 所在机器的 CPU 资源非常充裕,建议使用 CMS 收集器。启用方法是指定
-XX:+UseCurrentMarkSweepGC。 - 否则,使用吞吐量收集器。开启方法是指定
-XX:+UseParallelGC。
当然了,如果你已经在使用 Java 8 了,那么就用默认的 G1 收集器就好了。在没有任何调优的情况下,G1 表现得要比 CMS 出色,主要体现在更少的 Full GC,需要调整的参数更少等,所以使用 G1 就好了。
一般 G1 的调整只需要这两个参数即可
- MaxGCPauseMillis
该参数指定每次垃圾回收默认的停顿时间。该值不是固定的,G1可以根据需要使用更长的时间。它的默认值是 200ms,也就是说,每一轮垃圾回收大概需要200 ms 的时间。
- InitiatingHeapOccupancyPercent
该参数指定了 G1 启动新一轮垃圾回收之前可以使用的堆内存百分比,默认值是45,这就表明G1在堆使用率到达45之前不会启用垃圾回收。这个百分比包括新生代和老年代。
Kafka Producer
在 Kafka 中,我们把产生消息的那一方称为生产者,比如我们经常回去淘宝购物,你打开淘宝的那一刻,你的登陆信息,登陆次数都会作为消息传输到 Kafka 后台,当你浏览购物的时候,你的浏览信息,你的搜索指数,你的购物爱好都会作为一个个消息传递给 Kafka 后台,然后淘宝会根据你的爱好做智能推荐,致使你的钱包从来都禁不住诱惑,那么这些生产者产生的消息是怎么传到 Kafka 应用程序的呢?发送过程是怎么样的呢?
尽管消息的产生非常简单,但是消息的发送过程还是比较复杂的,如图

我们从创建一个ProducerRecord 对象开始,ProducerRecord 是 Kafka 中的一个核心类,它代表了一组 Kafka 需要发送的 key/value 键值对,它由记录要发送到的主题名称(Topic Name),可选的分区号(Partition Number)以及可选的键值对构成。
在发送 ProducerRecord 时,我们需要将键值对对象由序列化器转换为字节数组,这样它们才能够在网络上传输。然后消息到达了分区器。
如果发送过程中指定了有效的分区号,那么在发送记录时将使用该分区。如果发送过程中未指定分区,则将使用key 的 hash 函数映射指定一个分区。如果发送的过程中既没有分区号也没有,则将以循环的方式分配一个分区。选好分区后,生产者就知道向哪个主题和分区发送数据了。
ProducerRecord 还有关联的时间戳,如果用户没有提供时间戳,那么生产者将会在记录中使用当前的时间作为时间戳。Kafka 最终使用的时间戳取决于 topic 主题配置的时间戳类型。
- 如果将主题配置为使用
CreateTime,则生产者记录中的时间戳将由 broker 使用。 - 如果将主题配置为使用
LogAppendTime,则生产者记录中的时间戳在将消息添加到其日志中时,将由 broker 重写。
然后,这条消息被存放在一个记录批次里,这个批次里的所有消息会被发送到相同的主题和分区上。由一个独立的线程负责把它们发到 Kafka Broker 上。
Kafka Broker 在收到消息时会返回一个响应,如果写入成功,会返回一个 RecordMetaData 对象,它包含了主题和分区信息,以及记录在分区里的偏移量,上面两种的时间戳类型也会返回给用户。如果写入失败,会返回一个错误。生产者在收到错误之后会尝试重新发送消息,几次之后如果还是失败的话,就返回错误消息。
创建 Kafka 生产者
要向 Kafka 写入消息,首先需要创建一个生产者对象,并设置一些属性。Kafka 生产者有3个必选的属性
- bootstrap.servers
该属性指定 broker 的地址清单,地址的格式为 host:port。清单里不需要包含所有的 broker 地址,生产者会从给定的 broker 里查找到其他的 broker 信息。不过建议至少要提供两个 broker 信息,一旦其中一个宕机,生产者仍然能够连接到集群上。
- key.serializer
broker 需要接收到序列化之后的 key/value 值,所以生产者发送的消息需要经过序列化之后才传递给 Kafka Broker。生产者需要知道采用何种方式把 Java 对象转换为字节数组。key.serializer 必须被设置为一个实现了org.apache.kafka.common.serialization.Serializer 接口的类,生产者会使用这个类把键对象序列化为字节数组。这里拓展一下 Serializer 类
Serializer 是一个接口,它表示类将会采用何种方式序列化,它的作用是把对象转换为字节,实现了 Serializer 接口的类主要有 ByteArraySerializer、StringSerializer、IntegerSerializer ,其中 ByteArraySerialize 是 Kafka 默认使用的序列化器,其他的序列化器还有很多,你可以通过 这里 查看其他序列化器。要注意的一点:key.serializer 是必须要设置的,即使你打算只发送值的内容。
- value.serializer
与 key.serializer 一样,value.serializer 指定的类会将值序列化。
下面代码演示了如何创建一个 Kafka 生产者,这里只指定了必要的属性,其他使用默认的配置
private Properties properties = new Properties(); properties.put("bootstrap.servers","broker1:9092,broker2:9092"); properties.put("key.serializer","org.apache.kafka.common.serialization.StringSerializer"); properties.put("value.serializer","org.apache.kafka.common.serialization.StringSerializer"); properties = new KafkaProducer<String,String>(properties);
来解释一下这段代码
- 首先创建了一个 Properties 对象
- 使用
StringSerializer序列化器序列化 key / value 键值对 - 在这里我们创建了一个新的生产者对象,并为键值设置了恰当的类型,然后把 Properties 对象传递给他。
Kafka 消息发送
实例化生产者对象后,接下来就可以开始发送消息了,发送消息主要由下面几种方式
简单消息发送
Kafka 最简单的消息发送如下:
ProducerRecord<String,String> record = new ProducerRecord<String, String>("CustomerCountry","West","France");
producer.send(record);
代码中生产者(producer)的 send() 方法需要把 ProducerRecord 的对象作为参数进行发送,ProducerRecord 有很多构造函数,这个我们下面讨论,这里调用的是
public ProducerRecord(String topic, K key, V value) {}
这个构造函数,需要传递的是 topic主题,key 和 value。
把对应的参数传递完成后,生产者调用 send() 方法发送消息(ProducerRecord对象)。我们可以从生产者的架构图中看出,消息是先被写入分区中的缓冲区中,然后分批次发送给 Kafka Broker。

发送成功后,send() 方法会返回一个 Future(java.util.concurrent) 对象,Future 对象的类型是 RecordMetadata 类型,我们上面这段代码没有考虑返回值,所以没有生成对应的 Future 对象,所以没有办法知道消息是否发送成功。如果不是很重要的信息或者对结果不会产生影响的信息,可以使用这种方式进行发送。
我们可以忽略发送消息时可能发生的错误或者在服务器端可能发生的错误,但在消息发送之前,生产者还可能发生其他的异常。这些异常有可能是 SerializationException(序列化失败),BufferedExhaustedException 或 TimeoutException(说明缓冲区已满),又或是 InterruptedException(说明发送线程被中断)
同步发送消息
第二种消息发送机制如下所示
ProducerRecord<String,String> record = new ProducerRecord<String, String>("CustomerCountry","West","France");
try{ RecordMetadata recordMetadata = producer.send(record).get(); }catch(Exception e){ e.printStackTrace(); }
这种发送消息的方式较上面的发送方式有了改进,首先调用 send() 方法,然后再调用 get() 方法等待 Kafka 响应。如果服务器返回错误,get() 方法会抛出异常,如果没有发生错误,我们会得到 RecordMetadata 对象,可以用它来查看消息记录。
生产者(KafkaProducer)在发送的过程中会出现两类错误:其中一类是重试错误,这类错误可以通过重发消息来解决。比如连接的错误,可以通过再次建立连接来解决;无主错误则可以通过重新为分区选举首领来解决。KafkaProducer 被配置为自动重试,如果多次重试后仍无法解决问题,则会抛出重试异常。另一类错误是无法通过重试来解决的,比如消息过大对于这类错误,KafkaProducer 不会进行重试,直接抛出异常。
异步发送消息
同步发送消息都有个问题,那就是同一时间只能有一个消息在发送,这会造成许多消息无法直接发送,造成消息滞后,无法发挥效益最大化。
比如消息在应用程序和 Kafka 集群之间一个来回需要 10ms。如果发送完每个消息后都等待响应的话,那么发送100个消息需要 1 秒,但是如果是异步方式的话,发送 100 条消息所需要的时间就会少很多很多。大多数时候,虽然Kafka 会返回 RecordMetadata 消息,但是我们并不需要等待响应。
为了在异步发送消息的同时能够对异常情况进行处理,生产者提供了回掉支持。下面是回调的一个例子
ProducerRecord<String, String> producerRecord = new ProducerRecord<String, String>("CustomerCountry", "Huston", "America"); producer.send(producerRecord,new DemoProducerCallBack());
class DemoProducerCallBack implements Callback {
public void onCompletion(RecordMetadata metadata, Exception exception) { if(exception != null){ exception.printStackTrace();; } } }
首先实现回调需要定义一个实现了org.apache.kafka.clients.producer.Callback的类,这个接口只有一个 onCompletion方法。如果 kafka 返回一个错误,onCompletion 方法会抛出一个非空(non null)异常,这里我们只是简单的把它打印出来,如果是生产环境需要更详细的处理,然后在 send() 方法发送的时候传递一个 Callback 回调的对象。
生产者分区机制
Kafka 对于数据的读写是以分区为粒度的,分区可以分布在多个主机(Broker)中,这样每个节点能够实现独立的数据写入和读取,并且能够通过增加新的节点来增加 Kafka 集群的吞吐量,通过分区部署在多个 Broker 来实现负载均衡的效果。
上面我们介绍了生产者的发送方式有三种:不管结果如何直接发送、发送并返回结果、发送并回调。由于消息是存在主题(topic)的分区(partition)中的,所以当 Producer 生产者发送产生一条消息发给 topic 的时候,你如何判断这条消息会存在哪个分区中呢?
这其实就设计到 Kafka 的分区机制了。
分区策略
Kafka 的分区策略指的就是将生产者发送到哪个分区的算法。Kafka 为我们提供了默认的分区策略,同时它也支持你自定义分区策略。
如果要自定义分区策略的话,你需要显示配置生产者端的参数 Partitioner.class,我们可以看一下这个类它位于 org.apache.kafka.clients.producer 包下
public interface Partitioner extends Configurable, Closeable {
public int partition(String topic, Object key, byte[] keyBytes, Object value, byte[] valueBytes, Cluster cluster);
public void close();
default public void onNewBatch(String topic, Cluster cluster, int prevPartition) {} }
Partitioner 类有三个方法,分别来解释一下
- partition(): 这个类有几个参数:
topic,表示需要传递的主题;key表示消息中的键值;keyBytes表示分区中序列化过后的key,byte数组的形式传递;value表示消息的 value 值;valueBytes表示分区中序列化后的值数组;cluster表示当前集群的原数据。Kafka 给你这么多信息,就是希望让你能够充分地利用这些信息对消息进行分区,计算出它要被发送到哪个分区中。 - close() : 继承了
Closeable接口能够实现 close() 方法,在分区关闭时调用。 - onNewBatch(): 表示通知分区程序用来创建新的批次
其中与分区策略息息相关的就是 partition() 方法了,分区策略有下面这几种
顺序轮询
顺序分配,消息是均匀的分配给每个 partition,即每个分区存储一次消息。就像下面这样

上图表示的就是轮询策略,轮训策略是 Kafka Producer 提供的默认策略,如果你不使用指定的轮训策略的话,Kafka 默认会使用顺序轮训策略的方式。
随机轮询
随机轮询简而言之就是随机的向 partition 中保存消息,如下图所示

实现随机分配的代码只需要两行,如下
List<PartitionInfo> partitions = cluster.partitionsForTopic(topic); return ThreadLocalRandom.current().nextInt(partitions.size());
先计算出该主题总的分区数,然后随机地返回一个小于它的正整数。
本质上看随机策略也是力求将数据均匀地打散到各个分区,但从实际表现来看,它要逊于轮询策略,所以如果追求数据的均匀分布,还是使用轮询策略比较好。事实上,随机策略是老版本生产者使用的分区策略,在新版本中已经改为轮询了。
按照 key 进行消息保存
这个策略也叫做 key-ordering 策略,Kafka 中每条消息都会有自己的key,一旦消息被定义了 Key,那么你就可以保证同一个 Key 的所有消息都进入到相同的分区里面,由于每个分区下的消息处理都是有顺序的,故这个策略被称为按消息键保序策略,如下图所示

实现这个策略的 partition 方法同样简单,只需要下面两行代码即可:
List<PartitionInfo> partitions = cluster.partitionsForTopic(topic); return Math.abs(key.hashCode()) % partitions.size();
上面这几种分区策略都是比较基础的策略,除此之外,你还可以自定义分区策略。
生产者压缩机制
压缩一词简单来讲就是一种互换思想,它是一种经典的用 CPU 时间去换磁盘空间或者 I/O 传输量的思想,希望以较小的 CPU 开销带来更少的磁盘占用或更少的网络 I/O 传输。如果你还不了解的话我希望你先读完这篇文章 程序员需要了解的硬核知识之压缩算法,然后你就明白压缩是怎么回事了。
Kafka 压缩是什么
Kafka 的消息分为两层:消息集合 和 消息。一个消息集合中包含若干条日志项,而日志项才是真正封装消息的地方。Kafka 底层的消息日志由一系列消息集合日志项组成。Kafka 通常不会直接操作具体的一条条消息,它总是在消息集合这个层面上进行写入操作。
在 Kafka 中,压缩会发生在两个地方:Kafka Producer 和 Kafka Consumer,为什么启用压缩?说白了就是消息太大,需要变小一点 来使消息发的更快一些。
Kafka Producer 中使用 compression.type 来开启压缩
private Properties properties = new Properties(); properties.put("bootstrap.servers","192.168.1.9:9092"); properties.put("key.serializer","org.apache.kafka.common.serialization.StringSerializer"); properties.put("value.serializer","org.apache.kafka.common.serialization.StringSerializer"); properties.put("compression.type", "gzip");
Producer<String,String> producer = new KafkaProducer<String, String>(properties);
ProducerRecord<String,String> record = new ProducerRecord<String, String>("CustomerCountry","Precision Products","France");
上面代码表明该 Producer 的压缩算法使用的是 GZIP
有压缩必有解压缩,Producer 使用压缩算法压缩消息后并发送给服务器后,由 Consumer 消费者进行解压缩,因为采用的何种压缩算法是随着 key、value 一起发送过去的,所以消费者知道采用何种压缩算法。
Kafka 重要参数配置
在上一篇文章 带你涨姿势的认识一下kafka中,我们主要介绍了一下 kafka 集群搭建的参数,本篇文章我们来介绍一下 Kafka 生产者重要的配置,生产者有很多可配置的参数,在文档里(http://kafka.apache.org/documentation/#producerconfigs)都有说明,我们介绍几个在内存使用、性能和可靠性方面对生产者影响比较大的参数进行说明
key.serializer
用于 key 键的序列化,它实现了 org.apache.kafka.common.serialization.Serializer 接口
value.serializer
用于 value 值的序列化,实现了 org.apache.kafka.common.serialization.Serializer 接口
acks
acks 参数指定了要有多少个分区副本接收消息,生产者才认为消息是写入成功的。此参数对消息丢失的影响较大
- 如果 acks = 0,就表示生产者也不知道自己产生的消息是否被服务器接收了,它才知道它写成功了。如果发送的途中产生了错误,生产者也不知道,它也比较懵逼,因为没有返回任何消息。这就类似于 UDP 的运输层协议,只管发,服务器接受不接受它也不关心。
- 如果 acks = 1,只要集群的 Leader 接收到消息,就会给生产者返回一条消息,告诉它写入成功。如果发送途中造成了网络异常或者 Leader 还没选举出来等其他情况导致消息写入失败,生产者会受到错误消息,这时候生产者往往会再次重发数据。因为消息的发送也分为
同步和异步,Kafka 为了保证消息的高效传输会决定是同步发送还是异步发送。如果让客户端等待服务器的响应(通过调用Future中的get()方法),显然会增加延迟,如果客户端使用回调,就会解决这个问题。 - 如果 acks = all,这种情况下是只有当所有参与复制的节点都收到消息时,生产者才会接收到一个来自服务器的消息。不过,它的延迟比 acks =1 时更高,因为我们要等待不只一个服务器节点接收消息。
buffer.memory
此参数用来设置生产者内存缓冲区的大小,生产者用它缓冲要发送到服务器的消息。如果应用程序发送消息的速度超过发送到服务器的速度,会导致生产者空间不足。这个时候,send() 方法调用要么被阻塞,要么抛出异常,具体取决于 block.on.buffer.null 参数的设置。
compression.type
此参数来表示生产者启用何种压缩算法,默认情况下,消息发送时不会被压缩。该参数可以设置为 snappy、gzip 和 lz4,它指定了消息发送给 broker 之前使用哪一种压缩算法进行压缩。下面是各压缩算法的对比


retries
生产者从服务器收到的错误有可能是临时性的错误(比如分区找不到首领),在这种情况下,reteis 参数的值决定了生产者可以重发的消息次数,如果达到这个次数,生产者会放弃重试并返回错误。默认情况下,生产者在每次重试之间等待 100ms,这个等待参数可以通过 retry.backoff.ms 进行修改。
batch.size
当有多个消息需要被发送到同一个分区时,生产者会把它们放在同一个批次里。该参数指定了一个批次可以使用的内存大小,按照字节数计算。当批次被填满,批次里的所有消息会被发送出去。不过生产者井不一定都会等到批次被填满才发送,任意条数的消息都可能被发送。
client.id
此参数可以是任意的字符串,服务器会用它来识别消息的来源,一般配置在日志里
max.in.flight.requests.per.connection
此参数指定了生产者在收到服务器响应之前可以发送多少消息,它的值越高,就会占用越多的内存,不过也会提高吞吐量。把它设为1 可以保证消息是按照发送的顺序写入服务器。
timeout.ms、request.timeout.ms 和 metadata.fetch.timeout.ms
request.timeout.ms 指定了生产者在发送数据时等待服务器返回的响应时间,metadata.fetch.timeout.ms 指定了生产者在获取元数据(比如目标分区的首领是谁)时等待服务器返回响应的时间。如果等待时间超时,生产者要么重试发送数据,要么返回一个错误。timeout.ms 指定了 broker 等待同步副本返回消息确认的时间,与 asks 的配置相匹配—-如果在指定时间内没有收到同步副本的确认,那么 broker 就会返回一个错误。
max.block.ms
此参数指定了在调用 send() 方法或使用 partitionFor() 方法获取元数据时生产者的阻塞时间当生产者的发送缓冲区已捕,或者没有可用的元数据时,这些方法就会阻塞。在阻塞时间达到 max.block.ms 时,生产者会抛出超时异常。
max.request.size
该参数用于控制生产者发送的请求大小。它可以指能发送的单个消息的最大值,也可以指单个请求里所有消息的总大小。
receive.buffer.bytes 和 send.buffer.bytes
Kafka 是基于 TCP 实现的,为了保证可靠的消息传输,这两个参数分别指定了 TCP Socket 接收和发送数据包的缓冲区的大小。如果它们被设置为 -1,就使用操作系统的默认值。如果生产者或消费者与 broker 处于不同的数据中心,那么可以适当增大这些值。
Kafka Consumer
应用程序使用 KafkaConsumer 从 Kafka 中订阅主题并接收来自这些主题的消息,然后再把他们保存起来。应用程序首先需要创建一个 KafkaConsumer 对象,订阅主题并开始接受消息,验证消息并保存结果。一段时间后,生产者往主题写入的速度超过了应用程序验证数据的速度,这时候该如何处理?如果只使用单个消费者的话,应用程序会跟不上消息生成的速度,就像多个生产者像相同的主题写入消息一样,这时候就需要多个消费者共同参与消费主题中的消息,对消息进行分流处理。
Kafka 消费者从属于消费者群组。一个群组中的消费者订阅的都是相同的主题,每个消费者接收主题一部分分区的消息。下面是一个 Kafka 分区消费示意图

上图中的主题 T1 有四个分区,分别是分区0、分区1、分区2、分区3,我们创建一个消费者群组1,消费者群组中只有一个消费者,它订阅主题T1,接收到 T1 中的全部消息。由于一个消费者处理四个生产者发送到分区的消息,压力有些大,需要帮手来帮忙分担任务,于是就演变为下图

这样一来,消费者的消费能力就大大提高了,但是在某些环境下比如用户产生消息特别多的时候,生产者产生的消息仍旧让消费者吃不消,那就继续增加消费者。

如上图所示,每个分区所产生的消息能够被每个消费者群组中的消费者消费,如果向消费者群组中增加更多的消费者,那么多余的消费者将会闲置,如下图所示

向群组中增加消费者是横向伸缩消费能力的主要方式。总而言之,我们可以通过增加消费组的消费者来进行水平扩展提升消费能力。这也是为什么建议创建主题时使用比较多的分区数,这样可以在消费负载高的情况下增加消费者来提升性能。另外,消费者的数量不应该比分区数多,因为多出来的消费者是空闲的,没有任何帮助。
Kafka 一个很重要的特性就是,只需写入一次消息,可以支持任意多的应用读取这个消息。换句话说,每个应用都可以读到全量的消息。为了使得每个应用都能读到全量消息,应用需要有不同的消费组。对于上面的例子,假如我们新增了一个新的消费组 G2,而这个消费组有两个消费者,那么就演变为下图这样

在这个场景中,消费组 G1 和消费组 G2 都能收到 T1 主题的全量消息,在逻辑意义上来说它们属于不同的应用。
总结起来就是如果应用需要读取全量消息,那么请为该应用设置一个消费组;如果该应用消费能力不足,那么可以考虑在这个消费组里增加消费者。
消费者组和分区重平衡
消费者组是什么
消费者组(Consumer Group)是由一个或多个消费者实例(Consumer Instance)组成的群组,具有可扩展性和可容错性的一种机制。消费者组内的消费者共享一个消费者组ID,这个ID 也叫做 Group ID,组内的消费者共同对一个主题进行订阅和消费,同一个组中的消费者只能消费一个分区的消息,多余的消费者会闲置,派不上用场。
我们在上面提到了两种消费方式
- 一个消费者群组消费一个主题中的消息,这种消费模式又称为
点对点的消费方式,点对点的消费方式又被称为消息队列 - 一个主题中的消息被多个消费者群组共同消费,这种消费模式又称为
发布-订阅模式
消费者重平衡
我们从上面的消费者演变图中可以知道这么一个过程:最初是一个消费者订阅一个主题并消费其全部分区的消息,后来有一个消费者加入群组,随后又有更多的消费者加入群组,而新加入的消费者实例分摊了最初消费者的部分消息,这种把分区的所有权通过一个消费者转到其他消费者的行为称为重平衡,英文名也叫做 Rebalance 。如下图所示

重平衡非常重要,它为消费者群组带来了高可用性 和 伸缩性,我们可以放心的添加消费者或移除消费者,不过在正常情况下我们并不希望发生这样的行为。在重平衡期间,消费者无法读取消息,造成整个消费者组在重平衡的期间都不可用。另外,当分区被重新分配给另一个消费者时,消息当前的读取状态会丢失,它有可能还需要去刷新缓存,在它重新恢复状态之前会拖慢应用程序。
消费者通过向组织协调者(Kafka Broker)发送心跳来维护自己是消费者组的一员并确认其拥有的分区。对于不同不的消费群体来说,其组织协调者可以是不同的。只要消费者定期发送心跳,就会认为消费者是存活的并处理其分区中的消息。当消费者检索记录或者提交它所消费的记录时就会发送心跳。
如果过了一段时间 Kafka 停止发送心跳了,会话(Session)就会过期,组织协调者就会认为这个 Consumer 已经死亡,就会触发一次重平衡。如果消费者宕机并且停止发送消息,组织协调者会等待几秒钟,确认它死亡了才会触发重平衡。在这段时间里,死亡的消费者将不处理任何消息。在清理消费者时,消费者将通知协调者它要离开群组,组织协调者会触发一次重平衡,尽量降低处理停顿。
重平衡是一把双刃剑,它为消费者群组带来高可用性和伸缩性的同时,还有有一些明显的缺点(bug),而这些 bug 到现在社区还无法修改。
重平衡的过程对消费者组有极大的影响。因为每次重平衡过程中都会导致万物静止,参考 JVM 中的垃圾回收机制,也就是 Stop The World ,STW,(引用自《深入理解 Java 虚拟机》中 p76 关于 Serial 收集器的描述):
更重要的是它在进行垃圾收集时,必须暂停其他所有的工作线程。直到它收集结束。
Stop The World这个名字听起来很帅,但这项工作实际上是由虚拟机在后台自动发起并完成的,在用户不可见的情况下把用户正常工作的线程全部停掉,这对很多应用来说都是难以接受的。
也就是说,在重平衡期间,消费者组中的消费者实例都会停止消费,等待重平衡的完成。而且重平衡这个过程很慢……
创建消费者
上面的理论说的有点多,下面就通过代码来讲解一下消费者是如何消费的
在读取消息之前,需要先创建一个 KafkaConsumer 对象。创建 KafkaConsumer 对象与创建 KafkaProducer 对象十分相似 — 把需要传递给消费者的属性放在 properties 对象中,后面我们会着重讨论 Kafka 的一些配置,这里我们先简单的创建一下,使用3个属性就足矣,分别是 bootstrap.server,key.deserializer,value.deserializer 。
这三个属性我们已经用过很多次了,如果你还不是很清楚的话,可以参考 带你涨姿势是认识一下Kafka Producer
还有一个属性是 group.id 这个属性不是必须的,它指定了 KafkaConsumer 是属于哪个消费者群组。创建不属于任何一个群组的消费者也是可以的
Properties properties = new Properties(); properties.put("bootstrap.server","192.168.1.9:9092"); properties.put("key.serializer","org.apache.kafka.common.serialization.StringSerializer"); properties.put("value.serializer","org.apache.kafka.common.serialization.StringSerializer"); KafkaConsumer<String,String> consumer = new KafkaConsumer<>(properties);
主题订阅
创建好消费者之后,下一步就开始订阅主题了。subscribe() 方法接受一个主题列表作为参数,使用起来比较简单
consumer.subscribe(Collections.singletonList("customerTopic"));
为了简单我们只订阅了一个主题 customerTopic,参数传入的是一个正则表达式,正则表达式可以匹配多个主题,如果有人创建了新的主题,并且主题的名字与正则表达式相匹配,那么会立即触发一次重平衡,消费者就可以读取新的主题。
要订阅所有与 test 相关的主题,可以这样做
consumer.subscribe("test.*");
轮询
我们知道,Kafka 是支持订阅/发布模式的,生产者发送数据给 Kafka Broker,那么消费者是如何知道生产者发送了数据呢?其实生产者产生的数据消费者是不知道的,KafkaConsumer 采用轮询的方式定期去 Kafka Broker 中进行数据的检索,如果有数据就用来消费,如果没有就再继续轮询等待,下面是轮询等待的具体实现
try { while (true) { ConsumerRecords<String, String> records = consumer.poll(Duration.ofSeconds(100)); for (ConsumerRecord<String, String> record : records) { int updateCount = 1; if (map.containsKey(record.value())) { updateCount = (int) map.get(record.value() + 1); } map.put(record.value(), updateCount); } } }finally { consumer.close(); }
- 这是一个无限循环。消费者实际上是一个长期运行的应用程序,它通过轮询的方式向 Kafka 请求数据。
- 第三行代码非常重要,Kafka 必须定期循环请求数据,否则就会认为该 Consumer 已经挂了,会触发重平衡,它的分区会移交给群组中的其它消费者。传给
poll()方法的是一个超市时间,用java.time.Duration类来表示,如果该参数被设置为 0 ,poll() 方法会立刻返回,否则就会在指定的毫秒数内一直等待 broker 返回数据。 - poll() 方法会返回一个记录列表。每条记录都包含了记录所属主题的信息,记录所在分区的信息、记录在分区中的偏移量,以及记录的键值对。我们一般会遍历这个列表,逐条处理每条记录。
- 在退出应用程序之前使用
close()方法关闭消费者。网络连接和 socket 也会随之关闭,并立即触发一次重平衡,而不是等待群组协调器发现它不再发送心跳并认定它已经死亡。
线程安全性
在同一个群组中,我们无法让一个线程运行多个消费者,也无法让多个线程安全的共享一个消费者。按照规则,一个消费者使用一个线程,如果一个消费者群组中多个消费者都想要运行的话,那么必须让每个消费者在自己的线程中运行,可以使用 Java 中的
ExecutorService启动多个消费者进行进行处理。
消费者配置
到目前为止,我们学习了如何使用消费者 API,不过只介绍了几个最基本的属性,Kafka 文档列出了所有与消费者相关的配置说明。大部分参数都有合理的默认值,一般不需要修改它们,下面我们就来介绍一下这些参数。
- fetch.min.bytes
该属性指定了消费者从服务器获取记录的最小字节数。broker 在收到消费者的数据请求时,如果可用的数据量小于 fetch.min.bytes 指定的大小,那么它会等到有足够的可用数据时才把它返回给消费者。这样可以降低消费者和 broker 的工作负载,因为它们在主题使用频率不是很高的时候就不用来回处理消息。如果没有很多可用数据,但消费者的 CPU 使用率很高,那么就需要把该属性的值设得比默认值大。如果消费者的数量比较多,把该属性的值调大可以降低 broker 的工作负载。
- fetch.max.wait.ms
我们通过上面的 fetch.min.bytes 告诉 Kafka,等到有足够的数据时才会把它返回给消费者。而 fetch.max.wait.ms 则用于指定 broker 的等待时间,默认是 500 毫秒。如果没有足够的数据流入 kafka 的话,消费者获取的最小数据量要求就得不到满足,最终导致 500 毫秒的延迟。如果要降低潜在的延迟,就可以把参数值设置的小一些。如果 fetch.max.wait.ms 被设置为 100 毫秒的延迟,而 fetch.min.bytes 的值设置为 1MB,那么 Kafka 在收到消费者请求后,要么返回 1MB 的数据,要么在 100 ms 后返回所有可用的数据。就看哪个条件首先被满足。
- max.partition.fetch.bytes
该属性指定了服务器从每个分区里返回给消费者的最大字节数。它的默认值时 1MB,也就是说,KafkaConsumer.poll() 方法从每个分区里返回的记录最多不超过 max.partition.fetch.bytes 指定的字节。如果一个主题有20个分区和5个消费者,那么每个消费者需要至少4 MB的可用内存来接收记录。在为消费者分配内存时,可以给它们多分配一些,因为如果群组里有消费者发生崩溃,剩下的消费者需要处理更多的分区。max.partition.fetch.bytes 的值必须比 broker 能够接收的最大消息的字节数(通过 max.message.size 属性配置大),否则消费者可能无法读取这些消息,导致消费者一直挂起重试。 在设置该属性时,另外一个考量的因素是消费者处理数据的时间。消费者需要频繁的调用 poll() 方法来避免会话过期和发生分区再平衡,如果单次调用poll() 返回的数据太多,消费者需要更多的时间进行处理,可能无法及时进行下一个轮询来避免会话过期。如果出现这种情况,可以把 max.partition.fetch.bytes 值改小,或者延长会话过期时间。
- session.timeout.ms
这个属性指定了消费者在被认为死亡之前可以与服务器断开连接的时间,默认是 3s。如果消费者没有在 session.timeout.ms 指定的时间内发送心跳给群组协调器,就会被认定为死亡,协调器就会触发重平衡。把它的分区分配给消费者群组中的其它消费者,此属性与 heartbeat.interval.ms 紧密相关。heartbeat.interval.ms 指定了 poll() 方法向群组协调器发送心跳的频率,session.timeout.ms 则指定了消费者可以多久不发送心跳。所以,这两个属性一般需要同时修改,heartbeat.interval.ms 必须比 session.timeout.ms 小,一般是 session.timeout.ms 的三分之一。如果 session.timeout.ms 是 3s,那么 heartbeat.interval.ms 应该是 1s。把 session.timeout.ms 值设置的比默认值小,可以更快地检测和恢复崩愤的节点,不过长时间的轮询或垃圾收集可能导致非预期的重平衡。把该属性的值设置得大一些,可以减少意外的重平衡,不过检测节点崩溃需要更长的时间。
- auto.offset.reset
该属性指定了消费者在读取一个没有偏移量的分区或者偏移量无效的情况下的该如何处理。它的默认值是 latest,意思指的是,在偏移量无效的情况下,消费者将从最新的记录开始读取数据。另一个值是 earliest,意思指的是在偏移量无效的情况下,消费者将从起始位置处开始读取分区的记录。
- enable.auto.commit
我们稍后将介绍几种不同的提交偏移量的方式。该属性指定了消费者是否自动提交偏移量,默认值是 true,为了尽量避免出现重复数据和数据丢失,可以把它设置为 false,由自己控制何时提交偏移量。如果把它设置为 true,还可以通过 auto.commit.interval.ms 属性来控制提交的频率
- partition.assignment.strategy
我们知道,分区会分配给群组中的消费者。PartitionAssignor 会根据给定的消费者和主题,决定哪些分区应该被分配给哪个消费者,Kafka 有两个默认的分配策略Range 和 RoundRobin
- client.id
该属性可以是任意字符串,broker 用他来标识从客户端发送过来的消息,通常被用在日志、度量指标和配额中
- max.poll.records
该属性用于控制单次调用 call() 方法能够返回的记录数量,可以帮你控制在轮询中需要处理的数据量。
- receive.buffer.bytes 和 send.buffer.bytes
socket 在读写数据时用到的 TCP 缓冲区也可以设置大小。如果它们被设置为 -1,就使用操作系统默认值。如果生产者或消费者与 broker 处于不同的数据中心内,可以适当增大这些值,因为跨数据中心的网络一般都有比较高的延迟和比较低的带宽。
提交和偏移量的概念
特殊偏移
我们上面提到,消费者在每次调用poll() 方法进行定时轮询的时候,会返回由生产者写入 Kafka 但是还没有被消费者消费的记录,因此我们可以追踪到哪些记录是被群组里的哪个消费者读取的。消费者可以使用 Kafka 来追踪消息在分区中的位置(偏移量)
消费者会向一个叫做 _consumer_offset 的特殊主题中发送消息,这个主题会保存每次所发送消息中的分区偏移量,这个主题的主要作用就是消费者触发重平衡后记录偏移使用的,消费者每次向这个主题发送消息,正常情况下不触发重平衡,这个主题是不起作用的,当触发重平衡后,消费者停止工作,每个消费者可能会分到对应的分区,这个主题就是让消费者能够继续处理消息所设置的。
如果提交的偏移量小于客户端最后一次处理的偏移量,那么位于两个偏移量之间的消息就会被重复处理

如果提交的偏移量大于最后一次消费时的偏移量,那么处于两个偏移量中间的消息将会丢失

既然_consumer_offset 如此重要,那么它的提交方式是怎样的呢?下面我们就来说一下####提交方式
KafkaConsumer API 提供了多种方式来提交偏移量
自动提交
最简单的方式就是让消费者自动提交偏移量。如果 enable.auto.commit 被设置为true,那么每过 5s,消费者会自动把从 poll() 方法轮询到的最大偏移量提交上去。提交时间间隔由 auto.commit.interval.ms 控制,默认是 5s。与消费者里的其他东西一样,自动提交也是在轮询中进行的。消费者在每次轮询中会检查是否提交该偏移量了,如果是,那么就会提交从上一次轮询中返回的偏移量。
提交当前偏移量
把 auto.commit.offset 设置为 false,可以让应用程序决定何时提交偏移量。使用 commitSync() 提交偏移量。这个 API 会提交由 poll() 方法返回的最新偏移量,提交成功后马上返回,如果提交失败就抛出异常。
commitSync() 将会提交由 poll() 返回的最新偏移量,如果处理完所有记录后要确保调用了 commitSync(),否则还是会有丢失消息的风险,如果发生了在均衡,从最近一批消息到发生在均衡之间的所有消息都将被重复处理。
异步提交
异步提交 commitAsync() 与同步提交 commitSync() 最大的区别在于异步提交不会进行重试,同步提交会一致进行重试。
同步和异步组合提交
一般情况下,针对偶尔出现的提交失败,不进行重试不会有太大的问题,因为如果提交失败是因为临时问题导致的,那么后续的提交总会有成功的。但是如果在关闭消费者或再均衡前的最后一次提交,就要确保提交成功。
因此,在消费者关闭之前一般会组合使用commitAsync和commitSync提交偏移量。
提交特定的偏移量
消费者API允许调用 commitSync() 和 commitAsync() 方法时传入希望提交的 partition 和 offset 的 map,即提交特定的偏移量。
# 看完你就明白的锁系列之自旋锁-Java面试题
自旋锁的提出背景
由于在多处理器环境中某些资源的有限性,有时需要互斥访问(mutual exclusion),这时候就需要引入锁的概念,只有获取了锁的线程才能够对资源进行访问,由于多线程的核心是CPU的时间分片,所以同一时刻只能有一个线程获取到锁。那么就面临一个问题,那么没有获取到锁的线程应该怎么办?
通常有两种处理方式:一种是没有获取到锁的线程就一直循环等待判断该资源是否已经释放锁,这种锁叫做自旋锁,它不用将线程阻塞起来(NON-BLOCKING);还有一种处理方式就是把自己阻塞起来,等待重新调度请求,这种叫做互斥锁。
什么是自旋锁
自旋锁的定义:当一个线程尝试去获取某一把锁的时候,如果这个锁此时已经被别人获取(占用),那么此线程就无法获取到这把锁,该线程将会等待,间隔一段时间后会再次尝试获取。这种采用循环加锁 -> 等待的机制被称为自旋锁(spinlock)。

自旋锁的原理
自旋锁的原理比较简单,如果持有锁的线程能在短时间内释放锁资源,那么那些等待竞争锁的线程就不需要做内核态和用户态之间的切换进入阻塞状态,它们只需要等一等(自旋),等到持有锁的线程释放锁之后即可获取,这样就避免了用户进程和内核切换的消耗。
因为自旋锁避免了操作系统进程调度和线程切换,所以自旋锁通常适用在时间比较短的情况下。由于这个原因,操作系统的内核经常使用自旋锁。但是,如果长时间上锁的话,自旋锁会非常耗费性能,它阻止了其他线程的运行和调度。线程持有锁的时间越长,则持有该锁的线程将被 OS(Operating System) 调度程序中断的风险越大。如果发生中断情况,那么其他线程将保持旋转状态(反复尝试获取锁),而持有该锁的线程并不打算释放锁,这样导致的是结果是无限期推迟,直到持有锁的线程可以完成并释放它为止。
解决上面这种情况一个很好的方式是给自旋锁设定一个自旋时间,等时间一到立即释放自旋锁。自旋锁的目的是占着CPU资源不进行释放,等到获取锁立即进行处理。但是如何去选择自旋时间呢?如果自旋执行时间太长,会有大量的线程处于自旋状态占用 CPU 资源,进而会影响整体系统的性能。因此自旋的周期选的额外重要!JDK在1.6 引入了适应性自旋锁,适应性自旋锁意味着自旋时间不是固定的了,而是由前一次在同一个锁上的自旋时间以及锁拥有的状态来决定,基本认为一个线程上下文切换的时间是最佳的一个时间。
自旋锁的优缺点
自旋锁尽可能的减少线程的阻塞,这对于锁的竞争不激烈,且占用锁时间非常短的代码块来说性能能大幅度的提升,因为自旋的消耗会小于线程阻塞挂起再唤醒的操作的消耗,这些操作会导致线程发生两次上下文切换!
但是如果锁的竞争激烈,或者持有锁的线程需要长时间占用锁执行同步块,这时候就不适合使用自旋锁了,因为自旋锁在获取锁前一直都是占用 cpu 做无用功,占着 XX 不 XX,同时有大量线程在竞争一个锁,会导致获取锁的时间很长,线程自旋的消耗大于线程阻塞挂起操作的消耗,其它需要 cpu 的线程又不能获取到 cpu,造成 cpu 的浪费。所以这种情况下我们要关闭自旋锁。
自旋锁的实现
下面我们用Java 代码来实现一个简单的自旋锁
public class SpinLockTest {
private AtomicBoolean available = new AtomicBoolean(false);
public void lock(){
// 循环检测尝试获取锁
while (!tryLock()){
// doSomething...
}
}
public boolean tryLock(){
// 尝试获取锁,成功返回true,失败返回false
return available.compareAndSet(false,true);
}
public void unLock(){
if(!available.compareAndSet(true,false)){
throw new RuntimeException("释放锁失败");
}
}
}
这种简单的自旋锁有一个问题:无法保证多线程竞争的公平性。对于上面的SpinlockTest,当多个线程想要获取锁时,谁最先将available设为false谁就能最先获得锁,这可能会造成某些线程一直都未获取到锁造成线程饥饿。就像我们下课后蜂拥的跑向食堂,下班后蜂拥地挤向地铁,通常我们会采取排队的方式解决这样的问题,类似地,我们把这种锁叫排队自旋锁(QueuedSpinlock)。计算机科学家们使用了各种方式来实现排队自旋锁,如TicketLock,MCSLock,CLHLock。接下来我们分别对这几种锁做个大致的介绍。
TicketLock
在计算机科学领域中,TicketLock 是一种同步机制或锁定算法,它是一种自旋锁,它使用ticket 来控制线程执行顺序。
就像票据队列管理系统一样。面包店或者服务机构(例如银行)都会使用这种方式来为每个先到达的顾客记录其到达的顺序,而不用每次都进行排队。通常,这种地点都会有一个分配器(叫号器,挂号器等等都行),先到的人需要在这个机器上取出自己现在排队的号码,这个号码是按照自增的顺序进行的,旁边还会有一个标牌显示的是正在服务的标志,这通常是代表目前正在服务的队列号,当前的号码完成服务后,标志牌会显示下一个号码可以去服务了。
像上面系统一样,TicketLock 是基于先进先出(FIFO) 队列的机制。它增加了锁的公平性,其设计原则如下:TicketLock 中有两个 int 类型的数值,开始都是0,第一个值是队列ticket(队列票据), 第二个值是 出队(票据)。队列票据是线程在队列中的位置,而出队票据是现在持有锁的票证的队列位置。可能有点模糊不清,简单来说,就是队列票据是你取票号的位置,出队票据是你距离叫号的位置。现在应该明白一些了吧。
当叫号叫到你的时候,不能有相同的号码同时办业务,必须只有一个人可以去办,办完后,叫号机叫到下一个人,这就叫做原子性。你在办业务的时候不能被其他人所干扰,而且不可能会有两个持有相同号码的人去同时办业务。然后,下一个人看自己的号是否和叫到的号码保持一致,如果一致的话,那么就轮到你去办业务,否则只能继续等待。上面这个流程的关键点在于,每个办业务的人在办完业务之后,他必须丢弃自己的号码,叫号机才能继续叫到下面的人,如果这个人没有丢弃这个号码,那么其他人只能继续等待。下面来实现一下这个票据排队方案
public class TicketLock {
// 队列票据(当前排队号码)
private AtomicInteger queueNum = new AtomicInteger();
// 出队票据(当前需等待号码)
private AtomicInteger dueueNum = new AtomicInteger();
// 获取锁:如果获取成功,返回当前线程的排队号
public int lock(){
int currentTicketNum = dueueNum.incrementAndGet();
while (currentTicketNum != queueNum.get()){
// doSomething...
}
return currentTicketNum;
}
// 释放锁:传入当前排队的号码
public void unLock(int ticketNum){
queueNum.compareAndSet(ticketNum,ticketNum + 1);
}
}
每次叫号机在叫号的时候,都会判断自己是不是被叫的号,并且每个人在办完业务的时候,叫号机根据在当前号码的基础上 + 1,让队列继续往前走。
但是上面这个设计是有问题的,因为获得自己的号码之后,是可以对号码进行更改的,这就造成系统紊乱,锁不能及时释放。这时候就需要有一个能确保每个人按会着自己号码排队办业务的角色,在得知这一点之后,我们重新设计一下这个逻辑
public class TicketLock2 {
// 队列票据(当前排队号码)
private AtomicInteger queueNum = new AtomicInteger();
// 出队票据(当前需等待号码)
private AtomicInteger dueueNum = new AtomicInteger();
private ThreadLocal<Integer> ticketLocal = new ThreadLocal<>();
public void lock(){
int currentTicketNum = dueueNum.incrementAndGet();
// 获取锁的时候,将当前线程的排队号保存起来
ticketLocal.set(currentTicketNum);
while (currentTicketNum != queueNum.get()){
// doSomething...
}
}
// 释放锁:从排队缓冲池中取
public void unLock(){
Integer currentTicket = ticketLocal.get();
queueNum.compareAndSet(currentTicket,currentTicket + 1);
}
}
这次就不再需要返回值,办业务的时候,要将当前的这一个号码缓存起来,在办完业务后,需要释放缓存的这条票据。
缺点
TicketLock 虽然解决了公平性的问题,但是多处理器系统上,每个进程/线程占用的处理器都在读写同一个变量queueNum ,每次读写操作都必须在多个处理器缓存之间进行缓存同步,这会导致繁重的系统总线和内存的流量,大大降低系统整体的性能。
为了解决这个问题,MCSLock 和 CLHLock 应运而生。
CLHLock
上面说到TicketLock 是基于队列的,那么 CLHLock 就是基于链表设计的,CLH的发明人是:Craig,Landin and Hagersten,用它们各自的字母开头命名。CLH 是一种基于链表的可扩展,高性能,公平的自旋锁,申请线程只能在本地变量上自旋,它会不断轮询前驱的状态,如果发现前驱释放了锁就结束自旋。
public class CLHLock {
public static class CLHNode{
private volatile boolean isLocked = true;
}
// 尾部节点
private volatile CLHNode tail;
private static final ThreadLocal<CLHNode> LOCAL = new ThreadLocal<>();
private static final AtomicReferenceFieldUpdater<CLHLock,CLHNode> UPDATER =
AtomicReferenceFieldUpdater.newUpdater(CLHLock.class,CLHNode.class,"tail");
public void lock(){
// 新建节点并将节点与当前线程保存起来
CLHNode node = new CLHNode();
LOCAL.set(node);
// 将新建的节点设置为尾部节点,并返回旧的节点(原子操作),这里旧的节点实际上就是当前节点的前驱节点
CLHNode preNode = UPDATER.getAndSet(this,node);
if(preNode != null){
// 前驱节点不为null表示当锁被其他线程占用,通过不断轮询判断前驱节点的锁标志位等待前驱节点释放锁
while (preNode.isLocked){
}
preNode = null;
LOCAL.set(node);
}
// 如果不存在前驱节点,表示该锁没有被其他线程占用,则当前线程获得锁
}
public void unlock() {
// 获取当前线程对应的节点
CLHNode node = LOCAL.get();
// 如果tail节点等于node,则将tail节点更新为null,同时将node的lock状态职位false,表示当前线程释放了锁
if (!UPDATER.compareAndSet(this, node, null)) {
node.isLocked = false;
}
node = null;
}
}
MCSLock
MCS Spinlock 是一种基于链表的可扩展、高性能、公平的自旋锁,申请线程只在本地变量上自旋,直接前驱负责通知其结束自旋,从而极大地减少了不必要的处理器缓存同步的次数,降低了总线和内存的开销。MCS 来自于其发明人名字的首字母: John Mellor-Crummey和Michael Scott。
public class MCSLock {
public static class MCSNode {
volatile MCSNode next;
volatile boolean isLocked = true;
}
private static final ThreadLocal<MCSNode> NODE = new ThreadLocal<>();
// 队列
@SuppressWarnings("unused")
private volatile MCSNode queue;
private static final AtomicReferenceFieldUpdater<MCSLock,MCSNode> UPDATE =
AtomicReferenceFieldUpdater.newUpdater(MCSLock.class,MCSNode.class,"queue");
public void lock(){
// 创建节点并保存到ThreadLocal中
MCSNode currentNode = new MCSNode();
NODE.set(currentNode);
// 将queue设置为当前节点,并且返回之前的节点
MCSNode preNode = UPDATE.getAndSet(this, currentNode);
if (preNode != null) {
// 如果之前节点不为null,表示锁已经被其他线程持有
preNode.next = currentNode;
// 循环判断,直到当前节点的锁标志位为false
while (currentNode.isLocked) {
}
}
}
public void unlock() {
MCSNode currentNode = NODE.get();
// next为null表示没有正在等待获取锁的线程
if (currentNode.next == null) {
// 更新状态并设置queue为null
if (UPDATE.compareAndSet(this, currentNode, null)) {
// 如果成功了,表示queue==currentNode,即当前节点后面没有节点了
return;
} else {
// 如果不成功,表示queue!=currentNode,即当前节点后面多了一个节点,表示有线程在等待
// 如果当前节点的后续节点为null,则需要等待其不为null(参考加锁方法)
while (currentNode.next == null) {
}
}
} else {
// 如果不为null,表示有线程在等待获取锁,此时将等待线程对应的节点锁状态更新为false,同时将当前线程的后继节点设为null
currentNode.next.isLocked = false;
currentNode.next = null;
}
}
}
CLHLock 和 MCSLock
- 都是基于链表,不同的是CLHLock是基于隐式链表,没有真正的后续节点属性,MCSLock是显示链表,有一个指向后续节点的属性。
- 将获取锁的线程状态借助节点(node)保存,每个线程都有一份独立的节点,这样就解决了TicketLock多处理器缓存同步的问题。
总结
此篇文章我们主要讲述了自旋锁的提出背景,自旋锁是为了提高资源的使用频率而出现的一种锁,自旋锁说的是线程获取锁的时候,如果锁被其他线程持有,则当前线程将循环等待,直到获取到锁。
自旋锁在等待期间不会睡眠或者释放自己的线程。自旋锁不适用于长时间持有CPU的情况,这会加剧系统的负担,为了解决这种情况,需要设定自旋周期,那么自旋周期的设定也是一门学问。
还提到了自旋锁本身无法保证公平性,那么为了保证公平性又引出了TicketLock ,TicketLock 是采用排队叫号的机制来实现的一种公平锁,但是它每次读写操作都必须在多个处理器缓存之间进行缓存同步,这会导致繁重的系统总线和内存的流量,大大降低系统整体的性能。
所以我们又引出了CLHLock和MCSLock,CLHLock和MCSLock通过链表的方式避免了减少了处理器缓存同步,极大的提高了性能,区别在于CLHLock是通过轮询其前驱节点的状态,而MCS则是查看当前节点的锁状态。
# 并发编程入门-Java面试题
并发历史
在计算机最早期的时候,没有操作系统,执行程序只需要一种方式,那就是从头到尾依次执行。任何资源都会为这个程序服务,在计算机使用某些资源时,其他资源就会空闲,就会存在 浪费资源 的情况。
这里说的浪费资源指的是资源空闲,没有充分使用的情况。
操作系统的出现为我们的程序带来了 并发性,操作系统使我们的程序能够同时运行多个程序,一个程序就是一个进程,也就相当于同时运行多个进程。
操作系统是一个并发系统,并发性是操作系统非常重要的特征,操作系统具有同时处理和调度多个程序的能力,比如多个 I/O 设备同时在输入输出;设备 I/O 和 CPU 计算同时进行;内存中同时有多个系统和用户程序被启动交替、穿插地执行。操作系统在协调和分配进程的同时,操作系统也会为不同进程分配不同的资源。
操作系统实现多个程序同时运行解决了单个程序无法做到的问题,主要有下面三点
资源利用率,我们上面说到,单个进程存在资源浪费的情况,举个例子,当你在为某个文件夹赋予权限的时候,输入程序无法接受外部的输入字符,只有等到权限赋予完毕后才能接受外部输入。总的来讲,就是在等待程序时无法执行其他工作。如果在等待程序时可以运行另一个程序,那么将会大大提高资源的利用率。(资源并不会觉得累)因为它不会划水~公平性,不同的用户和程序都能够使用计算机上的资源。一种高效的运行方式是为不同的程序划分时间片来使用资源,但是有一点需要注意,操作系统可以决定不同进程的优先级。虽然每个进程都有能够公平享有资源的权利,但是当有一个进程释放资源后的同时有一个优先级更高的进程抢夺资源,就会造成优先级低的进程无法获得资源,进而导致进程饥饿。便利性,单个进程是是不用通信的,通信的本质就是信息交换,及时进行信息交换能够避免信息孤岛,做重复性的工作;任何并发能做的事情,单进程也能够实现,只不过这种方式效率很低,它是一种顺序性的。
但是,顺序编程(也称为串行编程)也不是一无是处的,串行编程的优势在于其直观性和简单性,客观来讲,串行编程更适合我们人脑的思考方式,但是我们并不会满足于顺序编程,we want it more!!! 。资源利用率、公平性和便利性促使着进程出现的同时,也促使着线程的出现。
如果你还不是很理解进程和线程的区别的话,那么我就以我多年操作系统的经验(吹牛逼,实则半年)来为你解释一下:进程是一个应用程序,而线程是应用程序中的一条顺序流。

进程中会有多个线程来完成一些任务,这些任务有可能相同有可能不同。每个线程都有自己的执行顺序。

每个线程都有自己的栈空间,这是线程私有的,还有一些其他线程内部的和线程共享的资源,如下所示。
在计算机中,一般堆栈指的就是栈,而堆指的才是堆
线程会共享进程范围内的资源,例如内存和文件句柄,但是每个线程也有自己私有的内容,比如程序计数器、栈以及局部变量。下面汇总了进程和线程共享资源的区别

线程是一种轻量级的进程,轻量级体现在线程的创建和销毁要比进程的开销小很多。
注意:任何比较都是相对的。
在大多数现代操作系统中,都以线程为基本的调度单位,所以我们的视角着重放在对线程的探究。
线程
什么是多线程
多线程意味着你能够在同一个应用程序中运行多个线程,我们知道,指令是在 CPU 中执行的,多线程应用程序就像是具有多个 CPU 在同时执行应用程序的代码。

其实这是一种假象,线程数量并不等于 CPU 数量,单个 CPU 将在多个线程之间共享 CPU 的时间片,在给定的时间片内执行每个线程之间的切换,每个线程也可以由不同的 CPU 执行,如下图所示

并发和并行的关系
并发意味着应用程序会执行多个的任务,但是如果计算机只有一个 CPU 的话,那么应用程序无法同时执行多个的任务,但是应用程序又需要执行多个任务,所以计算机在开始执行下一个任务之前,它并没有完成当前的任务,只是把状态暂存,进行任务切换,CPU 在多个任务之间进行切换,直到任务完成。如下图所示

并行是指应用程序将其任务分解为较小的子任务,这些子任务可以并行处理,例如在多个CPU上同时进行。

优势和劣势
合理使用线程是一门艺术,合理编写一道准确无误的多线程程序更是一门艺术,如果线程使用得当,能够有效的降低程序的开发和维护成本。
Java 很好的在用户空间实现了开发工具包,并在内核空间提供系统调用来支持多线程编程,Java 支持了丰富的类库 java.util.concurrent 和跨平台的内存模型,同时也提高了开发人员的门槛,并发一直以来是一个高阶的主题,但是现在,并发也成为了主流开发人员的必备素质。
虽然线程带来的好处很多,但是编写正确的多线程(并发)程序是一件极困难的事情,并发程序的 Bug 往往会诡异地出现又诡异的消失,在当你认为没有问题的时候它就出现了,难以定位 是并发程序的一个特征,所以在此基础上你需要有扎实的并发基本功。那么,并发为什么会出现呢?
并发为什么会出现
计算机世界的快速发展离不开 CPU、内存和 I/O 设备的高速发展,但是这三者一直存在速度差异性问题,我们可以从存储器的层次结构可以看出

CPU 内部是寄存器的构造,寄存器的访问速度要高于高速缓存,高速缓存的访问速度要高于内存,最慢的是磁盘访问。
程序是在内存中执行的,程序里大部分语句都要访问内存,有些还需要访问 I/O 设备,根据漏桶理论来说,程序整体的性能取决于最慢的操作也就是磁盘访问速度。
因为 CPU 速度太快了,所以为了发挥 CPU 的速度优势,平衡这三者的速度差异,计算机体系机构、操作系统、编译程序都做出了贡献,主要体现为:
- CPU 使用缓存来中和和内存的访问速度差异
- 操作系统提供进程和线程调度,让 CPU 在执行指令的同时分时复用线程,让内存和磁盘不断交互,不同的
CPU 时间片能够执行不同的任务,从而均衡这三者的差异 - 编译程序提供优化指令的执行顺序,让缓存能够合理的使用
我们在享受这些便利的同时,多线程也为我们带来了挑战,下面我们就来探讨一下并发问题为什么会出现以及多线程的源头是什么
线程带来的安全性问题
线程安全性是非常复杂的,在没有采用同步机制的情况下,多个线程中的执行操作往往是不可预测的,这也是多线程带来的挑战之一,下面我们给出一段代码,来看看安全性问题体现在哪
public class TSynchronized implements Runnable{
static int i = 0;
public void increase(){
i++;
}
@Override
public void run() {
for(int i = 0;i < 1000;i++) {
increase();
}
}
public static void main(String[] args) throws InterruptedException {
TSynchronized tSynchronized = new TSynchronized();
Thread aThread = new Thread(tSynchronized);
Thread bThread = new Thread(tSynchronized);
aThread.start();
bThread.start();
System.out.println("i = " + i);
}
}
这段程序输出后会发现,i 的值每次都不一样,这不符合我们的预测,那么为什么会出现这种情况呢?我们先来分析一下程序的运行过程。
TSynchronized 实现了 Runnable 接口,并定义了一个静态变量 i,然后在 increase 方法中每次都增加 i 的值,在其实现的 run 方法中进行循环调用,共执行 1000 次。
可见性问题
在单核 CPU 时代,所有的线程共用一个 CPU,CPU 缓存和内存的一致性问题容易解决,CPU 和 内存之间
如果用图来表示的话我想会是下面这样

在多核时代,因为有多核的存在,每个核都能够独立的运行一个线程,每颗 CPU 都有自己的缓存,这时 CPU 缓存与内存的数据一致性就没那么容易解决了,当多个线程在不同的 CPU 上执行时,这些线程操作的是不同的 CPU 缓存

因为 i 是静态变量,没有经过任何线程安全措施的保护,多个线程会并发修改 i 的值,所以我们认为 i 不是线程安全的,导致这种结果的出现是由于 aThread 和 bThread 中读取的 i 值彼此不可见,所以这是由于 可见性 导致的线程安全问题。
原子性问题
看起来很普通的一段程序却因为两个线程 aThread 和 bThread 交替执行产生了不同的结果。但是根源不是因为创建了两个线程导致的,多线程只是产生线程安全性的必要条件,最终的根源出现在 i++ 这个操作上。
这个操作怎么了?这不就是一个给 i 递增的操作吗?也就是 i++ => i = i + 1,这怎么就会产生问题了?
因为 i++ 不是一个 原子性 操作,仔细想一下,i++ 其实有三个步骤,读取 i 的值,执行 i + 1 操作,然后把 i + 1 得出的值重新赋给 i(将结果写入内存)。
当两个线程开始运行后,每个线程都会把 i 的值读入到 CPU 缓存中,然后执行 + 1 操作,再把 + 1 之后的值写入内存。因为线程间都有各自的虚拟机栈和程序计数器,他们彼此之间没有数据交换,所以当 aThread 执行 + 1 操作后,会把数据写入到内存,同时 bThread 执行 + 1 操作后,也会把数据写入到内存,因为 CPU 时间片的执行周期是不确定的,所以会出现当 aThread 还没有把数据写入内存时,bThread 就会读取内存中的数据,然后执行 + 1操作,再写回内存,从而覆盖 i 的值,导致 aThread 所做的努力白费。

为什么上面的线程切换会出现问题呢?
我们先来考虑一下正常情况下(即不会出现线程安全性问题的情况下)两条线程的执行顺序

可以看到,当 aThread 在执行完整个 i++ 的操作后,操作系统对线程进行切换,由 aThread -> bThread,这是最理想的操作,一旦操作系统在任意 读取/增加/写入 阶段产生线程切换,都会产生线程安全问题。例如如下图所示

最开始的时候,内存中 i = 0,aThread 读取内存中的值并把它读取到自己的寄存器中,执行 +1 操作,此时发生线程切换,bThread 开始执行,读取内存中的值并把它读取到自己的寄存器中,此时发生线程切换,线程切换至 aThread 开始运行,aThread 把自己寄存器的值写回到内存中,此时又发生线程切换,由 aThread -> bThread,线程 bThread 把自己寄存器的值 +1 然后写回内存,写完后内存中的值不是 2 ,而是 1, 内存中的 i 值被覆盖了。
我们上面提到 原子性 这个概念,那么什么是原子性呢?
并发编程的原子性操作是完全独立于任何其他进程运行的操作,原子操作多用于现代操作系统和并行处理系统中。
原子操作通常在内核中使用,因为内核是操作系统的主要组件。但是,大多数计算机硬件,编译器和库也提供原子性操作。
在加载和存储中,计算机硬件对存储器字进行读取和写入。为了对值进行匹配、增加或者减小操作,一般通过原子操作进行。在原子操作期间,处理器可以在同一数据传输期间完成读取和写入。 这样,其他输入/输出机制或处理器无法执行存储器读取或写入任务,直到原子操作完成为止。
简单来讲,就是原子操作要么全部执行,要么全部不执行。数据库事务的原子性也是基于这个概念演进的。
有序性问题
在并发编程中还有带来让人非常头疼的 有序性 问题,有序性顾名思义就是顺序性,在计算机中指的就是指令的先后执行顺序。一个非常显而易见的例子就是 JVM 中的类加载

这是一个 JVM 加载类的过程图,也称为类的生命周期,类从加载到 JVM 到卸载一共会经历五个阶段 加载、连接、初始化、使用、卸载。这五个过程的执行顺序是一定的,但是在连接阶段,也会分为三个过程,即 验证、准备、解析 阶段,这三个阶段的执行顺序不是确定的,通常交叉进行,在一个阶段的执行过程中会激活另一个阶段。
有序性问题一般是编译器带来的,编译器有的时候确实是 好心办坏事,它为了优化系统性能,往往更换指令的执行顺序。
活跃性问题
多线程还会带来活跃性问题,如何定义活跃性问题呢?活跃性问题关注的是 某件事情是否会发生。
如果一组线程中的每个线程都在等待一个事件的发生,而这个事件只能由该组中正在等待的线程触发,这种情况会导致死锁。
简单一点来表述一下,就是每个线程都在等待其他线程释放资源,而其他资源也在等待每个线程释放资源,这样没有线程抢先释放自己的资源,这种情况会产生死锁,所有线程都会无限的等待下去。
死锁的必要条件
造成死锁的原因有四个,破坏其中一个即可破坏死锁
- 互斥条件:指进程对所分配到的资源进行排它性使用,即在一段时间内某资源只由一个进程占用。如果此时还有其它进程请求资源,则请求者只能等待,直至占有资源的进程释放。
- 请求和保持条件:指进程已经保持至少一个资源,但又提出了新的资源请求,而该资源已被其它进程占有,此时请求进程阻塞,但又对自己已获得的其它资源保持占有。
- 不剥夺条件:指进程已获得的资源,在未使用完之前,不能被剥夺,只能在使用完时由自己释放。
- 循环等待:指在发生死锁时,必然存在一个进程对应的环形链。
换句话说,死锁线程集合中的每个线程都在等待另一个死锁线程占有的资源。但是由于所有线程都不能运行,它们之中任何一个资源都无法释放资源,所以没有一个线程可以被唤醒。
如果说死锁很痴情的话,那么活锁用一则成语来表示就是 弄巧成拙。
某些情况下,当线程意识到它不能获取所需要的下一个锁时,就会尝试礼貌的释放已经获得的锁,然后等待非常短的时间再次尝试获取。可以想像一下这个场景:当两个人在狭路相逢的时候,都想给对方让路,相同的步调会导致双方都无法前进。
现在假想有一对并行的线程用到了两个资源。它们分别尝试获取另一个锁失败后,两个线程都会释放自己持有的锁,再次进行尝试,这个过程会一直进行重复。很明显,这个过程中没有线程阻塞,但是线程仍然不会向下执行,这种状况我们称之为 活锁(livelock)。
如果我们期望的事情一直不会发生,就会产生活跃性问题,比如单线程中的无限循环
while(true){...}
for(;😉{}
在多线程中,比如 aThread 和 bThread 都需要某种资源,aThread 一直占用资源不释放,bThread 一直得不到执行,就会造成活跃性问题,bThread 线程会产生饥饿,我们后面会说。
性能问题
与活跃性问题密切相关的是 性能 问题,如果说活跃性问题关注的是最终的结果,那么性能问题关注的就是造成结果的过程,性能问题有很多方面:比如服务时间过长,吞吐率过低,资源消耗过高,在多线程中这样的问题同样存在。
在多线程中,有一个非常重要的性能因素那就是我们上面提到的 线程切换,也称为 上下文切换(Context Switch),这种操作开销很大。
在计算机世界中,老外都喜欢用 context 上下文这个词,这个词涵盖的内容很多,包括上下文切换的资源,寄存器的状态、程序计数器等。context switch 一般指的就是这些上下文切换的资源、寄存器状态、程序计数器的变化等。
在上下文切换中,会保存和恢复上下文,丢失局部性,把大量的时间消耗在线程切换上而不是线程运行上。
为什么线程切换会开销如此之大呢?线程间的切换会涉及到以下几个步骤

将 CPU 从一个线程切换到另一线程涉及挂起当前线程,保存其状态,例如寄存器,然后恢复到要切换的线程的状态,加载新的程序计数器,此时线程切换实际上就已经完成了;此时,CPU 不在执行线程切换代码,进而执行新的和线程关联的代码。
引起线程切换的几种方式
线程间的切换一般是操作系统层面需要考虑的问题,那么引起线程上下文切换有哪几种方式呢?或者说线程切换有哪几种诱因呢?主要有下面几种引起上下文切换的方式
- 当前正在执行的任务完成,系统的 CPU 正常调度下一个需要运行的线程
- 当前正在执行的任务遇到 I/O 等阻塞操作,线程调度器挂起此任务,继续调度下一个任务。
- 多个任务并发抢占锁资源,当前任务没有获得锁资源,被线程调度器挂起,继续调度下一个任务。
- 用户的代码挂起当前任务,比如线程执行 sleep 方法,让出CPU。
- 使用硬件中断的方式引起上下文切换
线程安全性
在 Java 中,要实现线程安全性,必须要正确的使用线程和锁,但是这些只是满足线程安全的一种方式,要编写正确无误的线程安全的代码,其核心就是对状态访问操作进行管理。最重要的就是最 共享(Shared)的 和 可变(Mutable)的状态。只有共享和可变的变量才会出现问题,私有变量不会出现问题,参考程序计数器。
对象的状态可以理解为存储在实例变量或者静态变量中的数据,共享意味着某个变量可以被多个线程同时访问、可变意味着变量在生命周期内会发生变化。一个变量是否是线程安全的,取决于它是否被多个线程访问。要使变量能够被安全访问,必须通过同步机制来对变量进行修饰。
如果不采用同步机制的话,那么就要避免多线程对共享变量的访问,主要有下面两种方式
- 不要在多线程之间共享变量
- 将共享变量置为不可变的
我们说了这么多次线程安全性,那么什么是线程安全性呢?
什么是线程安全性
多个线程可以同时安全调用的代码称为线程安全的,如果一段代码是安全的,那么这段代码就不存在 竞态条件。仅仅当多个线程共享资源时,才会出现竞态条件。
根据上面的探讨,我们可以得出一个简单的结论:当多个线程访问某个类时,这个类始终都能表现出正确的行为,那么就称这个类是线程安全的。
单线程就是一个线程数量为 1 的多线程,单线程一定是线程安全的。读取某个变量的值不会产生安全性问题,因为不管读取多少次,这个变量的值都不会被修改。
原子性
我们上面提到了原子性的概念,你可以把原子性操作想象成为一个不可分割 的整体,它的结果只有两种,要么全部执行,要么全部回滚。你可以把原子性认为是 婚姻关系 的一种,男人和女人只会产生两种结果,好好的 和 说散就散,一般男人的一生都可以把他看成是原子性的一种,当然我们不排除时间管理(线程切换)的个例,我们知道线程切换必然会伴随着安全性问题,男人要出去浪也会造成两种结果,这两种结果分别对应安全性的两个结果:线程安全(好好的)和线程不安全(说散就散)。
竞态条件
有了上面的线程切换的功底,那么竞态条件也就好定义了,它指的就是两个或多个线程同时对一共享数据进行修改,从而影响程序运行的正确性时,这种就被称为竞态条件(race condition) ,线程切换是导致竞态条件出现的诱导因素,我们通过一个示例来说明,来看一段代码
public class RaceCondition {
private Signleton single = null; public Signleton newSingleton(){ if(single == null){ single = new Signleton(); } return single; }
}
在上面的代码中,涉及到一个竞态条件,那就是判断 single 的时候,如果 single 判断为空,此时发生了线程切换,另外一个线程执行,判断 single 的时候,也是空,执行 new 操作,然后线程切换回之前的线程,再执行 new 操作,那么内存中就会有两个 Singleton 对象。
加锁机制
在 Java 中,有很多种方式来对共享和可变的资源进行加锁和保护。Java 提供一种内置的机制对资源进行保护:synchronized 关键字,它有三种保护机制
- 对方法进行加锁,确保多个线程中只有一个线程执行方法;
- 对某个对象实例(在我们上面的探讨中,变量可以使用对象来替换)进行加锁,确保多个线程中只有一个线程对对象实例进行访问;
- 对类对象进行加锁,确保多个线程只有一个线程能够访问类中的资源。
synchronized 关键字对资源进行保护的代码块俗称 同步代码块(Synchronized Block),例如
synchronized(lock){ // 线程安全的代码 }
每个 Java 对象都可以用做一个实现同步的锁,这些锁被称为 内置锁(Instrinsic Lock)或者 监视器锁(Monitor Lock)。线程在进入同步代码之前会自动获得锁,并且在退出同步代码时自动释放锁,而无论是通过正常执行路径退出还是通过异常路径退出,获得内置锁的唯一途径就是进入这个由锁保护的同步代码块或方法。
synchronized 的另一种隐含的语义就是 互斥,互斥意味着独占,最多只有一个线程持有锁,当线程 A 尝试获得一个由线程 B 持有的锁时,线程 A 必须等待或者阻塞,直到线程 B 释放这个锁,如果线程 B 不释放锁的话,那么线程 A 将会一直等待下去。
线程 A 获得线程 B 持有的锁时,线程 A 必须等待或者阻塞,但是获取锁的线程 B 可以重入,重入的意思可以用一段代码表示
public class Retreent {
public synchronized void doSomething(){ doSomethingElse(); System.out.println("doSomething......"); }
public synchronized void doSomethingElse(){ System.out.println("doSomethingElse......"); }
获取 doSomething() 方法锁的线程可以执行 doSomethingElse() 方法,执行完毕后可以重新执行 doSomething() 方法中的内容。锁重入也支持子类和父类之间的重入,具体的我们后面会进行介绍。
volatile 是一种轻量级的 synchronized,也就是一种轻量级的加锁方式,volatile 通过保证共享变量的可见性来从侧面对对象进行加锁。可见性的意思就是当一个线程修改一个共享变量时,另外一个线程能够 看见 这个修改的值。volatile 的执行成本要比 synchronized 低很多,因为 volatile 不会引起线程的上下文切换。

我们还可以使用原子类 来保证线程安全,原子类其实就是 rt.jar 下面以 atomic 开头的类

除此之外,我们还可以使用 java.util.concurrent 工具包下的线程安全的集合类来确保线程安全,具体的实现类和其原理我们后面会说。
可以使用不同的并发模型来实现并发系统,并发模型说的是系统中的线程如何协作完成并发任务。不同的并发模型以不同的方式拆分任务,线程可以以不同的方式进行通信和协作。
竞态条件和关键区域
竞态条件是在关键代码区域发生的一种特殊条件。关键区域是由多个线程同时执行的代码部分,关键区域中的代码执行顺序会对造成不一样的结果。如果多个线程执行一段关键代码,而这段关键代码会因为执行顺序不同而造成不同的结果时,那么这段代码就会包含竞争条件。
并发模型和分布式系统很相似
并发模型其实和分布式系统模型非常相似,在并发模型中是线程彼此进行通信,而在分布式系统模型中是 进程 彼此进行通信。然而本质上,进程和线程也非常相似。这也就是为什么并发模型和分布式模型非常相似的原因。
分布式系统通常要比并发系统面临更多的挑战和问题比如进程通信、网络可能出现异常,或者远程机器挂掉等等。但是一个并发模型同样面临着比如 CPU 故障、网卡出现问题、硬盘出现问题等。
因为并发模型和分布式模型很相似,因此他们可以相互借鉴,例如用于线程分配的模型就类似于分布式系统环境中的负载均衡模型。
其实说白了,分布式模型的思想就是借鉴并发模型的基础上推演发展来的。
认识两个状态
并发模型的一个重要的方面是,线程是否应该共享状态,是具有共享状态还是独立状态。共享状态也就意味着在不同线程之间共享某些状态
状态其实就是数据,比如一个或者多个对象。当线程要共享数据时,就会造成 竞态条件 或者 死锁 等问题。当然,这些问题只是可能会出现,具体实现方式取决于你是否安全的使用和访问共享对象。

独立的状态表明状态不会在多个线程之间共享,如果线程之间需要通信的话,他们可以访问不可变的对象来实现,这是最有效的避免并发问题的一种方式,如下图所示

使用独立状态让我们的设计更加简单,因为只有一个线程能够访问对象,即使交换对象,也是不可变的对象。
并发模型
并行 Worker
第一个并发模型是并行 worker 模型,客户端会把任务交给 代理人(Delegator),然后由代理人把工作分配给不同的 工人(worker)。如下图所示

并行 worker 的核心思想是,它主要有两个进程即代理人和工人,Delegator 负责接收来自客户端的任务并把任务下发,交给具体的 Worker 进行处理,Worker 处理完成后把结果返回给 Delegator,在 Delegator 接收到 Worker 处理的结果后对其进行汇总,然后交给客户端。
并行 Worker 模型是 Java 并发模型中非常常见的一种模型。许多 java.util.concurrent 包下的并发工具都使用了这种模型。
并行 Worker 的优点
并行 Worker 模型的一个非常明显的特点就是很容易理解,为了提高系统的并行度你可以增加多个 Worker 完成任务。
并行 Worker 模型的另外一个好处就是,它会将一个任务拆分成多个小任务,并发执行,Delegator 在接受到 Worker 的处理结果后就会返回给 Client,整个 Worker -> Delegator -> Client 的过程是异步的。
并行 Worker 的缺点
同样的,并行 Worker 模式同样会有一些隐藏的缺点
共享状态会变得很复杂
实际的并行 Worker 要比我们图中画出的更复杂,主要是并行 Worker 通常会访问内存或共享数据库中的某些共享数据。

这些共享状态可能会使用一些工作队列来保存业务数据、数据缓存、数据库的连接池等。在线程通信中,线程需要确保共享状态是否能够让其他线程共享,而不是仅仅停留在 CPU 缓存中让自己可用,当然这些都是程序员在设计时就需要考虑的问题。线程需要避免 竞态条件,死锁 和许多其他共享状态造成的并发问题。
多线程在访问共享数据时,会丢失并发性,因为操作系统要保证只有一个线程能够访问数据,这会导致共享数据的争用和抢占。未抢占到资源的线程会 阻塞。
现代的非阻塞并发算法可以减少争用提高性能,但是非阻塞算法比较难以实现。
可持久化的数据结构(Persistent data structures) 是另外一个选择。可持久化的数据结构在修改后始终会保留先前版本。因此,如果多个线程同时修改一个可持久化的数据结构,并且一个线程对其进行了修改,则修改的线程会获得对新数据结构的引用。
虽然可持久化的数据结构是一个新的解决方法,但是这种方法实行起来却有一些问题,比如,一个持久列表会将新元素添加到列表的开头,并返回所添加的新元素的引用,但是其他线程仍然只持有列表中先前的第一个元素的引用,他们看不到新添加的元素。
持久化的数据结构比如 链表(LinkedList) 在硬件性能上表现不佳。列表中的每个元素都是一个对象,这些对象散布在计算机内存中。现代 CPU 的顺序访问往往要快的多,因此使用数组等顺序访问的数据结构则能够获得更高的性能。CPU 高速缓存可以将一个大的矩阵块加载到高速缓存中,并让 CPU 在加载后直接访问 CPU 高速缓存中的数据。对于链表,将元素分散在整个 RAM 上,这实际上是不可能的。
无状态的 worker
共享状态可以由其他线程所修改,因此,worker 必须在每次操作共享状态时重新读取,以确保在副本上能够正确工作。不在线程内部保持状态的 worker 成为无状态的 worker。
作业顺序是不确定的
并行工作模型的另一个缺点是作业的顺序不确定,无法保证首先执行或最后执行哪些作业。任务 A 在任务 B 之前分配给 worker,但是任务 B 可能在任务 A 之前执行。
流水线
第二种并发模型就是我们经常在生产车间遇到的 流水线并发模型,下面是流水线设计模型的流程图

这种组织架构就像是工厂中装配线中的 worker,每个 worker 只完成全部工作的一部分,完成一部分后,worker 会将工作转发给下一个 worker。
每道程序都在自己的线程中运行,彼此之间不会共享状态,这种模型也被称为无共享并发模型。
使用流水线并发模型通常被设计为非阻塞I/O,也就是说,当没有给 worker 分配任务时,worker 会做其他工作。非阻塞I/O 意味着当 worker 开始 I/O 操作,例如从网络中读取文件,worker 不会等待 I/O 调用完成。因为 I/O 操作很慢,所以等待 I/O 非常耗费时间。在等待 I/O 的同时,CPU 可以做其他事情,I/O 操作完成后的结果将传递给下一个 worker。下面是非阻塞 I/O 的流程图

在实际情况中,任务通常不会按着一条装配线流动,由于大多数程序需要做很多事情,因此需要根据完成的不同工作在不同的 worker 之间流动,如下图所示

任务还可能需要多个 worker 共同参与完成

响应式 – 事件驱动系统
使用流水线模型的系统有时也被称为 响应式 或者 事件驱动系统,这种模型会根据外部的事件作出响应,事件可能是某个 HTTP 请求或者某个文件完成加载到内存中。
Actor 模型
在 Actor 模型中,每一个 Actor 其实就是一个 Worker, 每一个 Actor 都能够处理任务。
简单来说,Actor 模型是一个并发模型,它定义了一系列系统组件应该如何动作和交互的通用规则,最著名的使用这套规则的编程语言是 Erlang。一个参与者Actor对接收到的消息做出响应,然后可以创建出更多的 Actor 或发送更多的消息,同时准备接收下一条消息。

Channels 模型
在 Channel 模型中,worker 通常不会直接通信,与此相对的,他们通常将事件发送到不同的 通道(Channel)上,然后其他 worker 可以在这些通道上获取消息,下面是 Channel 的模型图

有的时候 worker 不需要明确知道接下来的 worker 是谁,他们只需要将作者写入通道中,监听 Channel 的 worker 可以订阅或者取消订阅,这种方式降低了 worker 和 worker 之间的耦合性。
流水线设计的优点
与并行设计模型相比,流水线模型具有一些优势,具体优势如下
不会存在共享状态
因为流水线设计能够保证 worker 在处理完成后再传递给下一个 worker,所以 worker 与 worker 之间不需要共享任何状态,也就无需考虑并发问题。你甚至可以在实现上把每个 worker 看成是单线程的一种。
有状态 worker
因为 worker 知道没有其他线程修改自身的数据,所以流水线设计中的 worker 是有状态的,有状态的意思是他们可以将需要操作的数据保留在内存中,有状态通常比无状态更快。
更好的硬件整合
因为你可以把流水线看成是单线程的,而单线程的工作优势在于它能够和硬件的工作方式相同。因为有状态的 worker 通常在 CPU 中缓存数据,这样可以更快地访问缓存的数据。
使任务更加有效的进行
可以对流水线并发模型中的任务进行排序,一般用来日志的写入和恢复。
流水线设计的缺点
流水线并发模型的缺点是任务会涉及多个 worker,因此可能会分散在项目代码的多个类中。因此很难确定每个 worker 都在执行哪个任务。流水线的代码编写也比较困难,设计许多嵌套回调处理程序的代码通常被称为 回调地狱。回调地狱很难追踪 debug。
函数性并行
函数性并行模型是最近才提出的一种并发模型,它的基本思路是使用函数调用来实现。消息的传递就相当于是函数的调用。传递给函数的参数都会被拷贝,因此在函数之外的任何实体都无法操纵函数内的数据。这使得函数执行类似于原子操作。每个函数调用都可以独立于任何其他函数调用执行。
当每个函数调用独立执行时,每个函数都可以在单独的 CPU 上执行。这也就是说,函数式并行并行相当于是各个 CPU 单独执行各自的任务。
JDK 1.7 中的 ForkAndJoinPool 类就实现了函数性并行的功能。Java 8 提出了 stream 的概念,使用并行流也能够实现大量集合的迭代。
函数性并行的难点是要知道函数的调用流程以及哪些 CPU 执行了哪些函数,跨 CPU 函数调用会带来额外的开销。
我们之前说过,线程就是进程中的一条顺序流,在 Java 中,每一条 Java 线程就像是 JVM 的一条顺序流,就像是虚拟 CPU 一样来执行代码。Java 中的 main() 方法是一条特殊的线程,JVM 创建的 main 线程是一条主执行线程,在 Java 中,方法都是由 main 方法发起的。在 main 方法中,你照样可以创建其他的线程(执行顺序流),这些线程可以和 main 方法共同执行应用代码。
Java 线程也是一种对象,它和其他对象一样。Java 中的 Thread 表示线程,Thread 是 java.lang.Thread 类或其子类的实例。那么下面我们就来一起探讨一下在 Java 中如何创建和启动线程。
创建并启动线程
在 Java 中,创建线程的方式主要有三种
- 通过继承
Thread类来创建线程 - 通过实现
Runnable接口来创建线程 - 通过
Callable和Future来创建线程
下面我们分别探讨一下这几种创建方式
继承 Thread 类来创建线程
第一种方式是继承 Thread 类来创建线程,如下示例
public class TJavaThread extends Thread{
static int count;
@Override
public synchronized void run() {
for(int i = 0;i < 10000;i++){
count++;
}
}
public static void main(String[] args) throws InterruptedException {
TJavaThread tJavaThread = new TJavaThread();
tJavaThread.start();
tJavaThread.join();
System.out.println("count = " + count);
}
}
线程的主要创建步骤如下
- 定义一个线程类使其继承 Thread 类,并重写其中的 run 方法,run 方法内部就是线程要完成的任务,因此 run 方法也被称为
执行体 - 创建了 Thread 的子类,上面代码中的子类是
TJavaThread - 启动方法需要注意,并不是直接调用
run方法来启动线程,而是使用start方法来启动线程。当然 run 方法可以调用,这样的话就会变成普通方法调用,而不是新创建一个线程来调用了。
public static void main(String[] args) throws InterruptedException {
TJavaThread tJavaThread = new TJavaThread(); tJavaThread.run(); System.out.println("count = " + count); }
这样的话,整个 main 方法只有一条执行线程也就是 main 线程,由两条执行线程变为一条执行线程

Thread 构造器只需要一个 Runnable 对象,调用 Thread 对象的 start() 方法为该线程执行必须的初始化操作,然后调用 Runnable 的 run 方法,以便在这个线程中启动任务。我们上面使用了线程的 join 方法,它用来等待线程的执行结束,如果我们不加 join 方法,它就不会等待 tJavaThread 的执行完毕,输出的结果可能就不是 10000

可以看到,在 run 方法还没有结束前,run 就被返回了。也就是说,程序不会等到 run 方法执行完毕就会执行下面的指令。
使用继承方式创建线程的优势:编写比较简单;可以使用 this 关键字直接指向当前线程,而无需使用 Thread.currentThread() 来获取当前线程。
使用继承方式创建线程的劣势:在 Java 中,只允许单继承(拒绝肛精说使用内部类可以实现多继承)的原则,所以使用继承的方式,子类就不能再继承其他类。
使用 Runnable 接口来创建线程
相对的,还可以使用 Runnable 接口来创建线程,如下示例
public class TJavaThreadUseImplements implements Runnable{
static int count;
@Override
public synchronized void run() {
for(int i = 0;i < 10000;i++){
count++;
}
}
public static void main(String[] args) throws InterruptedException {
new Thread(new TJavaThreadUseImplements()).start();
System.out.println("count = " + count);
}
}
线程的主要创建步骤如下
- 首先定义 Runnable 接口,并重写 Runnable 接口的 run 方法,run 方法的方法体同样是该线程的线程执行体。
- 创建线程实例,可以使用上面代码这种简单的方式创建,也可以通过 new 出线程的实例来创建,如下所示
TJavaThreadUseImplements tJavaThreadUseImplements = new TJavaThreadUseImplements(); new Thread(tJavaThreadUseImplements).start();
- 再调用线程对象的 start 方法来启动该线程。
线程在使用实现 Runnable 的同时也能实现其他接口,非常适合多个相同线程来处理同一份资源的情况,体现了面向对象的思想。
使用 Runnable 实现的劣势是编程稍微繁琐,如果要访问当前线程,则必须使用 Thread.currentThread() 方法。
使用 Callable 接口来创建线程
Runnable 接口执行的是独立的任务,Runnable 接口不会产生任何返回值,如果你希望在任务完成后能够返回一个值的话,那么你可以实现 Callable 接口而不是 Runnable 接口。Java SE5 引入了 Callable 接口,它的示例如下
public class CallableTask implements Callable {
static int count;
public CallableTask(int count){
this.count = count;
}
@Override
public Object call() {
return count;
}
public static void main(String[] args) throws ExecutionException, InterruptedException {
FutureTask<Integer> task = new FutureTask((Callable<Integer>) () -> {
for(int i = 0;i < 1000;i++){
count++;
}
return count;
});
Thread thread = new Thread(task);
thread.start();
Integer total = task.get();
System.out.println("total = " + total);
}
}
我想,使用 Callable 接口的好处你已经知道了吧,既能够实现多个接口,也能够得到执行结果的返回值。Callable 和 Runnable 接口还是有一些区别的,主要区别如下
- Callable 执行的任务有返回值,而 Runnable 执行的任务没有返回值
- Callable(重写)的方法是 call 方法,而 Runnable(重写)的方法是 run 方法。
- call 方法可以抛出异常,而 Runnable 方法不能抛出异常
使用线程池来创建线程
首先先来认识一下顶级接口 Executor,Executor 虽然不是传统线程创建的方式之一,但是它却成为了创建线程的替代者,使用线程池的好处如下
- 利用线程池能够复用线程、控制最大并发数。
- 实现任务线程队列
缓存策略和拒绝机制。 - 实现某些与时间相关的功能,如定时执行、周期执行等。
- 隔离线程环境。比如,交易服务和搜索服务在同一台服务器上,分别开启两个线程池,交易线程的资源消耗明显要大;因此,通过配置独立的线程池,将较慢的交易服务与搜索服务隔开,避免个服务线程互相影响。
你可以使用如下操作来替换线程创建
new Thread(new(RunnableTask())).start()
// 替换为
Executor executor = new ExecutorSubClass() // 线程池实现类; executor.execute(new RunnableTask1()); executor.execute(new RunnableTask2());
ExecutorService 是 Executor 的默认实现,也是 Executor 的扩展接口,ThreadPoolExecutor 类提供了线程池的扩展实现。Executors 类为这些 Executor 提供了方便的工厂方法。下面是使用 ExecutorService 创建线程的几种方式
CachedThreadPool
从而简化了并发编程。Executor 在客户端和任务之间提供了一个间接层;与客户端直接执行任务不同,这个中介对象将执行任务。Executor 允许你管理异步任务的执行,而无须显示地管理线程的生命周期。
public static void main(String[] args) { ExecutorService service = Executors.newCachedThreadPool(); for(int i = 0;i < 5;i++){ service.execute(new TestThread()); } service.shutdown(); }
CachedThreadPool 会为每个任务都创建一个线程。
注意:ExecutorService 对象是使用静态的
Executors创建的,这个方法可以确定 Executor 类型。对shutDown的调用可以防止新任务提交给 ExecutorService ,这个线程在 Executor 中所有任务完成后退出。
FixedThreadPool
FixedThreadPool 使你可以使用有限的线程集来启动多线程
public static void main(String[] args) { ExecutorService service = Executors.newFixedThreadPool(5); for(int i = 0;i < 5;i++){ service.execute(new TestThread()); } service.shutdown(); }
有了 FixedThreadPool 使你可以一次性的预先执行高昂的线程分配,因此也就可以限制线程的数量。这可以节省时间,因为你不必为每个任务都固定的付出创建线程的开销。
SingleThreadExecutor
SingleThreadExecutor 就是线程数量为 1 的 FixedThreadPool,如果向 SingleThreadPool 一次性提交了多个任务,那么这些任务将会排队,每个任务都会在下一个任务开始前结束,所有的任务都将使用相同的线程。SingleThreadPool 会序列化所有提交给他的任务,并会维护它自己(隐藏)的悬挂队列。
public static void main(String[] args) { ExecutorService service = Executors.newSingleThreadExecutor(); for(int i = 0;i < 5;i++){ service.execute(new TestThread()); } service.shutdown(); }
从输出的结果就可以看到,任务都是挨着执行的。我为任务分配了五个线程,但是这五个线程不像是我们之前看到的有换进换出的效果,它每次都会先执行完自己的那个线程,然后余下的线程继续走完这条线程的执行路径。你可以用 SingleThreadExecutor 来确保任意时刻都只有唯一一个任务在运行。
休眠
影响任务行为的一种简单方式就是使线程 休眠,选定给定的休眠时间,调用它的 sleep() 方法, 一般使用的TimeUnit 这个时间类替换 Thread.sleep() 方法,示例如下:
public class SuperclassThread extends TestThread{
@Override
public void run() {
System.out.println(Thread.currentThread() + "starting ..." );
try {
for(int i = 0;i < 5;i++){
if(i == 3){
System.out.println(Thread.currentThread() + "sleeping ...");
TimeUnit.MILLISECONDS.sleep(1000);
}
}
} catch (InterruptedException e) {
e.printStackTrace();
}
System.out.println(Thread.currentThread() + "wakeup and end ...");
}
public static void main(String[] args) {
ExecutorService executors = Executors.newCachedThreadPool();
for(int i = 0;i < 5;i++){
executors.execute(new SuperclassThread());
}
executors.shutdown();
}
}
关于 TimeUnit 中的 sleep() 方法和 Thread.sleep() 方法的比较,请参考下面这篇博客
优先级
上面提到线程调度器对每个线程的执行都是不可预知的,随机执行的,那么有没有办法告诉线程调度器哪个任务想要优先被执行呢?你可以通过设置线程的优先级状态,告诉线程调度器哪个线程的执行优先级比较高,请给这个骑手马上派单,线程调度器倾向于让优先级较高的线程优先执行,然而,这并不意味着优先级低的线程得不到执行,也就是说,优先级不会导致死锁的问题。优先级较低的线程只是执行频率较低。
public class SimplePriorities implements Runnable{
private int priority;
public SimplePriorities(int priority) {
this.priority = priority;
}
@Override
public void run() {
Thread.currentThread().setPriority(priority);
for(int i = 0;i < 100;i++){
System.out.println(this);
if(i % 10 == 0){
Thread.yield();
}
}
}
@Override
public String toString() {
return Thread.currentThread() + " " + priority;
}
public static void main(String[] args) {
ExecutorService service = Executors.newCachedThreadPool();
for(int i = 0;i < 5;i++){
service.execute(new SimplePriorities(Thread.MAX_PRIORITY));
}
service.execute(new SimplePriorities(Thread.MIN_PRIORITY));
}
}
toString() 方法被覆盖,以便通过使用 Thread.toString() 方法来打印线程的名称。你可以改写线程的默认输出,这里采用了 Thread[pool-1-thread-1,10,main] 这种形式的输出。
通过输出,你可以看到,最后一个线程的优先级最低,其余的线程优先级最高。注意,优先级是在 run 开头设置的,在构造器中设置它们不会有任何好处,因为这个时候线程还没有执行任务。
尽管 JDK 有 10 个优先级,但是一般只有MAX_PRIORITY,NORM_PRIORITY,MIN_PRIORITY 三种级别。
作出让步
我们上面提过,如果知道一个线程已经在 run() 方法中运行的差不多了,那么它就可以给线程调度器一个提示:我已经完成了任务中最重要的部分,可以让给别的线程使用 CPU 了。这个暗示将通过 yield() 方法作出。
有一个很重要的点就是,Thread.yield() 是建议执行切换CPU,而不是强制执行CPU切换。
对于任何重要的控制或者在调用应用时,都不能依赖于 yield() 方法,实际上, yield() 方法经常被滥用。
后台线程
后台(daemon) 线程,是指运行时在后台提供的一种服务线程,这种线程不是属于必须的。当所有非后台线程结束时,程序也就停止了,同时会终止所有的后台线程。反过来说,只要有任何非后台线程还在运行,程序就不会终止。
public class SimpleDaemons implements Runnable{
@Override
public void run() {
while (true){
try {
TimeUnit.MILLISECONDS.sleep(100);
System.out.println(Thread.currentThread() + " " + this);
} catch (InterruptedException e) {
System.out.println("sleep() interrupted");
}
}
}
public static void main(String[] args) throws InterruptedException {
for(int i = 0;i < 10;i++){
Thread daemon = new Thread(new SimpleDaemons());
daemon.setDaemon(true);
daemon.start();
}
System.out.println("All Daemons started");
TimeUnit.MILLISECONDS.sleep(175);
}
}
在每次的循环中会创建 10 个线程,并把每个线程设置为后台线程,然后开始运行,for 循环会进行十次,然后输出信息,随后主线程睡眠一段时间后停止运行。在每次 run 循环中,都会打印当前线程的信息,主线程运行完毕,程序就执行完毕了。因为 daemon 是后台线程,无法影响主线程的执行。
但是当你把 daemon.setDaemon(true) 去掉时,while(true) 会进行无限循环,那么主线程一直在执行最重要的任务,所以会一直循环下去无法停止。
ThreadFactory
按需要创建线程的对象。使用线程工厂替换了 Thread 或者 Runnable 接口的硬连接,使程序能够使用特殊的线程子类,优先级等。一般的创建方式为
class SimpleThreadFactory implements ThreadFactory { public Thread newThread(Runnable r) { return new Thread(r); } }
Executors.defaultThreadFactory 方法提供了一个更有用的简单实现,它在返回之前将创建的线程上下文设置为已知值
ThreadFactory 是一个接口,它只有一个方法就是创建线程的方法
public interface ThreadFactory {
// 构建一个新的线程。实现类可能初始化优先级,名称,后台线程状态和 线程组等
Thread newThread(Runnable r);
}
下面来看一个 ThreadFactory 的例子
public class DaemonThreadFactory implements ThreadFactory {
@Override
public Thread newThread(Runnable r) {
Thread t = new Thread(r);
t.setDaemon(true);
return t;
}
}
public class DaemonFromFactory implements Runnable{
@Override
public void run() {
while (true){
try {
TimeUnit.MILLISECONDS.sleep(100);
System.out.println(Thread.currentThread() + " " + this);
} catch (InterruptedException e) {
System.out.println("Interrupted");
}
}
}
public static void main(String[] args) throws InterruptedException {
ExecutorService service = Executors.newCachedThreadPool(new DaemonThreadFactory());
for(int i = 0;i < 10;i++){
service.execute(new DaemonFromFactory());
}
System.out.println("All daemons started");
TimeUnit.MILLISECONDS.sleep(500);
}
}
Executors.newCachedThreadPool 可以接受一个线程池对象,创建一个根据需要创建新线程的线程池,但会在它们可用时重用先前构造的线程,并在需要时使用提供的 ThreadFactory 创建新线程。
public static ExecutorService newCachedThreadPool(ThreadFactory threadFactory) { return new ThreadPoolExecutor(0, Integer.MAX_VALUE, 60L, TimeUnit.SECONDS, new SynchronousQueue<Runnable>(), threadFactory); }
加入一个线程
一个线程可以在其他线程上调用 join() 方法,其效果是等待一段时间直到第二个线程结束才正常执行。如果某个线程在另一个线程 t 上调用 t.join() 方法,此线程将被挂起,直到目标线程 t 结束才回复(可以用 t.isAlive() 返回为真假判断)。
也可以在调用 join 时带上一个超时参数,来设置到期时间,时间到期,join方法自动返回。
对 join 的调用也可以被中断,做法是在线程上调用 interrupted 方法,这时需要用到 try…catch 子句
public class TestJoinMethod extends Thread{
@Override
public void run() {
for(int i = 0;i < 5;i++){
try {
TimeUnit.MILLISECONDS.sleep(1000);
} catch (InterruptedException e) {
System.out.println("Interrupted sleep");
}
System.out.println(Thread.currentThread() + " " + i);
}
}
public static void main(String[] args) throws InterruptedException {
TestJoinMethod join1 = new TestJoinMethod();
TestJoinMethod join2 = new TestJoinMethod();
TestJoinMethod join3 = new TestJoinMethod();
join1.start();
// join1.join();
join2.start();
join3.start();
}
}
join() 方法等待线程死亡。 换句话说,它会导致当前运行的线程停止执行,直到它加入的线程完成其任务。
线程异常捕获
由于线程的本质,使你不能捕获从线程中逃逸的异常,一旦异常逃出任务的 run 方法,它就会向外传播到控制台,除非你采取特殊的步骤捕获这种错误的异常,在 Java5 之前,你可以通过线程组来捕获,但是在 Java 5 之后,就需要用 Executor 来解决问题,因为线程组不是一次好的尝试。
下面的任务会在 run 方法的执行期间抛出一个异常,并且这个异常会抛到 run 方法的外面,而且 main 方法无法对它进行捕获
public class ExceptionThread implements Runnable{
@Override
public void run() {
throw new RuntimeException();
}
public static void main(String[] args) {
try {
ExecutorService service = Executors.newCachedThreadPool();
service.execute(new ExceptionThread());
}catch (Exception e){
System.out.println("eeeee");
}
}
}
为了解决这个问题,我们需要修改 Executor 产生线程的方式,Java5 提供了一个新的接口 Thread.UncaughtExceptionHandler ,它允许你在每个 Thread 上都附着一个异常处理器。Thread.UncaughtExceptionHandler.uncaughtException() 会在线程因未捕获临近死亡时被调用。
public class ExceptionThread2 implements Runnable{
@Override
public void run() {
Thread t = Thread.currentThread();
System.out.println("run() by " + t);
System.out.println("eh = " + t.getUncaughtExceptionHandler());
// 手动抛出异常
throw new RuntimeException();
}
}
// 实现Thread.UncaughtExceptionHandler 接口,创建异常处理器 public class MyUncaughtExceptionHandler implements Thread.UncaughtExceptionHandler{
@Override
public void uncaughtException(Thread t, Throwable e) {
System.out.println("caught " + e);
}
}
public class HandlerThreadFactory implements ThreadFactory {
@Override
public Thread newThread(Runnable r) {
System.out.println(this + " creating new Thread");
Thread t = new Thread(r);
System.out.println("created " + t);
t.setUncaughtExceptionHandler(new MyUncaughtExceptionHandler());
System.out.println("ex = " + t.getUncaughtExceptionHandler());
return t;
}
}
public class CaptureUncaughtException {
public static void main(String[] args) {
ExecutorService service = Executors.newCachedThreadPool(new HandlerThreadFactory());
service.execute(new ExceptionThread2());
}
}
在程序中添加了额外的追踪机制,用来验证工厂创建的线程会传递给UncaughtExceptionHandler,你可以看到,未捕获的异常是通过 uncaughtException 来捕获的。
# 662.怎样将 GB2312 编码的字符串转换为 ISO-8859-1 编码的字符串?-Java面试题
代码如下所示:
String s1 = "你好"; String s2 = newString(s1.getBytes("GB2312"), "ISO-8859-1");
# 661.如何实现字符串的反转及替换-Java面试题
方法很多,可以自己写实现也可以使用 String 或 StringBuffer / StringBuilder 中的方法。
# 660.数据类型之间的转换-Java面试题
- 如何将字符串转换为基本数据类型?
- 如何将基本数据类型转换为字符串?
答:
- 调用基本数据类型对应的包装类中的方法 parseXXX(String)或 valueOf(String)即可返回相应基本类型;
- 一种方法是将基本数据类型与空字符串(””)连接(+)即可获得其所对应的字符串;另一种方法是调用 String 类中的 valueOf(…)方法返回相应字符
# 659.指出下面程序的运行结果-Java面试题

执行结果:1a2b2b。创建对象时构造器的调用顺序是:先初始化静态成员,然后调用父类构造器,再初始化非静态成员,最后调用自身构造器。
# 658.Java 中的 final 关键字有哪些用法-Java面试题
- 修饰类:表示该类不能被继承;
- 修饰方法:表示方法不能被重写;
- 修饰变量:表示变量只能一次赋值以后值不能被修改(常量)。
# 657.内部类可以引用它的包含类(外部类)的成员吗?有没有什么限制-Java面试题
一个内部类对象可以访问创建它的外部类对象的成员,包括私有成员。
# 656.Anonymous Inner Class(匿名内部类)是否可以继承其它类?是否可以 实现接口-Java面试题
可以继承其他类或实现其他接口,在 Swing 编程中常用此方式来实现事件监听和回调
# 655.一个“.java”源文件中是否可以包含多个类(不是内部类) 有什么限制-Java面试题
可以,但一个源文件中最多只能有一个公开类(public class)而且文件名必须和公开类的类名完全保持一致
# 654.接口是否可继承(extends)接口? 抽象类是否可实现(implements) 接口? 抽象类是否可继承具体类(concrete class)-Java面试题
接口可以继承接口。抽象类可以实现(implements)接口,抽象类可继承具体类,但前提是具体类必须有明确的构造函数。
# 653.String s=new String(“xyz”);创建了几个字符串对象-Java面试题
两个对象,一个是静态存储区的"xyz",一个是用 new 创建在堆上的对象。
# 652.GC 是什么?为什么要有 GC?-Java面试题
GC 是垃圾收集的意思,内存处理是编程人员容易出现问题的地方,忘记或者错误的内存回收会导致程序或系统的不稳定甚至崩溃,Java 提供的 GC 功能可以自动监测对象是否超过作用域从而达到自动回收内存的目的,Java 语言没有提供释放已分配内存的显示操作方法。Java 程序员不用担心内存管理,因为垃圾收集器会自动进行管理。要请求垃圾收集,可以调用下面的方法之一:System.gc() 或 Runtime.getRuntime().gc() ,但 JVM 可以屏蔽掉显示的垃圾回收调用。
垃圾回收可以有效的防止内存泄露,有效的使用可以使用的内存。垃圾回收器通常是作为一个单独的低优先级的线程运行,不可预知的情况下对内存堆中已经死亡的或者长时间没有使用的对象进行清除和回收,程序员不能实时的调用垃圾回收器对某个对象或所有对象进行垃圾回收。在 Java 诞生初期,垃圾回收是 Java最大的亮点之一,因为服务器端的编程需要有效的防止内存泄露问题,然而时过境迁,如今 Java 的垃圾回收机制已经成为被诟病的东西。移动智能终端用户通常觉得 iOS 的系统比 Android 系统有更好的用户体验,其中一个深层次的原因就在于 Android 系统中垃圾回收的不可预知性。
补充:垃圾回收机制有很多种,包括:分代复制垃圾回收、标记垃圾回收、增量垃圾回收等方式。标准的 Java 进程既有栈又有堆。栈保存了原始型局部变量,堆保存了要创建的对象。Java 平台对堆内存回收和再利用的基本算法被称为标记和清除,但是 Java 对其进行了改进,采用“分代式垃圾收集”。这种方法会跟 Java 对象的生命周期将堆内存划分为不同的区域,在垃圾收集过程中,可能会将对象移动到不同区域:
- 伊甸园(Eden):这是对象最初诞生的区域,并且对大多数对象来说,这里是它们唯一存在过的区域。
- 幸存者乐园(Survivor):从伊甸园幸存下来的对象会被挪到这里。
- 终身颐养园(Tenured):这是足够老的幸存对象的归宿。年轻代收集(Minor-GC)过程是不会触及这个地方的。当年轻代收集不能把对象放进终身颐养园时,就会触发一次完全收集(Major-GC),这里可能还会牵扯到压缩,以便为大对象腾出足够的空间。
与垃圾回收相关的 JVM 参数:
- -Xms / -Xmx — 堆的初始大小 / 堆的最大大小
- -Xmn — 堆中年轻代的大小
- -XX:-DisableExplicitGC — 让 System.gc()不产生任何作用
- -XX:+PrintGCDetail — 打印 GC 的细节
- -XX:+PrintGCDateStamps — 打印 GC 操作的时间戳
# 651.如何实现对象克隆?-Java面试题
有两种方式:
- 实现 Cloneable 接口并重写 Object 类中的 clone()方法;
- 实现 Serializable 接口,通过对象的序列化和反序列化实现克隆,可以实现真正的深度克隆,代码如下

注意:基于序列化和反序列化实现的克隆不仅仅是深度克隆,更重要的是通过泛型限定,可以检查出要克隆的对象是否支持序列化,这项检查是编译器完成的,不是在运行时抛出异常,这种是方案明显优于使用 Object 类的 clone 方法克隆对象。
# 650.是否可以从一个静态(static)方法内部发出对非静态(non-static)方法 的调用?-Java面试题
不可以,静态方法只能访问静态成员,因为非静态方法的调用要先创建对象,因此在调用静态方法时可能对象并没有被初始化。
# 649.静态变量和实例变量的区别?-Java面试题
静态变量是被 static 修饰符修饰的变量,也称为类变量,它属于类,不属于类的任何一个对象,一个类不管创建多少个对象,静态变量在内存中有且仅有一个拷贝;实例变量必须依存于某一实例,需要先创建对象然后通过对象才能访问到它。静态变量可以实现让多个对象共享内存。在 Java 开发中,上下文类和工具类中通常会有大量的静态成员。
# 648.抽象的(abstract)方法是否可同时是静态的(static),是否可同时是本 地方法(native),是否可同时被 synchronized 修饰-Java面试题
都不能。抽象方法需要子类重写,而静态的方法是无法被重写的,因此二者是矛盾的。本地方法是由本地代码(如 C 代码)实现的方法,而抽象方法是没有实现的,也是矛盾的。synchronized 和方法的实现细节有关,抽象方法不涉及实现细节,因此也是相互矛盾的。
# 647.Java 中会存在内存泄漏吗,请简单描述。-Java面试题
理论上 Java 因为有垃圾回收机制(GC)不会存在内存泄露问题(这也是 Java 被广泛使用于服务器端编程的一个重要原因);然而在实际开发中,可能会存在无用但可达的对象,这些对象不能被 GC 回收也会发生内存泄露。一个例子就是 Hibernate 的 Session(一级缓存)中的对象属于持久态,垃圾回收器是不会回收这些对象的,然而这些对象中可能存在无用的垃圾对象。
# 646.静态嵌套类(Static Nested Class)和内部类(Inner Class)的不同-Java面试题
Static Nested Class 是被声明为静态(static)的内部类,它可以不依赖于外部类实例被实例化。而通常的内部类需要在外部类实例化后才能实例化,其语法看起来挺诡异的,如下所示




# 645.抽象类(abstract class)和接口(interface)有什么异同-Java面试题
抽象类和接口都不能够实例化,但可以定义抽象类和接口类型的引用。一个类如果继承了某个抽象类或者实现了某个接口都需要对其中的抽象方法全部进行实现,否则该类仍然需要被声明为抽象类。接口比抽象类更加抽象,因为抽象类中可以定义构造器,可以有抽象方法和具体方法,而接口中不能定义构造器而且其中的方法全部都是抽象方法。抽象类中的成员可以是 private、默认、protected、public 的,而接口中的成员全都是 public 的。抽象类中可以定义成员变量,而接口中定义的成员变量实际上都是常量。有抽象方法的类必须被声明为抽象类,而抽象类未必要有抽象方法。
# 644.char 型变量中能不能存贮一个中文汉字?为什么?-Java面试题
char 类型可以存储一个中文汉字,因为 Java 中使用的编码是 Unicode(不选择任何特定的编码,直接使用字符在字符集中的编号,这是统一的唯一方法),一个 char 类型占 2 个字节(16bit),所以放一个中文是没问题的。
补充:
使用 Unicode 意味着字符在 JVM 内部和外部有不同的表现形式,在 JVM 内部都是 Unicode,当这个字符被从 JVM 内部转移到外部时(例如存入文件系统中),需要进行编码转换。所以 Java 中有字节流和字符流,以及在字符流和字节流之间进行转换的转换流,如 InputStreamReader 和 OutputStreamReader,这两个类是字节流和字符流之间的适配器类,承担了编码转换的任务;对于 C 程序员来说,要完成这样的编码转换恐怕要依赖于 union(联合体/共用体)共享内存的特征来实现了。
# 643.描述一下 JVM 加载 class 文件的原理机制?-Java面试题
JVM 中类的装载是由类加载器(ClassLoader) 和它的子类来实现的,Java 中的类加载器是一个重要的 Java 运行时系统组件,它负责在运行时查找和装入类文件中的类。
补充:
- 由于 Java 的跨平台性,经过编译的 Java 源程序并不是一个可执行程序,而是一个或多个类文件。当 Java 程序需要使用某个类时,JVM 会确保这个类已经被加载、连接(验证、准备和解析)和初始化。类的加载是指把类的.class 文件中的数据读入到内存中,通常是创建一个字节数组读入.class 文件,然后产生与所加载类对应的 Class 对象。加载完成后,Class 对象还不完整,所以此时的类还不可用。当类被加载后就进入连接阶段,这一阶段包括验证、准备(为静态变量分配内存并设置默认的初始值)和解析(将符号引用替换为直接引用)三个步骤。最后JVM 对类进行初始化,包括:1 如果类存在直接的父类并且这个类还没有被初始化,那么就先初始化父类;2 如果类中存在初始化语句,就依次执行这些初始化语句。
- 类的加载是由类加载器完成的,类加载器包括:根加载器(BootStrap)、扩展加载器(Extension)、系统加载器(System)和用户自定义类加载器(java.lang.ClassLoader 的子类)。从 JDK 1.2 开始,类加载过程采取了父亲委托机制(PDM)。PDM 更好的保证了 Java 平台的安全性,在该机制中,JVM 自带的 Bootstrap 是根加载器,其他的加载器都有且仅有一个父类加载器。类的加载首先请求父类加载器加载,父类加载器无能为力时才由其子类加载器自行加载。JVM 不会向 Java 程序提供对 Bootstrap 的引用。下面是关于几个类加载器的说明:
- Bootstrap:一般用本地代码实现,负责加载 JVM 基础核心类库(rt.jar);
- Extension:从 java.ext.dirs 系统属性所指定的目录中加载类库,它的父加载器是 Bootstrap;
- System:又叫应用类加载器,其父类是 Extension。它是应用最广泛的类加载器。它从环境变量 classpath 或者系统属性 java.class.path 所指定的目录中记载类,是用户自定义加载器的默认父加载器。
# 642.重载(Overload)和重写(Override)的区别。重载的方法能否根据返 回类型进行区分?-Java面试题
方法的重载和重写都是实现多态的方式,区别在于前者实现的是编译时的多态性,而后者实现的是运行时的多态性。重载发生在一个类中,同名的方法如果有不同的参数列表(参数类型不同、参数个数不同或者二者都不同)则视为重载;
重写发生在子类与父类之间,重写要求子类被重写方法与父类被重写方法有相同的返回类型,比父类被重写方法更好访问,不能比父类被重写方法声明更多的异常(里氏代换原则)。重载对返回类型没有特殊的要求
# 641.String 和 StringBuilder、StringBuffer 的区别?-Java面试题
Java 平台提供了两种类型的字符串:String 和 StringBuffer / StringBuilder,它们可以储存和操作字符串。其中 String 是只读字符串,也就意味着 String 引用的字符串内容是不能被改变的。而 StringBuffer 和 StringBuilder 类表示的字符串对象可以直接进行修改。StringBuilder 是 JDK 1.5 中引入的,它和StringBuffer 的方法完全相同,区别在于它是在单线程环境下使用的,因为它的所有方面都没有被 synchronized 修饰,因此它的效率也比 StringBuffer 略高。
补充 1:有一个面试题问:有没有哪种情况用+做字符串连接比调用 StringBuffer / StringBuilder 对象的 append 方法性能更好?如果连接后得到的字符串在静态存储区中是早已存在的,那么用+做字符串连接是优于 StringBuffer / StringBuilder 的 append 方法的。
# 640.当一个对象被当作参数传递到一个方法后,此方法可改变这个对象的属性, 并可返回变化后的结果,那么这里到底是值传递还是引用传递?-Java面试题
是值传递。Java 编程语言只有值传递参数。当一个对象实例作为一个参数被传递到方法中时,参数的值就是对该对象的引用。对象的属性可以在被调用过程中被改变,但对象的引用是永远不会改变的。C++和 C#中可以通过传引用或传输出参数来改变传入的参数的值。
补充:Java 中没有传引用实在是非常的不方便,这一点在 Java 8 中仍然没有得到改进,正是如此在 Java 编写的代码中才会出现大量的 Wrapper 类(将需要通过方法调用修改的引用置于一个 Wrapper 类中,再将 Wrapper 对象传入方法),这样的做法只会让代码变得臃肿,尤其是让从 C 和 C++转型为 Java 程序员的开发者无法容忍。
# 639.是否可以继承 String 类-Java面试题
String 类是 final 类,不可以被继承。
补充:继承 String 本身就是一个错误的行为,对 String 类型最好的重用方式是关联(HAS-A)而不是继承(IS-A)
# 638.两个对象值相同(x.equals(y) == true),但却可有不同的 hash code, 这句话对不对?-Java面试题
不对,如果两个对象 x 和 y 满足 x.equals(y) == true,它们的哈希码(hash code)应当相同。Java 对于 eqauls 方法和 hashCode 方法是这样规定的:
- 如果两个对象相同(equals 方法返回 true),那么它们的 hashCode 值一定要相同;
- 如果两个对象的 hashCode 相同,它们并不一定相同。当然,你未必要按照要求去做,但是如果你违背了上述原则就会发现在使用容器时,相同的对象可以出现在 Set 集合中,同时增加新元素的效率会大大下降(对于使用哈希存储的系统,如果哈希码频繁的冲突将会造成存取性能急剧下降)。
# 637.构造器(constructor)是否可被重写(override)?-Java面试题
构造器不能被继承,因此不能被重写,但可以被重载。
# 636.在 Java 中,如何跳出当前的多重嵌套循环-Java面试题
在最外层循环前加一个标记如 A,然后用 break A;可以跳出多重循环。(Java 中支持带标签的 break 和 continue 语句,作用有点类似于 C 和 C++中的 goto 语句,但是就像要避免使用 goto 一样,应该避免使用带标签的 break 和 continue,因为它不会让你的程序变得更优雅,很多时候甚至有相反的作用,所以这种语法其实不知道更好)
# 635.数组有没有 length()方法?String 有没有 length()方法?-Java面试题
数组没有 length()方法,有 length 的属性。String 有 length()方法。JavaScript 中,获得字符串的长度是通过 length 属性得到的,这一点容易和 Java混淆
# 634.用最有效率的方法计算 2 乘以 8?-Java面试题
2 << 3(左移 3 位相当于乘以 2 的 3 次方,右移 3 位相当于除以 2 的 3次方)。
# 633.swtich 是否能作用在 byte 上,是否能作用在 long 上,是否能作用在 S tring 上?-Java面试题
早期的 JDK 中,switch(expr)中,expr 可以是 byte、short、char、int。从 1.5 版开始,Java 中引入了枚举类型(enum),expr 也可以是枚举,从 JDK 1.7 版开始,还可以是字符串(String)。长整型(long)是不可以的。
# 632.Math.round(11.5) 等于多少? Math.round(-11.5)等于多少?-Java面试题
Math.round(11.5)的返回值是 12,Math.round(-11.5)的返回值是-11。四舍五入的原理是在参数上加 0.5 然后进行下取整。
# 631.解释内存中的栈(stack)、堆(heap)和静态存储区的用法。-Java面试题
通常我们定义一个基本数据类型的变量,一个对象的引用,还有就是函数调用的现场保存都使用内存中的栈空间;而通过 new 关键字和构造器创建的对象放在堆空间;程序中的字面量(literal)如直接书写的 100、“hello”和常量都是放在静态存储区中。栈空间操作最快但是也很小,通常大量的对象都是放在堆空间,整个内存包括硬盘上的虚拟内存都可以被当成堆空间来使用。
String str = new String(“hello”);
上面的语句中 str 放在栈上,用 new 创建出来的字符串对象放在堆上,而“hello”这个字面量放在静态存储区。
补充:较新版本的 Java 中使用了一项叫“逃逸分析“的技术,可以将一些局部对象放在栈上以提升对象的操作性能。
# 630.&和&&的区别?-Java面试题
&运算符有两种用法:(1)按位与;(2)逻辑与。
&&运算符是短路与运算。逻辑与跟短路与的差别是非常巨大的,虽然二者都要求运算符左右两端的布尔值都是 true 整个表达式的值才是 true。&&之所以称为短路运算是因为,如果&&左边的表达式的值是 false,右边的表达式会被直接短路掉,不会进行运算。
很多时候我们可能都需要用&&而不是&,例如在验证用户登录时判定用户名不是 null 而且不是空字符串,应当写为:username != null &&!username.equals(“”),二者的顺序不能交换,更不能用&运算符,因为第一个条件如果不成立,根本不能进行字符串的 equals 比较,否则会产生 NullPointerException异常。
注意:逻辑或运算符(|)和短路或运算符(||)的差别也是如此。
补充:如果你熟悉 JavaScript,那你可能更能感受到短路运算的强大,想成为 JavaScript 的高手就先从玩转短路运算开始吧。
# 629.int 和 Integer 有什么区别?-Java面试题
Java 是一个近乎纯洁的面向对象编程语言,但是为了编程的方便还是引入不是对象的基本数据类型,但是为了能够将这些基本数据类型当成对象操作,Java 为每一个基本数据类型都引入了对应的包装类型(wrapper class),int的包装类就是 Integer,从 JDK 1.5 开始引入了自动装箱/拆箱机制,使得二者可以相互转换。
Java 为每个原始类型提供了包装类型:
原始类型: boolean,char,byte,short,int,long,float,double
包装类型:Boolean,Character,Byte,Short,Integer,Long,Float,Double
# 628.Java 有没有 goto?-Java面试题
goto 是 Java 中的保留字,在目前版本的 Java 中没有使用。(根据 James Gosling(Java 之父)编写的《The Java Programming Language》一书的附录中给出了一个 Java 关键字列表,其中有 goto 和 const,但是这两个是目前无法使用的关键字,因此有些地方将其称之为保留字,其实保留字这个词应该有更广泛的意义,因为熟悉 C 语言的程序员都知道,在系统类库中使用过的有特殊意义的单词或单词的组合都被视为保留字)
# 627.short s1 = 1; s1 = s1 + 1;有错吗?short s1 = 1; s1 += 1;有错吗?-Java面试题
对于 short s1 = 1; s1 = s1 + 1;由于 1 是 int 类型,因此 s1+1 运算结果也是 int 型,需要强制转换类型才能赋值给 short 型。而 short s1 = 1; s1+= 1;可以正确编译,因为 s1+= 1;相当于 s1 = (short)(s1 + 1);其中有隐含的强制类型转换。
# 626.、float f=3.4;是否正确-Java面试题
不正确。3.4 是双精度数,将双精度型(double)赋值给浮点型(float)属于下转型(down-casting,也称为窄化)会造成精度损失,因此需要强制类型转换 float f =(float)3.4; 或者写成 float f =3.4F;。
# 625.String 是最基本的数据类型吗?-Java面试题
不是。Java 中的基本数据类型只有 8 个:
byte、short、int、long、float、double、char、boolean;
除了基本类型(primitive type)和枚举类型(enumeration type),剩下的都是引用类型(reference type)
# 624.访问修饰符 public,private,protected,以及不写(默认)时的区别?-Java面试题
区别如下:
| 作用域 | 当前类 | 同包 | 子类 | 其他 |
|---|---|---|---|---|
| public | √ | √ | √ | √ |
| protected | √ | √ | √ | × |
| default | √ | √ | × | × |
| private | √ | × | × | × |
类的成员不写访问修饰时默认为 default。默认对于同一个包中的其他类相当于公开(public),对于不是同一个包中的其他类相当于私有(private)。受保护(protected)对子类相当于公开,对不是同一包中的没有父子关系的类相当于私有。
# 623.面向对象的特征有哪些方面?-Java面试题
面向对象的特征主要有以下几个方面:
- 抽象:抽象是将一类对象的共同特征总结出来构造类的过程,包括数据抽象和行为抽象两方面。抽象只关注对象有哪些属性和行为,并不关注这些行为的细节是什么。
- 继承:继承是从已有类得到继承信息创建新类的过程。提供继承信息的类被称为父类(超类、基类);得到继承信息的类被称为子类(派生类)。继承让变化中的软件系统有了一定的延续性,同时继承也是封装程序中可变因素的重要手段(如果不能理解请阅读阎宏博士的《Java 与模式》或《设计模式精解》中关于桥梁模式的部分)。
- 封装:通常认为封装是把数据和操作数据的方法绑定起来,对数据的访问只能通过已定义的接口。面向对象的本质就是将现实世界描绘成一系列完全自治、封闭的对象。我们在类中编写的方法就是对实现细节的一种封装;我们编写一个类就是对数据和数据操作的封装。可以说,封装就是隐藏一切可隐藏的东西,只向外界提供最简单的编程接口(可以想想普通洗衣机和全自动洗衣机的差别,明显全自动洗衣机封装更好因此操作起来更简单;我们现在使用的智能手机也是封装得足够好的,因为几个按键就搞定了所有的事情)。
- 多态性:多态性是指允许不同子类型的对象对同一消息作出不同的响应。简单的说就是用同样的对象引用调用同样的方法但是做了不同的事情。多态性分为编译时的多态性和运行时的多态性。如果将对象的方法视为对象向外界提供的服务,那么运行时的多态性可以解释为:当 A 系统访问 B 系统提供的服务时,B系统有多种提供服务的方式,但一切对 A 系统来说都是透明的(就像电动剃须刀是 A 系统,它的供电系统是 B 系统,B 系统可以使用电池供电或者用交流电,甚至还有可能是太阳能,A 系统只会通过 B 类对象调用供电的方法,但并不知道供电系统的底层实现是什么,究竟通过何种方式获得了动力)。方法重载(overload)实现的是编译时的多态性(也称为前绑定),而方法重写(override)实现的是运行时的多态性(也称为后绑定)。运行时的多态是面向对象最精髓的东西,要实现多态需要做两件事:1. 方法重写(子类继承父类并重写父类中已有的或抽象的方法);2. 对象造型(用父类型引用引用子类型对象,这样同样的引用调用同样的方法就会根据子类对象的不同而表现出不同的行为)。
# 349.ELK-Java面试题
ELK 是软件集合 Elasticsearch、Logstash、Kibana 的简称,由这三个软件及其相关的组件可以打造大规模日志实时处理系统。
- Elasticsearch 是一个基于 Lucene 的、支持全文索引的分布式存储和索引引擎,主要负责将日志索引并存储起来,方便业务方检索查询。
- Logstash 是一个日志收集、过滤、转发的中间件,主要负责将各条业务线的各类日志统一收集、过滤后,转发给 Elasticsearch 进行下一步处理。
- Kibana 是一个可视化工具,主要负责查询 Elasticsearch 的数据并以可视化的方式展现给业务方,比如各类饼图、直方图、区域图等。
# 348.Logback 优点-Java面试题
- 同样的代码路径,Logback 执行更快
- 更充分的测试
- 原生实现了 SLF4J API(Log4J 还需要有一个中间转换层)
- 内容更丰富的文档
- 支持 XML 或者 Groovy 方式配置
- 配置文件自动热加载
- 从 IO 错误中优雅恢复
- 自动删除日志归档
- 自动压缩日志成为归档文件
- 支持 Prudent 模式,使多个 JVM 进程能记录同一个日志文件
- 支持配置文件中加入条件判断来适应不同的环境
- 更强大的过滤器
- 支持 SiftingAppender(可筛选 Appender)
- 异常栈信息带有包信息
# 347.LogBack-Java面试题
简单地说,Logback 是一个 Java 领域的日志框架。它被认为是 Log4J 的继承人。
Logback 主要由三个模块组成:logback-core,logback-classic。logback-access
logback-core 是其它模块的基础设施,其它模块基于它构建,显然,logback-core 提供了一些关键的通用机制。
logback-classic 的地位和作用等同于 Log4J,它也被认为是 Log4J 的一个改进版,并且它实现了简单日志门面 SLF4J;
logback-access 主要作为一个与 Servlet 容器交互的模块,比如说 tomcat 或者 jetty,提供一些与HTTP 访问相关的功能。
# 346.Log4j-Java面试题
Log4j 是 Apache 的一个开源项目,通过使用 Log4j,我们可以控制日志信息输送的目的地是控制台、文件、GUI 组件,甚至是套接口服务器、NT 的事件记录器、UNIX Syslog 守护进程等;我们也可以控制每一条日志的输出格式;通过定义每一条日志信息的级别,我们能够更加细致地控制日志的生成过程。
Log4j 由三个重要的组成构成:日志记录器(Loggers),输出端(Appenders)和日志格式化器(Layout)。
- Logger:控制要启用或禁用哪些日志记录语句,并对日志信息进行级别限制
- Appenders : 指定了日志将打印到控制台还是文件中
- Layout : 控制日志信息的显示格式
Log4j 中将要输出的 Log 信息定义了 5 种级别,依次为 DEBUG、INFO、WARN、ERROR 和 FATAL,当输出时,只有级别高过配置中规定的 级别的信息才能真正的输出,这样就很方便的来配置不同情况下要输出的内容,而不需要更改代码。
# 345.Slf4j-Java面试题
slf4j 的全称是 Simple Loging Facade For Java,即它仅仅是一个为 Java 程序提供日志输出的统一接口,并不是一个具体的日志实现方案,就比如 JDBC 一样,只是一种规则而已。所以单独的 slf4j 是不能工作的,必须搭配其他具体的日志实现方案,比如 apache 的 org.apache.log4j.Logger,jdk 自带的 java.util.logging.Logger 等。
# 212.序列化(深 clone 一中实现)-Java面试题
在 Java 语言里深复制一个对象,常常可以先使对象实现Serializable 接口,然后把对象(实际上只是对象的一个拷贝)写到一个流里,再从流里读出来,便可以重建对象。
# 211.深复制(复制对象和其应用对象)-Java面试题
深拷贝不仅复制对象本身,而且复制对象包含的引用指向的所有对象。
class Student implements Cloneable { String name; int age; Professor p; Student(String name, int age, Professor p) { this.name = name; this.age = age; this.p = p; } public Object clone() { Student o = null; try { o = (Student) super.clone(); } catch (CloneNotSupportedException e) { System.out.println(e.toString()); } o.p = (Professor) p.clone(); return o; } }
# 210.浅复制(复制引用但不复制引用的对象)-Java面试题
创建一个新对象,然后将当前对象的非静态字段复制到该新对象,如果字段是值类型的,那么对该字段执行复制;如果该字段是引用类型的话,则复制引用但不复制引用的对象。因此,原始对象及其副本引用同一个对象。
class Resume implements Cloneable{ public Object clone() { try { return (Resume)super.clone(); } catch (Exception e) { e.printStackTrace(); return null; } } }
# 209.直接赋值复制-Java面试题
直接赋值。在 Java 中,A a1 = a2,我们需要理解的是这实际上复制的是引用,也就是说 a1 和 a2 指向的是同一个对象。因此,当 a1 变化的时候,a2 里面的成员变量也会跟着变化。
# 208.JAVA 复制-Java面试题
将一个对象的引用复制给另外一个对象,一共有三种方式。第一种方式是直接赋值,第二种方式是浅拷贝,第三种是深拷贝。所以大家知道了哈,这三种概念实际上都是为了拷贝对象。
# 207.Transient 关键字阻止该变量被序列化到文件中-Java面试题
- 在变量声明前加上 Transient 关键字,可以阻止该变量被序列化到文件中,在被反序列化后,transient 变量的值被设为初始值,如 int 型的是 0,对象型的是 null。
- 服务器端给客户端发送序列化对象数据,对象中有一些数据是敏感的,比如密码字符串等,希望对该密码字段在序列化时,进行加密,而客户端如果拥有解密的密钥,只有在客户端进行反序列化时,才可以对密码进行读取,这样可以一定程度保证序列化对象的数据安全。
# 206.序列化子父类说明-Java面试题
要想将父类对象也序列化,就需要让父类也实现 Serializable 接口。
# 205.序列化静态变量-Java面试题
序列化并不保存静态变量
# 204.序列化 ID-Java面试题
虚拟机是否允许反序列化,不仅取决于类路径和功能代码是否一致,一个非常重要的一点是两个类的序列化 ID 是否一致(就是 private static final long serialVersionUID)
# 203.writeObject 和 readObject 自定义序列化策略-Java面试题
在类中增加 writeObject 和 readObject 方法可以实现自定义序列化策略。
# 202.ObjectOutputStream 和 ObjectInputStream 对对象进行序列化及反序列化-Java面试题
通过 ObjectOutputStream 和 ObjectInputStream 对对象进行序列化及反序列化。
# 201.Serializable 实现序列化-Java面试题
在 Java 中,只要一个类实现了 java.io.Serializable 接口,那么它就可以被序列化。
# 200.序列化用户远程对象传输-Java面试题
除了在持久化对象时会用到对象序列化之外,当使用 RMI(远程方法调用),或在网络中传递对象时,都会用到对象序列化。Java序列化API为处理对象序列化提供了一个标准机制,该API简单易用。
# 199.序列化对象以字节数组保持-静态成员不保存-Java面试题
使用 Java 对象序列化,在保存对象时,会把其状态保存为一组字节,在未来,再将这些字节组装成对象。必须注意地是,对象序列化保存的是对象的”状态”,即它的成员变量。由此可知,对象序列化不会关注类中的静态变量。
# 198.保存(持久化)对象及其状态到内存或者磁盘-Java面试题
Java 平台允许我们在内存中创建可复用的 Java 对象,但一般情况下,只有当 JVM 处于运行时,这些对象才可能存在,即,这些对象的生命周期不会比 JVM 的生命周期更长。但在现实应用中,就可能要求在JVM停止运行之后能够保存(持久化)指定的对象,并在将来重新读取被保存的对象。Java 对象序列化就能够帮助我们实现该功能。
