
 java基础03
java基础03
# 196.类型通配符?-Java面试题
类型通配符一般是使用 ? 代 替 具 体 的 类 型 参 数 。 例 如 List<?> 在逻辑上是List
# 195.泛型类-Java面试题
泛型类的声明和非泛型类的声明类似,除了在类名后面添加了类型参数声明部分。和泛型方法一样,泛型类的类型参数声明部分也包含一个或多个类型参数,参数间用逗号隔开。一个泛型参数,也被称为一个类型变量,是用于指定一个泛型类型名称的标识符。因为他们接受一个或多个参数,这些类被称为参数化的类或参数化的类型。
public class Box<T> { private T t; public void add(T t) { this.t = t; } public T get() { return t; }# 194.泛型方法()-Java面试题
你可以写一个泛型方法,该方法在调用时可以接收不同类型的参数。根据传递给泛型方法的参数类型,编译器适当地处理每一个方法调用。
// 泛型方法 printArray public static < E > void printArray( E[] inputArray ) { for ( E element : inputArray ){ System.out.printf( "%s ", element ); } }- <? extends T>表示该通配符所代表的类型是 T 类型的子类。
- <? super T>表示该通配符所代表的类型是 T 类型的父类。
# 193.JAVA 泛型-Java面试题
泛型提供了编译时类型安全检测机制,该机制允许程序员在编译时检测到非法的类型。泛型的本质是参数化类型,也就是说所操作的数据类型被指定为一个参数。比如我们要写一个排序方法,能够对整型数组、字符串数组甚至其他任何类型的数组进行排序,我们就可以使用 Java 泛型。
# 192.匿名内部类(要继承一个父类或者实现一个接口、直接使用 new 来生成一个对象的引用)-Java面试题
匿名内部类我们必须要继承一个父类或者实现一个接口,当然也仅能只继承一个父类或者实现一个接口。同时它也是没有 class 关键字,这是因为匿名内部类是直接使用 new 来生成一个对象的引用。
public abstract class Bird { private String name; public String getName() { return name; } public void setName(String name) { this.name = name; } public abstract int fly(); } public class Test { public void test(Bird bird){ System.out.println(bird.getName() + "能够飞 " + bird.fly() + "米"); } public static void main(String[] args) { Test test = new Test(); test.test(new Bird() { public int fly() { return 10000; } public String getName() { return "大雁"; } }); } }# 191.局部内部类(定义在方法中的类)-Java面试题
定义在方法中的类,就是局部类。如果一个类只在某个方法中使用,则可以考虑使用局部类。
public class Out { private static int a; private int b; public void test(final int c) { final int d = 1; class Inner { public void print() { System.out.println(c); } } } }# 190.成员内部类-Java面试题
定义在类内部的非静态类,就是成员内部类。成员内部类不能定义静态方法和变量(final 修饰的除外)。这是因为成员内部类是非静态的,类初始化的时候先初始化静态成员,如果允许成员内部类定义静态变量,那么成员内部类的静态变量初始化顺序是有歧义的。
public class Out { private static int a; private int b; public class Inner { public void print() { System.out.println(a); System.out.println(b); } } }# 189.静态内部类-Java面试题
定义在类内部的静态类,就是静态内部类。
public class Out { private static int a; private int b; public static class Inner { public void print() { System.out.println(a); } } }- 静态内部类可以访问外部类所有的静态变量和方法,即使是 private 的也一样。
- 静态内部类和一般类一致,可以定义静态变量、方法,构造方法等。
- 其它类使用静态内部类需要使用“外部类.静态内部类”方式,如下所示:Out.Inner inner = new Out.Inner();inner.print();
- Java集合类HashMap内部就有一个静态内部类Entry。Entry是HashMap存放元素的抽象,HashMap 内部维护 Entry 数组用了存放元素,但是 Entry 对使用者是透明的。像这种和外部类关系密切的,且不依赖外部类实例的,都可以使用静态内部类。
# 188.JAVA 内部类-Java面试题
Java 类中不仅可以定义变量和方法,还可以定义类,这样定义在类内部的类就被称为内部类。根据定义的方式不同,内部类分为静态内部类,成员内部类,局部内部类,匿名内部类四种。
# 187.注解处理器-Java面试题
如果没有用来读取注解的方法和工作,那么注解也就不会比注释更有用处了。使用注解的过程中,很重要的一部分就是创建于使用注解处理器。Java SE5 扩展了反射机制的 API,以帮助程序员快速的构造自定义注解处理器。下面实现一个注解处理器。
/1:*** 定义注解*/
@Target(ElementType.FIELD) @Retention(RetentionPolicy.RUNTIME) @Documented public @interface FruitProvider { /供应商编号/ public int id() default -1; /** 供应商名称*/ public String name() default ""; /** * 供应商地址*/ public String address() default ""; } //2:注解使用 public class Apple { @FruitProvider(id = 1, name = "陕西红富士集团", address = "陕西省西安市延安路") private String appleProvider; public void setAppleProvider(String appleProvider) { this.appleProvider = appleProvider; } public String getAppleProvider() { return appleProvider; } } /3:*********** 注解处理器 ***************/ public class FruitInfoUtil { public static void getFruitInfo(Class<?> clazz) { String strFruitProvicer = "供应商信息:"; Field[] fields = clazz.getDeclaredFields();//通过反射获取处理注解 for (Field field : fields) { if (field.isAnnotationPresent(FruitProvider.class)) { FruitProvider fruitProvider = (FruitProvider) field.getAnnotation(FruitProvider.class); //注解信息的处理地方 strFruitProvicer = " 供应商编号:" + fruitProvider.id() + " 供应商名称:"
- fruitProvider.name() + " 供应商地址:"+ fruitProvider.address(); System.out.println(strFruitProvicer); } } } }
public class FruitRun { public static void main(String[] args) { FruitInfoUtil.getFruitInfo(Apple.class); /输出结果****/ // 供应商编号:1 供应商名称:陕西红富士集团 供应商地址:陕西省西安市延 } }
# 186.4 种标准元注解-Java面试题
元注解的作用是负责注解其他注解。 Java5.0 定义了 4 个标准的 meta-annotation 类型,它们被用来提供对其它 annotation 类型作说明。
@Target 修饰的对象范围
@Target说明了Annotation所修饰的对象范围: Annotation可被用于 packages、types(类、接口、枚举、Annotation 类型)、类型成员(方法、构造方法、成员变量、枚举值)、方法参数和本地变量(如循环变量、catch 参数)。在 Annotation 类型的声明中使用了 target 可更加明晰其修饰的目标
@Retention 定义 被保留的时间长短
Retention 定义了该 Annotation 被保留的时间长短:表示需要在什么级别保存注解信息,用于描述注解的生命周期(即:被描述的注解在什么范围内有效),取值(RetentionPoicy)由:
- SOURCE:在源文件中有效(即源文件保留)
- CLASS:在 class 文件中有效(即 class 保留)
- RUNTIME:在运行时有效(即运行时保留)
@Documented 描述-javadoc
@ Documented 用于描述其它类型的 annotation 应该被作为被标注的程序成员的公共 API,因此可以被例如 javadoc 此类的工具文档化。
@Inherited 阐述了某个被标注的类型是被继承的
@Inherited 元注解是一个标记注解,@Inherited 阐述了某个被标注的类型是被继承的。如果一个使用了@Inherited 修饰的 annotation 类型被用于一个 class,则这个 annotation 将被用于该class 的子类。
# 185.JAVA 注解概念-Java面试题
Annotation(注解)是 Java 提供的一种对元程序中元素关联信息和元数据(metadata)的途径和方法。Annatation(注解)是一个接口,程序可以通过反射来获取指定程序中元素的 Annotation对象,然后通过该 Annotation 对象来获取注解中的元数据信息。
# 184.创建对象的两种方法-Java面试题
Class 对象的 newInstance()
使用 Class 对象的 newInstance()方法来创建该 Class 对象对应类的实例,但是这种方法要求该 Class 对象对应的类有默认的空构造器。
调用 Constructor 对象的 newInstance()先使用 Class 对象获取指定的 Constructor 对象,再调用 Constructor 对象的 newInstance()方法来创建 Class 对象对应类的实例,通过这种方法可以选定构造方法创建实例。
# 183.获取 Class 对象的 3 种方法-Java面试题
调用某个对象的 getClass()方法
Person p=new Person(); Class clazz=p.getClass();调用某个类的 class 属性来获取该类对应的 Class 对象
Class clazz=Person.class;使用 Class 类中的 forName()静态方法(最安全/性能最好)
Class clazz=Class.forName("类的全路径"); (最常用)当我们获得了想要操作的类的 Class 对象后,可以通过 Class 类中的方法获取并查看该类中的方法和属性。
//获取 Person 类的 Class 对象 Class clazz=Class.forName("reflection.Person"); //获取 Person 类的所有方法信息 Method[] method=clazz.getDeclaredMethods(); for(Method m:method){ System.out.println(m.toString()); } //获取 Person 类的所有成员属性信息 Field[] field=clazz.getDeclaredFields(); for(Field f:field){ System.out.println(f.toString()); } //获取 Person 类的所有构造方法信息 Constructor[] constructor=clazz.getDeclaredConstructors(); for(Constructor c:constructor){ System.out.println(c.toString()); }# 182.反射使用步骤(获取 Class 对象、调用对象方法)-Java面试题
- 获取想要操作的类的 Class 对象,他是反射的核心,通过 Class 对象我们可以任意调用类的方法。
- 调用 Class 类中的方法,既就是反射的使用阶段。
- 使用反射 API 来操作这些信息。
# 181.Java 反射 API-Java面试题
反射 API 用来生成 JVM 中的类、接口或则对象的信息。
- Class 类:反射的核心类,可以获取类的属性,方法等信息。
- Field 类:Java.lang.reflec 包中的类,表示类的成员变量,可以用来获取和设置类之中的属性值。
- Method 类: Java.lang.reflec 包中的类,表示类的方法,它可以用来获取类中的方法信息或者执行方法。
- Constructor 类: Java.lang.reflec 包中的类,表示类的构造方法。
# 180.反射的应用场合-Java面试题
编译时类型和运行时类型
在 Java 程序中许多对象在运行是都会出现两种类型:编译时类型和运行时类型。 编译时的类型由声明对象时实用的类型来决定,运行时的类型由实际赋值给对象的类型决定 。如:
其中编译时类型为 Person,运行时类型为 Student。
的编译时类型无法获取具体方法
程序在运行时还可能接收到外部传入的对象,该对象的编译时类型为 Object,但是程序有需要调用该对象的运行时类型的方法。为了解决这些问题,程序需要在运行时发现对象和类的真实信息。然而,如果编译时根本无法预知该对象和类属于哪些类,程序只能依靠运行时信息来发现该对象和类的真实信息,此时就必须使用到反射了。
# 179.反射机制概念 (运行状态中知道类所有的属性和方法)-Java面试题
在 Java 中的反射机制是指在运行状态中,对于任意一个类都能够知道这个类所有的属性和方法;并且对于任意一个对象,都能够调用它的任意一个方法;这种动态获取信息以及动态调用对象方法的功能成为 Java 语言的反射机制。
# 177.Throw 和 throws 的区别-Java面试题
位置不同
throws 用在函数上,后面跟的是异常类,可以跟多个;而 throw 用在函数内,后面跟的是异常对象。
功能不同:throws 用来声明异常,让调用者只知道该功能可能出现的问题,可以给出预先的处理方式;throw 抛出具体的问题对象,执行到 throw,功能就已经结束了,跳转到调用者,并将具体的问题对象抛给调用者。也就是说 throw 语句独立存在时,下面不要定义其他语句,因为执行不到。
throws 表示出现异常的一种可能性,并不一定会发生这些异常;throw 则是抛出了异常,执行 throw 则一定抛出了某种异常对象。
两者都是消极处理异常的方式,只是抛出或者可能抛出异常,但是不会由函数去处理异常,真正的处理异常由函数的上层调用处理。
# 176.异常的处理方式-Java面试题
遇到问题不进行具体处理,而是继续抛给调用者(throw,throws)
抛出异常有三种形式,一是 throw,一个 throws,还有一种系统自动抛异常。
public static void main(String[] args) { String s = "abc"; if(s.equals("abc")) { throw new NumberFormatException(); } else { System.out.println(s); } } int div(int a,int b) throws Exception{ return a/b;}try catch 捕获异常针对性处理方式
# 175.异常分类-Java面试题
Throwable 是 Java 语言中所有错误或异常的超类。下一层分为 Error 和 Exception
Error
- Error 类是指 java 运行时系统的内部错误和资源耗尽错误。应用程序不会抛出该类对象。如果出现了这样的错误,除了告知用户,剩下的就是尽力使程序安全的终止。
Exception(RuntimeException、CheckedException)
- Exception 又 有 两 个 分 支 , 一 个 是 运 行 时 异 常 RuntimeException , 一 个 是CheckedException。
RuntimeException
如 : NullPointerException 、 ClassCastException ; 一 个 是 检 查 异 常CheckedException,如 I/O 错误导致的 IOException、SQLException。 RuntimeException 是那些可能在 Java 虚拟机正常运行期间抛出的异常的超类。 如果出现 RuntimeException,那么一定是程序员的错误.
检查异常 CheckedException:
一般是外部错误,这种异常都发生在编译阶段,Java 编译器会强制程序去捕获此类异常,即会出现要求你把这段可能出现异常的程序进行 try catch,该类异常一般包括几个方面:
- 试图在文件尾部读取数据
- 试图打开一个错误格式的 URL
- 试图根据给定的字符串查找 class 对象,而这个字符串表示的类并不存在
# 174.JAVA 异常分类及处理的概念-Java面试题
如果某个方法不能按照正常的途径完成任务,就可以通过另一种路径退出方法。在这种情况下会抛出一个封装了错误信息的对象。此时,这个方法会立刻退出同时不返回任何值。另外,调用这个方法的其他代码也无法继续执行,异常处理机制会将代码执行交给异常处理器。
# ReentrantLock源码分析-Java面试题
回答一个问题
在开始本篇文章的内容讲述前,先来回答我一个问题,为什么 JDK 提供一个 synchronized 关键字之后还要提供一个 Lock 锁,这不是多此一举吗?难道 JDK 设计人员都是沙雕吗?
我听过一句话非常的经典,也是我认为是每个人都应该了解的一句话:你以为的并不是你以为的。明白什么意思么?不明白的话,加我微信我告诉你。
初识 ReentrantLock
ReentrantLock 位于 java.util.concurrent.locks 包下,它实现了 Lock 接口和 Serializable 接口。

ReentrantLock 是一把可重入锁和互斥锁,它具有与 synchronized 关键字相同的含有隐式监视器锁(monitor)的基本行为和语义,但是它比 synchronized 具有更多的方法和功能。
ReentrantLock 基本方法
构造方法
ReentrantLock 类中带有两个构造函数,一个是默认的构造函数,不带任何参数;一个是带有 fair 参数的构造函数
public ReentrantLock() { sync = new NonfairSync(); }public ReentrantLock(boolean fair) { sync = fair ? new FairSync() : new NonfairSync(); }
第二个构造函数也是判断 ReentrantLock 是否是公平锁的条件,如果 fair 为 true,则会创建一个公平锁的实现,也就是 new FairSync(),如果 fair 为 false,则会创建一个 非公平锁的实现,也就是 new NonfairSync(),默认的情况下创建的是非公平锁
// 创建的是非公平锁 private ReentrantLock lock = new ReentrantLock(false);
// 默认创建非公平锁 private ReentrantLock lock = new ReentrantLock();
FairSync 和 NonfairSync 都是 ReentrantLock 的内部类,继承于 Sync 类,下面来看一下它们的继承结构,便于梳理。

static final class FairSync extends Sync {...}
static final class NonfairSync extends Sync {...}
在多线程尝试加锁时,如果是公平锁,那么锁获取的机会是相同的。否则,如果是非公平锁,那么 ReentrantLock 则不会保证每个锁的访问顺序。
下面是一个公平锁的实现
private ReentrantLock lock = new ReentrantLock(true);
public void fairLock(){
try {
lock.lock();
System.out.println(Thread.currentThread().getName() + "正在持有锁");
}finally {
System.out.println(Thread.currentThread().getName() + "释放了锁");
lock.unlock();
}
}
public static void main(String[] args) {
MyFairLock myFairLock = new MyFairLock();
Runnable runnable = () -> {
System.out.println(Thread.currentThread().getName() + "启动");
myFairLock.fairLock();
};
Thread[] thread = new Thread[10];
for(int i = 0;i < 10;i++){
thread[i] = new Thread(runnable);
}
for(int i = 0;i < 10;i++){
thread[i].start();
}
}
}
不信?不信你输出试试啊!懒得输出?就知道你懒得输出,所以直接告诉你结论吧,结论就是自己试。
试完了吗?试完了我是不会让你休息的,过来再试一下非公平锁的测试和结论,知道怎么试吗?上面不是讲过要给 ReentrantLock 传递一个参数的吗?你想,传 true 的时候是公平锁,那么反过来不就是非公平锁了?其他代码还用改吗?不需要了啊。
明白了吧,再来测试一下非公平锁的流程,看看是不是你想要的结果。
公平锁的加锁(lock)流程详解
通常情况下,使用多线程访问公平锁的效率会非常低(通常情况下会慢很多),但是 ReentrantLock 会保证每个线程都会公平的持有锁,线程饥饿的次数比较小。锁的公平性并不能保证线程调度的公平性。
此时如果你想了解更多的话,那么我就从源码的角度跟你聊聊如何 ReentrantLock 是如何实现这两种锁的。

如上图所示,公平锁的加锁流程要比非公平锁的加锁流程简单,下面要聊一下具体的流程了,请小伙伴们备好板凳。
下面先看一张流程图,这张图是 acquire 方法的三条主要流程

首先是第一条路线,tryAcquire 方法,顾名思义尝试获取,也就是说可以成功获取锁,也可以获取锁失败。
使用 ctrl+左键 点进去是调用 AQS 的方法,但是 ReentrantLock 实现了 AQS 接口,所以调用的是 ReentrantLock 的 tryAcquire 方法;

首先会取得当前线程,然后去读取当前锁的同步状态,还记得锁的四种状态吗?分别是 无锁、偏向锁、轻量级锁和重量级锁,如果你不是很明白的话,请参考博主这篇文章(不懂什么是锁?看看这篇你就明白了),如果判断同步状态是 0 的话,就证明是无锁的,参考下面这幅图( 1bit 表示的是是否偏向锁 )

如果是无锁(也就是没有加锁),说明是第一次上锁,首先会先判断一下队列中是否有比当前线程等待时间更长的线程(hasQueuedPredecessors);然后通过 CAS 方法原子性的更新锁的状态,CAS 方法更新的要求涉及三个变量,currentValue(当前线程的值),expectedValue(期望更新的值),updateValue(更新的值),它们的更新如下
CAS 通过 C 底层机制保证原子性,这个你不需要考虑它。如果既没有排队的线程而且使用 CAS 方法成功的把 0 -> 1 (偏向锁),那么当前线程就会获得偏向锁,记录获取锁的线程为当前线程。
然后我们看 else if 逻辑,如果读取的同步状态是1,说明已经线程获取到了锁,那么就先判断当前线程是不是获取锁的线程,如果是的话,记录一下获取锁的次数 + 1,也就是说,只有同步状态为 0 的时候是无锁状态。如果当前线程不是获取锁的线程,直接返回 false。
acquire 方法会先查看同步状态是否获取成功,如果成功则方法结束返回,也就是 !tryAcquire == false ,若失败则先调用 addWaiter 方法再调用 acquireQueued 方法
然后看一下第二条路线 addWaiter

这里首先把当前线程和 Node 的节点类型进行封装,Node 节点的类型有两种,EXCLUSIVE 和 SHARED ,前者为独占模式,后者为共享模式,具体的区别我们会在 AQS 源码讨论,这里读者只需要知道即可。
首先会进行 tail 节点的判断,有没有尾节点,其实没有头节点也就相当于没有尾节点,如果有尾节点,就会原子性的将当前节点插入同步队列中,再执行 enq 入队操作,入队操作相当于原子性的把节点插入队列中。
如果当前同步队列尾节点为null,说明当前线程是第一个加入同步队列进行等待的线程。
在看第三条路线 acquireQueued

主要会有两个分支判断,首先会进行无限循环中,循环中每次都会判断给定当前节点的先驱节点,如果没有先驱节点会直接抛出空指针异常,直到返回 true。
然后判断给定节点的先驱节点是不是头节点,并且当前节点能否获取独占式锁,如果是头节点并且成功获取独占锁后,队列头指针用指向当前节点,然后释放前驱节点。如果没有获取到独占锁,就会进入 shouldParkAfterFailedAcquire 和 parkAndCheckInterrupt 方法中,我们贴出这两个方法的源码

shouldParkAfterFailedAcquire 方法主要逻辑是使用compareAndSetWaitStatus(pred, ws, Node.SIGNAL)使用CAS将节点状态由 INITIAL 设置成 SIGNAL,表示当前线程阻塞。当 compareAndSetWaitStatus 设置失败则说明 shouldParkAfterFailedAcquire 方法返回 false,然后会在 acquireQueued 方法中死循环中会继续重试,直至compareAndSetWaitStatus 设置节点状态位为 SIGNAL 时 shouldParkAfterFailedAcquire 返回 true 时才会执行方法 parkAndCheckInterrupt 方法。(这块在后面研究 AQS 会细讲)
parkAndCheckInterrupt 该方法的关键是会调用 LookSupport.park 方法(关于LookSupport会在以后的文章进行讨论),该方法是用来阻塞当前线程。
所以 acquireQueued 主要做了两件事情:如果当前节点的前驱节点是头节点,并且能够获取独占锁,那么当前线程能够获得锁该方法执行结束退出
如果获取锁失败的话,先将节点状态设置成 SIGNAL,然后调用 LookSupport.park 方法使得当前线程阻塞。
如果 !tryAcquire 和 acquireQueued 都为 true 的话,则打断当前线程。
那么它们的主要流程如下(注:只是加锁流程,并不是 lock 所有流程)

非公平锁的加锁(lock)流程详解
非公平锁的加锁步骤和公平锁的步骤只有两处不同,一处是非公平锁在加锁前会直接使用 CAS 操作设置同步状态,如果设置成功,就会把当前线程设置为偏向锁的线程;一处是 CAS 操作失败执行 tryAcquire 方法,读取线程同步状态,如果未加锁会使用 CAS 再次进行加锁,不会等待 hasQueuedPredecessors 方法的执行,达到只要线程释放锁就会加锁的目的。下面通过源码和流程图来详细理解

这是非公平锁和公平锁不同的两处地方,下面是非公平锁的加锁流程图

lockInterruptibly 以可中断的方式获取锁
以下是 JavaDoc 官方解释:
lockInterruptibly 的中文意思为如果没有被打断,则获取锁。如果没有其他线程持有该锁,则获取该锁并立即返回,将锁保持计数设置为1。如果当前线程已经持有锁,那么此方法会立刻返回并且持有锁的数量会 + 1。如果锁是由另一个线程持有的,则出于线程调度目的,当前线程将被禁用,并处于休眠状态,直到发生以下两种情况之一
- 锁被当前线程持有
- 一些其他线程打断了当前线程
如果当前线程获取了锁,则锁保持计数将设置为1。
如果当前线程发生了如下情况:
- 在进入此方法时设置了其中断状态
- 当获取锁的时候发生了中断(Thread.interrupt)
那么当前线程就会抛出InterruptedException 并且当前线程的中断状态会清除。
下面看一下它的源码是怎么写的

首先会调用 acquireInterruptibly 这个方法,判断当前线程是否被中断,如果中断抛出异常,没有中断则判断公平锁/非公平锁 是否已经获取锁,如果没有获取锁(tryAcquire 返回 false)则调用 doAcquireInterruptibly 方法,这个方法和 acquireQueued 方法没什么区别,就是线程在等待状态的过程中,如果线程被中断,线程会抛出异常。
下面是它的流程图

tryLock 尝试加锁
仅仅当其他线程没有获取这把锁的时候获取这把锁,tryLock 的源代码和非公平锁的加锁流程基本一致,它的源代码如下

tryLock 超时获取锁
ReentrantLock除了能以中断的方式去获取锁,还可以以超时等待的方式去获取锁,所谓超时等待就是线程如果在超时时间内没有获取到锁,那么就会返回false,而不是一直死循环获取。可以使用 tryLock 和 tryLock(timeout, unit)) 结合起来实现公平锁,像这样
如果超过了指定时间,则返回值为 false。如果时间小于或者等于零,则该方法根本不会等待。
它的源码如下

首先需要了解一下 TimeUnit 工具类,TimeUnit 表示给定粒度单位的持续时间,并且提供了一些用于时分秒跨单位转换的方法,通过使用这些方法进行定时和延迟操作。
toNanos 用于把 long 型表示的时间转换成为纳秒,然后判断线程是否被打断,如果没有打断,则以公平锁/非公平锁 的方式获取锁,如果能够获取返回true,获取失败则调用doAcquireNanos方法使用超时等待的方式获取锁。在超时等待获取锁的过程中,如果等待时间大于应等待时间,或者应等待时间设置不合理的话,返回 false。

这里面以超时的方式获取锁也可以画一张流程图如下

unlock 解锁流程
unlock 和 lock 是一对情侣,它们分不开彼此,在调用 lock 后必须通过 unlock 进行解锁。如果当前线程持有锁,在调用 unlock 后,count 计数将减少。如果保持计数为0就会进行解锁。如果当前线程没有持有锁,在调用 unlock 会抛出 IllegalMonitorStateException 异常。下面是它的源码

在有了上面阅读源码的经历后,相信你会很快明白这段代码的意思,锁的释放不会区分公平锁还是非公平锁,主要的判断逻辑就是 tryRelease 方法,getState 方法会取得同步锁的重入次数,如果是获取了偏向锁,那么可能会多次获取,state 的值会大于 1,这时候 c 的值 > 0 ,返回 false,解锁失败。如果 state = 1,那么 c = 0,再判断当前线程是否是独占锁的线程,释放独占锁,返回 true,当 head 指向的头结点不为 null,并且该节点的状态值不为0的话才会执行 unparkSuccessor 方法,再进行锁的获取。

ReentrantLock 其他方法
isHeldByCurrentThread & getHoldCount
在多线程同时访问时,ReentrantLock 由最后一次成功锁定的线程拥有,当这把锁没有被其他线程拥有时,线程调用 lock() 方法会立刻返回并成功获取锁。如果当前线程已经拥有锁,这个方法会立刻返回。可以通过 isHeldByCurrentThread 和 getHoldCount 来进行检查。
首先来看 isHeldByCurrentThread 方法
public boolean isHeldByCurrentThread() { return sync.isHeldExclusively(); }根据方法名可以略知一二,是否被当前线程持有,它用来询问锁是否被其他线程拥有,这个方法和 Thread.holdsLock(Object) 方法内置的监视器锁相同,而 Thread.holdsLock(Object) 是 Thread 类的静态方法,是一个 native 类,它表示的意思是如果当前线程在某个对象上持有 monitor lock(监视器锁) 就会返回 true。这个类没有实际作用,仅仅用来测试和调试所用。例如
public void lock(){ assert lock.isHeldByCurrentThread(); }
这个方法也可以确保重入锁能够表现出不可重入的行为
public void lock(){ assert !lock.isHeldByCurrentThread(); lock.lock(); try { // 执行业务代码 }finally { lock.unlock(); } }
如果当前线程持有锁则 lock.isHeldByCurrentThread() 返回 true,否则返回 false。
我们在了解它的用法后,看一下它内部是怎样实现的,它内部只是调用了一下 sync.isHeldExclusively(),sync 是 ReentrantLock 的一个静态内部类,基于 AQS 实现,而 AQS 它是一种抽象队列同步器,是许多并发实现类的基础,例如 ReentrantLock/Semaphore/CountDownLatch。sync.isHeldExclusively() 方法如下
此方法会在拥有锁之前先去读一下状态,如果当前线程是锁的拥有者,则不需要检查。
getHoldCount()方法和isHeldByCurrentThread 都是用来检查线程是否持有锁的方法,不同之处在于 getHoldCount() 用来查询当前线程持有锁的数量,对于每个未通过解锁操作匹配的锁定操作,线程都会保持锁定状态,这个方法也通常用于调试和测试,例如
public void lock(){ assert lock.getHoldCount() == 0; lock.lock(); try { // 执行业务代码 }finally { lock.unlock(); } }
这个方法会返回当前线程持有锁的次数,如果当前线程没有持有锁,则返回0。
newCondition 创建 ConditionObject 对象
ReentrantLock 可以通过 newCondition 方法创建 ConditionObject 对象,而 ConditionObject 实现了 Condition 接口,关于 Condition 的用法我们后面再讲。
isLocked 判断是否锁定
查询是否有任意线程已经获取锁,这个方法用来监视系统状态,而不是用来同步控制,很简单,直接判断 state 是否等于0。
isFair 判断是否是公平锁的实例
这个方法也比较简单,直接使用 instanceof 判断是不是 FairSync 内部类的实例
getOwner 判断锁拥有者
判断同步状态是否为0,如果是0,则没有线程拥有锁,如果不是0,直接返回获取锁的线程。
final Thread getOwner() { return getState() == 0 ? null : getExclusiveOwnerThread(); }hasQueuedThreads 是否有等待线程
判断是否有线程正在等待获取锁,如果头节点与尾节点不相等,说明有等待获取锁的线程。
public final boolean hasQueuedThreads() { return head != tail; }isQueued 判断线程是否排队
判断给定的线程是否正在排队,如果正在排队,返回 true。这个方法会遍历队列,如果找到匹配的线程,返回true
public final boolean isQueued(Thread thread) { if (thread == null) throw new NullPointerException(); for (Node p = tail; p != null; p = p.prev) if (p.thread == thread) return true; return false; }getQueueLength 获取队列长度
此方法会返回一个队列长度的估计值,该值只是一个估计值,因为在此方法遍历内部数据结构时,线程数可能会动态变化。 此方法设计用于监视系统状态,而不用于同步控制。
public final int getQueueLength() { int n = 0; for (Node p = tail; p != null; p = p.prev) { if (p.thread != null) ++n; } return n; }getQueuedThreads 获取排队线程
返回一个包含可能正在等待获取此锁的线程的集合。 因为实际的线程集在构造此结果时可能会动态更改,所以返回的集合只是一个大概的列表集合。 返回的集合的元素没有特定的顺序。
public final Collection<Thread> getQueuedThreads() { ArrayList<Thread> list = new ArrayList<Thread>(); for (Node p = tail; p != null; p = p.prev) { Thread t = p.thread; if (t != null) list.add(t); } return list; }回答上面那个问题
那么你看完源码分析后,你能总结出 synchronized 和 lock 锁的实现 ReentrantLock 有什么异同吗?
Synchronzied 和 Lock 的主要区别如下:
存在层面:Syncronized 是Java 中的一个关键字,存在于 JVM 层面,Lock 是 Java 中的一个接口
锁的释放条件:1. 获取锁的线程执行完同步代码后,自动释放;2. 线程发生异常时,JVM会让线程释放锁;Lock 必须在 finally 关键字中释放锁,不然容易造成线程死锁
锁的获取: 在 Syncronized 中,假设线程 A 获得锁,B 线程等待。如果 A 发生阻塞,那么 B 会一直等待。在 Lock 中,会分情况而定,Lock 中有尝试获取锁的方法,如果尝试获取到锁,则不用一直等待
锁的状态:Synchronized 无法判断锁的状态,Lock 则可以判断
锁的类型:Synchronized 是可重入,不可中断,非公平锁;Lock 锁则是 可重入,可判断,可公平锁
锁的性能:Synchronized 适用于少量同步的情况下,性能开销比较大。Lock 锁适用于大量同步阶段:
Lock 锁可以提高多个线程进行读的效率(使用 readWriteLock)
在竞争不是很激烈的情况下,Synchronized的性能要优于ReetrantLock,但是在资源竞争很激烈的情况下,Synchronized的性能会下降几十倍,但是ReetrantLock的性能能维持常态;
ReetrantLock 提供了多样化的同步,比如有时间限制的同步,可以被Interrupt的同步(synchronized的同步是不能Interrupt的)等
还有什么要说的吗
面试官可能还会问你 ReentrantLock 的加锁流程是怎样的,其实如果你能把源码给他讲出来的话,一定是高分。如果你记不住源码流程的话可以记住下面这个简化版的加锁流程
如果 lock 加锁设置成功,设置当前线程为独占锁的线程;
如果 lock 加锁设置失败,还会再尝试获取一次锁数量,
如果锁数量为0,再基于 CAS 尝试将 state(锁数量)从0设置为1一次,如果设置成功,设置当前线程为独占锁的线程;
如果锁数量不为0或者上边的尝试又失败了,查看当前线程是不是已经是独占锁的线程了,如果是,则将当前的锁数量+1;如果不是,则将该线程封装在一个Node内,并加入到等待队列中去。等待被其前一个线程节点唤醒。
# 看完你就明白的锁系列之锁的状态-Java面试题
看完你就会知道,线程如果锁住了某个资源,致使其他线程无法访问的这种锁被称为悲观锁,相反,线程不锁住资源的锁被称为乐观锁,而自旋锁是基于 CAS 机制实现的,CAS又是乐观锁的一种实现,那么对于锁来说,多个线程同步访问某个资源的流程细节是否一样呢?换句话说,在多线程同步访问某个资源时,锁的状态会如何变化呢?本篇文章来探讨一下。
锁状态的分类
Java 语言专门针对 synchronized 关键字设置了四种状态,它们分别是:无锁、偏向锁、轻量级锁和重量级锁,但是在了解这些锁之前还需要先了解一下 Java 对象头和 Monitor。
Java 对象头
我们知道 synchronized 是悲观锁,在操作同步之前需要给资源加锁,这把锁就是对象头里面的,而Java 对象头又是什么呢?我们以 Hotspot 虚拟机为例,Hopspot 对象头主要包括两部分数据:Mark Word(标记字段) 和 Klass Pointer(类型指针)。
Mark Word:默认存储对象的HashCode,分代年龄和锁标志位信息。这些信息都是与对象自身定义无关的数据,所以Mark Word被设计成一个非固定的数据结构以便在极小的空间内存存储尽量多的数据。它会根据对象的状态复用自己的存储空间,也就是说在运行期间Mark Word里存储的数据会随着锁标志位的变化而变化。
Klass Point:对象指向它的类元数据的指针,虚拟机通过这个指针来确定这个对象是哪个类的实例。
在32位虚拟机和64位虚拟机的 Mark Word 所占用的字节大小不一样,32位虚拟机的 Mark Word 和 Klass Pointer 分别占用 32bits 的字节,而 64位虚拟机的 Mark Word 和 Klass Pointer 占用了64bits 的字节,下面我们以 32位虚拟机为例,来看一下其 Mark Word 的字节具体是如何分配的


用中文翻译过来就是

- 无状态也就是
无锁的时候,对象头开辟 25bit 的空间用来存储对象的 hashcode ,4bit 用于存放分代年龄,1bit 用来存放是否偏向锁的标识位,2bit 用来存放锁标识位为01 偏向锁中划分更细,还是开辟25bit 的空间,其中23bit 用来存放线程ID,2bit 用来存放 epoch,4bit 存放分代年龄,1bit 存放是否偏向锁标识, 0表示无锁,1表示偏向锁,锁的标识位还是01轻量级锁中直接开辟 30bit 的空间存放指向栈中锁记录的指针,2bit 存放锁的标志位,其标志位为00重量级锁中和轻量级锁一样,30bit 的空间用来存放指向重量级锁的指针,2bit 存放锁的标识位,为11GC标记开辟30bit 的内存空间却没有占用,2bit 空间存放锁标志位为11。
其中无锁和偏向锁的锁标志位都是01,只是在前面的1bit区分了这是无锁状态还是偏向锁状态。
关于为什么这么分配的内存,我们可以从 OpenJDK 中的markOop.hpp类中的枚举窥出端倪

来解释一下
- age_bits 就是我们说的分代回收的标识,占用4字节
- lock_bits 是锁的标志位,占用2个字节
- biased_lock_bits 是是否偏向锁的标识,占用1个字节
- max_hash_bits 是针对无锁计算的hashcode 占用字节数量,如果是32位虚拟机,就是 32 – 4 – 2 -1 = 25 byte,如果是64 位虚拟机,64 – 4 – 2 – 1 = 57 byte,但是会有 25 字节未使用,所以64位的 hashcode 占用 31 byte
- hash_bits 是针对 64 位虚拟机来说,如果最大字节数大于 31,则取31,否则取真实的字节数
- cms_bits 我觉得应该是不是64位虚拟机就占用 0 byte,是64位就占用 1byte
- epoch_bits 就是 epoch 所占用的字节大小,2字节。
Synchronized锁
synchronized用的锁是存在Java对象头里的。
JVM基于进入和退出 Monitor 对象来实现方法同步和代码块同步。代码块同步是使用 monitorenter 和 monitorexit 指令实现的,monitorenter 指令是在编译后插入到同步代码块的开始位置,而 monitorexit 是插入到方法结束处和异常处。任何对象都有一个 monitor 与之关联,当且一个 monitor 被持有后,它将处于锁定状态。
根据虚拟机规范的要求,在执行 monitorenter 指令时,首先要去尝试获取对象的锁,如果这个对象没被锁定,或者当前线程已经拥有了那个对象的锁,把锁的计数器加1,相应地,在执行 monitorexit 指令时会将锁计数器减1,当计数器被减到0时,锁就释放了。如果获取对象锁失败了,那当前线程就要阻塞等待,直到对象锁被另一个线程释放为止。
Monitor
Synchronized是通过对象内部的一个叫做监视器锁(monitor)来实现的,监视器锁本质又是依赖于底层的操作系统的 Mutex Lock(互斥锁)来实现的。而操作系统实现线程之间的切换需要从用户态转换到核心态,这个成本非常高,状态之间的转换需要相对比较长的时间,这就是为什么 Synchronized 效率低的原因。因此,这种依赖于操作系统 Mutex Lock 所实现的锁我们称之为重量级锁。
Java SE 1.6为了减少获得锁和释放锁带来的性能消耗,引入了偏向锁和轻量级锁:锁一共有4种状态,级别从低到高依次是:无锁状态、偏向锁状态、轻量级锁状态和重量级锁状态。锁可以升级但不能降级。
所以锁的状态总共有四种:无锁状态、偏向锁、轻量级锁和重量级锁。随着锁的竞争,锁可以从偏向锁升级到轻量级锁,再升级的重量级锁(但是锁的升级是单向的,也就是说只能从低到高升级,不会出现锁的降级)。JDK 1.6中默认是开启偏向锁和轻量级锁的,我们也可以通过-XX:-UseBiasedLocking=false来禁用偏向锁。
锁的分类及其解释
无锁
无锁状态,无锁即没有对资源进行锁定,所有的线程都可以对同一个资源进行访问,但是只有一个线程能够成功修改资源。
无锁的特点就是在循环内进行修改操作,线程会不断的尝试修改共享资源,直到能够成功修改资源并退出,在此过程中没有出现冲突的发生,这很像我们在之前文章中介绍的 CAS 实现,CAS 的原理和应用就是无锁的实现。无锁无法全面代替有锁,但无锁在某些场合下的性能是非常高的。
偏向锁
Hotspot 的作者经过研究发现,大多数情况下,锁不仅不存在多线程竞争,还存在锁由同一线程多次获得的情况,偏向锁就是在这种情况下出现的,它的出现是为了解决只有在一个线程执行同步时提高性能。
可以从对象头的分配中看到,偏向锁要比无锁多了线程ID 和 epoch,当一个线程访问同步代码块并获取锁时,会在对象头和栈帧的记录中存储线程的ID,等到下一次线程在进入和退出同步代码块时就不需要进行 CAS 操作进行加锁和解锁,只需要简单判断一下对象头的 Mark Word 中是否存储着指向当前线程的线程ID,判断的标志当然是根据锁的标志位来判断的。
偏向锁的获取过程
访问 Mark Word 中偏向锁的标志是否设置成 1,锁的标志位是否是 01 — 确认为可偏向状态。
如果确认为可偏向状态,判断当前线程id 和 对象头中存储的线程 ID 是否一致,如果一致的话,则执行步骤5,如果不一致,进入步骤3
如果当前线程ID 与对象头中存储的线程ID 不一致的话,则通过 CAS 操作来竞争获取锁。如果竞争成功,则将 Mark Word 中的线程ID 修改为当前线程ID,然后执行步骤5,如果不一致,则执行步骤4
如果 CAS 获取偏向锁失败,则表示有竞争(CAS 获取偏向锁失败则表明至少有其他线程曾经获取过偏向锁,因为线程不会主动释放偏向锁)。当到达全局安全点(SafePoint)时,会首先暂停拥有偏向锁的线程,然后检查持有偏向锁的线程是否存活(因为可能持有偏向锁的线程已经执行完毕,但是该线程并不会主动去释放偏向锁),如果线程不处于活动状态,则将对象头置为
无锁状态(标志位为01),然后重新偏向新的线程;如果线程仍然活着,撤销偏向锁后升级到轻量级锁的状态(标志位为00),此时轻量级锁由原持有偏向锁的线程持有,继续执行其同步代码,而正在竞争的线程会进入自旋等待获得该轻量级锁。执行同步代码
偏向锁的释放过程
偏向锁的释放过程可以参考上述的步骤4 ,偏向锁在遇到其他线程竞争锁时,持有偏向锁的线程才会释放锁,线程不会主动释放偏向锁。偏向锁的撤销,需要等待全局安全点(在这个时间点上没有字节码正在执行),它会首先暂停拥有偏向锁的线程,判断锁是否处于被锁定状态,撤销偏向锁后恢复到未锁定(标志位为01)或轻量级锁(标志位为00)的状态。
关闭偏向锁
偏向锁在Java 6 和Java 7 里是默认启用的。由于偏向锁是为了在只有一个线程执行同步块时提高性能,如果你确定应用程序里所有的锁通常情况下处于竞争状态,可以通过JVM参数关闭偏向锁:-XX:-UseBiasedLocking=false,那么程序默认会进入轻量级锁状态。
关于 epoch
真正理解 epoch 的概念比较复杂,这里简单理解,就是 epoch 的值可以作为一种检测偏向锁有效性的时间戳
轻量级锁
轻量级锁是指当前锁是偏向锁的时候,被另外的线程所访问,那么偏向锁就会升级为轻量级锁,其他线程会通过自旋的形式尝试获取锁,不会阻塞,从而提高性能。
加锁过程
在代码进入同步块的时候,如果同步对象锁状态为无锁状态(锁标志位为 01 状态,是否为偏向锁为 0 ),虚拟机首先将在当前线程的栈帧中建立一个名为锁记录(Lock Record)的空间,用于存储锁对象目前的 Mark Word 的拷贝,然后拷贝对象头中的 Mark Word 复制到锁记录中。

拷贝成功后,虚拟机将使用 CAS 操作尝试将对象的 Mark Word 更新为指向 Lock Record 的指针,并将 Lock Record里的 owner 指针指向对象的 Mark Word。
如果这个更新动作成功了,那么这个线程就拥有了该对象的锁,并且对象Mark Word的锁标志位设置为 00 ,表示此对象处于轻量级锁定状态。

如果这个更新操作失败了,虚拟机首先会检查对象的 Mark Word 是否指向当前线程的栈帧,如果是就说明当前线程已经拥有了这个对象的锁,那就可以直接进入同步块继续执行。否则说明多个线程竞争锁,轻量级锁就要膨胀为重量级锁,锁标志的状态值变为 10 ,Mark Word中存储的就是指向重量级锁(互斥量)的指针,后面等待锁的线程也要进入阻塞状态。
重量级锁
重量级锁也就是通常说 synchronized 的对象锁,锁标识位为10,其中指针指向的是 monitor 对象(也称为管程或监视器锁)的起始地址。每个对象都存在着一个 monitor 与之关联,对象与其 monitor 之间的关系有存在多种实现方式,如 monitor 可以与对象一起创建销毁或当线程试图获取对象锁时自动生成,但当一个 monitor 被某个线程持有后,它便处于锁定状态。

上图简单描述多线程获取锁的过程,当多个线程同时访问一段同步代码时,首先会进入 Entry Set当线程获取到对象的 monitor 后进入 The Owner 区域并把 monitor 中的 owner 变量设置为当前线程,同时 monitor 中的计数器count 加1,若线程调用 wait() 方法,将释放当前持有的 monitor,owner变量恢复为 null,count自减1,同时该线程进入 WaitSet 集合中等待被唤醒。若当前线程执行完毕也将释放 monitor (锁)并复位变量的值,以便其他线程进入获取monitor(锁)。
由此看来,monitor 对象存在于每个Java对象的对象头中(存储的指针的指向),synchronized 锁便是通过这种方式获取锁的,也是为什么Java中任意对象可以作为锁的原因,同时也是 notify/notifyAll/wait 等方法存在于顶级对象Object中的原因。(部分来源于网络)
# Semaphore用法和源码解析-Java面试题
这是并发线程工具类的第二篇文章,在第一篇中,我们分析过 CountDownLatch 的相关内容,你可以参考
那么本篇文章我们继续来和你聊聊并发工具类的第二篇文章 — Semaphore 。
认识 Semaphore
Semaphore 是什么
Semaphore 一般译作 信号量,它也是一种线程同步工具,主要用于多个线程对共享资源进行并行操作的一种工具类。它代表了一种许可的概念,是否允许多线程对同一资源进行操作的许可,使用 Semaphore 可以控制并发访问资源的线程个数。
Semaphore 的使用场景
Semaphore 的使用场景主要用于流量控制,比如数据库连接,同时使用的数据库连接会有数量限制,数据库连接不能超过一定的数量,当连接到达了限制数量后,后面的线程只能排队等前面的线程释放数据库连接后才能获得数据库连接。
再比如交通公路上的红绿灯,绿灯亮起时只能让 100 辆车通过,红灯亮起不允许车辆通过。
再比如停车场的场景中,一个停车场有有限数量的车位,同时能够容纳多少台车,车位满了之后只有等里面的车离开停车场外面的车才可以进入。
Semaphore 使用
下面我们就来模拟一下停车场的业务场景:在进入停车场之前会有一个提示牌,上面显示着停车位还有多少,当车位为 0 时,不能进入停车场,当车位不为 0 时,才会允许车辆进入停车场。所以停车场有几个关键因素:停车场车位的总容量,当一辆车进入时,停车场车位的总容量 – 1,当一辆车离开时,总容量 + 1,停车场车位不足时,车辆只能在停车场外等待。
public class CarParking {private static Semaphore semaphore = new Semaphore(10);
public static void main(String[] args){
for(int i = 0;i< 100;i++){
Thread thread = new Thread(new Runnable() {
@Override
public void run() {
System.out.println("欢迎 " + Thread.currentThread().getName() + " 来到停车场");
// 判断是否允许停车
if(semaphore.availablePermits() == 0) {
System.out.println("车位不足,请耐心等待");
}
try {
// 尝试获取
semaphore.acquire();
System.out.println(Thread.currentThread().getName() + " 进入停车场");
Thread.sleep(new Random().nextInt(10000));// 模拟车辆在停车场停留的时间
System.out.println(Thread.currentThread().getName() + " 驶出停车场");
semaphore.release();
} catch (InterruptedException e) {
e.printStackTrace();
}
}
}, i + "号车");
thread.start();
}
}
}
在上面这段代码中,我们给出了 Semaphore 的初始容量,也就是只有 10 个车位,我们用这 10 个车位来控制 100 辆车的流量,所以结果和我们预想的很相似,即大部分车都在等待状态。但是同时仍允许一些车驶入停车场,驶入停车场的车辆,就会 semaphore.acquire 占用一个车位,驶出停车场时,就会 semaphore.release 让出一个车位,让后面的车再次驶入。
Semaphore 信号量的模型
上面代码虽然比较简单,但是却能让我们了解到一个信号量模型的五脏六腑。下面是一个信号量的模型:

来解释一下 Semaphore ,Semaphore 有一个初始容量,这个初始容量就是 Semaphore 所能够允许的信号量。在调用 Semaphore 中的 acquire 方法后,Semaphore 的容量 -1,相对的在调用 release 方法后,Semaphore 的容量 + 1,在这个过程中,计数器一直在监控 Semaphore 数量的变化,等到流量超过 Semaphore 的容量后,多余的流量就会放入等待队列中进行排队等待。等到 Semaphore 的容量允许后,方可重新进入。
Semaphore 所控制的流量其实就是一个个的线程,因为并发工具最主要的研究对象就是线程。
它的工作流程如下

这幅图应该很好理解吧,这里就不再过多解释啦。
Semaphore 深入理解
在了解 Semaphore 的基本使用和 Semaphore 的模型后,下面我们还是得从源码来和你聊一聊 Semaphore 的种种细节问题,因为我写文章最核心的东西就是想让我的读者 了解 xxx,看这一篇就够了,这是我写文章的追求,好了话不多说,源码走起来!
Semaphore 基本属性
Semaphore 中只有一个属性
private final Sync sync;Sync 是 Semaphore 的同步实现,Semaphore 保证线程安全性的方式和 ReentrantLock 、CountDownLatch 类似,都是继承于 AQS 的实现。同样的,这个 Sync 也是继承于 AbstractQueuedSynchronizer 的一个变量,也就是说,聊 Semaphore 也绕不开 AQS,所以说 AQS 真的太重要了。
Semaphore 的公平性和非公平性
那么我们进入 Sync 内部看看它实现了哪些方法
abstract static class Sync extends AbstractQueuedSynchronizer { private static final long serialVersionUID = 1192457210091910933L;Sync(int permits) { setState(permits); }
final int getPermits() { return getState(); }
final int nonfairTryAcquireShared(int acquires) { for (;😉 { int available = getState(); int remaining = available - acquires; if (remaining < 0 || compareAndSetState(available, remaining)) return remaining; } }
protected final boolean tryReleaseShared(int releases) { for (;😉 { int current = getState(); int next = current + releases; if (next < current) // overflow throw new Error("Maximum permit count exceeded"); if (compareAndSetState(current, next)) return true; } }
final void reducePermits(int reductions) { for (;😉 { int current = getState(); int next = current - reductions; if (next > current) // underflow throw new Error("Permit count underflow"); if (compareAndSetState(current, next)) return; } }
final int drainPermits() { for (;😉 { int current = getState(); if (current == 0 || compareAndSetState(current, 0)) return current; } } }
首先是 Sync 的初始化,内部调用了 setState 并传递了 permits ,我们知道,AQS 中的 State 其实就是同步状态的值,而 Semaphore 的这个 permits 就是代表了许可的数量。
getPermits 其实就是调用了 getState 方法获取了一下线程同步状态值。后面的 nonfairTryAcquireShared 方法其实是在 Semaphore 中构造了 NonfairSync 中的 tryAcquireShared 调用的

这里需要提及一下什么是 NonfairSync,除了 NonfairSync 是不是还有 FairSync 呢?查阅 JDK 源码发现确实有。
那么这里的 FairSync 和 NonfairSync 都代表了什么?为什么会有这两个类呢?
事实上,Semaphore 就像 ReentrantLock 一样,也存在“公平”和"不公平"两种,默认情况下 Semaphore 是一种不公平的信号量

Semaphore 的不公平意味着它不会保证线程获得许可的顺序,Semaphore 会在线程等待之前为调用 acquire 的线程分配一个许可,拥有这个许可的线程会自动将自己置于线程等待队列的头部。
当这个参数为 true 时,Semaphore 确保任何调用 acquire 的方法,都会按照先入先出的顺序来获取许可。
final int nonfairTryAcquireShared(int acquires) { for (;😉 { // 获取同步状态值 int available = getState(); // state 的值 - 当前线程需要获取的信号量(通常默认是 -1),只有 // remaining > 0 才表示可以获取。 int remaining = available - acquires; // 先判断是否小于 0 ,如果小于 0 则表示无法获取,如果是正数 // 就需要使用 CAS 判断内存值和同步状态值是否一致,然后更新为同步状态值 - 1 if (remaining < 0 || compareAndSetState(available, remaining)) return remaining; } }
从上面这幅源码对比图可以看到,NonfairSync 和 FairSync 最大的区别就在于 tryAcquireShared 方法的区别。
NonfairSync 版本中,是不会管当前等待队列中是否有排队许可的,它会直接判断信号许可量和 CAS 方法的可行性。
FairSync 版本中,它首先会判断是否有许可进行排队,如果有的话就直接获取失败。
这时候可能就会有读者问了,你上面说公平性和非公平性的区别一直针对的是 acquire 方法来说的,怎么现在他们两个主要的区别在于
tryAcquireShared方法呢?
别急,让我们进入到 acquire 方法一探究竟

可以看到,在 acquire 方法中,会调用 tryAcquireShared 方法,根据其返回值判断是否调用 doAcquireSharedInterruptibly 方法,更多关于 doAcquireSharedInterruptibly 的使用分析,请参考读者的这篇文章
这里需要注意下,acquire 方法具有阻塞性,而 tryAcquire 方法不具有阻塞性。
这也就是说,调用 acquire 方法如果获取不到许可,那么 Semaphore 会阻塞,直到有可用的许可。而 tryAcquire 方法如果获取不到许可会直接返回 false。
这里还需要注意下 acquireUninterruptibly 方法,其他 acquire 的相关方法要么是非阻塞,要么是阻塞可中断,而 acquireUninterruptibly 方法不仅在没有许可的情况下执着的等待,而且也不会中断,使用这个方法时需要注意,这个方法很容易在出现大规模线程阻塞而导致 Java 进程出现假死的情况。
有获取许可相对应的就有释放许可,但是释放许可不会区分到底是公平释放还是非公平释放。不管方式如何都是释放一个许可给 Semaphore ,同样的 Semaphore 中的许可数量会增加。

在上图中调用 tryReleaseShared 判断是否能进行释放后,再会调用 AQS 中的 releasedShared 方法进行释放。

上面这个释放流程只是释放一个许可,除此之外,还可以释放多个许可
public void release(int permits) { if (permits < 0) throw new IllegalArgumentException(); sync.releaseShared(permits); }后面这个 releaseShared 的释放流程和上面的释放流程一致。
其他 Semaphore 方法
除了上面基本的 acquire 和 release 相关方法外,我们也要了解一下 Semaphore 的其他方法。Semaphore 的其他方法比较少,只有下面这几个
drainPermits : 获取并退还所有立即可用的许可,其实相当于使用 CAS 方法把内存值置为 0
reducePermits:和 nonfairTryAcquireShared 方法类似,只不过 nonfairTryAcquireShared 是使用 CAS 使内存值 + 1,而 reducePermits 是使内存值 – 1 。
isFair:对 Semaphore 许可的争夺是采用公平还是非公平的方式,对应到内部的实现就是 FairSync 和 NonfairSync。
hasQueuedThreads:当前是否有线程由于要获取 Semaphore 许可而进入阻塞。
getQueuedThreads:返回一个包含了等待获取许可的线程集合。
getQueueLength:获取正在排队而进入阻塞状态的线程个数
# 深入理解volatile关键字-Java面试题
volatile 这个关键字大家都不陌生,这个关键字一般通常用于并发编程中,是 Java 虚拟机提供的轻量化同步机制,你可能知道 volatile 是干啥的,但是你未必能够清晰明了的知道 volatile 的实现机制,以及 volatile 解决了什么问题,这篇文章我就来带大家解析一波。
volatile 能够保证共享变量之间的 可见性,共享变量是存在堆区的,而堆区又与内存模型有关,所以我们要聊 volatile ,就需要首先了解一下 JVM 内存模型,而 JVM 又是和内存进行交互的,所以在聊 JVM 内存模型前,我们还需要了解一下操作系统层面中内存模型的相关概念。
先从内存模型谈起
计算机在执行程序时,会从内存中读取数据,然后加载到 CPU 中运行。由于 CPU 执行指令的速度要比从内存中读取和写入的速度快的多,所以如果每条指令都要和内存交互的话,会大大降低 CPU 的运行速度,造成昂贵的 CPU 性能损耗,为了解决这种问题,设计了 CPU 高速缓存。有了 CPU 高速缓存后,CPU 就不再需要频繁的和内存交互了,有高速缓存就行了,而 CPU 高速缓存,就是我们经常说的 L1 、L2、L3 cache。
当程序在运行过程中,会将运算需要的数据从主存复制一份到 CPU 的高速缓存中,在 CPU 进行计算时就可以直接从它的高速缓存读写数据,当运算结束之后,再将高速缓存中的数据刷新到主存中。
就拿我们常说的
i = i + 1来举例子
当 CPU 执行这条语句时,会先从内存中读取 i 的值,复制一份到高速缓存当中,然后 CPU 执行指令对 i 进行加 1 操作,再将数据写入高速缓存,最后将高速缓存中 i 最新的值刷新到主存当中。
这个代码在单线程中运行是没有任何问题的,但是在多线程中运行就会有问题了,因为每个 CPU 都可以运行一条线程,线程就是程序的顺序执行流,因此每个线程运行时有自己的高速缓存(对单核 CPU 来说,其实也会出现这种问题,只不过是以线程调度的形式来分别执行的)。本文我们以多核 CPU 为例来讲解说明。
比如同时有 2 个线程执行这段代码,假如初始时 i 的值为 0,那么我们希望两个线程执行完之后 i 的值变为 2,但是事实会是这样吗?
可能存在下面一种情况:初始时,两个线程分别读取 i 的值存入各自所在的 CPU 高速缓存中,然后线程 1 执行加 1 操作,把 i 的最新值 1 写入到内存。此时线程 2 的高速缓存当中 i 的值还是 0,进行加 1 操作之后,i 的值为 1,然后线程 2 把 i 的值写入内存。
最终结果 i 的值是 1,而不是 2。这就是著名的缓存一致性问题。通常称这种被多个线程访问的变量为共享变量。
也就是说,如果一个变量在多个 CPU 中都存在缓存(一般在多线程编程时才会出现),就很可能存在缓存不一致的问题。
JVM 内存模型
我们上面说到,共享变量会存在缓存不一致的问题,缓存不一致问题换种说法就是线程安全问题,那么共享变量在 Java 中是如何存在的呢?JVM 中有没有提供线程安全的变量或者数据呢?
这就要聊聊 JVM 内存模型的问题了,图示如下

虚拟机栈: Java 虚拟机栈是线程私有的数据区,Java 虚拟机栈的生命周期与线程相同,虚拟机栈也是局部变量的存储位置。方法在执行过程中,会在虚拟机栈种创建一个栈帧(stack frame)。本地方法栈: 本地方法栈也是线程私有的数据区,本地方法栈存储的区域主要是 Java 中使用native关键字修饰的方法所存储的区域。程序计数器:程序计数器也是线程私有的数据区,这部分区域用于存储线程的指令地址,用于判断线程的分支、循环、跳转、异常、线程切换和恢复等功能,这些都通过程序计数器来完成。方法区:方法区是各个线程共享的内存区域,它用于存储虚拟机加载的 类信息、常量、静态变量、即时编译器编译后的代码等数据。堆: 堆是线程共享的数据区,堆是 JVM 中最大的一块存储区域,所有的对象实例都会分配在堆上运行时常量池:运行时常量池又被称为Runtime Constant Pool,这块区域是方法区的一部分,它的名字非常有意思,它并不要求常量一定只有在编译期才能产生,也就是并非编译期间将常量放在常量池中,运行期间也可以将新的常量放入常量池中,String 的 intern 方法就是一个典型的例子。
根据上面的描述可以看到,会产生缓存不一致问题(线程安全问题)的有堆区和方法区。而虚拟机栈、本地方法栈、程序计数器是线程私有,由线程封闭的原因,它们不存在线程安全问题。
针对线程安全问题,有没有解决办法呢?
一般情况下,Java 中解决缓存不一致的方法有两种,第一种就是 synchronized 使用的总线锁方式,也就是在总线上声言 LOCK# 信号;第二种就是著名的 MESI 协议。这两种都是硬件层面提供的解决方式。
我们先来说一下第一种总线锁的方式。通过在总线上声言 LOCK# 信号,能够有效的阻塞其他 CPU 对于总线的访问,从而使得只能有一个 CPU 访问变量所在的内存。在上面的 i = i + 1 代码示例中,在代码执行的过程中,声言了 LOCK# 信号后,那么只有等待 i = i + 1 的结果执行完毕并应用到内存后,总线锁才会解开,其他 CPU 才能够继续访问内存中的变量,再继续执行后面的代码,这样就解决了缓存不一致问题。

但是上面的方式会有一个问题,由于在锁住总线期间,其他 CPU 无法访问内存,导致效率低下。
在 JDK 1.6 之后,优化了 synchronized 声言 LOCK# 的方式,不再对总线进行锁定,转而采取了对 CPU 缓存行进行锁定,因为本篇文章不是介绍 synchronized 实现细节的文章,所以不再对这种方式进行详细介绍,读者只需要知道在优化之后,synchronized 的性能不再成为并发问题的瓶颈了。
MESI 协议就是缓存一致性协议,即 Modified(被修改)Exclusive(独占的) Shared(共享的) Or Invalid(无效的)。MESI 的基本思想就是如果发现 CPU 操作的是共享变量,其他 CPU 中也会出现这个共享变量的副本,在 CPU 执行代码期间,会发出信号通知其他 CPU 自己正在修改共享变量,其他 CPU 收到通知后就会把自己的共享变量置为无效状态。

并发编程中的三个主要问题
可见性问题
在单核 CPU 时代,所有的线程共用一个 CPU,CPU 缓存和内存的一致性问题容易解决,我们还拿上面的 i = 1 + 1 来举例,CPU 和 内存之间如果用图来表示的话我想会是下面这样。

在多核时代,每个核都能够独立的运行一个线程,每个 CPU 都有自己的缓存,这时 CPU 缓存与内存的数据一致性就没那么容易解决了,当多个线程在不同的 CPU 上执行时,这些线程使用的是不同的 CPU 缓存。

因为 i 没有经过任何线程安全措施的保护,多个线程会并发修改 i 的值,所以我们认为 i 不是线程安全的,导致这种结果的出现是由于 aThread 和 bThread 中读取的 i 值彼此不可见,所以这是由于 可见性 导致的线程安全问题。
原子性问题
当两个线程开始运行后,每个线程都会把 i 的值读入到 CPU 缓存中,再执行 + 1 操作,然后把 + 1 之后的值写入内存。因为线程间都有各自的虚拟机栈和程序计数器,他们彼此之间没有数据交换,所以当 aThread 执行 + 1 操作后,会把数据写入到内存,同时 bThread 执行 + 1 操作后,也会把数据写入到内存,因为 CPU 时间片的执行周期是不确定的,所以会出现当 aThread 还没有把数据写入内存时,bThread 就会读取内存中的数据,然后执行 + 1操作,再写回内存,从而覆盖 i 的值。

有序性问题
在并发编程中还有带来让人非常头疼的 有序性 问题,有序性顾名思义就是顺序性,在计算机中指的就是指令的先后执行顺序。一个非常显而易见的例子就是 JVM 中的类加载。

这是一个 JVM 加载类的过程图,也称为类的生命周期,类从加载到 JVM 到卸载一共会经历五个阶段 加载、连接、初始化、使用、卸载。这五个过程的执行顺序是一定的,但是在连接阶段,也会分为三个过程,即 验证、准备、解析 阶段,这三个阶段的执行顺序不是确定的,通常交叉进行,在一个阶段的执行过程中会激活另一个阶段。
在执行程序的过程中,为了提高性能,编译器和处理器通常会对指令进行重排序。重排序主要分为三类
- 编译器优化的重排序:编译器在不改变单线程语义的情况下,会对执行语句进行重新排序。
- 指令集重排序:现代操作系统中的处理器都是并行的,如果执行语句之间不存在数据依赖性,处理器可以改变语句的执行顺序
- 内存重排序:由于处理器会使用读/写缓冲区,出于性能的原因,内存会对读/写进行重排序
也就是说,要想并发程序正确地执行,必须要保证原子性、可见性以及有序性。只要有一个没有被保证,就有可能会导致程序运行不正确。
volatile 的实现原理
上面聊了这么多,你可能都要忘了这篇文章的故事主角了吧?主角永远存在于我们心中 ……
其实上面聊的这些,都是在为 volatile 做铺垫。
在并发编程中,最需要处理的就是线程之间的通信和线程间的同步问题,上面的可见性、原子性、有序性也是这两个问题带来的。
可见性
而 volatile 就是为了解决这些问题而存在的。Java 语言规范对 volatile 下了定义:Java 语言为了确保能够安全的访问共享变量,提供了 volatile 这个关键字,volatile 是一种轻量级同步机制,它并不会对共享变量进行加锁,但在某些情况下要比加锁更加方便,如果一个字段被声明为 volatile,Java 线程内存模型能够确保所有线程访问这个变量的值都是一致的。
一旦共享变量被 volatile 修饰后,就具有了下面两种含义
- 保证了这个字段的可见性,也就是说所有线程都能够"看到"这个变量的值,如果某个 CPU 修改了这个变量的值之后,其他 CPU 也能够获得通知。
- 能够禁止指令的重排序
下面我们来看一段代码,这也是我们编写并发代码中经常会使用到的
boolean isStop = false; while(!isStop){ ... }isStop = true;
在这段代码中,如果线程一正在执行 while 循环,而线程二把 isStop 改为 true 之后,转而去做其他事情,因为线程一并不知道线程二把 isStop 改为 true ,所以线程一就会一直运行下去。
如果 isStop 用 volatile 修饰之后,那么事情就会变的不一样了。
使用 volatile 修饰了 isStop 之后,在线程二把 isStop 改为 true 之后,会强制将其写入内存,并且会把线程一中 isStop 的值置为无效(这个值实际上是在缓存在 CPU 中的缓存行里),当线程一继续执行代码的时候,会从内存中重新读取 isStop 的值,此时 isStop 的值就是正确的内存地址的值。
volatile 有下面两条实现原则,其实这两条原则我们在上面介绍的时候已经提过了,一种是总线锁的方式,我们后面说总线锁的方式开销比较大,所以后面设计人员做了优化,采用了锁缓存的方式。另外一种是 MESI 协议的方式。
- 在 IA-32 架构软件开发者的手册中,有一种 Lock 前缀指令,这种指令能够声言 LOCK# 信号,在最近的处理器中,LOCK# 信号用于锁缓存,等到指令执行完毕后,会把缓存的内容写回内存,这种操作一般又被称为缓存锁定。
- 当缓存写回内存后,IA-32 和 IA-64 处理器会使用 MESI 协议控制内部缓存和其他处理器一致。IA-32 和 IA-64 处理器能够嗅探其他处理器访问系统内部缓存,当内存值修改后,处理器会从内存中重新读取内存值进行新的缓存行填充。
由此可见,volatile 能够保证线程的可见性。
那么 volatile 能够保证原子性吗?
原子性
我们还是以 i = i + 1 这个例子来说明一下,i = i + 1 分为三个操作
- 读取 i 的值
- 自增 i 的值
- 把 i 的值写会内存
我们知道,volatile 能够保证修改 i 的值对其他线程可见,所以我们此时假设线程一执行 i 的读取操作,此时发生了线程切换,线程二读取到最新 i 的值是 0 ,然后线程再次发生切换,线程一把 i 的值改为 1,线程再次切换,因为此时 i 的值还没有应用到内存,所以线程 i 同样把 i 的值改为 1 后,线程再次发生切换,线程一把 i 的值写入内存后,再次发生切换,线程二再次把 i 的值写会内存,所以此时,虽然内存值改了两次,但是最后的结果却不是 2。

那么 volatile 不能保证原子性,那么该如何保证原子性呢?
在 JDK 5 的 java.util.concurrent.atomic 包下提供了一些原子操作类,例如 AtomicInteger、AtomicLong、AtomicBoolean,这些操作是原子性操作。它们是利用 CAS 来实现原子性操作的(Compare And Swap),CAS实际上是利用处理器提供的 CMPXCHG 指令实现的,而处理器执行 CMPXCHG 指令是一个原子性操作。
详情可以参考笔者的这篇文章 一场 Atomic XXX 的魔幻之旅。
那么 volatile 能不能保证有序性呢?
这里就需要和你聊一聊 volatile 对有序性的影响了
有序性
上面提到过,重排序分为编译器重排序、处理器重排序和内存重排序。我们说的 volatile 会禁用指令重排序,实际上 volatile 禁用的是编译器重排序和处理器重排序。
下面是 volatile 禁用重排序的规则

从这个表中可以看出来,读写操作有四种,即不加任何修饰的普通读写和使用 volatile 修饰的读写。
从这个表中,我们可以得出下面这些结论
- 只要第二个操作(这个操作就指的是代码执行指令)是 volatile 修饰的写操作,那么无论第一个操作是什么,都不能被重排序。
- 当第一个操作是 volatile 读时,不管第二个操作是什么,都不能进行重排序。
- 当第一个操作是 volatile 写之后,第二个操作是 volatile 读/写都不能重排序。
为了实现这种有序性,编译器会在生成字节码中,会在指令序列中插入内存屏障来禁止特定类型的处理器重排序。
这里我们先来了解一下内存屏障的概念。
内存屏障也叫做栅栏,它是一种底层原语。它使得 CPU 或编译器在对内存进行操作的时候, 要严格按照一定的顺序来执行, 也就是说在 memory barrier 之前的指令和 memory barrier 之后的指令不会由于系统优化等原因而导致乱序。
内存屏障提供了两个功能。首先,它们通过确保从另一个 CPU 来看屏障的两边的所有指令都是正确的程序顺序;其次它们可以实现内存数据可见性,确保内存数据会同步到 CPU 缓存子系统。
不同计算机体系结构下面的内存屏障也不一样,通常需要认真研读硬件手册来确定,所以我们的主要研究对象是基于 x86 的内存屏障,通常情况下,硬件为我们提供了四种类型的内存屏障。
- LoadLoad 屏障
它的执行顺序是 Load1 ; LoadLoad ;Load2 ,其中的 Load1 和 Load2 都是加载指令。LoadLoad 指令能够确保执行顺序是在 Load1 之后,Load2 之前,LoadLoad 指令是一个比较有效的防止看到旧数据的指令。
- StoreStore 屏障
它的执行顺序是 Store1 ;StoreStore ;Store2 ,和上面的 LoadLoad 屏障的执行顺序相似,它也能够确保执行顺序是在 Store1 之后,Store2 之前。
- LoadStore 屏障
它的执行顺序是 Load1 ; StoreLoad ; Store2 ,保证 Load1 的数据被加载在与这数据相关的 Store2 和之后的 store 指令之前。
- StoreLoad 屏障
它的执行顺序是 Store1 ; StoreLoad ; Load2 ,保证 Store1 的数据被其他 CPU 看到,在数据被 Load2 和之后的 load 指令加载之前。也就是说,它有效的防止所有 barrier 之前的 stores 与所有 barrier 之后的 load 乱序。
JMM 采取了保守策略来实现内存屏障,JMM 使用的内存屏障如下

下面是一个使用内存屏障的示例
class MemoryBarrierTest { int a, b; volatile int v, u; void f() { int i, j;i = a;
j = b;
i = v;
j = u;
a = i;
b = j;
v = i;
u = j;
i = u;
j = b;
a = i;
} }
这段代码虽然比较简单,但是使用了不少变量,看起来有些乱,我们反编译一下来分析一下内存屏障对这段代码的影响。

从反编译的代码我们是看不到内存屏障的,因为内存屏障是一种硬件层面的指令,单凭字节码是肯定无法看到的。虽然无法看到内存屏障的硬件指令,但是 JSR-133 为我们说明了哪些字节码会出现内存屏障。
- 普通的读类似 getfield 、getstatic 、 不加 volatile 修饰的数组 load 。
- 普通的写类似 putfield 、 putstatic 、 不加 volatile 修饰的数组 store 。
- volatile 读是可以被多个线程访问修饰的 getfield、 getstatic 字段。
- volatile 写是可以被当个线程访问修饰的 putfield、 putstatic 字段。
这也就是说,只要是普通的读写加上了 volatile 关键字之后,就是 volatile 读写(呃呃呃,我好像说了一句废话),并没有其他特殊的 volatile 独有的指令。
根据这段描述,我们来继续分析一下上面的字节码。
a、b 是全局变量,也就是实例变量,不加 volatile 修饰,u、v 是 volatile 修饰的全局变量;i、j 是局部变量。
首先 i = a、j = b 只是把全局变量的值赋给了局部变量,由于是获取对象引用的操作,所以是字节码指令是 getfield 。
从官方手册就可以知晓原因了。

地址在 https://docs.oracle.com/javase/specs/jvms/se7/html/jvms-6.html
由内存屏障的表格可知,第一个操作是普通读写的情况下,只有第二个操作是 volatile 写才会设置内存屏障。
继续向下分析,遇到了 i = v,这个是把 volatile 变量赋值给局部变量,是一种 volatile 读,同样的 j = u 也是一种 volatile 读,所以这两个操作之间会设置 LoadLoad 屏障。
下面遇到了 a = i ,这是为全局变量赋值操作,所以其对应的字节码是 putfield

地址在 https://docs.oracle.com/javase/specs/jvms/se7/html/jvms-6.html
所以在 j = u 和 a = i 之间会增加 LoadStore 屏障。然后 a = i 和 b = j 是两个普通写,所以这两个操作之间不需要有内存屏障。
继续往下面分析,第一个操作是 b = j ,第二个操作是 v = i 也就是 volatile 写,所以需要有 StoreStore 屏障;同样的,v = i 和 u = j 之间也需要有 StoreStore 屏障。
第一个操作是 u = j 和 第二个操作 i = u volatile 读之间需要 StoreLoad 屏障。
最后一点需要注意下,因为最后两个操作是普通读和普通写,所以最后需要插入两个内存屏障,防止 volatile 读和普通读/写重排序。
《Java 并发编程艺术》里面也提到了这个关键点。

从上面的分析可知,volatile 实现有序性是通过内存屏障来实现的。
关键概念
在 volatile 实现可见性和有序性的过程中,有一些关键概念,cxuan 这里重新给读者朋友们唠叨下。
缓冲行:英文概念是 cache line,它是缓存中可以分配的最小存储单位。因为数据在内存中不是以独立的项进行存储的,而是以临近 64 字节的方式进行存储。
缓存行填充:cache line fill,当 CPU 把内存的数据载入缓存时,会把临近的共 64 字节的数据一同放入同一个 Cache line,因为局部性原理:临近的数据在将来被访问的可能性大。
缓存命中:cache hit,当 CPU 从内存地址中提取数据进行缓存行填充时,发现提取的位置仍然是上次访问的位置,此时 CPU 会选择从缓存中读取操作数,而不是从内存中取。
写命中:write hit ,当处理器打算将操作数写回到内存时,首先会检查这个缓存的内存地址是否在缓存行中,如果存在一个有效的缓存行,则处理器会将这个操作数写回到缓存,而不是写回到内存,这种方式被称为写命中。
内存屏障:memory barriers,是一组硬件指令,是 volatile 实现有序性的基础。
原子操作:atomic operations,是一组不可中断的一个或者一组操作。
如何正确的使用 volatile 变量
上面我们聊了这么多 volatile 的原理,下面我们就来谈一谈 volatile 的使用问题。
volatile 通常用来和 synchronized 锁进行比较,虽然它和锁都具有可见性,但是 volatile 不具有原子性,它不是真正意义上具有线程安全性的一种工具。
从程序代码简易性和可伸缩性角度来看,你可能更倾向于使用 volatile 而不是锁,因为 volatile 写起来更方便,并且 volatile 不会像锁那样造成线程阻塞,而且如果程序中的读操作的使用远远大于写操作的话,volatile 相对于锁还更加具有性能优势。
很多并发专家都推荐远离 volatile 变量,因为它们相对于锁更加容易出错,但是如果你谨慎的遵从一些模式,就能够安全的使用 volatile 变量,这里有一个 volatile 使用原则
只有在状态真正独立于程序内其他内容时才能使用 volatile。
下面我们通过几段代码来感受一下这条规则的力量。
状态标志
一种最简单使用 volatile 的方式就是将 volatile 作为状态标志来使用。
volatile boolean shutdownRequested;public void shutdown() { shutdownRequested = true; }
public void doWork() { while (!shutdownRequested) { // do stuff } }
为了能够正确的调用 shutdown() 方法,你需要确保 shutdownRequested 的可见性。这种状态标志的一种特性就是通常只有一种状态转换:shutdownRequested 的标志从 false 转为 true,然后程序停止。这种模式可以相互来回转换。
双重检查锁
使用 volatile 和 synchronized 可以满足双重检查锁的单例模式。
class Singleton{private volatile static Singleton instance = null;
private Singleton() {}
public static Singleton getInstance() {
if(instance == null) {
synchronized (Singleton.class) {
if(instance == null)
instance = new Singleton();
}
}
return instance;
}
}
这里说下为什么要用两次检查,假如有两个线程,线程一在进入到 synchronized 同步代码块之后,在还没有生成 Singleton 对象前发生线程切换,此时线程二判断 instance == null 为 true,会发生线程切换,切换到线程一,然后退出同步代码块,线程切换,线程二进入同步代码块后,会再判断一下 instance 的值,这就是双重检查锁的必要所在。
读-写锁
这也是 volatile 和 synchronized 一起使用的示例,用于实现开销比较低的读-写锁。
public class ReadWriteLockTest { private volatile int value;public int getValue() { return value; }
public synchronized int increment() {
return value++;
}
}
如果只使用 volatile 是不能安全实现计数器的,但是你能够在读操作中使用 volatile 保证可见性。如果你想要实现一种读写锁的话,必须进行外部加锁。
# AtomicInteger的用法和实现原理-Java面试题
i++ 不是线程安全的操作,因为它不是一个原子性操作。
那么,如果我想要达到类似 i++ 的这种效果,我应该使用哪些集合或者说工具类呢?
在 JDK1.5 之前,为了确保在多线程下对某基本数据类型或者引用数据类型运算的原子性,必须依赖于外部关键字 synchronized,但是这种情况在 JDK1.5 之后发生了改观,当然你依然可以使用 synchronized 来保证原子性,我们这里所说的一种线程安全的方式是原子性的工具类,比如 AtomicInteger、AtomicBoolean 等。这些原子类都是线程安全的工具类,他们同时也是 Lock-Free 的。下面我们就来一起认识一下这些工具类以及 Lock – Free 是个什么概念。
了解 AtomicInteger
AtomicInteger 是 JDK 1.5 新添加的工具类,我们首先来看一下它的继承关系

与 int 的包装类 Integer 一样,都是继承于 Number 类的。

这个 Number 类是基本数据类型的包装类,一般和数据类型有关的对象都会继承于 Number 类。
它的继承体系很简单,下面我们来看一下它的基本属性和方法
AtomicInteger 的基本属性
AtomicInteger 的基本属性有三个

Unsafe 是 sun.misc 包下面的类,AtomicInteger 主要是依赖于 sun.misc.Unsafe 提供的一些 native 方法保证操作的原子性。
Unsafe 的 objectFieldOffset 方法可以获取成员属性在内存中的地址相对于对象内存地址的偏移量。说得简单点就是找到这个变量在内存中的地址,便于后续通过内存地址直接进行操作,这个值就是 value
这个我们后面会再细说
value 就是 AtomicIneger 的值。
AtomicInteger 的构造方法
继续往下看,AtomicInteger 的构造方法只有两个,一个是无参数的构造方法,无参数的构造方法默认的 value 初始值是 0 ,带参数的构造方法可以指定初始值。

AtomicInteger 中的方法
下面我们就来聊一下 AtomicInteger 中的方法。
Get 和 Set
我们首先来看一下最简单的 get 、set 方法:
get() : 获取当前 AtomicInteger 的值
set() : 设置当前 AtomicInteger 的值
get() 可以原子性的读取 AtomicInteger 中的数据,set() 可以原子性的设置当前的值,因为 get() 和 set() 最终都是作用于 value 变量,而 value 是由 volatile 修饰的,所以 get 、set 相当于都是对内存进行读取和设置。如下图所示

我们上面提到了 i++ 和 i++ 的非原子性操作,我们说可以使用 AtomicInteger 中的方法进行替换。
Incremental 操作
AtomicInteger 中的 Incremental 相关方法可以满足我们的需求
getAndIncrement(): 原子性的增加当前的值,并把结果返回。相当于i++的操作。

为了验证是不是线程安全的,我们用下面的例子进行测试
public class TAtomicTest implements Runnable{AtomicInteger atomicInteger = new AtomicInteger();
@Override
public void run() {
for(int i = 0;i < 10000;i++){
System.out.println(atomicInteger.getAndIncrement());
}
}
public static void main(String[] args) {
TAtomicTest tAtomicTest = new TAtomicTest();
Thread t1 = new Thread(tAtomicTest);
Thread t2 = new Thread(tAtomicTest);
t1.start();
t2.start();
}
}
通过输出结果你会发现它是一个线程安全的操作,你可以修改 i 的值,但是最后的结果仍然是 i – 1,因为先取值,然后再 + 1,它的示意图如下。

incrementAndGet与此相反,首先执行 + 1 操作,然后返回自增后的结果,该操作方法能够确保对 value 的原子性操作。如下图所示

Decremental 操作
与此相对,x– 或者 x = x – 1 这样的自减操作也是原子性的。我们仍然可以使用 AtomicInteger 中的方法来替换
getAndDecrement: 返回当前类型的 int 值,然后对 value 的值进行自减运算。下面是测试代码
AtomicInteger atomicInteger = new AtomicInteger(20000);
@Override
public void run() {
for(int i = 0;i < 10000 ;i++){
System.out.println(atomicInteger.getAndDecrement());
}
}
public static void main(String[] args) {
TAtomicTestDecrement tAtomicTest = new TAtomicTestDecrement();
Thread t1 = new Thread(tAtomicTest);
Thread t2 = new Thread(tAtomicTest);
t1.start();
t2.start();
}
}
下面是 getAndDecrement 的示意图

decrementAndGet:同样的,decrementAndGet 方法就是先执行递减操作,然后再获取 value 的值,示意图如下

LazySet 方法
volatile 有内存屏障你知道吗?
内存屏障是啥啊?
内存屏障,也称
内存栅栏,内存栅障,屏障指令等, 是一类同步屏障指令,是 CPU 或编译器在对内存随机访问的操作中的一个同步点,使得此点之前的所有读写操作都执行后才可以开始执行此点之后的操作。也是一个让CPU 处理单元中的内存状态对其它处理单元可见的一项技术。
CPU 使用了很多优化,使用缓存、指令重排等,其最终的目的都是为了性能,也就是说,当一个程序执行时,只要最终的结果是一样的,指令是否被重排并不重要。所以指令的执行时序并不是顺序执行的,而是乱序执行的,这就会带来很多问题,这也促使着内存屏障的出现。
语义上,内存屏障之前的所有写操作都要写入内存;内存屏障之后的读操作都可以获得同步屏障之前的写操作的结果。因此,对于敏感的程序块,写操作之后、读操作之前可以插入内存屏障。
内存屏障的开销非常轻量级,但是再小也是有开销的,LazySet 的作用正是如此,它会以普通变量的形式来读写变量。
也可以说是:懒得设置屏障了

GetAndSet 方法
以原子方式设置为给定值并返回旧值。
它的源码就是调用了一下 unsafe 中的 getAndSetInt 方法,如下所示

就是先进行循环,然后调用 getIntVolatile 方法,这个方法我在 cpp 中没有找到,找到的小伙伴们记得及时告诉让我学习一下。
循环直到 compareAndSwapInt 返回 false,这就说明使用 CAS 并没有更新为新的值,所以 var5 返回的就是最新的内存值。
CAS 方法
我们一直常说的 CAS 其实就是 CompareAndSet 方法,这个方法顾名思义,就是 比较并更新 的意思,当然这是字面理解,字面理解有点偏差,其实人家的意思是先比较,如果满足那么再进行更新。

上面给出了 CAS Java 层面的源码,JDK 官方给它的解释就是 如果当前值等于 expect 的值,那么就以原子性的方式将当前值设置为 update 给定值,这个方法会返回一个 boolean 类型,如果是 true 就表示比较并更新成功,否则表示失败。
CAS 同时也是一种无锁并发机制,也称为 Lock Free,所以你觉得 Lock Free 很高大上吗?并没有。
下面我们构建一个加锁解锁的 CASLock
AtomicInteger atomicInteger = new AtomicInteger();
Thread currentThread = null;
public void tryLock() throws Exception{
boolean isLock = atomicInteger.compareAndSet(0, 1);
if(!isLock){
throw new Exception("加锁失败");
}
currentThread = Thread.currentThread();
System.out.println(currentThread + " tryLock");
}
public void unlock() {
int lockValue = atomicInteger.get();
if(lockValue == 0){
return;
}
if(currentThread == Thread.currentThread()){
atomicInteger.compareAndSet(1,0);
System.out.println(currentThread + " unlock");
}
}
public static void main(String[] args) {
CASLock casLock = new CASLock();
for(int i = 0;i < 5;i++){
new Thread(() -> {
try {
casLock.tryLock();
Thread.sleep(10000);
} catch (Exception e) {
e.printStackTrace();
}finally {
casLock.unlock();
}
}).start();
}
}
}
在上面的代码中,我们构建了一个 CASLock,在 tryLock 方法中,我们先使用 CAS 方法进行更新,如果更新不成功则抛出异常,并把当前线程设置为加锁线程。在 unLock 方法中,我们先判断当前值是否为 0 ,如果是 0 就是我们愿意看到的结果,直接返回。否则是 1,则表示当前线程还在加锁,我们再来判断一下当前线程是否是加锁线程,如果是则执行解锁操作。
那么我们上面提到的 compareAndSet,它其实可以解析为如下操作
// 伪代码// 当前值 int v = 0; int a = 0; int b = 1;
if(compare(0,0) == true){ set(0,1); } else{ // 继续向下执行 }
也可以拿生活场景中的买票举例子,你去景区旅游肯定要持票才能进,如果你拿着是假票或者不符合景区的票肯定是能够被识别出来的,如果你没有拿票拿你也肯定进不去景区。
废话少说,这就祭出来 compareAndSet 的示意图

weakCompareAndSet: 妈的非常认真看了好几遍,发现 JDK1.8 的这个方法和 compareAndSet 方法完全一摸一样啊,坑我。。。

但是真的是这样么?并不是,JDK 源码很博大精深,才不会设计一个重复的方法,你想想 JDK 团队也不是会犯这种低级团队,但是原因是什么呢?
《Java 高并发详解》这本书给出了我们一个答案

AddAndGet
AddAndGet 和 getAndIncrement、getAndAdd、incrementAndGet 等等方法都是使用了 do … while + CAS 操作,其实也就相当于是一个自旋锁,如果 CAS 修改成功就会一直循环,修改失败才会返回。示意图如下

深入 AtomicInteger
我们上面探讨了 AtomicInteger 的具体使用,同时我们知道 AtomicInteger 是依靠 volatile 和 CAS 来保证原子性的,那么我们下面就来分析一下为什么 CAS 能够保证原子性,它的底层是什么?AtomicInteger 与乐观锁又有什么关系呢?
AtomicInteger 的底层实现原理
我们再来瞧瞧这个可爱的 compareAndSetL(CAS) 方法,为什么就这两行代码就保证原子性了?

我们可以看到,这个 CAS 方法相当于是调用了 unsafe 中的 compareAndSwapInt 方法,我们进到 unsafe 方能发中看一下具体实现。

compareAndSwapInt 是 sun.misc 中的方法,这个方法是一个 native 方法,它的底层是 C/C++ 实现的,所以我们需要看 C/C++ 的源码。
知道 C/C++ 的牛逼之处了么。使用 Java 就是玩应用和架构的,C/C++ 是玩服务器、底层的。
compareAndSwapInt 的源码在 jdk8u-dev/hotspot/src/share/vm/prims/unsafe.app 路径下,它的源码实现是

也就是 Unsafe_CompareAndSwapInt 方法,我们找到这个方法

C/C++ 源码我也看不懂,但是这不妨碍我们找到关键代码 Atomic::cmpxchg ,cmpxchg 是 x86 CPU 架构的汇编指令,它的主要作用就是比较并交换操作数。我们继续往下跟找一下这个指令的定义。
我们会发现对应不同的 os,其底层实现方式不一样

我们找到 Windows 的实现方式如下

我们继续向下找,它其实定义的是第 216 行的代码,我们找进去

此时就需要汇编指令和寄存器相关的知识了。
上面的 os::is-MP() 是多处理操作系统的接口,下面是 __asm ,它是 C/C++ 的关键字,用于调用内联汇编程序。
__asm 中的代码是汇编程序,大致来说就是把 dest、exchange_value 、compare_value 的值都放在寄存器中,下面的 LOCK_IF_MP 中代码的大致意思就是

如果是多处理器的话就会执行 lock,然后进行比较操作。其中的 cmp 表示比较,mp 表示的就是 MultiProcess,je 表示相等跳转,L0 表示的是标识位。
我们回到上面的汇编指令,我们可以看到,CAS 的底层就是 cmpxchg 指令。
乐观锁
你有没有这个疑问,为什么 AtomicInteger 可以获取当前值,那为什么还会出现 expectValue 和 value 不一致的情况呢?
因为 AtomicInteger 只是一个原子性的工具类,它不具有排他性,它不像是 synchronized 或者是 lock 一样具有互斥和排他性,还记得 AtomicInteger 中有两个方法 get 和 set 吗?它们只是用 volatile 修饰了一下,而 volatile 不具有原子性,所以可能会存在 expectValue 和 value 的当前值不一致的情况,因此可能会出现重复修改。
针对上面这种情况的解决办法有两种,一种是使用 synchronized 和 lock 等类似的加锁机制,这种锁具有独占性,也就是说同一时刻只能有一个线程来进行修改,这种方式能够保证原子性,但是相对开销比较大,这种锁也叫做悲观锁。另外一种解决办法是使用版本号或者是 CAS 方法。
版本号
版本号机制是在数据表中加上一个 version 字段来实现的,表示数据被修改的次数,当执行写操作并且写入成功后,version = version + 1,当线程 A 要更新数据时,在读取数据的同时也会读取 version 值,在提交更新时,若刚才读取到的 version 值为当前数据库中的 version 值相等时才更新,否则重试更新操作,直到更新成功。
CAS 方法
还有一种方式就是 CAS 了,我们上面用了大量的篇幅来介绍 CAS 方法,那么我们认为你现在已经对其运行机制有一定的了解了,我们就不再阐述它的运行机制了。
任何事情都是有利也有弊,软件行业没有完美的解决方案只有最优的解决方案,所以乐观锁也有它的弱点和缺陷,那就是 ABA 问题。
ABA 问题
ABA 问题说的是,如果一个变量第一次读取的值是 A,准备好需要对 A 进行写操作的时候,发现值还是 A,那么这种情况下,能认为 A 的值没有被改变过吗?可以是由 A -> B -> A 的这种情况,但是 AtomicInteger 却不会这么认为,它只相信它看到的,它看到的是什么就是什么。举个例子来说
假如现在有一个单链表,如下图所示

A.next = B ,B.next = null,此时有两个线程 T1 和 T2 分别从单链表中取出 A ,由于一些特殊原因,T2 把 A 改为 B ,然后又改为 A ,此时 T1 执行 CAS 方法,发现单链表仍然是 A ,就会执行 CAS 方法,虽然结果没错,但是这种操作会造成一些潜在的问题。

此时还是一个单链表,两个线程 T1 和 T2 分别从单链表中取出 A ,然后 T1 把链表改为 ACD 如下图所示

此时 T2,发现内存值还是 A ,就会把 A 的值尝试替换为 B ,因为 B 的引用是 null,此时就会造成 C、D 处于游离态

JDK 1.5 以后的 AtomicStampedReference 类就提供了此种能力,其中的 compareAndSet 方法就是首先检查当前值是否等于预期值,判断的标准就是当前引用和邮戳分别和预期引用和邮戳相等,如果全部相等,则以原子方式设置为给定的更新值。

好了,上面就是 Java 代码流程了,看到 native 我们知道又要撸 cpp 了。开撸

简单解释一下就是 UnsafeWrapper 就是包装器,换个名字而已。然后经过一些 JNI 的处理,因为 compareAndSwapOject 比较的是引用,所以需要经过 C++ 面向对象的转换。最主要的方法是 atomic_compare_exchange_oop

可以看到,又出现了熟悉的词汇 cmpxchg ,也就是说 compareAndSwapOject 使用的还是 cmpxchg 原子性指令,只是它经过了一系列转换。
后记
抛出来一个问题,CAS 能保证变量之间的可见性么?为什么?
还有一个问题,getIntVolatile 方法的 cpp 源码在哪里?怎么找?
如果上面大佬们对这两个问题有兴趣,欢迎交流。
# JSR-133都解决了哪些问题?-Java面试题
究竟什么是内存模型?
在多处理系统中,每个 CPU 通常都包含一层或者多层内存缓存,这样设计的原因是为了加快数据访问速度(因为数据会更靠近处理器) 并且能够减少共享内存总线上的流量(因为可以满足许多内存操作)来提高性能。内存缓存能够极大的提高性能。
但是同时,这种设计方式也带来了许多挑战。
比如,当两个 CPU 同时对同一内存位置进行操作时会发生什么?在什么情况下这两个 CPU 会看到同一个内存值?
现在,内存模型登场了!!!在处理器层面,内存模型明确定义了其他处理器的写入是如何对当前处理器保持可见的,以及当前处理器写入内存的值是如何使其他处理器可见的,这种特性被称为可见性,这是官方定义的一种说法。
然而,可见性也分为强可见性和弱可见性,强可见性说的是任何 CPU 都能够看到指定内存位置具有相同的值;弱可见性说的是需要一种被称为内存屏障的特殊指令来刷新缓存或者使本地处理器缓存无效,才能看到其他 CPU 对指定内存位置写入的值,写入后的值就是内存值。这些特殊的内存屏障是被封装之后的,我们不研究源码的话是不知道内存屏障这个概念的。
内存模型还规定了另外一种特性,这种特性能够使编译器对代码进行重新排序(其实重新排序不只是编译器所具有的特性),这种特性被称为有序性。如果两行代码彼此没有相关性,那么编译器是能够改变这两行代码的编译顺序的,只要代码不会改变程序的语义,那么编译器就会这样做。
我们上面刚提到了,重新排序不只是编译器所特有的功能,编译器的这种重排序只是一种静态重排序,其实在运行时或者硬件执行指令的过程中也会发生重排序,重排序是一种提高程序运行效率的一种方式。
比如下面这段代码
Class Reordering { int x = 0, y = 0; public void writer() { x = 1; y = 2; }public void reader() { int r1 = y; int r2 = x; } }
当两个线程并行执行上面这段代码时,可能会发生重排序现象,因为 x 、 y 是两个互不相关的变量,所以当线程一执行到 writer 中时,发生重排序,y = 2 先被编译,然后线程切换,执行 r1 的写入,紧接着执行 r2 的写入,注意此时 x 的值是 0 ,因为 x = 1 没有编译。这时候线程切换到 writer ,编译 x = 1,所以最后的值为 r1 = 2,r2 = 0,这就是重排序可能导致的后果。
所以 Java 内存模型为我们带来了什么?
Java 内存模型描述了多线程中哪些行为是合法的,以及线程之间是如何通过内存进行交互的。Java 内存模型提供了两种特性,即变量之间的可见性和有序性,这些特性是需要我们在日常开发中所注意到的点。Java 中也提供了一些关键字比如 volatile、final 和 synchronized 来帮助我们应对 Java 内存模型带来的问题,同时 Java 内存模型也定义了 volatile 和 synchronized 的行为。
其他语言,比如 C++ 会有内存模型吗?
其他语言比如 C 和 C++ 在设计时并未直接支持多线程,这些语言针对编译器和硬件发生的重排序是依靠线程库(比如 pthread )、所使用的编译器以及运行代码的平台提供的保证。
JSR – 133 是关于啥的?
在 1997 年,在此时 Java 版本中的内存模型中发现了几个严重的缺陷,这个缺陷经常会出现诡异的问题,比如字段的值经常会发生改变,并且非常容易削弱编译器的优化能力。
所以,Java 提出了一项雄心勃勃的畅想:合并内存模型,这是编程语言规范第一次尝试合并一个内存模型,这个模型能够为跨各种架构的并发性提供一致的语义,但是实际操作起来要比畅想困难很多。
最终,JSR-133 为 Java 语言定义了一个新的内存模型,它修复了早期内存模型的缺陷。
所以,我们说的 JSR – 133 是关于内存模型的一种规范和定义。
JSR – 133 的设计目标主要包括:
- 保留 Java 现有的安全性保证,比如类型安全,并加强其他安全性保证,比如线程观察到的每个变量的值都必须是某个线程对变量进行修改之后的。
- 程序的同步语义应该尽可能简单和直观。
- 将多线程如何交互的细节交给程序员进行处理。
- 在广泛、流行的硬件架构上设计正确、高性能的 JVM 实现。
- 应提供初始化安全的保证,如果一个对象被正确构造后,那么所有看到对象构造的线程都能够看到构造函数中设置其最终字段的值,而不用进行任何的同步操作。
- 对现有的代码影响要尽可能的小。
重排序是什么?
在很多情况下,访问程序变量,比如对象实例字段、类静态字段和数组元素的执行顺序与程序员编写的程序指定的执行顺序不同。编译器可以以优化的名义任意调整指令的执行顺序。在这种情况下,数据可以按照不同于程序指定的顺序在寄存器、处理器缓存和内存之间移动。
有许多潜在的重新排序来源,例如编译器、JIT(即时编译)和缓存。
重排序是硬件、编译器一起制造出来的一种错觉,在单线程程序中不会发生重排序的现象,重排序往往发生在未正确同步的多线程程序中。
旧的内存模型有什么错误?
新内存模型的提出是为了弥补旧内存模型的不足,所以旧内存模型有哪些不足,我相信读者也能大致猜到了。
首先,旧的内存模型不允许发生重排序。再一点,旧的内存模型没有保证 final 的真正 不可变性,这是一个非常令人大跌眼睛的结论,旧的内存模型没有把 final 和其他不用 final 修饰的字段区别对待,这也就意味着,String 并非是真正不可变,这确实是一个非常严重的问题。
其次,旧的内存模型允许 volatile 写入与非 volatile 读取和写入重新排序,这与大多数开发人员对 volatile 的直觉不一致,因此引起了混乱。
什么是不正确同步?
当我们讨论不正确同步的时候,我们指的是任何代码
- 一个线程对一个变量执行写操作,
- 另一个线程读取了相同的变量,
- 并且读写之间并没有正确的同步
当违反这些规则时,我们说在这个变量上发生了数据竞争现象。 具有数据竞争现象的程序是不正确同步的程序。
同步(synchronization)都做了哪些事情?
同步有几个方面,最容易理解的是互斥,也就是说一次只有一个线程可以持有一个监视器(monitor)
但是同步不仅仅只有互斥,它还有可见,同步能够确保线程在进入同步代码块之前和同步代码块执行期间,线程写入内存的值对在同一 monitor 上同步的其他线程可见。
在进入同步块之前,会获取 monitor ,它具有使本地处理器缓存失效的效果,以便变量将从主内存中重新读取。 在退出一个同步代码块后,会释放 monitor ,它具有将缓存刷新到主存的功能,以便其他线程可以看到该线程所写入的值。
新的内存模型语义在内存操作上面制定了一些特定的顺序,这些内存操作包含(read、write、lock、unlock)和一些线程操作(start 、join),这些特定的顺序保证了第一个动作在执行之前对第二个动作可见,这就是 happens-before 原则,这些特定的顺序有
- 线程中的每个操作都 happens – before 按照程序定义的线程操作之前。
- Monitor 中的每个 unlock 操作都 happens-before 相同 monitor 的后续 lock 操作之前。
- 对 volatile 字段的写入都 happens-before 在每次后续读取同一 volatile 变量之前。
- 对线程的 start() 调用都 happens-before 在已启动线程的任何操作之前。
- 线程中的所有操作都 happens-before 在任何其他线程从该线程上的 join() 成功返回之前。
需要注意非常重要的一点:两个线程在同一个 monitor 之间的同步非常重要。并不是线程 A 在对象 X 上同步时可见的所有内容在对象 Y 上同步后对线程 B 可见。释放和获取必须进行
匹配(即,在同一个 monitor 上执行)才能有正确的内存语义,否则就会发生数据竞争现象。
另外,关于 synchronized 在 Java 中的用法,你可以参考这篇文章 synchronized 的超多干货!
final 在新的 JMM 下是如何工作的?
通过上面的讲述,你现在已经知道,final 在旧的 JMM 下是无法正常工作的,在旧的 JMM 下,final 的语义就和普通的字段一样,没什么其他区别,但是在新的 JMM 下,final 的这种内存语义发生了质的改变,下面我们就来探讨一下 final 在新的 JMM 下是如何工作的。
对象的 final 字段在构造函数中设置,一旦对象被正确的构造出来,那么在构造函数中的 final 的值将对其他所有线程可见,无需进行同步操作。
什么是正确的构造呢?
正确的构造意味着在构造的过程中不允许对正在构造的对象的引用发生 逃逸,也就是说,不要将正在构造的对象的引用放在另外一个线程能够看到它的地方。下面是一个正确构造的示例:
static void writer() { f = new FinalFieldExample(); }
static void reader() { if (f != null) { int i = f.x; int j = f.y; } } }
执行读取器的线程一定会看到 f.x 的值 3,因为它是 final 的。 不能保证看到 y 的值 4,因为它不是 final 的。 如果 FinalFieldExample 的构造函数如下所示:
public FinalFieldExample() { x = 3; y = 4; // 错误的构造,可能会发生逃逸 global.obj = this; }这样就不会保证读取 x 的值一定是 3 了。
这也就说是,如果在一个线程构造了一个不可变对象(即一个只包含 final 字段的对象)之后,你想要确保它被所有其他线程正确地看到,通常仍然需要正确的使用同步。
volatile 做了哪些事情?
我写过一篇 volatile 的详细用法和其原理的文章,你可以阅读这篇文章 volatile 的用法和实现原理
新的内存模型修复了双重检查锁的问题吗?
也许我们大家都见过多线程单例模式双重检查锁的写法,这是一种支持延迟初始化同时避免同步开销的技巧。
class DoubleCheckSync{ private static DoubleCheckSync instance = null; public DoubleCheckSync getInstance() { if (instance == null) { synchronized (this) { if (instance == null) instance = new DoubleCheckSync(); } } return instance; } }这样的代码看起来在程序定义的顺序上看起来很聪明,但是这段代码却有一个致命的问题:它不起作用。
??????
双重检查锁不起作用?
是的!
为毛?
原因就是初始化实例的写入和对实例字段的写入可以由编译器或缓存重新排序,看起来我们可能读取了初始化了 instance 对象,但其实你可能只是读取了一个未初始化的 instance 对象。
有很多小伙伴认为使用 volatile 能够解决这个问题,但是在 1.5 之前的 JVM 中,volatile 不能保证。在新的内存模型下,使用 volatile 会修复双重检查锁定的问题,因为这样在构造线程初始化 DoubleCheckSync 和返回其值之间将存在 happens-before 关系读取它的线程。
# Atomicxxx的用法和实现原理-Java面试题
i++ 不是线程安全的操作,因为它不是一个原子性操作。
那么,如果我想要达到类似 i++ 的这种效果,我应该使用哪些集合或者说工具类呢?
在 JDK1.5 之前,为了确保在多线程下对某基本数据类型或者引用数据类型运算的原子性,必须依赖于外部关键字 synchronized,但是这种情况在 JDK1.5 之后发生了改观,当然你依然可以使用 synchronized 来保证原子性,我们这里所说的一种线程安全的方式是原子性的工具类,比如 AtomicInteger、AtomicBoolean 等。这些原子类都是线程安全的工具类,他们同时也是 Lock-Free 的。下面我们就来一起认识一下这些工具类以及 Lock – Free 是个什么概念。
了解 AtomicInteger
AtomicInteger 是 JDK 1.5 新添加的工具类,我们首先来看一下它的继承关系

与 int 的包装类 Integer 一样,都是继承于 Number 类的。

这个 Number 类是基本数据类型的包装类,一般和数据类型有关的对象都会继承于 Number 类。
它的继承体系很简单,下面我们来看一下它的基本属性和方法
AtomicInteger 的基本属性
AtomicInteger 的基本属性有三个

Unsafe 是 sun.misc 包下面的类,AtomicInteger 主要是依赖于 sun.misc.Unsafe 提供的一些 native 方法保证操作的原子性。
Unsafe 的 objectFieldOffset 方法可以获取成员属性在内存中的地址相对于对象内存地址的偏移量。说得简单点就是找到这个变量在内存中的地址,便于后续通过内存地址直接进行操作,这个值就是 value
这个我们后面会再细说
value 就是 AtomicIneger 的值。
AtomicInteger 的构造方法
继续往下看,AtomicInteger 的构造方法只有两个,一个是无参数的构造方法,无参数的构造方法默认的 value 初始值是 0 ,带参数的构造方法可以指定初始值。

AtomicInteger 中的方法
下面我们就来聊一下 AtomicInteger 中的方法。
Get 和 Set
我们首先来看一下最简单的 get 、set 方法:
get() : 获取当前 AtomicInteger 的值
set() : 设置当前 AtomicInteger 的值
get() 可以原子性的读取 AtomicInteger 中的数据,set() 可以原子性的设置当前的值,因为 get() 和 set() 最终都是作用于 value 变量,而 value 是由 volatile 修饰的,所以 get 、set 相当于都是对内存进行读取和设置。如下图所示

我们上面提到了 i++ 和 i++ 的非原子性操作,我们说可以使用 AtomicInteger 中的方法进行替换。
Incremental 操作
AtomicInteger 中的 Incremental 相关方法可以满足我们的需求
getAndIncrement(): 原子性的增加当前的值,并把结果返回。相当于i++的操作。

为了验证是不是线程安全的,我们用下面的例子进行测试
public class TAtomicTest implements Runnable{AtomicInteger atomicInteger = new AtomicInteger();
@Override
public void run() {
for(int i = 0;i < 10000;i++){
System.out.println(atomicInteger.getAndIncrement());
}
}
public static void main(String[] args) {
TAtomicTest tAtomicTest = new TAtomicTest();
Thread t1 = new Thread(tAtomicTest);
Thread t2 = new Thread(tAtomicTest);
t1.start();
t2.start();
}
}
通过输出结果你会发现它是一个线程安全的操作,你可以修改 i 的值,但是最后的结果仍然是 i – 1,因为先取值,然后再 + 1,它的示意图如下。

incrementAndGet与此相反,首先执行 + 1 操作,然后返回自增后的结果,该操作方法能够确保对 value 的原子性操作。如下图所示

Decremental 操作
与此相对,x– 或者 x = x – 1 这样的自减操作也是原子性的。我们仍然可以使用 AtomicInteger 中的方法来替换
getAndDecrement: 返回当前类型的 int 值,然后对 value 的值进行自减运算。下面是测试代码
AtomicInteger atomicInteger = new AtomicInteger(20000);
@Override
public void run() {
for(int i = 0;i < 10000 ;i++){
System.out.println(atomicInteger.getAndDecrement());
}
}
public static void main(String[] args) {
TAtomicTestDecrement tAtomicTest = new TAtomicTestDecrement();
Thread t1 = new Thread(tAtomicTest);
Thread t2 = new Thread(tAtomicTest);
t1.start();
t2.start();
}
}
下面是 getAndDecrement 的示意图

decrementAndGet:同样的,decrementAndGet 方法就是先执行递减操作,然后再获取 value 的值,示意图如下

LazySet 方法
volatile 有内存屏障你知道吗?
内存屏障是啥啊?
内存屏障,也称
内存栅栏,内存栅障,屏障指令等, 是一类同步屏障指令,是 CPU 或编译器在对内存随机访问的操作中的一个同步点,使得此点之前的所有读写操作都执行后才可以开始执行此点之后的操作。也是一个让CPU 处理单元中的内存状态对其它处理单元可见的一项技术。
CPU 使用了很多优化,使用缓存、指令重排等,其最终的目的都是为了性能,也就是说,当一个程序执行时,只要最终的结果是一样的,指令是否被重排并不重要。所以指令的执行时序并不是顺序执行的,而是乱序执行的,这就会带来很多问题,这也促使着内存屏障的出现。
语义上,内存屏障之前的所有写操作都要写入内存;内存屏障之后的读操作都可以获得同步屏障之前的写操作的结果。因此,对于敏感的程序块,写操作之后、读操作之前可以插入内存屏障。
内存屏障的开销非常轻量级,但是再小也是有开销的,LazySet 的作用正是如此,它会以普通变量的形式来读写变量。
也可以说是:懒得设置屏障了

GetAndSet 方法
以原子方式设置为给定值并返回旧值。
它的源码就是调用了一下 unsafe 中的 getAndSetInt 方法,如下所示

就是先进行循环,然后调用 getIntVolatile 方法,这个方法我在 cpp 中没有找到,找到的小伙伴们记得及时告诉让我学习一下。
循环直到 compareAndSwapInt 返回 false,这就说明使用 CAS 并没有更新为新的值,所以 var5 返回的就是最新的内存值。
CAS 方法
我们一直常说的 CAS 其实就是 CompareAndSet 方法,这个方法顾名思义,就是 比较并更新 的意思,当然这是字面理解,字面理解有点偏差,其实人家的意思是先比较,如果满足那么再进行更新。

上面给出了 CAS Java 层面的源码,JDK 官方给它的解释就是 如果当前值等于 expect 的值,那么就以原子性的方式将当前值设置为 update 给定值,这个方法会返回一个 boolean 类型,如果是 true 就表示比较并更新成功,否则表示失败。
CAS 同时也是一种无锁并发机制,也称为 Lock Free,所以你觉得 Lock Free 很高大上吗?并没有。
下面我们构建一个加锁解锁的 CASLock
AtomicInteger atomicInteger = new AtomicInteger();
Thread currentThread = null;
public void tryLock() throws Exception{
boolean isLock = atomicInteger.compareAndSet(0, 1);
if(!isLock){
throw new Exception("加锁失败");
}
currentThread = Thread.currentThread();
System.out.println(currentThread + " tryLock");
}
public void unlock() {
int lockValue = atomicInteger.get();
if(lockValue == 0){
return;
}
if(currentThread == Thread.currentThread()){
atomicInteger.compareAndSet(1,0);
System.out.println(currentThread + " unlock");
}
}
public static void main(String[] args) {
CASLock casLock = new CASLock();
for(int i = 0;i < 5;i++){
new Thread(() -> {
try {
casLock.tryLock();
Thread.sleep(10000);
} catch (Exception e) {
e.printStackTrace();
}finally {
casLock.unlock();
}
}).start();
}
}
}
在上面的代码中,我们构建了一个 CASLock,在 tryLock 方法中,我们先使用 CAS 方法进行更新,如果更新不成功则抛出异常,并把当前线程设置为加锁线程。在 unLock 方法中,我们先判断当前值是否为 0 ,如果是 0 就是我们愿意看到的结果,直接返回。否则是 1,则表示当前线程还在加锁,我们再来判断一下当前线程是否是加锁线程,如果是则执行解锁操作。
那么我们上面提到的 compareAndSet,它其实可以解析为如下操作
// 伪代码// 当前值 int v = 0; int a = 0; int b = 1;
if(compare(0,0) == true){ set(0,1); } else{ // 继续向下执行 }
也可以拿生活场景中的买票举例子,你去景区旅游肯定要持票才能进,如果你拿着是假票或者不符合景区的票肯定是能够被识别出来的,如果你没有拿票拿你也肯定进不去景区。
废话少说,这就祭出来 compareAndSet 的示意图

weakCompareAndSet: 妈的非常认真看了好几遍,发现 JDK1.8 的这个方法和 compareAndSet 方法完全一摸一样啊,坑我。。。

但是真的是这样么?并不是,JDK 源码很博大精深,才不会设计一个重复的方法,你想想 JDK 团队也不是会犯这种低级团队,但是原因是什么呢?
《Java 高并发详解》这本书给出了我们一个答案

AddAndGet
AddAndGet 和 getAndIncrement、getAndAdd、incrementAndGet 等等方法都是使用了 do … while + CAS 操作,其实也就相当于是一个自旋锁,如果 CAS 修改成功就会一直循环,修改失败才会返回。示意图如下

深入 AtomicInteger
我们上面探讨了 AtomicInteger 的具体使用,同时我们知道 AtomicInteger 是依靠 volatile 和 CAS 来保证原子性的,那么我们下面就来分析一下为什么 CAS 能够保证原子性,它的底层是什么?AtomicInteger 与乐观锁又有什么关系呢?
AtomicInteger 的底层实现原理
我们再来瞧瞧这个可爱的 compareAndSetL(CAS) 方法,为什么就这两行代码就保证原子性了?

我们可以看到,这个 CAS 方法相当于是调用了 unsafe 中的 compareAndSwapInt 方法,我们进到 unsafe 方能发中看一下具体实现。

compareAndSwapInt 是 sun.misc 中的方法,这个方法是一个 native 方法,它的底层是 C/C++ 实现的,所以我们需要看 C/C++ 的源码。
知道 C/C++ 的牛逼之处了么。使用 Java 就是玩应用和架构的,C/C++ 是玩服务器、底层的。
compareAndSwapInt 的源码在 jdk8u-dev/hotspot/src/share/vm/prims/unsafe.app 路径下,它的源码实现是

也就是 Unsafe_CompareAndSwapInt 方法,我们找到这个方法

C/C++ 源码我也看不懂,但是这不妨碍我们找到关键代码 Atomic::cmpxchg ,cmpxchg 是 x86 CPU 架构的汇编指令,它的主要作用就是比较并交换操作数。我们继续往下跟找一下这个指令的定义。
我们会发现对应不同的 os,其底层实现方式不一样

我们找到 Windows 的实现方式如下

我们继续向下找,它其实定义的是第 216 行的代码,我们找进去

此时就需要汇编指令和寄存器相关的知识了。
上面的 os::is-MP() 是多处理操作系统的接口,下面是 __asm ,它是 C/C++ 的关键字,用于调用内联汇编程序。
__asm 中的代码是汇编程序,大致来说就是把 dest、exchange_value 、compare_value 的值都放在寄存器中,下面的 LOCK_IF_MP 中代码的大致意思就是

如果是多处理器的话就会执行 lock,然后进行比较操作。其中的 cmp 表示比较,mp 表示的就是 MultiProcess,je 表示相等跳转,L0 表示的是标识位。
我们回到上面的汇编指令,我们可以看到,CAS 的底层就是 cmpxchg 指令。
乐观锁
你有没有这个疑问,为什么 AtomicInteger 可以获取当前值,那为什么还会出现 expectValue 和 value 不一致的情况呢?
因为 AtomicInteger 只是一个原子性的工具类,它不具有排他性,它不像是 synchronized 或者是 lock 一样具有互斥和排他性,还记得 AtomicInteger 中有两个方法 get 和 set 吗?它们只是用 volatile 修饰了一下,而 volatile 不具有原子性,所以可能会存在 expectValue 和 value 的当前值不一致的情况,因此可能会出现重复修改。
针对上面这种情况的解决办法有两种,一种是使用 synchronized 和 lock 等类似的加锁机制,这种锁具有独占性,也就是说同一时刻只能有一个线程来进行修改,这种方式能够保证原子性,但是相对开销比较大,这种锁也叫做悲观锁。另外一种解决办法是使用版本号或者是 CAS 方法。
版本号
版本号机制是在数据表中加上一个 version 字段来实现的,表示数据被修改的次数,当执行写操作并且写入成功后,version = version + 1,当线程 A 要更新数据时,在读取数据的同时也会读取 version 值,在提交更新时,若刚才读取到的 version 值为当前数据库中的 version 值相等时才更新,否则重试更新操作,直到更新成功。
CAS 方法
还有一种方式就是 CAS 了,我们上面用了大量的篇幅来介绍 CAS 方法,那么我们认为你现在已经对其运行机制有一定的了解了,我们就不再阐述它的运行机制了。
任何事情都是有利也有弊,软件行业没有完美的解决方案只有最优的解决方案,所以乐观锁也有它的弱点和缺陷,那就是 ABA 问题。
ABA 问题
ABA 问题说的是,如果一个变量第一次读取的值是 A,准备好需要对 A 进行写操作的时候,发现值还是 A,那么这种情况下,能认为 A 的值没有被改变过吗?可以是由 A -> B -> A 的这种情况,但是 AtomicInteger 却不会这么认为,它只相信它看到的,它看到的是什么就是什么。举个例子来说
假如现在有一个单链表,如下图所示

A.next = B ,B.next = null,此时有两个线程 T1 和 T2 分别从单链表中取出 A ,由于一些特殊原因,T2 把 A 改为 B ,然后又改为 A ,此时 T1 执行 CAS 方法,发现单链表仍然是 A ,就会执行 CAS 方法,虽然结果没错,但是这种操作会造成一些潜在的问题。

此时还是一个单链表,两个线程 T1 和 T2 分别从单链表中取出 A ,然后 T1 把链表改为 ACD 如下图所示

此时 T2,发现内存值还是 A ,就会把 A 的值尝试替换为 B ,因为 B 的引用是 null,此时就会造成 C、D 处于游离态

JDK 1.5 以后的 AtomicStampedReference 类就提供了此种能力,其中的 compareAndSet 方法就是首先检查当前值是否等于预期值,判断的标准就是当前引用和邮戳分别和预期引用和邮戳相等,如果全部相等,则以原子方式设置为给定的更新值。

好了,上面就是 Java 代码流程了,看到 native 我们知道又要撸 cpp 了。开撸

简单解释一下就是 UnsafeWrapper 就是包装器,换个名字而已。然后经过一些 JNI 的处理,因为 compareAndSwapOject 比较的是引用,所以需要经过 C++ 面向对象的转换。最主要的方法是 atomic_compare_exchange_oop

可以看到,又出现了熟悉的词汇 cmpxchg ,也就是说 compareAndSwapOject 使用的还是 cmpxchg 原子性指令,只是它经过了一系列转换。
我们上面介绍到了 AtomicInteger 是一种原子性的工具类,它的底层是依靠 CAS + Volatile 关键字来实现的原子性和可见性。那么作为八种基本数据类型的原子工具类,我们此篇文章就来介绍一下另外一个原子工具类那就是 AtomicBoolean,通常情况下,AtomicBoolean 用于原子性的更新状态标示位。
认识 AtomicBoolean
AtomicBoolean 的用法和 AtomicInteger 的非常相似,我们具体来看一下。

为什么 AtomicInteger 可以继承 Number 类而 AtomicBoolean 却没有继承于 Number 类呢?
我们先来看下 Number 类是什么吧

JDK 源码给出了我们解释
Number 类是 JDK 平台的超类,同时也是一个抽象类,它可以转换为具体数值的类,比如原始类型 byte、double、float、int、long 和 short。
注意:可以看到只有六中基本数据类型,并没有 char 和 boolean。
也就是说,Number 类是基本数据类型 byte、double、float、int、long 和 short 包装类的超类,Number 类只进行方法的定义,不提供方法的具体实现,具体的实现交给子类去做。

不同的数值之间的转换会存在数值丢失的问题,JDK 源码也给出了我们说明

简单证明一下。
Double d1 = 3.1214; System.out.println(d1.intValue());那么,还有两种基本数据类型 char 和 boolean ,char 和 boolean 的包装类又分别是啥呢?它们为什么没有被划分为 Number 超类中呢?
char 类型的包装类其实是 character

而 boolean 类型的包装类是 Boolean。
Char 是字符,它可以代表任何值,而不单单是数字,Boolean 只有两个数值:TRUE 和 FALSE,而 Boolean 在传输的过程中会被当作整数来看待,没有必要再继承于 Number 类。
在了解完 Number 之后,我们继续回到 AtomicBoolean 类的讨论上来。
AtomicBoolean 创建
AtomicBoolean 用于原子性的更新标志值,它不能作为 boolean 的包装类 Boolean 的替代。
AtomicBoolean 的创建有两种,一种是无参的构造方法;一种是带参数的构造方法,如果 boolean 是 true 的话,那么 value 的值就是 1, 否则就是 0。
和 AtomicInteger 的构造方法一摸一样,只不过 AtomicInteger 的值可以是任意的,而 AtomicBoolean 的值只能是 true 和 false。

AtomicBoolean 基本方法
AtomicBoolean 中的方法很少,下面一起来认识一下。
Get
AtomicBoolean 你看起来像是一个 Boolean 类型的值,但是其内部仍然使用 value 这个 int 值来进行存储,int 的值只能是 1 或 0 ,分别对应 true 或 false。

所以如果当前值是 1 就返回 true,如果是 0 就返回 false。
而 AtomicInteger 中的 get 方法只是返回当前值。
CompareAndSet
AtomicBoolean 也有 CAS 方法,而且和 AtomicInteger 中的 compareAndSet 底层都是使用的 unfase.compareAndSwapInt 方法,也就是说是,如果你的值只是使用的 0 和 1 ,那么不管是使用 AtomicBoolean 还是 AtomicInteger 达到的效果一样。

Set
JDK 给出的解释是无条件的设置为当前值。AtomicInteger 也是一样的。

LazySet
就连 lazySet 都和 AtomicInteger 底层使用的方法也一样。只是 AtomicBoolean 比 AtomicInteger 多了一层判断

GetAndSet
AtomicBoolean 中的 getAndSet 方法还是和 AtomicInteger 中的有点区别的。

AtomicBoolean 的底层和方法和 AtomicInteger 一样,如果了解了 AtomicInteger 之后,那么 AtomicBoolean 也就没问题了。AtomicBoolean 本身没多少东西。但是 AtomicBoolean 很适合做开关,因为 AtomicBoolean 中的值只有 1 和 0 。
AtomicLong
与 AtomicInteger 一样,AtomicLong 也是继承于 Number 类的,AtomicLong 里面的方法几乎和 AtomicInteger 一样,不过 AtomicLong 底层源码可不一样。
对比如下
| 方法 | AtomicInteger 底层 | AtomicLong 底层 |
|---|---|---|
| lazySet | putOrderedLong | putOrderedInt |
| getAndSet | getAndSetLong | getAndSetInt |
| compareAndSet | compareAndSwapLong | compareAndSwapInt |
| getAndIncrement 等等 | getAndAddLong | getAndAddInt |
可以看到,虽然只有一词之差,但是其中的 C/C++ 源码可是相差很多,这次我们简单介绍一下 AtomicLong 的底层实现。
CAS 方法
下面我们一起来看一下 CAS 的区别

在 /jdk8u-dev/hotspot/src/share/vm/prims/unsafe.cpp 中定义了 CAS 中的方法 UNSAFE_ENTRY。如下所示

相比于 compareAndSwapInt 方法,在 unsafe.cpp 中,compareAndSwapLong 方法包含了条件编译 SUPPORTS_NATIVE_CX8,这是啥?
我们在 AtomicLong 的 .java 文件中也能看到定义

JDK 源码给出了我们解释
VM_SUPPORTS_LONG_CAS 是 JVM 的一项用来记录,用来记录是否长期支持无锁的 compareAndSwap 方法。尽管 Unsafe.compareAndSwapLong 在有锁和无锁情况下都支持,但是应该在 Java 级别处理某些构造,以避免锁定用户可见的锁。
从代码可以看到,UNSAFE_ENTRY 方法首先会判断是否支持 SUPPORTS_NATIVE_CX8,啥意思呢?它的意思就是判断机器是否支持 8 字节的 cmpxchg 这个 CPU 指令。如果硬件不支持,就会判断 JVM 是否支持,如果 JVM 也不支持,就表明这个操作不是 Lock Free 的。此时JVM 会使用显示锁例如 synchronized 来接管。这也是上面这段 cpp 源码的解释。
比如 32 位 CPU 肯定不支持 8 字节 64 位数字的 cpmxchg 指令
那么如何判断系统是否支持 8 字节的 cmpxchg 指令呢?或许用下面这段代码可以证明
public static void main(String[] args) throws Exception {Class klass = Class.forName("java.util.concurrent.atomic.AtomicLong"); Field field = klass.getDeclaredField("VM_SUPPORTS_LONG_CAS"); field.setAccessible(true); boolean VMSupportsCS8 = field.getBoolean(null); System.out.println(VMSupportsCS8); if (! VMSupportsCS8) throw new Exception("Unexpected value for VMSupportsCS8"); }
这段代码摘自/jdk8u-dev/jdk/test/java/util/concurrent/atomic/VMSupportsCS8.java
JDK 源码真是个好东西。
LazySet
lazySet 的底层调用的是 unsafe.putOrderedLong 方法,它的底层源码是

可以看到,也出现了 SUPPORTS_NATIVE_CX8 这个判断,如果硬件支持的话,那么就会长期使用 CAS + Volatile 这种 Lock Free 的方式来保证原子性,下面的 SET_FIELD_VOLATILE 同时也证明了这一点,就是使用 volatile 内存语义来保证可见性。
否则就会判断 JVM 是否支持 ,如果 JVM 不值得话,也会使用 synchronized 进行锁定。
其他的方法其实大同小异了。
# 深入理解synchronized关键字-Java面试题
前言
synchronized 这个关键字的重要性不言而喻,几乎可以说是并发、多线程必须会问到的关键字了。synchronized 会涉及到锁、升级降级操作、锁的撤销、对象头等。所以理解 synchronized 非常重要,本篇文章就带你从 synchronized 的基本用法、再到 synchronized 的深入理解,对象头等,为你揭开 synchronized 的面纱。
浅析 synchronized
synchronized 是 Java 并发模块非常重要的关键字,它是 Java 内建的一种同步机制,代表了某种内在锁定的概念,当一个线程对某个共享资源加锁后,其他想要获取共享资源的线程必须进行等待,synchronized 也具有互斥和排他的语义。
什么是互斥?我们想必小时候都玩儿过磁铁,磁铁会有正负极的概念,同性相斥异性相吸,相斥相当于就是一种互斥的概念,也就是两者互不相容。
synchronized 也是一种独占的关键字,但是它这种独占的语义更多的是为了增加线程安全性,通过独占某个资源以达到互斥、排他的目的。
在了解了排他和互斥的语义后,我们先来看一下 synchronized 的用法,先来了解用法,再来了解底层实现。
synchronized 的使用
关于 synchronized 想必你应该都大致了解过
- synchronized 修饰实例方法,相当于是对类的实例进行加锁,进入同步代码前需要获得当前实例的锁
- synchronized 修饰静态方法,相当于是对类对象进行加锁
- synchronized 修饰代码块,相当于是给对象进行加锁,在进入代码块前需要先获得对象的锁
下面我们针对每个用法进行解释
synchronized 修饰实例方法
synchronized 修饰实例方法,实例方法是属于类的实例。synchronized 修饰的实例方法相当于是对象锁。下面是一个 synchronized 修饰实例方法的例子。
public synchronized void method() { // ... }像如上述 synchronized 修饰的方法就是实例方法,下面我们通过一个完整的例子来认识一下 synchronized 修饰实例方法
public class TSynchronized implements Runnable{static int i = 0;
public synchronized void increase(){
i++;
System.out.println(Thread.currentThread().getName());
}
@Override
public void run() {
for(int i = 0;i < 1000;i++) {
increase();
}
}
public static void main(String[] args) throws InterruptedException {
TSynchronized tSynchronized = new TSynchronized();
Thread aThread = new Thread(tSynchronized);
Thread bThread = new Thread(tSynchronized);
aThread.start();
bThread.start();
aThread.join();
bThread.join();
System.out.println("i = " + i);
}
}
上面输出的结果 i = 2000 ,并且每次都会打印当前现成的名字
来解释一下上面代码,代码中的 i 是一个静态变量,静态变量也是全局变量,静态变量存储在方法区中。increase 方法由 synchronized 关键字修饰,但是没有使用 static 关键字修饰,表示 increase 方法是一个实例方法,每次创建一个 TSynchronized 类的同时都会创建一个 increase 方法,increase 方法中只是打印出来了当前访问的线程名称。Synchronized 类实现了 Runnable 接口,重写了 run 方法,run 方法里面就是一个 0 – 1000 的计数器,这个没什么好说的。在 main 方法中,new 出了两个线程,分别是 aThread 和 bThread,Thread.join 表示等待这个线程处理结束。这段代码主要的作用就是判断 synchronized 修饰的方法能够具有独占性。
synchronized 修饰静态方法
synchronized 修饰静态方法就是 synchronized 和 static 关键字一起使用
public static synchronized void increase(){}当 synchronized 作用于静态方法时,表示的就是当前类的锁,因为静态方法是属于类的,它不属于任何一个实例成员,因此可以通过 class 对象控制并发访问。
这里需要注意一点,因为 synchronized 修饰的实例方法是属于实例对象,而 synchronized 修饰的静态方法是属于类对象,所以调用 synchronized 的实例方法并不会阻止访问 synchronized 的静态方法。
synchronized 修饰代码块
synchronized 除了修饰实例方法和静态方法外,synchronized 还可用于修饰代码块,代码块可以嵌套在方法体的内部使用。
public void run() { synchronized(obj){ for(int j = 0;j < 1000;j++){ i++; } } }上面代码中将 obj 作为锁对象对其加锁,每次当线程进入 synchronized 修饰的代码块时就会要求当前线程持有obj 实例对象锁,如果当前有其他线程正持有该对象锁,那么新到的线程就必须等待。
synchronized 修饰的代码块,除了可以锁定对象之外,也可以对当前实例对象锁、class 对象锁进行锁定
// 实例对象锁 synchronized(this){ for(int j = 0;j < 1000;j++){ i++; } }//class对象锁 synchronized(TSynchronized.class){ for(int j = 0;j < 1000;j++){ i++; } }
synchronized 底层原理
在简单介绍完 synchronized 之后,我们就来聊一下 synchronized 的底层原理了。
我们或许都有所了解(下文会细致分析),synchronized 的代码块是由一组 monitorenter/monitorexit 指令实现的。而Monitor 对象是实现同步的基本单元。
啥是
Monitor对象呢?
Monitor 对象
任何对象都关联了一个管程,管程就是控制对象并发访问的一种机制。管程 是一种同步原语,在 Java 中指的就是 synchronized,可以理解为 synchronized 就是 Java 中对管程的实现。
管程提供了一种排他访问机制,这种机制也就是 互斥。互斥保证了在每个时间点上,最多只有一个线程会执行同步方法。
所以你理解了 Monitor 对象其实就是使用管程控制同步访问的一种对象。
对象内存布局
在 hotspot 虚拟机中,对象在内存中的布局分为三块区域:
对象头(Header)实例数据(Instance Data)对齐填充(Padding)
这三块区域的内存分布如下图所示

我们来详细介绍一下上面对象中的内容。
对象头 Header
对象头 Header 主要包含 MarkWord 和对象指针 Klass Pointer,如果是数组的话,还要包含数组的长度。

在 32 位的虚拟机中 MarkWord ,Klass Pointer 和数组长度分别占用 32 位,也就是 4 字节。
如果是 64 位虚拟机的话,MarkWord ,Klass Pointer 和数组长度分别占用 64 位,也就是 8 字节。
在 32 位虚拟机和 64 位虚拟机的 Mark Word 所占用的字节大小不一样,32 位虚拟机的 Mark Word 和 Klass Pointer 分别占用 32 bits 的字节,而 64 位虚拟机的 Mark Word 和 Klass Pointer 占用了64 bits 的字节,下面我们以 32 位虚拟机为例,来看一下其 Mark Word 的字节具体是如何分配的。


用中文翻译过来就是

- 无状态也就是
无锁的时候,对象头开辟 25 bit 的空间用来存储对象的 hashcode ,4 bit 用于存放分代年龄,1 bit 用来存放是否偏向锁的标识位,2 bit 用来存放锁标识位为 01。 偏向锁中划分更细,还是开辟 25 bit 的空间,其中 23 bit 用来存放线程ID,2bit 用来存放 epoch,4bit 存放分代年龄,1 bit 存放是否偏向锁标识, 0 表示无锁,1 表示偏向锁,锁的标识位还是 01。轻量级锁中直接开辟 30 bit 的空间存放指向栈中锁记录的指针,2bit 存放锁的标志位,其标志位为 00。重量级锁中和轻量级锁一样,30 bit 的空间用来存放指向重量级锁的指针,2 bit 存放锁的标识位,为 11GC标记开辟 30 bit 的内存空间却没有占用,2 bit 空间存放锁标志位为 11。
其中无锁和偏向锁的锁标志位都是 01,只是在前面的 1 bit 区分了这是无锁状态还是偏向锁状态。
关于为什么这么分配的内存,我们可以从 OpenJDK 中的markOop.hpp类中的枚举窥出端倪

来解释一下
- age_bits 就是我们说的分代回收的标识,占用4字节
- lock_bits 是锁的标志位,占用2个字节
- biased_lock_bits 是是否偏向锁的标识,占用1个字节。
- max_hash_bits 是针对无锁计算的 hashcode 占用字节数量,如果是 32 位虚拟机,就是 32 – 4 – 2 -1 = 25 byte,如果是 64 位虚拟机,64 – 4 – 2 – 1 = 57 byte,但是会有 25 字节未使用,所以 64 位的 hashcode 占用 31 byte。
- hash_bits 是针对 64 位虚拟机来说,如果最大字节数大于 31,则取 31,否则取真实的字节数
- cms_bits 我觉得应该是不是 64 位虚拟机就占用 0 byte,是 64 位就占用 1byte
- epoch_bits 就是 epoch 所占用的字节大小,2 字节。
在上面的虚拟机对象头分配表中,我们可以看到有几种锁的状态:无锁(无状态),偏向锁,轻量级锁,重量级锁,其中轻量级锁和偏向锁是 JDK1.6 中对 synchronized 锁进行优化后新增加的,其目的就是为了大大优化锁的性能,所以在 JDK 1.6 中,使用 synchronized 的开销也没那么大了。其实从锁有无锁定来讲,还是只有无锁和重量级锁,偏向锁和轻量级锁的出现就是增加了锁的获取性能而已,并没有出现新的锁。
所以我们的重点放在对 synchronized 重量级锁的研究上,当 monitor 被某个线程持有后,它就会处于锁定状态。在 HotSpot 虚拟机中,monitor 的底层代码是由 ObjectMonitor 实现的,其主要数据结构如下(位于 HotSpot 虚拟机源码 ObjectMonitor.hpp 文件,C++ 实现的)

这段 C++ 中需要注意几个属性:_WaitSet 、 _EntryList 和 _Owner,每个等待获取锁的线程都会被封装称为 ObjectWaiter 对象。

_Owner 是指向了 ObjectMonitor 对象的线程,而 _WaitSet 和 _EntryList 就是用来保存每个线程的列表。
那么这两个列表有什么区别呢?这个问题我和你聊一下锁的获取流程你就清楚了。
锁的两个列表
当多个线程同时访问某段同步代码时,首先会进入 _EntryList 集合,当线程获取到对象的 monitor 之后,就会进入 _Owner 区域,并把 ObjectMonitor 对象的 _Owner 指向为当前线程,并使 _count + 1,如果调用了释放锁(比如 wait)的操作,就会释放当前持有的 monitor ,owner = null, _count – 1,同时这个线程会进入到 _WaitSet 列表中等待被唤醒。如果当前线程执行完毕后也会释放 monitor 锁,只不过此时不会进入 _WaitSet 列表了,而是直接复位 _count 的值。

Klass Pointer 表示的是类型指针,也就是对象指向它的类元数据的指针,虚拟机通过这个指针来确定这个对象是哪个类的实例。
你可能不是很理解指针是个什么概念,你可以简单理解为指针就是指向某个数据的地址。

实例数据 Instance Data
实例数据部分是对象真正存储的有效信息,也是代码中定义的各个字段的字节大小,比如一个 byte 占 1 个字节,一个 int 占用 4 个字节。
对齐 Padding
对齐不是必须存在的,它只起到了占位符(%d, %c 等)的作用。这就是 JVM 的要求了,因为 HotSpot JVM 要求对象的起始地址必须是 8 字节的整数倍,也就是说对象的字节大小是 8 的整数倍,不够的需要使用 Padding 补全。
锁的升级流程
先来个大体的流程图来感受一下这个过程,然后下面我们再分开来说

无锁
无锁状态,无锁即没有对资源进行锁定,所有的线程都可以对同一个资源进行访问,但是只有一个线程能够成功修改资源。

无锁的特点就是在循环内进行修改操作,线程会不断的尝试修改共享资源,直到能够成功修改资源并退出,在此过程中没有出现冲突的发生,这很像我们在之前文章中介绍的 CAS 实现,CAS 的原理和应用就是无锁的实现。无锁无法全面代替有锁,但无锁在某些场合下的性能是非常高的。
偏向锁
HotSpot 的作者经过研究发现,大多数情况下,锁不仅不存在多线程竞争,还存在锁由同一线程多次获得的情况,偏向锁就是在这种情况下出现的,它的出现是为了解决只有在一个线程执行同步时提高性能。

可以从对象头的分配中看到,偏向锁要比无锁多了线程ID 和 epoch,下面我们就来描述一下偏向锁的获取过程
偏向锁获取过程
- 首先线程访问同步代码块,会通过检查对象头 Mark Word 的
锁标志位判断目前锁的状态,如果是 01,说明就是无锁或者偏向锁,然后再根据是否偏向锁的标示判断是无锁还是偏向锁,如果是无锁情况下,执行下一步 - 线程使用 CAS 操作来尝试对对象加锁,如果使用 CAS 替换 ThreadID 成功,就说明是第一次上锁,那么当前线程就会获得对象的偏向锁,此时会在对象头的 Mark Word 中记录当前线程 ID 和获取锁的时间 epoch 等信息,然后执行同步代码块。
全局安全点(Safe Point):全局安全点的理解会涉及到 C 语言底层的一些知识,这里简单理解 SafePoint 是 Java 代码中的一个线程可能暂停执行的位置。
等到下一次线程在进入和退出同步代码块时就不需要进行 CAS 操作进行加锁和解锁,只需要简单判断一下对象头的 Mark Word 中是否存储着指向当前线程的线程ID,判断的标志当然是根据锁的标志位来判断的。如果用流程图来表示的话就是下面这样

关闭偏向锁
偏向锁在Java 6 和Java 7 里是默认启用的。由于偏向锁是为了在只有一个线程执行同步块时提高性能,如果你确定应用程序里所有的锁通常情况下处于竞争状态,可以通过JVM参数关闭偏向锁:-XX:-UseBiasedLocking=false,那么程序默认会进入轻量级锁状态。
关于 epoch
偏向锁的对象头中有一个被称为 epoch 的值,它作为偏差有效性的时间戳。
轻量级锁
轻量级锁是指当前锁是偏向锁的时候,资源被另外的线程所访问,那么偏向锁就会升级为轻量级锁,其他线程会通过自旋的形式尝试获取锁,不会阻塞,从而提高性能,下面是详细的获取过程。
轻量级锁加锁过程
- 紧接着上一步,如果 CAS 操作替换 ThreadID 没有获取成功,执行下一步
- 如果使用 CAS 操作替换 ThreadID 失败(这时候就切换到另外一个线程的角度)说明该资源已被同步访问过,这时候就会执行锁的撤销操作,撤销偏向锁,然后等原持有偏向锁的线程到达
全局安全点(SafePoint)时,会暂停原持有偏向锁的线程,然后会检查原持有偏向锁的状态,如果已经退出同步,就会唤醒持有偏向锁的线程,执行下一步 - 检查对象头中的 Mark Word 记录的是否是当前线程 ID,如果是,执行同步代码,如果不是,执行偏向锁获取流程 的第2步。
如果用流程表示的话就是下面这样(已经包含偏向锁的获取)

重量级锁
重量级锁其实就是 synchronized 最终加锁的过程,在 JDK 1.6 之前,就是由无锁 -> 加锁的这个过程。
重量级锁的获取流程
- 接着上面偏向锁的获取过程,由偏向锁升级为轻量级锁,执行下一步
- 会在原持有偏向锁的线程的栈中分配锁记录,将对象头中的 Mark Word 拷贝到原持有偏向锁线程的记录中,然后原持有偏向锁的线程获得轻量级锁,然后唤醒原持有偏向锁的线程,从安全点处继续执行,执行完毕后,执行下一步,当前线程执行第 4 步
- 执行完毕后,开始轻量级解锁操作,解锁需要判断两个条件
- 判断对象头中的 Mark Word 中锁记录指针是否指向当前栈中记录的指针

- 拷贝在当前线程锁记录的 Mark Word 信息是否与对象头中的 Mark Word 一致。
如果上面两个判断条件都符合的话,就进行锁释放,如果其中一个条件不符合,就会释放锁,并唤起等待的线程,进行新一轮的锁竞争。
- 在当前线程的栈中分配锁记录,拷贝对象头中的 MarkWord 到当前线程的锁记录中,执行 CAS 加锁操作,会把对象头 Mark Word 中锁记录指针指向当前线程锁记录,如果成功,获取轻量级锁,执行同步代码,然后执行第3步,如果不成功,执行下一步
- 当前线程没有使用 CAS 成功获取锁,就会自旋一会儿,再次尝试获取,如果在多次自旋到达上限后还没有获取到锁,那么轻量级锁就会升级为
重量级锁

如果用流程图表示是这样的

根据上面对于锁升级细致的描述,我们可以总结一下不同锁的适用范围和场景。
| 锁类型 | 适用场景 | 缺点 | 优点 |
|---|---|---|---|
| 偏向锁 | 适用于只有一个线程访问的同步场景 | 如果存在多个线程竞争使用锁,会带来额外的锁撤销消耗 | 加锁和解消耗小 |
| 轻量级锁 | 适用于追求响应时间的应用场景 | 如果始终得不到资源,会自旋消耗 CPU | 提高程序响应速度 |
| 重量级锁 | 适用于追求吞吐量的应用场景 | 得不到锁的线程会阻塞,性能比较差 | 阻塞,不需要消耗 CPU |
synchronized 代码块的底层实现
为了便于方便研究,我们把 synchronized 修饰代码块的示例简单化,如下代码所示
public class SynchronizedTest {private int i;
public void syncTask(){
synchronized (this){
i++;
}
}
}
我们主要关注一下 synchronized 的字节码,如下所示

从这段字节码中我们可以知道,同步语句块使用的是 monitorenter 和 monitorexit 指令,其中 monitorenter 指令指向同步代码块的开始位置,monitorexit 指令指向同步代码块的结束位置。
那么为什么会有两个 monitorexit 呢?
不知道你注意到下面的异常表了吗?如果你不知道什么是异常表,那么我建议你读一下这篇文章
看完这篇Exception 和 Error,和面试官扯皮就没问题了
synchronized 修饰方法的底层原理
方法的同步是隐式的,也就是说 synchronized 修饰方法的底层无需使用字节码来控制,真的是这样吗?我们来反编译一波看看结果
public class SynchronizedTest {private int i;
public synchronized void syncTask(){
i++;
}
}
这次我们使用 javap -verbose 来输出详细的结果

从字节码上可以看出,synchronized 修饰的方法并没有使用 monitorenter 和 monitorexit 指令,取得代之是ACC_SYNCHRONIZED 标识,该标识指明了此方法是一个同步方法,JVM 通过该 ACC_SYNCHRONIZED 访问标志来辨别一个方法是否声明为同步方法,从而执行相应的同步调用。这就是 synchronized 锁在同步代码块上和同步方法上的实现差别。
# 深入理解AQS-Java面试题
前言
谈到并发,我们不得不说AQS(AbstractQueuedSynchronizer),所谓的AQS即是抽象的队列式的同步器,内部定义了很多锁相关的方法,我们熟知的ReentrantLock、ReentrantReadWriteLock、CountDownLatch、Semaphore等都是基于AQS来实现的。
我们先看下AQS相关的UML图:
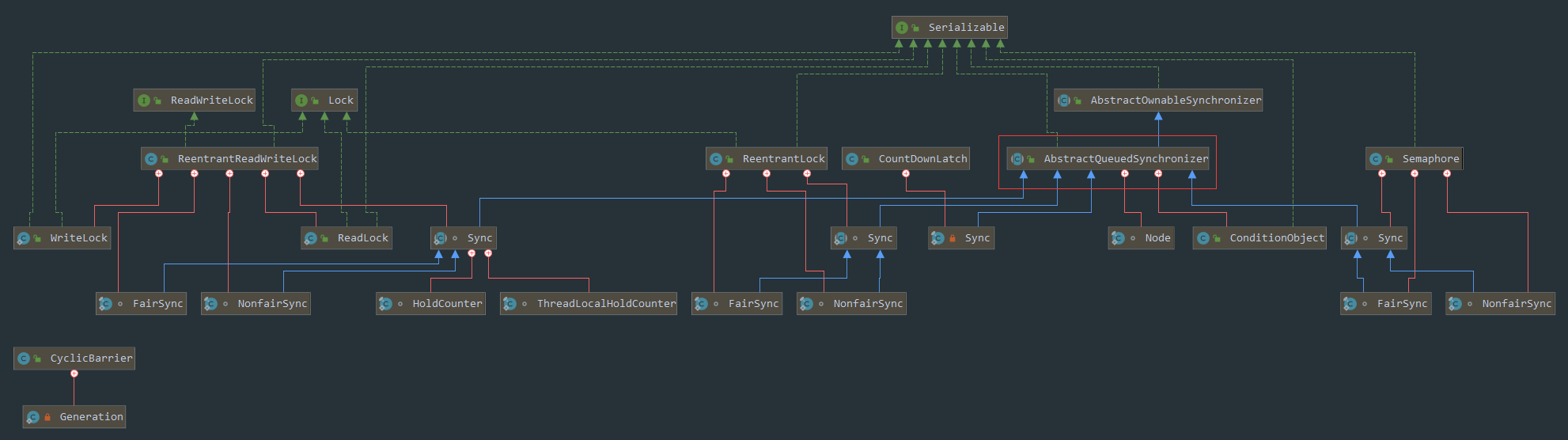
思维导图:
AQS实现原理
AQS中 维护了一个volatile int state(代表共享资源)和一个FIFO线程等待队列(多线程争用资源被阻塞时会进入此队列)。
这里volatile能够保证多线程下的可见性,当state=1则代表当前对象锁已经被占有,其他线程来加锁时则会失败,加锁失败的线程会被放入一个FIFO的等待队列中,比列会被UNSAFE.park()操作挂起,等待其他获取锁的线程释放锁才能够被唤醒。
另外state的操作都是通过CAS来保证其并发修改的安全性。
具体原理我们可以用一张图来简单概括:
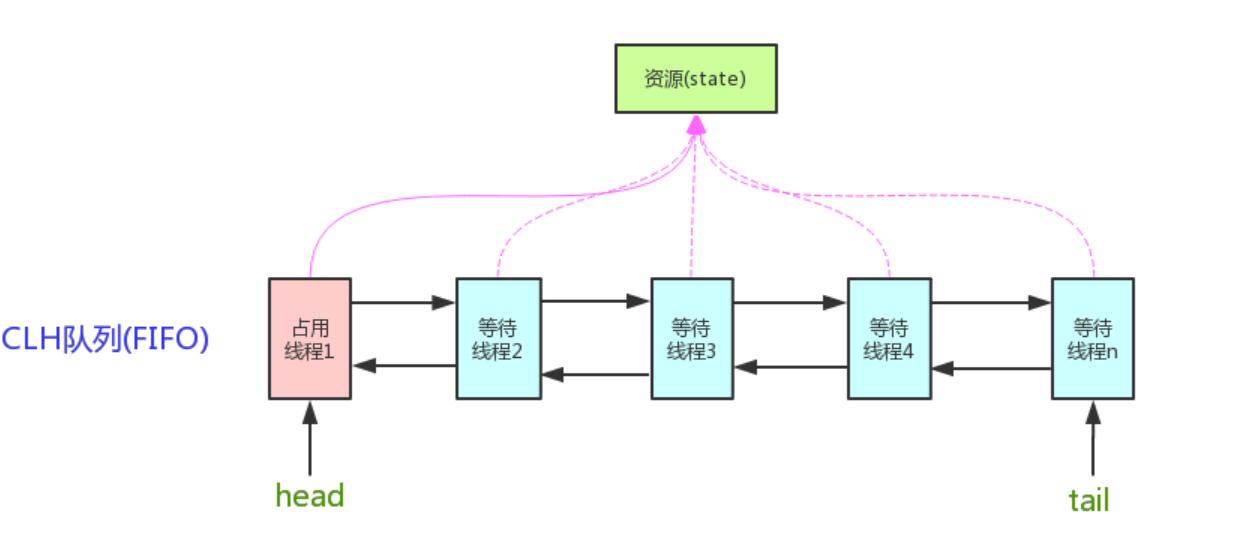
AQS 中提供了很多关于锁的实现方法,
- getState():获取锁的标志state值
- setState():设置锁的标志state值
- tryAcquire(int):独占方式获取锁。尝试获取资源,成功则返回true,失败则返回false。
- tryRelease(int):独占方式释放锁。尝试释放资源,成功则返回true,失败则返回false。
这里还有一些方法并没有列出来,接下来我们以ReentrantLock作为突破点通过源码和画图的形式一步步了解AQS内部实现原理。
目录结构
文章准备模拟多线程竞争锁、释放锁的场景来进行分析AQS源码:
三个线程(线程一、线程二、线程三)同时来加锁/释放锁
目录如下:
- 线程一加锁成功时
AQS内部实现 - 线程二/三加锁失败时
AQS中等待队列的数据模型 - 线程一释放锁及线程二获取锁实现原理
- 通过线程场景来讲解公平锁具体实现原理
- 通过线程场景来讲解Condition中a
wait()和signal()实现原理
这里会通过画图来分析每个线程加锁、释放锁后AQS内部的数据结构和实现原理
场景分析
线程一加锁成功
如果同时有三个线程并发抢占锁,此时线程一抢占锁成功,线程二和线程三抢占锁失败,具体执行流程如下:
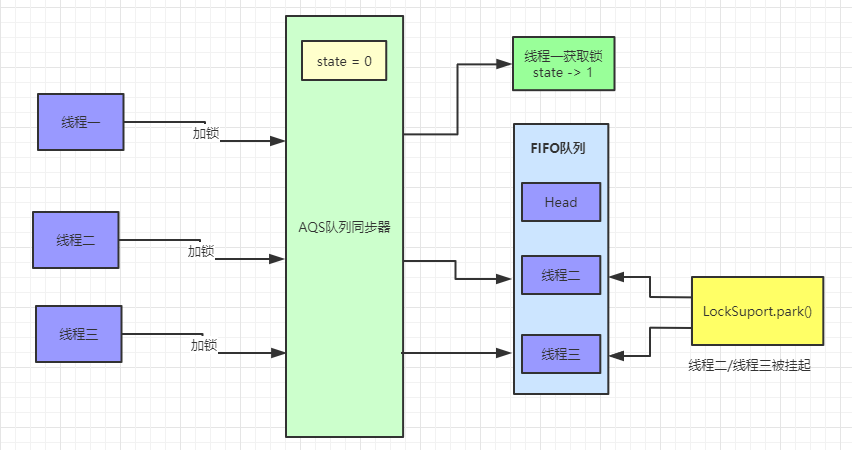
此时AQS内部数据为:
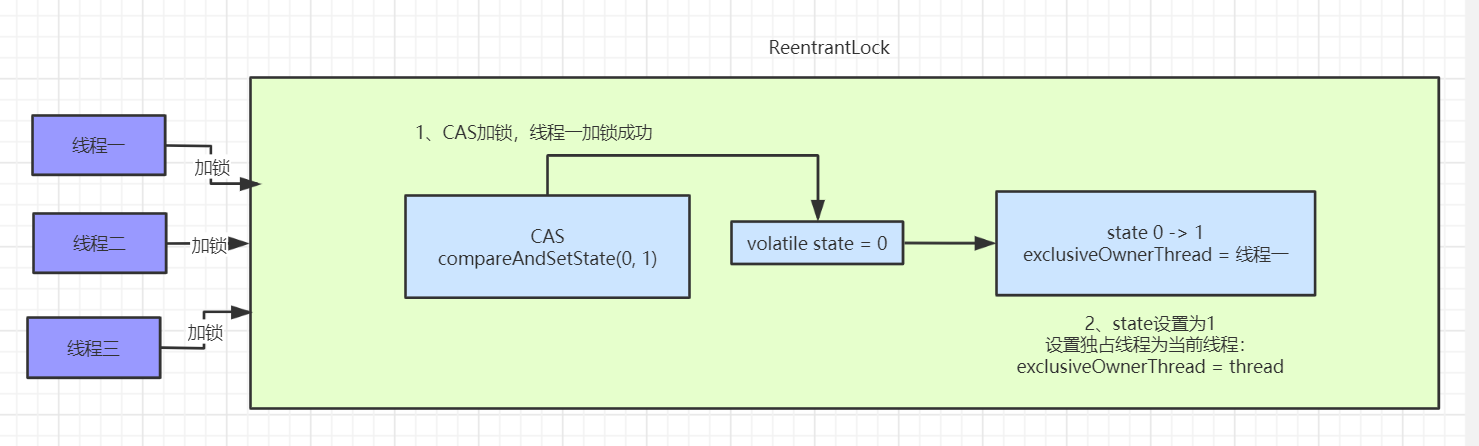
线程二、线程三加锁失败:
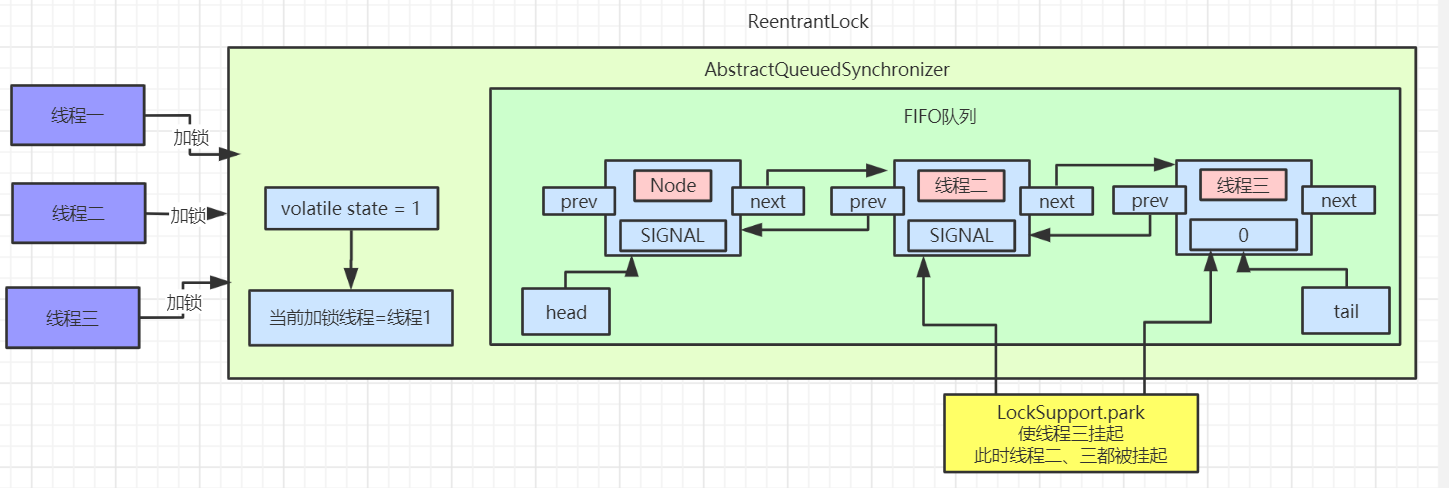
有图可以看出,等待队列中的节点Node是一个双向链表,这里SIGNAL是Node中waitStatus属性,Node中还有一个nextWaiter属性,这个并未在图中画出来,这个到后面Condition会具体讲解的。
具体看下抢占锁代码实现:
java.util.concurrent.locks.ReentrantLock .NonfairSync:
final void lock() {
if (compareAndSetState(0, 1))
setExclusiveOwnerThread(Thread.currentThread());
else
acquire(1);
}
protected final boolean tryAcquire(int acquires) {
return nonfairTryAcquire(acquires);
}
}
这里使用的ReentrantLock非公平锁,线程进来直接利用CAS尝试抢占锁,如果抢占成功state值回被改为1,且设置对象独占锁线程为当前线程。如下所示:
protected final void setExclusiveOwnerThread(Thread thread) { exclusiveOwnerThread = thread; }
线程二抢占锁失败
我们按照真实场景来分析,线程一抢占锁成功后,state变为1,线程二通过CAS修改state变量必然会失败。此时AQS中FIFO(First In First Out 先进先出)队列中数据如图所示:
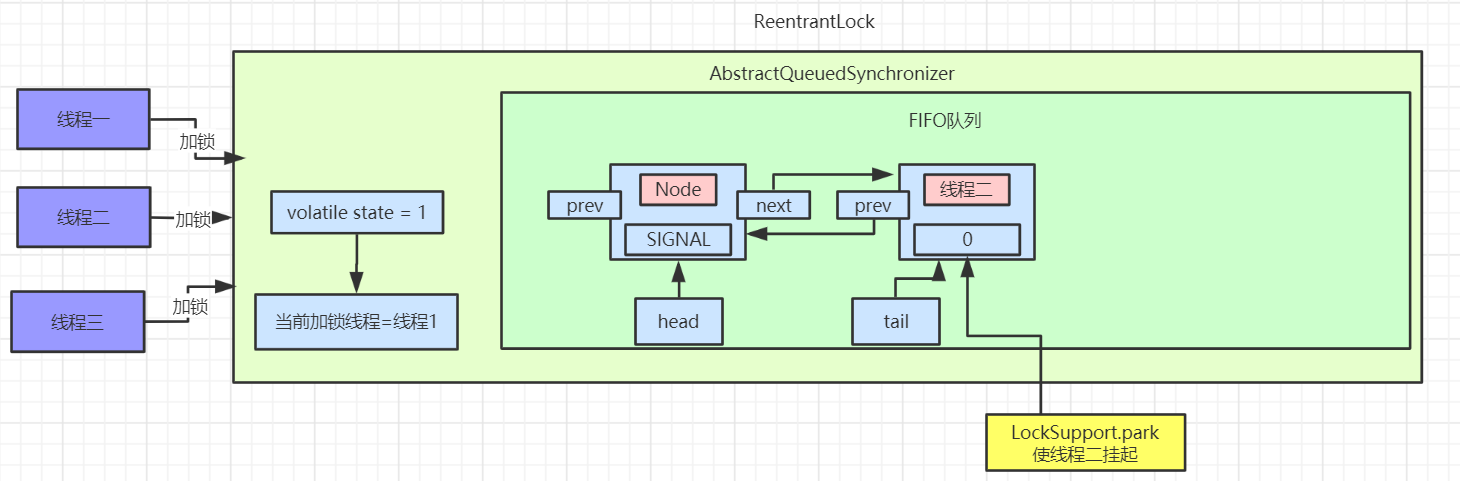
我们将线程二执行的逻辑一步步拆解来看:
java.util.concurrent.locks.AbstractQueuedSynchronizer.acquire():
先看看tryAcquire()的具体实现:
java.util.concurrent.locks.ReentrantLock .nonfairTryAcquire():
nonfairTryAcquire()方法中首先会获取state的值,如果不为0则说明当前对象的锁已经被其他线程所占有,接着判断占有锁的线程是否为当前线程,如果是则累加state值,这就是可重入锁的具体实现,累加state值,释放锁的时候也要依次递减state值。
如果state为0,则执行CAS操作,尝试更新state值为1,如果更新成功则代表当前线程加锁成功。
以线程二为例,因为线程一已经将state修改为1,所以线程二通过CAS修改state的值不会成功。加锁失败。
线程二执行tryAcquire()后会返回false,接着执行addWaiter(Node.EXCLUSIVE)逻辑,将自己加入到一个FIFO等待队列中,代码实现如下:
java.util.concurrent.locks.AbstractQueuedSynchronizer.addWaiter():
Node node = new Node(Thread.currentThread(), mode); Node pred = tail; if (pred != null) { node.prev = pred; if (compareAndSetTail(pred, node)) { pred.next = node; return node; } } enq(node); return node; }
这段代码首先会创建一个和当前线程绑定的Node节点,Node为双向链表。此时等待对内中的tail指针为空,直接调用enq(node)方法将当前线程加入等待队列尾部:
第一遍循环时tail指针为空,进入if逻辑,使用CAS操作设置head指针,将head指向一个新创建的Node节点。此时AQS中数据:
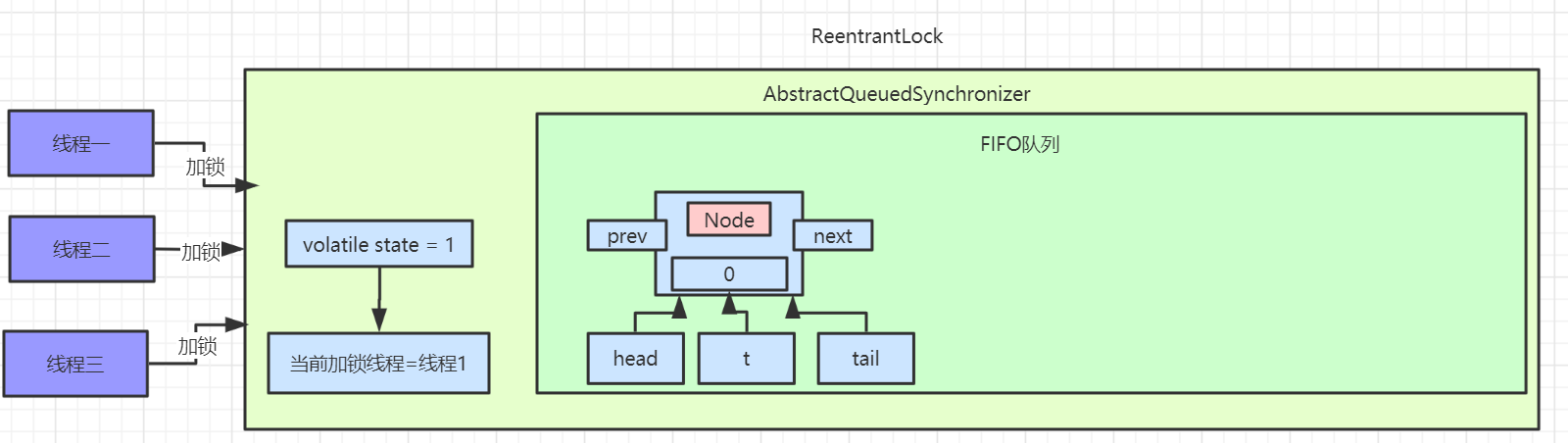
执行完成之后,head、tail、t都指向第一个Node元素。
接着执行第二遍循环,进入else逻辑,此时已经有了head节点,这里要操作的就是将线程二对应的Node节点挂到head节点后面。此时队列中就有了两个Node节点:
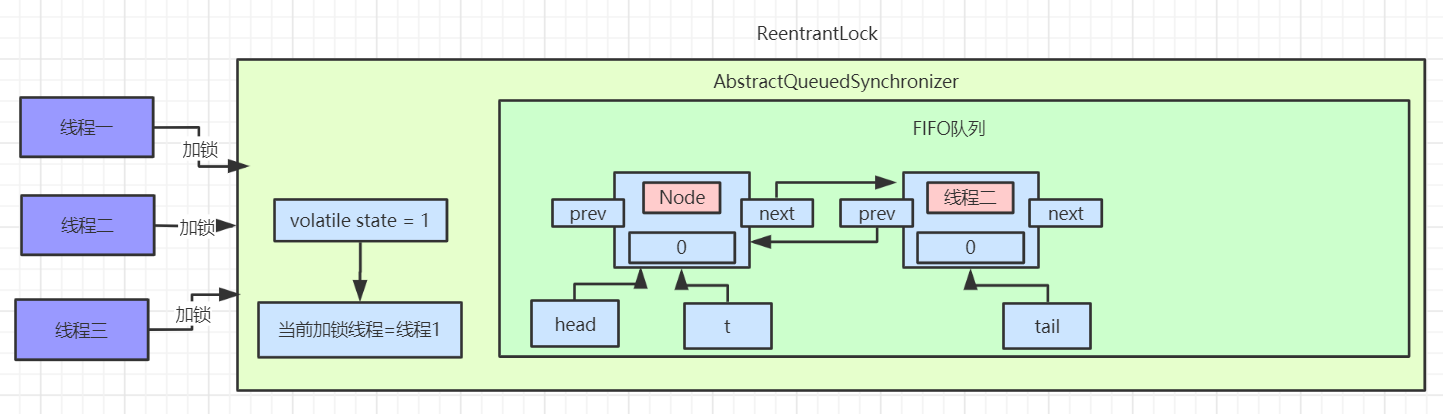
addWaiter()方法执行完后,会返回当前线程创建的节点信息。继续往后执行acquireQueued(addWaiter(Node.EXCLUSIVE), arg)
逻辑,此时传入的参数为线程二对应的Node节点信息:
java.util.concurrent.locks.AbstractQueuedSynchronizer.acquireQueued():
private static boolean shouldParkAfterFailedAcquire(Node pred, Node node) { int ws = pred.waitStatus; if (ws == Node.SIGNAL) return true; if (ws > 0) { do { node.prev = pred = pred.prev; } while (pred.waitStatus > 0); pred.next = node; } else { compareAndSetWaitStatus(pred, ws, Node.SIGNAL); } return false; }
private final boolean parkAndCheckInterrupt() { LockSupport.park(this); return Thread.interrupted(); }
acquireQueued()这个方法会先判断当前传入的Node对应的前置节点是否为head,如果是则尝试加锁。加锁成功过则将当前节点设置为head节点,然后空置之前的head节点,方便后续被垃圾回收掉。
如果加锁失败或者Node的前置节点不是head节点,就会通过shouldParkAfterFailedAcquire方法
将head节点的waitStatus变为了SIGNAL=-1,最后执行parkAndChecknIterrupt方法,调用LockSupport.park()挂起当前线程。
此时AQS中的数据如下图:
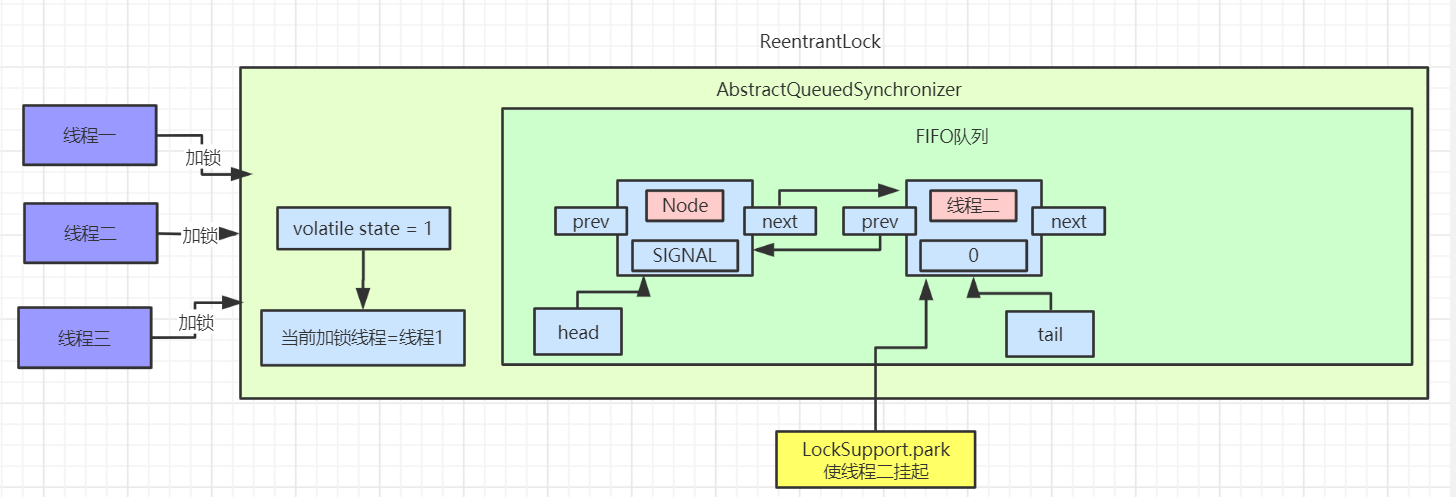
此时线程二就静静的待在AQS的等待队列里面了,等着其他线程释放锁来唤醒它。
线程三抢占锁失败
看完了线程二抢占锁失败的分析,那么再来分析线程三抢占锁失败就很简单了,先看看addWaiter(Node mode)方法:
此时等待队列的tail节点指向线程二,进入if逻辑后,通过CAS指令将tail节点重新指向线程三。接着线程三调用enq()方法执行入队操作,和上面线程二执行方式是一致的,入队后会修改线程二对应的Node中的waitStatus=SIGNAL。最后线程三也会被挂起。此时等待队列的数据如图:
线程一释放锁
现在来分析下释放锁的过程,首先是线程一释放锁,释放锁后会唤醒head节点的后置节点,也就是我们现在的线程二,具体操作流程如下:
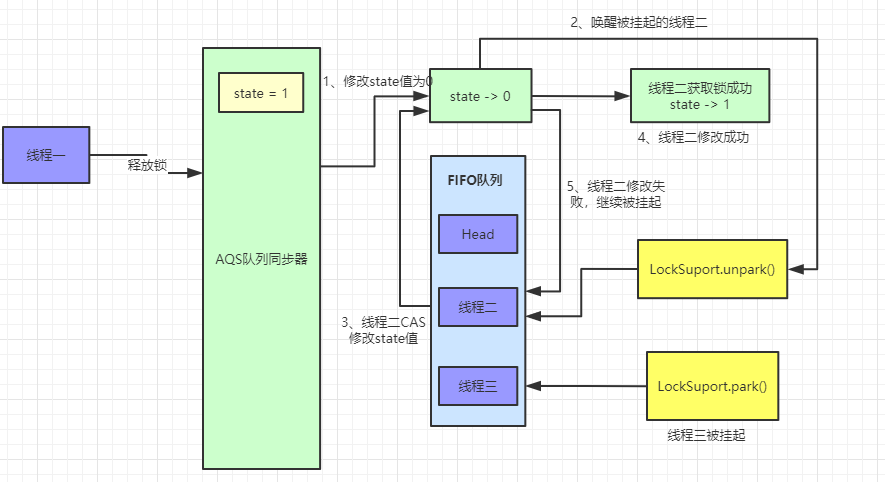
执行完后等待队列数据如下:
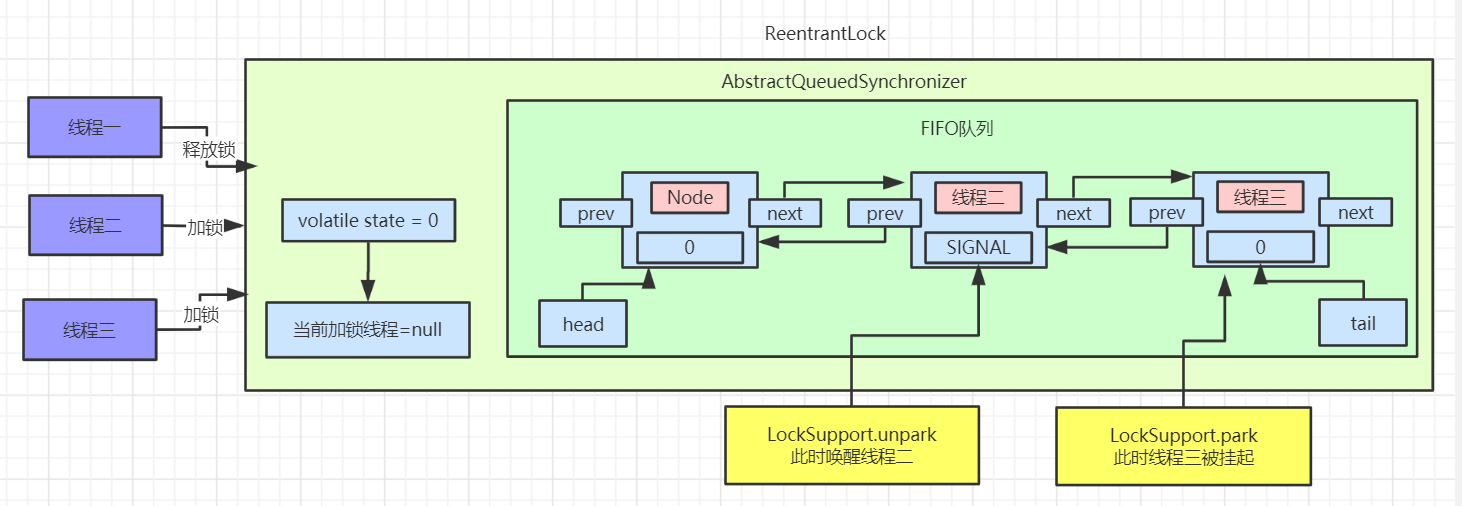
此时线程二已经被唤醒,继续尝试获取锁,如果获取锁失败,则会继续被挂起。如果获取锁成功,则AQS中数据如图:
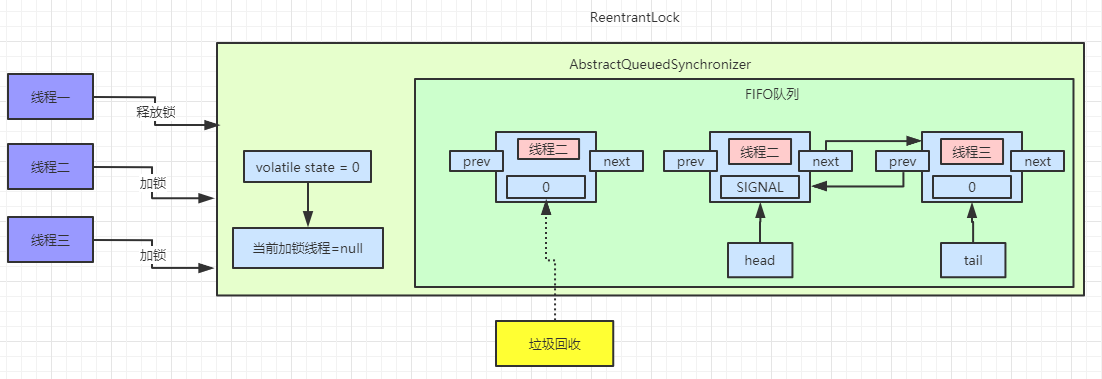
接着还是一步步拆解来看,先看看线程一释放锁的代码:
java.util.concurrent.locks.AbstractQueuedSynchronizer.release()
这里首先会执行tryRelease()方法,这个方法具体实现在ReentrantLock中,如果tryRelease执行成功,则继续判断head节点的waitStatus是否为0,前面我们已经看到过,head的waitStatue为SIGNAL(-1),这里就会执行unparkSuccessor()方法来唤醒head的后置节点,也就是我们上面图中线程二对应的Node节点。
此时看ReentrantLock.tryRelease()中的具体实现:
执行完ReentrantLock.tryRelease()后,state被设置成0,Lock对象的独占锁被设置为null。此时看下AQS中的数据:
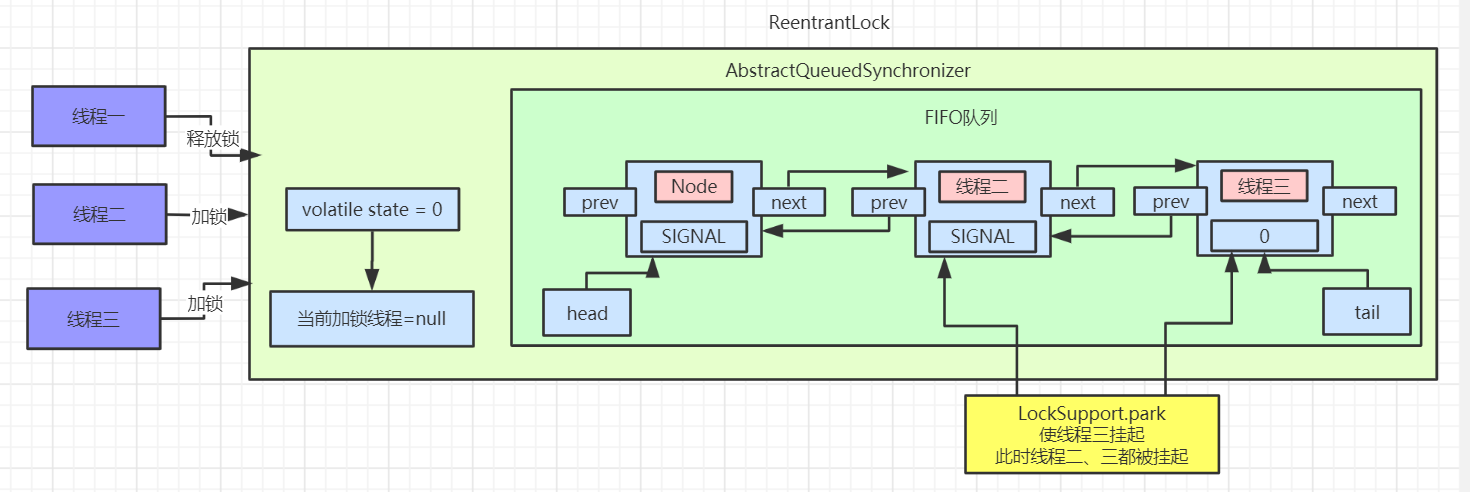
接着执行java.util.concurrent.locks.AbstractQueuedSynchronizer.unparkSuccessor()方法,唤醒head的后置节点:
这里主要是将head节点的waitStatus设置为0,然后解除head节点next的指向,使head节点空置,等待着被垃圾回收。
此时重新将head指针指向线程二对应的Node节点,且使用LockSupport.unpark方法来唤醒线程二。
被唤醒的线程二会接着尝试获取锁,用CAS指令修改state数据。
执行完成后可以查看AQS中数据:
此时线程二被唤醒,线程二接着之前被park的地方继续执行,继续执行acquireQueued()方法。
线程二唤醒继续加锁
final boolean acquireQueued(final Node node, int arg) { boolean failed = true; try { boolean interrupted = false; for (;😉 { final Node p = node.predecessor(); if (p == head && tryAcquire(arg)) { setHead(node); p.next = null; // help GC failed = false; return interrupted; } if (shouldParkAfterFailedAcquire(p, node) && parkAndCheckInterrupt()) interrupted = true; } } finally { if (failed) cancelAcquire(node); } }此时线程二被唤醒,继续执行for循环,判断线程二的前置节点是否为head,如果是则继续使用tryAcquire()方法来尝试获取锁,其实就是使用CAS操作来修改state值,如果修改成功则代表获取锁成功。接着将线程二设置为head节点,然后空置之前的head节点数据,被空置的节点数据等着被垃圾回收。
此时线程三获取锁成功,AQS中队列数据如下:
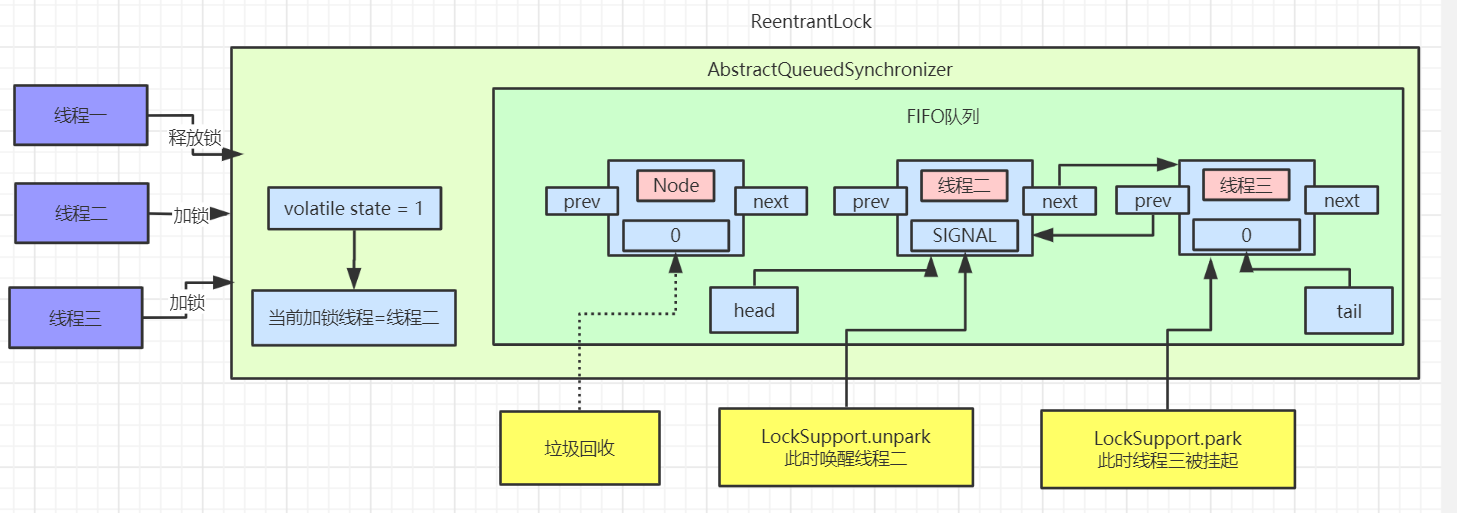
等待队列中的数据都等待着被垃圾回收。
线程二释放锁/线程三加锁
当线程二释放锁时,会唤醒被挂起的线程三,流程和上面大致相同,被唤醒的线程三会再次尝试加锁,具体代码可以参考上面内容。具体流程图如下:
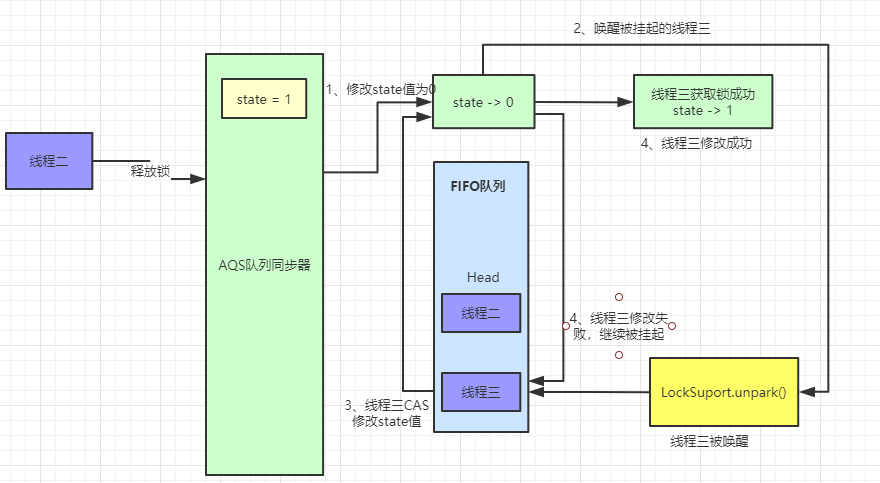
此时AQS中队列数据如图:
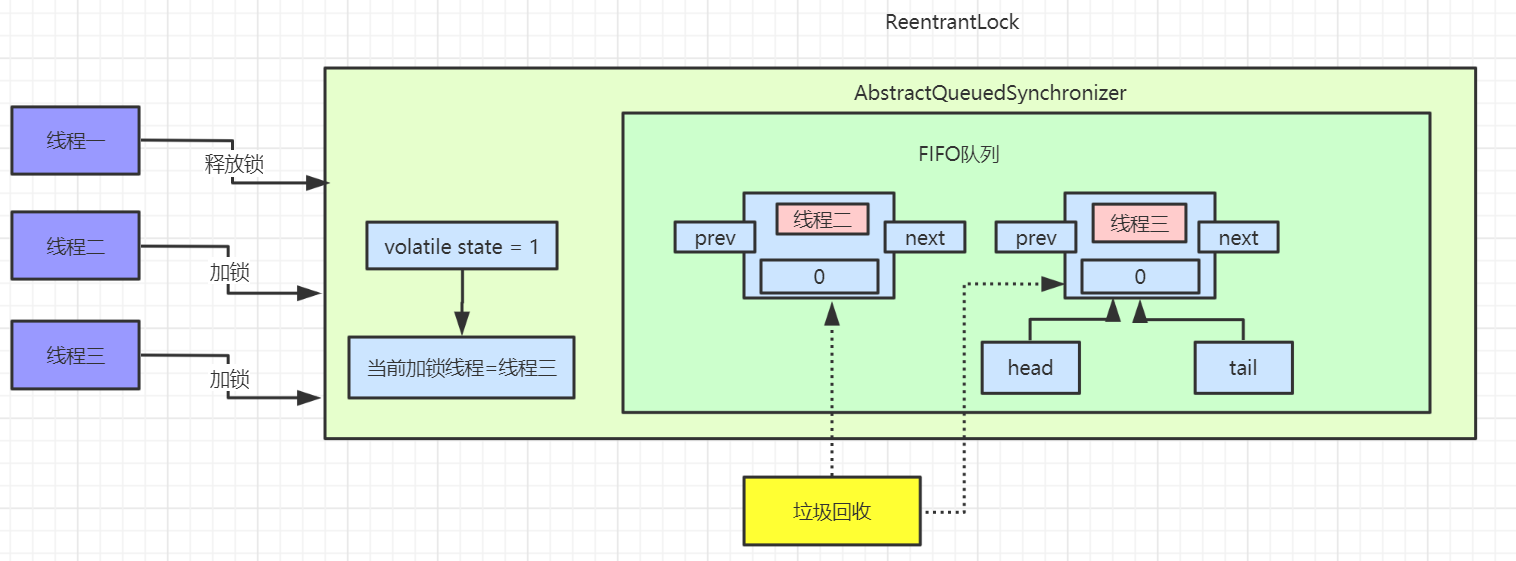
公平锁实现原理
上面所有的加锁场景都是基于非公平锁来实现的,非公平锁是ReentrantLock的默认实现,那我们接着来看一下公平锁的实现原理,这里先用一张图来解释公平锁和非公平锁的区别:
非公平锁执行流程:
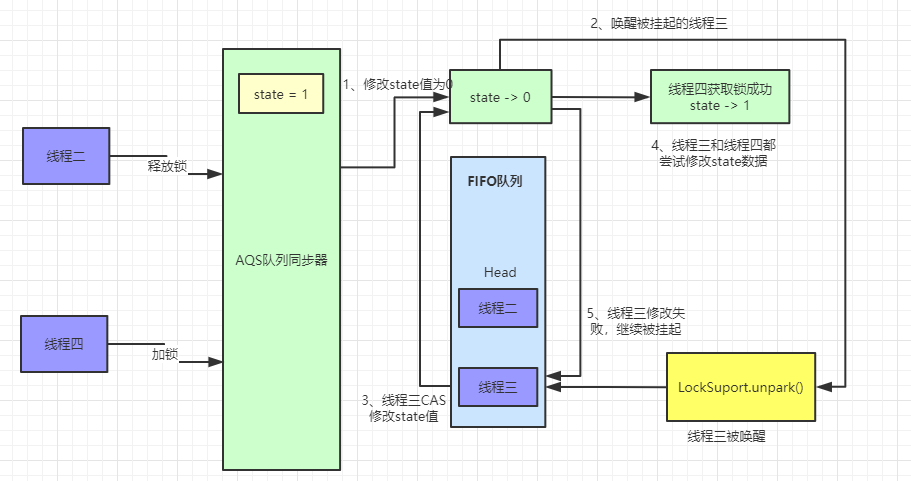
这里我们还是用之前的线程模型来举例子,当线程二释放锁的时候,唤醒被挂起的线程三,线程三执行tryAcquire()方法使用CAS操作来尝试修改state值,如果此时又来了一个线程四也来执行加锁操作,同样会执行tryAcquire()方法。
这种情况就会出现竞争,线程四如果获取锁成功,线程三仍然需要待在等待队列中被挂起。这就是所谓的非公平锁,线程三辛辛苦苦排队等到自己获取锁,却眼巴巴的看到线程四插队获取到了锁。
公平锁执行流程:
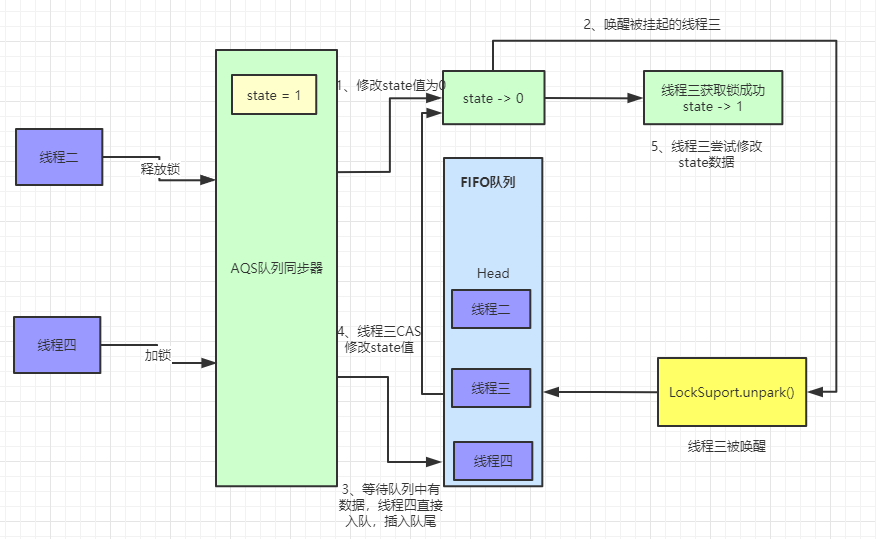
公平锁在加锁的时候,会先判断AQS等待队列中是存在节点,如果存在节点则会直接入队等待,具体代码如下.
公平锁在获取锁是也是首先会执行acquire()方法,只不过公平锁单独实现了tryAcquire()方法:
#java.util.concurrent.locks.AbstractQueuedSynchronizer.acquire():
这里会执行ReentrantLock中公平锁的tryAcquire()方法
#java.util.concurrent.locks.ReentrantLock.FairSync.tryAcquire():
这里会先判断state值,如果不为0且获取锁的线程不是当前线程,直接返回false代表获取锁失败,被加入等待队列。如果是当前线程则可重入获取锁。
如果state=0则代表此时没有线程持有锁,执行hasQueuedPredecessors()判断AQS等待队列中是否有元素存在,如果存在其他等待线程,那么自己也会加入到等待队列尾部,做到真正的先来后到,有序加锁。具体代码如下:
#java.util.concurrent.locks.AbstractQueuedSynchronizer.hasQueuedPredecessors():
这段代码很有意思,返回false代表队列中没有节点或者仅有一个节点是当前线程创建的节点。返回true则代表队列中存在等待节点,当前线程需要入队等待。
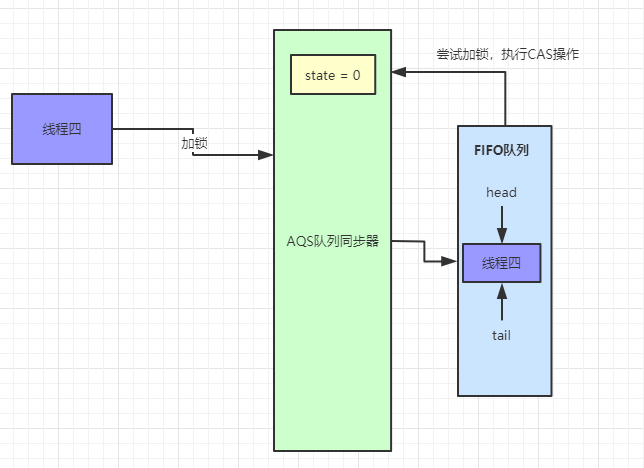
先判断head是否等于tail,如果队列中只有一个Node节点,那么head会等于tail,接着判断head的后置节点,这里肯定会是null,如果此Node节点对应的线程和当前的线程是同一个线程,那么则会返回false,代表没有等待节点或者等待节点就是当前线程创建的Node节点。此时当前线程会尝试获取锁。
如果head和tail不相等,说明队列中有等待线程创建的节点,此时直接返回true,如果只有一个节点,而此节点的线程和当前线程不一致,也会返回true
非公平锁和公平锁的区别:
非公平锁性能高于公平锁性能。非公平锁可以减少CPU唤醒线程的开销,整体的吞吐效率会高点,CPU也不必取唤醒所有线程,会减少唤起线程的数量
非公平锁性能虽然优于公平锁,但是会存在导致线程饥饿的情况。在最坏的情况下,可能存在某个线程一直获取不到锁。不过相比性能而言,饥饿问题可以暂时忽略,这可能就是ReentrantLock默认创建非公平锁的原因之一了。
Condition实现原理
Condition简介
上面已经介绍了AQS所提供的核心功能,当然它还有很多其他的特性,这里我们来继续说下Condition这个组件。
Condition是在java 1.5中才出现的,它用来替代传统的Object的wait()、notify()实现线程间的协作,相比使用Object的wait()、notify(),使用Condition中的await()、signal()这种方式实现线程间协作更加安全和高效。因此通常来说比较推荐使用Condition
其中AbstractQueueSynchronizer中实现了Condition中的方法,主要对外提供awaite(Object.wait())和signal(Object.notify())调用。
Condition Demo示例
使用示例代码:
/**ReentrantLock 实现源码学习
@author 一枝花算不算浪漫
@date 2020/4/28 7:20 */ public class ReentrantLockDemo { static ReentrantLock lock = new ReentrantLock();
public static void main(String[] args) { Condition condition = lock.newCondition();
new Thread(() -> { lock.lock(); try { System.out.println("线程一加锁成功"); System.out.println("线程一执行await被挂起"); condition.await(); System.out.println("线程一被唤醒成功"); } catch (Exception e) { e.printStackTrace(); } finally { lock.unlock(); System.out.println("线程一释放锁成功"); } }).start(); new Thread(() -> { lock.lock(); try { System.out.println("线程二加锁成功"); condition.signal(); System.out.println("线程二唤醒线程一"); } finally { lock.unlock(); System.out.println("线程二释放锁成功"); } }).start();} }
执行结果如下图:
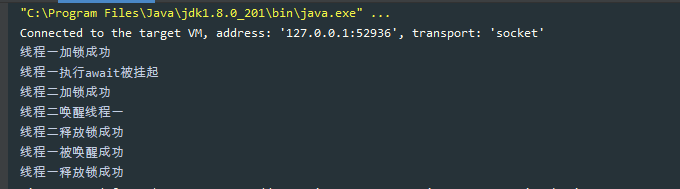
这里线程一先获取锁,然后使用
await()方法挂起当前线程并释放锁,线程二获取锁后使用signal唤醒线程一。Condition实现原理图解
我们还是用上面的
demo作为实例,执行的流程如下: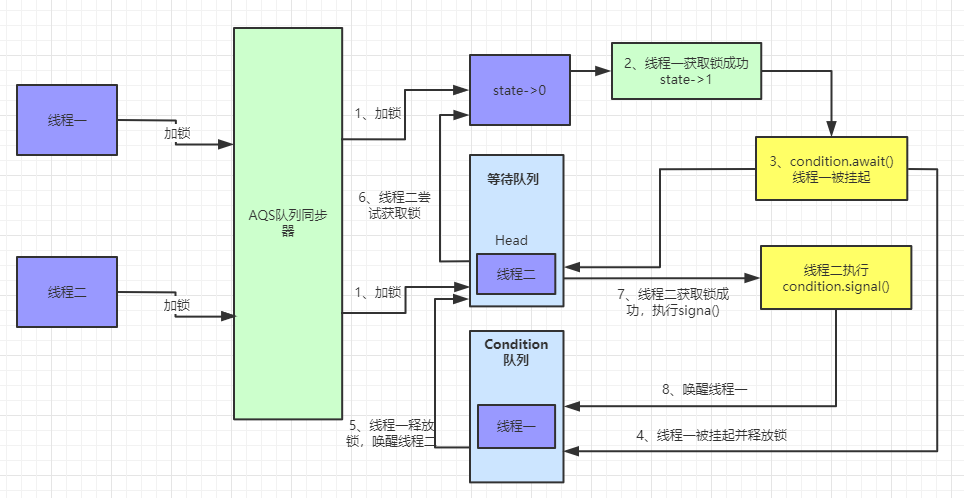
线程一执行
await()方法:先看下具体的代码实现,
public final void await() throws InterruptedException { if (Thread.interrupted()) throw new InterruptedException(); Node node = addConditionWaiter(); int savedState = fullyRelease(node); int interruptMode = 0; while (!isOnSyncQueue(node)) { LockSupport.park(this); if ((interruptMode = checkInterruptWhileWaiting(node)) != 0) break; } if (acquireQueued(node, savedState) && interruptMode != THROW_IE) interruptMode = REINTERRUPT; if (node.nextWaiter != null) // clean up if cancelled unlinkCancelledWaiters(); if (interruptMode != 0) reportInterruptAfterWait(interruptMode); }#java.util.concurrent.locks.AbstractQueuedSynchronizer.ConditionObject.await():await()方法中首先调用addConditionWaiter()将当前线程加入到Condition队列中。执行完后我们可以看下
Condition队列中的数据: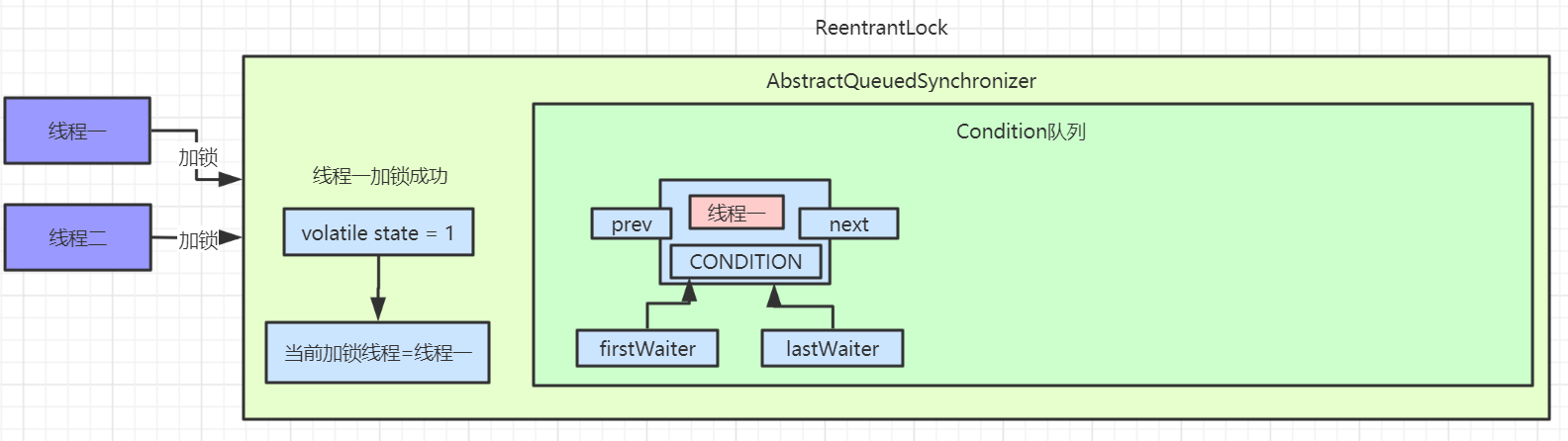
具体实现代码为:
private Node addConditionWaiter() { Node t = lastWaiter; if (t != null && t.waitStatus != Node.CONDITION) { unlinkCancelledWaiters(); t = lastWaiter; } Node node = new Node(Thread.currentThread(), Node.CONDITION); if (t == null) firstWaiter = node; else t.nextWaiter = node; lastWaiter = node; return node; }这里会用当前线程创建一个
Node节点,waitStatus为CONDITION。接着会释放该节点的锁,调用之前解析过的release()方法,释放锁后此时会唤醒被挂起的线程二,线程二会继续尝试获取锁。接着调用
isOnSyncQueue()方法判断当前节点是否为Condition队列中的头部节点,如果是则调用LockSupport.park(this)挂起Condition中当前线程。此时线程一被挂起,线程二获取锁成功。具体流程如下图:
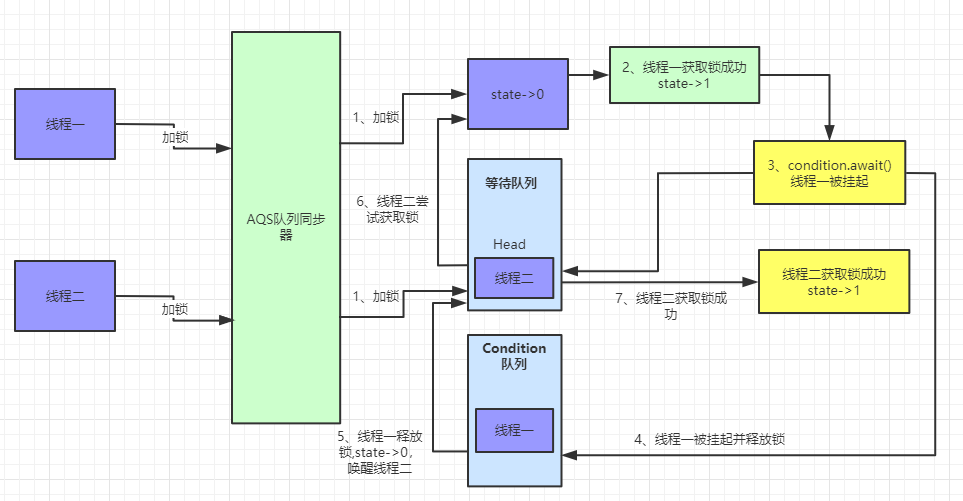
线程二执行
signal()方法:首先我们考虑下线程二已经获取到锁,此时
AQS等待队列中已经没有了数据。接着就来看看线程二唤醒线程一的具体执行流程:
public final void signal() { if (!isHeldExclusively()) throw new IllegalMonitorStateException(); Node first = firstWaiter; if (first != null) doSignal(first); }先判断当前线程是否为获取锁的线程,如果不是则直接抛出异常。
private void doSignal(Node first) { do { if ( (firstWaiter = first.nextWaiter) == null) lastWaiter = null; first.nextWaiter = null; } while (!transferForSignal(first) && (first = firstWaiter) != null); }
接着调用doSignal()方法来唤醒线程。
final boolean transferForSignal(Node node) { if (!compareAndSetWaitStatus(node, Node.CONDITION, 0)) return false;
Node p = enq(node);
int ws = p.waitStatus;
if (ws > 0 || !compareAndSetWaitStatus(p, ws, Node.SIGNAL))
LockSupport.unpark(node.thread);
return true;
}
/**
- Inserts node into queue, initializing if necessary. See picture above.
- @param node the node to insert
- @return node's predecessor
*/
private Node enq(final Node node) {
for (;😉 {
Node t = tail;
if (t == null) { // Must initialize
if (compareAndSetHead(new Node()))
tail = head;
} else {
node.prev = t;
if (compareAndSetTail(t, node)) {
t.next = node;
return t;
}
}
}
}
这里先从
transferForSignal()方法来看,通过上面的分析我们知道Condition队列中只有线程一创建的一个Node节点,且waitStatue为CONDITION,先通过CAS修改当前节点waitStatus为0,然后执行enq()方法将当前线程加入到等待队列中,并返回当前线程的前置节点。加入等待队列的代码在上面也已经分析过,此时等待队列中数据如下图:
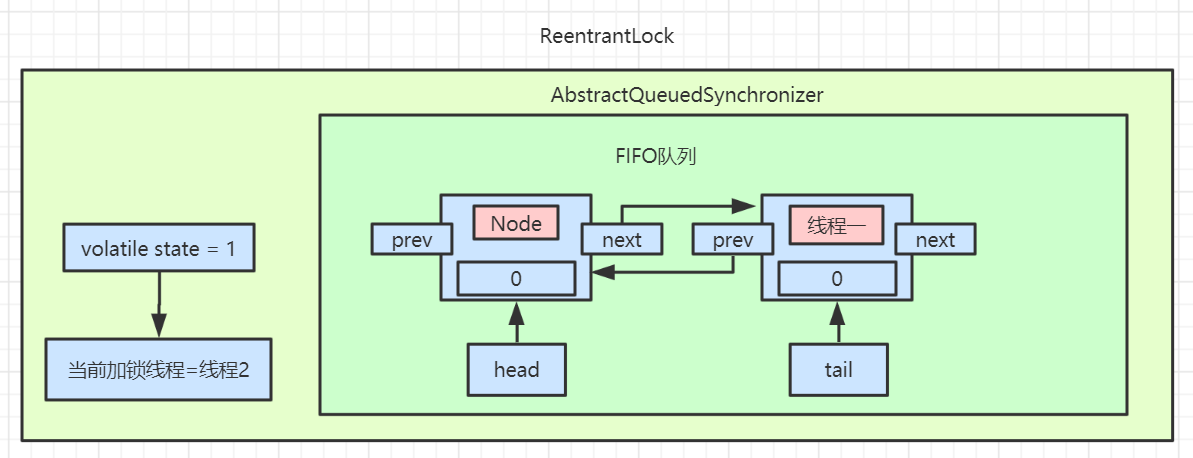
接着开始通过
CAS修改当前节点的前置节点waitStatus为SIGNAL,并且唤醒当前线程。此时AQS中等待队列数据为: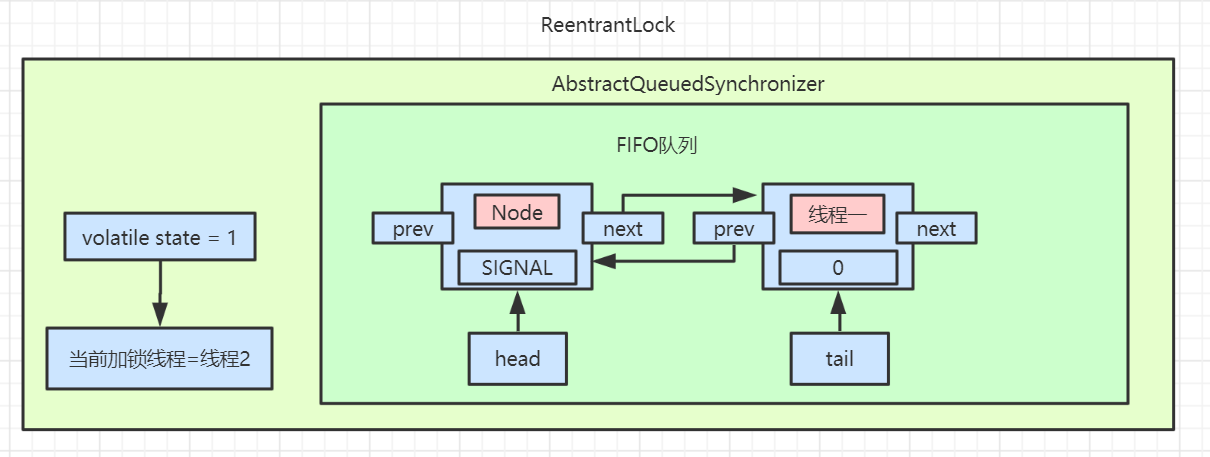
线程一被唤醒后,继续执行
public final void await() throws InterruptedException { if (Thread.interrupted()) throw new InterruptedException(); Node node = addConditionWaiter(); int savedState = fullyRelease(node); int interruptMode = 0; while (!isOnSyncQueue(node)) { LockSupport.park(this); if ((interruptMode = checkInterruptWhileWaiting(node)) != 0) break; } if (acquireQueued(node, savedState) && interruptMode != THROW_IE) interruptMode = REINTERRUPT; if (node.nextWaiter != null) // clean up if cancelled unlinkCancelledWaiters(); if (interruptMode != 0) reportInterruptAfterWait(interruptMode); }await()方法中的while循环。因为此时线程一的
waitStatus已经被修改为0,所以执行isOnSyncQueue()方法会返回false。跳出while循环。接着执行
final boolean acquireQueued(final Node node, int arg) { boolean failed = true; try { boolean interrupted = false; for (;😉 { final Node p = node.predecessor(); if (p == head && tryAcquire(arg)) { setHead(node); p.next = null; // help GC failed = false; return interrupted; } if (shouldParkAfterFailedAcquire(p, node) && parkAndCheckInterrupt()) interrupted = true; } } finally { if (failed) cancelAcquire(node); } }acquireQueued()方法,这里之前也有讲过,尝试重新获取锁,如果获取锁失败继续会被挂起。直到另外线程释放锁才被唤醒。此时线程一的流程都已经分析完了,等线程二释放锁后,线程一会继续重试获取锁,流程到此终结。
Condition总结
我们总结下Condition和wait/notify的比较:
Condition可以精准的对多个不同条件进行控制,wait/notify只能和synchronized关键字一起使用,并且只能唤醒一个或者全部的等待队列;
Condition需要使用Lock进行控制,使用的时候要注意lock()后及时的unlock(),Condition有类似于await的机制,因此不会产生加锁方式而产生的死锁出现,同时底层实现的是park/unpark的机制,因此也不会产生先唤醒再挂起的死锁,一句话就是不会产生死锁,但是wait/notify会产生先唤醒再挂起的死锁。
总结
这里用了一步一图的方式结合三个线程依次加锁/释放锁来展示了
ReentrantLock的实现方式和实现原理,而ReentrantLock底层就是基于AQS实现的,所以我们也对AQS有了深刻的理解。另外还介绍了公平锁与非公平锁的实现原理,
Condition的实现原理,基本上都是使用源码+绘图的讲解方式,尽量让大家更容易去理解。参考资料:
- 打通 Java 任督二脉 —— 并发数据结构的基石
https://juejin.im/post/5c11d6376fb9a049e82b6253 - Java并发之AQS详解https://www.cnblogs.com/waterystone/p/4920797.html
# Java锁之乐观锁和悲观锁-Java面试题
Java 按照锁的实现分为乐观锁和悲观锁,乐观锁和悲观锁并不是一种真实存在的锁,而是一种设计思想,乐观锁和悲观锁对于理解 Java 多线程和数据库来说至关重要,那么本篇文章就来详细探讨一下这两种锁的概念以及实现方式。
悲观锁
悲观锁是一种悲观思想,它总认为最坏的情况可能会出现,它认为数据很可能会被其他人所修改,所以悲观锁在持有数据的时候总会把资源 或者 数据 锁住,这样其他线程想要请求这个资源的时候就会阻塞,直到等到悲观锁把资源释放为止。传统的关系型数据库里边就用到了很多这种锁机制,比如行锁,表锁等,读锁,写锁等,都是在做操作之前先上锁。悲观锁的实现往往依靠数据库本身的锁功能实现。
Java 中的 Synchronized 和 ReentrantLock 等独占锁(排他锁)也是一种悲观锁思想的实现,因为 Synchronzied 和 ReetrantLock 不管是否持有资源,它都会尝试去加锁,生怕自己心爱的宝贝被别人拿走。
乐观锁
乐观锁的思想与悲观锁的思想相反,它总认为资源和数据不会被别人所修改,所以读取不会上锁,但是乐观锁在进行写入操作的时候会判断当前数据是否被修改过(具体如何判断我们下面再说)。乐观锁的实现方案一般来说有两种: 版本号机制 和 CAS实现 。乐观锁多适用于多度的应用类型,这样可以提高吞吐量。
在Java中java.util.concurrent.atomic包下面的原子变量类就是使用了乐观锁的一种实现方式CAS实现的。
两种锁的使用场景
上面介绍了两种锁的基本概念,并提到了两种锁的适用场景,一般来说,悲观锁不仅会对写操作加锁还会对读操作加锁,一个典型的悲观锁调用:
select * from student where name="cxuan" for update这条 sql 语句从 Student 表中选取 name = "cxuan" 的记录并对其加锁,那么其他写操作再这个事务提交之前都不会对这条数据进行操作,起到了独占和排他的作用。
悲观锁因为对读写都加锁,所以它的性能比较低,对于现在互联网提倡的三高(高性能、高可用、高并发)来说,悲观锁的实现用的越来越少了,但是一般多读的情况下还是需要使用悲观锁的,因为虽然加锁的性能比较低,但是也阻止了像乐观锁一样,遇到写不一致的情况下一直重试的时间。
相对而言,乐观锁用于读多写少的情况,即很少发生冲突的场景,这样可以省去锁的开销,增加系统的吞吐量。
乐观锁的适用场景有很多,典型的比如说成本系统,柜员要对一笔金额做修改,为了保证数据的准确性和实效性,使用悲观锁锁住某个数据后,再遇到其他需要修改数据的操作,那么此操作就无法完成金额的修改,对产品来说是灾难性的一刻,使用乐观锁的版本号机制能够解决这个问题,我们下面说。
乐观锁的实现方式
乐观锁一般有两种实现方式:采用版本号机制 和 CAS(Compare-and-Swap,即比较并替换)算法实现。
版本号机制
版本号机制是在数据表中加上一个 version 字段来实现的,表示数据被修改的次数,当执行写操作并且写入成功后,version = version + 1,当线程A要更新数据时,在读取数据的同时也会读取 version 值,在提交更新时,若刚才读取到的 version 值为当前数据库中的version值相等时才更新,否则重试更新操作,直到更新成功。
我们以上面的金融系统为例,来简述一下这个过程。

- 成本系统中有一个数据表,表中有两个字段分别是
金额和version,金额的属性是能够实时变化,而 version 表示的是金额每次发生变化的版本,一般的策略是,当金额发生改变时,version 采用递增的策略每次都在上一个版本号的基础上 + 1。 - 在了解了基本情况和基本信息之后,我们来看一下这个过程:公司收到回款后,需要把这笔钱放在金库中,假如金库中存有100 元钱
- 下面开启事务一:当男柜员执行回款写入操作前,他会先查看(读)一下金库中还有多少钱,此时读到金库中有 100 元,可以执行写操作,并把数据库中的钱更新为 120 元,提交事务,金库中的钱由 100 -> 120,version的版本号由 0 -> 1。
- 开启事务二:女柜员收到给员工发工资的请求后,需要先执行读请求,查看金库中的钱还有多少,此时的版本号是多少,然后从金库中取出员工的工资进行发放,提交事务,成功后版本 + 1,此时版本由 1 -> 2。
上面两种情况是最乐观的情况,上面的两个事务都是顺序执行的,也就是事务一和事务二互不干扰,那么事务要并行执行会如何呢?

事务一开启,男柜员先执行读操作,取出金额和版本号,执行写操作
begin update 表 set 金额 = 120,version = version + 1 where 金额 = 100 and version = 0此时金额改为 120,版本号为1,事务还没有提交
事务二开启,女柜员先执行读操作,取出金额和版本号,执行写操作
begin update 表 set 金额 = 50,version = version + 1 where 金额 = 100 and version = 0此时金额改为 50,版本号变为 1,事务未提交
现在提交事务一,金额改为 120,版本变为1,提交事务。理想情况下应该变为 金额 = 50,版本号 = 2,但是实际上事务二 的更新是建立在金额为 100 和 版本号为 0 的基础上的,所以事务二不会提交成功,应该重新读取金额和版本号,再次进行写操作。
这样,就避免了女柜员 用基于 version=0 的旧数据修改的结果覆盖男操作员操作结果的可能。
CAS 算法
先来看一道经典的并发执行 1000次递增和递减后的问题:
public class Counter {int count = 0;
public int getCount() {
return count;
}
public void setCount(int count) {
this.count = count;
}
public void add(){
count += 1;
}
public void dec(){
count -= 1;
}
} public class Consumer extends Thread{
Counter counter;
public Consumer(Counter counter){
this.counter = counter;
}
@Override
public void run() {
for(int j = 0;j < Test.LOOP;j++){
counter.dec();
}
}
}
public class Producer extends Thread{
Counter counter;
public Producer(Counter counter){
this.counter = counter;
}
@Override
public void run() {
for(int i = 0;i < Test.LOOP;++i){
counter.add();
}
}
}
public class Test {
final static int LOOP = 1000;
public static void main(String[] args) throws InterruptedException {
Counter counter = new Counter();
Producer producer = new Producer(counter);
Consumer consumer = new Consumer(counter);
producer.start();
consumer.start();
producer.join();
consumer.join();
System.out.println(counter.getCount());
}
}
多次测试的结果都不为 0,也就是说出现了并发后数据不一致的问题,原因是 count -= 1 和 count += 1 都是非原子性操作,它们的执行步骤分为三步:
- 从内存中读取 count 的值,把它放入寄存器中
- 执行 + 1 或者 – 1 操作
- 执行完成的结果再复制到内存中
如果要把证它们的原子性,必须进行加锁,使用 Synchronzied 或者 ReentrantLock,我们前面介绍它们是悲观锁的实现,我们现在讨论的是乐观锁,那么用哪种方式保证它们的原子性呢?请继续往下看
CAS 即 compare and swap(比较与交换),是一种有名的无锁算法。即不使用锁的情况下实现多线程之间的变量同步,也就是在没有线程被阻塞的情况下实现变量的同步,所以也叫非阻塞同步(Non-blocking Synchronization
CAS 中涉及三个要素:
- 需要读写的内存值 V
- 进行比较的值 A
- 拟写入的新值 B
当且仅当预期值A和内存值V相同时,将内存值V修改为B,否则什么都不做。
JAVA对CAS的支持:在JDK1.5 中新添加 java.util.concurrent (J.U.C) 就是建立在 CAS 之上的。对于 synchronized 这种阻塞算法,CAS是非阻塞算法的一种实现。所以J.U.C在性能上有了很大的提升。
我们以 java.util.concurrent 中的 AtomicInteger 为例,看一下在不用锁的情况下是如何保证线程安全的
private AtomicInteger integer = new AtomicInteger();
public AtomicInteger getInteger() {
return integer;
}
public void setInteger(AtomicInteger integer) {
this.integer = integer;
}
public void increment(){
integer.incrementAndGet();
}
public void decrement(){
integer.decrementAndGet();
}
}
public class AtomicProducer extends Thread{
private AtomicCounter atomicCounter;
public AtomicProducer(AtomicCounter atomicCounter){
this.atomicCounter = atomicCounter;
}
@Override
public void run() {
for(int j = 0; j < AtomicTest.LOOP; j++) {
System.out.println("producer : " + atomicCounter.getInteger());
atomicCounter.increment();
}
}
}
public class AtomicConsumer extends Thread{
private AtomicCounter atomicCounter;
public AtomicConsumer(AtomicCounter atomicCounter){
this.atomicCounter = atomicCounter;
}
@Override
public void run() {
for(int j = 0; j < AtomicTest.LOOP; j++) {
System.out.println("consumer : " + atomicCounter.getInteger());
atomicCounter.decrement();
}
}
}
public class AtomicTest {
final static int LOOP = 10000;
public static void main(String[] args) throws InterruptedException {
AtomicCounter counter = new AtomicCounter();
AtomicProducer producer = new AtomicProducer(counter);
AtomicConsumer consumer = new AtomicConsumer(counter);
producer.start();
consumer.start();
producer.join();
consumer.join();
System.out.println(counter.getInteger());
}
}
经测试可得,不管循环多少次最后的结果都是0,也就是多线程并行的情况下,使用 AtomicInteger 可以保证线程安全性。 incrementAndGet 和 decrementAndGet 都是原子性操作。本篇文章暂不探讨它们的实现方式。
乐观锁的缺点
任何事情都是有利也有弊,软件行业没有完美的解决方案只有最优的解决方案,所以乐观锁也有它的弱点和缺陷:
ABA 问题
ABA 问题说的是,如果一个变量第一次读取的值是 A,准备好需要对 A 进行写操作的时候,发现值还是 A,那么这种情况下,能认为 A 的值没有被改变过吗?可以是由 A -> B -> A 的这种情况,但是 AtomicInteger 却不会这么认为,它只相信它看到的,它看到的是什么就是什么。
JDK 1.5 以后的 AtomicStampedReference 类就提供了此种能力,其中的 compareAndSet 方法就是首先检查当前引用是否等于预期引用,并且当前标志是否等于预期标志,如果全部相等,则以原子方式将该引用和该标志的值设置为给定的更新值。
也可以采用CAS的一个变种DCAS来解决这个问题。
DCAS,是对于每一个V增加一个引用的表示修改次数的标记符。对于每个V,如果引用修改了一次,这个计数器就加1。然后再这个变量需要update的时候,就同时检查变量的值和计数器的值。
循环开销大
我们知道乐观锁在进行写操作的时候会判断是否能够写入成功,如果写入不成功将触发等待 -> 重试机制,这种情况是一个自旋锁,简单来说就是适用于短期内获取不到,进行等待重试的锁,它不适用于长期获取不到锁的情况,另外,自旋循环对于性能开销比较大。
CAS与synchronized的使用情景
简单的来说 CAS 适用于写比较少的情况下(多读场景,冲突一般较少),synchronized 适用于写比较多的情况下(多写场景,冲突一般较多)
- 对于资源竞争较少(线程冲突较轻)的情况,使用 synchronized 同步锁进行线程阻塞和唤醒切换以及用户态内核态间的切换操作额外浪费消耗 cpu 资源;而 CAS 基于硬件实现,不需要进入内核,不需要切换线程,操作自旋几率较少,因此可以获得更高的性能。
- 对于资源竞争严重(线程冲突严重)的情况,CAS 自旋的概率会比较大,从而浪费更多的 CPU 资源,效率低于 synchronized。
补充: Java并发编程这个领域中 synchronized 关键字一直都是元老级的角色,很久之前很多人都会称它为 “重量级锁” 。但是,在JavaSE 1.6之后进行了主要包括为了减少获得锁和释放锁带来的性能消耗而引入的 偏向锁 和 轻量级锁 以及其它各种优化之后变得在某些情况下并不是那么重了。synchronized 的底层实现主要依靠 Lock-Free 的队列,基本思路是 自旋后阻塞,竞争切换后继续竞争锁,稍微牺牲了公平性,但获得了高吞吐量。在线程冲突较少的情况下,可以获得和 CAS 类似的性能;而线程冲突严重的情况下,性能远高于CAS。
# CountDownLatch用法和源码解析-Java面试题
CountDownLatch 是多线程控制的一种工具,它被称为 门阀、 计数器或者 闭锁。这个工具经常用来用来协调多个线程之间的同步,或者说起到线程之间的通信(而不是用作互斥的作用)。下面我们就来一起认识一下 CountDownLatch
认识 CountDownLatch
CountDownLatch 能够使一个线程在等待另外一些线程完成各自工作之后,再继续执行。它相当于是一个计数器,这个计数器的初始值就是线程的数量,每当一个任务完成后,计数器的值就会减一,当计数器的值为 0 时,表示所有的线程都已经任务了,然后在 CountDownLatch 上等待的线程就可以恢复执行接下来的任务。
CountDownLatch 的使用
CountDownLatch 提供了一个构造方法,你必须指定其初始值,还指定了 countDown 方法,这个方法的作用主要用来减小计数器的值,当计数器变为 0 时,在 CountDownLatch 上 await 的线程就会被唤醒,继续执行其他任务。当然也可以延迟唤醒,给 CountDownLatch 加一个延迟时间就可以实现。

其主要方法如下

CountDownLatch 主要有下面这几个应用场景
CountDownLatch 应用场景
典型的应用场景就是当一个服务启动时,同时会加载很多组件和服务,这时候主线程会等待组件和服务的加载。当所有的组件和服务都加载完毕后,主线程和其他线程在一起完成某个任务。
CountDownLatch 还可以实现学生一起比赛跑步的程序,CountDownLatch 初始化为学生数量的线程,鸣枪后,每个学生就是一条线程,来完成各自的任务,当第一个学生跑完全程后,CountDownLatch 就会减一,直到所有的学生完成后,CountDownLatch 会变为 0 ,接下来再一起宣布跑步成绩。
顺着这个场景,你自己就可以延伸、拓展出来很多其他任务场景。
CountDownLatch 用法
下面我们通过一个简单的计数器来演示一下 CountDownLatch 的用法
public class TCountDownLatch {public static void main(String[] args) {
CountDownLatch latch = new CountDownLatch(5);
Increment increment = new Increment(latch);
Decrement decrement = new Decrement(latch);
new Thread(increment).start();
new Thread(decrement).start();
try {
Thread.sleep(6000);
} catch (InterruptedException e) {
e.printStackTrace();
}
}
}
class Decrement implements Runnable {
CountDownLatch countDownLatch;
public Decrement(CountDownLatch countDownLatch){
this.countDownLatch = countDownLatch;
}
@Override
public void run() {
try {
for(long i = countDownLatch.getCount();i > 0;i--){
Thread.sleep(1000);
System.out.println("countdown");
this.countDownLatch.countDown();
}
} catch (InterruptedException e) {
e.printStackTrace();
}
}
}
class Increment implements Runnable {
CountDownLatch countDownLatch;
public Increment(CountDownLatch countDownLatch){
this.countDownLatch = countDownLatch;
}
@Override
public void run() {
try {
System.out.println("await");
countDownLatch.await();
} catch (InterruptedException e) {
e.printStackTrace();
}
System.out.println("Waiter Released");
}
}
在 main 方法中我们初始化了一个计数器为 5 的 CountDownLatch,在 Decrement 方法中我们使用 countDown 执行减一操作,然后睡眠一段时间,同时在 Increment 类中进行等待,直到 Decrement 中的线程完成计数减一的操作后,唤醒 Increment 类中的 run 方法,使其继续执行。
下面我们再来通过学生赛跑这个例子来演示一下 CountDownLatch 的具体用法
public class StudentRunRace {CountDownLatch stopLatch = new CountDownLatch(1);
CountDownLatch runLatch = new CountDownLatch(10);
public void waitSignal() throws Exception{
System.out.println("选手" + Thread.currentThread().getName() + "正在等待裁判发布口令");
stopLatch.await();
System.out.println("选手" + Thread.currentThread().getName() + "已接受裁判口令");
Thread.sleep((long) (Math.random() * 10000));
System.out.println("选手" + Thread.currentThread().getName() + "到达终点");
runLatch.countDown();
}
public void waitStop() throws Exception{
Thread.sleep((long) (Math.random() * 10000));
System.out.println("裁判"+Thread.currentThread().getName()+"即将发布口令");
stopLatch.countDown();
System.out.println("裁判"+Thread.currentThread().getName()+"已发送口令,正在等待所有选手到达终点");
runLatch.await();
System.out.println("所有选手都到达终点");
System.out.println("裁判"+Thread.currentThread().getName()+"汇总成绩排名");
}
public static void main(String[] args) {
ExecutorService service = Executors.newCachedThreadPool();
StudentRunRace studentRunRace = new StudentRunRace();
for (int i = 0; i < 10; i++) {
Runnable runnable = () -> {
try {
studentRunRace.waitSignal();
} catch (Exception e) {
e.printStackTrace();
}
};
service.execute(runnable);
}
try {
studentRunRace.waitStop();
} catch (Exception e) {
e.printStackTrace();
}
service.shutdown();
}
}
下面我们就来一起分析一下 CountDownLatch 的源码
CountDownLatch 源码分析
CountDownLatch 使用起来比较简单,但是却非常有用,现在你可以在你的工具箱中加上 CountDownLatch 这个工具类了。下面我们就来深入认识一下 CountDownLatch。
CountDownLatch 的底层是由 AbstractQueuedSynchronizer 支持,而 AQS 的数据结构的核心就是两个队列,一个是 同步队列(sync queue),一个是条件队列(condition queue)。
Sync 内部类
CountDownLatch 在其内部是一个 Sync ,它继承了 AQS 抽象类。
private static final class Sync extends AbstractQueuedSynchronizer {...}CountDownLatch 其实其内部只有一个 sync 属性,并且是 final 的
CountDownLatch 只有一个带参数的构造方法
public CountDownLatch(int count) { if (count < 0) throw new IllegalArgumentException("count < 0"); this.sync = new Sync(count); }也就是说,初始化的时候必须指定计数器的数量,如果数量为负会直接抛出异常。
然后把 count 初始化为 Sync 内部的 count,也就是
Sync(int count) { setState(count); }注意这里有一个 setState(count),这是什么意思呢?见闻知意这只是一个设置状态的操作,但是实际上不单单是,还有一层意思是 state 的值代表着待达到条件的线程数。这个我们在聊 countDown 方法的时候再讨论。
getCount() 方法的返回值是 getState() 方法,它是 AbstractQueuedSynchronizer 中的方法,这个方法会返回当前线程计数,具有 volatile 读取的内存语义。
int getCount() { return getState(); }
// ---- AbstractQueuedSynchronizer ----
protected final int getState() { return state; }
tryAcquireShared() 方法用于获取·共享状态下对象的状态,判断对象是否为 0 ,如果为 0 返回 1 ,表示能够尝试获取,如果不为 0,那么返回 -1,表示无法获取。
// ---- getState() 方法和上面的方法相同 ----
这个 共享状态 属于 AQS 中的概念,在 AQS 中分为两种模式,一种是 独占模式,一种是 共享模式。
- tryAcquire 独占模式,尝试获取资源,成功则返回 true,失败则返回 false。
- tryAcquireShared 共享方式,尝试获取资源。负数表示失败;0 表示成功,但没有剩余可用资源;正数表示成功,且有剩余资源。
tryReleaseShared() 方法用于共享模式下的释放
这个方法是一个无限循环,获取线程状态,如果线程状态是 0 则表示没有被线程占有,没有占有的话那么直接返回 false ,表示已经释放;然后下一个状态进行 – 1 ,使用 compareAndSetState CAS 方法进行和内存值的比较,如果内存值也是 1 的话,就会更新内存值为 0 ,判断 nextc 是否为 0 ,如果 CAS 比较不成功的话,会再次进行循环判断。
如果 CAS 用法不清楚的话,读者朋友们可以参考这篇文章 告诉你一个 AtomicInteger 的惊天大秘密!
await 方法
await() 方法是 CountDownLatch 一个非常重要的方法,基本上可以说只有 countDown 和 await 方法才是 CountDownLatch 的精髓所在,这个方法将会使当前线程在 CountDownLatch 计数减至零之前一直等待,除非线程被中断。
CountDownLatch 中的 await 方法有两种,一种是不带任何参数的 await(),一种是可以等待一段时间的await(long timeout, TimeUnit unit)。下面我们先来看一下 await() 方法。
await 方法内部会调用 acquireSharedInterruptibly 方法,这个 acquireSharedInterruptibly 是 AQS 中的方法,以共享模式进行中断。
public final void acquireSharedInterruptibly(int arg) throws InterruptedException { if (Thread.interrupted()) throw new InterruptedException(); if (tryAcquireShared(arg) < 0) doAcquireSharedInterruptibly(arg); }可以看到,acquireSharedInterruptibly 方法的内部会首先判断线程是否中断,如果线程中断,则直接抛出线程中断异常。如果没有中断,那么会以共享的方式获取。如果能够在共享的方式下不能获取锁,那么就会以共享的方式断开链接。
这个方法有些长,我们分开来看
- 首先,会先构造一个共享模式的 Node 入队
- 然后使用无限循环判断新构造 node 的前驱节点,如果 node 节点的前驱节点是头节点,那么就会判断线程的状态,这里调用了一个 setHeadAndPropagate ,其源码如下
首先会设置头节点,然后进行一系列的判断,获取节点的获取节点的后继,以共享模式进行释放,就会调用 doReleaseShared 方法,我们再来看一下 doReleaseShared 方法
private void doReleaseShared() {for (;😉 { Node h = head; if (h != null && h != tail) { int ws = h.waitStatus; if (ws == Node.SIGNAL) { if (!compareAndSetWaitStatus(h, Node.SIGNAL, 0)) continue; // loop to recheck cases unparkSuccessor(h); } else if (ws == 0 && !compareAndSetWaitStatus(h, 0, Node.PROPAGATE)) continue; // loop on failed CAS } if (h == head) // loop if head changed break; } }
这个方法会以无限循环的方式首先判断头节点是否等于尾节点,如果头节点等于尾节点的话,就会直接退出。如果头节点不等于尾节点,会判断状态是否为 SIGNAL,不是的话就继续循环 compareAndSetWaitStatus,然后断开后继节点。如果状态不是 SIGNAL,也会调用 compareAndSetWaitStatus 设置状态为 PROPAGATE,状态为 0 并且不成功,就会继续循环。
也就是说 setHeadAndPropagate 就是设置头节点并且释放后继节点的一系列过程。
- 我们来看下面的 if 判断,也就是
shouldParkAfterFailedAcquire(p, node)这里
如果上面 Node p = node.predecessor() 获取前驱节点不是头节点,就会进行 park 断开操作,判断此时是否能够断开,判断的标准如下
private static boolean shouldParkAfterFailedAcquire(Node pred, Node node) { int ws = pred.waitStatus; if (ws == Node.SIGNAL) return true; if (ws > 0) { do { node.prev = pred = pred.prev; } while (pred.waitStatus > 0); pred.next = node; } else { compareAndSetWaitStatus(pred, ws, Node.SIGNAL); } return false; }这个方法会判断 Node p 的前驱节点的结点状态(waitStatus),节点状态一共有五种,分别是
CANCELLED(1):表示当前结点已取消调度。当超时或被中断(响应中断的情况下),会触发变更为此状态,进入该状态后的结点将不会再变化。SIGNAL(-1):表示后继结点在等待当前结点唤醒。后继结点入队时,会将前继结点的状态更新为 SIGNAL。CONDITION(-2):表示结点等待在 Condition 上,当其他线程调用了 Condition 的 signal() 方法后,CONDITION状态的结点将从等待队列转移到同步队列中,等待获取同步锁。PROPAGATE(-3):共享模式下,前继结点不仅会唤醒其后继结点,同时也可能会唤醒后继的后继结点。0:新结点入队时的默认状态。
如果前驱节点是 SIGNAL 就会返回 true 表示可以断开,如果前驱节点的状态大于 0 (此时为什么不用 ws == Node.CANCELLED ) 呢?因为 ws 大于 0 的条件只有 CANCELLED 状态了。然后就是一系列的查找遍历操作直到前驱节点的 waitStatus > 0。如果 ws <= 0 ,而且还不是 SIGNAL 状态的话,就会使用 CAS 替换前驱节点的 ws 为 SIGNAL 状态。
如果检查判断是中断状态的话,就会返回 false。
private final boolean parkAndCheckInterrupt() { LockSupport.park(this); return Thread.interrupted(); }这个方法使用 LockSupport.park 断开连接,然后返回线程是否中断的标志。
cancelAcquire()用于取消等待队列,如果等待过程中没有成功获取资源(如timeout,或者可中断的情况下被中断了),那么取消结点在队列中的等待。
node.thread = null;
Node pred = node.prev; while (pred.waitStatus > 0) node.prev = pred = pred.prev;
Node predNext = pred.next;
node.waitStatus = Node.CANCELLED;
if (node == tail && compareAndSetTail(node, pred)) { compareAndSetNext(pred, predNext, null); } else { int ws; if (pred != head && ((ws = pred.waitStatus) == Node.SIGNAL || (ws <= 0 && compareAndSetWaitStatus(pred, ws, Node.SIGNAL))) && pred.thread != null) { Node next = node.next; if (next != null && next.waitStatus <= 0) compareAndSetNext(pred, predNext, next); } else { unparkSuccessor(node); } node.next = node; // help GC } }
所以,对 CountDownLatch 的 await 调用大致会有如下的调用过程。

一个和 await 重载的方法是 await(long timeout, TimeUnit unit),这个方法和 await 最主要的区别就是这个方法能够可以等待计数器一段时间再执行后续操作。
countDown 方法
countDown 是和 await 同等重要的方法,countDown 用于减少计数器的数量,如果计数减为 0 的话,就会释放所有的线程。
public void countDown() { sync.releaseShared(1); }这个方法会调用 releaseShared 方法,此方法用于共享模式下的释放操作,首先会判断是否能够进行释放,判断的方法就是 CountDownLatch 内部类 Sync 的 tryReleaseShared 方法
public final boolean releaseShared(int arg) { if (tryReleaseShared(arg)) { doReleaseShared(); return true; } return false; }// ---- CountDownLatch ----
protected boolean tryReleaseShared(int releases) { for (;😉 { int c = getState(); if (c == 0) return false; int nextc = c-1; if (compareAndSetState(c, nextc)) return nextc == 0; } }
tryReleaseShared 会进行 for 循环判断线程状态值,使用 CAS 不断尝试进行替换。
如果能够释放,就会调用 doReleaseShared 方法
private void doReleaseShared() { for (;😉 { Node h = head; if (h != null && h != tail) { int ws = h.waitStatus; if (ws == Node.SIGNAL) { if (!compareAndSetWaitStatus(h, Node.SIGNAL, 0)) continue; // loop to recheck cases unparkSuccessor(h); } else if (ws == 0 && !compareAndSetWaitStatus(h, 0, Node.PROPAGATE)) continue; // loop on failed CAS } if (h == head) // loop if head changed break; } }可以看到,doReleaseShared 其实也是一个无限循环不断使用 CAS 尝试替换的操作。
总结
本文是 CountDownLatch 的基本使用和源码分析,CountDownLatch 就是一个基于 AQS 的计数器,它内部的方法都是围绕 AQS 框架来谈的,除此之外还有其他比如 ReentrantLock、Semaphore 等都是 AQS 的实现,所以要研究并发的话,离不开对 AQS 的探讨。CountDownLatch 的源码看起来很少,比较简单,但是其内部比如 await 方法的调用链路却很长,也值得花费时间深入研究。
# AtomicReference用法和源码分析-Java面试题
我们之前了解过了 AtomicInteger、AtomicLong、AtomicBoolean 等原子性工具类,下面我们继续了解一下位于 java.util.concurrent.atomic 包下的工具类。
关于 AtomicInteger、AtomicLong、AtomicBoolean 相关的内容请查阅
关于 AtomicReference 这种 JDK 工具类的了解的文章比较枯燥,并不是代表着文章质量的下降,因为我想搞出一整套 bestJavaer 的全方位解析,那就势必离不开对 JDK 工具类的了解。
记住:技术要做长线。
AtomicReference 基本使用
我们这里再聊起老生常谈的账户问题,通过个人银行账户问题,来逐渐引入 AtomicReference 的使用,我们首先来看一下基本的个人账户类
public class BankCard {private final String accountName;
private final int money;
// 构造函数初始化 accountName 和 money
public BankCard(String accountName,int money){
this.accountName = accountName;
this.money = money;
}
// 不提供任何修改个人账户的 set 方法,只提供 get 方法
public String getAccountName() {
return accountName;
}
public int getMoney() {
return money;
}
// 重写 toString() 方法, 方便打印 BankCard
@Override
public String toString() {
return "BankCard{" +
"accountName='" + accountName + '\'' +
", money='" + money + '\'' +
'}';
}
}
个人账户类只包含两个字段:accountName 和 money,这两个字段代表账户名和账户金额,账户名和账户金额一旦设置后就不能再被修改。
现在假设有多个人分别向这个账户打款,每次存入一定数量的金额,那么理想状态下每个人在每次打款后,该账户的金额都是在不断增加的,下面我们就来验证一下这个过程。
public class BankCardTest {private static volatile BankCard bankCard = new BankCard("cxuan",100);
public static void main(String[] args) {
for(int i = 0;i < 10;i++){
new Thread(() -> {
// 先读取全局的引用
final BankCard card = bankCard;
// 构造一个新的账户,存入一定数量的钱
BankCard newCard = new BankCard(card.getAccountName(),card.getMoney() + 100);
System.out.println(newCard);
// 最后把新的账户的引用赋给原账户
bankCard = newCard;
try {
TimeUnit.MICROSECONDS.sleep(1000);
}catch (Exception e){
e.printStackTrace();
}
}).start();
}
}
}
在上面的代码中,我们首先声明了一个全局变量 BankCard,这个 BankCard 由 volatile进行修饰,目的就是在对其引用进行变化后对其他线程可见,在每个打款人都存入一定数量的款项后,输出账户的金额变化,我们可以观察一下这个输出结果。

可以看到,我们预想最后的结果应该是 1100 元,但是最后却只存入了 900 元,那 200 元去哪了呢?我们可以断定上面的代码不是一个线程安全的操作。
问题出现在哪里?
虽然每次 volatile 都能保证每个账户的金额都是最新的,但是由于上面的步骤中出现了组合操作,即获取账户引用和更改账户引用,每个单独的操作虽然都是原子性的,但是组合在一起就不是原子性的了。所以最后的结果会出现偏差。
我们可以用如下线程切换图来表示一下这个过程的变化。

可以看到,最后的结果可能是因为在线程 t1 获取最新账户变化后,线程切换到 t2,t2 也获取了最新账户情况,然后再切换到 t1,t1 修改引用,线程切换到 t2,t2 修改引用,所以账户引用的值被修改了两次。
那么该如何确保获取引用和修改引用之间的线程安全性呢?
最简单粗暴的方式就是直接使用 synchronized 关键字进行加锁了。
使用 synchronized 保证线程安全性
使用 synchronized 可以保证共享数据的安全性,代码如下
public class BankCardSyncTest {private static volatile BankCard bankCard = new BankCard("cxuan",100);
public static void main(String[] args) {
for(int i = 0;i < 10;i++){
new Thread(() -> {
synchronized (BankCardSyncTest.class) {
// 先读取全局的引用
final BankCard card = bankCard;
// 构造一个新的账户,存入一定数量的钱
BankCard newCard = new BankCard(card.getAccountName(), card.getMoney() + 100);
System.out.println(newCard);
// 最后把新的账户的引用赋给原账户
bankCard = newCard;
try {
TimeUnit.MICROSECONDS.sleep(1000);
} catch (Exception e) {
e.printStackTrace();
}
}
}).start();
}
}
}
相较于 BankCardTest ,BankCardSyncTest 增加了 synchronized 锁,运行 BankCardSyncTest 后我们发现能够得到正确的结果。
修改 BankCardSyncTest.class 为 bankCard 对象,我们发现同样能够确保线程安全性,这是因为在这段程序中,只有 bankCard 会进行变化,不会再有其他共享数据。
如果有其他共享数据的话,我们需要使用 BankCardSyncTest.clas 确保线程安全性。
除此之外,java.util.concurrent.atomic 包下的 AtomicReference 也可以保证线程安全性。
我们先来认识一下 AtomicReference ,然后再使用 AtomicReference 改写上面的代码。
了解 AtomicReference
使用 AtomicReference 保证线程安全性
下面我们改写一下上面的那个示例
public class BankCardARTest {private static AtomicReference<BankCard> bankCardRef = new AtomicReference<>(new BankCard("cxuan",100));
public static void main(String[] args) {
for(int i = 0;i < 10;i++){
new Thread(() -> {
while (true){
// 使用 AtomicReference.get 获取
final BankCard card = bankCardRef.get();
BankCard newCard = new BankCard(card.getAccountName(), card.getMoney() + 100);
// 使用 CAS 乐观锁进行非阻塞更新
if(bankCardRef.compareAndSet(card,newCard)){
System.out.println(newCard);
}
try {
TimeUnit.SECONDS.sleep(1);
} catch (Exception e) {
e.printStackTrace();
}
}
}).start();
}
}
}
在上面的示例代码中,我们使用了 AtomicReference 封装了 BankCard 的引用,然后使用 get() 方法获得原子性的引用,接着使用 CAS 乐观锁进行非阻塞更新,更新的标准是如果使用 bankCardRef.get() 获取的值等于内存值的话,就会把银行卡账户的资金 + 100,我们观察一下输出结果。

可以看到,有一些输出是乱序执行的,出现这个原因很简单,有可能在输出结果之前,进行线程切换,然后打印了后面线程的值,然后线程切换回来再进行输出,但是可以看到,没有出现银行卡金额相同的情况。
AtomicReference 源码解析
在了解上面这个例子之后,我们来看一下 AtomicReference 的使用方法
AtomicReference 和 AtomicInteger 非常相似,它们内部都是用了下面三个属性

Unsafe 是 sun.misc 包下面的类,AtomicReference 主要是依赖于 sun.misc.Unsafe 提供的一些 native 方法保证操作的原子性。
Unsafe 的 objectFieldOffset 方法可以获取成员属性在内存中的地址相对于对象内存地址的偏移量。这个偏移量也就是 valueOffset ,说得简单点就是找到这个变量在内存中的地址,便于后续通过内存地址直接进行操作。
value 就是 AtomicReference 中的实际值,因为有 volatile ,这个值实际上就是内存值。
不同之处就在于 AtomicInteger 是对整数的封装,而 AtomicReference 则对应普通的对象引用。也就是它可以保证你在修改对象引用时的线程安全性。
get and set
我们首先来看一下最简单的 get 、set 方法:
get() : 获取当前 AtomicReference 的值
set() : 设置当前 AtomicReference 的值
get() 可以原子性的读取 AtomicReference 中的数据,set() 可以原子性的设置当前的值,因为 get() 和 set() 最终都是作用于 value 变量,而 value 是由 volatile 修饰的,所以 get 、set 相当于都是对内存进行读取和设置。如下图所示

lazySet 方法
volatile 有内存屏障你知道吗?
内存屏障是啥啊?
内存屏障,也称
内存栅栏,内存栅障,屏障指令等, 是一类同步屏障指令,是 CPU 或编译器在对内存随机访问的操作中的一个同步点,使得此点之前的所有读写操作都执行后才可以开始执行此点之后的操作。也是一个让CPU 处理单元中的内存状态对其它处理单元可见的一项技术。
CPU 使用了很多优化,使用缓存、指令重排等,其最终的目的都是为了性能,也就是说,当一个程序执行时,只要最终的结果是一样的,指令是否被重排并不重要。所以指令的执行时序并不是顺序执行的,而是乱序执行的,这就会带来很多问题,这也促使着内存屏障的出现。
语义上,内存屏障之前的所有写操作都要写入内存;内存屏障之后的读操作都可以获得同步屏障之前的写操作的结果。因此,对于敏感的程序块,写操作之后、读操作之前可以插入内存屏障。
内存屏障的开销非常轻量级,但是再小也是有开销的,LazySet 的作用正是如此,它会以普通变量的形式来读写变量。
也可以说是:懒得设置屏障了
getAndSet 方法
以原子方式设置为给定值并返回旧值。它的源码如下

它会调用 unsafe 中的 getAndSetObject 方法,源码如下

可以看到这个 getAndSet 方法涉及两个 cpp 实现的方法,一个是 getObjectVolatile ,一个是 compareAndSwapObject 方法,他们用在 do…while 循环中,也就是说,每次都会先获取最新对象引用的值,如果使用 CAS 成功交换两个对象的话,就会直接返回 var5 的值,var5 此时应该就是更新前的内存值,也就是旧值。
compareAndSet 方法
这就是 AtomicReference 非常关键的 CAS 方法了,与 AtomicInteger 不同的是,AtomicReference 是调用的 compareAndSwapObject ,而 AtomicInteger 调用的是 compareAndSwapInt 方法。这两个方法的实现如下

路径在 hotspot/src/share/vm/prims/unsafe.cpp 中。
我们之前解析过 AtomicInteger 的源码,所以我们接下来解析一下 AtomicReference 源码。
因为对象存在于堆中,所以方法 index_oop_from_field_offset_long 应该是获取对象的内存地址,然后使用 atomic_compare_exchange_oop 方法进行对象的 CAS 交换。

这段代码会首先判断是否使用了 UseCompressedOops,也就是指针压缩。
这里简单解释一下指针压缩的概念:JVM 最初的时候是 32 位的,但是随着 64 位 JVM 的兴起,也带来一个问题,内存占用空间更大了 ,但是 JVM 内存最好不要超过 32 G,为了节省空间,在 JDK 1.6 的版本后,我们在 64位中的 JVM 中可以开启指针压缩(UseCompressedOops)来压缩我们对象指针的大小,来帮助我们节省内存空间,在 JDK 8来说,这个指令是默认开启的。
如果不开启指针压缩的话,64 位 JVM 会采用 8 字节(64位)存储真实内存地址,比之前采用4字节(32位)压缩存储地址带来的问题:
- 增加了 GC 开销:64 位对象引用需要占用更多的堆空间,留给其他数据的空间将会减少,
从而加快了 GC 的发生,更频繁的进行 GC。 - 降低 CPU 缓存命中率:64 位对象引用增大了,CPU 能缓存的 oop 将会更少,从而降低了 CPU 缓存的效率。
由于 64 位存储内存地址会带来这么多问题,程序员发明了指针压缩技术,可以让我们既能够使用之前 4 字节存储指针地址,又能够扩大内存存储。
可以看到,atomic_compare_exchange_oop 方法底层也是使用了 Atomic:cmpxchg 方法进行 CAS 交换,然后把旧值进行 decode 返回 (我这局限的 C++ 知识,只能解析到这里了,如果大家懂这段代码一定告诉我,让我请教一波)
weakCompareAndSet 方法
weakCompareAndSet: 非常认真看了好几遍,发现 JDK1.8 的这个方法和 compareAndSet 方法完全一摸一样啊,坑我。。。
但是真的是这样么?并不是,JDK 源码很博大精深,才不会设计一个重复的方法,你想想 JDK 团队也不是会犯这种低级团队,但是原因是什么呢?
《Java 高并发详解》这本书给出了我们一个答案

总结
此篇文章主要介绍了 AtomicReference 的出现背景,AtomicReference 的使用场景,以及介绍了 AtomicReference 的源码,重点方法的源码分析。此篇 AtomicReference 的文章基本上涵盖了网络上所有关于 AtomicReference 的内容了,遗憾的是就是 cpp 源码可能分析的不是很到位,这需要充足的 C/C++ 编程知识,如果有读者朋友们有最新的研究成果,请及时告诉我。
# Java线程池-Java面试题

我们知道,线程需要的时候要进行创建,不需要的时候需要进行销毁,但是线程的创建和销毁都是一个开销比较大的操作。
为什么开销大呢?
虽然我们程序员创建一个线程很容易,直接使用 new Thread() 创建就可以了,但是操作系统做的工作会多很多,它需要发出 系统调用,陷入内核,调用内核 API 创建线程,为线程分配资源等,这一些操作有很大的开销。
所以,在高并发大流量的情况下,频繁的创建和销毁线程会大大拖慢响应速度,那么有什么能够提高响应速度的方式吗?方式有很多,尽量避免线程的创建和销毁是一种提升性能的方式,也就是把线程 复用 起来,因为性能是我们日常最关注的因素。
本篇文章我们先来通过认识一下 Executor 框架、然后通过描述线程池的基本概念入手、逐步认识线程池的核心类,然后慢慢进入线程池的原理中,带你一步一步理解线程池。
在 Java 中可以通过线程池来达到这样的效果。今天我们就来详细讲解一下 Java 的线程池。
Executor 框架
为什么要先说一下 Executor 呢?因为我认为 Executor 是线程池的一个驱动,我们平常创建并执行线程用的一般都是 new Thread().start() 这个方法,这个方法更多强调 创建一个线程并开始运行。而我们后面讲到创建线程池更多体现在驱动执行上。
Executor 的总体框架如下,我们下面会对 Executor 框架中的每个类进行介绍。

我们首先来认识一下 Executor
Executor 接口
Executor 是 java.util.concurrent 的顶级接口,这个接口只有一个方法,那就是 execute 方法。我们平常创建并启动线程会使用 new Thread().start() ,而 Executor 中的 execute 方法替代了显示创建线程的方式。Executor 的设计初衷就是将任务提交和任务执行细节进行解藕。使用 Executor 框架,你可以使用如下的方式创建线程
execute方法接收一个 Runnable 实例,它用来执行一个任务,而任务就是一个实现了 Runnable 接口的类,但是 execute 方法不能接收实现了 Callable 接口的类,也就是说,execute 方法不能接收具有返回值的任务。
execute 方法创建的线程是异步执行的,也就是说,你不用等待每个任务执行完毕后再执行下一个任务。

比如下面就是一个简单的使用 Executor 创建并执行线程的示例
public class RunnableTask implements Runnable{@Override
public void run() {
System.out.println("running");
}
public static void main(String[] args) {
Executor executor = Executors.newSingleThreadExecutor(); // 你可能不太理解这是什么意思,我们后面会说。
executor.execute(new RunnableTask());
}
}
Executor 就相当于是族长,大佬只发号令,族长让你异步执行你就得异步执行,族长说不用汇报任务你就不用回报,但是这个族长管的事情有点少,所以除了 Executor 之外,我们还需要认识其他管家,比如说管你这个线程啥时候终止,啥时候暂停,判断你这个线程当前的状态等,ExecutorService 就是一位大管家。
ExecutorService 接口
ExecutorService 也是一个接口,它是 Executor 的拓展,提供了一些 Executor 中没有的方法,下面我们来介绍一下这些方法
void shutdown();shutdown 方法调用后,ExecutorService 会有序关闭正在执行的任务,但是不接受新任务。如果任务已经关闭,那么这个方法不会产生任何影响。
ExecutorService 还有一个和 shutdown 方法类似的方法是
List<Runnable> shutdownNow();shutdownNow 会尝试停止关闭所有正在执行的任务,停止正在等待的任务,并返回正在等待执行的任务列表。
既然 shutdown 和 shutdownNow 这么相似,那么二者有啥区别呢?
- shutdown 方法只是会将
线程池的状态设置为SHUTWDOWN,正在执行的任务会继续执行下去,线程池会等待任务的执行完毕,而没有执行的线程则会中断。- shutdownNow 方法会将线程池的状态设置为
STOP,正在执行和等待的任务则被停止,返回等待执行的任务列表
ExecutorService 还有三个判断线程状态的方法,分别是
boolean isShutdown(); boolean isTerminated(); boolean awaitTermination(long timeout, TimeUnit unit) throws InterruptedException;isShutdown方法表示执行器是否已经关闭,如果已经关闭,返回 true,否则返回 false。isTerminated方法表示判断所有任务再关闭后是否已完成,如果完成返回 false,这个需要注意一点,除非首先调用 shutdown 或者 shutdownNow 方法,否则 isTerminated 方法永远不会为 true。awaitTermination方法会阻塞,直到发出调用 shutdown 请求后所有的任务已经完成执行后才会解除。这个方法不是非常容易理解,下面通过一个小例子来看一下。
public static void main(String[] args) throws InterruptedException { for (int i = 0; i < 10; i++) { executorService.submit(() -> { System.out.println(Thread.currentThread().getName()); try { Thread.sleep(10); } catch (InterruptedException e) { e.printStackTrace(); } });
}
executorService.shutdown(); System.out.println("Waiting..."); boolean isTermination = executorService.awaitTermination(3, TimeUnit.SECONDS); System.out.println("Waiting...Done"); if(isTermination){ System.out.println("All Thread Done"); } System.out.println(Thread.currentThread().getName()); }
如果在调用 executorService.shutdown() 之后,所有线程完成任务,isTermination 返回 true,程序才会打印出 All Thread Done ,如果注释掉 executorService.shutdown() 或者在任务没有完成后 awaitTermination 就超时了,那么 isTermination 就会返回 false。
ExecutorService 当大管家还有一个原因是因为它不仅能够包容 Runnable 对象,还能够接纳 Callable 对象。在 ExecutorService 中,submit 方法扮演了这个角色。
submit 方法会返回一个 Future对象,<T> 表示范型,它是对 Callable 产生的返回值来说的,submit 方法提交的任务中的 call 方法如果返回 Integer,那么 submit 方法就返回 Future<Integer>,依此类推。
invokeAll 方法用于执行给定的任务结合,执行完成后会返回一个任务列表,任务列表每一项是一个任务,每个任务会包括任务状态和执行结果,同样 invokeAll 方法也会返回 Future 对象。
invokeAny 会获得最先完成任务的结果,即Callable<T> 接口中的 call 的返回值,在获得结果时,会中断其他正在执行的任务,具有阻塞性。
大管家的职责相对于组长来说标准更多,管的事情也比较宽,但是大管家毕竟也是家族的中流砥柱,他不会做具体的活,他的下面有各个干将,干将是一个家族的核心,他负责完成大管家的工作。
AbstractExecutorService 抽象类
AbstractExecutorService 是一个抽象类,它实现了 ExecutorService 中的部分方法,它相当一个干将,会分析大管家有哪些要做的工作,然后针对大管家的要求做一些具体的规划,然后找他的得力助手 ThreadPoolExecutor 来完成目标。
AbstractExecutorService 这个抽象类主要实现了 invokeAll 和 invokeAny 方法,关于这两个方法的源码分析我们会在后面进行解释。
ScheduledExecutorService 接口
ScheduledExecutorService 也是一个接口,它扩展了 ExecutorService 接口,提供了 ExecutorService 接口所没有的功能,ScheduledExecutorService 顾名思义就是一个定时执行器,定时执行器可以安排命令在一定延迟时间后运行或者定期执行。
它主要有三个接口方法,一个重载方法。下面我们先来看一下这两个重载方法。
public ScheduledFuture<?> schedule(Runnable command, long delay, TimeUnit unit); public <V> ScheduledFuture<V> schedule(Callable<V> callable, long delay, TimeUnit unit);schedule 方法能够延迟一定时间后执行任务,并且只能执行一次。可以看到,schedule 方法也返回了一个 ScheduledFuture 对象,ScheduledFuture 对象扩展了 Future 和 Delayed 接口,它表示异步延迟计算的结果。schedule 方法支持零延迟和负延迟,这两类值都被视为立即执行任务。
还有一点需要说明的是,schedule 方法能够接收相对的时间和周期作为参数,而不是固定的日期,你可以使用 date.getTime – System.currentTimeMillis() 来得到相对的时间间隔。
public ScheduledFuture<?> scheduleAtFixedRate(Runnable command, long initialDelay, long period, TimeUnit unit);scheduleAtFixedRate 表示任务会根据固定的速率在时间 initialDelay 后不断地执行。
这个方法和上面的方法很类似,它表示的是以固定延迟时间的方式来执行任务。
public class ScheduleTest {scheduleAtFixedRate 和 scheduleWithFixedDelay 这两个方法容易混淆,下面我们通过一个示例来说明一下这两个方法的区别。
public static void main(String[] args) {
Runnable command = () -> {
long startTime = System.currentTimeMillis();
System.out.println("current timestamp = " + startTime);
try {
TimeUnit.MILLISECONDS.sleep(new Random().nextInt(100));
} catch (InterruptedException e) {
e.printStackTrace();
}
System.out.println("time spend = " + (System.currentTimeMillis() - startTime));
};
ScheduledExecutorService scheduledExecutorService = Executors.newScheduledThreadPool(10);
scheduledExecutorService.scheduleAtFixedRate(command,100,1000,TimeUnit.MILLISECONDS);
}
}
输出结果大致如下

可以看到,没次打印出来 current timestamp 的时间间隔大约等于 1000 毫秒,所以可以断定 scheduleAtFixedRate 是以恒定的速率来执行任务的。
然后我们再看一下 scheduleWithFixedDelay 方法,和上面测试类一样,只不过我们把 scheduleAtFixedRate 换为了 scheduleWithFixedDelay 。
然后观察一下输出结果

可以看到,两个 current timestamp 之间的间隔大约等于 1000(固定时间) + delay(time spend) 的总和,由此可以确定 scheduleWithFixedDelay 是以固定时延来执行的。
线程池的描述
下面我们先来认识一下什么是线程池,线程池从概念上来看就是一个池子,什么池子呢?是指管理同一组工作线程的池子,也就是说,线程池会统一管理内部的工作线程。
wiki 上说,线程池其实就是一种软件设计模式,这种设计模式用于实现计算机程序中的并发。

比如下面就是一个简单的线程池概念图。

注意:这个图只是一个概念模型,不是真正的线程池实现,希望读者不要混淆。
可以看到,这种其实也相当于是生产者-消费者模型,任务队列中的线程会进入到线程池中,由线程池进行管理,线程池中的一个个线程就是工作线程,工作线程执行完毕后会放入完成队列中,代表已经完成的任务。
上图有个缺点,那就是队列中的线程执行完毕后就会销毁,销毁就会产生性能损耗,降低响应速度,而我们使用线程池的目的往往是需要把线程重用起来,提高程序性能。
所以我们应该把执行完成后的工作线程重新利用起来,等待下一次使用。
线程池创建
我们上面大概聊了一下什么线程池的基本执行机制,你知道了线程是如何复用的,那么任何事物不可能是凭空出现的,线程也一样,那么它是如何创建出来的呢?下面就不得不提一个工具类,那就是 Executors。
Executors 也是java.util.concurrent 包下的成员,它是一个创建线程池的工厂,可以使用静态工厂方法来创建线程池,下面就是 Executors 所能够创建线程池的具体类型。

newFixedThreadPool:newFixedThreadPool 将会创建固定数量的线程池,这个数量可以由程序员通过创建Executors.newFixedThreadPool(int nThreads)时手动指定,每次提交一个任务就会创建一个线程,在任何时候,nThreads 的值是最多允许活动的线程。如果在所有线程都处于活跃状态时有额外的任务被创建,这些新创建的线程会进入等待队列等待线程调度。如果有任何线程由于执行期间出现意外导致线程终止,那么在执行后续任务时会使用等待队列中的线程进行替代。newWorkStealingPool:newWorkStealingPool 是 JDK1.8 新增加的线程池,它是基于fork-join机制的一种线程池实现,使用了Work-Stealing算法。newWorkStealingPool 会创建足够的线程来支持并行度,会使用多个队列来减少竞争。work-stealing pool 线程池不会保证提交任务的执行顺序。newSingleThreadExecutor:newSingleThreadExecutor 是一个单线程的执行器,它只会创建单个线程来执行任务,如果这个线程异常结束,则会创建另外一个线程来替代。newSingleThreadExecutor 会确保任务在任务队列中的执行次序,也就是说,任务的执行是有序的。newCachedThreadPool:newCachedThreadPool 会根据实际需要创建一个可缓存的线程池。如果线程池的线程数量超过实际需要处理的任务,那么 newCachedThreadPool 将会回收多余的线程。如果实际需要处理的线程不能满足任务的数量,则回你添加新的线程到线程池中,线程池中线程的数量不存在任何限制。newSingleThreadScheduledExecutor:newSingleThreadScheduledExecutor 和 newSingleThreadExecutor 很类似,只不过带有 scheduled 的这个执行器哥们能够在一定延迟后执行或者定期执行任务。newScheduledThreadPool:这个线程池和上面的 scheduled 执行器类似,只不过 newSingleThreadScheduledExecutor 比 newScheduledThreadPool 多加了一个DelegatedScheduledExecutorService代理,这其实包装器设计模式的体现。
上面这些线程池的底层实现都是由 ThreadPoolExecutor 来提供支持的,所以要理解这些线程池的工作原理,你就需要先把 ThreadPoolExecutor 搞明白,下面我们就来聊一聊 ThreadPoolExecutor。
ThreadPoolExecutor 类
ThreadPoolExecutor 位于 java.util.concurrent 工具类下,可以说它是线程池中最核心的一个类了。如果你要想把线程池理解透彻的话,就要首先了解一下这个类。
如果我们再拿上面家族举例子的话,ThreadPoolExecutor 就是一个家族的骨干人才,家族顶梁柱。ThreadPoolExecutor 做的工作真是太多太多了。
首先,ThreadPoolExecutor 提供了四个构造方法,然而前三个构造方法最终都会调用最后一个构造方法进行初始化
public class ThreadPoolExecutor extends AbstractExecutorService { ..... // 1 public ThreadPoolExecutor(int corePoolSize,int maximumPoolSize,long keepAliveTime,TimeUnit unit, BlockingQueue<Runnable> workQueue); // 2 public ThreadPoolExecutor(int corePoolSize,int maximumPoolSize,long keepAliveTime,TimeUnit unit, BlockingQueue<Runnable> workQueue,ThreadFactory threadFactory); // 3 public ThreadPoolExecutor(int corePoolSize,int maximumPoolSize,long keepAliveTime,TimeUnit unit, BlockingQueue<Runnable> workQueue,RejectedExecutionHandler handler); // 4 public ThreadPoolExecutor(int corePoolSize,int maximumPoolSize,long keepAliveTime,TimeUnit unit, BlockingQueue<Runnable> workQueue,ThreadFactory threadFactory,RejectedExecutionHandler handler); ... }所以我们直接就来看一波最后这个线程池,看看参数都有啥,如果我没数错的话,应该是有 7 个参数(小学数学水平。。。。。。)
- 首先,一个非常重要的参数就是
corePoolSize,核心线程池的容量/大小,你叫啥我觉得都没毛病。只不过你得理解这个参数的意义,它和线程池的实现原理有非常密切的关系。你刚开始创建了一个线程池,此时是没有任何线程的,这个很好理解,因为我现在没有任务可以执行啊,创建线程干啥啊?而且创建线程还有开销啊,所以等到任务过来时再创建线程也不晚。但是!我要说但是了,如果调用了 prestartAllCoreThreads 或者 prestartCoreThread 方法,就会在没有任务到来时创建线程,前者是创建 corePoolSize 个线程,后者是只创建一个线程。Lea 爷爷本来想让我们程序员当个懒汉,等任务来了再干;可是你非要当个饿汉,提前完成任务。如果我们想当个懒汉的话,在创建了线程池后,线程池中的线程数为 0,当有任务来之后,就会创建一个线程去执行任务,当线程池中的线程数目达到 corePoolSize 后,就会把到达的任务放到缓存队列当中。

maximumPoolSize:又来一个线程池的容量,只不过这个是线程池的最大容量,也就是线程池所能容纳最大的线程,而上面的 corePoolSize 只是核心线程容量。
我知道你此时会有疑问,那就是不知道如何核心线程的容量和线程最大容量的区别是吧?我们后面会解释这点。
keepAliveTime:这个参数是线程池的保活机制,表示线程在没有任务执行的情况下保持多久会终止。在默认情况下,这个参数只在线程数量大于 corePoolSize 时才会生效。当线程数量大于 corePoolSize 时,如果任意一个空闲的线程的等待时间 > keepAliveTime 后,那么这个线程会被剔除,直到线程数量等于 corePoolSize 为止。如果调用了 allowCoreThreadTimeOut 方法,线程数量在 corePoolSize 范围内也会生效,直到线程减为 0。
TimeUnit.DAYS; //天 TimeUnit.HOURS; //小时 TimeUnit.MINUTES; //分钟 TimeUnit.SECONDS; //秒 TimeUnit.MILLISECONDS; //毫秒 TimeUnit.MICROSECONDS; //微妙 TimeUnit.NANOSECONDS; //纳秒unit:这个参数好说,它就是一个TimeUnit的变量,unit 表示的是 keepAliveTime 的时间单位。unit 的类型有下面这几种workQueue:这个参数表示的概念就是等待队列,我们上面说过,如果核心线程 > corePoolSize 的话,就会把任务放入等待队列,这个等待队列的选择也是一门学问。Lea 爷爷给我们展示了三种等待队列的选择
SynchronousQueue: 基于阻塞队列(BlockingQueue)的实现,它会直接将任务交给消费者,必须等队列中的添加元素被消费后才能继续添加新的元素。使用 SynchronousQueue 阻塞队列一般要求maximumPoolSizes 为无界,也就是 Integer.MAX_VALUE,避免线程拒绝执行操作。LinkedBlockingQueue:LinkedBlockingQueue 是一个无界缓存等待队列。当前执行的线程数量达到 corePoolSize 的数量时,剩余的元素会在阻塞队列里等待。ArrayBlockingQueue:ArrayBlockingQueue 是一个有界缓存等待队列,可以指定缓存队列的大小,当正在执行的线程数等于 corePoolSize 时,多余的元素缓存在 ArrayBlockingQueue 队列中等待有空闲的线程时继续执行,当 ArrayBlockingQueue 已满时,加入 ArrayBlockingQueue 失败,会开启新的线程去执行,当线程数已经达到最大的 maximumPoolSizes 时,再有新的元素尝试加入 ArrayBlockingQueue时会报错
threadFactory:线程工厂,这个参数主要用来创建线程;handler:拒绝策略,拒绝策略主要有以下取值
AbortPolicy:丢弃任务并抛出 RejectedExecutionException 异常。DiscardPolicy: 直接丢弃任务,但是不抛出异常。DiscardOldestPolicy:直接丢弃队列最前面的任务,然后重新尝试执行任务(重复此过程)。CallerRunsPolicy:由调用线程处理该任务。
深入理解线程池
上面我和你简单聊了一下线程池的基本构造,线程池有几个非常重要的参数可以细细品味,但是哥们醒醒,接下来才是刺激的地方。
线程池状态
首先我们先来聊聊线程池状态,线程池状态是一个非常有趣的设计点,ThreadPoolExecutor 使用 ctl 来存储线程池状态,这些状态也叫做线程池的生命周期。想想也是,线程池作为一个存储管理线程的资源池,它自己也要有这些状态,以及状态之间的变更才能更好的满足我们的需求。ctl 其实就是一个 AtomicInteger 类型的变量,保证原子性。
ctl 除了存储线程池状态之外,它还存储 workerCount 这个概念,workerCount 指示的是有效线程数,workerCount 表示的是已经被允许启动但不允许停止的工作线程数量。workerCount 的值与实际活动线程的数量不同。
ctl 高低位来判断是线程池状态还是工作线程数量,线程池状态位于高位。
这里有个设计点,为什么使用 AtomicInteger 而不是存储上线更大的 AtomicLong 之类的呢?
Lea 并非没有考虑过这个问题,为了表示 int 值,目前 workerCount 的大小是(2 ^ 29)-1(约 5 亿个线程),而不是(2 ^ 31)-1(20亿个)可表示的线程。如果将来有问题,可以将该变量更改为 AtomicLong。但是在需要之前,使用 int 可以使此代码更快,更简单,int 存储占用存储空间更小。
runState 具有如下几种状态
private static final int RUNNING = -1 << COUNT_BITS; private static final int SHUTDOWN = 0 << COUNT_BITS; private static final int STOP = 1 << COUNT_BITS; private static final int TIDYING = 2 << COUNT_BITS; private static final int TERMINATED = 3 << COUNT_BITS;我们先上状态轮转图,然后根据状态轮转图做详细的解释。

这几种状态的解释如下
RUNNING: 如果线程池处于 RUNNING 状态下的话,能够接收新任务,也能处理正在运行的任务。可以从 ctl 的初始化得知,线程池一旦创建出来就会处于 RUNNING 状态,并且线程池中的有效线程数为 0。
SHUTDOWN: 在调用 shutdown 方法后,线程池的状态会由 RUNNING -> SHUTDOWN 状态,位于 SHUTDOWN 状态的线程池能够处理正在运行的任务,但是不能接受新的任务,这和我们上面说的对与 shutdown 的描述一致。STOP: 和 shutdown 方法类似,在调用 shutdownNow 方法时,程序会从 RUNNING/SHUTDOWN -> STOP 状态,处于 STOP 状态的线程池,不接收新任务,不处理已添加的任务,并且会中断正在处理的任务。TIDYING:TIDYING 状态有个前置条件,分为两种:一种是是当线程池位于 SHUTDOWN 状态下,阻塞队列和线程池中的线程数量为空时,会由 SHUTDOWN -> TIDYING;另一种是当线程池位于 STOP 状态下时,线程池中的数量为空时,会由 STOP -> TIDYING 状态。转换为 TIDYING 的线程池会调用terminated这个钩子方法,terminated 在 ThreadPoolExecutor 类中是空实现,若用户想在线程池变为 TIDYING 时,进行相应的处理,可以通过重载 terminated 函数来实现。TERMINATED:TERMINATED 状态是线程池的最后一个状态,线程池处在 TIDYING 状态时,执行完terminated 方法之后,就会由 TIDYING -> TERMINATED 状态。此时表示线程池的彻底终止。
重要变量
下面我们一起来了解一下线程池中的重要变量。
private final BlockingQueue<Runnable> workQueue;阻塞队列,这个和我们上面说的阻塞队列的参数是一个意思,因为在构造 ThreadPoolExecutor 时,会把参数的值赋给 this.workQueue。
private final ReentrantLock mainLock = new ReentrantLock();线程池的主要状态锁,对线程池的状态(比如线程池大小、运行状态)的改变都需要使用到这个锁
workers 持有线程池中所有线程的集合,只有持有上面 mainLock 的锁才能够访问。
等待条件,用来支持 awaitTermination 方法。Condition 和 Lock 一起使用可以实现通知/等待机制。
private int largestPoolSize;largestPoolSize 表示线程池中最大池的大小,只有持有 mainLock 才能访问
private long completedTaskCount;completedTaskCount 表示任务完成的计数,它仅仅在任务终止时更新,需要持有 mainLock 才能访问。
private volatile ThreadFactory threadFactory;threadFactory 是创建线程的工厂,所有的线程都会使用这个工厂,调用 addWorker 方法创建。
handler 表示拒绝策略,handler 会在线程饱和或者将要关闭的时候调用。
private volatile long keepAliveTime;保活时间,它指的是空闲线程等待工作的超时时间,当存在多个 corePoolSize 或 allowCoreThreadTimeOut 时,线程将使用这个超时时间。
下面是一些其他变量,这些变量比较简单,我就直接给出注释了。
private volatile boolean allowCoreThreadTimeOut; //是否允许为核心线程设置存活时间 private volatile int corePoolSize; //核心池的大小(即线程池中的线程数目大于这个参数时,提交的任务会被放进任务缓存队列) private volatile int maximumPoolSize; //线程池最大能容忍的线程数 private static final RejectedExecutionHandler defaultHandler = new AbortPolicy(); // 默认的拒绝策略任务提交
现在我们知道了 ThreadPoolExecutor 创建出来就会处于运行状态,此时线程数量为 0 ,等任务到来时,线程池就会创建线程来执行任务,而下面我们的关注点就会放在任务提交这个过程上。
通常情况下,我们会使用
executor.execute()来执行任务,我在很多书和博客教程上都看到过这个执行过程,下面是一些书和博客教程所画的 ThreadPoolExecutor 的执行示意图和执行流程图
执行示意图

处理流程图

ThreadPoolExecutor 的执行 execute 的方法分为下面四种情况
- 如果当前运行的工作线程少于 corePoolSize 的话,那么会创建新线程来执行任务 ,这一步需要获取 mainLock
全局锁。 - 如果运行线程不小于 corePoolSize,则将任务加入 BlockingQueue 阻塞队列。
- 如果无法将任务加入 BlockingQueue 中,此时的现象就是队列已满,此时需要创建新的线程来处理任务,这一步同样需呀获取 mainLock 全局锁。
- 如果创建新线程会使当前运行的线程超过
maximumPoolSize的话,任务将被拒绝,并且使用RejectedExecutionHandler.rejectEExecution()方法拒绝新的任务。
ThreadPoolExecutor 采取上面的整体设计思路,是为了在执行 execute 方法时,避免获取全局锁,因为频繁获取全局锁会是一个严重的可伸缩瓶颈,所以,几乎所有的 execute 方法调用都是通过执行步骤2。
上面指出了 execute 的运行过程,整体上来说这个执行过程把非常重要的点讲解出来了,但是不够细致,我查阅 ThreadPoolExecute 和部分源码分析文章后,发现这事其实没这么简单,先来看一下 execute 的源码,我已经给出了中文注释
public void execute(Runnable command) { if (command == null) throw new NullPointerException(); // 获取 ctl 的值 int c = ctl.get(); // 判断 ctl 的值是否小于核心线程池的数量 if (workerCountOf(c) < corePoolSize) { // 如果小于,增加工作队列,command 就是一个个的任务 if (addWorker(command, true)) // 线程创建成功,直接返回 return; // 线程添加不成功,需要再次判断,每需要一次判断都会获取 ctl 的值 c = ctl.get(); } // 如果线程池处于运行状态并且能够成功的放入阻塞队列 if (isRunning(c) && workQueue.offer(command)) { // 再次进行检查 int recheck = ctl.get(); // 如果不是运行态并且成功的从阻塞队列中删除 if (! isRunning(recheck) && remove(command)) // 执行拒绝策略 reject(command); // worker 线程数量是否为 0 else if (workerCountOf(recheck) == 0) // 增加工作线程 addWorker(null, false); } // 如果不能增加工作线程的数量,就会直接执行拒绝策略 else if (!addWorker(command, false)) reject(command); }下面是我根据源码画出的执行流程图

下面我们针对 execute 流程进行分析,可能有点啰嗦,因为几个核心流程上面已经提过了,不过为了流程的完整性,我们再在这里重新提一下。
- 如果线程池的核心数量少于
corePoolSize,那么就会使用 addWorker 创建新线程,addworker 的流程我们会在下面进行分析。如果创建成功,那么 execute 方法会直接返回。如果没创建成功,可能是由于线程池已经 shutdown,可能是由于并发情况下 workerCountOf(c) < corePoolSize ,别的线程先创建了 worker 线程,导致 workerCoun t>= corePoolSize。 - 如果线程池还在 Running 状态,会将 task 加入阻塞队列,加入成功后会进行
double-check双重校验,继续下面的步骤,如果加入失败,可能是由于队列线程已满,此时会判断是否能够加入线程池中,如果线程池也满了的话,就会直接执行拒绝策略,如果线程池能加入,execute 方法结束。 - 步骤 2 中的 double-check 主要是为了判断进入 workQueue 中的 task 是否能被执行:如果线程池已经不是 Running 状态,则应该拒绝添加任务,从 workQueue 队列中删除任务。如果线程池是 Running,但是从 workQueue 中删除失败了,此时的原因可能是由于其他线程执行了这个任务,此时会直接执行拒绝策略。
- 如果线程是 Running 状态,并且不能把任务从队列中移除,进而判断工作线程是否为 0 ,如果不为 0 ,execute 执行完毕,如果工作线程是 0 ,则会使用 addWorker 增加工作线程,execute 执行完毕。
添加 worker 线程
从上面的执行流程可以看出,添加一个 worker 涉及的工作也非常多,这也是一个比价难啃的点,我们一起来分析下,这是 worker 的源码
private boolean addWorker(Runnable firstTask, boolean core) { // retry 的用法相当于 goto retry: for (;😉 { int c = ctl.get(); int rs = runStateOf(c);// Check if queue empty only if necessary.
// 仅在必要时检查队列是否为空。
// 线程池状态有五种,state 越小越是运行状态
// rs >= SHUTDOWN,表示此时线程池状态可能是 SHUTDOWN、STOP、TIDYING、TERMINATED
// 默认 rs >= SHUTDOWN,如果 rs = SHUTDOWN,直接返回 false
// 默认 rs < SHUTDOWN,是 RUNNING,如果任务不是空,返回 false
// 默认 RUNNING,任务是空,如果工作队列为空,返回 false
//
if (rs >= SHUTDOWN &&
! (rs == SHUTDOWN &&
firstTask == null &&
! workQueue.isEmpty()))
return false;
// 执行循环
for (;;) {
// 统计工作线程数量
int wc = workerCountOf(c);
// 如果 worker 数量>线程池最大上限 CAPACITY(即使用int低29位可以容纳的最大值)
// 或者 worker数量 > corePoolSize 或 worker数量>maximumPoolSize ),即已经超过了给定的边界
if (wc >= CAPACITY ||
wc >= (core ? corePoolSize : maximumPoolSize))
return false;
// 使用 CAS 增加 worker 数量,增加成功,跳出循环。
if (compareAndIncrementWorkerCount(c))
break retry;
// 检查 ctl
c = ctl.get(); // Re-read ctl
// 如果状态不等于之前获取的 state,跳出内层循环,继续去外层循环判断
if (runStateOf(c) != rs)
continue retry;
// else CAS failed due to workerCount change; retry inner loop
}
}
/* worker数量+1成功的后续操作 * 添加到 workers Set 集合,并启动 worker 线程 */ boolean workerStarted = false; boolean workerAdded = false; Worker w = null; try { // 包装 Runnable 对象 // 设置 firstTask 的值为 -1 // 赋值给当前任务 // 使用 worker 自身这个 runnable,调用 ThreadFactory 创建一个线程,并设置给worker的成员变量thread w = new Worker(firstTask); final Thread t = w.thread; if (t != null) { final ReentrantLock mainLock = this.mainLock; mainLock.lock(); try { // 在持有锁的时候重新检查 // 如果 ThreadFactory 失败或在获得锁之前关闭,请回退。 int rs = runStateOf(ctl.get());
//如果线程池在运行 running<shutdown 或者 线程池已经 shutdown,且firstTask==null
// (可能是 workQueue 中仍有未执行完成的任务,创建没有初始任务的 worker 线程执行)
//worker 数量 -1 的操作在 addWorkerFailed()
if (rs < SHUTDOWN ||
(rs == SHUTDOWN && firstTask == null)) {
if (t.isAlive()) // precheck that t is startable
throw new IllegalThreadStateException();
// workers 就是一个 HashSet 集合
workers.add(w);
// 设置最大的池大小 largestPoolSize,workerAdded 设置为true
int s = workers.size();
if (s > largestPoolSize)
largestPoolSize = s;
workerAdded = true;
}
} finally {
mainLock.unlock();
}
if (workerAdded) {
t.start();
workerStarted = true;
}
}
//如果启动线程失败
// worker 数量 -1
} finally { if (! workerStarted) addWorkerFailed(w); } return workerStarted; }
真长的一个方法,有点想吐血,其实我肝到现在已经肝不动了,但我一想到看这篇文章的读者们能给我一个关注,就算咳出一口老血也值了。
这个方法的执行流程图如下

这里我们就不再文字描述了,但是上面流程图中有一个对象引起了我的注意,那就是 worker 对象,这个对象就代表了线程池中的工作线程,那么这个 worker 对象到底是啥呢?
worker 对象
Worker 位于 ThreadPoolExecutor 内部,它继承了 AQS 类并且实现了 Runnable 接口。Worker 类主要维护了线程运行过程中的中断控制状态。它提供了锁的获取和释放操作。在 worker 的实现中,我们使用了非重入的互斥锁而不是使用重复锁,因为 Lea 觉得我们不应该在调用诸如 setCorePoolSize 之类的控制方法时能够重新获取锁。
worker 对象的源码比较简单和标准,这里我们只说一下 worker 对象的构造方法,也就是
Worker(Runnable firstTask) { setState(-1); this.firstTask = firstTask; this.thread = getThreadFactory().newThread(this); }构造一个 worker 对象需要做三步操作:
- 初始 AQS 状态为 -1,此时不允许中断 interrupt(),只有在 worker 线程启动了,执行了 runWorker() 方法后,将 state 置为0,才能进行中断。
- 将 firstTask 赋值给为当前类的全局变量
- 通过
ThreadFactory创建一个新的线程。
任务运行
我们前面的流程主要分析了线程池的 execute 方法的执行过程,这个执行过程相当于是任务提交过程,而我们下面要说的是从队列中获取任务并运行的这个工作流程。
一般情况下,我们会从初始任务开始运行,所以我们不需要获取第一个任务。否则,只要线程池还处于 Running 状态,我们会调用 getTask 方法获取任务。getTask 方法可能会返回 null,此时可能是由于线程池状态改变或者是配置参数更改而导致的退出。还有一种情况可能是由于 异常 而引发的,这个我们后面会细说。
下面来看一下 runWorker 方法的源码:
下面是 runWorker 的执行流程图

这里需要注意一下最后的 processWorkerExit 方法,这里面其实也做了很多事情,包括判断 completedAbruptly 的布尔值来表示是否完成任务,获取锁,尝试从队列中移除 worker,然后尝试中断,接下来会判断一下中断状态,在线程池当前状态小于 STOP 的情况下会创建一个新的 worker 来替换被销毁的 worker。
任务获取
任务获取就是 getTask 方法的执行过程,这个环节主要用来获取任务和剔除任务。下面进入源码分析环节
private Runnable getTask() { // 判断最后一个 poll 是否超时。 boolean timedOut = false; // Did the last poll() time out?for (;😉 { int c = ctl.get(); int rs = runStateOf(c);
// Check if queue empty only if necessary.
// 必要时检查队列是否为空
// 对线程池状态的判断,两种情况会 workerCount-1,并且返回 null
// 线程池状态为 shutdown,且 workQueue 为空(反映了 shutdown 状态的线程池还是要执行 workQueue 中剩余的任务的)
// 线程池状态为 stop(shutdownNow() 会导致变成 STOP)(此时不用考虑 workQueue 的情况)
if (rs >= SHUTDOWN && (rs >= STOP || workQueue.isEmpty())) {
decrementWorkerCount();
return null;
}
int wc = workerCountOf(c);
// Are workers subject to culling?
// 是否需要定时从 workQueue 中获取
boolean timed = allowCoreThreadTimeOut || wc > corePoolSize;
// 如果工作线程的数量大于 maximumPoolSize 会进行线程剔除
// 如果使用了 allowCoreThreadTimeOut ,并且工作线程不为0或者队列有任务的话,会直接进行线程剔除
if ((wc > maximumPoolSize || (timed && timedOut))
&& (wc > 1 || workQueue.isEmpty())) {
if (compareAndDecrementWorkerCount(c))
return null;
continue;
}
try {
Runnable r = timed ?
workQueue.poll(keepAliveTime, TimeUnit.NANOSECONDS) :
workQueue.take();
if (r != null)
return r;
timedOut = true;
} catch (InterruptedException retry) {
timedOut = false;
}
} }
getTask 方法的执行流程图如下

工作线程退出
工作线程退出是 runWorker 的最后一步,这一步会判断工作线程是否突然终止,并且会尝试终止线程,以及是否需要增加线程来替换原工作线程。
private void processWorkerExit(Worker w, boolean completedAbruptly) { // worker数量 -1 // completedAbruptly 是 true,突然终止,说明是 task 执行时异常情况导致,即run()方法执行时发生了异常,那么正在工作的 worker 线程数量需要-1 // completedAbruptly 是 false 是突然终止,说明是 worker 线程没有 task 可执行了,不用-1,因为已经在 getTask() 方法中-1了 if (completedAbruptly) // If abrupt, then workerCount wasn't adjusted decrementWorkerCount();// 从 Workers Set 中移除 worker final ReentrantLock mainLock = this.mainLock; mainLock.lock(); try { completedTaskCount += w.completedTasks; workers.remove(w); } finally { mainLock.unlock(); }
// 尝试终止线程, tryTerminate();
// 是否需要增加 worker 线程 // 线程池状态是 running 或 shutdown // 如果当前线程是突然终止的,addWorker() // 如果当前线程不是突然终止的,但当前线程数量 < 要维护的线程数量,addWorker() // 故如果调用线程池 shutdown(),直到workQueue为空前,线程池都会维持 corePoolSize 个线程, // 然后再逐渐销毁这 corePoolSize 个线程 int c = ctl.get(); if (runStateLessThan(c, STOP)) { if (!completedAbruptly) { int min = allowCoreThreadTimeOut ? 0 : corePoolSize; if (min == 0 && ! workQueue.isEmpty()) min = 1; if (workerCountOf(c) >= min) return; // replacement not needed } addWorker(null, false); } }
源码搞的有点头大了,可能一时半会无法理解上面这些源码,不过你可以先把注释粘过去,等有时间了需要反复刺激,加深印象!
其他线程池
下面我们来了解一下其他线程池的构造原理,主要涉及 FixedThreadPool、SingleThreadExecutor、CachedThreadPool。
newFixedThreadPool
newFixedThreadPool 被称为可重用固定线程数的线程池,下面是 newFixedThreadPool 的源码
可以看到,newFixedThreadPool 的 corePoolSize 和 maximumPoolSize 都被设置为创建 FixedThreadPool 时指定的参数 nThreads,也就是说,在 newFiexedThreadPool 中,核心线程数就是最大线程数。
下面是 newFixedThreadPool 的执行示意图

newFixedThreadPool 的工作流程如下
- 如果当前运行的线程数少于 corePoolSize,则会创建新线程 addworker 来执行任务
- 如果当前线程的线程数等于 corePoolSize,会将任务直接加入到
LinkedBlockingQueue无界阻塞队列中,LinkedBlockingQueue 的上限如果没有制定,默认为 Integer.MAX_VALUE 大小。 - 等到线程池中的任务执行完毕后,newFixedThreadPool 会反复从 LinkedBlockingQueue 中获取任务来执行。
相较于 ThreadPoolExecutor,newFixedThreadPool 主要做了以下改变
核心线程数等于最大线程数,因此 newFixedThreadPool 只有两个最大容量,一个是线程池的线程容量,还有一个是 LinkedBlockingQueue 无界阻塞队列的线程容量。
这里可以看到还有一个变化是 0L,也就是 keepAliveTime = 0L,keepAliveTime 就是到达工作线程最大容量后的线程等待时间,0L 就意味着当线程池中的线程数大于 corePoolsize 时,空余的线程会被立即终止。
由于使用无界队列,运行中的 newFixedThreadPool 不会拒绝任务,也就是不会调用 RejectedExecutionHandler.rejectedExecution 方法。
newSingleThreadExecutor
newSingleThreadExecutor 中只有单个工作线程,也就是说它是一个只有单个 worker 的 Executor。
public static ExecutorService newSingleThreadExecutor(ThreadFactory threadFactory) { return new FinalizableDelegatedExecutorService (new ThreadPoolExecutor(1, 1, 0L, TimeUnit.MILLISECONDS, new LinkedBlockingQueue<Runnable>(), threadFactory)); }可以看到,在 newSingleThreadExecutor 中,corePoolSize 和 maximumPoolSize 都被设置为 1,也不存在超时情况,同样使用了 LinkedBlockingQueue 无界阻塞队列,除了 corePoolSize 和 maximumPoolSize 外,其他几乎和 newFixedThreadPool 一模一样。
下面是 newSingleThreadExecutor 的执行示意图

newSingleThreadExecutor 的执行过程和 newFixedThreadPool 相同,只是 newSingleThreadExecutor 的工作线程数为 1。
newCachedThreadPool
newCachedThreadPool 是一个根据需要创建工作线程的线程池,newCachedThreadPool 线程池最大数量是 Integer.MAX_VALUE,保活时间是 60 秒,使用的是SynchronousQueue 无缓冲阻塞队列。
它的执行示意图如下

- 首先会先执行 SynchronousQueue.offer 方法,如果当前 maximumPool 中有空闲线程正在执行
SynchronousQueue.poll,就会把任务交给空闲线程来执行,execute 方法执行完毕,否则的话,继续向下执行。 - 如果 maximumPool 中没有线程执行 SynchronousQueue.poll 方法,这种情况下 newCachedThreadPool 会创建一个新线程执行任务,execute 方法执行完成。
- 执行完成的线程将执行 poll 操作,这个 poll 操作会让空闲线程最多在 SynchronousQueue 中等待 60 秒钟。如果 60 秒钟内提交了一个新任务,那么空闲线程会执行这个新提交的任务,否则空闲线程将会终止。
这里的关键点在于 SynchronousQueue 队列,它是一个没有容量的阻塞队列。每个插入操作必须等待另一个线程对应的移除操作。这其实就是一种任务传递,如下图所示

其实还有一个线程池 ScheduledThreadPoolExecutor ,就先不在此篇文章做详细赘述了。
线程池实践考量因素
下面介绍几种在实践过程中使用线程池需要考虑的几个点
- 避免任务堆积,比如我们上面提到的 newFixedThreadPool,它是创建指定数目的线程,但是工作队列是无界的,这就导致如果工作队列线程太少,导致处理速度跟不上入队速度,这种情况下很可能会导致 OOM,诊断时可以使用
jmap检查是否有大量任务入队。 - 生产实践中很可能由于逻辑不严谨或者工作线程不能及时释放导致 线程泄漏,这个时候最好检查一下线程栈
- 避免死锁等同步问题
- 尽量避免在使用线程池时操作
ThreadLocal,因为工作线程的生命周期可能会超过任务的生命周期。
线程池大小的设置
线程池大小的设置也是面试官经常会考到的一个点,一般需要根据任务类型来配置线程池大小
- 如果是 CPU 密集型任务,那么就意味着 CPU 是稀缺资源,这个时候我们通常不能通过增加线程数来提高计算能力,因为线程数量太多,会导致频繁的上下文切换,一般这种情况下,建议合理的线程数值是
N(CPU)数 + 1。 - 如果是 I/O 密集型任务,就说明需要较多的等待,这个时候可以参考 Brain Goetz 的推荐方法 线程数 = CPU核数 × (1 + 平均等待时间/平均工作时间)。参考值可以是 N(CPU) 核数 * 2。
当然,这只是一个参考值,具体的设置还需要根据实际情况进行调整,比如可以先将线程池大小设置为参考值,再观察任务运行情况和系统负载、资源利用率来进行适当调整。
后记
这篇文章真的写了很久,因为之前对线程池认识不是很深,所以花了大力气来研究,希望这篇文章对你有所帮助。
# Java锁事-Java面试题
Java 锁分类
Java 中的锁有很多,可以按照不同的功能、种类进行分类,下面是我对 Java 中一些常用锁的分类,包括一些基本的概述

- 从线程是否需要对资源加锁可以分为
悲观锁和乐观锁 - 从资源已被锁定,线程是否阻塞可以分为
自旋锁 - 从多个线程并发访问资源,也就是 Synchronized 可以分为
无锁、偏向锁、轻量级锁和重量级锁 - 从锁的公平性进行区分,可以分为
公平锁和非公平锁 - 从根据锁是否重复获取可以分为
可重入锁和不可重入锁 - 从那个多个线程能否获取同一把锁分为
共享锁和排他锁
下面我们依次对各个锁的分类进行详细阐述。
线程是否需要对资源加锁
Java 按照是否对资源加锁分为乐观锁和悲观锁,乐观锁和悲观锁并不是一种真实存在的锁,而是一种设计思想,乐观锁和悲观锁对于理解 Java 多线程和数据库来说至关重要,下面就来探讨一下这两种实现方式的区别和优缺点
悲观锁
悲观锁是一种悲观思想,它总认为最坏的情况可能会出现,它认为数据很可能会被其他人所修改,所以悲观锁在持有数据的时候总会把资源 或者 数据 锁住,这样其他线程想要请求这个资源的时候就会阻塞,直到等到悲观锁把资源释放为止。传统的关系型数据库里边就用到了很多这种锁机制,比如行锁,表锁等,读锁,写锁等,都是在做操作之前先上锁。悲观锁的实现往往依靠数据库本身的锁功能实现。
Java 中的 Synchronized 和 ReentrantLock 等独占锁(排他锁)也是一种悲观锁思想的实现,因为 Synchronzied 和 ReetrantLock 不管是否持有资源,它都会尝试去加锁,生怕自己心爱的宝贝被别人拿走。
乐观锁
乐观锁的思想与悲观锁的思想相反,它总认为资源和数据不会被别人所修改,所以读取不会上锁,但是乐观锁在进行写入操作的时候会判断当前数据是否被修改过(具体如何判断我们下面再说)。乐观锁的实现方案一般来说有两种: 版本号机制 和 CAS实现 。乐观锁多适用于多度的应用类型,这样可以提高吞吐量。
在Java中java.util.concurrent.atomic包下面的原子变量类就是使用了乐观锁的一种实现方式 CAS 实现的。
两种锁的使用场景
上面介绍了两种锁的基本概念,并提到了两种锁的适用场景,一般来说,悲观锁不仅会对写操作加锁还会对读操作加锁,一个典型的悲观锁调用:
select * from student where name="cxuan" for update这条 sql 语句从 Student 表中选取 name = "cxuan" 的记录并对其加锁,那么其他写操作再这个事务提交之前都不会对这条数据进行操作,起到了独占和排他的作用。
悲观锁因为对读写都加锁,所以它的性能比较低,对于现在互联网提倡的三高(高性能、高可用、高并发)来说,悲观锁的实现用的越来越少了,但是一般多读的情况下还是需要使用悲观锁的,因为虽然加锁的性能比较低,但是也阻止了像乐观锁一样,遇到写不一致的情况下一直重试的时间。
相对而言,乐观锁用于读多写少的情况,即很少发生冲突的场景,这样可以省去锁的开销,增加系统的吞吐量。
乐观锁的适用场景有很多,典型的比如说成本系统,柜员要对一笔金额做修改,为了保证数据的准确性和实效性,使用悲观锁锁住某个数据后,再遇到其他需要修改数据的操作,那么此操作就无法完成金额的修改,对产品来说是灾难性的一刻,使用乐观锁的版本号机制能够解决这个问题,我们下面说。
乐观锁的实现方式
乐观锁一般有两种实现方式:采用版本号机制 和 CAS(Compare-and-Swap,即比较并替换)算法实现。
版本号机制
版本号机制是在数据表中加上一个 version 字段来实现的,表示数据被修改的次数,当执行写操作并且写入成功后,version = version + 1,当线程A要更新数据时,在读取数据的同时也会读取 version 值,在提交更新时,若刚才读取到的 version 值为当前数据库中的version值相等时才更新,否则重试更新操作,直到更新成功。
我们以上面的金融系统为例,来简述一下这个过程。

- 成本系统中有一个数据表,表中有两个字段分别是
金额和version,金额的属性是能够实时变化,而 version 表示的是金额每次发生变化的版本,一般的策略是,当金额发生改变时,version 采用递增的策略每次都在上一个版本号的基础上 + 1。 - 在了解了基本情况和基本信息之后,我们来看一下这个过程:公司收到回款后,需要把这笔钱放在金库中,假如金库中存有100 元钱
- 下面开启事务一:当男柜员执行回款写入操作前,他会先查看(读)一下金库中还有多少钱,此时读到金库中有 100 元,可以执行写操作,并把数据库中的钱更新为 120 元,提交事务,金库中的钱由 100 -> 120,version的版本号由 0 -> 1。
- 开启事务二:女柜员收到给员工发工资的请求后,需要先执行读请求,查看金库中的钱还有多少,此时的版本号是多少,然后从金库中取出员工的工资进行发放,提交事务,成功后版本 + 1,此时版本由 1 -> 2。
上面两种情况是最乐观的情况,上面的两个事务都是顺序执行的,也就是事务一和事务二互不干扰,那么事务要并行执行会如何呢?

事务一开启,男柜员先执行读操作,取出金额和版本号,执行写操作
begin update 表 set 金额 = 120,version = version + 1 where 金额 = 100 and version = 0此时金额改为 120,版本号为1,事务还没有提交
事务二开启,女柜员先执行读操作,取出金额和版本号,执行写操作
begin update 表 set 金额 = 50,version = version + 1 where 金额 = 100 and version = 0此时金额改为 50,版本号变为 1,事务未提交
现在提交事务一,金额改为 120,版本变为1,提交事务。理想情况下应该变为 金额 = 50,版本号 = 2,但是实际上事务二 的更新是建立在金额为 100 和 版本号为 0 的基础上的,所以事务二不会提交成功,应该重新读取金额和版本号,再次进行写操作。
这样,就避免了女柜员 用基于 version = 0 的旧数据修改的结果覆盖男操作员操作结果的可能。
CAS 算法
省略代码,完整代码请参照 看完你就应该能明白的悲观锁和乐观锁
CAS 即 compare and swap(比较与交换),是一种有名的无锁算法。即不使用锁的情况下实现多线程之间的变量同步,也就是在没有线程被阻塞的情况下实现变量的同步,所以也叫非阻塞同步(Non-blocking Synchronization
Java 从 JDK1.5 开始支持,java.util.concurrent 包里提供了很多面向并发编程的类,也提供了 CAS 算法的支持,一些以 Atomic 为开头的一些原子类都使用 CAS 作为其实现方式。使用这些类在多核 CPU 的机器上会有比较好的性能。
如果要把证它们的原子性,必须进行加锁,使用 Synchronzied 或者 ReentrantLock,我们前面介绍它们是悲观锁的实现,我们现在讨论的是乐观锁,那么用哪种方式保证它们的原子性呢?请继续往下看
CAS 中涉及三个要素:
- 需要读写的内存值 V
- 进行比较的值 A
- 拟写入的新值 B
当且仅当预期值A和内存值V相同时,将内存值V修改为B,否则什么都不做。
我们以 java.util.concurrent 中的 AtomicInteger 为例,看一下在不用锁的情况下是如何保证线程安全的
private AtomicInteger integer = new AtomicInteger();
public AtomicInteger getInteger() {
return integer;
}
public void setInteger(AtomicInteger integer) {
this.integer = integer;
}
public void increment(){
integer.incrementAndGet();
}
public void decrement(){
integer.decrementAndGet();
}
}
public class AtomicProducer extends Thread{
private AtomicCounter atomicCounter;
public AtomicProducer(AtomicCounter atomicCounter){
this.atomicCounter = atomicCounter;
}
@Override
public void run() {
for(int j = 0; j < AtomicTest.LOOP; j++) {
System.out.println("producer : " + atomicCounter.getInteger());
atomicCounter.increment();
}
}
}
public class AtomicConsumer extends Thread{
private AtomicCounter atomicCounter;
public AtomicConsumer(AtomicCounter atomicCounter){
this.atomicCounter = atomicCounter;
}
@Override
public void run() {
for(int j = 0; j < AtomicTest.LOOP; j++) {
System.out.println("consumer : " + atomicCounter.getInteger());
atomicCounter.decrement();
}
}
}
public class AtomicTest {
final static int LOOP = 10000;
public static void main(String[] args) throws InterruptedException {
AtomicCounter counter = new AtomicCounter();
AtomicProducer producer = new AtomicProducer(counter);
AtomicConsumer consumer = new AtomicConsumer(counter);
producer.start();
consumer.start();
producer.join();
consumer.join();
System.out.println(counter.getInteger());
}
}
经测试可得,不管循环多少次最后的结果都是0,也就是多线程并行的情况下,使用 AtomicInteger 可以保证线程安全性。 incrementAndGet 和 decrementAndGet 都是原子性操作。
乐观锁的缺点
任何事情都是有利也有弊,软件行业没有完美的解决方案只有最优的解决方案,所以乐观锁也有它的弱点和缺陷:
ABA 问题
ABA 问题说的是,如果一个变量第一次读取的值是 A,准备好需要对 A 进行写操作的时候,发现值还是 A,那么这种情况下,能认为 A 的值没有被改变过吗?可以是由 A -> B -> A 的这种情况,但是 AtomicInteger 却不会这么认为,它只相信它看到的,它看到的是什么就是什么。
JDK 1.5 以后的 AtomicStampedReference 类就提供了此种能力,其中的 compareAndSet 方法就是首先检查当前引用是否等于预期引用,并且当前标志是否等于预期标志,如果全部相等,则以原子方式将该引用和该标志的值设置为给定的更新值。
也可以采用CAS的一个变种DCAS来解决这个问题。
DCAS,是对于每一个V增加一个引用的表示修改次数的标记符。对于每个V,如果引用修改了一次,这个计数器就加1。然后再这个变量需要update的时候,就同时检查变量的值和计数器的值。
循环开销大
我们知道乐观锁在进行写操作的时候会判断是否能够写入成功,如果写入不成功将触发等待 -> 重试机制,这种情况是一个自旋锁,简单来说就是适用于短期内获取不到,进行等待重试的锁,它不适用于长期获取不到锁的情况,另外,自旋循环对于性能开销比较大。
CAS与synchronized的使用情景
简单的来说 CAS 适用于写比较少的情况下(多读场景,冲突一般较少),synchronized 适用于写比较多的情况下(多写场景,冲突一般较多)
- 对于资源竞争较少(线程冲突较轻)的情况,使用 Synchronized 同步锁进行线程阻塞和唤醒切换以及用户态内核态间的切换操作额外浪费消耗 cpu 资源;而 CAS 基于硬件实现,不需要进入内核,不需要切换线程,操作自旋几率较少,因此可以获得更高的性能。
- 对于资源竞争严重(线程冲突严重)的情况,CAS 自旋的概率会比较大,从而浪费更多的 CPU 资源,效率低于 synchronized。
资源已被锁定,线程是否阻塞
自旋锁的提出背景
由于在多处理器环境中某些资源的有限性,有时需要互斥访问(mutual exclusion),这时候就需要引入锁的概念,只有获取了锁的线程才能够对资源进行访问,由于多线程的核心是CPU的时间分片,所以同一时刻只能有一个线程获取到锁。那么就面临一个问题,那么没有获取到锁的线程应该怎么办?
通常有两种处理方式:一种是没有获取到锁的线程就一直循环等待判断该资源是否已经释放锁,这种锁叫做自旋锁,它不用将线程阻塞起来(NON-BLOCKING);还有一种处理方式就是把自己阻塞起来,等待重新调度请求,这种叫做互斥锁。
什么是自旋锁
自旋锁的定义:当一个线程尝试去获取某一把锁的时候,如果这个锁此时已经被别人获取(占用),那么此线程就无法获取到这把锁,该线程将会等待,间隔一段时间后会再次尝试获取。这种采用循环加锁 -> 等待的机制被称为自旋锁(spinlock)。

自旋锁的原理
自旋锁的原理比较简单,如果持有锁的线程能在短时间内释放锁资源,那么那些等待竞争锁的线程就不需要做内核态和用户态之间的切换进入阻塞状态,它们只需要等一等(自旋),等到持有锁的线程释放锁之后即可获取,这样就避免了用户进程和内核切换的消耗。
因为自旋锁避免了操作系统进程调度和线程切换,所以自旋锁通常适用在时间比较短的情况下。由于这个原因,操作系统的内核经常使用自旋锁。但是,如果长时间上锁的话,自旋锁会非常耗费性能,它阻止了其他线程的运行和调度。线程持有锁的时间越长,则持有该锁的线程将被 OS(Operating System) 调度程序中断的风险越大。如果发生中断情况,那么其他线程将保持旋转状态(反复尝试获取锁),而持有该锁的线程并不打算释放锁,这样导致的是结果是无限期推迟,直到持有锁的线程可以完成并释放它为止。
解决上面这种情况一个很好的方式是给自旋锁设定一个自旋时间,等时间一到立即释放自旋锁。自旋锁的目的是占着CPU资源不进行释放,等到获取锁立即进行处理。但是如何去选择自旋时间呢?如果自旋执行时间太长,会有大量的线程处于自旋状态占用 CPU 资源,进而会影响整体系统的性能。因此自旋的周期选的额外重要!JDK在1.6 引入了适应性自旋锁,适应性自旋锁意味着自旋时间不是固定的了,而是由前一次在同一个锁上的自旋时间以及锁拥有的状态来决定,基本认为一个线程上下文切换的时间是最佳的一个时间。
自旋锁的优缺点
自旋锁尽可能的减少线程的阻塞,这对于锁的竞争不激烈,且占用锁时间非常短的代码块来说性能能大幅度的提升,因为自旋的消耗会小于线程阻塞挂起再唤醒的操作的消耗,这些操作会导致线程发生两次上下文切换!
但是如果锁的竞争激烈,或者持有锁的线程需要长时间占用锁执行同步块,这时候就不适合使用自旋锁了,因为自旋锁在获取锁前一直都是占用 cpu 做无用功,占着 XX 不 XX,同时有大量线程在竞争一个锁,会导致获取锁的时间很长,线程自旋的消耗大于线程阻塞挂起操作的消耗,其它需要 cpu 的线程又不能获取到 cpu,造成 cpu 的浪费。所以这种情况下我们要关闭自旋锁。
自旋锁的实现
下面我们用Java 代码来实现一个简单的自旋锁
public class SpinLockTest {private AtomicBoolean available = new AtomicBoolean(false);
public void lock(){
// 循环检测尝试获取锁
while (!tryLock()){
// doSomething...
}
}
public boolean tryLock(){
// 尝试获取锁,成功返回true,失败返回false
return available.compareAndSet(false,true);
}
public void unLock(){
if(!available.compareAndSet(true,false)){
throw new RuntimeException("释放锁失败");
}
}
}
这种简单的自旋锁有一个问题:无法保证多线程竞争的公平性。对于上面的 SpinlockTest,当多个线程想要获取锁时,谁最先将available设为false谁就能最先获得锁,这可能会造成某些线程一直都未获取到锁造成线程饥饿。就像我们下课后蜂拥的跑向食堂,下班后蜂拥地挤向地铁,通常我们会采取排队的方式解决这样的问题,类似地,我们把这种锁叫排队自旋锁(QueuedSpinlock)。计算机科学家们使用了各种方式来实现排队自旋锁,如TicketLock,MCSLock,CLHLock。接下来我们分别对这几种锁做个大致的介绍。
TicketLock
在计算机科学领域中,TicketLock 是一种同步机制或锁定算法,它是一种自旋锁,它使用ticket 来控制线程执行顺序。
就像票据队列管理系统一样。面包店或者服务机构(例如银行)都会使用这种方式来为每个先到达的顾客记录其到达的顺序,而不用每次都进行排队。通常,这种地点都会有一个分配器(叫号器,挂号器等等都行),先到的人需要在这个机器上取出自己现在排队的号码,这个号码是按照自增的顺序进行的,旁边还会有一个标牌显示的是正在服务的标志,这通常是代表目前正在服务的队列号,当前的号码完成服务后,标志牌会显示下一个号码可以去服务了。
像上面系统一样,TicketLock 是基于先进先出(FIFO) 队列的机制。它增加了锁的公平性,其设计原则如下:TicketLock 中有两个 int 类型的数值,开始都是0,第一个值是队列ticket(队列票据), 第二个值是 出队(票据)。队列票据是线程在队列中的位置,而出队票据是现在持有锁的票证的队列位置。可能有点模糊不清,简单来说,就是队列票据是你取票号的位置,出队票据是你距离叫号的位置。现在应该明白一些了吧。
当叫号叫到你的时候,不能有相同的号码同时办业务,必须只有一个人可以去办,办完后,叫号机叫到下一个人,这就叫做原子性。你在办业务的时候不能被其他人所干扰,而且不可能会有两个持有相同号码的人去同时办业务。然后,下一个人看自己的号是否和叫到的号码保持一致,如果一致的话,那么就轮到你去办业务,否则只能继续等待。上面这个流程的关键点在于,每个办业务的人在办完业务之后,他必须丢弃自己的号码,叫号机才能继续叫到下面的人,如果这个人没有丢弃这个号码,那么其他人只能继续等待。下面来实现一下这个票据排队方案
// 队列票据(当前排队号码)
private AtomicInteger queueNum = new AtomicInteger();
// 出队票据(当前需等待号码)
private AtomicInteger dueueNum = new AtomicInteger();
// 获取锁:如果获取成功,返回当前线程的排队号
public int lock(){
int currentTicketNum = dueueNum.incrementAndGet();
while (currentTicketNum != queueNum.get()){
// doSomething...
}
return currentTicketNum;
}
// 释放锁:传入当前排队的号码
public void unLock(int ticketNum){
queueNum.compareAndSet(ticketNum,ticketNum + 1);
}
}
每次叫号机在叫号的时候,都会判断自己是不是被叫的号,并且每个人在办完业务的时候,叫号机根据在当前号码的基础上 + 1,让队列继续往前走。
但是上面这个设计是有问题的,因为获得自己的号码之后,是可以对号码进行更改的,这就造成系统紊乱,锁不能及时释放。这时候就需要有一个能确保每个人按会着自己号码排队办业务的角色,在得知这一点之后,我们重新设计一下这个逻辑
public class TicketLock2 {// 队列票据(当前排队号码)
private AtomicInteger queueNum = new AtomicInteger();
// 出队票据(当前需等待号码)
private AtomicInteger dueueNum = new AtomicInteger();
private ThreadLocal<Integer> ticketLocal = new ThreadLocal<>();
public void lock(){
int currentTicketNum = dueueNum.incrementAndGet();
// 获取锁的时候,将当前线程的排队号保存起来
ticketLocal.set(currentTicketNum);
while (currentTicketNum != queueNum.get()){
// doSomething...
}
}
// 释放锁:从排队缓冲池中取
public void unLock(){
Integer currentTicket = ticketLocal.get();
queueNum.compareAndSet(currentTicket,currentTicket + 1);
}
}
这次就不再需要返回值,办业务的时候,要将当前的这一个号码缓存起来,在办完业务后,需要释放缓存的这条票据。
缺点
TicketLock 虽然解决了公平性的问题,但是多处理器系统上,每个进程/线程占用的处理器都在读写同一个变量queueNum ,每次读写操作都必须在多个处理器缓存之间进行缓存同步,这会导致繁重的系统总线和内存的流量,大大降低系统整体的性能。
为了解决这个问题,MCSLock 和 CLHLock 应运而生。
CLHLock
上面说到TicketLock 是基于队列的,那么 CLHLock 就是基于链表设计的,CLH的发明人是:Craig,Landin and Hagersten,用它们各自的字母开头命名。CLH 是一种基于链表的可扩展,高性能,公平的自旋锁,申请线程只能在本地变量上自旋,它会不断轮询前驱的状态,如果发现前驱释放了锁就结束自旋。
public class CLHLock {public static class CLHNode{
private volatile boolean isLocked = true;
}
// 尾部节点
private volatile CLHNode tail;
private static final ThreadLocal<CLHNode> LOCAL = new ThreadLocal<>();
private static final AtomicReferenceFieldUpdater<CLHLock,CLHNode> UPDATER =
AtomicReferenceFieldUpdater.newUpdater(CLHLock.class,CLHNode.class,"tail");
public void lock(){
// 新建节点并将节点与当前线程保存起来
CLHNode node = new CLHNode();
LOCAL.set(node);
// 将新建的节点设置为尾部节点,并返回旧的节点(原子操作),这里旧的节点实际上就是当前节点的前驱节点
CLHNode preNode = UPDATER.getAndSet(this,node);
if(preNode != null){
// 前驱节点不为null表示当锁被其他线程占用,通过不断轮询判断前驱节点的锁标志位等待前驱节点释放锁
while (preNode.isLocked){
}
preNode = null;
LOCAL.set(node);
}
// 如果不存在前驱节点,表示该锁没有被其他线程占用,则当前线程获得锁
}
public void unlock() {
// 获取当前线程对应的节点
CLHNode node = LOCAL.get();
// 如果tail节点等于node,则将tail节点更新为null,同时将node的lock状态职位false,表示当前线程释放了锁
if (!UPDATER.compareAndSet(this, node, null)) {
node.isLocked = false;
}
node = null;
}
}
MCSLock
MCS Spinlock 是一种基于链表的可扩展、高性能、公平的自旋锁,申请线程只在本地变量上自旋,直接前驱负责通知其结束自旋,从而极大地减少了不必要的处理器缓存同步的次数,降低了总线和内存的开销。MCS 来自于其发明人名字的首字母: John Mellor-Crummey 和 Michael Scott。
public class MCSLock {public static class MCSNode {
volatile MCSNode next;
volatile boolean isLocked = true;
}
private static final ThreadLocal<MCSNode> NODE = new ThreadLocal<>();
// 队列
@SuppressWarnings("unused")
private volatile MCSNode queue;
private static final AtomicReferenceFieldUpdater<MCSLock,MCSNode> UPDATE =
AtomicReferenceFieldUpdater.newUpdater(MCSLock.class,MCSNode.class,"queue");
public void lock(){
// 创建节点并保存到ThreadLocal中
MCSNode currentNode = new MCSNode();
NODE.set(currentNode);
// 将queue设置为当前节点,并且返回之前的节点
MCSNode preNode = UPDATE.getAndSet(this, currentNode);
if (preNode != null) {
// 如果之前节点不为null,表示锁已经被其他线程持有
preNode.next = currentNode;
// 循环判断,直到当前节点的锁标志位为false
while (currentNode.isLocked) {
}
}
}
public void unlock() {
MCSNode currentNode = NODE.get();
// next为null表示没有正在等待获取锁的线程
if (currentNode.next == null) {
// 更新状态并设置queue为null
if (UPDATE.compareAndSet(this, currentNode, null)) {
// 如果成功了,表示queue==currentNode,即当前节点后面没有节点了
return;
} else {
// 如果不成功,表示queue!=currentNode,即当前节点后面多了一个节点,表示有线程在等待
// 如果当前节点的后续节点为null,则需要等待其不为null(参考加锁方法)
while (currentNode.next == null) {
}
}
} else {
// 如果不为null,表示有线程在等待获取锁,此时将等待线程对应的节点锁状态更新为false,同时将当前线程的后继节点设为null
currentNode.next.isLocked = false;
currentNode.next = null;
}
}
}
CLHLock 和 MCSLock
- 都是基于链表,不同的是CLHLock是基于隐式链表,没有真正的后续节点属性,MCSLock是显示链表,有一个指向后续节点的属性。
- 将获取锁的线程状态借助节点(node)保存,每个线程都有一份独立的节点,这样就解决了TicketLock多处理器缓存同步的问题。
多个线程并发访问资源
锁状态的分类
Java 语言专门针对 synchronized 关键字设置了四种状态,它们分别是:无锁、偏向锁、轻量级锁和重量级锁,但是在了解这些锁之前还需要先了解一下 Java 对象头和 Monitor。
Java 对象头
我们知道 synchronized 是悲观锁,在操作同步之前需要给资源加锁,这把锁就是对象头里面的,而Java 对象头又是什么呢?我们以 Hotspot 虚拟机为例,Hopspot 对象头主要包括两部分数据:Mark Word(标记字段) 和 class Pointer(类型指针)。
Mark Word:默认存储对象的HashCode,分代年龄和锁标志位信息。这些信息都是与对象自身定义无关的数据,所以Mark Word被设计成一个非固定的数据结构以便在极小的空间内存存储尽量多的数据。它会根据对象的状态复用自己的存储空间,也就是说在运行期间Mark Word里存储的数据会随着锁标志位的变化而变化。
class Point:对象指向它的类元数据的指针,虚拟机通过这个指针来确定这个对象是哪个类的实例。
在32位虚拟机和64位虚拟机的 Mark Word 所占用的字节大小不一样,32位虚拟机的 Mark Word 和 class Pointer 分别占用 32bits 的字节,而 64位虚拟机的 Mark Word 和 class Pointer 占用了64bits 的字节,下面我们以 32位虚拟机为例,来看一下其 Mark Word 的字节具体是如何分配的


用中文翻译过来就是

- 无状态也就是
无锁的时候,对象头开辟 25bit 的空间用来存储对象的 hashcode ,4bit 用于存放分代年龄,1bit 用来存放是否偏向锁的标识位,2bit 用来存放锁标识位为01 偏向锁中划分更细,还是开辟25bit 的空间,其中23bit 用来存放线程ID,2bit 用来存放 epoch,4bit 存放分代年龄,1bit 存放是否偏向锁标识, 0表示无锁,1表示偏向锁,锁的标识位还是01轻量级锁中直接开辟 30bit 的空间存放指向栈中锁记录的指针,2bit 存放锁的标志位,其标志位为00重量级锁中和轻量级锁一样,30bit 的空间用来存放指向重量级锁的指针,2bit 存放锁的标识位,为11GC标记开辟30bit 的内存空间却没有占用,2bit 空间存放锁标志位为11。
其中无锁和偏向锁的锁标志位都是01,只是在前面的1bit区分了这是无锁状态还是偏向锁状态。
关于为什么这么分配的内存,我们可以从 OpenJDK 中的markOop.hpp类中的枚举窥出端倪

来解释一下
- age_bits 就是我们说的分代回收的标识,占用4字节
- lock_bits 是锁的标志位,占用2个字节
- biased_lock_bits 是是否偏向锁的标识,占用1个字节
- max_hash_bits 是针对无锁计算的hashcode 占用字节数量,如果是32位虚拟机,就是 32 – 4 – 2 -1 = 25 byte,如果是64 位虚拟机,64 – 4 – 2 – 1 = 57 byte,但是会有 25 字节未使用,所以64位的 hashcode 占用 31 byte
- hash_bits 是针对 64 位虚拟机来说,如果最大字节数大于 31,则取31,否则取真实的字节数
- cms_bits 我觉得应该是不是64位虚拟机就占用 0 byte,是64位就占用 1byte
- epoch_bits 就是 epoch 所占用的字节大小,2字节。
Synchronized锁
synchronized用的锁记录是存在Java对象头里的。
JVM基于进入和退出 Monitor 对象来实现方法同步和代码块同步。代码块同步是使用 monitorenter 和 monitorexit 指令实现的,monitorenter 指令是在编译后插入到同步代码块的开始位置,而 monitorexit 是插入到方法结束处和异常处。任何对象都有一个 monitor 与之关联,当且一个 monitor 被持有后,它将处于锁定状态。
根据虚拟机规范的要求,在执行 monitorenter 指令时,首先要去尝试获取对象的锁,如果这个对象没被锁定,或者当前线程已经拥有了那个对象的锁,把锁的计数器加1,相应地,在执行 monitorexit 指令时会将锁计数器减1,当计数器被减到0时,锁就释放了。如果获取对象锁失败了,那当前线程就要阻塞等待,直到对象锁被另一个线程释放为止。
Monitor
Synchronized是通过对象内部的一个叫做监视器锁(monitor)来实现的,监视器锁本质又是依赖于底层的操作系统的 Mutex Lock(互斥锁)来实现的。而操作系统实现线程之间的切换需要从用户态转换到核心态,这个成本非常高,状态之间的转换需要相对比较长的时间,这就是为什么 Synchronized 效率低的原因。因此,这种依赖于操作系统 Mutex Lock 所实现的锁我们称之为重量级锁。
Java SE 1.6为了减少获得锁和释放锁带来的性能消耗,引入了偏向锁和轻量级锁:锁一共有4种状态,级别从低到高依次是:无锁状态、偏向锁状态、轻量级锁状态和重量级锁状态。锁可以升级但不能降级。
所以锁的状态总共有四种:无锁状态、偏向锁、轻量级锁和重量级锁。随着锁的竞争,锁可以从偏向锁升级到轻量级锁,再升级的重量级锁(但是锁的升级是单向的,也就是说只能从低到高升级,不会出现锁的降级)。JDK 1.6中默认是开启偏向锁和轻量级锁的,我们也可以通过-XX:-UseBiasedLocking=false来禁用偏向锁。
锁的分类及其解释
先来个大体的流程图来感受一下这个过程,然后下面我们再分开来说

无锁
无锁状态,无锁即没有对资源进行锁定,所有的线程都可以对同一个资源进行访问,但是只有一个线程能够成功修改资源。

无锁的特点就是在循环内进行修改操作,线程会不断的尝试修改共享资源,直到能够成功修改资源并退出,在此过程中没有出现冲突的发生,这很像我们在之前文章中介绍的 CAS 实现,CAS 的原理和应用就是无锁的实现。无锁无法全面代替有锁,但无锁在某些场合下的性能是非常高的。
偏向锁
HotSpot 的作者经过研究发现,大多数情况下,锁不仅不存在多线程竞争,还存在锁由同一线程多次获得的情况,偏向锁就是在这种情况下出现的,它的出现是为了解决只有在一个线程执行同步时提高性能。

可以从对象头的分配中看到,偏向锁要比无锁多了线程ID 和 epoch,下面我们就来描述一下偏向锁的获取过程
偏向锁获取过程
- 首先线程访问同步代码块,会通过检查对象头 Mark Word 的
锁标志位判断目前锁的状态,如果是 01,说明就是无锁或者偏向锁,然后再根据是否偏向锁的标示判断是无锁还是偏向锁,如果是无锁情况下,执行下一步 - 线程使用 CAS 操作来尝试对对象加锁,如果使用 CAS 替换 ThreadID 成功,就说明是第一次上锁,那么当前线程就会获得对象的偏向锁,此时会在对象头的 Mark Word 中记录当前线程 ID 和获取锁的时间 epoch 等信息,然后执行同步代码块。
全局安全点(Safe Point):全局安全点的理解会涉及到 C 语言底层的一些知识,这里简单理解 SafePoint 是 Java 代码中的一个线程可能暂停执行的位置。
等到下一次线程在进入和退出同步代码块时就不需要进行 CAS 操作进行加锁和解锁,只需要简单判断一下对象头的 Mark Word 中是否存储着指向当前线程的线程ID,判断的标志当然是根据锁的标志位来判断的。如果用流程图来表示的话就是下面这样

关闭偏向锁
偏向锁在Java 6 和Java 7 里是默认启用的。由于偏向锁是为了在只有一个线程执行同步块时提高性能,如果你确定应用程序里所有的锁通常情况下处于竞争状态,可以通过JVM参数关闭偏向锁:-XX:-UseBiasedLocking=false,那么程序默认会进入轻量级锁状态。
关于 epoch
偏向锁的对象头中有一个被称为 epoch 的值,它作为偏差有效性的时间戳。
轻量级锁
轻量级锁是指当前锁是偏向锁的时候,资源被另外的线程所访问,那么偏向锁就会升级为轻量级锁,其他线程会通过自旋的形式尝试获取锁,不会阻塞,从而提高性能,下面是详细的获取过程。
轻量级锁加锁过程
- 紧接着上一步,如果 CAS 操作替换 ThreadID 没有获取成功,执行下一步
- 如果使用 CAS 操作替换 ThreadID 失败(这时候就切换到另外一个线程的角度)说明该资源已被同步访问过,这时候就会执行锁的撤销操作,撤销偏向锁,然后等原持有偏向锁的线程到达
全局安全点(SafePoint)时,会暂停原持有偏向锁的线程,然后会检查原持有偏向锁的状态,如果已经退出同步,就会唤醒持有偏向锁的线程,执行下一步 - 检查对象头中的 Mark Word 记录的是否是当前线程 ID,如果是,执行同步代码,如果不是,执行偏向锁获取流程 的第2步。
如果用流程表示的话就是下面这样(已经包含偏向锁的获取)

重量级锁
重量级锁的获取流程比较复杂,小伙伴们做好准备,其实多看几遍也没那么麻烦,呵呵。
重量级锁的获取流程
接着上面偏向锁的获取过程,由偏向锁升级为轻量级锁,执行下一步
会在原持有偏向锁的线程的栈中分配锁记录,将对象头中的 Mark Word 拷贝到原持有偏向锁线程的记录中,然后原持有偏向锁的线程获得轻量级锁,然后唤醒原持有偏向锁的线程,从安全点处继续执行,执行完毕后,执行下一步,当前线程执行第4步
执行完毕后,开始轻量级解锁操作,解锁需要判断两个条件
- 判断对象头中的 Mark Word 中锁记录指针是否指向当前栈中记录的指针

拷贝在当前线程锁记录的 Mark Word 信息是否与对象头中的 Mark Word 一致。
如果上面两个判断条件都符合的话,就进行锁释放,如果其中一个条件不符合,就会释放锁,并唤起等待的线程,进行新一轮的锁竞争。
在当前线程的栈中分配锁记录,拷贝对象头中的 MarkWord 到当前线程的锁记录中,执行 CAS 加锁操作,会把对象头 Mark Word 中锁记录指针指向当前线程锁记录,如果成功,获取轻量级锁,执行同步代码,然后执行第3步,如果不成功,执行下一步
当前线程没有使用 CAS 成功获取锁,就会自旋一会儿,再次尝试获取,如果在多次自旋到达上限后还没有获取到锁,那么轻量级锁就会升级为
重量级锁

如果用流程图表示是这样的

锁的公平性与非公平性
我们知道,在并发环境中,多个线程需要对同一资源进行访问,同一时刻只能有一个线程能够获取到锁并进行资源访问,那么剩下的这些线程怎么办呢?这就好比食堂排队打饭的模型,最先到达食堂的人拥有最先买饭的权利,那么剩下的人就需要在第一个人后面排队,这是理想的情况,即每个人都能够买上饭。那么现实情况是,在你排队的过程中,就有个别不老实的人想走捷径,插队打饭,如果插队的这个人后面没有人制止他这种行为,他就能够顺利买上饭,如果有人制止,他就也得去队伍后面排队。
对于正常排队的人来说,没有人插队,每个人都在等待排队打饭的机会,那么这种方式对每个人来说都是公平的,先来后到嘛。这种锁也叫做公平锁。

那么假如插队的这个人成功买上饭并且在买饭的过程不管有没有人制止他,他的这种行为对正常排队的人来说都是不公平的,这在锁的世界中也叫做非公平锁。


那么我们根据上面的描述可以得出下面的结论
公平锁表示线程获取锁的顺序是按照线程加锁的顺序来分配的,即先来先得的FIFO先进先出顺序。而非公平锁就是一种获取锁的抢占机制,是随机获得锁的,和公平锁不一样的就是先来的不一定先得到锁,这个方式可能造成某些线程一直拿不到锁,结果也就是不公平的了。
锁公平性的实现
在 Java 中,我们一般通过 ReetrantLock 来实现锁的公平性
我们分别通过两个例子来讲解一下锁的公平性和非公平性
锁的公平性
public class MyFairLock extends Thread{private ReentrantLock lock = new ReentrantLock(true);
public void fairLock(){
try {
lock.lock();
System.out.println(Thread.currentThread().getName() + "正在持有锁");
}finally {
System.out.println(Thread.currentThread().getName() + "释放了锁");
lock.unlock();
}
}
public static void main(String[] args) {
MyFairLock myFairLock = new MyFairLock();
Runnable runnable = () -> {
System.out.println(Thread.currentThread().getName() + "启动");
myFairLock.fairLock();
};
Thread[] thread = new Thread[10];
for(int i = 0;i < 10;i++){
thread[i] = new Thread(runnable);
}
for(int i = 0;i < 10;i++){
thread[i].start();
}
}
}
我们创建了一个 ReetrantLock,并给构造函数传了一个 true,我们可以查看 ReetrantLock 的构造函数
public ReentrantLock(boolean fair) { sync = fair ? new FairSync() : new NonfairSync(); }根据 JavaDoc 的注释可知,如果是 true 的话,那么就会创建一个 ReentrantLock 的公平锁,然后并创建一个 FairSync ,FairSync 其实是一个 Sync 的内部类,它的主要作用是同步对象以获取公平锁。

而 Sync 是 ReentrantLock 中的内部类,Sync 继承 AbstractQueuedSynchronizer 类,AbstractQueuedSynchronizer 就是我们常说的 AQS ,它是 JUC(java.util.concurrent) 中最重要的一个类,通过它来实现独占锁和共享锁。
也就是说,我们把 fair 参数设置为 true 之后,就可以实现一个公平锁了,是这样吗?我们回到示例代码,我们可以执行一下这段代码,它的输出是顺序获取的(碍于篇幅的原因,这里就暂不贴出了),也就是说我们创建了一个公平锁
锁的非公平性
与公平性相对的就是非公平性,我们通过设置 fair 参数为 true,便实现了一个公平锁,与之相对的,我们把 fair 参数设置为 false,是不是就是非公平锁了?用事实证明一下
其他代码不变,我们执行一下看看输出(部分输出)
Thread-1启动 Thread-4启动 Thread-1正在持有锁 Thread-1释放了锁 Thread-5启动 Thread-6启动 Thread-3启动 Thread-7启动 Thread-2启动可以看到,线程的启动并没有按顺序获取,可以看出非公平锁对锁的获取是乱序的,即有一个抢占锁的过程。也就是说,我们把 fair 参数设置为 false 便实现了一个非公平锁。
ReentrantLock 基本概述
ReentrantLock 是一把可重入锁,也是一把互斥锁,它具有与 synchronized 相同的方法和监视器锁的语义,但是它比 synchronized 有更多可扩展的功能。
ReentrantLock 的可重入性是指它可以由上次成功锁定但还未解锁的线程拥有。当只有一个线程尝试加锁时,该线程调用 lock() 方法会立刻返回成功并直接获取锁。如果当前线程已经拥有这把锁,这个方法会立刻返回。可以使用 isHeldByCurrentThread 和 getHoldCount 进行检查。
这个类的构造函数接受可选择的 fairness 参数,当 fairness 设置为 true 时,在多线程争夺尝试加锁时,锁倾向于对等待时间最长的线程访问,这也是公平性的一种体现。否则,锁不能保证每个线程的访问顺序,也就是非公平锁。与使用默认设置的程序相比,使用许多线程访问的公平锁的程序可能会显示较低的总体吞吐量(即较慢;通常要慢得多)。但是获取锁并保证线程不会饥饿的次数比较小。无论如何请注意:锁的公平性不能保证线程调度的公平性。因此,使用公平锁的多线程之一可能会连续多次获得它,而其他活动线程没有进行且当前未持有该锁。这也是互斥性 的一种体现。
也要注意的 tryLock() 方法不支持公平性。如果锁是可以获取的,那么即使其他线程等待,它仍然能够返回成功。
推荐使用下面的代码来进行加锁和解锁
class MyFairLock { private final ReentrantLock lock = new ReentrantLock();public void m() {
lock.lock();
try {
// ...
} finally {
lock.unlock()
}
}
}
ReentrantLock 锁通过同一线程最多支持2147483647个递归锁。 尝试超过此限制会导致锁定方法引发错误。
ReentrantLock 如何实现锁公平性
我们在上面的简述中提到,ReentrantLock 是可以实现锁的公平性的,那么原理是什么呢?下面我们通过其源码来了解一下 ReentrantLock 是如何实现锁的公平性的
跟踪其源码发现,调用 Lock.lock() 方法其实是调用了 sync 的内部的方法
而 sync 是最基础的同步控制 Lock 的类,它有公平锁和非公平锁的实现。它继承 AbstractQueuedSynchronizer 即 使用 AQS 状态代表锁持有的数量。
lock 是抽象方法是需要被子类实现的,而继承了 AQS 的类主要有

我们可以看到,所有实现了 AQS 的类都位于 JUC 包下,主要有五类:ReentrantLock、ReentrantReadWriteLock、Semaphore、CountDownLatch 和 ThreadPoolExecutor,其中 ReentrantLock、ReentrantReadWriteLock、Semaphore 都可以实现公平锁和非公平锁。
下面是公平锁 FairSync 的继承关系

非公平锁的NonFairSync 的继承关系

由继承图可以看到,两个类的继承关系都是相同的,我们从源码发现,公平锁和非公平锁的实现就是下面这段代码的区别(下一篇文章我们会从原理角度分析一下公平锁和非公平锁的实现)

通过上图中的源代码对比,我们可以明显的看出公平锁与非公平锁的lock()方法唯一的区别就在于公平锁在获取同步状态时多了一个限制条件:hasQueuedPredecessors()。
hasQueuedPredecessors() 也是 AQS 中的方法,它主要是用来 查询是否有任何线程在等待获取锁的时间比当前线程长,也就是说每个等待线程都是在一个队列中,此方法就是判断队列中在当前线程获取锁时,是否有等待锁时间比自己还长的队列,如果当前线程之前有排队的线程,返回 true,如果当前线程位于队列的开头或队列为空,返回 false。
综上,公平锁就是通过同步队列来实现多个线程按照申请锁的顺序来获取锁,从而实现公平的特性。非公平锁加锁时不考虑排队等待问题,直接尝试获取锁,所以存在后申请却先获得锁的情况。
根据锁是否可重入进行区分
可重入锁
可重入锁又称为递归锁,是指在同一个线程在外层方法获取锁的时候,再进入该线程的内层方法会自动获取锁(前提锁对象得是同一个对象或者class),不会因为之前已经获取过还没释放而阻塞。Java 中 ReentrantLock 和synchronized 都是可重入锁,可重入锁的一个优点是在一定程度上可以避免死锁。
我们先来看一段代码来说明一下 synchronized 的可重入性
private synchronized void doSomething(){ System.out.println("doSomething..."); doSomethingElse(); }private synchronized void doSomethingElse(){ System.out.println("doSomethingElse..."); }
在上面这段代码中,我们对 doSomething() 和 doSomethingElse() 分别使用了 synchronized 进行锁定,doSomething() 方法中调用了 doSomethingElse() 方法,因为 synchronized 是可重入锁,所以同一个线程在调用 doSomething() 方法时,也能够进入 doSomethingElse() 方法中。
不可重入锁
如果 synchronized 是不可重入锁的话,那么在调用 doSomethingElse() 方法的时候,必须把 doSomething() 的锁丢掉,实际上该对象锁已被当前线程所持有,且无法释放。所以此时会出现死锁。
也就是说,不可重入锁会造成死锁
多个线程能够共享同一把锁
独占锁和共享锁
独占多和共享锁一般对应 JDK 源码的 ReentrantLock 和 ReentrantReadWriteLock 源码来介绍独占锁和共享锁。
独占锁又叫做排他锁,是指锁在同一时刻只能被一个线程拥有,其他线程想要访问资源,就会被阻塞。JDK 中 synchronized和 JUC 中 Lock 的实现类就是互斥锁。
共享锁指的是锁能够被多个线程所拥有,如果某个线程对资源加上共享锁后,则其他线程只能对资源再加共享锁,不能加排它锁。获得共享锁的线程只能读数据,不能修改数据。

我们看到 ReentrantReadWriteLock 有两把锁:ReadLock 和 WriteLock,也就是一个读锁一个写锁,合在一起叫做读写锁。再进一步观察可以发现 ReadLock 和 WriteLock 是靠内部类 Sync 实现的锁。Sync 是继承于 AQS 子类的,AQS 是并发的根本,这种结构在CountDownLatch、ReentrantLock、Semaphore里面也都存在。
在 ReentrantReadWriteLock 里面,读锁和写锁的锁主体都是 Sync,但读锁和写锁的加锁方式不一样。读锁是共享锁,写锁是独享锁。读锁的共享锁可保证并发读非常高效,而读写、写读、写写的过程互斥,因为读锁和写锁是分离的。所以ReentrantReadWriteLock的并发性相比一般的互斥锁有了很大提升。
# 简单认识并发-Java面试题
到目前为止,你学到的都是顺序编程,顺序编程的概念就是某一时刻只有一个任务在执行,顺序编程固然能够解决很多问题,但是对于某种任务,如果能够并发的执行程序中重要的部分就显得尤为重要,同时也可以极大提高程序运行效率,享受并发为你带来的便利。但是,熟练掌握并发编程理论和技术,对于只会CRUD的你来说是一种和你刚学面向对象一样的一种飞跃。
正如你所看到的,当并行的任务彼此干涉时,实际的并发问题就会接踵而至。而且并发问题不是很难复现,在你实际的测试过程中往往会忽略它们,因为故障是偶尔发生的,这也是我们研究它们的必要条件:如果你对并发问题置之不理,那么你最终会承受它给你带来的损害。
并发的多面性
更快的执行
速度问题听起来很简单,如果你想让一个程序运行的更快一些,那么可以将其切成多个分片,在单独的处理器上运行各自的分片:前提是这些任务彼此之间没有联系。
注意:速度的提高是以多核处理器而不是芯片的形式出现的。
如果你有一台多处理器的机器,那么你就可以在这些处理器之间分布多个任务,从而极大的提高吞吐量。但是,并发通常是提高在单处理器上的程序的性能。在单处理上的性能开销要比多处理器上的性能开销大很多,因为这其中增加了线程切换(从一个线程切换到另外一个线程)的重要依据。表面上看,将程序的所有部分当作单个的任务运行好像是开销更小一点,节省了线程切换的时间。
改进代码的设计
在单CPU机器上使用多任务的程序在任意时刻仍旧只在执行一项工作,你肉眼观察到控制台的输出好像是这些线程在同时工作,这不过是CPU的障眼法罢了,CPU为每个任务都提供了不固定的时间切片。Java 的线程机制是抢占式的,也就是说,你必须编写某种让步语句才会让线程进行切换,切换给其他线程。
基本的线程机制
并发编程使我们可以将程序划分成多个分离的,独立运行的任务。通过使用多线程机制,这些独立任务中的每一项任务都由执行线程来驱动。一个线程就是进程中的一个单一的顺序控制流。因此,单个进程可以拥有多个并发执行的任务,但是你的程序看起来每个任务都有自己的CPU一样。其底层是切分CPU时间,通常你不需要考虑它。
定义任务
线程可以驱动任务,因此你需要一种描述任务的方式,这可以由 Runnable 接口来提供,要想定义任务,只需要实现 Runnable 接口,并在run 方法中实现你的逻辑即可。
public static int i = 0;
@Override
public void run() {
System.out.println("start thread..." + i);
i++;
System.out.println("end thread ..." + i);
}
public static void main(String[] args) {
for(int i = 0;i < 5;i++){
TestThread testThread = new TestThread();
testThread.run();
}
}
}
任务 run 方法会有某种形式的循环,使得任务一直运行下去直到不再需要,所以要设定 run 方法的跳出条件(有一种选择是从 run 中直接返回,下面会说到。)
在 run 中使用静态方法 Thread.yield() 可以使用线程调度,它的意思是建议线程机制进行切换:你已经执行完重要的部分了,剩下的交给其他线程跑一跑吧。注意是建议执行,而不是强制执行。在下面添加 Thread.yield() 你会看到有意思的输出
Thread 类
将 Runnable 转变工作方式的传统方式是使用 Thread 类托管他,下面展示了使用 Thread 类来实现一个线程。
public static void main(String[] args) { for(int i = 0;i < 5;i++){ Thread t = new Thread(new TestThread()); t.start(); } System.out.println("Waiting thread ..."); }Thread 构造器只需要一个 Runnable 对象,调用 Thread 对象的 start() 方法为该线程执行必须的初始化操作,然后调用 Runnable 的 run 方法,以便在这个线程中启动任务。可以看到,在 run 方法还没有结束前,run 就被返回了。也就是说,程序不会等到 run 方法执行完毕就会执行下面的指令。
在 run 方法中打印出每个线程的名字,就更能看到不同的线程的切换和调度
@Override public void run() { System.out.println(Thread.currentThread() + "start thread..." + i); i++; System.out.println(Thread.currentThread() + "end thread ..." + i); }这种线程切换和调度是交由 线程调度器 来自动控制的,如果你的机器上有多个处理器,线程调度器会在这些处理器之间默默的分发线程。每一次的运行结果都不尽相同,因为线程调度机制是未确定的。
使用 Executor
CachedThreadPool
JDK1.5 的java.util.concurrent 包中的执行器 Executor 将为你管理 Thread 对象,从而简化了并发编程。Executor 在客户端和任务之间提供了一个间接层;与客户端直接执行任务不同,这个中介对象将执行任务。Executor 允许你管理异步任务的执行,而无须显示地管理线程的生命周期。
public static void main(String[] args) { ExecutorService service = Executors.newCachedThreadPool(); for(int i = 0;i < 5;i++){ service.execute(new TestThread()); } service.shutdown(); }我们使用 Executor 来替代上述显示创建 Thread 对象。CachedThreadPool 为每个任务都创建一个线程。注意:ExecutorService 对象是使用静态的 Executors 创建的,这个方法可以确定 Executor 类型。对 shutDown 的调用可以防止新任务提交给 ExecutorService ,这个线程在 Executor 中所有任务完成后退出。
FixedThreadPool
FixedThreadPool 使你可以使用有限的线程集来启动多线程
public static void main(String[] args) { ExecutorService service = Executors.newFixedThreadPool(5); for(int i = 0;i < 5;i++){ service.execute(new TestThread()); } service.shutdown(); }有了 FixedThreadPool 使你可以一次性的预先执行高昂的线程分配,因此也就可以限制线程的数量。这可以节省时间,因为你不必为每个任务都固定的付出创建线程的开销。
SingleThreadExecutor
SingleThreadExecutor 就是线程数量为 1 的 FixedThreadPool,如果向 SingleThreadPool 一次性提交了多个任务,那么这些任务将会排队,每个任务都会在下一个任务开始前结束,所有的任务都将使用相同的线程。SingleThreadPool 会序列化所有提交给他的任务,并会维护它自己(隐藏)的悬挂队列。
public static void main(String[] args) { ExecutorService service = Executors.newSingleThreadExecutor(); for(int i = 0;i < 5;i++){ service.execute(new TestThread()); } service.shutdown(); }从输出的结果就可以看到,任务都是挨着执行的。我为任务分配了五个线程,但是这五个线程不像是我们之前看到的有换进换出的效果,它每次都会先执行完自己的那个线程,然后余下的线程继续“走完”这条线程的执行路径。你可以用 SingleThreadExecutor 来确保任意时刻都只有唯一一个任务在运行。
从任务中产生返回值
Runnable 是执行工作的独立任务,但它不返回任何值。如果你希望任务在完成时能够返回一个值 ,这个时候你就需要考虑使用 Callable 接口,它是 JDK1.5 之后引入的,通过调用它的 submit 方法,可以把它的返回值放在一个 Future 对象中,然后根据相应的 get() 方法取得提交之后的返回值。
private int id;
public TaskWithResult(int id){
this.id = id;
}
@Override
public String call() throws Exception {
return "result of TaskWithResult " + id;
}
}
public class CallableDemo {
public static void main(String[] args) throws ExecutionException, InterruptedException {
ExecutorService executors = Executors.newCachedThreadPool();
ArrayList<Future<String>> future = new ArrayList<>();
for(int i = 0;i < 10;i++){
// 返回的是调用 call 方法的结果
future.add(executors.submit(new TaskWithResult(i)));
}
for(Future<String> fs : future){
System.out.println(fs.get());
}
}
}
submit() 方法会返回 Future 对象,Future 对象存储的也就是你返回的结果。你也可以使用 isDone 来查询 Future 是否已经完成。
休眠
影响任务行为的一种简单方式就是使线程 休眠,选定给定的休眠时间,调用它的 sleep() 方法, 一般使用的TimeUnit 这个时间类替换 Thread.sleep() 方法,示例如下:
@Override
public void run() {
System.out.println(Thread.currentThread() + "starting ..." );
try {
for(int i = 0;i < 5;i++){
if(i == 3){
System.out.println(Thread.currentThread() + "sleeping ...");
TimeUnit.MILLISECONDS.sleep(1000);
}
}
} catch (InterruptedException e) {
e.printStackTrace();
}
System.out.println(Thread.currentThread() + "wakeup and end ...");
}
public static void main(String[] args) {
ExecutorService executors = Executors.newCachedThreadPool();
for(int i = 0;i < 5;i++){
executors.execute(new SuperclassThread());
}
executors.shutdown();
}
}
关于 TimeUnit 中的 sleep() 方法和 Thread.sleep() 方法的比较,请参考下面这篇博客
优先级
上面提到线程调度器对每个线程的执行都是不可预知的,随机执行的,那么有没有办法告诉线程调度器哪个任务想要优先被执行呢?你可以通过设置线程的优先级状态,告诉线程调度器哪个线程的执行优先级比较高,"请给这个骑手马上派单",线程调度器倾向于让优先级较高的线程优先执行,然而,这并不意味着优先级低的线程得不到执行,也就是说,优先级不会导致死锁的问题。优先级较低的线程只是执行频率较低。
public class SimplePriorities implements Runnable{private int priority;
public SimplePriorities(int priority) {
this.priority = priority;
}
@Override
public void run() {
Thread.currentThread().setPriority(priority);
for(int i = 0;i < 100;i++){
System.out.println(this);
if(i % 10 == 0){
Thread.yield();
}
}
}
@Override
public String toString() {
return Thread.currentThread() + " " + priority;
}
public static void main(String[] args) {
ExecutorService service = Executors.newCachedThreadPool();
for(int i = 0;i < 5;i++){
service.execute(new SimplePriorities(Thread.MAX_PRIORITY));
}
service.execute(new SimplePriorities(Thread.MIN_PRIORITY));
}
}
toString() 方法被覆盖,以便通过使用 Thread.toString() 方法来打印线程的名称。你可以改写线程的默认输出,这里采用了 Thread[pool-1-thread-1,10,main] 这种形式的输出。
通过输出,你可以看到,最后一个线程的优先级最低,其余的线程优先级最高。注意,优先级是在 run 开头设置的,在构造器中设置它们不会有任何好处,因为这个时候线程还没有执行任务。
尽管JDK有10个优先级,但是一般只有MAX_PRIORITY,NORM_PRIORITY,MIN_PRIORITY 三种级别。
作出让步
我们上面提过,如果知道一个线程已经在 run() 方法中运行的差不多了,那么它就可以给线程调度器一个提示:我已经完成了任务中最重要的部分,可以让给别的线程使用CPU了。这个暗示将通过 yield() 方法作出。
有一个很重要的点就是,Thread.yield() 是建议执行切换CPU,而不是强制执行CPU切换。
对于任何重要的控制或者在调用应用时,都不能依赖于 yield() 方法,实际上, yield() 方法经常被滥用。
后台线程
后台(daemon) 线程,是指运行时在后台提供的一种服务线程,这种线程不是属于必须的。当所有非后台线程结束时,程序也就停止了,同时会终止所有的后台线程。反过来说,只要有任何非后台线程还在运行,程序就不会终止。
public class SimpleDaemons implements Runnable{@Override
public void run() {
while (true){
try {
TimeUnit.MILLISECONDS.sleep(100);
System.out.println(Thread.currentThread() + " " + this);
} catch (InterruptedException e) {
System.out.println("sleep() interrupted");
}
}
}
public static void main(String[] args) throws InterruptedException {
for(int i = 0;i < 10;i++){
Thread daemon = new Thread(new SimpleDaemons());
daemon.setDaemon(true);
daemon.start();
}
System.out.println("All Daemons started");
TimeUnit.MILLISECONDS.sleep(175);
}
}
在每次的循环中会创建10个线程,并把每个线程设置为后台线程,然后开始运行,for循环会进行十次,然后输出信息,随后主线程睡眠一段时间后停止运行。在每次run 循环中,都会打印当前线程的信息,主线程运行完毕,程序就执行完毕了。因为 daemon 是后台线程,无法影响主线程的执行。
但是当你把 daemon.setDaemon(true) 去掉时,while(true) 会进行无限循环,那么主线程一直在执行最重要的任务,所以会一直循环下去无法停止。
ThreadFactory
按需要创建线程的对象。使用线程工厂替换了 Thread 或者 Runnable 接口的硬连接,使程序能够使用特殊的线程子类,优先级等。一般的创建方式为
class SimpleThreadFactory implements ThreadFactory { public Thread newThread(Runnable r) { return new Thread(r); } }Executors.defaultThreadFactory 方法提供了一个更有用的简单实现,它在返回之前将创建的线程上下文设置为已知值
ThreadFactory 是一个接口,它只有一个方法就是创建线程的方法
public interface ThreadFactory {// 构建一个新的线程。实现类可能初始化优先级,名称,后台线程状态和 线程组等
Thread newThread(Runnable r);
}
下面来看一个 ThreadFactory 的例子
public class DaemonThreadFactory implements ThreadFactory {@Override
public Thread newThread(Runnable r) {
Thread t = new Thread(r);
t.setDaemon(true);
return t;
}
}
public class DaemonFromFactory implements Runnable{
@Override
public void run() {
while (true){
try {
TimeUnit.MILLISECONDS.sleep(100);
System.out.println(Thread.currentThread() + " " + this);
} catch (InterruptedException e) {
System.out.println("Interrupted");
}
}
}
public static void main(String[] args) throws InterruptedException {
ExecutorService service = Executors.newCachedThreadPool(new DaemonThreadFactory());
for(int i = 0;i < 10;i++){
service.execute(new DaemonFromFactory());
}
System.out.println("All daemons started");
TimeUnit.MILLISECONDS.sleep(500);
}
}
Executors.newCachedThreadPool 可以接受一个线程池对象,创建一个根据需要创建新线程的线程池,但会在它们可用时重用先前构造的线程,并在需要时使用提供的ThreadFactory创建新线程。
加入一个线程
一个线程可以在其他线程上调用 join() 方法,其效果是等待一段时间直到第二个线程结束才正常执行。如果某个线程在另一个线程 t 上调用 t.join() 方法,此线程将被挂起,直到目标线程 t 结束才回复(可以用 t.isAlive() 返回为真假判断)。
也可以在调用 join 时带上一个超时参数,来设置到期时间,时间到期,join方法自动返回。
对 join 的调用也可以被中断,做法是在线程上调用 interrupted 方法,这时需要用到 try…catch 子句
@Override
public void run() {
for(int i = 0;i < 5;i++){
try {
TimeUnit.MILLISECONDS.sleep(1000);
} catch (InterruptedException e) {
System.out.println("Interrupted sleep");
}
System.out.println(Thread.currentThread() + " " + i);
}
}
public static void main(String[] args) throws InterruptedException {
TestJoinMethod join1 = new TestJoinMethod();
TestJoinMethod join2 = new TestJoinMethod();
TestJoinMethod join3 = new TestJoinMethod();
join1.start();
// join1.join();
join2.start();
join3.start();
}
}
join() 方法等待线程死亡。 换句话说,它会导致当前运行的线程停止执行,直到它加入的线程完成其任务。
线程异常捕获
由于线程的本质,使你不能捕获从线程中逃逸的异常,一旦异常逃出任务的run 方法,它就会向外传播到控制台,除非你采取特殊的步骤捕获这种错误的异常,在 Java5 之前,你可以通过线程组来捕获,但是在 Java5 之后,就需要用 Executor 来解决问题,因为线程组不是一次好的尝试。
下面的任务会在 run 方法的执行期间抛出一个异常,并且这个异常会抛到 run 方法的外面,而且 main 方法无法对它进行捕获
public class ExceptionThread implements Runnable{@Override
public void run() {
throw new RuntimeException();
}
public static void main(String[] args) {
try {
ExecutorService service = Executors.newCachedThreadPool();
service.execute(new ExceptionThread());
}catch (Exception e){
System.out.println("eeeee");
}
}
}
为了解决这个问题,我们需要修改 Executor 产生线程的方式,Java5 提供了一个新的接口 Thread.UncaughtExceptionHandler ,它允许你在每个 Thread 上都附着一个异常处理器。Thread.UncaughtExceptionHandler.uncaughtException() 会在线程因未捕获临近死亡时被调用。
@Override
public void run() {
Thread t = Thread.currentThread();
System.out.println("run() by " + t);
System.out.println("eh = " + t.getUncaughtExceptionHandler());
// 手动抛出异常
throw new RuntimeException();
}
}
// 实现Thread.UncaughtExceptionHandler 接口,创建异常处理器 public class MyUncaughtExceptionHandler implements Thread.UncaughtExceptionHandler{
@Override
public void uncaughtException(Thread t, Throwable e) {
System.out.println("caught " + e);
}
}
public class HandlerThreadFactory implements ThreadFactory {
@Override
public Thread newThread(Runnable r) {
System.out.println(this + " creating new Thread");
Thread t = new Thread(r);
System.out.println("created " + t);
t.setUncaughtExceptionHandler(new MyUncaughtExceptionHandler());
System.out.println("ex = " + t.getUncaughtExceptionHandler());
return t;
}
}
public class CaptureUncaughtException {
public static void main(String[] args) {
ExecutorService service = Executors.newCachedThreadPool(new HandlerThreadFactory());
service.execute(new ExceptionThread2());
}
}
在程序中添加了额外的追踪机制,用来验证工厂创建的线程会传递给UncaughtExceptionHandler,你可以看到,未捕获的异常是通过 uncaughtException 来捕获的。
# Exception和Error-Java面试题
在 Java 中的基本理念是 结构不佳的代码不能运行,发现错误的理想时期是在编译期间,因为你不用运行程序,只是凭借着对 Java 基本理念的理解就能发现问题。但是编译期并不能找出所有的问题,有一些 NullPointerException 和 ClassNotFoundException 在编译期找不到,这些异常是 RuntimeException 运行时异常,这些异常往往在运行时才能被发现。
我们写 Java 程序经常会出现两种问题,一种是 java.lang.Exception ,一种是 java.lang.Error,都用来表示出现了异常情况,下面就针对这两种概念进行理解。
认识 Exception
Exception 位于 java.lang 包下,它是一种顶级接口,继承于 Throwable 类,Exception 类及其子类都是 Throwable 的组成条件,是程序出现的合理情况。
在认识 Exception 之前,有必要先了解一下什么是 Throwable。
什么是 Throwable
Throwable 类是 Java 语言中所有错误(errors)和异常(exceptions)的父类。只有继承于 Throwable 的类或者其子类才能够被抛出,还有一种方式是带有 Java 中的 @throw 注解的类也可以抛出。
在Java规范中,对非受查异常和受查异常的定义是这样的:
The unchecked exception classes are the run-time exception classes and the error classes.
The checked exception classes are all exception classes other than the unchecked exception classes. That is, the checked exception classes are
Throwableand all its subclasses other thanRuntimeExceptionand its subclasses andErrorand its subclasses.
也就是说,除了 RuntimeException 和其子类,以及error和其子类,其它的所有异常都是 checkedException。
那么,按照这种逻辑关系,我们可以对 Throwable 及其子类进行归类分析
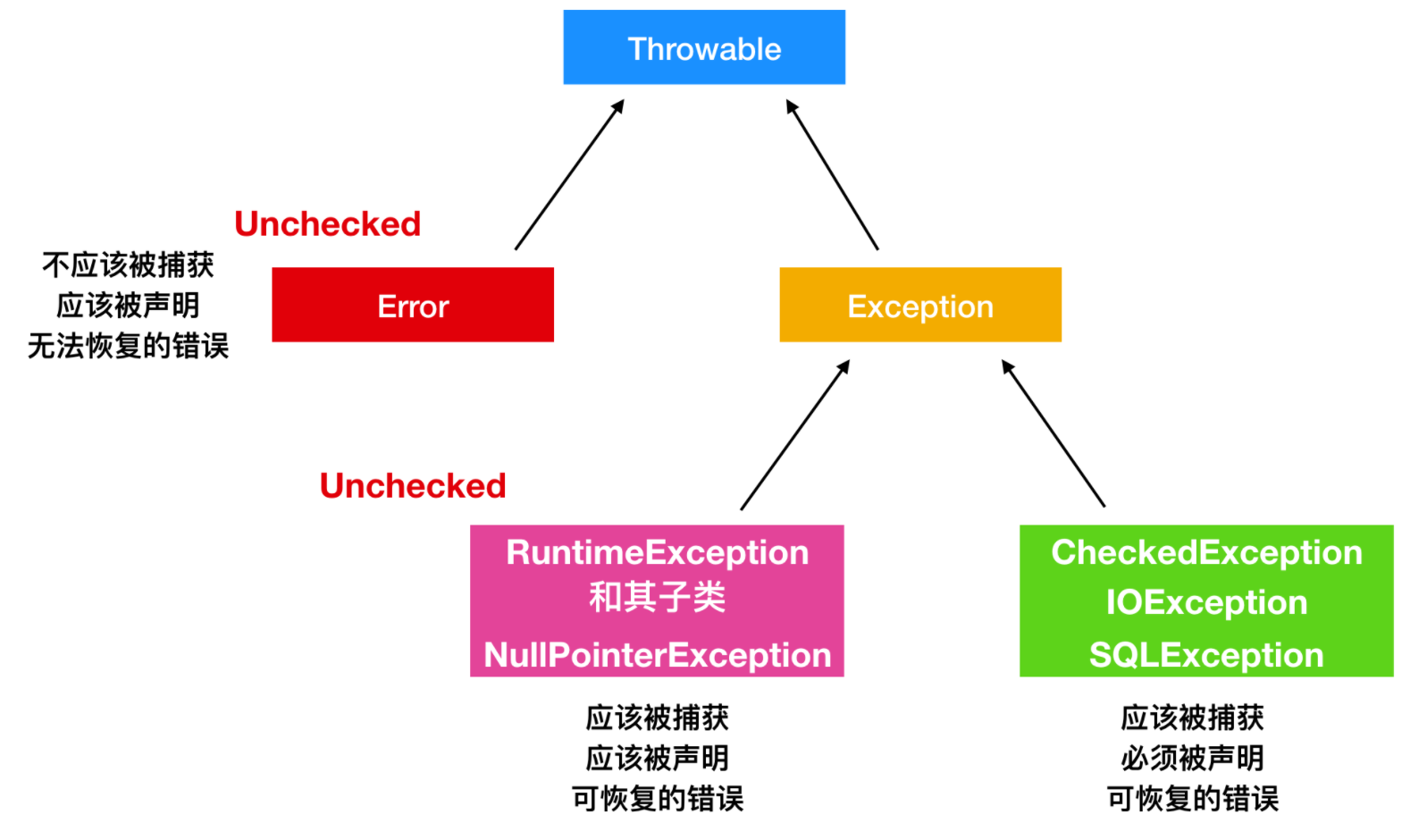
可以看到,Throwable 位于异常和错误的最顶层,我们查看 Throwable 类中发现它的方法和属性有很多,我们只讨论其中几个比较常用的
// 返回抛出异常的详细信息 public string getMessage(); public string getLocalizedMessage();//返回异常发生时的简要描述 public public String toString();
// 打印异常信息到标准输出流上 public void printStackTrace(); public void printStackTrace(PrintStream s); public void printStackTrace(PrintWriter s)
// 记录栈帧的的当前状态 public synchronized Throwable fillInStackTrace();
此外,因为 Throwable 的父类也是 Object,所以常用的方法还有继承其父类的getClass() 和 getName() 方法。
常见的 Exception
下面我们回到 Exception 的探讨上来,现在你知道了 Exception 的父类是 Throwable,并且 Exception 有两种异常,一种是 RuntimeException ;一种是 CheckedException,这两种异常都应该去捕获。
下面列出了一些 Java 中常见的异常及其分类,这块面试官也可能让你举出几个常见的异常情况并将其分类
RuntimeException
| 序号 | 异常名称 | 异常描述 |
|---|---|---|
| 1 | ArrayIndexOutOfBoundsException | 数组越界异常 |
| 2 | NullPointerException | 空指针异常 |
| 3 | IllegalArgumentException | 非法参数异常 |
| 4 | NegativeArraySizeException | 数组长度为负异常 |
| 5 | IllegalStateException | 非法状态异常 |
| 6 | ClassCastException | 类型转换异常 |
UncheckedException
| 序号 | 异常名称 | 异常描述 |
|---|---|---|
| 1 | NoSuchFieldException | 表示该类没有指定名称抛出来的异常 |
| 2 | NoSuchMethodException | 表示该类没有指定方法抛出来的异常 |
| 3 | IllegalAccessException | 不允许访问某个类的异常 |
| 4 | ClassNotFoundException | 类没有找到抛出异常 |
与 Exception 有关的 Java 关键字
那么 Java 中是如何处理这些异常的呢?在 Java 中有这几个关键字 throws、throw、try、finally、catch 下面我们分别来探讨一下
throws 和 throw
在 Java 中,异常也就是一个对象,它能够被程序员自定义抛出或者应用程序抛出,必须借助于 throws 和 throw 语句来定义抛出异常。
throws 和 throw 通常是成对出现的,例如
static void cacheException() throws Exception{throw new Exception();
}
throw 语句用在方法体内,表示抛出异常,由方法体内的语句处理。
throws 语句用在方法声明后面,表示再抛出异常,由该方法的调用者来处理。
throws 主要是声明这个方法会抛出这种类型的异常,使它的调用者知道要捕获这个异常。
throw 是具体向外抛异常的动作,所以它是抛出一个异常实例。
try 、finally 、catch
这三个关键字主要有下面几种组合方式 try…catch 、try…finally、try…catch…finally。
try…catch 表示对某一段代码可能抛出异常进行的捕获,如下
static void cacheException() throws Exception{try { System.out.println("1"); }catch (Exception e){ e.printStackTrace(); }
}
try…finally 表示对一段代码不管执行情况如何,都会走 finally 中的代码
static void cacheException() throws Exception{ for (int i = 0; i < 5; i++) { System.out.println("enter: i=" + i); try { System.out.println("execute: i=" + i); continue; } finally { System.out.println("leave: i=" + i); } } }try…catch…finally 也是一样的,表示对异常捕获后,再走 finally 中的代码逻辑。
JDK1.7 使用 try…with…resources 优雅关闭资源
Java 类库中有许多资源需要通过 close 方法进行关闭。比如 InputStream、OutputStream,数据库连接对象 Connection,MyBatis 中的 SqlSession 会话等。作为开发人员经常会忽略掉资源的关闭方法,导致内存泄漏。
根据经验,try-finally语句是确保资源会被关闭的最佳方法,就算异常或者返回也一样。try-catch-finally 一般是这样来用的
这样看起来代码还是比较整洁,但是当我们添加第二个需要关闭的资源的时候,就像下面这样
static void copy(String src,String dst) throws Exception{ InputStream is = new FileInputStream(src); try {OutputStream os = new FileOutputStream(dst);
try {
byte[] buf = new byte[100];
int n;
while ((n = is.read()) >= 0){
os.write(buf,n,0);
}
}finally {
os.close();
}
}finally { is.close(); } }
这样感觉这个方法已经变得臃肿起来了。
而且这种写法也存在诸多问题,即使 try – finally 能够正确关闭资源,但是它不能阻止异常的抛出,因为 try 和 finally 块中都可能有异常的发生。
比如说你正在读取的时候硬盘损坏,这个时候你就无法读取文件和关闭资源了,此时会抛出两个异常。但是在这种情况下,第二个异常会抹掉第一个异常。在异常堆栈中也无法找到第一个异常的记录,怎么办,难道像这样来捕捉异常么?
static void tryThrowException(String path) throws Exception {BufferedReader br = new BufferedReader(new FileReader(path)); try { String s = br.readLine(); System.out.println("s = " + s);
}catch (Exception e){ e.printStackTrace(); }finally { try { br.close(); }catch (Exception e){ e.printStackTrace(); }finally { br.close(); } } }
这种写法,虽然能解决异常抛出的问题,但是各种 try-cath-finally 的嵌套会让代码变得非常臃肿。
Java7 中引入了try-with-resources 语句时,所有这些问题都能得到解决。要使用 try-with-resources 语句,首先要实现 AutoCloseable 接口,此接口包含了单个返回的 close 方法。Java 类库与三方类库中的许多类和接口,现在都实现或者扩展了 AutoCloseable 接口。如果编写了一个类,它代表的是必须关闭的资源,那么这个类应该实现 AutoCloseable 接口。
java 引入了 try-with-resources 声明,将 try-catch-finally 简化为 try-catch,这其实是一种语法糖,在编译时会进行转化为 try-catch-finally 语句。
下面是使用 try-with-resources 的第一个范例
/** * 使用try-with-resources 改写示例一 * @param path * @return * @throws IOException */ static String firstLineOfFileAutoClose(String path) throws IOException {try(BufferedReader br = new BufferedReader(new FileReader(path))){ return br.readLine(); } }
使用 try-with-resources 改写程序的第二个示例
static void copyAutoClose(String src,String dst) throws IOException{try(InputStream in = new FileInputStream(src); OutputStream os = new FileOutputStream(dst)){ byte[] buf = new byte[1000]; int n; while ((n = in.read(buf)) >= 0){ os.write(buf,0,n); } } }
使用 try-with-resources 不仅使代码变得通俗易懂,也更容易诊断。以firstLineOfFileAutoClose方法为例,如果调用 readLine() 和 close() 方法都抛出异常,后一个异常就会被禁止,以保留第一个异常。
异常处理的原则
我们在日常处理异常的代码中,应该遵循三个原则
- 不要捕获类似
Exception之类的异常,而应该捕获类似特定的异常,比如InterruptedException,方便排查问题,而且也能够让其他人接手你的代码时,会减少骂你的次数。 - 不要生吞异常。这是异常处理中要特别注重的事情,因为很可能会非常难以正常结束情况。如果我们不把异常抛出来,或者也没有输出到 Logger 日志中,程序可能会在后面以不可控的方式结束。
- 不要在函数式编程中使用
checkedException。
什么是 Error
Error 是程序无法处理的错误,表示运行应用程序中较严重问题。大多数错误与代码编写者执行的操作无关,而表示代码运行时 JVM(Java 虚拟机)出现的问题。这些错误是不可检查的,因为它们在应用程序的控制和处理能力之 外,而且绝大多数是程序运行时不允许出现的状况,比如 OutOfMemoryError 和 StackOverflowError异常的出现会有几种情况,这里需要先介绍一下 Java 内存模型 JDK1.7。
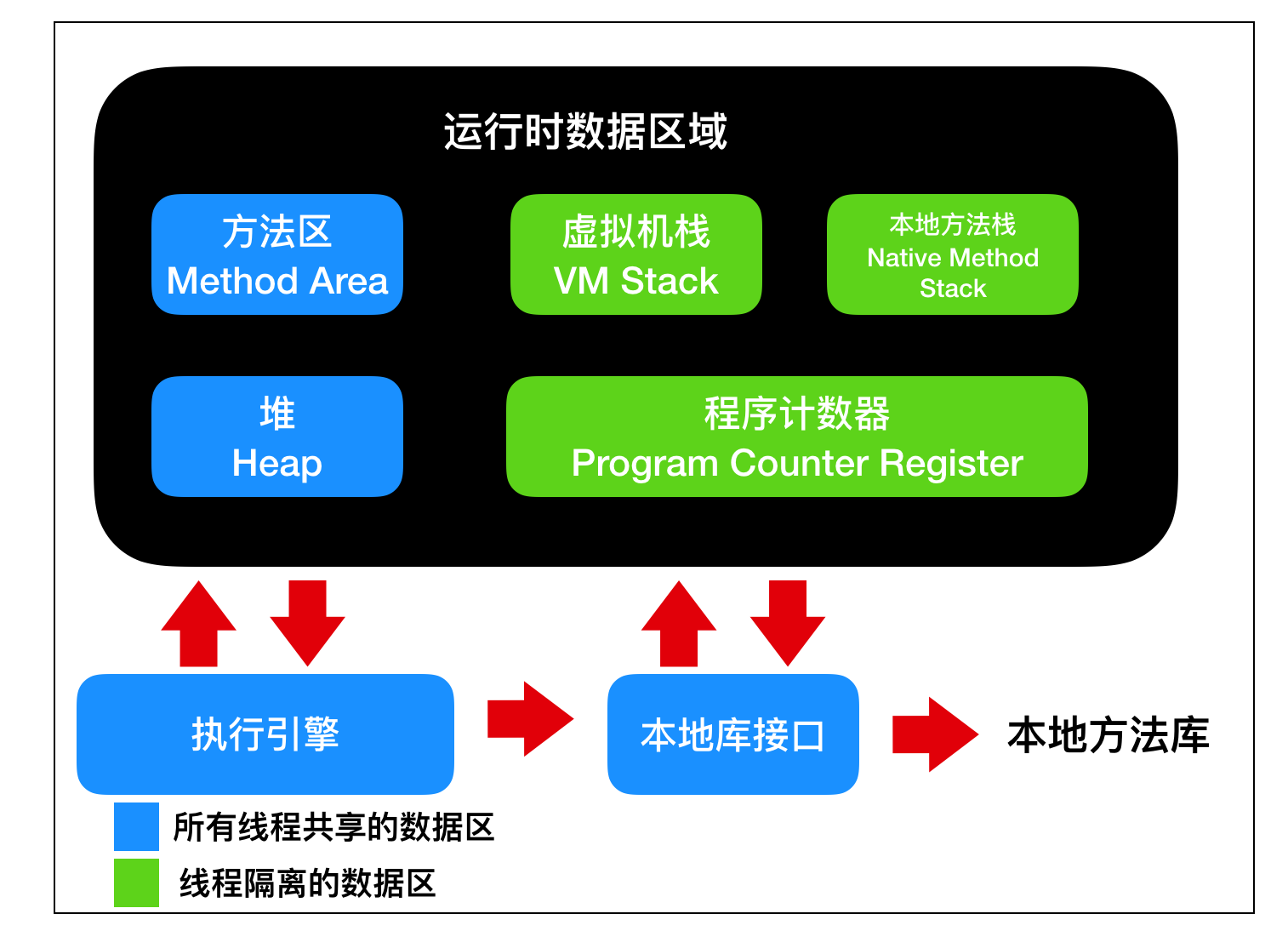
其中包括两部分,由所有线程共享的数据区和线程隔离的数据区组成,在上面的 Java 内存模型中,只有程序计数器是不会发生 OutOfMemoryError 情况的区域,程序计数器控制着计算机指令的分支、循环、跳转、异常处理和线程恢复,并且程序计数器是每个线程私有的。
什么是线程私有:表示的就是各条线程之间互不影响,独立存储的内存区域。
如果应用程序执行的是 Java 方法,那么这个计数器记录的就是虚拟机字节码指令的地址;如果正在执行的是 Native 方法,这个计数器值则为空(Undefined)。
除了程序计数器外,其他区域:方法区(Method Area)、虚拟机栈(VM Stack)、本地方法栈(Native Method Stack) 和 堆(Heap) 都是可能发生 OutOfMemoryError 的区域。
虚拟机栈:如果线程请求的栈深度大于虚拟机栈所允许的深度,将会出现
StackOverflowError异常;如果虚拟机动态扩展无法申请到足够的内存,将出现OutOfMemoryError。本地方法栈和虚拟机栈一样
堆:Java 堆可以处于物理上不连续,逻辑上连续,就像我们的磁盘空间一样,如果堆中没有内存完成实例分配,并且堆无法扩展时,将会抛出 OutOfMemoryError。
方法区:方法区无法满足内存分配需求时,将抛出 OutOfMemoryError 异常。
一道经典的面试题
一道非常经典的面试题,NoClassDefFoundError 和 ClassNotFoundException 有什么区别?
在类的加载过程中, JVM 或者 ClassLoader 无法找到对应的类时,都可能会引起这两种异常/错误,由于不同的 ClassLoader 会从不同的地方加载类,有时是错误的 CLASSPATH 类路径导致的这类错误,有时是某个库的 jar 包缺失引发这类错误。NoClassDefFoundError 表示这个类在编译时期存在,但是在运行时却找不到此类,有时静态初始化块也会导致 NoClassDefFoundError 错误。
ClassLoader 是类路径装载器,在Java 中,类路径装载器一共有三种两类
一种是虚拟机自带的 ClassLoader,分为三种
启动类加载器(Bootstrap),负责加载 $JAVAHOME/jre/lib/rt.jar扩展类加载器(Extension),负责加载 $JAVAHOME/jre/lib/ext/*.jar应用程序类加载器(AppClassLoader),加载当前应用的 classpath 的所有类第二种是用户自定义类加载器
- Java.lang.ClassLoader 的子类,用户可以定制类的加载方式。
另一方面,ClassNotFoundException 与编译时期无关,当你尝试在运行时使用反射加载类时,ClassNotFoundException 就会出现。
简而言之,ClassNotFoundException 和 NoClassDefFoundError 都是由 CLASSPATH 中缺少类引起的,通常是由于缺少 JAR 文件而引起的,但是如果 JVM 认为应用运行时找不到相应的引用,就会抛出 NoClassDefFoundError 错误;当你在代码中显示的加载类比如 Class.forName() 调用时却没有找到相应的类,就会抛出 java.lang.ClassNotFoundException。
- NoClassDefFoundError 是 JVM 引起的错误,是 unchecked,未经检查的。因此不会使用 try-catch 或者 finally 语句块;另外,ClassNotFoundException 是受检异常,因此需要 try-catch 语句块或者 try-finally 语句块包围,否则会导致编译错误。
- 调用 Class.forName()、ClassLoader.findClass() 和 ClassLoader.loadClass() 等方法时可能会引起
java.lang.ClassNotFoundException,如图所示
- NoClassDefFoundError 是链接错误,发生在链接阶段,当解析引用找不到对应的类,就会触发;而 ClassNotFoundException 是发生在运行时的异常。
# 超全Java集合框架讲解-Java面试题
集合在我们日常开发使用的次数数不胜数,ArrayList/LinkedList/HashMap/HashSet······信手拈来,抬手就拿来用,在 IDE 上龙飞凤舞,但是作为一名合格的优雅的程序猿,仅仅了解怎么使用API是远远不够的,如果在调用API时,知道它内部发生了什么事情,就像开了透视外挂一样,洞穿一切,这种感觉才真的爽,而且这样就不是集合提供什么功能给我们使用,而是我们选择使用它的什么功能了。
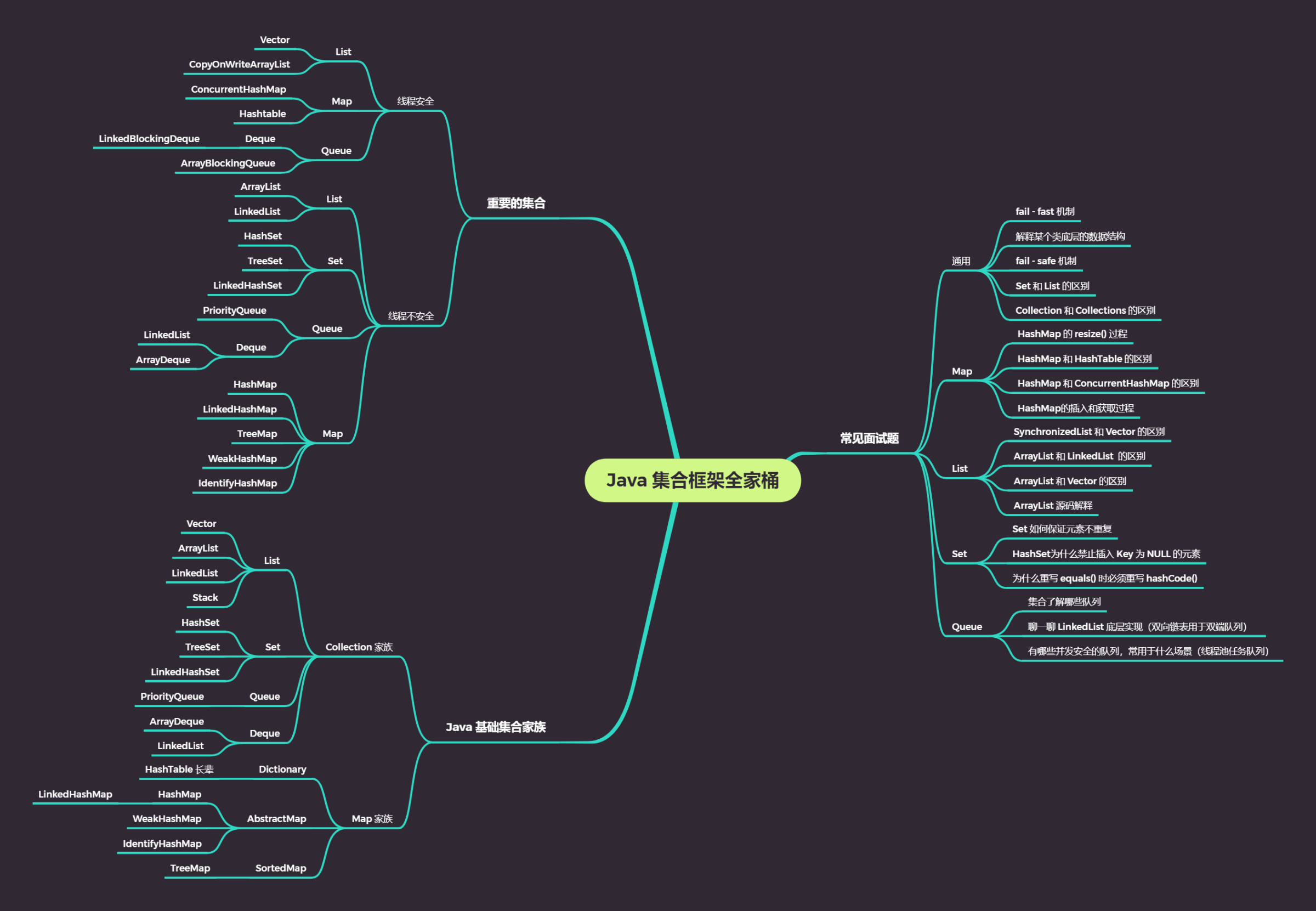
集合框架总览
下图堪称集合框架的上帝视角,讲到集合框架不得不看的就是这幅图,当然,你会觉得眼花缭乱,不知如何看起,这篇文章带你一步一步地秒杀上面的每一个接口、抽象类和具体类。我们将会从最顶层的接口开始讲起,一步一步往下深入,帮助你把对集合的认知构建起一个知识网络。
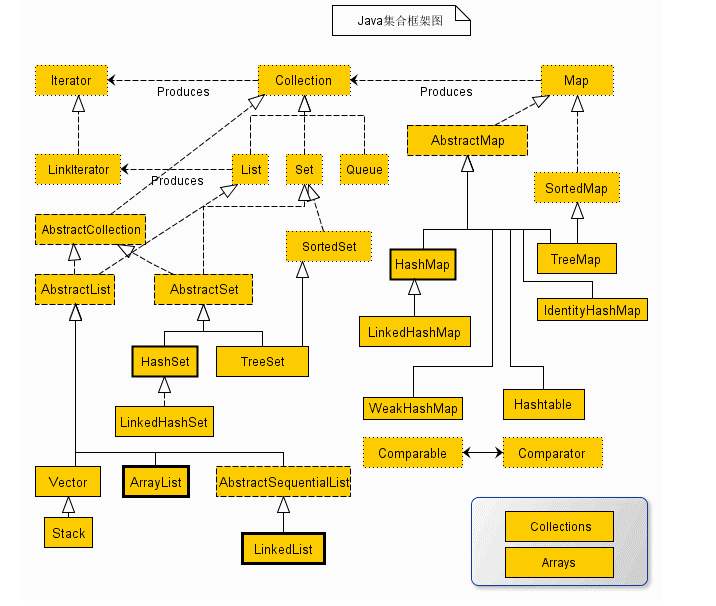
工欲善其事必先利其器,让我们先来过一遍整个集合框架的组成部分:
- 集合框架提供了两个遍历接口:
Iterator和ListIterator,其中后者是前者的优化版,支持在任意一个位置进行前后双向遍历。注意图中的Collection应当继承的是Iterable而不是Iterator,后面会解释Iterable和Iterator的区别 - 整个集合框架分为两个门派(类型):
Collection和Map,前者是一个容器,存储一系列的对象;后者是键值对<key, value>,存储一系列的键值对 - 在集合框架体系下,衍生出四种具体的集合类型:
Map、Set、List、Queue Map存储<key,value>键值对,查找元素时通过key查找valueSet内部存储一系列不可重复的对象,且是一个无序集合,对象排列顺序不一List内部存储一系列可重复的对象,是一个有序集合,对象按插入顺序排列Queue是一个队列容器,其特性与List相同,但只能从队头和队尾操作元素- JDK 为集合的各种操作提供了两个工具类
Collections和Arrays,之后会讲解工具类的常用方法 - 四种抽象集合类型内部也会衍生出许多具有不同特性的集合类,不同场景下择优使用,没有最佳的集合
上面了解了整个集合框架体系的组成部分,接下来的章节会严格按照上面罗列的顺序进行讲解,每一步都会有承上启下的作用
学习
Set前,最好最好要先学习Map,因为Set的操作本质上是对Map的操作,往下看准没错
Iterator Iterable ListIterator
在第一次看这两个接口,真以为是一模一样的,没发现里面有啥不同,存在即合理,它们两个还是有本质上的区别的。
首先来看Iterator接口:
提供的API接口含义如下:
hasNext():判断集合中是否存在下一个对象next():返回集合中的下一个对象,并将访问指针移动一位remove():删除集合中调用next()方法返回的对象
在早期,遍历集合的方式只有一种,通过Iterator迭代器操作
再来看Iterable接口:
可以看到Iterable接口里面提供了Iterator接口,所以实现了Iterable接口的集合依旧可以使用迭代器遍历和操作集合中的对象;
而在 JDK 1.8中,Iterable提供了一个新的方法forEach(),它允许使用增强 for 循环遍历对象。
我们通过命令:javap -c反编译上面的这段代码后,发现它只是 Java 中的一个语法糖,本质上还是调用Iterator去遍历。
翻译成代码,就和一开始的Iterator迭代器遍历方式基本相同了。
还有更深层次的探讨:为什么要设计两个接口
Iterable和Iterator,而不是保留其中一个就可以了。简单讲解:
Iterator的保留可以让子类去实现自己的迭代器,而Iterable接口更加关注于for-each的增强语法。具体可参考:Java中的Iterable与Iterator详解
关于Iterator和Iterable的讲解告一段落,下面来总结一下它们的重点:
Iterator是提供集合操作内部对象的一个迭代器,它可以遍历、移除对象,且只能够单向移动Iterable是对Iterator的封装,在JDK 1.8时,实现了Iterable接口的集合可以使用增强 for 循环遍历集合对象,我们通过反编译后发现底层还是使用Iterator迭代器进行遍历
等等,这一章还没完,还有一个ListIterator。它继承 Iterator 接口,在遍历List集合时可以从任意索引下标开始遍历,而且支持双向遍历。
ListIterator 存在于 List 集合之中,通过调用方法可以返回起始下标为 index的迭代器
ListIterator 中有几个重要方法,大多数方法与 Iterator 中定义的含义相同,但是比 Iterator 强大的地方是可以在任意一个下标位置返回该迭代器,且可以实现双向遍历。
public interface ListIterator<E> extends Iterator<E> { boolean hasNext(); E next(); boolean hasPrevious(); E previous(); int nextIndex(); int previousIndex(); void remove(); // 替换当前下标的元素,即访问过的最后一个元素 void set(E e); void add(E e); }Map 和 Collection 接口
Map 接口和 Collection 接口是集合框架体系的两大门派,Collection 是存储元素本身,而 Map 是存储<key, value>键值对,在 Collection 门派下有一小部分弟子去偷师,利用 Map 门派下的弟子来修炼自己。
是不是听的一头雾水哈哈哈,举个例子你就懂了:HashSet底层利用了HashMap,TreeSet底层用了TreeMap,LinkedHashSet底层用了LinkedHashMap。
下面我会详细讲到各个具体集合类哦,所以在这里,我们先从整体上了解这两个门派的特点和区别。
Map接口定义了存储的数据结构是<key, value>形式,根据 key 映射到 value,一个 key 对应一个 value ,所以key不可重复,而value可重复。
在Map接口下会将存储的方式细分为不同的种类:
SortedMap接口:该类映射可以对<key, value>按照自己的规则进行排序,具体实现有 TreeMapAbsractMap:它为子类提供好一些通用的API实现,所有的具体Map如HashMap都会继承它
而Collection接口提供了所有集合的通用方法(注意这里不包括Map):
- 添加方法:
add(E e)/addAll(Collection<? extends E> var1) - 删除方法:
remove(Object var1)/removeAll(Collection<?> var1) - 查找方法:
contains(Object var1)/containsAll(Collection<?> var1); - 查询集合自身信息:
size()/isEmpty() - ···
在Collection接口下,同样会将集合细分为不同的种类:
Set接口:一个不允许存储重复元素的无序集合,具体实现有HashSet/TreeSet···List接口:一个可存储重复元素的有序集合,具体实现有ArrayList/LinkedList···Queue接口:一个可存储重复元素的队列,具体实现有PriorityQueue/ArrayDeque···
Map 集合体系详解
Map接口是由<key, value>组成的集合,由key映射到唯一的value,所以Map不能包含重复的key,每个键至多映射一个值。下图是整个 Map 集合体系的主要组成部分,我将会按照日常使用频率从高到低一一讲解。
不得不提的是 Map 的设计理念:定位元素的时间复杂度优化到 O(1)
Map 体系下主要分为 AbstractMap 和 SortedMap两类集合
AbstractMap是对 Map 接口的扩展,它定义了普通的 Map 集合具有的通用行为,可以避免子类重复编写大量相同的代码,子类继承 AbstractMap 后可以重写它的方法,实现额外的逻辑,对外提供更多的功能。
SortedMap 定义了该类 Map 具有 排序行为,同时它在内部定义好有关排序的抽象方法,当子类实现它时,必须重写所有方法,对外提供排序功能。
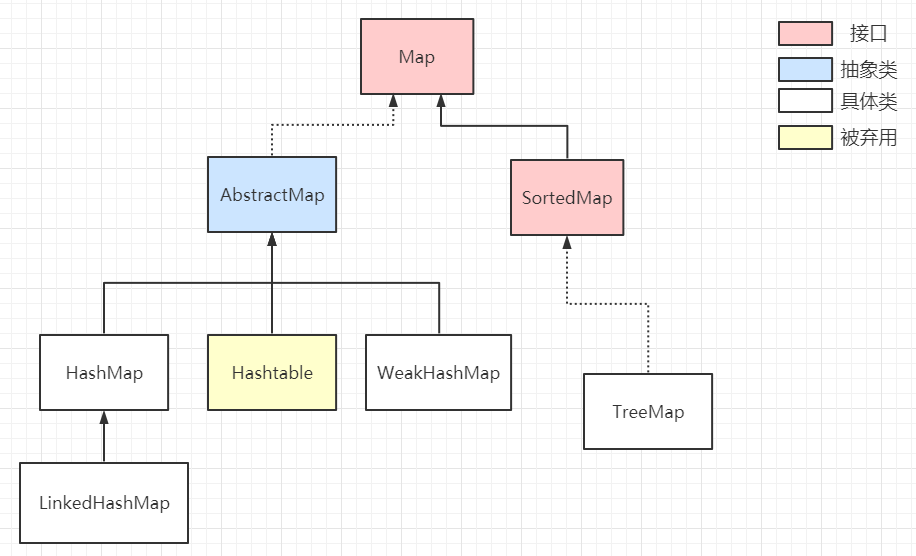
HashMap
HashMap 是一个最通用的利用哈希表存储元素的集合,将元素放入 HashMap 时,将key的哈希值转换为数组的索引下标确定存放位置,查找时,根据key的哈希地址转换成数组的索引下标确定查找位置。
HashMap 底层是用数组 + 链表 + 红黑树这三种数据结构实现,它是非线程安全的集合。
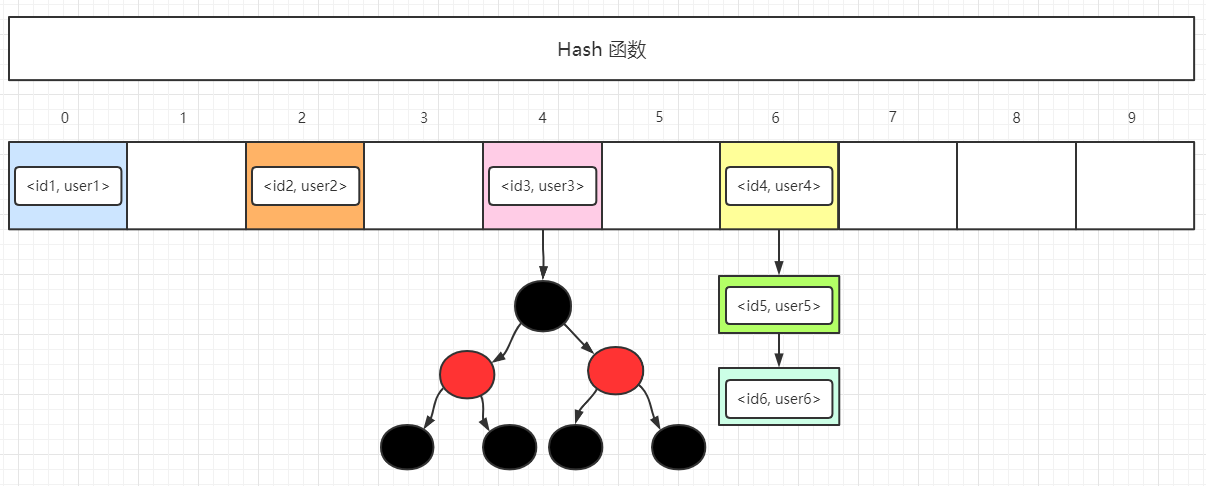
发送哈希冲突时,HashMap 的解决方法是将相同映射地址的元素连成一条链表,如果链表的长度大于8时,且数组的长度大于64则会转换成红黑树数据结构。
关于 HashMap 的简要总结:
- 它是集合中最常用的
Map集合类型,底层由数组 + 链表 + 红黑树组成 - HashMap不是线程安全的
- 插入元素时,通过计算元素的
哈希值,通过哈希映射函数转换为数组下标;查找元素时,同样通过哈希映射函数得到数组下标定位元素的位置
LinkedHashMap
LinkedHashMap 可以看作是 HashMap 和 LinkedList 的结合:它在 HashMap 的基础上添加了一条双向链表,默认存储各个元素的插入顺序,但由于这条双向链表,使得 LinkedHashMap 可以实现 LRU缓存淘汰策略,因为我们可以设置这条双向链表按照元素的访问次序进行排序
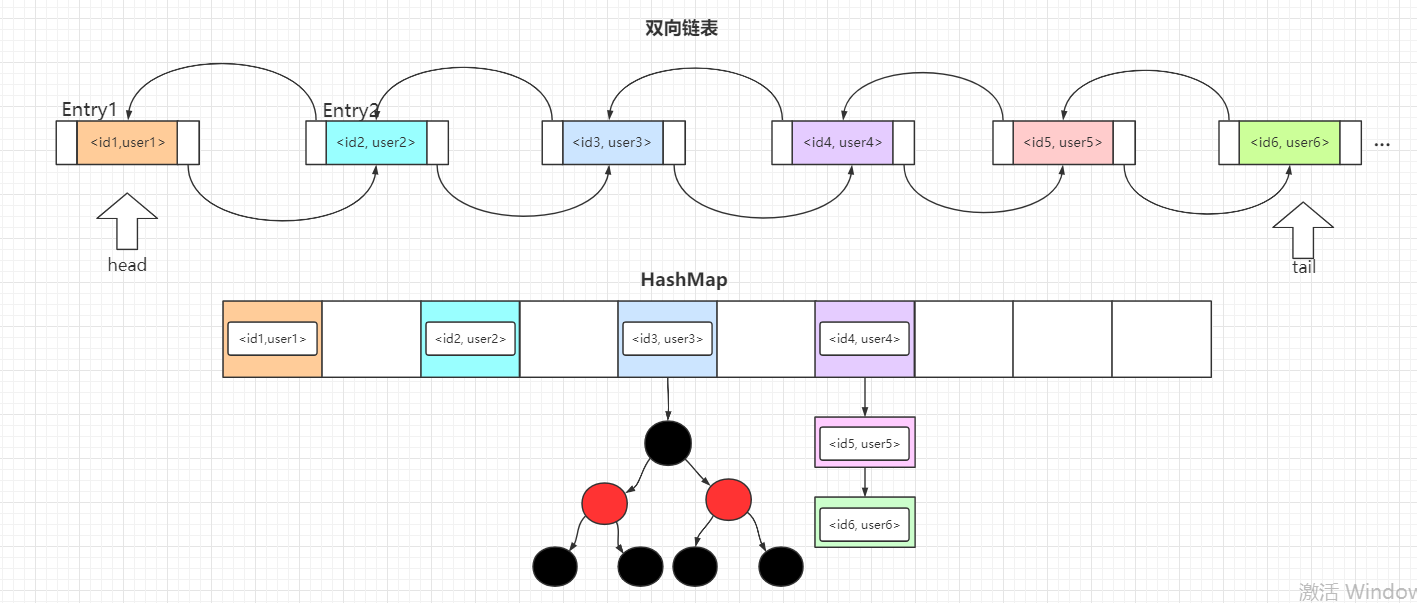
LinkedHashMap 是 HashMap 的子类,所以它具备 HashMap 的所有特点,其次,它在 HashMap 的基础上维护了一条双向链表,该链表存储了所有元素,默认元素的顺序与插入顺序一致。若accessOrder属性为true,则遍历顺序按元素的访问次序进行排序。
利用 LinkedHashMap 可以实现 LRU 缓存淘汰策略,因为它提供了一个方法:
该方法可以移除最靠近链表头部的一个节点,而在get()方法中可以看到下面这段代码,其作用是挪动结点的位置:
只要调用了get()且accessOrder = true,则会将该节点更新到链表尾部,具体的逻辑在afterNodeAccess()中,感兴趣的可翻看源码,篇幅原因这里不再展开。
现在如果要实现一个LRU缓存策略,则需要做两件事情:
- 指定
accessOrder = true可以设定链表按照访问顺序排列,通过提供的构造器可以设定accessOrder
- 重写
removeEldestEntry()方法,内部定义逻辑,通常是判断容量是否达到上限,若是则执行淘汰。
这里就要贴出一道大厂面试必考题目:146. LRU缓存机制,只要跟着我的步骤,就能顺利完成这道大厂题了。
关于 LinkedHashMap 主要介绍两点:
- 它底层维护了一条
双向链表,因为继承了 HashMap,所以它也不是线程安全的 - LinkedHashMap 可实现
LRU缓存淘汰策略,其原理是通过设置accessOrder为true并重写removeEldestEntry方法定义淘汰元素时需满足的条件
TreeMap
TreeMap 是 SortedMap 的子类,所以它具有排序功能。它是基于红黑树数据结构实现的,每一个键值对<key, value>都是一个结点,默认情况下按照key自然排序,另一种是可以通过传入定制的Comparator进行自定义规则排序。
TreeMap 底层使用了数组+红黑树实现,所以里面的存储结构可以理解成下面这幅图哦。
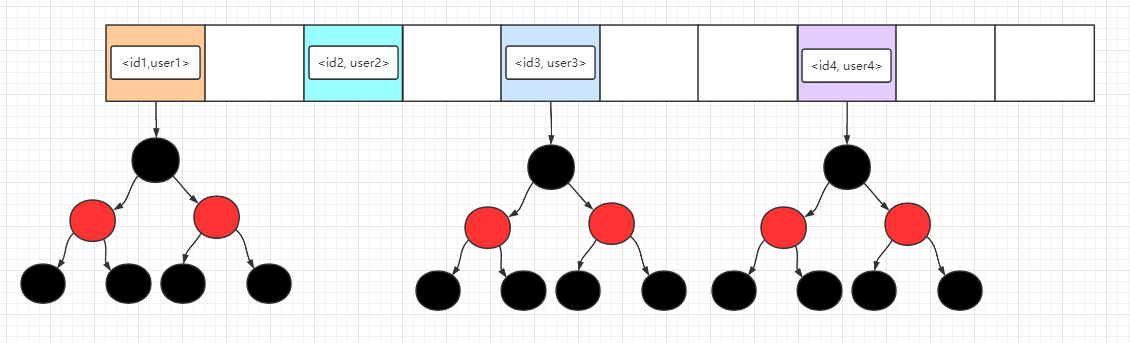
图中红黑树的每一个节点都是一个Entry,在这里为了图片的简洁性,就不标明 key 和 value 了,注意这些元素都是已经按照key排好序了,整个数据结构都是保持着有序 的状态!
关于自然排序与定制排序:
- 自然排序:要求
key必须实现Comparable接口。
由于Integer类实现了 Comparable 接口,按照自然排序规则是按照key从小到大排序。
- 定制排序:在初始化 TreeMap 时传入新的
Comparator,不要求key实现 Comparable 接口
通过传入新的Comparator比较器,可以覆盖默认的排序规则,上面的代码按照key降序排序,在实际应用中还可以按照其它规则自定义排序。
compare()方法的返回值有三种,分别是:0,-1,+1
(1)如果返回0,代表两个元素相等,不需要调换顺序
(2)如果返回+1,代表前面的元素需要与后面的元素调换位置
(3)如果返回-1,代表前面的元素不需要与后面的元素调换位置
而何时返回+1和-1,则由我们自己去定义,JDK默认是按照自然排序,而我们可以根据key的不同去定义降序还是升序排序。
关于 TreeMap 主要介绍了两点:
- 它底层是由
红黑树这种数据结构实现的,所以操作的时间复杂度恒为O(logN) - TreeMap 可以对
key进行自然排序或者自定义排序,自定义排序时需要传入Comparator,而自然排序要求key实现了Comparable接口 - TreeMap 不是线程安全的。
WeakHashMap
WeakHashMap 日常开发中比较少见,它是基于普通的Map实现的,而里面Entry中的键在每一次的垃圾回收都会被清除掉,所以非常适合用于短暂访问、仅访问一次的元素,缓存在WeakHashMap中,并尽早地把它回收掉。
当Entry被GC时,WeakHashMap 是如何感知到某个元素被回收的呢?
在 WeakHashMap 内部维护了一个引用队列queue
这个 queue 里包含了所有被GC掉的键,当JVM开启GC后,如果回收掉 WeakHashMap 中的 key,会将 key 放入queue 中,在expungeStaleEntries()中遍历 queue,把 queue 中的所有key拿出来,并在 WeakHashMap 中删除掉,以达到同步。
再者,需要注意 WeakHashMap 底层存储的元素的数据结构是数组 + 链表,没有红黑树哦,可以换一个角度想,如果还有红黑树,那干脆直接继承 HashMap ,然后再扩展就完事了嘛,然而它并没有这样做:
}
所以,WeakHashMap 的数据结构图我也为你准备好啦。
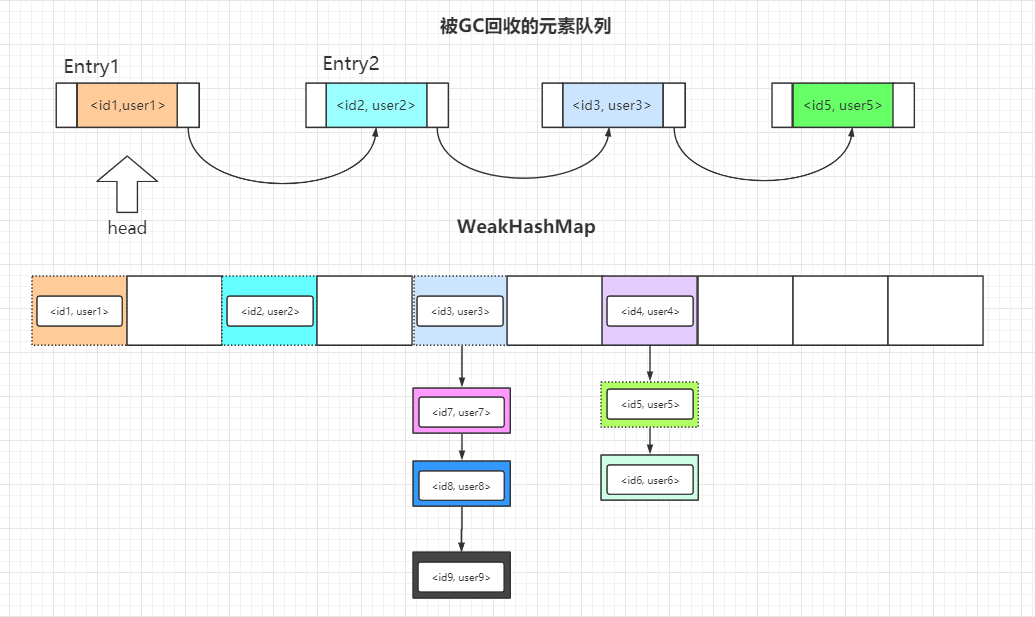
图中被虚线标识的元素将会在下一次访问 WeakHashMap 时被删除掉,WeakHashMap 内部会做好一系列的调整工作,所以记住队列的作用就是标志那些已经被GC回收掉的元素。
关于 WeakHashMap 需要注意两点:
- 它的键是一种弱键,放入 WeakHashMap 时,随时会被回收掉,所以不能确保某次访问元素一定存在
- 它依赖普通的
Map进行实现,是一个非线程安全的集合 - WeakHashMap 通常作为缓存使用,适合存储那些只需访问一次、或只需保存短暂时间的键值对
Hashtable
Hashtable 底层的存储结构是数组 + 链表,而它是一个线程安全的集合,但是因为这个线程安全,它就被淘汰掉了。
下面是Hashtable存储元素时的数据结构图,它只会存在数组+链表,当链表过长时,查询的效率过低,而且会长时间锁住 Hashtable。
这幅图是否有点眼熟哈哈哈哈,本质上就是 WeakHashMap 的底层存储结构了。你千万别问为什么 WeakHashMap 不继承 Hashtable 哦,Hashtable 的
性能在并发环境下非常差,在非并发环境下可以用HashMap更优。
HashTable 本质上是 HashMap 的前辈,它被淘汰的原因也主要因为两个字:性能
HashTable 是一个 线程安全 的 Map,它所有的方法都被加上了 synchronized 关键字,也是因为这个关键字,它注定成为了时代的弃儿。
HashTable 底层采用 数组+链表 存储键值对,由于被弃用,后人也没有对它进行任何改进
HashTable 默认长度为 11,负载因子为 0.75F,即元素个数达到数组长度的 75% 时,会进行一次扩容,每次扩容为原来数组长度的 2 倍
HashTable 所有的操作都是线程安全的。
Collection 集合体系详解
Collection 集合体系的顶层接口就是Collection,它规定了该集合下的一系列行为约定。
该集合下可以分为三大类集合:List,Set和Queue
Set接口定义了该类集合不允许存储重复的元素,且任何操作时均需要通过哈希函数映射到集合内部定位元素,集合内部的元素默认是无序的。
List接口定义了该类集合允许存储重复的元素,且集合内部的元素按照元素插入的顺序有序排列,可以通过索引访问元素。
Queue接口定义了该类集合是以队列作为存储结构,所以集合内部的元素有序排列,仅可以操作头结点元素,无法访问队列中间的元素。
上面三个接口是最普通,最抽象的实现,而在各个集合接口内部,还会有更加具体的表现,衍生出各种不同的额外功能,使开发者能够对比各个集合的优势,择优使用。
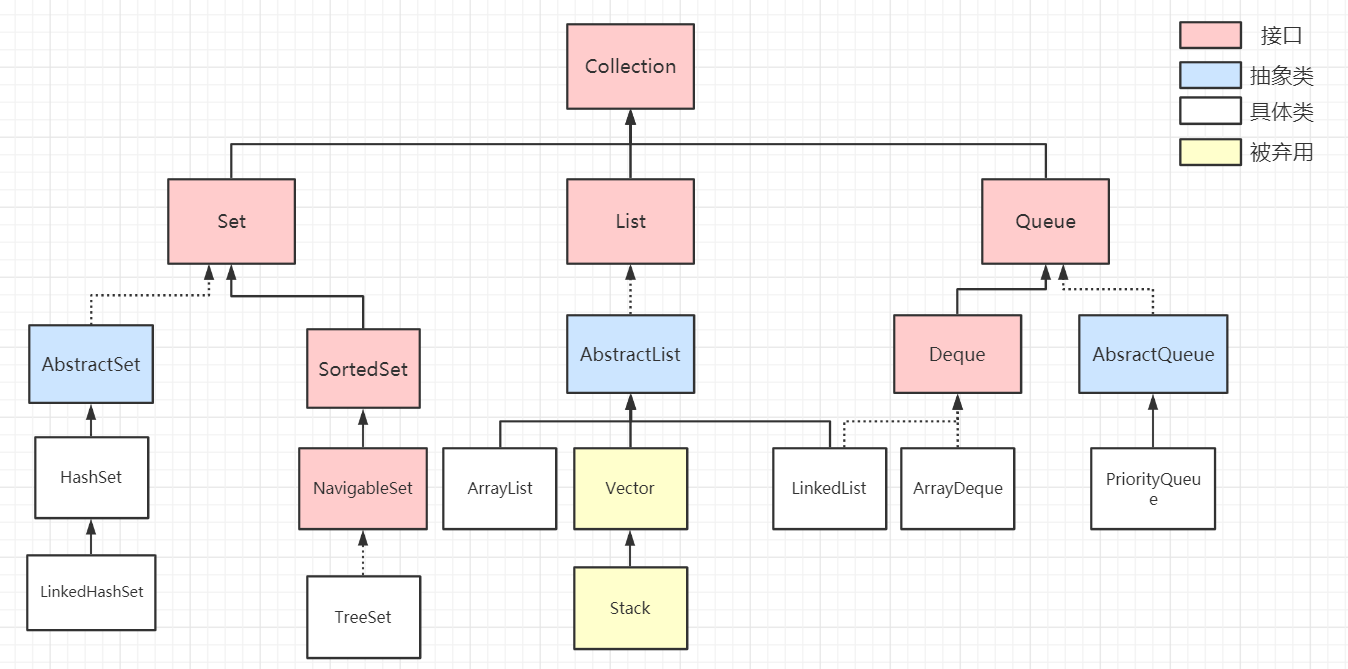
Set 接口
Set接口继承了Collection接口,是一个不包括重复元素的集合,更确切地说,Set 中任意两个元素不会出现 o1.equals(o2),而且 Set 至多只能存储一个 NULL 值元素,Set 集合的组成部分可以用下面这张图概括:
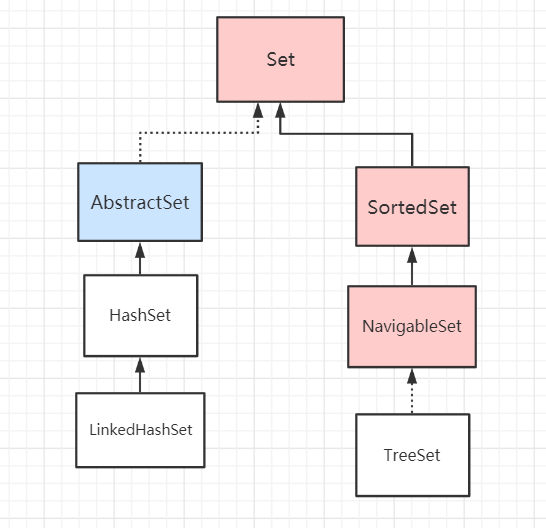
在 Set 集合体系中,我们需要着重关注两点:
存入可变元素时,必须非常小心,因为任意时候元素状态的改变都有可能使得 Set 内部出现两个相等的元素,即
o1.equals(o2) = true,所以一般不要更改存入 Set 中的元素,否则将会破坏了equals()的作用!Set 的最大作用就是判重,在项目中最大的作用也是判重!
接下来我们去看它的实现类和子类: AbstractSet 和 SortedSet
AbstractSet 抽象类
AbstractSet 是一个实现 Set 的一个抽象类,定义在这里可以将所有具体 Set 集合的相同行为在这里实现,避免子类包含大量的重复代码
所有的 Set 也应该要有相同的 hashCode() 和 equals() 方法,所以使用抽象类把该方法重写后,子类无需关心这两个方法。
SortedSet 接口
SortedSet 是一个接口,它在 Set 的基础上扩展了排序的行为,所以所有实现它的子类都会拥有排序功能。
HashSet
HashSet 底层借助 HashMap 实现,我们可以观察它的多个构造方法,本质上都是 new 一个 HashMap
public class HashSet<E> extends AbstractSet<E> implements Set<E>, Cloneable, Serializable { public HashSet() { this.map = new HashMap(); } public HashSet(int initialCapacity, float loadFactor) { this.map = new HashMap(initialCapacity, loadFactor); } public HashSet(int initialCapacity) { this.map = new HashMap(initialCapacity); } }这也是这篇文章为什么先讲解 Map 再讲解 Set 的原因!先学习 Map,有助于理解 Set
我们可以观察 add() 方法和remove()方法是如何将 HashSet 的操作嫁接到 HashMap 的。
public boolean add(E e) { return this.map.put(e, PRESENT) == null; } public boolean remove(Object o) { return this.map.remove(o) == PRESENT; }
我们看到 PRESENT 就是一个静态常量:使用 PRESENT 作为 HashMap 的 value 值,使用HashSet的开发者只需关注于需要插入的 key,屏蔽了 HashMap 的 value
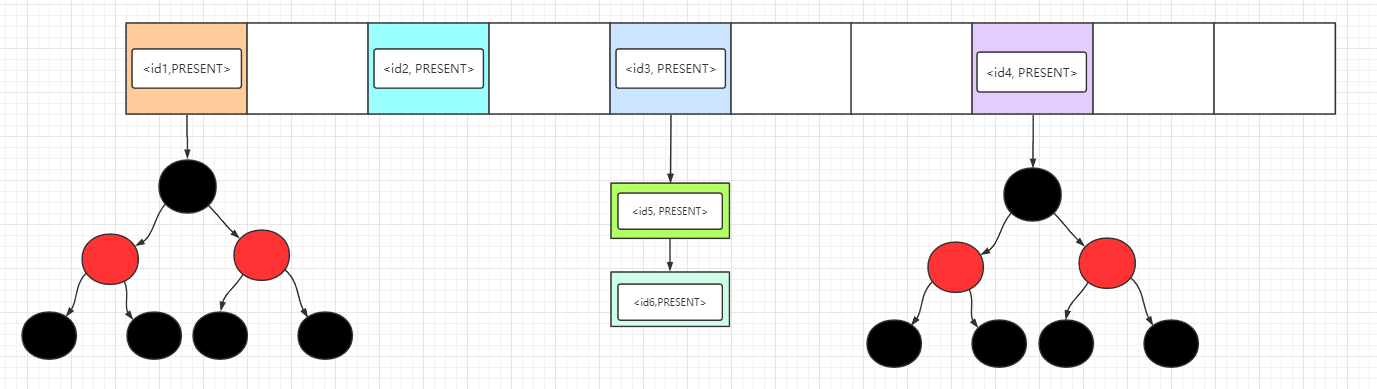
上图可以观察到每个Entry的value都是 PRESENT 空对象,我们就不用再理会它了。
HashSet 在 HashMap 基础上实现,所以很多地方可以联系到 HashMap:
- 底层数据结构:HashSet 也是采用
数组 + 链表 + 红黑树实现 - 线程安全性:由于采用 HashMap 实现,而 HashMap 本身线程不安全,在HashSet 中没有添加额外的同步策略,所以 HashSet 也线程不安全
- 存入 HashSet 的对象的状态最好不要发生变化,因为有可能改变状态后,在集合内部出现两个元素
o1.equals(o2),破坏了equals()的语义。
LinkedHashSet
LinkedHashSet 的代码少的可怜,不信我给你我粘出来
少归少,还是不能闹,LinkedHashSet继承了HashSet,我们跟随到父类 HashSet 的构造方法看看
发现父类中 map 的实现采用LinkedHashMap,这里注意不是HashMap,而 LinkedHashMap 底层又采用 HashMap + 双向链表 实现的,所以本质上 LinkedHashSet 还是使用 HashMap 实现的。
LinkedHashSet -> LinkedHashMap -> HashMap + 双向链表
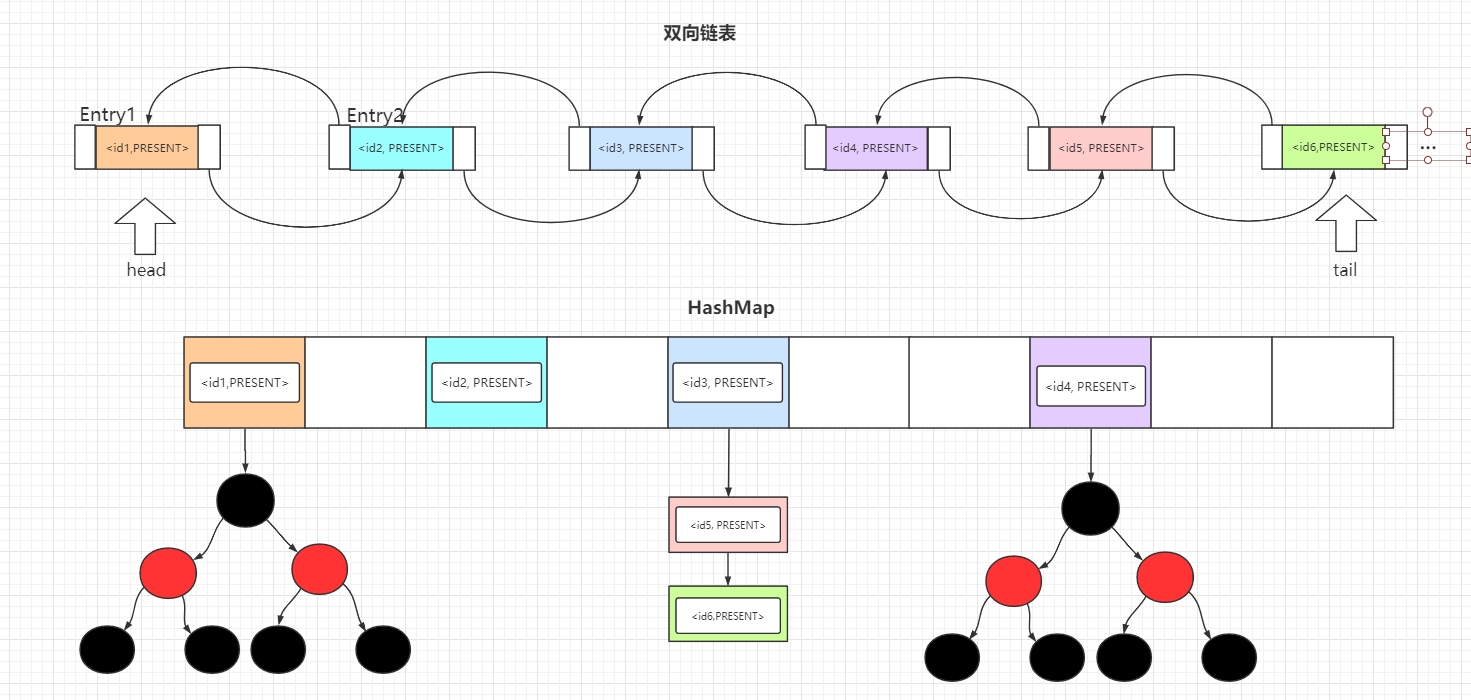
而 LinkedHashMap 是采用 HashMap和双向链表实现的,这条双向链表中保存了元素的插入顺序。所以 LinkedHashSet 可以按照元素的插入顺序遍历元素,如果你熟悉LinkedHashMap,那 LinkedHashSet 也就更不在话下了。
关于 LinkedHashSet 需要注意几个地方:
- 它继承了
HashSet,而 HashSet 默认是采用 HashMap 存储数据的,但是 LinkedHashSet 调用父类构造方法初始化 map 时是 LinkedHashMap 而不是 HashMap,这个要额外注意一下 - 由于 LinkedHashMap 不是线程安全的,且在 LinkedHashSet 中没有添加额外的同步策略,所以 LinkedHashSet 集合也不是线程安全的
TreeSet
TreeSet 是基于 TreeMap 的实现,所以存储的元素是有序的,底层的数据结构是数组 + 红黑树。
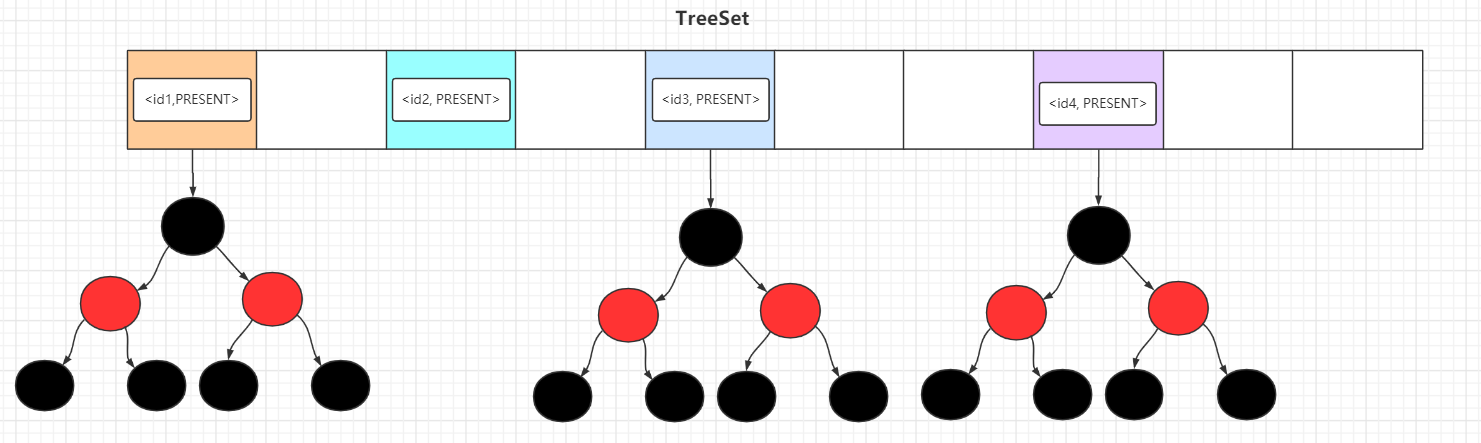
而元素的排列顺序有2种,和 TreeMap 相同:自然排序和定制排序,常用的构造方法已经在下面展示出来了,TreeSet 默认按照自然排序,如果需要定制排序,需要传入Comparator。
TreeSet 应用场景有很多,像在游戏里的玩家战斗力排行榜
public class Player implements Comparable<Integer> { public String name; public int score; @Override public int compareTo(Student o) { return Integer.compareTo(this.score, o.score); } } public static void main(String[] args) { Player s1 = new Player("张三", 100); Player s2 = new Player("李四", 90); Player s3 = new Player("王五", 80); TreeSet<Player> set = new TreeSet(); set.add(s2); set.add(s1); set.add(s3); System.out.println(set); } // [Student{name='王五', score=80}, Student{name='李四', score=90}, Student{name='张三', score=100}]对 TreeSet 介绍了它的主要实现方式和应用场景,有几个值得注意的点。
- TreeSet 的所有操作都会转换为对 TreeMap 的操作,TreeMap 采用红黑树实现,任意操作的平均时间复杂度为
O(logN) - TreeSet 是一个线程不安全的集合
- TreeSet 常应用于对不重复的元素定制排序,例如玩家战力排行榜
注意:TreeSet判断元素是否重复的方法是判断compareTo()方法是否返回0,而不是调用 hashcode() 和 equals() 方法,如果返回 0 则认为集合内已经存在相同的元素,不会再加入到集合当中。
List 接口
List 接口和 Set 接口齐头并进,是我们日常开发中接触的很多的一种集合类型了。整个 List 集合的组成部分如下图
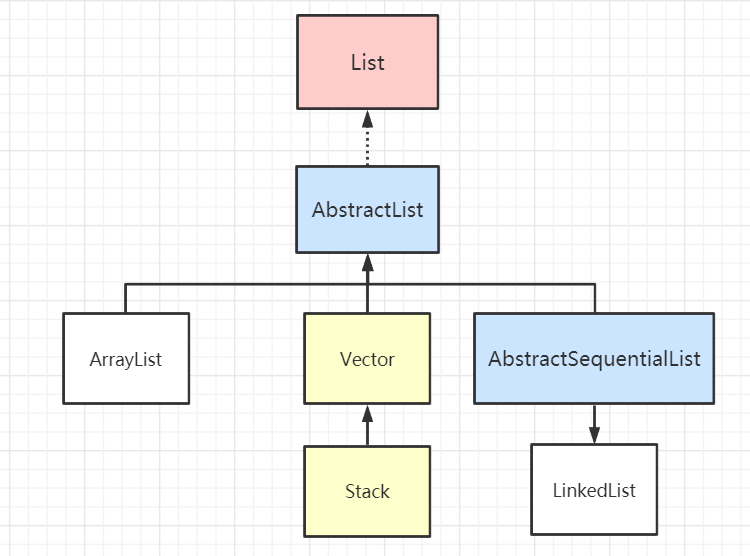
List 接口直接继承 Collection 接口,它定义为可以存储重复元素的集合,并且元素按照插入顺序有序排列,且可以通过索引访问指定位置的元素。常见的实现有:ArrayList、LinkedList、Vector和Stack
AbstractList 和 AbstractSequentialList
AbstractList 抽象类实现了 List 接口,其内部实现了所有的 List 都需具备的功能,子类可以专注于实现自己具体的操作逻辑。
// 查找元素 o 第一次出现的索引位置 public int indexOf(Object o) // 查找元素 o 最后一次出现的索引位置 public int lastIndexOf(Object o) //···AbstractSequentialList 抽象类继承了 AbstractList,在原基础上限制了访问元素的顺序只能够按照顺序访问,而不支持随机访问,如果需要满足随机访问的特性,则继承 AbstractList。子类 LinkedList 使用链表实现,所以仅能支持顺序访问,顾继承了 AbstractSequentialList而不是 AbstractList。
Vector
Vector 在现在已经是一种过时的集合了,包括继承它的 Stack 集合也如此,它们被淘汰的原因都是因为性能低下。
public synchronized boolean add(E e); public synchronized E get(int index);JDK 1.0 时代,ArrayList 还没诞生,大家都是使用 Vector 集合,但由于 Vector 的每个操作都被 synchronized 关键字修饰,即使在线程安全的情况下,仍然进行无意义的加锁与释放锁,造成额外的性能开销,做了无用功。
在 JDK 1.2 时,Collection 家族出现了,它提供了大量高性能、适用於不同场合的集合,而 Vector 也是其中一员,但由于 Vector 在每个方法上都加了锁,由于需要兼容许多老的项目,很难在此基础上优化Vector了,所以渐渐地也就被历史淘汰了。
现在,在线程安全的情况下,不需要选用 Vector 集合,取而代之的是 ArrayList 集合;在并发环境下,出现了 CopyOnWriteArrayList,Vector 完全被弃用了。
Stack
Stack是一种后入先出(LIFO)型的集合容器,如图中所示,大雄是最后一个进入容器的,top指针指向大雄,那么弹出元素时,大雄也是第一个被弹出去的。
Stack 继承了 Vector 类,提供了栈顶的压入元素操作(push)和弹出元素操作(pop),以及查看栈顶元素的方法(peek)等等,但由于继承了 Vector,正所谓跟错老大没福报,Stack 也渐渐被淘汰了。
取而代之的是后起之秀 Deque接口,其实现有 ArrayDeque,该数据结构更加完善、可靠性更好,依靠队列也可以实现LIFO的栈操作,所以优先选择 ArrayDeque 实现栈。
ArrayDeque 的数据结构是:数组,并提供头尾指针下标对数组元素进行操作。本文也会讲到哦,客官请继续往下看,莫着急!😄
ArrayList
ArrayList 以数组作为存储结构,它是线程不安全的集合;具有查询快、在数组中间或头部增删慢的特点,所以它除了线程不安全这一点,其余可以替代Vector,而且线程安全的 ArrayList 可以使用 CopyOnWriteArrayList代替 Vector。
关于 ArrayList 有几个重要的点需要注意的:
具备随机访问特点,访问元素的效率较高,ArrayList 在频繁插入、删除集合元素的场景下效率较
低。底层数据结构:ArrayList 底层使用数组作为存储结构,具备查找快、增删慢的特点
线程安全性:ArrayList 是线程不安全的集合
ArrayList 首次扩容后的长度为
10,调用add()时需要计算容器的最小容量。可以看到如果数组elementData为空数组,会将最小容量设置为10,之后会将数组长度完成首次扩容到 10。
- 集合从第二次扩容开始,数组长度将扩容为原来的
1.5倍,即:newLength = oldLength * 1.5
LinkedList
LinkedList 底层采用双向链表数据结构存储元素,由于链表的内存地址非连续,所以它不具备随机访问的特点,但由于它利用指针连接各个元素,所以插入、删除元素只需要操作指针,不需要移动元素,故具有增删快、查询慢的特点。它也是一个非线程安全的集合。
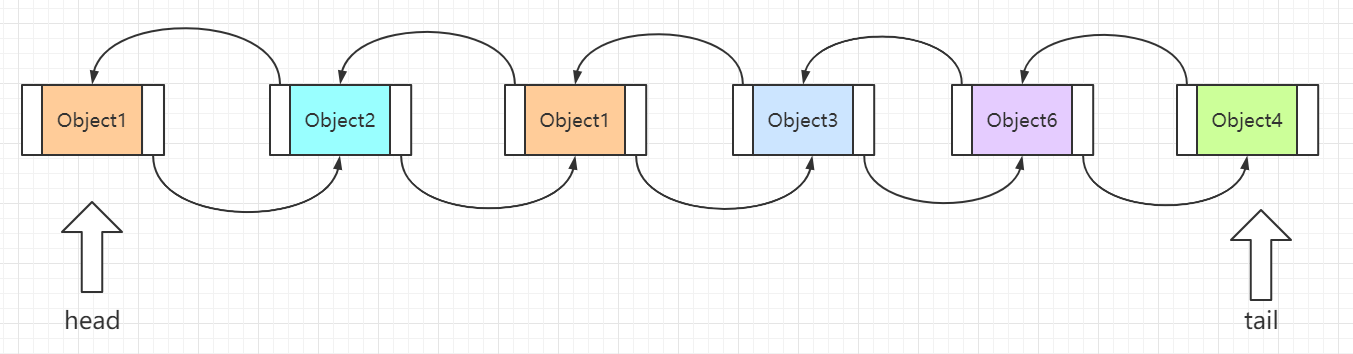
由于以双向链表作为数据结构,它是线程不安全的集合;存储的每个节点称为一个Node,下图可以看到 Node 中保存了next和prev指针,item是该节点的值。在插入和删除时,时间复杂度都保持为 O(1)
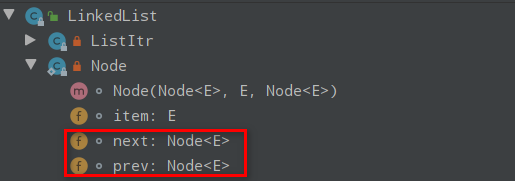
关于 LinkedList,除了它是以链表实现的集合外,还有一些特殊的特性需要注意的。
- 优势:LinkedList 底层没有
扩容机制,使用双向链表存储元素,所以插入和删除元素效率较高,适用于频繁操作元素的场景 - 劣势:LinkedList 不具备
随机访问的特点,查找某个元素只能从head或tail指针一个一个比较,所以查找中间的元素时效率很低 - 查找优化:LinkedList 查找某个下标
index的元素时做了优化,若index > (size / 2),则从head往后查找,否则从tail开始往前查找,代码如下所示:
- 双端队列:使用双端链表实现,并且实现了
Deque接口,使得 LinkedList 可以用作双端队列。下图可以看到 Node 是集合中的元素,提供了前驱指针和后继指针,还提供了一系列操作头结点和尾结点的方法,具有双端队列的特性。
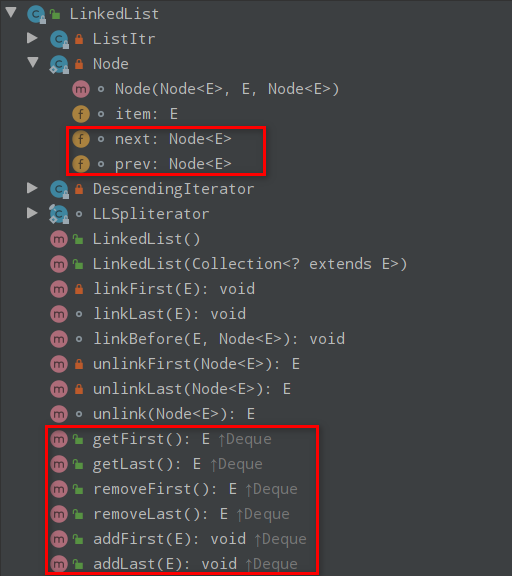
LinkedList 集合最让人树枝的是它的链表结构,但是我们同时也要注意它是一个双端队列型的集合。
Deque<Object> deque = new LinkedList<>();Queue接口
Queue队列,在 JDK 中有两种不同类型的集合实现:单向队列(AbstractQueue) 和 双端队列(Deque)
Queue 中提供了两套增加、删除元素的 API,当插入或删除元素失败时,会有两种不同的失败处理策略。
| 方法及失败策略 | 插入方法 | 删除方法 | 查找方法 |
|---|---|---|---|
| 抛出异常 | add() | remove() | get() |
| 返回失败默认值 | offer() | poll() | peek() |
选取哪种方法的决定因素:插入和删除元素失败时,希望抛出异常还是返回布尔值
add() 和 offer() 对比:
在队列长度大小确定的场景下,队列放满元素后,添加下一个元素时,add() 会抛出 IllegalStateException异常,而 offer() 会返回 false 。
但是它们两个方法在插入某些不合法的元素时都会抛出三个相同的异常。
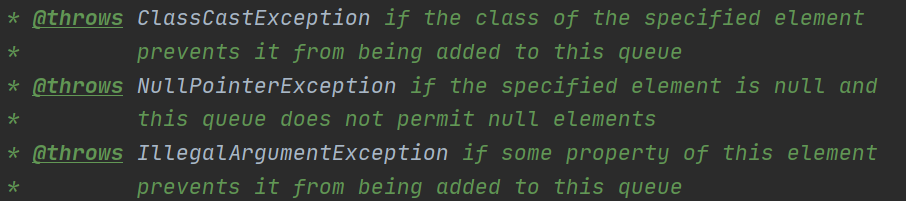
remove() 和 poll() 对比:
在队列为空的场景下, remove() 会抛出 NoSuchElementException异常,而 poll() 则返回 null 。
get()和peek()对比:
在队列为空的情况下,get()会抛出NoSuchElementException异常,而peek()则返回null。
Deque 接口
Deque 接口的实现非常好理解:从单向队列演变为双向队列,内部额外提供双向队列的操作方法即可:
Deque 接口额外提供了针对队列的头结点和尾结点操作的方法,而插入、删除方法同样也提供了两套不同的失败策略。除了add()和offer(),remove()和poll()以外,还有get()和peek()出现了不同的策略
AbstractQueue 抽象类
AbstractQueue 类中提供了各个 API 的基本实现,主要针对各个不同的处理策略给出基本的方法实现,定义在这里的作用是让子类根据其方法规范(操作失败时抛出异常还是返回默认值)实现具体的业务逻辑。
LinkedList
LinkedList 在上面已经详细解释了,它实现了 Deque 接口,提供了针对头结点和尾结点的操作,并且每个结点都有前驱和后继指针,具备了双向队列的所有特性。
ArrayDeque
使用数组实现的双端队列,它是无界的双端队列,最小的容量是8(JDK 1.8)。在 JDK 11 看到它默认容量已经是 16了。
ArrayDeque 在日常使用得不多,值得注意的是它与 LinkedList 的对比:LinkedList 采用链表实现双端队列,而 ArrayDeque 使用数组实现双端队列。
在文档中作者写到:ArrayDeque 作为栈时比 Stack 性能好,作为队列时比 LinkedList 性能好
由于双端队列只能在头部和尾部操作元素,所以删除元素和插入元素的时间复杂度大部分都稳定在 O(1) ,除非在扩容时会涉及到元素的批量复制操作。但是在大多数情况下,使用它时应该指定一个大概的数组长度,避免频繁的扩容。
个人观点:链表的插入、删除操作涉及到指针的操作,我个人认为作者是觉得数组下标的移动要比指针的操作要廉价,而且数组采用连续的内存地址空间,而链表元素的内存地址是不连续的,所以数组操作元素的效率在寻址上会比链表要快。请批判看待观点。
PriorityQueue
PriorityQueue 基于优先级堆实现的优先级队列,而堆是采用数组实现:

文档中的描述告诉我们:该数组中的元素通过传入 Comparator 进行定制排序,如果不传入Comparator时,则按照元素本身自然排序,但要求元素实现了Comparable接口,所以 PriorityQueue 不允许存储 NULL 元素。
PriorityQueue 应用场景:元素本身具有优先级,需要按照优先级处理元素
- 例如游戏中的VIP玩家与普通玩家,VIP 等级越高的玩家越先安排进入服务器玩耍,减少玩家流失。
执行上面的代码可以得到下面这种有趣的结果,可以看到氪金使人带来快乐。

VIP 等级越高(优先级越高)就越优先安排进入游戏(优先处理),类似这种有优先级的场景还有非常多,各位可以发挥自己的想象力。
PriorityQueue 总结:
PriorityQueue 是基于优先级堆实现的优先级队列,而堆是用数组维护的
PriorityQueue 适用于元素按优先级处理的业务场景,例如用户在请求人工客服需要排队时,根据用户的VIP等级进行
插队处理,等级越高,越先安排客服。
章节结束各集合总结:(以 JDK1.8 为例)
| 数据类型 | 插入、删除时间复杂度 | 查询时间复杂度 | 底层数据结构 | 是否线程安全 |
|---|---|---|---|---|
| Vector | O(N) | O(1) | 数组 | 是(已淘汰) |
| ArrayList | O(N) | O(1) | 数组 | 否 |
| LinkedList | O(1) | O(N) | 双向链表 | 否 |
| HashSet | O(1) | O(1) | 数组+链表+红黑树 | 否 |
| TreeSet | O(logN) | O(logN) | 红黑树 | 否 |
| LinkedHashSet | O(1) | O(1)~O(N) | 数组 + 链表 + 红黑树 | 否 |
| ArrayDeque | O(N) | O(1) | 数组 | 否 |
| PriorityQueue | O(logN) | O(logN) | 堆(数组实现) | 否 |
| HashMap | O(1) ~ O(N) | O(1) ~ O(N) | 数组+链表+红黑树 | 否 |
| TreeMap | O(logN) | O(logN) | 数组+红黑树 | 否 |
| HashTable | O(1) / O(N) | O(1) / O(N) | 数组+链表 | 是(已淘汰) |
文末总结
这一篇文章对各个集合都有些点到即止的味道,此文的目的是对整个集合框架有一个较为整体的了解,分析了最常用的集合的相关特性,以及某些特殊集合的应用场景例如TreeSet、TreeMap这种可定制排序的集合。
Collection接口提供了整个集合框架最通用的增删改查以及集合自身操作的抽象方法,让子类去实现Set接口决定了它的子类都是无序、无重复元素的集合,其主要实现有HashSet、TreeSet、LinkedHashSet。HashSet底层采用HashMap实现,而TreeSet底层使用TreeMap实现,大部分 Set 集合的操作都会转换为 Map 的操作,TreeSet 可以将元素按照规则进行排序。
List接口决定了它的子类都是有序、可存储重复元素的集合,常见的实现有 ArrayList,LinkedList,VectorArrayList使用数组实现,而 LinkedList 使用链表实现,所以它们两个的使用场景几乎是相反的,频繁查询的场景使用 ArrayList,而频繁插入删除的场景最好使用 LinkedListLinkedList和ArrayDeque都可用于双端队列,而 Josh Bloch and Doug Lea 认为ArrayDeque具有比LinkedList更好的性能,ArrayDeque使用数组实现双端队列,LinkedList使用链表实现双端队列。
Queue接口定义了队列的基本操作,子类集合都会拥有队列的特性:先进先出,主要实现有:LinkedList,ArrayDequePriorityQueue底层使用二叉堆维护的优先级队列,而二叉堆是由数组实现的,它可以按照元素的优先级进行排序,优先级越高的元素,排在队列前面,优先被弹出处理。
Map接口定义了该种集合类型是以<key,value>键值对形式保存,其主要实现有:HashMap,TreeMap,LinkedHashMap,Hashtable- LinkedHashMap 底层多加了一条双向链表,设置
accessOrder为true并重写方法则可以实现LRU缓存 - TreeMap 底层采用数组+红黑树实现,集合内的元素默认按照自然排序,也可以传入
Comparator定制排序
- LinkedHashMap 底层多加了一条双向链表,设置
看到这里非常不容易,感谢你愿意阅读我的文章,希望能对你有所帮助,你可以参考着文末总结的顺序,每当我提到一个集合时,回想它的重要知识点是什么,主要就是底层数据结构,线程安全性,该集合的一两个特有性质,只要能够回答出来个大概,我相信之后运用这些数据结构,你能够熟能生巧。
本文对整个集合体系的所有常用的集合类都分析了,这里并没有对集合内部的实现深入剖析,我想先从最宏观的角度让大家了解每个集合的的作用,应用场景,以及简单的对比,之后会抽时间对常见的集合进行源码剖析,尽情期待,感谢阅读!
最后有些话想说:这篇文章花了我半个月去写,也是意义重大,多谢
cxuan哥一直指导我写文章,一步一步地去打磨出一篇好的文章真的非常不容易,写下的每一个字都能够让别人看得懂是一件非常难的事情,总结出最精华的知识分享给你们也是非常难的一件事情,希望能够一直进步下去!不忘初心,热爱分享,喜爱写作。
# Java中的语法糖,真甜-Java面试题
我们在日常开发中经常会使用到诸如泛型、自动拆箱和装箱、内部类、增强 for 循环、try-with-resources 语法、lambda 表达式等,我们只觉得用的很爽,因为这些特性能够帮助我们减轻开发工作量;但我们未曾认真研究过这些特性的本质是什么,那么这篇文章,cxuan 就来为你揭开这些特性背后的真相。
语法糖
在聊之前我们需要先了解一下 语法糖 的概念:语法糖(Syntactic sugar),也叫做糖衣语法,是英国科学家发明的一个术语,通常来说使用语法糖能够增加程序的可读性,从而减少程序代码出错的机会,真是又香又甜。
语法糖指的是计算机语言中添加的某种语法,这种语法对语言的功能并没有影响,但是更方便程序员使用。因为 Java 代码需要运行在 JVM 中,JVM 是并不支持语法糖的,语法糖在程序编译阶段就会被还原成简单的基础语法结构,这个过程就是解语法糖。所以在 Java 中,真正支持语法糖的是 Java 编译器,真是换汤不换药,万变不离其宗,关了灯都一样。。。。。。
下面我们就来认识一下 Java 中的这些语法糖
泛型
泛型是一种语法糖。在 JDK1.5 中,引入了泛型机制,但是泛型机制的本身是通过类型擦除 来实现的,在 JVM 中没有泛型,只有普通类型和普通方法,泛型类的类型参数,在编译时都会被擦除。泛型并没有自己独特的 Class类型。如下代码所示
System.out.println(aList.getClass() == bList.getClass());
List<Ineger> 和 List<String> 被认为是不同的类型,但是输出却得到了相同的结果,这是因为,泛型信息只存在于代码编译阶段,在进入 JVM 之前,与泛型相关的信息会被擦除掉,专业术语叫做类型擦除。但是,如果将一个 Integer 类型的数据放入到 List<String> 中或者将一个 String 类型的数据放在 List<Ineger> 中是不允许的。
如下图所示

无法将一个 Integer 类型的数据放在 List<String> 和无法将一个 String 类型的数据放在 List<Integer> 中是一样会编译失败。
自动拆箱和自动装箱
自动拆箱和自动装箱是一种语法糖,它说的是八种基本数据类型的包装类和其基本数据类型之间的自动转换。简单的说,拆箱就是自动将基本数据类型转换为包装器类型;装箱就是自动将包装器类型转换为基本数据类型。
我们先来了解一下基本数据类型的包装类都有哪些
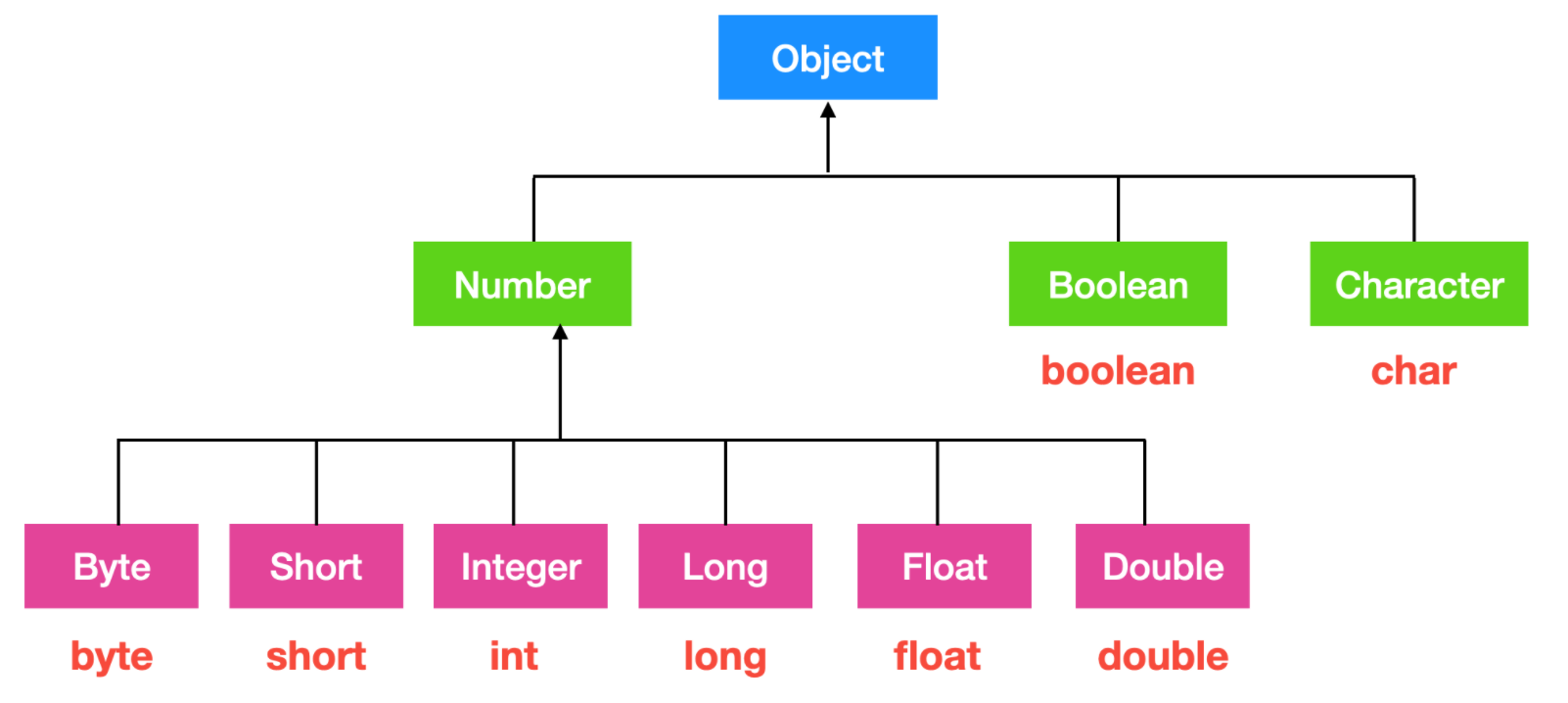
也就是说,上面这些基本数据类型和包装类在进行转换的过程中会发生自动装箱/拆箱,例如下面代码
Integer integer = 66; // 自动装箱int i1 = integer; // 自动拆箱
上面代码中的 integer 对象会使用基本数据类型来进行赋值,而基本数据类型 i1 却把它赋值给了一个对象类型,一般情况下是不能这样操作的,但是编译器却允许我们这么做,这其实就是一种语法糖。这种语法糖使我们方便我们进行数值运算,如果没有语法糖,在进行数值运算时,你需要先将对象转换成基本数据类型,基本数据类型同时也需要转换成包装类型才能使用其内置的方法,无疑增加了代码冗余。
那么自动拆箱和自动装箱是如何实现的呢?
其实这背后的原理是编译器做了优化。将基本类型赋值给包装类其实是调用了包装类的 valueOf() 方法创建了一个包装类再赋值给了基本类型。
而包装类赋值给基本类型就是调用了包装类的 xxxValue() 方法拿到基本数据类型后再进行赋值。
Integer i1 = new Integer(1).intValue();我们使用 javap -c 反编译一下上面的自动装箱和自动拆箱来验证一下

可以看到,在 Code 2 处调用 invokestatic 的时候,相当于是编译器自动为我们添加了一下 Integer.valueOf 方法从而把基本数据类型转换为了包装类型。
在 Code 7 处调用了 invokevirtual 的时候,相当于是编译器为我们添加了 Integer.intValue() 方法把 Integer 的值转换为了基本数据类型。
枚举
我们在日常开发中经常会使用到 enum 和 public static final ... 这类语法。那么什么时候用 enum 或者是 public static final 这类常量呢?好像都可以。
但是在 Java 字节码结构中,并没有枚举类型。枚举只是一个语法糖,在编译完成后就会被编译成一个普通的类,也是用 Class 修饰。这个类继承于 java.lang.Enum,并被 final 关键字修饰。
我们举个例子来看一下
public enum School { STUDENT, TEACHER; }这是一个 School 的枚举,里面包括两个字段,一个是 STUDENT ,一个是 TEACHER,除此之外并无其他。
下面我们使用 javap 反编译一下这个 School.class 。反编译完成之后的结果如下

从图中我们可以看到,枚举其实就是一个继承于 java.lang.Enum 类的 class 。而里面的属性 STUDENT 和 TEACHER 本质也就是 public static final 修饰的字段。这其实也是一种编译器的优化,毕竟 STUDENT 要比 public static final School STUDENT 的美观性、简洁性都要好很多。
除此之外,编译器还会为我们生成两个方法,values() 方法和 valueOf 方法,这两个方法都是编译器为我们添加的方法,通过使用 values() 方法可以获取所有的 Enum 属性值,而通过 valueOf 方法用于获取单个的属性值。
注意,Enum 的 values() 方法不属于 JDK API 的一部分,在 Java 源码中,没有 values() 方法的相关注释。
用法如下
public enum School {STUDENT("Student"),
TEACHER("Teacher");
private String name;
School(String name){
this.name = name;
}
public String getName() {
return name;
}
public static void main(String[] args) {
System.out.println(School.STUDENT.getName());
School[] values = School.values();
for(School school : values){
System.out.println("name = "+ school.getName());
}
}
}
内部类
内部类是 Java 一个小众 的特性,我之所以说小众,并不是说内部类没有用,而是我们日常开发中其实很少用到,但是翻看 JDK 源码,发现很多源码中都有内部类的构造。比如常见的 ArrayList 源码中就有一个 Itr 内部类继承于 Iterator 类;再比如 HashMap 中就构造了一个 Node 继承于 Map.Entry<K,V> 来表示 HashMap 的每一个节点。
Java 语言中之所以引入内部类,是因为有些时候一个类只想在一个类中有用,不想让其在其他地方被使用,也就是对外隐藏内部细节。
内部类其实也是一个语法糖,因为其只是一个编译时的概念,一旦编译完成,编译器就会为内部类生成一个单独的class 文件,名为 outer$innter.class。
下面我们就根据一个示例来验证一下。
public class OuterClass {private String label;
class InnerClass {
public String linkOuter(){
return label = "inner";
}
}
public static void main(String[] args) {
OuterClass outerClass = new OuterClass();
InnerClass innerClass = outerClass.new InnerClass();
System.out.println(innerClass.linkOuter());
}
}
上面这段编译后就会生成两个 class 文件,一个是 OuterClass.class ,一个是 OuterClass$InnerClass.class ,这就表明,外部类可以链接到内部类,内部类可以修改外部类的属性等。
我们来看一下内部类编译后的结果
如上图所示,内部类经过编译后的 linkOuter() 方法会生成一个指向外部类的 this 引用,这个引用就是连接外部类和内部类的引用。
变长参数
变长参数也是一个比较小众的用法,所谓变长参数,就是方法可以接受长度不定确定的参数。一般我们开发不会使用到变长参数,而且变长参数也不推荐使用,它会使我们的程序变的难以处理。但是我们有必要了解一下变长参数的特性。
其基本用法如下
public class VariableArgs {public static void printMessage(String... args){
for(String str : args){
System.out.println("str = " + str);
}
}
public static void main(String[] args) {
VariableArgs.printMessage("l","am","cxuan");
}
}
变长参数也是一种语法糖,那么它是如何实现的呢?我们可以猜测一下其内部应该是由数组构成,否则无法接受多个值,那么我们反编译看一下是不是由数组实现的。

可以看到,printMessage() 的参数就是使用了一个数组来接收,所以千万别被变长参数忽悠了!
变长参数特性是在 JDK 1.5 中引入的,使用变长参数有两个条件,一是变长的那一部分参数具有相同的类型,二是变长参数必须位于方法参数列表的最后面。
增强 for 循环
为什么有了普通的 for 循环后,还要有增强 for 循环呢?想一下,普通 for 循环你不是需要知道遍历次数?每次还需要知道数组的索引是多少,这种写法明显有些繁琐。增强 for 循环与普通 for 循环相比,功能更强并且代码更加简洁,你无需知道遍历的次数和数组的索引即可进行遍历。
增强 for 循环的对象要么是一个数组,要么实现了 Iterable 接口。这个语法糖主要用来对数组或者集合进行遍历,其在循环过程中不能改变集合的大小。
public static void main(String[] args) { String[] params = new String[]{"hello","world"}; //增强for循环对象为数组 for(String str : params){ System.out.println(str); }List<String> lists = Arrays.asList("hello","world");
//增强for循环对象实现Iterable接口
for(String str : lists){
System.out.println(str);
}
}
经过编译后的 class 文件如下
public static void main(String[] args) { String[] params = new String[]{"hello", "world"}; String[] lists = params; int var3 = params.length; //数组形式的增强for退化为普通for for(int str = 0; str < var3; ++str) { String str1 = lists[str]; System.out.println(str1); }List var6 = Arrays.asList(new String[]{"hello", "world"}); Iterator var7 = var6.iterator(); //实现Iterable接口的增强for使用iterator接口进行遍历 while(var7.hasNext()) { String var8 = (String)var7.next(); System.out.println(var8); }
}
如上代码所示,如果对数组进行增强 for 循环的话,其内部还是对数组进行遍历,只不过语法糖把你忽悠了,让你以一种更简洁的方式编写代码。
而对继承于 Iterator 迭代器进行增强 for 循环遍历的话,相当于是调用了 Iterator 的 hasNext() 和 next() 方法。
Switch 支持字符串和枚举
switch 关键字原生只能支持整数类型。如果 switch 后面是 String 类型的话,编译器会将其转换成 String 的hashCode 的值,所以其实 switch 语法比较的是 String 的 hashCode 。
如下代码所示
public class SwitchCaseTest {public static void main(String[] args) {
String str = "cxuan";
switch (str){
case "cuan":
System.out.println("cuan");
break;
case "xuan":
System.out.println("xuan");
break;
case "cxuan":
System.out.println("cxuan");
break;
default:
break;
}
}
}
我们反编译一下,看看我们的猜想是否正确
根据字节码可以看到,进行 switch 的实际是 hashcode 进行判断,然后通过使用 equals 方法进行比较,因为字符串有可能会产生哈希冲突的现象。
条件编译
这个又是让小伙伴们摸不着头脑了,什么是条件编译呢?其实,如果你用过 C 或者 C++ 你就知道可以通过预处理语句来实现条件编译。
那么什么是条件编译呢?
一般情况下,源程序中所有的行都参加编译。但有时希望对其中一部分内容只在满足一定条件下才进行编译,即对一部分内容指定编译条件,这就是 条件编译(conditional compile)。
#IFDEF DEBUUG
/* code block 1 /
#ELSE
/ code block 2 */
#ENDIF
但是在 Java 中没有预处理和宏定义这些内容,那么我们想实现条件编译,应该怎样做呢?
使用 final + if 的组合就可以实现条件编译了。如下代码所示
public static void main(String[] args) {final boolean DEBUG = true;
if (DEBUG) {
System.out.println("Hello, world!");
} else { System.out.println("nothing"); } }
这段代码会发生什么?我们反编译看一下

我们可以看到,我们明明是使用了 if …else 语句,但是编译器却只为我们编译了 DEBUG = true 的条件,
所以,Java 语法的条件编译,是通过判断条件为常量的 if 语句实现的,编译器不会为我们编译分支为 false 的代码。
断言
你在 Java 中使用过断言作为日常的判断条件吗?
断言:也就是所谓的 assert 关键字,是 jdk 1.4 后加入的新功能。它主要使用在代码开发和测试时期,用于对某些关键数据的判断,如果这个关键数据不是你程序所预期的数据,程序就提出警告或退出。当软件正式发布后,可以取消断言部分的代码。它也是一个语法糖吗?现在我不告诉你,我们先来看一下 assert 如何使用。
static int i = 5;
public static void main(String[] args) {
assert i == 5;
System.out.println("如果断言正常,我就被打印");
}
如果要开启断言检查,则需要用开关 -enableassertions 或 -ea 来开启。其实断言的底层实现就是 if 判断,如果断言结果为 true,则什么都不做,程序继续执行,如果断言结果为 false,则程序抛出 AssertError 来打断程序的执行。
assert 断言就是通过对布尔标志位进行了一个 if 判断。
try-with-resources
JDK 1.7 开始,java引入了 try-with-resources 声明,将 try-catch-finally 简化为 try-catch,这其实是一种语法糖,在编译时会进行转化为 try-catch-finally 语句。新的声明包含三部分:try-with-resources 声明、try 块、catch 块。它要求在 try-with-resources 声明中定义的变量实现了 AutoCloseable 接口,这样在系统可以自动调用它们的 close 方法,从而替代了 finally 中关闭资源的功能。
如下代码所示
public class TryWithResourcesTest {public static void main(String[] args) {
try(InputStream inputStream = new FileInputStream(new File("xxx"))) {
inputStream.read();
}catch (Exception e){
e.printStackTrace();
}
}
}
我们可以看一下 try-with-resources 反编译之后的代码

可以看到,生成的 try-with-resources 经过编译后还是使用的 try…catch…finally 语句,只不过这部分工作由编译器替我们做了,这样能让我们的代码更加简洁,从而消除样板代码。
字符串相加
这个想必大家应该都知道,字符串的拼接有两种,如果能够在编译时期确定拼接的结果,那么使用 + 号连接的字符串会被编译器直接优化为相加的结果,如果编译期不能确定拼接的结果,底层会直接使用 StringBuilder 的 append 进行拼接,如下图所示。
public static void main(String[] args) {
String s1 = "I am " + "cxuan";
String s2 = "I am " + new String("cxuan");
String s3 = "I am ";
String s4 = "cxuan";
String s5 = s3 + s4;
}
}
上面这段代码就包含了两种字符串拼接的结果,我们反编译看一下
首先来看一下 s1 ,s1 因为 = 号右边是两个常量,所以两个字符串拼接会被直接优化成为 I am cxuan。而 s2 由于在堆空间中分配了一个 cxuan 对象,所以 + 号两边进行字符串拼接会直接转换为 StringBuilder ,调用其 append 方法进行拼接,最后再调用 toString() 方法转换成字符串。
而由于 s5 进行拼接的两个对象在编译期不能判定其拼接结果,所以会直接使用 StringBuilder 进行拼接。
学习语法糖的意义
互联网时代,有很多标新立异的想法和框架层出不穷,但是,我们对于学习来说应该抓住技术的核心。然而,软件工程是一门协作的艺术,对于工程来说如何提高工程质量,如何提高工程效率也是我们要关注的,既然这些语法糖能辅助我们以更好的方式编写备受欢迎的代码,我们程序员为什么要 抵制 呢?
语法糖也是一种进步,这就和你写作文似的,大白话能把故事讲明白的它就没有语言优美、酣畅淋漓的把故事讲生动的更令人喜欢。
我们要在敞开怀抱拥抱变化的同时也要掌握其 屠龙之技。
# 看完这篇HashMap,和面试官扯皮就没问题了-Java面试题
- 看完这篇 HashMap,和面试官扯皮就没问题了
HashMap 概述
如果你没有时间细抠本文,可以直接看 HashMap 概述,能让你对 HashMap 有个大致的了解。
HashMap 是 Map 接口的实现,HashMap 允许空的 key-value 键值对,HashMap 被认为是 Hashtable 的增强版,HashMap 是一个非线程安全的容器,如果想构造线程安全的 Map 考虑使用 ConcurrentHashMap。HashMap 是无序的,因为 HashMap 无法保证内部存储的键值对的有序性。
HashMap 的底层数据结构是数组 + 链表的集合体,数组在 HashMap 中又被称为桶(bucket)。遍历 HashMap 需要的时间损耗为 HashMap 实例桶的数量 + (key – value 映射) 的数量。因此,如果遍历元素很重要的话,不要把初始容量设置的太高或者负载因子设置的太低。
HashMap 实例有两个很重要的因素,初始容量和负载因子,初始容量指的就是 hash 表桶的数量,负载因子是一种衡量哈希表填充程度的标准,当哈希表中存在足够数量的 entry,以至于超过了负载因子和当前容量,这个哈希表会进行 rehash 操作,内部的数据结构重新 rebuilt。
注意 HashMap 不是线程安全的,如果多个线程同时影响了 HashMap ,并且至少一个线程修改了 HashMap 的结构,那么必须对 HashMap 进行同步操作。可以使用 Collections.synchronizedMap(new HashMap) 来创建一个线程安全的 Map。
HashMap 会导致除了迭代器本身的 remove 外,外部 remove 方法都可能会导致 fail-fast 机制,因此尽量要用迭代器自己的 remove 方法。如果在迭代器创建的过程中修改了 map 的结构,就会抛出 ConcurrentModificationException 异常。
下面就来聊一聊 HashMap 的细节问题。我们还是从面试题入手来分析 HashMap 。
HashMap 和 HashTable 的区别
我们上面介绍了一下 HashMap ,现在来介绍一下 HashTable
相同点
HashMap 和 HashTable 都是基于哈希表实现的,其内部每个元素都是 key-value 键值对,HashMap 和 HashTable 都实现了 Map、Cloneable、Serializable 接口。
不同点
父类不同:HashMap 继承了
AbstractMap类,而 HashTable 继承了Dictionary类

空值不同:HashMap 允许空的 key 和 value 值,HashTable 不允许空的 key 和 value 值。HashMap 会把 Null key 当做普通的 key 对待。不允许 null key 重复。
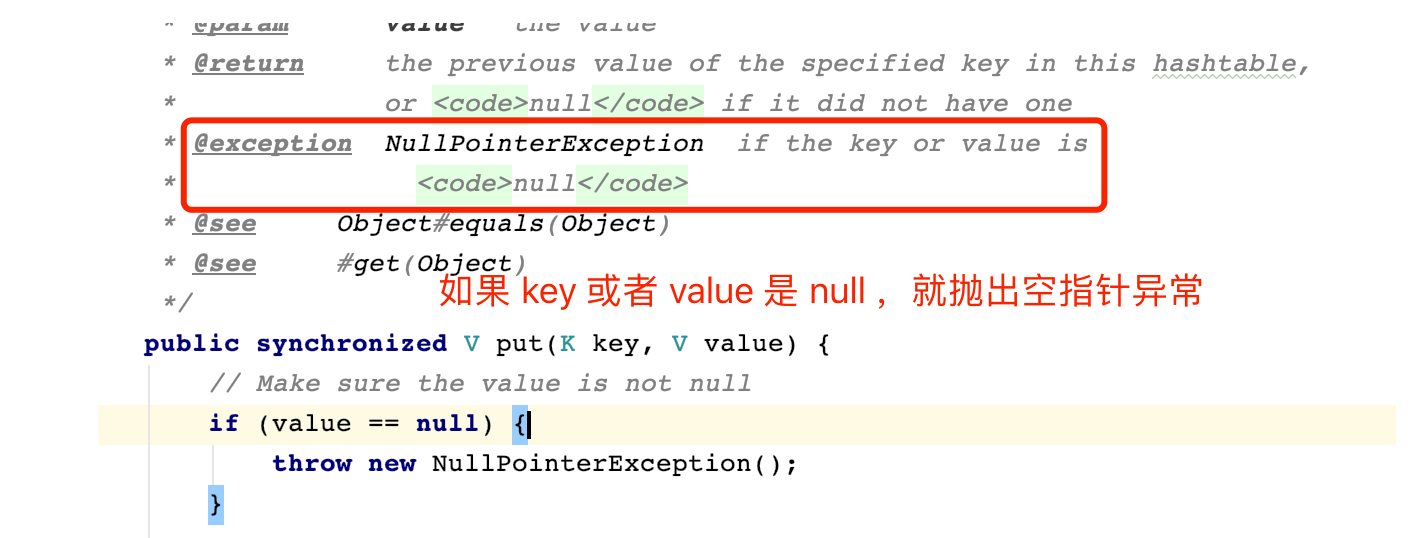
线程安全性:HashMap 不是线程安全的,如果多个外部操作同时修改 HashMap 的数据结构比如 add 或者是 delete,必须进行同步操作,仅仅对 key 或者 value 的修改不是改变数据结构的操作。可以选择构造线程安全的 Map 比如
Collections.synchronizedMap或者是ConcurrentHashMap。而 HashTable 本身就是线程安全的容器。性能方面:虽然 HashMap 和 HashTable 都是基于单链表的,但是 HashMap 进行 put 或者 get 操作,可以达到常数时间的性能;而 HashTable 的 put 和 get 操作都是加了
synchronized锁的,所以效率很差。

初始容量不同:HashTable 的初始长度是11,之后每次扩充容量变为之前的 2n+1(n为上一次的长度)
而 HashMap 的初始长度为16,之后每次扩充变为原来的两倍。创建时,如果给定了容量初始值,那么HashTable 会直接使用你给定的大小,而 HashMap 会将其扩充为2的幂次方大小。
HashMap 和 HashSet 的区别
也经常会问到 HashMap 和 HashSet 的区别
HashSet 继承于 AbstractSet 接口,实现了 Set、Cloneable,、java.io.Serializable 接口。HashSet 不允许集合中出现重复的值。HashSet 底层其实就是 HashMap,所有对 HashSet 的操作其实就是对 HashMap 的操作。所以 HashSet 也不保证集合的顺序。
HashMap 底层结构
要了解一个类,先要了解这个类的结构,先来看一下 HashMap 的结构:
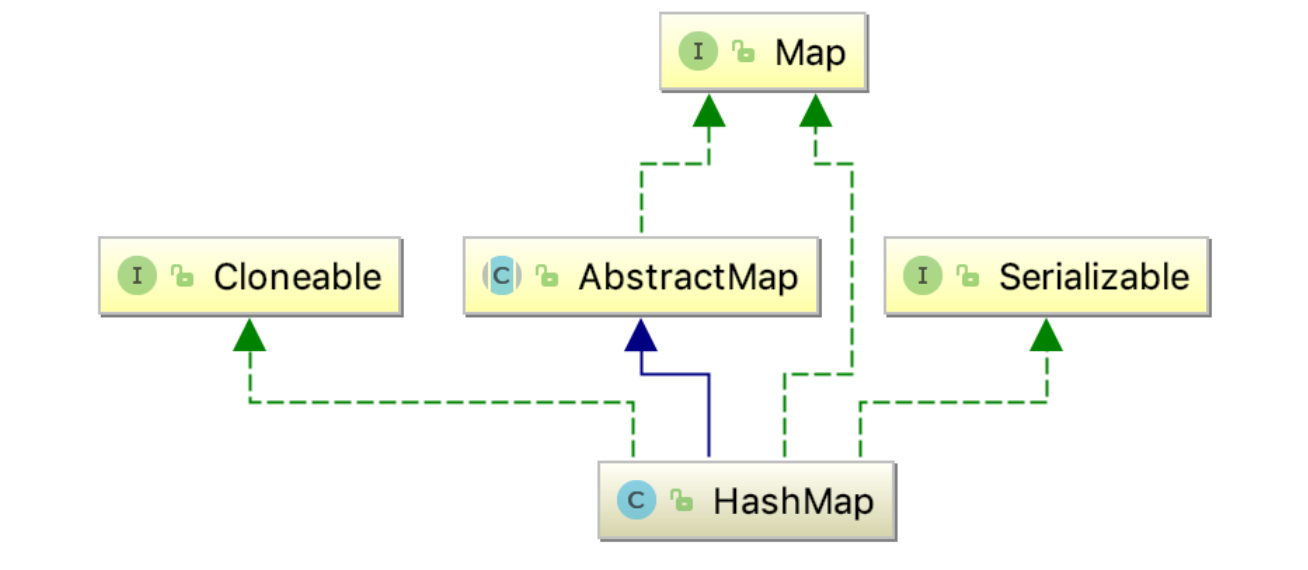
最主要的三个类(接口)就是 HashMap,AbstractMap和 Map 了,HashMap 我们上面已经在概述中简单介绍了一下,下面来介绍一下 AbstractMap。
AbstractMap 类
这个抽象类是 Map 接口的骨干实现,以求最大化的减少实现类的工作量。为了实现不可修改的 map,程序员仅需要继承这个类并且提供 entrySet 方法的实现即可。它将会返回一组 map 映射的某一段。通常,返回的集合将在AbstractSet 之上实现。这个set不应该支持 add 或者 remove 方法,并且它的迭代器也不支持 remove 方法。
为了实现可修改的 map,程序员必须额外重写这个类的 put 方法(否则就会抛出UnsupportedOperationException),并且 entrySet.iterator() 返回的 iterator 必须实现 remove() 方法。
Map 接口
Map 接口定义了 key-value 键值对的标准。一个对象支持 key-value 存储。Map不能包含重复的 key,每个键最多映射一个值。这个接口代替了Dictionary 类,Dictionary是一个抽象类而不是接口。
Map 接口提供了三个集合的构造器,它允许将 map 的内容视为一组键,值集合或一组键值映射。map的顺序定义为map映射集合上的迭代器返回其元素的顺序。一些map实现,像是TreeMap类,保证了map的有序性;其他的实现,像是HashMap,则没有保证。
重要内部类和接口
Node 接口
Node节点是用来存储HashMap的一个个实例,它实现了 Map.Entry接口,我们先来看一下 Map中的内部接口 Entry 接口的定义
Map.Entry
// 一个map 的entry 链,这个Map.entrySet()方法返回一个集合的视图,包含类中的元素, // 这个唯一的方式是从集合的视图进行迭代,获取一个map的entry链。这些Map.Entry链只在 // 迭代期间有效。 interface Entry<K,V> { K getKey(); V getValue(); V setValue(V value); boolean equals(Object o); int hashCode(); }Node 节点会存储四个属性,hash值,key,value,指向下一个Node节点的引用
// hash值 final int hash; // 键 final K key; // 值 V value; // 指向下一个Node节点的Node类型 Node<K,V> next;因为Map.Entry 是一条条entry 链连接在一起的,所以Node节点也是一条条entry链。构造一个新的HashMap实例的时候,会把这四个属性值分为传入
Node(int hash, K key, V value, Node<K,V> next) { this.hash = hash; this.key = key; this.value = value; this.next = next; }实现了 Map.Entry 接口所以必须实现其中的方法,所以 Node 节点中也包括上面的五个方法
KeySet 内部类
keySet 类继承于 AbstractSet 抽象类,它是由 HashMap 中的 keyset() 方法来创建 KeySet 实例的,旨在对HashMap 中的key键进行操作,看一个代码示例

图中把1, 2, 3这三个key 放在了HashMap中,然后使用 lambda 表达式循环遍历 key 值,可以看到,map.keySet() 其实是返回了一个 Set 接口,KeySet() 是在 Map 接口中进行定义的,不过是被HashMap 进行了实现操作,来看一下源码就明白了
// 返回一个set视图,这个视图中包含了map中的key。 public Set<K> keySet() { // // keySet 指向的是 AbstractMap 中的 keyset Set<K> ks = keySet; if (ks == null) { // 如果 ks 为空,就创建一个 KeySet 对象 // 并对 ks 赋值。 ks = new KeySet(); keySet = ks; } return ks; }所以 KeySet 类中都是对 Map中的 Key 进行操作的:
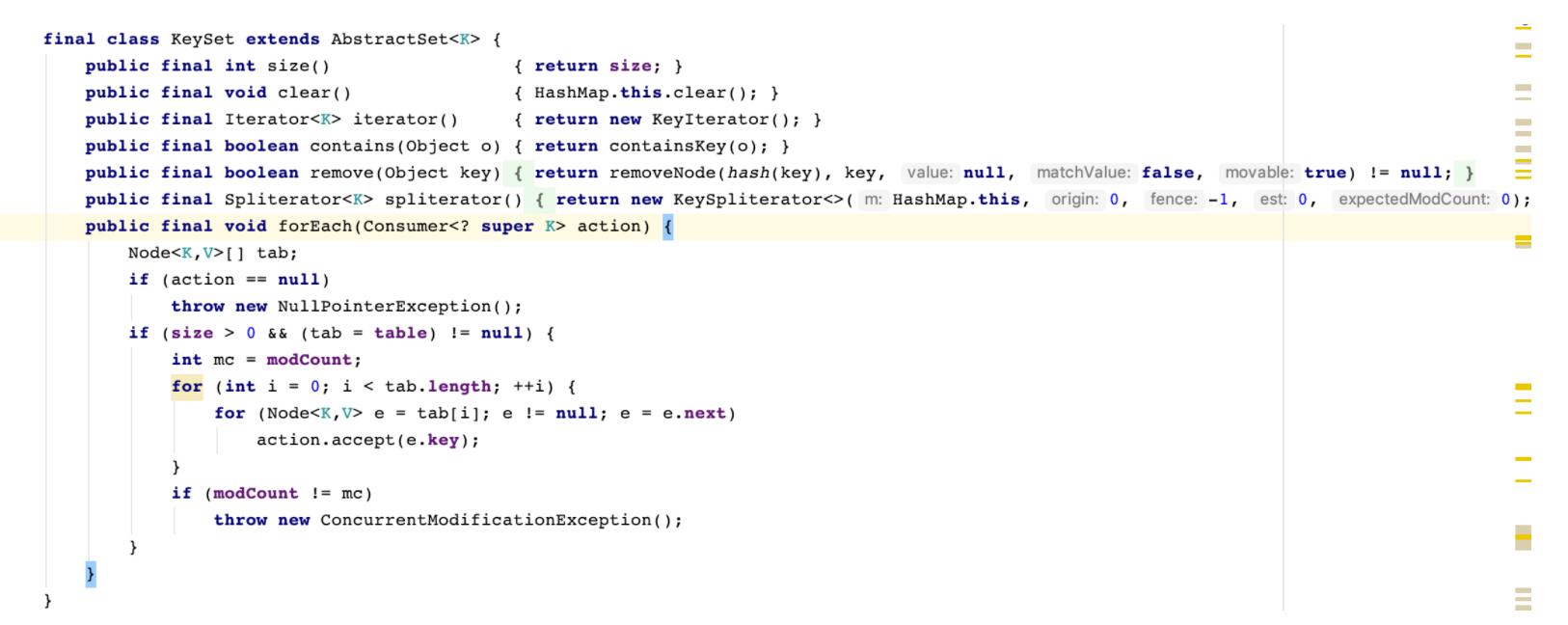
Values 内部类
Values 类的创建其实是和 KeySet 类很相似,不过 KeySet 旨在对 Map中的键进行操作,Values 旨在对key-value 键值对中的 value 值进行使用,看一下代码示例:

循环遍历 Map中的 values值,看一下 values() 方法最终创建的是什么:
public Collection<V> values() { // values 其实是 AbstractMap 中的 values Collection<V> vs = values; if (vs == null) { vs = new Values(); values = vs; } return vs; }所有的 values 其实都存储在 AbstractMap 中,而 Values 类其实也是实现了 Map 中的 Values 接口,看一下对 values 的操作都有哪些方法
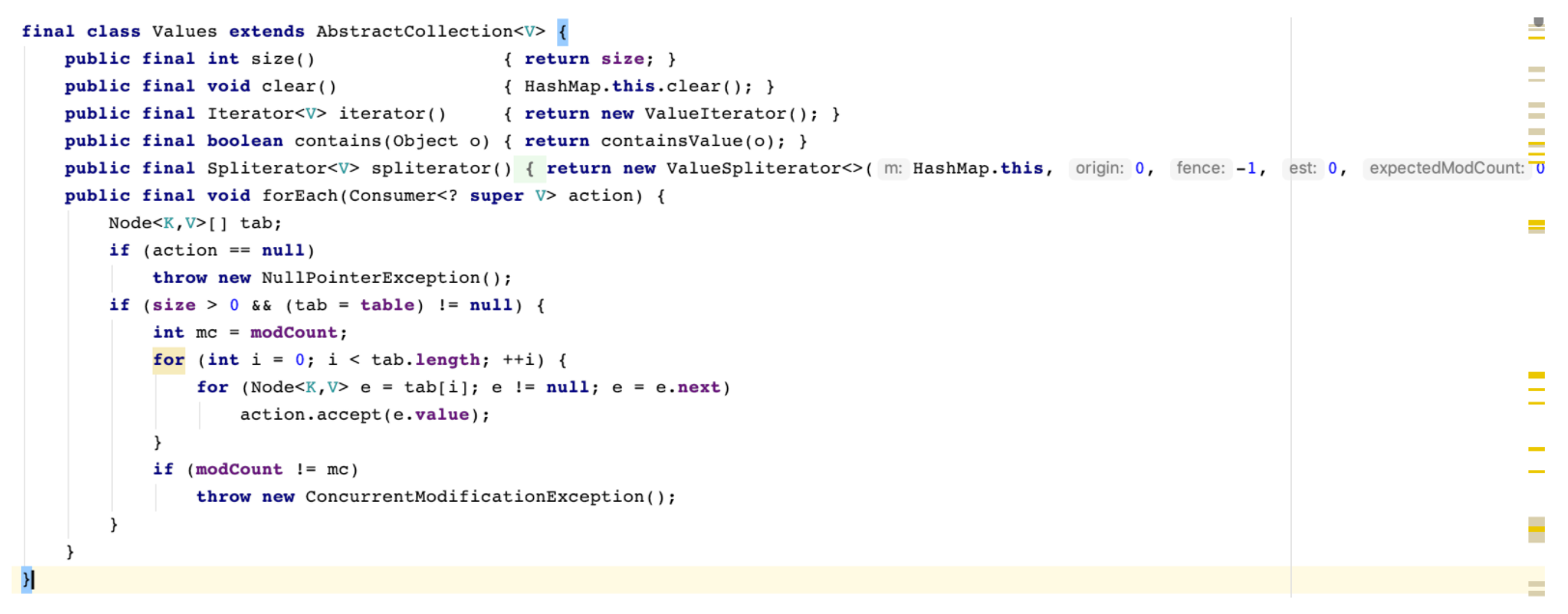
其实是和 key 的操作差不多
EntrySet 内部类
上面提到了HashMap中分别有对 key、value 进行操作的,其实还有对 key-value 键值对进行操作的内部类,它就是 EntrySet,来看一下EntrySet 的创建过程:

点进去 entrySet() 会发现这个方法也是在 Map 接口中定义的,HashMap对它进行了重写
// 返回一个 set 视图,此视图包含了 map 中的key-value 键值对 public Set<Map.Entry<K,V>> entrySet() { Set<Map.Entry<K,V>> es; return (es = entrySet) == null ? (entrySet = new EntrySet()) : es; }如果 es 为空创建一个新的 EntrySet 实例,EntrySet 主要包括了对key-value 键值对映射的方法,如下

HashMap 1.7 的底层结构
JDK1.7 中,HashMap 采用位桶 + 链表的实现,即使用链表来处理冲突,同一 hash 值的链表都存储在一个数组中。但是当位于一个桶中的元素较多,即 hash 值相等的元素较多时,通过 key 值依次查找的效率较低。它的数据结构如下
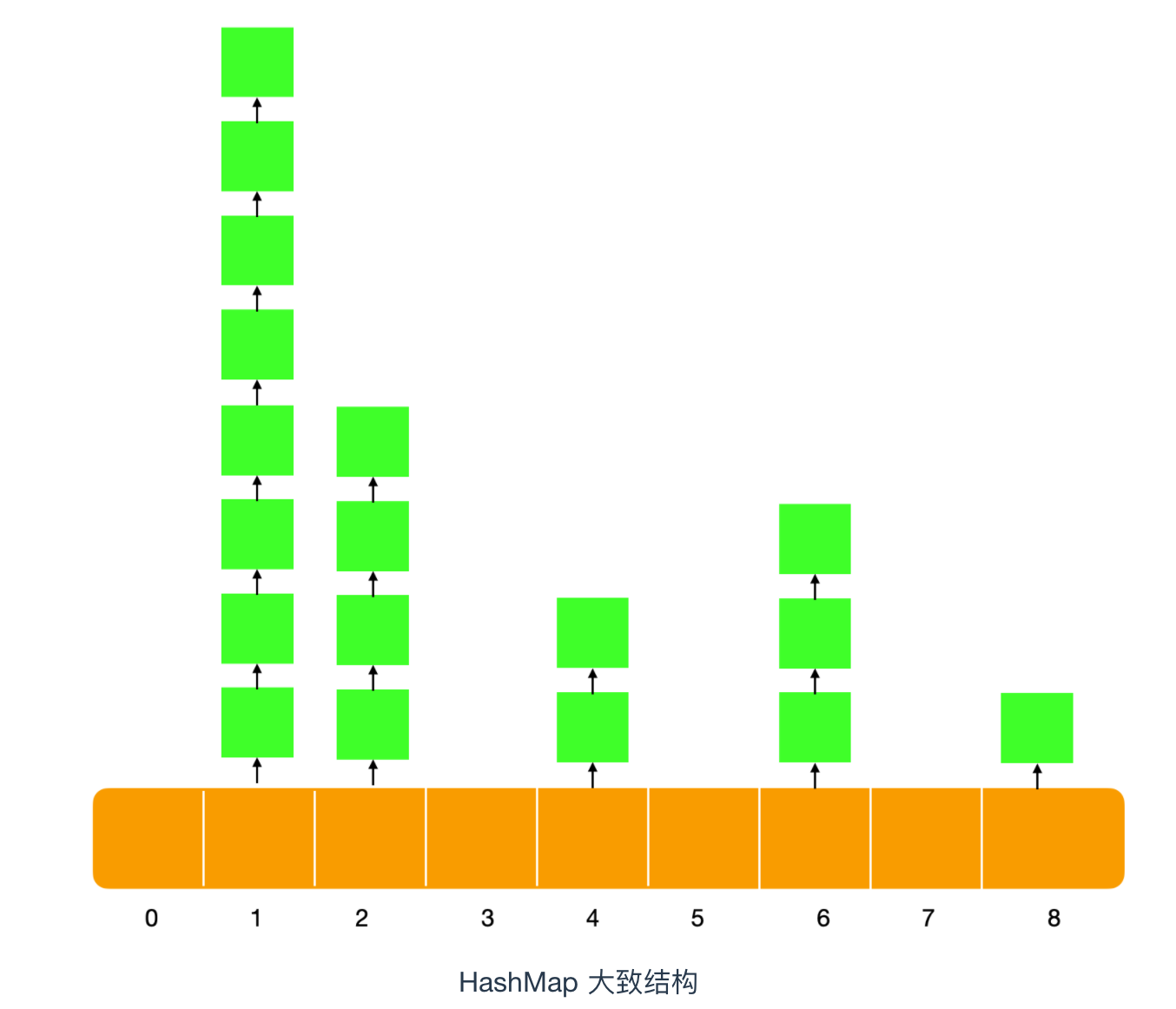
HashMap 底层数据结构就是一个 Entry 数组,Entry 是 HashMap 的基本组成单元,每个 Entry 中包含一个 key-value 键值对。
transient Entry<K,V>[] table = (Entry<K,V>[]) EMPTY_TABLE;而每个 Entry 中包含 hash, key ,value 属性,它是 HashMap 的一个内部类
static class Entry<K,V> implements Map.Entry<K,V> { final K key; V value; Entry<K,V> next; int hash;Entry(int h, K k, V v, Entry<K,V> n) { value = v; next = n; key = k; hash = h; } ... }
所以,HashMap 的整体结构就像下面这样
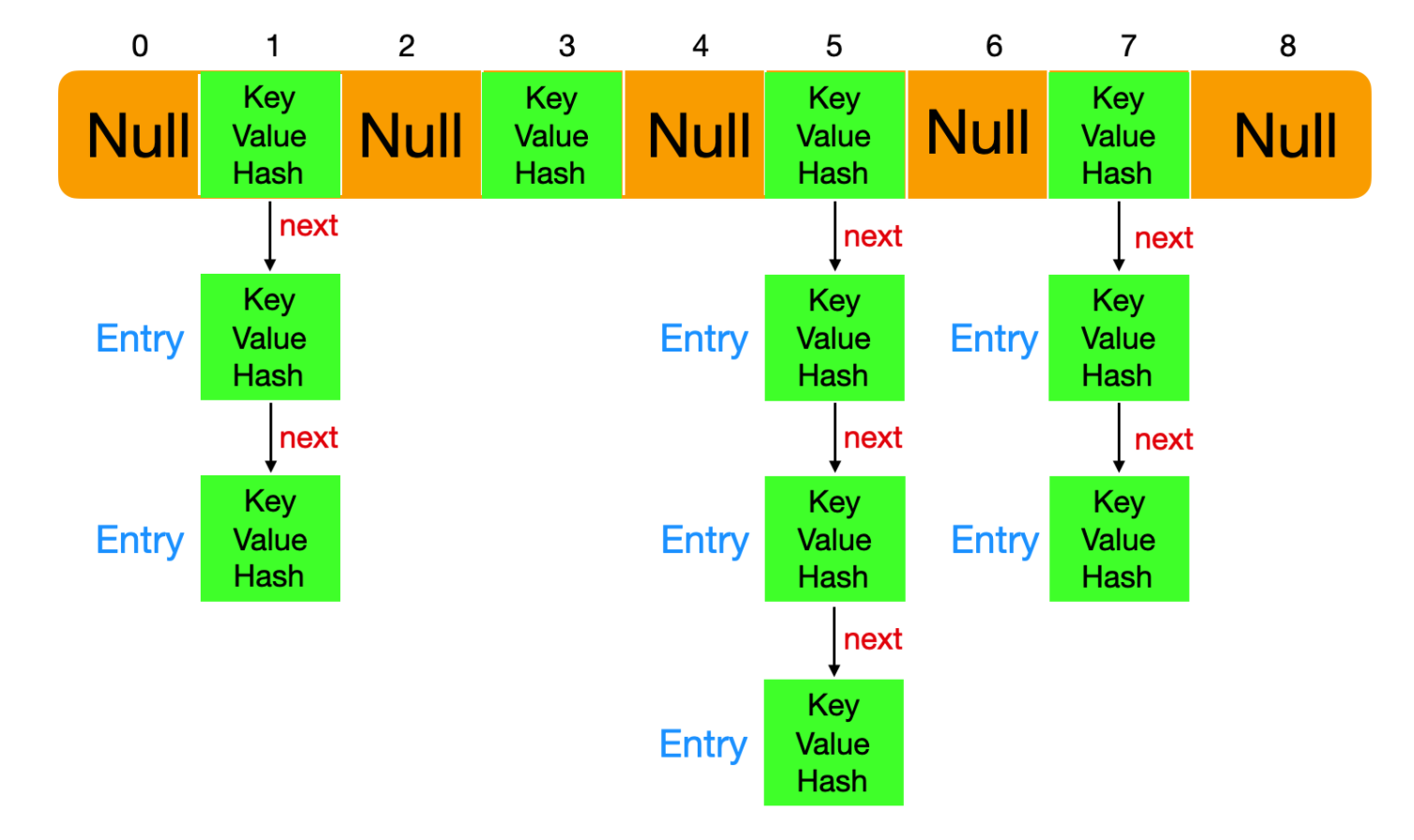
HashMap 1.8 的底层结构
与 JDK 1.7 相比,1.8 在底层结构方面做了一些改变,当每个桶中元素大于 8 的时候,会转变为红黑树,目的就是优化查询效率,JDK 1.8 重写了 resize() 方法。
HashMap 重要属性
初始容量
HashMap 的默认初始容量是由 DEFAULT_INITIAL_CAPACITY 属性管理的。
HashMaap 的默认初始容量是 1 << 4 = 16, << 是一个左移操作,它相当于是

最大容量
HashMap 的最大容量是
static final int MAXIMUM_CAPACITY = 1 << 30;这里是不是有个疑问?int 占用四个字节,按说最大容量应该是左移 31 位,为什么 HashMap 最大容量是左移 30 位呢?因为在数值计算中,最高位也就是最左位的位 是代表着符号为,0 -> 正数,1 -> 负数,容量不可能是负数,所以 HashMap 最高位只能移位到 2 ^ 30 次幂。
默认负载因子
HashMap 的默认负载因子是
static final float DEFAULT_LOAD_FACTOR = 0.75f;float 类型所以用 .f 为单位,负载因子是和扩容机制有关,这里大致提一下,后面会细说。扩容机制的原则是当 HashMap 中存储的数量 > HashMap 容量 * 负载因子时,就会把 HashMap 的容量扩大为原来的二倍。
HashMap 的第一次扩容就在 DEFAULT_INITIAL_CAPACITY * DEFAULT_LOAD_FACTOR = 12 时进行。
树化阈值
HashMap 的树化阈值是
static final int TREEIFY_THRESHOLD = 8;在进行添加元素时,当一个桶中存储元素的数量 > 8 时,会自动转换为红黑树(JDK1.8 特性)。
链表阈值
HashMap 的链表阈值是
static final int UNTREEIFY_THRESHOLD = 6;在进行删除元素时,如果一个桶中存储元素数量 < 6 后,会自动转换为链表
扩容临界值
static final int MIN_TREEIFY_CAPACITY = 64;这个值表示的是当桶数组容量小于该值时,优先进行扩容,而不是树化
节点数组
HashMap 中的节点数组就是 Entry 数组,它代表的就是 HashMap 中 数组 + 链表 数据结构中的数组。
transient Node<K,V>[] table;Node 数组在第一次使用的时候进行初始化操作,在必要的时候进行 resize,resize 后数组的长度扩容为原来的二倍。
键值对数量
在 HashMap 中,使用 size 来表示 HashMap 中键值对的数量。
修改次数
在 HashMap 中,使用 modCount 来表示修改次数,主要用于做并发修改 HashMap 时的快速失败 – fail-fast 机制。
扩容阈值
在 HashMap 中,使用 threshold 表示扩容的阈值,也就是 初始容量 * 负载因子的值。
threshold 涉及到一个扩容的阈值问题,这个问题是由 tableSizeFor 源码解决的。我们先看一下它的源码再来解释
代码中涉及一个运算符 |= ,它表示的是按位或,啥意思呢?你一定知道 a+=b 的意思是 a=a+b,那么 同理:a |= b 就是 a = a | b ,也就是双方都转换为二进制,来进行与操作。如下图所示

我们上面采用了一个比较大的数字进行扩容,由上图可知 2^29 次方的数组经过一系列的或操作后,会算出来结果是 2^30 次方。
所以扩容后的数组长度是原来的 2 倍。
负载因子
loadFactor 表示负载因子,它表示的是 HashMap 中的密集程度。
HashMap 构造函数
在 HashMap 源码中,有四种构造函数,分别来介绍一下
- 带有
初始容量 initialCapacity和负载因子 loadFactor的构造函数
初始容量不能为负,所以当传递初始容量 < 0 的时候,会直接抛出 IllegalArgumentException 异常。如果传递进来的初始容量 > 最大容量时,初始容量 = 最大容量。负载因子也不能小于 0 。然后进行数组的扩容,这个扩容机制也非常重要,我们后面进行探讨
- 只带有 initialCapacity 的构造函数
最终也会调用到上面的构造函数,不过这个默认的负载因子就是 HashMap 的默认负载因子也就是 0.75f
- 无参数的构造函数
默认的负载因子也就是 0.75f
- 带有 map 的构造函数
带有 Map 的构造函数,会直接把外部元素批量放入 HashMap 中。
讲一讲 HashMap put 的全过程
我记得刚毕业一年去北京面试,一家公司问我 HashMap put 过程的时候,我支支吾吾答不上来,后面痛下决心好好整。以 JDK 1.8 为基准进行分析,后面也是。先贴出整段代码,后面会逐行进行分析。
final V putVal(int hash, K key, V value, boolean onlyIfAbsent, boolean evict) { Node<K,V>[] tab; Node<K,V> p; int n, i; // 如果table 为null 或者没有为 table 分配内存,就resize一次 if ((tab = table) == null || (n = tab.length) == 0) n = (tab = resize()).length; // 指定hash值节点为空则直接插入,这个(n - 1) & hash才是表中真正的哈希 if ((p = tab[i = (n - 1) & hash]) == null) tab[i] = newNode(hash, key, value, null); // 如果不为空 else { Node<K,V> e; K k; // 计算表中的这个真正的哈希值与要插入的key.hash相比 if (p.hash == hash && ((k = p.key) == key || (key != null && key.equals(k)))) e = p; // 若不同的话,并且当前节点已经在 TreeNode 上了 else if (p instanceof TreeNode) // 采用红黑树存储方式 e = ((TreeNode<K,V>)p).putTreeVal(this, tab, hash, key, value); // key.hash 不同并且也不再 TreeNode 上,在链表上找到 p.next==null else { for (int binCount = 0; ; ++binCount) { if ((e = p.next) == null) { // 在表尾插入 p.next = newNode(hash, key, value, null); // 新增节点后如果节点个数到达阈值,则进入 treeifyBin() 进行再次判断 if (binCount >= TREEIFY_THRESHOLD - 1) // -1 for 1st treeifyBin(tab, hash); break; } // 如果找到了同 hash、key 的节点,那么直接退出循环 if (e.hash == hash && ((k = e.key) == key || (key != null && key.equals(k)))) break; // 更新 p 指向下一节点 p = e; } } // map中含有旧值,返回旧值 if (e != null) { // existing mapping for key V oldValue = e.value; if (!onlyIfAbsent || oldValue == null) e.value = value; afterNodeAccess(e); return oldValue; } } // map调整次数 + 1 ++modCount; // 键值对的数量达到阈值,需要扩容 if (++size > threshold) resize(); afterNodeInsertion(evict); return null; }首先看一下 putVal 方法,这个方法是 final 的,如果你自已定义 HashMap 继承的话,是不允许你自己重写 put 方法的,然后这个方法涉及五个参数
- hash -> put 放在桶中的位置,在 put 之前,会进行 hash 函数的计算。
- key -> 参数的 key 值
- value -> 参数的 value 值
- onlyIfAbsent -> 是否改变已经存在的值,也就是是否进行 value 值的替换标志
- evict -> 是否是刚创建 HashMap 的标志
在调用到 putVal 方法时,首先会进行 hash 函数计算应该插入的位置
public V put(K key, V value) { return putVal(hash(key), key, value, false, true); }哈希函数的源码如下
static final int hash(Object key) { int h; return (key == null) ? 0 : (h = key.hashCode()) ^ (h >>> 16); }首先先来理解一下 hash 函数的计算规则
Hash 函数
hash 函数会根据你传递的 key 值进行计算,首先计算 key 的 hashCode 值,然后再对 hashcode 进行无符号右移操作,最后再和 hashCode 进行异或 ^ 操作。
>>>: 无符号右移操作,它指的是 无符号右移,也叫逻辑右移,即若该数为正,则高位补0,而若该数为负数,则右移后高位同样补0 ,也就是不管是正数还是负数,右移都会在空缺位补 0 。
在得到 hash 值后,就会进行 put 过程。
首先会判断 HashMap 中的 Node 数组是否为 null,如果第一次创建 HashMap 并进行第一次插入元素,首先会进行数组的 resize,也就是重新分配,这里还涉及到一个 resize() 扩容机制源码分析,我们后面会介绍。扩容完毕后,会计算出 HashMap 的存放位置,通过使用 ( n – 1 ) & hash 进行计算得出。
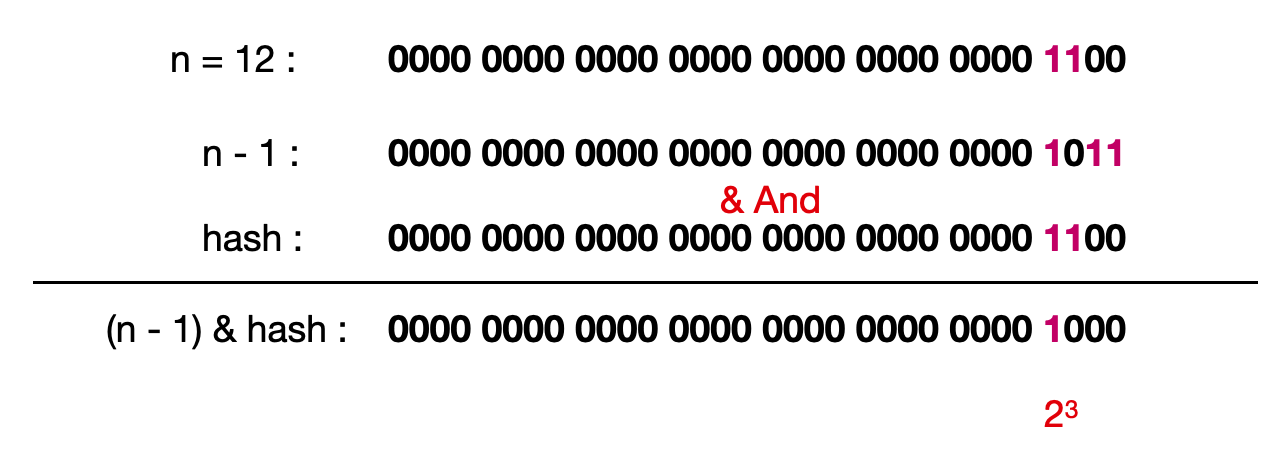
然后会把这个位置作为数组的下标作为存放元素的位置。如果不为空,那么计算表中的这个真正的哈希值与要插入的 key.hash 相比。如果哈希值相同,key-value 不一样,再判断是否是树的实例,如果是的话,那么就把它插入到树上。如果不是,就执行尾插法在 entry 链尾进行插入。
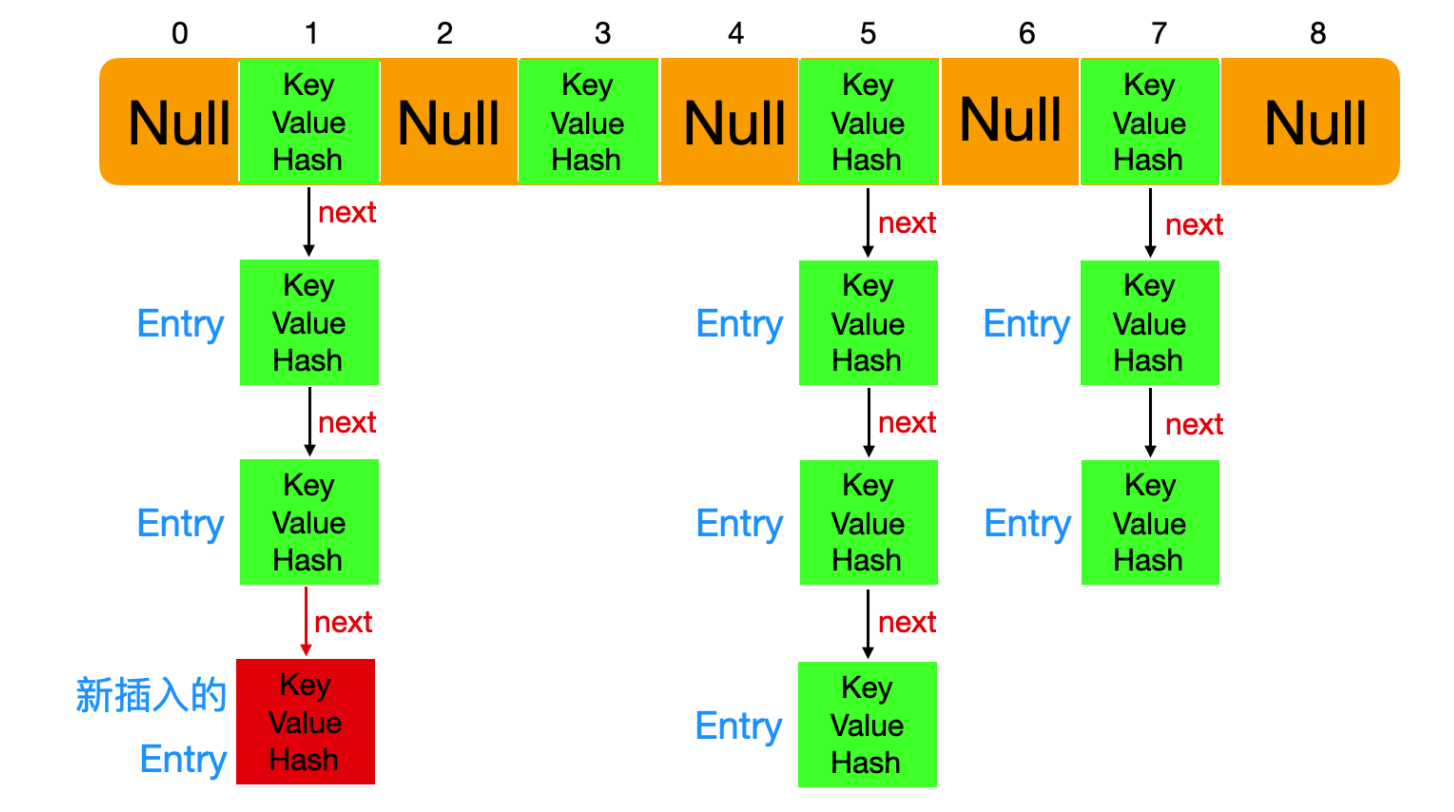
会根据桶中元素的数量判断是链表还是红黑树。然后判断键值对数量是否大于阈值,大于的话则进行扩容。
扩容机制
在 Java 中,数组的长度是固定的,这意味着数组只能存储固定量的数据。但在开发的过程中,很多时候我们无法知道该建多大的数组合适。好在 HashMap 是一种自动扩容的数据结构,在这种基于变长的数据结构中,扩容机制是非常重要的。
在 HashMap 中,阈值大小为桶数组长度与负载因子的乘积。当 HashMap 中的键值对数量超过阈值时,进行扩容。HashMap 中的扩容机制是由 resize() 方法来实现的,下面我们就来一次认识下。(贴出中文注释,便于复制)
扩容机制源码比较长,我们耐心点进行拆分
我们以 if…else if…else 逻辑进行拆分,上面代码主要做了这几个事情
- 判断 HashMap 中的数组的长度,也就是
(Node<K,V>[])oldTab.length(),再判断数组的长度是否比最大的的长度也就是 2^30 次幂要大,大的话直接取最大长度,否则利用位运算<<扩容为原来的两倍

- 如果数组长度不大于0 ,再判断扩容阈值
threshold是否大于 0 ,也就是看有无外部指定的扩容阈值,若有则使用,这里需要说明一下 threshold 何时是oldThr > 0,因为 oldThr = threshold ,这里其实比较的就是 threshold,因为 HashMap 中的每个构造方法都会调用HashMap(initCapacity,loadFactor)这个构造方法,所以如果没有外部指定 initialCapacity,初始容量使用的就是 16,然后根据this.threshold = tableSizeFor(initialCapacity);求得 threshold 的值。

- 否则,直接使用默认的初始容量和扩容阈值,走 else 的逻辑是在 table 刚刚初始化的时候。

然后会判断 newThr 是否为 0 ,笔者在刚开始研究时发现 newThr = (int)(DEFAULT_LOAD_FACTOR * DEFAULT_INITIAL_CAPACITY); 一直以为这是常量做乘法,怎么会为 0 ,其实不是这部分的问题,在于上面逻辑判断中的扩容操作,可能会导致位溢出。
导致位溢出的示例:oldCap = 2^28 次幂,threshold > 2 的三次方整数次幂。在进入到 float ft = (float)newCap * loadFactor; 这个方法是 2^28 * 2^(3+n) 会直接 > 2^31 次幂,导致全部归零。
在扩容后需要把节点放在新扩容的数组中,这里也涉及到三个步骤
循环桶中的每个 Node 节点,判断 Node[i] 是否为空,为空直接返回,不为空则遍历桶数组,并将键值对映射到新的桶数组中。
如果不为空,再判断是否是树形结构,如果是树形结构则按照树形结构进行拆分,拆分方法在
split方法中。如果不是树形结构,则遍历链表,并将链表节点按原顺序进行分组。

讲一讲 get 方法全过程
我们上面讲了 HashMap 中的 put 方法全过程,下面我们来看一下 get 方法的过程,
final Node<K,V> getNode(int hash, Object key) { Node<K,V>[] tab; Node<K,V> first, e; int n; K k;
// 找到真实的元素位置 if ((tab = table) != null && (n = tab.length) > 0 && (first = tab[(n - 1) & hash]) != null) { // 总是会check 一下第一个元素 if (first.hash == hash && // always check first node ((k = first.key) == key || (key != null && key.equals(k)))) return first;
// 如果不是第一个元素,并且下一个元素不是空的
if ((e = first.next) != null) {
// 判断是否属于 TreeNode,如果是 TreeNode 实例,直接从 TreeNode.getTreeNode 取
if (first instanceof TreeNode)
return ((TreeNode<K,V>)first).getTreeNode(hash, key);
// 如果还不是 TreeNode 实例,就直接循环数组元素,直到找到指定元素位置
do {
if (e.hash == hash &&
((k = e.key) == key || (key != null && key.equals(k))))
return e;
} while ((e = e.next) != null);
}
} return null; }
来简单介绍下吧,首先会检查 table 中的元素是否为空,然后根据 hash 算出指定 key 的位置。然后检查链表的第一个元素是否为空,如果不为空,是否匹配,如果匹配,直接返回这条记录;如果匹配,再判断下一个元素的值是否为 null,为空直接返回,如果不为空,再判断是否是 TreeNode 实例,如果是 TreeNode 实例,则直接使用 TreeNode.getTreeNode 取出元素,否则执行循环,直到下一个元素为 null 位置。
getNode 方法有一个比较重要的过程就是 (n – 1) & hash,这段代码是确定需要查找的桶的位置的,那么,为什么要 (n – 1) & hash 呢?
n 就是 HashMap 中桶的数量,这句话的意思也就是说 (n – 1) & hash 就是 (桶的容量 – 1) & hash
// 为什么 HashMap 的检索位置是 (table.size - 1) & hash public static void main(String[] args) {Map<String,Object> map = new HashMap<>();
// debug 得知 1 的 hash 值算出来是 49 map.put("1","cxuan"); // debug 得知 1 的 hash 值算出来是 50 map.put("2","cxuan"); // debug 得知 1 的 hash 值算出来是 51 map.put("3","cxuan");
}
那么每次算完之后的 (n – 1) & hash ,依次为

也就是 tab[(n – 1) & hash] 算出的具体位置。
HashMap 的遍历方式
HashMap 的遍历,也是一个使用频次特别高的操作
HashMap 遍历的基类是 HashIterator,它是一个 Hash 迭代器,它是一个 HashMap 内部的抽象类,它的构造比较简单,只有三种方法,hasNext 、 remove 和 nextNode 方法,其中 nextNode 方法是由三种迭代器实现的
这三种迭代器就就是
KeyIterator,对 key 进行遍历ValueIterator,对 value 进行遍历EntryIterator, 对 Entry 链进行遍历
虽然说看着迭代器比较多,但其实他们的遍历顺序都是一样的,构造也非常简单,都是使用 HashIterator 中的 nextNode 方法进行遍历
final class ValueIterator extends HashIterator implements Iterator<V> { public final V next() { return nextNode().value; } }
final class EntryIterator extends HashIterator implements Iterator<Map.Entry<K,V>> { public final Map.Entry<K,V> next() { return nextNode(); } }
HashIterator 中的遍历方式
abstract class HashIterator { Node<K,V> next; // 下一个 entry 节点 Node<K,V> current; // 当前 entry 节点 int expectedModCount; // fail-fast 的判断标识 int index; // 当前槽HashIterator() { expectedModCount = modCount; Node<K,V>[] t = table; current = next = null; index = 0; if (t != null && size > 0) { // advance to first entry do {} while (index < t.length && (next = t[index++]) == null); } }
public final boolean hasNext() { return next != null; }
final Node<K,V> nextNode() { Node<K,V>[] t; Node<K,V> e = next; if (modCount != expectedModCount) throw new ConcurrentModificationException(); if (e == null) throw new NoSuchElementException(); if ((next = (current = e).next) == null && (t = table) != null) { do {} while (index < t.length && (next = t[index++]) == null); } return e; }
public final void remove() {...} }
next 和 current 分别表示下一个 Node 节点和当前的 Node 节点,HashIterator 在初始化时会遍历所有的节点。下面我们用图来表示一下他们的遍历顺序
你会发现 nextNode() 方法的遍历方式和 HashIterator 的遍历方式一样,只不过判断条件不一样,构造 HashIterator 的时候判断条件是有没有链表,桶是否为 null,而遍历 nextNode 的判断条件变为下一个 node 节点是不是 null ,并且桶是不是为 null。
HashMap 中的移除方法
HashMap 中的移除方法也比较简单了,源码如下
public V remove(Object key) { Node<K,V> e; return (e = removeNode(hash(key), key, null, false, true)) == null ? null : e.value; }final Node<K,V> removeNode(int hash, Object key, Object value, boolean matchValue, boolean movable) { Node<K,V>[] tab; Node<K,V> p; int n, index; if ((tab = table) != null && (n = tab.length) > 0 && (p = tab[index = (n - 1) & hash]) != null) { Node<K,V> node = null, e; K k; V v; if (p.hash == hash && ((k = p.key) == key || (key != null && key.equals(k)))) node = p; else if ((e = p.next) != null) { if (p instanceof TreeNode) node = ((TreeNode<K,V>)p).getTreeNode(hash, key); else { do { if (e.hash == hash && ((k = e.key) == key || (key != null && key.equals(k)))) { node = e; break; } p = e; } while ((e = e.next) != null); } } if (node != null && (!matchValue || (v = node.value) == value || (value != null && value.equals(v)))) { if (node instanceof TreeNode) ((TreeNode<K,V>)node).removeTreeNode(this, tab, movable); else if (node == p) tab[index] = node.next; else p.next = node.next; ++modCount; --size; afterNodeRemoval(node); return node; } } return null; }
remove 方法有很多,最终都会调用到 removeNode 方法,只不过传递的参数值不同,我们拿 remove(object) 来演示一下。
首先会通过 hash 来找到对应的 bucket,然后通过遍历链表,找到键值相等的节点,然后把对应的节点进行删除。
关于 HashMap 的面试题
HashMap 的数据结构
JDK1.7 中,HashMap 采用位桶 + 链表的实现,即使用链表来处理冲突,同一 hash 值的链表都存储在一个数组中。但是当位于一个桶中的元素较多,即 hash 值相等的元素较多时,通过 key 值依次查找的效率较低。
所以,与 JDK 1.7 相比,JDK 1.8 在底层结构方面做了一些改变,当每个桶中元素大于 8 的时候,会转变为红黑树,目的就是优化查询效率。
HashMap 的 put 过程
大致过程如下,首先会使用 hash 方法计算对象的哈希码,根据哈希码来确定在 bucket 中存放的位置,如果 bucket 中没有 Node 节点则直接进行 put,如果对应 bucket 已经有 Node 节点,会对链表长度进行分析,判断长度是否大于 8,如果链表长度小于 8 ,在 JDK1.7 前会使用头插法,在 JDK1.8 之后更改为尾插法。如果链表长度大于 8 会进行树化操作,把链表转换为红黑树,在红黑树上进行存储。
HashMap 为啥线程不安全
HashMap 不是一个线程安全的容器,不安全性体现在多线程并发对 HashMap 进行 put 操作上。如果有两个线程 A 和 B ,首先 A 希望插入一个键值对到 HashMap 中,在决定好桶的位置进行 put 时,此时 A 的时间片正好用完了,轮到 B 运行,B 运行后执行和 A 一样的操作,只不过 B 成功把键值对插入进去了。如果 A 和 B 插入的位置(桶)是一样的,那么线程 A 继续执行后就会覆盖 B 的记录,造成了数据不一致问题。
还有一点在于 HashMap 在扩容时,因 resize 方法会形成环,造成死循环,导致 CPU 飙高。
HashMap 是如何处理哈希碰撞的
HashMap 底层是使用位桶 + 链表实现的,位桶决定元素的插入位置,位桶是由 hash 方法决定的,当多个元素的 hash 计算得到相同的哈希值后,HashMap 会把多个 Node 元素都放在对应的位桶中,形成链表,这种处理哈希碰撞的方式被称为链地址法。
其他处理 hash 碰撞的方式还有 开放地址法、rehash 方法、建立一个公共溢出区这几种方法。
HashMap 是如何 get 元素的
首先会检查 table 中的元素是否为空,然后根据 hash 算出指定 key 的位置。然后检查链表的第一个元素是否为空,如果不为空,是否匹配,如果匹配,直接返回这条记录;如果匹配,再判断下一个元素的值是否为 null,为空直接返回,如果不为空,再判断是否是 TreeNode 实例,如果是 TreeNode 实例,则直接使用 TreeNode.getTreeNode 取出元素,否则执行循环,直到下一个元素为 null 位置。
HashMap 和 HashTable 有什么区别
见上
HashMap 和 HashSet 的区别
见上
HashMap 是如何扩容的
HashMap 中有两个非常重要的变量,一个是 loadFactor ,一个是 threshold ,loadFactor 表示的就是负载因子,threshold 表示的是下一次要扩容的阈值,当 threshold = loadFactor * 数组长度时,数组长度扩大位原来的两倍,来重新调整 map 的大小,并将原来的对象放入新的 bucket 数组中。
HashMap 的长度为什么是 2 的幂次方
这道题我想了几天,之前和群里小伙伴们探讨每日一题的时候,问他们为什么 length%hash == (n – 1) & hash,它们说相等的前提是 length 的长度 2 的幂次方,然后我回了一句难道 length 还能不是 2 的幂次方吗?其实是我没有搞懂因果关系,因为 HashMap 的长度是 2 的幂次方,所以使用余数来判断在桶中的下标。如果 length 的长度不是 2 的幂次方,小伙伴们可以举个例子来试试
例如长度为 9 时候,3 & (9-1) = 0,2 & (9-1) = 0 ,都在 0 上,碰撞了;
这样会增大 HashMap 碰撞的几率。
HashMap 线程安全的实现有哪些
因为 HashMap 不是一个线程安全的容器,所以并发场景下推荐使用 ConcurrentHashMap ,或者使用线程安全的 HashMap,使用 Collections 包下的线程安全的容器,比如说
还可以使用 HashTable ,它也是线程安全的容器,基于 key-value 存储,经常用 HashMap 和 HashTable 做比较就是因为 HashTable 的数据结构和 HashMap 相同。
上面效率最高的就是 ConcurrentHashMap。
后记
文章并没有叙述太多关于红黑树的构造、包含添加、删除、树化等过程,一方面是自己能力还达不到,一方面是关于红黑树的描述太过于占据篇幅,红黑树又是很大的一部分内容,所以会考虑放在后面的红黑树进行讲解。
# 谈谈强引用、软引用、弱引用、幻象引用-Java面试题
我们说的不同的引用类型其实都是逻辑上的,而对于虚拟机来说,主要体现的是对象的不同的可达性(reachable) 状态和对垃圾收集(garbage collector)的影响。
初识引用
对于刚接触 Java 的 C++ 程序员而言,理解栈和堆的关系可能很不习惯。在 C++ 中,可以使用 new 操作符在堆上创建对象,或者使用自动分配在栈上创建对象。下面的 C++ 语句是合法的,但是 Java 编译器却拒绝这么写代码,会出现 syntax error 编译错误。
Java 和 C 不一样,Java 中会把对象都放在堆上,需要 new 操作符来创建对象。本地变量存储在栈中,它们持有一个指向堆中对象的引用(指针)。下面是一个 Java 方法,该方法具有一个 Integer 变量,该变量从 String 解析值
这段代码我们使用堆栈分配图可以看一下它们的关系
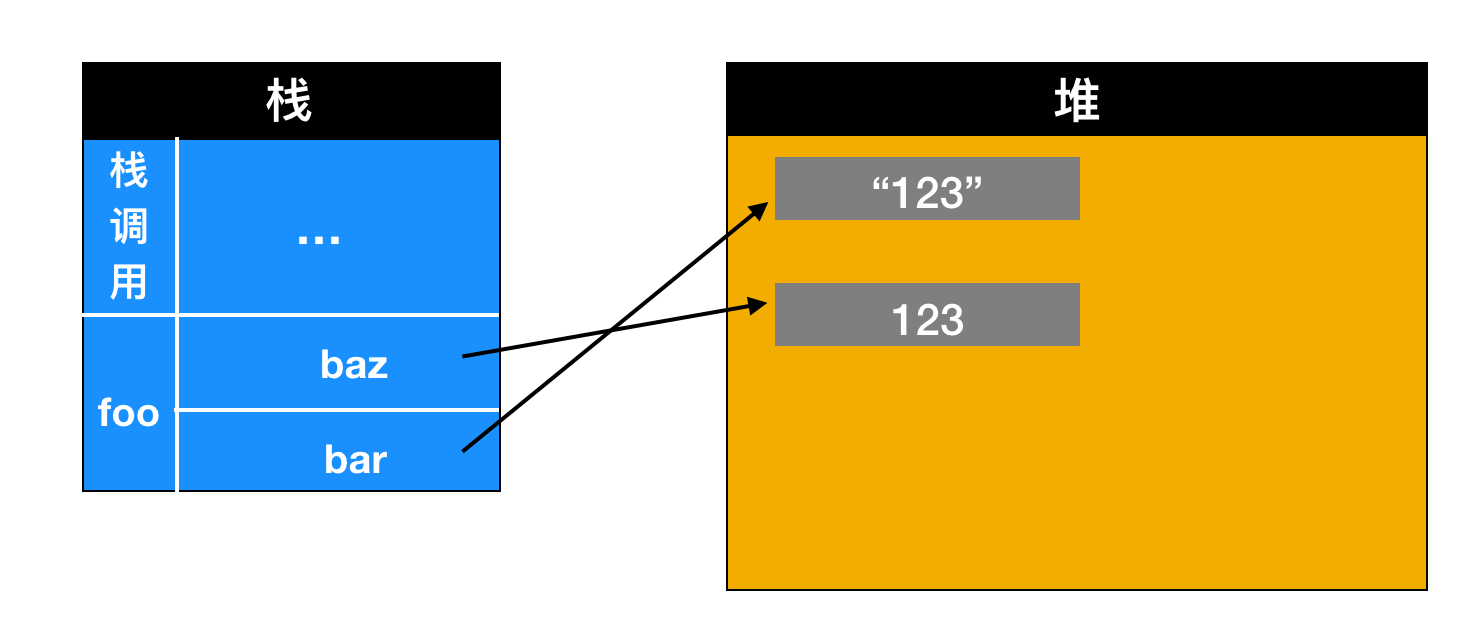
首先先来看一下 foo() 方法,这一行代码分配了一个新的 Integer 对象,JVM 尝试在堆空间中开辟一块内存空间。如果允许分配的话,就会调用 Integer 的构造方法把 String 字符串转换为 Integer 对象。JVM 将指向该对象的指针存储在变量 baz 中。
上面这种情况是我们乐意看到的情况,毕竟我们不想在编写代码的时候遇到阻碍,但是这种情况是不可能出现的,当堆空间无法为 bar 和 baz 开辟内存空间时,就会出现 OutOfMemoryError,然后就会调用垃圾收集器(garbage collector) 来尝试腾出内存空间。这中间涉及到一个问题,垃圾收集器会回收哪些对象?
垃圾收集器
Java 给你提供了一个 new 操作符来为堆中的对象开辟内存空间,但它没有提供 delete 操作符来释放对象空间。当 foo() 方法返回时,如果变量 baz 超过最大内存,但它所指向的对象仍然还在堆中。如果没有垃圾回收器的话,那么程序就会抛出 OutOfMemoryError 错误。然而 Java 不会,它会提供垃圾收集器来释放不再引用的对象。
当程序尝试创建新对象并且堆中没有足够的空间时,垃圾收集器就开始工作。当收集器访问堆时,请求线程被挂起,试图查找程序不再主动使用的对象,并回收它们的空间。如果垃圾收集器无法释放足够的内存空间,并且JVM 无法扩展堆,则会出现 OutOfMemoryError,你的应用程序通常在这之后崩溃。还有一种情况是 StackOverflowError ,它出现的原因是因为线程请求的栈深度要大于虚拟机所允许的深度时出现的错误。
标记 – 清除算法
Java 能永久不衰的一个原因就是因为垃圾收集器。许多人认为 JVM 会为每个对象保留一个引用计数,当每次引用对象的时候,引用计数器的值就 + 1,当引用失效的时候,引用计数器的值就 – 1。而垃圾收集器只会回收引用计数器的值为 0 的情况。这其实是 引用计数法(Reference Counting) 的收集方式。但是这种方式无法解决对象之间相会引用的问题,如下
} class B{ public A a; } public class Main{ public static void main(String[] args){ A a = new A(); B b = new B(); a.b=b; b.a=a; } }
然而实际上,JVM 使用一种叫做 标记-清除(Mark-Sweep)的算法,标记清除垃圾回收背后的想法很简单:程序无法到达的每个对象都是垃圾,可以进行回收。
标记-清除收集具有如下几个阶段
- 阶段一:标记
垃圾收集器会从 根(root) 引用开始,标记它到达的所有对象。如果用老师给学生判断卷子来比喻,这就相当于是给试卷上的全部答案判断正确还是错误的过程。

- 阶段二:清理
在第一阶段中所有可回收的的内容都能够被垃圾收集器进行回收。如果一个对象被判定为是可以回收的对象,那么这个对象就被放在一个 finalization queue(回收队列)中,并在稍后会由一个虚拟机自动建立的、低优先级的 finalizer 线程去执行它。

- 阶段三:整理(可选)
一些收集器有第三个步骤,整理。在这个步骤中,GC 将对象移动到垃圾收集器回收完对象后所留下的自由空间中。这么做可以防止堆碎片化,防止大对象在堆中由于堆空间的不连续性而无法分配的情况。
所以上面的过程中就涉及到一个根节点(GC Roots) 来判断是否存在需要回收的对象。这个算法的基本思想就是通过一系列的 GC Roots 作为起始点,从这些节点向下搜索,搜索所走过的路径称为 引用链(Reference Chain),当一个对象到 GC Roots 之间没有任何引用链相连的话,则证明此对象不可用。引用链上的任何一个能够被访问的对象都是强引用 对象,垃圾收集器不会回收强引用对象。
因此,返回到 foo() 方法中,仅在执行方法时,参数 bar 和局部变量 baz 才是强引用。一旦方法执行完成,它们都超过了作用域的时候,它们引用的对象都会进行垃圾回收。
下面来考虑一个例子
LinkedList foo = new LinkedList(); foo.add(new Integer(111));变量 foo 是一个强引用,它指向一个 LinkedList 对象。LinkedList(JDK.18) 是一个链表的数据结构,每一个元素都会指向前驱元素,每个元素都有其后继元素。

当我们调用add() 方法时,我们会增加一个新的链表元素,并且该链表元素指向值为 111 的 Integer 实例。这是一连串的强引用,也就是说,这个 Integer 的实例不符合垃圾收集条件。一旦 foo 对象超出了程序运行的作用域,LinkedList 和其中的引用内容都可以进行收集,收集的前提是没有强引用关系。
Finalizers
C++ 允许对象定义析构函数方法:当对象超出作用范围或被明确删除时,会调用析构函数来清理使用的资源。对于大多数对象来说,析构函数能够释放使用 new 或者 malloc 函数分配的内存。 在Java中,垃圾收集器会为你自动清除对象,分配内存,因此不需要显式析构函数即可执行此操作。这也是 Java 和 C++ 的一大区别。
然而,内存并不是唯一需要被释放的资源。考虑 FileOutputStream:当你创建此对象的实例时,它从操作系统分配文件句柄。如果你让流的引用在关闭前超过了其作用范围,该文件句柄会怎么样?实际上,每个流都会有一个 finalizer 方法,这个方法是垃圾回收器在回收之前由 JVM 调用的方法。对于 FileOutputStream 来说,finalizer 方法会关闭流,释放文件句柄给操作系统,然后清除缓冲区,确保数据能够写入磁盘。
任何对象都具有 finalizer 方法,你要做的就是声明 finalize() 方法。如下
虽然 finalizers 的 finalize() 方法是一种好的清除方式,但是这种方法产生的负面影响非常大,你不应该依靠这个方法来做任何垃圾回收工作。因为 finalize 方法的运行开销比较大,不确定性强,无法保证各个对象的调用顺序。finalize 能做的任何事情,可以使用 try-finally 或者其他方式来做,甚至做的更好。
对象的生命周期
综上所述,可以通过下面的流程来对对象的生命周期做一个总结
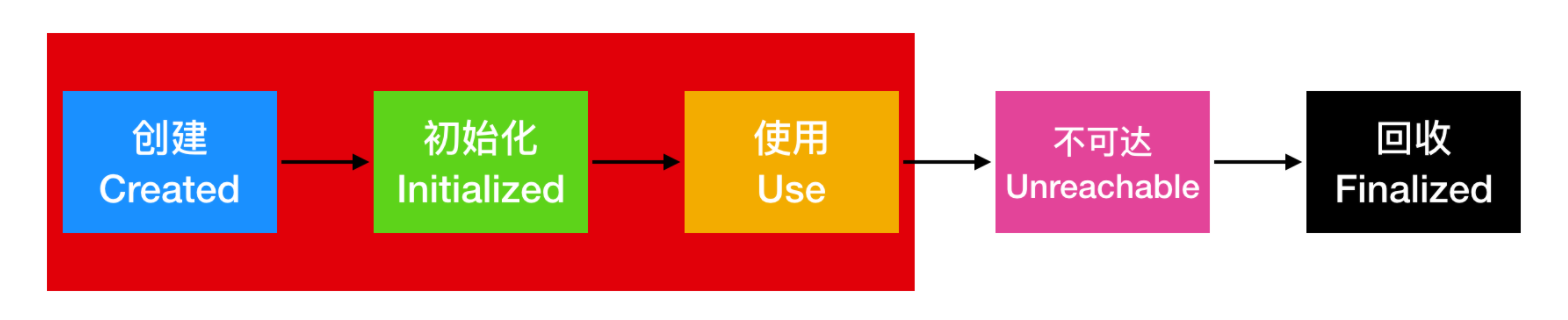
对象被创建并初始化,对象在运行时被使用,然后离开对象的作用域,对象会变成不可达并会被垃圾收集器回收。图中用红色标明的区域表示对象处于强可达阶段。
JDK1.2 介绍了 java.lang.ref 包,对象的生命周期有四个阶段:强可达(Strongly Reachable)、软可达(Soft Reachable)、弱可达(Weak Reachable)、 幻象可达(Phantom Reachable)。
如果只讨论符合垃圾回收条件的对象,那么只有三种:软可达、弱可达和幻象可达。
软可达:软可达就是我们只能通过软引用才能访问的状态,软可达的对象是由
SoftReference引用的对象,并且没有强引用的对象。软引用是用来描述一些还有用但是非必须的对象。垃圾收集器会尽可能长时间的保留软引用的对象,但是会在发生OutOfMemoryError之前,回收软引用的对象。如果回收完软引用的对象,内存还是不够分配的话,就会直接抛出 OutOfMemoryError。弱可达:弱可达的对象是
WeakReference引用的对象。垃圾收集器可以随时收集弱引用的对象,不会尝试保留软引用的对象。幻象可达:幻象可达是由
PhantomReference引用的对象,幻象可达就是没有强、软、弱引用进行关联,并且已经被 finalize 过了,只有幻象引用指向这个对象的时候。
除此之外,还有强可达和不可达的两种可达性判断条件
- 强可达:就是一个对象刚被创建、初始化、使用中的对象都是处于强可达的状态
不可达(unreachable):处于不可达的对象就意味着对象可以被清除了。
下面是一个不同可达性状态的转换图

判断可达性条件,也是 JVM 垃圾收集器决定如何处理对象的一部分考虑因素。
所有的对象可达性引用都是 java.lang.ref.Reference 的子类,它里面有一个get() 方法,返回引用对象。 如果已通过程序或垃圾收集器清除了此引用对象,则此方法返回 null 。也就是说,除了幻象引用外,软引用和弱引用都是可以得到对象的。而且这些对象可以人为拯救,变为强引用,例如把 this 关键字赋值给对象,只要重新和引用链上的任意一个对象建立关联即可。
ReferenceQueue
引用队列又称为 ReferenceQueue,它位于 java.lang.ref 包下。我们在建各种引用(软引用,弱引用,幻象引用)并关联到响应对象时,可以选择是否需要关联引用队列。JVM 会在特定的时机将引用入队到队列中,程序可以通过判断引用队列中是否已经加入引用,来了解被引用的对象是否被GC回收。
Reference
java.lang.ref.Reference 为软(soft)引用、弱(weak)引用、虚(phantom)引用的父类。因为 Reference 对象和垃圾回收密切配合实现,该类可能不能被直接子类化。
# Java基础反射篇-Java面试题
反射是一个非常重要的知识点,在学习Spring 框架时,Bean的初始化用到了反射,在破坏单例模式时也用到了反射,在获取标注的注解
当然了,反射在日常开发中,我们没碰到过多少,至少我没怎么用过。但面试是造火箭现场,可爱的面试官们又怎会轻易地放过我们呢?反射是开源框架中的一个重要设计理念,在源码分析中少不了它的身影,所以,今天我会尽量用浅显易懂的语言,让你去理解下面这几点:
(1)反射的思想以及它的作用 :point_right: 概念篇
(2)反射的基本使用及应用场景 :point_right: 应用篇
(3)使用反射能给我们编码时带来的优势以及存在的缺陷 :point_right: 分析篇
反射的思想及作用
有反必有正,就像世间的阴和阳,计算机的0和1一样。天道有轮回,苍天…(净会在这瞎bibi)
在学习反射之前,先来了解正射是什么。我们平常用的最多的 new 方式实例化对象的方式就是一种正射的体现。假如我需要实例化一个HashMap,代码就会是这样子。
某一天发现,该段程序不适合用 HashMap 存储键值对,更倾向于用LinkedHashMap存储。重新编写代码后变成下面这个样子。
假如又有一天,发现数据还是适合用 HashMap来存储,难道又要重新修改源码吗?
发现问题了吗?我们每次改变一种需求,都要去重新修改源码,然后对代码进行编译,打包,再到 JVM 上重启项目。这么些步骤下来,效率非常低。
对于这种需求频繁变更但变更不大的场景,频繁地更改源码肯定是一种不允许的操作,我们可以使用一个开关,判断什么时候使用哪一种数据结构。
通过传入参数param决定使用哪一种数据结构,可以在项目运行时,通过动态传入参数决定使用哪一个数据结构。
如果某一天还想用TreeMap,还是避免不了修改源码,重新编译执行的弊端。这个时候,反射就派上用场了。
在代码运行之前,我们不确定将来会使用哪一种数据结构,只有在程序运行时才决定使用哪一个数据类,而反射可以在程序运行过程中动态获取类信息和调用类方法。通过反射构造类实例,代码会演变成下面这样。
无论使用什么 Map,只要实现了Map接口,就可以使用全类名路径传入到方法中,获得对应的 Map 实例。例如java.util.HashMap / java.util.LinkedHashMap····如果要创建其它类例如WeakHashMap,我也不需要修改上面这段源码。
我们来回顾一下如何从 new 一个对象引出使用反射的。
- 在不使用反射时,构造对象使用 new 方式实现,这种方式在编译期就可以把对象的类型确定下来。
- 如果需求发生变更,需要构造另一个对象,则需要修改源码,非常不优雅,所以我们通过使用
开关,在程序运行时判断需要构造哪一个对象,在运行时可以变更开关来实例化不同的数据结构。 - 如果还有其它扩展的类有可能被使用,就会创建出非常多的分支,且在编码时不知道有什么其他的类被使用到,假如日后
Map接口下多了一个集合类是xxxHashMap,还得创建分支,此时引出了反射:可以在运行时才确定使用哪一个数据类,在切换类时,无需重新修改源码、编译程序。
第一章总结:
- 反射的思想:在程序运行过程中确定和解析数据类的类型。
- 反射的作用:对于在
编译期无法确定使用哪个数据类的场景,通过反射可以在程序运行时构造出不同的数据类实例。
反射的基本使用
Java 反射的主要组成部分有4个:
Class:任何运行在内存中的所有类都是该 Class 类的实例对象,每个 Class 类对象内部都包含了本来的所有信息。记着一句话,通过反射干任何事,先找 Class 准没错!Field:描述一个类的属性,内部包含了该属性的所有信息,例如数据类型,属性名,访问修饰符······Constructor:描述一个类的构造方法,内部包含了构造方法的所有信息,例如参数类型,参数名字,访问修饰符······Method:描述一个类的所有方法(包括抽象方法),内部包含了该方法的所有信息,与Constructor类似,不同之处是 Method 拥有返回值类型信息,因为构造方法是没有返回值的。
我总结了一张脑图,放在了下面,如果用到了反射,离不开这核心的4个类,只有去了解它们内部提供了哪些信息,有什么作用,运用它们的时候才能易如反掌。
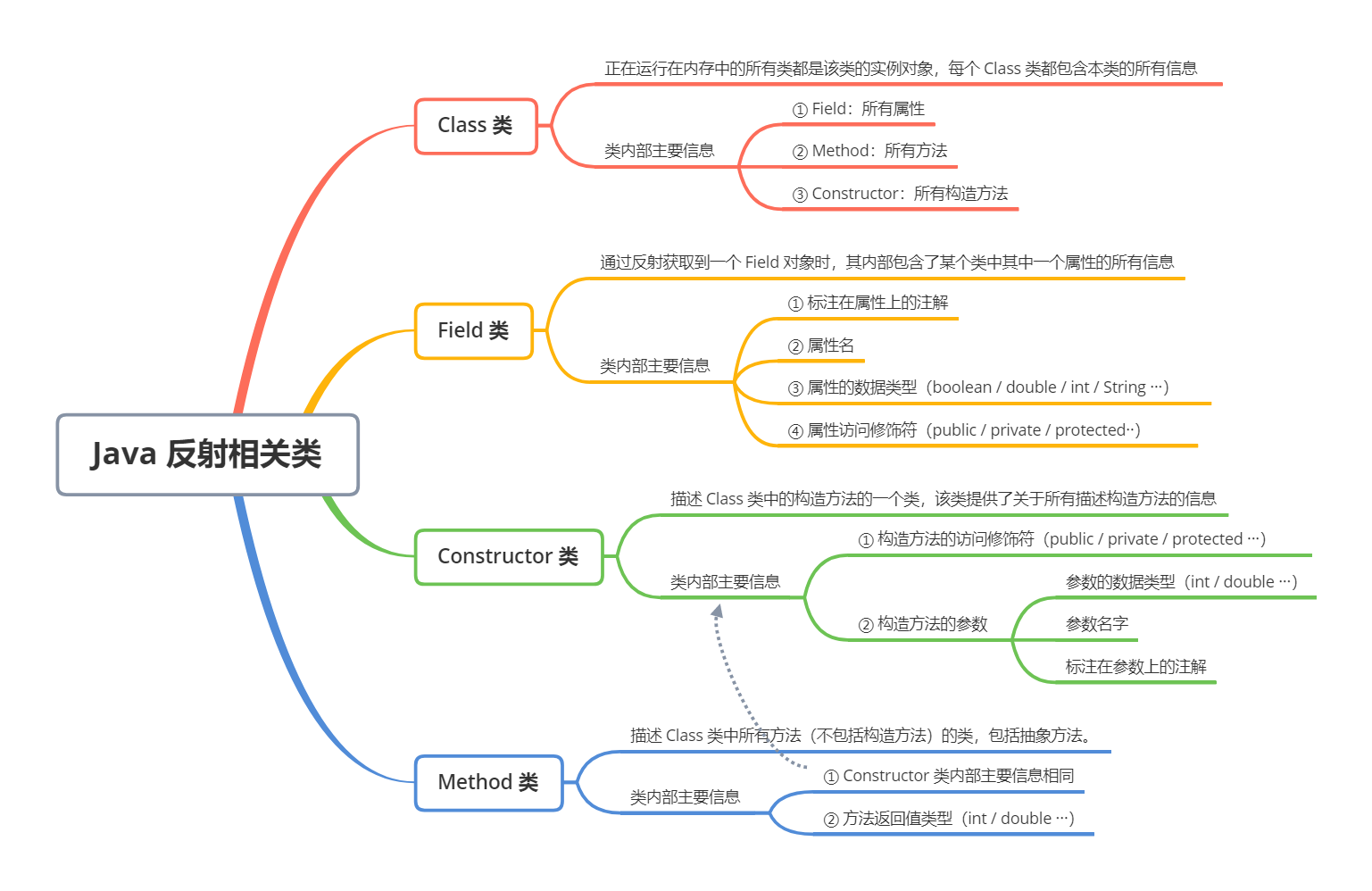
我们在学习反射的基本使用时,我会用一个SmallPineapple类作为模板进行说明,首先我们先来熟悉这个类的基本组成:属性,构造函数和方法
public SmallPineapple() {}
public SmallPineapple(String name, int age) {
this.name = name;
this.age = age;
}
public void getInfo() {
System.out.print("["+ name + " 的年龄是:" + age + "]");
}
}
反射中的用法有非常非常多,常见的功能有以下这几个:
- 在运行时获取一个类的 Class 对象
- 在运行时构造一个类的实例化对象
- 在运行时获取一个类的所有信息:变量、方法、构造器、注解
获取类的 Class 对象
在 Java 中,每一个类都会有专属于自己的 Class 对象,当我们编写完.java文件后,使用javac编译后,就会产生一个字节码文件.class,在字节码文件中包含类的所有信息,如属性,构造方法,方法······当字节码文件被装载进虚拟机执行时,会在内存中生成 Class 对象,它包含了该类内部的所有信息,在程序运行时可以获取这些信息。
获取 Class 对象的方法有3种:
类名.class:这种获取方式只有在编译前已经声明了该类的类型才能获取到 Class 对象
实例.getClass():通过实例化对象获取该实例的 Class 对象
Class.forName(className):通过类的全限定名获取该类的 Class 对象
拿到 Class对象就可以对它为所欲为了:剥开它的皮(获取类信息)、指挥它做事(调用它的方法),看透它的一切(获取属性),总之它就没有隐私了。
不过在程序中,每个类的 Class 对象只有一个,也就是说你只有这一个奴隶。我们用上面三种方式测试,通过三种方式打印各个 Class 对象都是相同的。
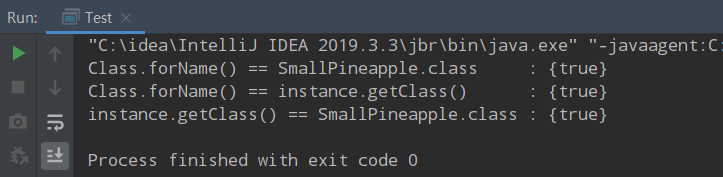
内存中只有一个 Class 对象的原因要牵扯到
JVM 类加载机制的双亲委派模型,它保证了程序运行时,加载类时每个类在内存中仅会产生一个Class对象。在这里我不打算详细展开说明,可以简单地理解为 JVM 帮我们保证了一个类在内存中至多存在一个 Class 对象。
构造类的实例化对象
通过反射构造一个类的实例方式有2种:
- Class 对象调用
newInstance()方法
即使 SmallPineapple 已经显式定义了构造方法,通过 newInstance() 创建的实例中,所有属性值都是对应类型的初始值,因为 newInstance() 构造实例会调用默认无参构造器。
- Constructor 构造器调用
newInstance()方法
通过 getConstructor(Object… paramTypes) 方法指定获取指定参数类型的 Constructor, Constructor 调用 newInstance(Object… paramValues) 时传入构造方法参数的值,同样可以构造一个实例,且内部属性已经被赋值。
通过Class对象调用 newInstance() 会走默认无参构造方法,如果想通过显式构造方法构造实例,需要提前从Class中调用getConstructor()方法获取对应的构造器,通过构造器去实例化对象。
这些 API 是在开发当中最常遇到的,当然还有非常多重载的方法,本文由于篇幅原因,且如果每个方法都一一讲解,我们也记不住,所以用到的时候去类里面查找就已经足够了。
获取一个类的所有信息
Class 对象中包含了该类的所有信息,在编译期我们能看到的信息就是该类的变量、方法、构造器,在运行时最常被获取的也是这些信息。

获取类中的变量(Field)
- Field[] getFields():获取类中所有被
public修饰的所有变量 - Field getField(String name):根据变量名获取类中的一个变量,该变量必须被public修饰
- Field[] getDeclaredFields():获取类中所有的变量,但无法获取继承下来的变量
- Field getDeclaredField(String name):根据姓名获取类中的某个变量,无法获取继承下来的变量
获取类中的方法(Method)
Method[] getMethods():获取类中被
public修饰的所有方法Method getMethod(String name, Class…<?> paramTypes):根据名字和参数类型获取对应方法,该方法必须被
public修饰Method[] getDeclaredMethods():获取
所有方法,但无法获取继承下来的方法Method getDeclaredMethod(String name, Class…<?> paramTypes):根据名字和参数类型获取对应方法,无法获取继承下来的方法
获取类的构造器(Constructor)
- Constuctor[] getConstructors():获取类中所有被
public修饰的构造器 - Constructor getConstructor(Class…<?> paramTypes):根据
参数类型获取类中某个构造器,该构造器必须被public修饰 - Constructor[] getDeclaredConstructors():获取类中所有构造器
- Constructor getDeclaredConstructor(class…<?> paramTypes):根据
参数类型获取对应的构造器
每种功能内部以 Declared 细分为2类:
有
Declared修饰的方法:可以获取该类内部包含的所有变量、方法和构造器,但是无法获取继承下来的信息无
Declared修饰的方法:可以获取该类中public修饰的变量、方法和构造器,可获取继承下来的信息
如果想获取类中所有的(包括继承)变量、方法和构造器,则需要同时调用getXXXs()和getDeclaredXXXs()两个方法,用Set集合存储它们获得的变量、构造器和方法,以防两个方法获取到相同的东西。
例如:要获取SmallPineapple获取类中所有的变量,代码应该是下面这样写。
Class clazz = Class.forName("com.bean.SmallPineapple"); // 获取 public 属性,包括继承 Field[] fields1 = clazz.getFields(); // 获取所有属性,不包括继承 Field[] fields2 = clazz.getDeclaredFields(); // 将所有属性汇总到 set Set<Field> allFields = new HashSet<>(); allFields.addAll(Arrays.asList(fields1)); allFields.addAll(Arrays.asList(fields2));不知道你有没有发现一件有趣的事情,如果父类的属性用
protected修饰,利用反射是无法获取到的。protected 修饰符的作用范围:只允许
同一个包下或者子类访问,可以继承到子类。getFields() 只能获取到本类的
public属性的变量值;getDeclaredFields() 只能获取到本类的所有属性,不包括继承的;无论如何都获取不到父类的 protected 属性修饰的变量,但是它的的确确存在于子类中。
获取注解
获取注解单独拧了出来,因为它并不是专属于 Class 对象的一种信息,每个变量,方法和构造器都可以被注解修饰,所以在反射中,Field,Constructor 和 Method 类对象都可以调用下面这些方法获取标注在它们之上的注解。
- Annotation[] getAnnotations():获取该对象上的所有注解
- Annotation getAnnotation(Class annotaionClass):传入
注解类型,获取该对象上的特定一个注解 - Annotation[] getDeclaredAnnotations():获取该对象上的显式标注的所有注解,无法获取
继承下来的注解 - Annotation getDeclaredAnnotation(Class annotationClass):根据
注解类型,获取该对象上的特定一个注解,无法获取继承下来的注解
只有注解的@Retension标注为RUNTIME时,才能够通过反射获取到该注解,@Retension 有3种保存策略:
SOURCE:只在源文件(.java)中保存,即该注解只会保留在源文件中,编译时编译器会忽略该注解,例如 @Override 注解CLASS:保存在字节码文件(.class)中,注解会随着编译跟随字节码文件中,但是运行时不会对该注解进行解析RUNTIME:一直保存到运行时,用得最多的一种保存策略,在运行时可以获取到该注解的所有信息
像下面这个例子,SmallPineapple 类继承了抽象类Pineapple,getInfo()方法上标识有 @Override 注解,且在子类中标注了@Transient注解,在运行时获取子类重写方法上的所有注解,只能获取到@Transient的信息。
启动类Bootstrap获取 SmallPineapple 类中的 getInfo() 方法上的注解信息:
通过反射调用方法
通过反射获取到某个 Method 类对象后,可以通过调用invoke方法执行。
invoke(Oject obj, Object... args):参数`1指定调用该方法的对象,参数2是方法的参数列表值。
如果调用的方法是静态方法,参数1只需要传入null,因为静态方法不与某个对象有关,只与某个类有关。
可以像下面这种做法,通过反射实例化一个对象,然后获取Method方法对象,调用invoke()指定SmallPineapple的getInfo()方法。
反射的应用场景
反射常见的应用场景这里介绍3个:
- Spring 实例化对象:当程序启动时,Spring 会读取配置文件
applicationContext.xml并解析出里面所有的标签实例化到 IOC容器中。 - 反射 + 工厂模式:通过
反射消除工厂中的多个分支,如果需要生产新的类,无需关注工厂类,工厂类可以应对各种新增的类,反射可以使得程序更加健壮。 - JDBC连接数据库:使用JDBC连接数据库时,指定连接数据库的
驱动类时用到反射加载驱动类
Spring 的 IOC 容器
在 Spring 中,经常会编写一个上下文配置文件applicationContext.xml,里面就是关于bean的配置,程序启动时会读取该 xml 文件,解析出所有的 <bean>标签,并实例化对象放入IOC容器中。
在定义好上面的文件后,通过ClassPathXmlApplicationContext加载该配置文件,程序启动时,Spring 会将该配置文件中的所有bean都实例化,放入 IOC 容器中,IOC 容器本质上就是一个工厂,通过该工厂传入
id属性获取到对应的实例。
Spring 在实例化对象的过程经过简化之后,可以理解为反射实例化对象的步骤:
- 获取Class对象的构造器
- 通过构造器调用 newInstance() 实例化对象
当然 Spring 在实例化对象时,做了非常多额外的操作,才能够让现在的开发足够的便捷且稳定。
在之后的文章中会专门写一篇文章讲解如何利用反射实现一个
简易版的IOC容器,IOC容器原理很简单,只要掌握了反射的思想,了解反射的常用 API 就可以实现,我可以提供一个简单的思路:利用 HashMap 存储所有实例,key 代表
标签的 id,value 存储对应的实例,这对应了 Spring IOC容器管理的对象默认是 单例的。
反射 + 抽象工厂模式
传统的工厂模式,如果需要生产新的子类,需要修改工厂类,在工厂类中增加新的分支;
public class MapFactory { public Map<Object, object> produceMap(String name) { if ("HashMap".equals(name)) { return new HashMap<>(); } else if ("TreeMap".equals(name)) { return new TreeMap<>(); } // ··· } }利用反射和工厂模式相结合,在产生新的子类时,工厂类不用修改任何东西,可以专注于子类的实现,当子类确定下来时,工厂也就可以生产该子类了。
反射 + 抽象工厂的核心思想是:
- 在运行时通过参数传入不同子类的全限定名获取到不同的 Class 对象,调用 newInstance() 方法返回不同的子类。细心的读者会发现提到了子类这个概念,所以反射 + 抽象工厂模式,一般会用于有继承或者接口实现关系。
例如,在运行时才确定使用哪一种 Map 结构,我们可以利用反射传入某个具体 Map 的全限定名,实例化一个特定的子类。
className 可以指定为 java.util.HashMap,或者 java.util.TreeMap 等等,根据业务场景来定。
JDBC 加载数据库驱动类
在导入第三方库时,JVM不会主动去加载外部导入的类,而是等到真正使用时,才去加载需要的类,正是如此,我们可以在获取数据库连接时传入驱动类的全限定名,交给 JVM 加载该类。
public class DBConnectionUtil { /* 指定数据库的驱动类 */ private static final String DRIVER_CLASS_NAME = "com.mysql.jdbc.Driver";public static Connection getConnection() {
Connection conn = null;
// 加载驱动类
Class.forName(DRIVER_CLASS_NAME);
// 获取数据库连接对象
conn = DriverManager.getConnection("jdbc:mysql://···", "root", "root");
return conn;
}
}
在我们开发 SpringBoot 项目时,会经常遇到这个类,但是可能习惯成自然了,就没多大在乎,我在这里给你们看看常见的application.yml中的数据库配置,我想你应该会恍然大悟吧。
这里的 driver-class-name,和我们一开始加载的类是不是觉得很相似,这是因为MySQL版本不同引起的驱动类不同,这体现使用反射的好处:不需要修改源码,仅加载配置文件就可以完成驱动类的替换。
在之后的文章中会专门写一篇文章详细地介绍反射的应用场景,实现简单的
IOC容器以及通过反射实现工厂模式的好处。在这里,你只需要掌握反射的基本用法和它的思想,了解它的主要使用场景。
反射的优势及缺陷
反射的优点:
- 增加程序的灵活性:面对需求变更时,可以灵活地实例化不同对象
但是,有得必有失,一项技术不可能只有优点没有缺点,反射也有两个比较隐晦的缺点:
- 破坏类的封装性:可以强制访问 private 修饰的信息
- 性能损耗:反射相比直接实例化对象、调用方法、访问变量,中间需要非常多的检查步骤和解析步骤,JVM无法对它们优化。
增加程序的灵活性
这里不再用 SmallPineapple 举例了,我们来看一个更加贴近开发的例子:
- 利用反射连接数据库,涉及到数据库的数据源。在 SpringBoot 中一切约定大于配置,想要定制配置时,使用
application.properties配置文件指定数据源
角色1 – Java的设计者:我们设计好DataSource接口,你们其它数据库厂商想要开发者用你们的数据源监控数据库,就得实现我的这个接口!
角色2 – 数据库厂商:
- MySQL 数据库厂商:我们提供了 com.mysql.cj.jdbc.MysqlDataSource 数据源,开发者可以使用它连接 MySQL。
- 阿里巴巴厂商:我们提供了 com.alibaba.druid.pool.DruidDataSource 数据源,我这个数据源更牛逼,具有页面监控,慢SQL日志记录等功能,开发者快来用它监控 MySQL吧!
- SQLServer 厂商:我们提供了 com.microsoft.sqlserver.jdbc.SQLServerDataSource 数据源,如果你想实用SQL Server 作为数据库,那就使用我们的这个数据源连接吧
角色3 – 开发者:我们可以用配置文件指定使用DruidDataSource数据源
需求变更:某一天,老板来跟我们说,Druid 数据源不太符合我们现在的项目了,我们使用 MysqlDataSource 吧,然后程序猿就会修改配置文件,重新加载配置文件,并重启项目,完成数据源的切换。
spring.datasource.type=com.mysql.cj.jdbc.MysqlDataSource在改变连接数据库的数据源时,只需要改变配置文件即可,无需改变任何代码,原因是:
- Spring Boot 底层封装好了连接数据库的数据源配置,利用反射,适配各个数据源。
下面来简略的进行源码分析。我们用ctrl+左键点击spring.datasource.type进入 DataSourceProperties 类中,发现使用setType() 将全类名转化为 Class 对象注入到type成员变量当中。在连接并监控数据库时,就会使用指定的数据源操作。
public void setType(Class<? extends DataSource> type) { this.type = type; }
Class对象指定了泛型上界DataSource,我们去看一下各大数据源的类图结构。

上图展示了一部分数据源,当然不止这些,但是我们可以看到,无论指定使用哪一种数据源,我们都只需要与配置文件打交道,而无需更改源码,这就是反射的灵活性!
破坏类的封装性
很明显的一个特点,反射可以获取类中被private修饰的变量、方法和构造器,这违反了面向对象的封装特性,因为被 private 修饰意味着不想对外暴露,只允许本类访问,而setAccessable(true)可以无视访问修饰符的限制,外界可以强制访问。
还记得单例模式一文吗?里面讲到反射破坏饿汉式和懒汉式单例模式,所以之后用了枚举避免被反射KO。
回到最初的起点,SmallPineapple 里有一个 weight 属性被 private 修饰符修饰,目的在于自己的体重并不想给外界知道。
public class SmallPineapple { public String name; public int age; private double weight; // 体重只有自己知道public SmallPineapple(String name, int age, double weight) {
this.name = name;
this.age = age;
this.weight = weight;
}
}
虽然 weight 属性理论上只有自己知道,但是如果经过反射,这个类就像在裸奔一样,在反射面前变得一览无遗。
性能损耗
在直接 new 对象并调用对象方法和访问属性时,编译器会在编译期提前检查可访问性,如果尝试进行不正确的访问,IDE会提前提示错误,例如参数传递类型不匹配,非法访问 private 属性和方法。
而在利用反射操作对象时,编译器无法提前得知对象的类型,访问是否合法,参数传递类型是否匹配。只有在程序运行时调用反射的代码时才会从头开始检查、调用、返回结果,JVM也无法对反射的代码进行优化。
虽然反射具有性能损耗的特点,但是我们不能一概而论,产生了使用反射就会性能下降的思想,反射的慢,需要同时调用上100W次才可能体现出来,在几次、几十次的调用,并不能体现反射的性能低下。所以不要一味地戴有色眼镜看反射,在单次调用反射的过程中,性能损耗可以忽略不计。如果程序的性能要求很高,那么尽量不要使用反射。
反射基础篇文末总结
- 反射的思想:反射就像是一面镜子一样,在运行时才看到自己是谁,可获取到自己的信息,甚至实例化对象。
- 反射的作用:在运行时才确定实例化对象,使程序更加健壮,面对需求变更时,可以最大程度地做到不修改程序源码应对不同的场景,实例化不同类型的对象。
- 反射的应用场景常见的有
3个:Spring的 IOC 容器,反射+工厂模式 使工厂类更稳定,JDBC连接数据库时加载驱动类 - 反射的
3个特点:增加程序的灵活性、破坏类的封装性以及性能损耗
# @SuppressWarnings用法-Java面试题
从Java 5.0起,您可以使用java.lang.SuppressWarning注释,来停用与编译单元子集相关的编译警告
作用:用于抑制编译器产生警告信息。
Idea 设置泛型检查,变量、方法未使用检查
从 eclipse 转换到idea 发现有很多不习惯的地方,比如说
String s; List list = new ArrayList();没有未使用的变量,未检查泛型,未使用的方法提示,特意查找了一下相关资料
设置泛型检查
我使用的是mac电脑,windows电脑应该类似
打开如图
会出现如下页面
选择 editor —> inspections —> 搜索 Raw use of —> 勾上 Raw use of parameterized class
效果如图:

设置变量未使用提示
打开如图:
出现如下页面
在 Editor —> General —> Errors and Warnings —> 选择 Unused symbol
右侧勾选上 Error stripe mark 和 Effects 下面选择 Underwaved波浪线
参考:
https://blog.csdn.net/Lovincc/article/details/80464782
https://blog.csdn.net/codejas/article/details/78657560
变量未使用产生的警告
如上设置完成之后,变量未使用的提示应该是这样的:

如图 , list、set、map 都未被使用
1.为未使用的变量设置SuppressWarning
在方法前添加
@SuppressWarning("unused")能够越过变量未使用检查,@SuppressWarning 中的属性我们稍后再讨论。

2.对未使用的方法添加SuppressWarning跳过方法未调用检查
可以在方法上添加SuppressWarning 跳过对方法未使用的检查

3.为单行泛型添加SuppressWarning 跳过泛型检查
在单个泛型代码上添加@SuppressWarning("rawtypes")可以跳过泛型检查,但是需要注意: 还需要在方法上添加
@SuppressWarning("unchecked")注释
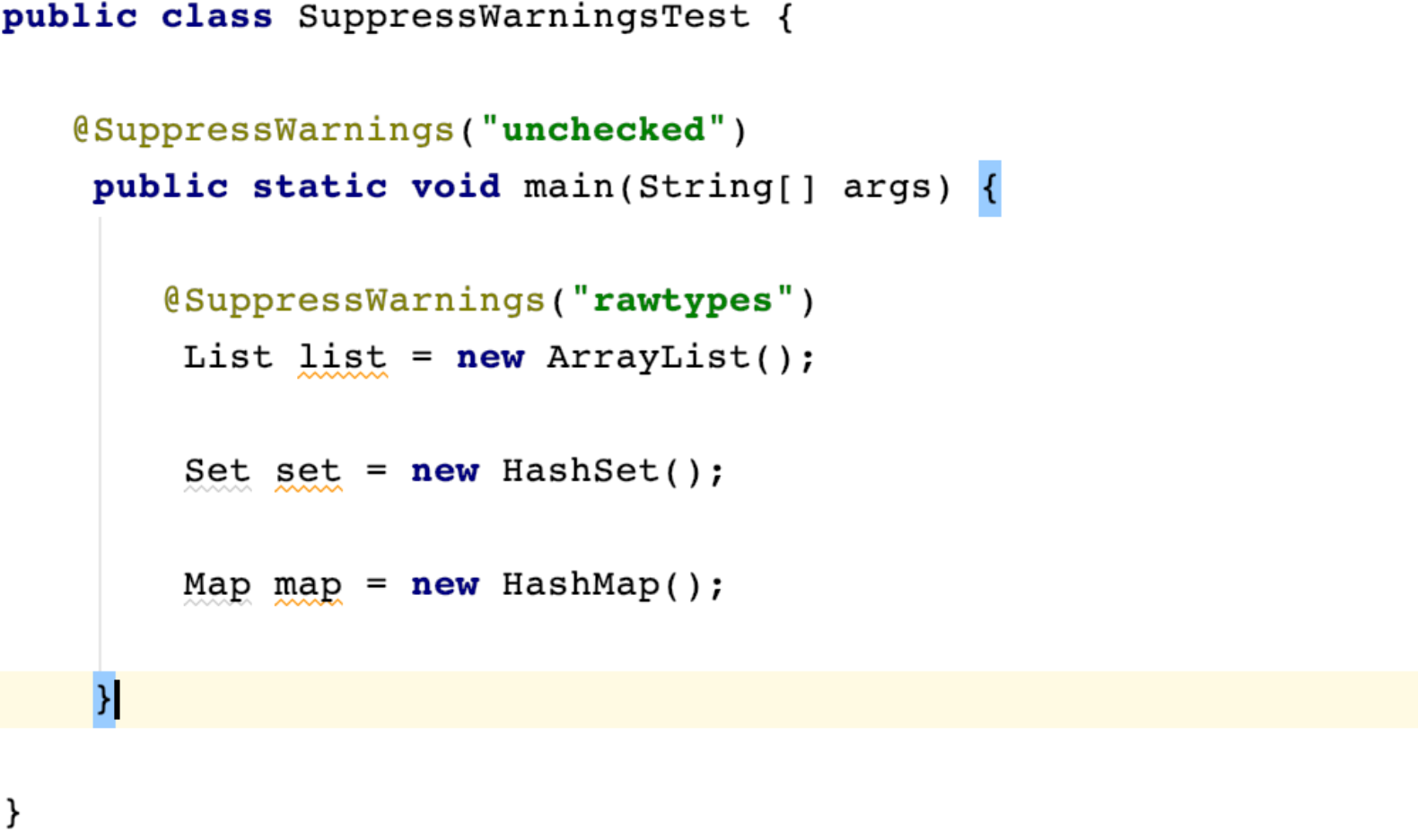
如上图所示,可以对单个泛型设置@SuppressWarning 跳过类型检查
4. 为方法体上添加SuppressWarning 跳过泛型检查
如果一个方法体上含有多个未被检查的泛型,需要在方法体上添加@SuppressWarning(value={"unchecked","rawtypes"}) 跳过泛型检查
如图所示:

也可以使用 @SuppressWarning("all") ,来跳过所有的检查。
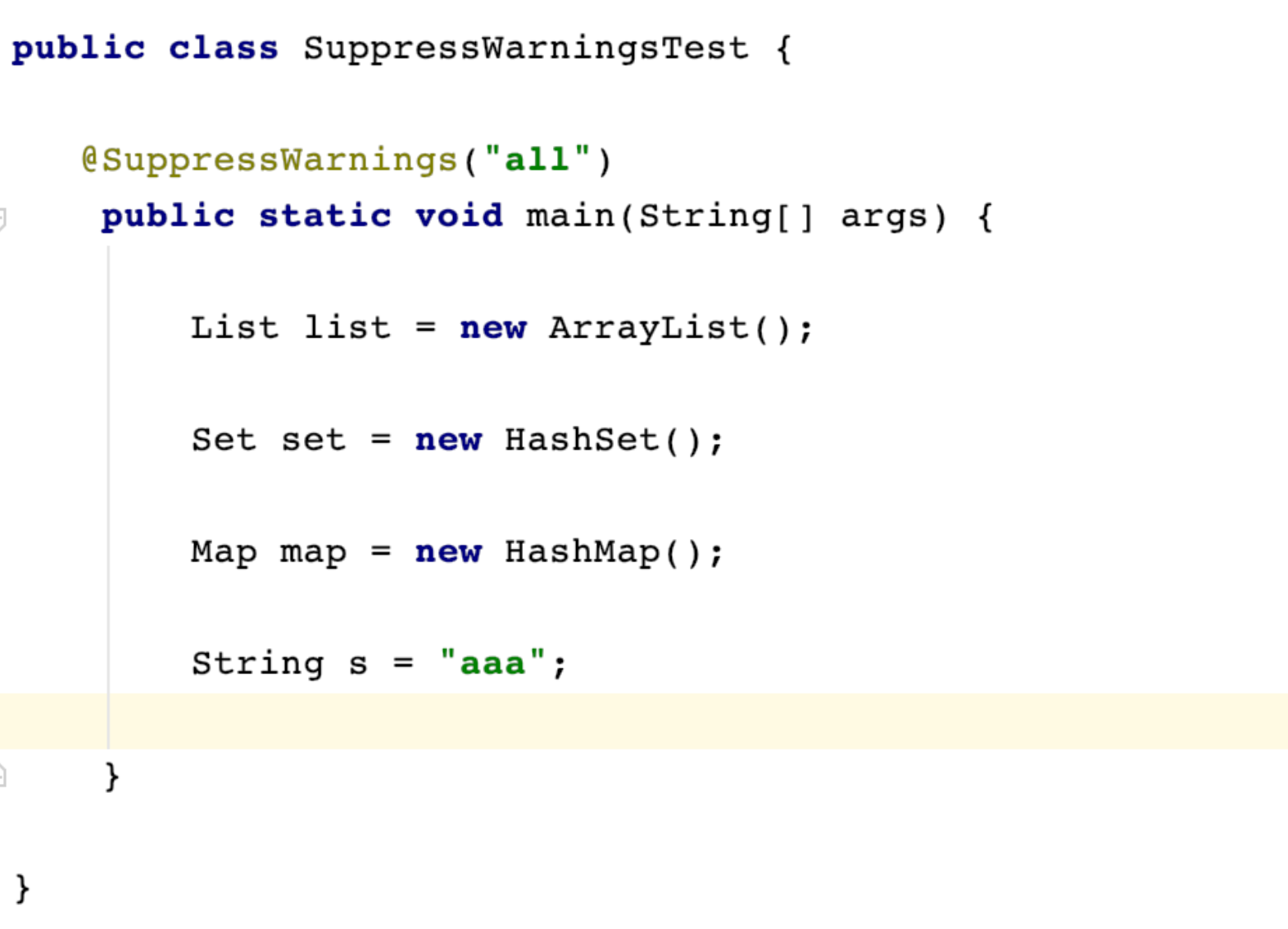
5.@SuppressWarning 中的属性介绍以及属性说明
- all,抑制所有警告
- boxing,抑制与封装/拆装作业相关的警告
- cast,抑制与强制转型作业相关的警告
- dep-ann,抑制与淘汰注释相关的警告
- deprecation,抑制与淘汰的相关警告
- fallthrough,抑制与switch陈述式中遗漏break相关的警告
- finally,抑制与未传回finally区块相关的警告
- hiding,抑制与隐藏变数的区域变数相关的警告
- incomplete-switch,抑制与switch陈述式(enum case)中遗漏项目相关的警告
- javadoc,抑制与javadoc相关的警告
- nls,抑制与非nls字串文字相关的警告
- null,抑制与空值分析相关的警告
- rawtypes,抑制与使用raw类型相关的警告
- resource,抑制与使用Closeable类型的资源相关的警告
- restriction,抑制与使用不建议或禁止参照相关的警告
- serial,抑制与可序列化的类别遗漏serialVersionUID栏位相关的警告
- static-access,抑制与静态存取不正确相关的警告
- static-method,抑制与可能宣告为static的方法相关的警告
- super,抑制与置换方法相关但不含super呼叫的警告
- synthetic-access,抑制与内部类别的存取未最佳化相关的警告
- sync-override,抑制因为置换同步方法而遗漏同步化的警告
- unchecked,抑制与未检查的作业相关的警告
- unqualified-field-access,抑制与栏位存取不合格相关的警告
- unused,抑制与未用的程式码及停用的程式码相关的警告
后记: @SuppressWarning 注解的主要作用就是抑制编译时期所产生的警告,从而提高程序的可读性,对于上面 @SuppressWarning 的所有属性,读者不用全部记忆,读两遍加深印象即可。用到的时候从google或者本文章都可查询
# 理解静态绑定与动态绑定-Java面试题
一个Java 程序要经过编写、编译、运行三个步骤,其中编写代码不在我们讨论的范围之内,那么我们的重点自然就放在了编译 和 运行这两个阶段,由于编译和运行阶段过程相当繁琐,下面就我的理解来进行解释:
Java程序从源文件创建到程序运行要经过两大步骤:
1、编译时期是由编译器将源文件编译成字节码的过程
2、字节码文件由Java虚拟机解释执行
绑定
绑定就是一个方法的调用与调用这个方法的类连接在一起的过程被称为绑定。
绑定分类
绑定主要分为两种:
静态绑定 和 动态绑定
绑定的其他叫法
静态绑定 == 前期绑定 == 编译时绑定
动态绑定 == 后期绑定 == 运行时绑定
为了方便区分: 下面统一称呼为静态绑定和动态绑定
静态绑定
在程序运行前,也就是编译时期JVM就能够确定方法由谁调用,这种机制称为静态绑定
识别静态绑定的三个关键字以及各自的理解
如果一个方法由private、Static、final任意一个关键字所修饰,那么这个方法是前期绑定的
构造方法也是前期绑定
private:private关键字是私有的意思,如果被private修饰的方法是无法由本类之外的其他类所调用的,也就是本类所特有的方法,所以也就由编译器识别此方法是属于哪个类的
public class Person {private String talk;
private String canTalk(){
return talk;
}
}
class Animal{
public static void main(String[] args) {
Person p = new Person();
// private 修饰的方法是Person类独有的,所以Animal类无法访问(动物本来就不能说话)
// p.canTalk(); } }
final:final修饰的方法不能被重写,但是可以由子类进行调用,如果将方法声明为final可以有效的关闭动态绑定
public class Fruit {private String fruitName;
final String eatingFruit(String name){
System.out.println("eating " + name);
return fruitName;
}
}
class Apple extends Fruit{
// 不能重写final方法,eatingFruit方法只属于Fruit类,Apple类无法调用
// String eatingFruit(String name){ // super.eatingFruit(name); // }
String eatingApple(String name){
return super.eatingFruit(name);
}
}
static: static修饰的方法比较特殊,不用通过new出某个类来调用,由类名.变量名直接调用该方法,这个就很关键了,new 很关键,也可以认为是开启多态的导火索,而由类名.变量名直接调用的话,此时的类名是确定的,并不会产生多态,如下代码:
public class SuperClass {public static void sayHello(){
System.out.println("由 superClass 说你好");
}
}
public class SubClass extends SuperClass{
public static void sayHello(){
System.out.println("由 SubClass 说你好");
}
public static void main(String[] args) {
SuperClass.sayHello();
SubClass.sayHello();
}
}
SubClass 继承SuperClass 后,在
是无法重写sayHello方法的,也就是说sayHello()方法是对子类隐藏的,但是你可以编写"自己的"sayHello()方法,也就是子类SubClass 的sayHello()方法,由此可见,方法由static 关键词所修饰,也是编译时绑定
动态绑定
概念
在运行时根据具体对象的类型进行绑定
除了由private、final、static 所修饰的方法和构造方法外,JVM在运行期间决定方法由哪个对象调用的过程称为动态绑定
如果把编译、运行看成一条时间线的话,在运行前必须要进行程序的编译过程,那么在编译期进行的绑定是前期绑定,在程序运行了,发生的绑定就是后期绑定
代码理解
public class Father {void drinkMilk(){
System.out.println("父亲喜欢喝牛奶");
}
}
public class Son extends Father{
@Override
void drinkMilk() {
System.out.println("儿子喜欢喝牛奶");
}
public static void main(String[] args) {
Father son = new Son();
son.drinkMilk();
}
}
Son类继承Father类,并重写了父类的dringMilk()方法,在输出结果得出的是儿子喜欢喝牛奶。那么上面的绑定方式是什么呢?
上面的绑定方式称之为动态绑定,因为在你编写 Father son = new Son()的时候,编译器并不知道son对象真正引用的是谁,在程序运行时期才知道,这个son是一个Father类的对象,但是却指向了Son的引用,这种概念称之为多态,那么我们就能够整理出来多态的三个原则:
1. 继承
2.重写
3.父类对象指向子类引用
也就是说,在Father son = new Son() ,触发了动态绑定机制。
动态绑定的过程
- 虚拟机提取对象的实际类型的方法表;
- 虚拟机搜索方法签名;
- 调用方法。
动态绑定和静态绑定的特点
静态绑定
静态绑定在编译时期触发,那么它的主要特点是
1、编译期触发,能够提早知道代码错误
2、提高程序运行效率
动态绑定
1、使用动态绑定的前提条件能够提高代码的可用性,使代码更加灵活。
2、多态是设计模式的基础,能够降低耦合性。
# String、StringBuffer和StringBuilder的区别-Java面试题
碎碎念
这是一道老生常谈的问题了,字符串是不仅是 Java 中非常重要的一个对象,它在其他语言中也存在。比如 C++、Visual Basic、C# 等。字符串使用 String 来表示,字符串一旦被创建出来就不会被修改,当你想修改 StringBuffer 或者是 StringBuilder,出于效率的考量,虽然 String 可以通过 + 来创建多个对象达到字符串拼接的效果,但是这种拼接的效率相比 StringBuffer 和 StringBuilder,那就是心有余而力不足了。本篇文章我们一起来深入了解一下这三个对象。
简单认识这三个对象
String
String 表示的就是 Java 中的字符串,我们日常开发用到的使用 "" 双引号包围的数都是字符串的实例。String 类其实是通过 char 数组来保存字符串的。下面是一个典型的字符串的声明
上面你创建了一个名为 abc 的字符串。
字符串是恒定的,一旦创建出来就不会被修改,怎么理解这句话?我们可以看下 String 源码的声明

告诉我你看到了什么?String 对象是由final 修饰的,一旦使用 final 修饰的类不能被继承、方法不能被重写、属性不能被修改。而且 String 不只只有类是 final 的,它其中的方法也是由 final 修饰的,换句话说,Sring 类就是一个典型的 Immutable 类。也由于 String 的不可变性,类似字符串拼接、字符串截取等操作都会产生新的 String 对象。
所以请你告诉我下面
String s1 = "aaa"; String s2 = "bbb" + "ccc"; String s3 = s1 + "bbb"; String s4 = new String("aaa");分别创建了几个对象?

- 首先第一个问题,s1 创建了几个对象。字符串在创建对象时,会在常量池中看有没有 aaa 这个字符串;如果没有此时还会在常量池中创建一个;如果有则不创建。我们默认是没有的情况,所以会创建一个对象。下同。
- 那么 s2 创建了几个对象呢?是两个对象还是一个对象?我们可以使用
javap -c看一下反汇编代码
public static void main(java.lang.String[]); Code: 0: ldc #2 // 将 String aaa 执行入栈操作 2: astore_1 # pop出栈引用值,将其(引用)赋值给局部变量表中的变量 s1 3: ldc #3 // String bbbccc 5: astore_2 6: return }
编译器做了优化 String s2 = "bbb" + "ccc" 会直接被优化为 bbbccc。也就是直接创建了一个 bbbccc 对象。
javap 是 jdk 自带的
反汇编工具。它的作用就是根据 class 字节码文件,反汇编出当前类对应的 code 区(汇编指令)、本地变量表、异常表和代码行偏移量映射表、常量池等等信息。javap -c 就是对代码进行反汇编操作。
- 下面来看 s3,s3 创建了几个对象呢?是一个还是两个?还是有其他选项?我们使用 javap -c 来看一下

我们可以看到,s3 执行 + 操作会创建一个 StringBuilder 对象然后执行初始化。执行 + 号相当于是执行 new StringBuilder.append() 操作。所以
==
String s3 = new StringBuilder().append(s1).append("bbb").toString();
// Stringbuilder.toString() 方法也会创建一个 String
public String toString() { // Create a copy, don't share the array return new String(value, 0, count); }
所以 s3 执行完成后,相当于创建了 3 个对象。
- 下面来看 s4 创建了几个对象,在创建这个对象时因为使用了 new 关键字,所以肯定会在堆中创建一个对象。然后会在常量池中看有没有 aaa 这个字符串;如果没有此时还会在常量池中创建一个;如果有则不创建。所以可能是创建一个或者两个对象,但是一定存在两个对象。

说完了 String 对象,我们再来说一下 StringBuilder 和 StringBuffer 对象。
上面的 String 对象竟然和 StringBuilder 产生了千丝万缕的联系。不得不说 StringBuilder 是一个牛逼的对象。String 对象底层是使用了 StringBuilder 对象的 append 方法进行字符串拼接的,不由得对 StringBuilder 心生敬意。

不由得我们想要真正认识一下这个 StringBuilder 大佬,但是在认识大佬前,还有一个大 boss 就是 StringBuffer 对象,这也是你不得不跨越的鸿沟。

StringBuffer
StringBuffer 对象 代表一个可变的字符串序列,当一个 StringBuffer 被创建以后,通过 StringBuffer 的一系列方法可以实现字符串的拼接、截取等操作。一旦通过 StringBuffer 生成了最终想要的字符串后,就可以调用其 toString 方法来生成一个新的字符串。例如
我们上面提到 + 操作符连接两个字符串,会自动执行 toString() 方法。那你猜 StringBuffer.append 方法会自动调用吗?直接看一下反汇编代码不就完了么?
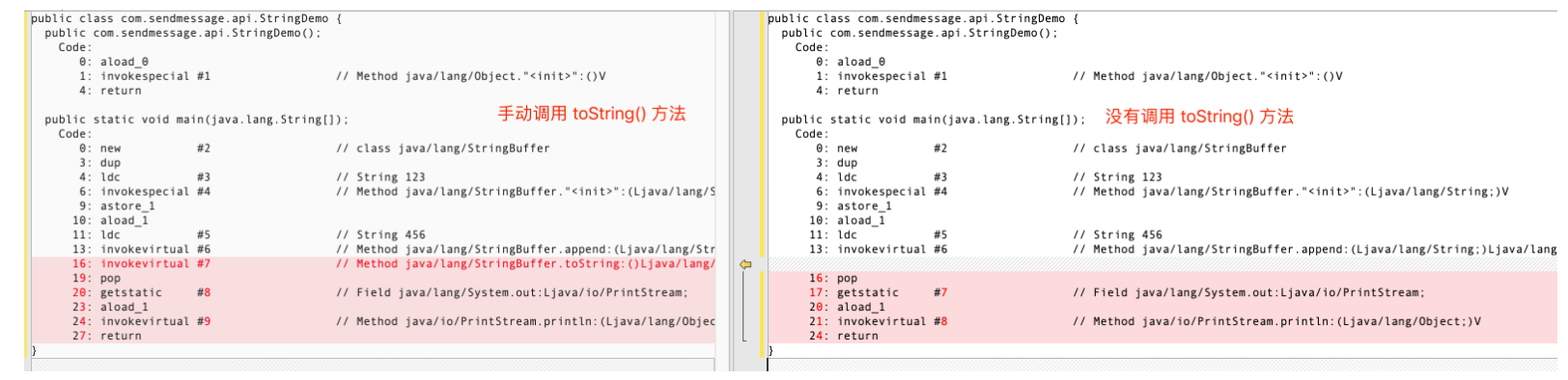
上图左边是手动调用 toString 方法的代码,右图是没有调用 toString 方法的代码,可以看到,toString() 方法不像 + 一样自动被调用。
StringBuffer 是线程安全的,我们可以通过它的源码可以看出
StringBuffer 在字符串拼接上面直接使用 synchronized 关键字加锁,从而保证了线程安全性。
StringBuilder
最后来认识大佬了,StringBuilder 其实是和 StringBuffer 几乎一样,只不过 StringBuilder 是非线程安全的。并且,为什么 + 号操作符使用 StringBuilder 作为拼接条件而不是使用 StringBuffer 呢?我猜测原因是加锁是一个比较耗时的操作,而加锁会影响性能,所以 String 底层使用 StringBuilder 作为字符串拼接。

深入理解 String、StringBuilder、StringBuffer
我们上面说到,使用 + 连接符时,JVM 会隐式创建 StringBuilder 对象,这种方式在大部分情况下并不会造成效率的损失,不过在进行大量循环拼接字符串时则需要注意。如下这段代码
这是一段很普通的代码,只不过对字符串 s 进行了 + 操作,我们通过反编译代码来看一下。
// 经过反编译后 String s = "aaa"; for(int i = 0; i < 10000; i++) { s = (new StringBuilder()).append(s).append("bbb").toString(); }你能看出来需要注意的地方了吗?在每次进行循环时,都会创建一个 StringBuilder 对象,每次都会把一个新的字符串元素 bbb 拼接到 aaa 的后面,所以,执行几次后的结果如下

每次都会创建一个 StringBuilder ,并把引用赋给 StringBuilder 对象,因此每个 StringBuilder 对象都是强引用, 这样在创建完毕后,内存中就会多了很多 StringBuilder 的无用对象。了解更多关于引用的知识,请看
https://mp.weixin.qq.com/s/ZflBpn2TBzTNv_-G-zZxNg
这样由于大量 StringBuilder 创建在堆内存中,肯定会造成效率的损失,所以在这种情况下建议在循环体外创建一个 StringBuilder 对象调用 append() 方法手动拼接。
例如
StringBuilder builder = new StringBuilder("aaa"); for (int i = 0; i < 10000; i++) { builder.append("bbb"); } builder.toString();这段代码中,只会创建一个 builder 对象,每次循环都会使用这个 builder 对象进行拼接,因此提高了拼接效率。
从设计角度理解
我们前面说过,String 类是典型的 Immutable 不可变类实现,保证了线程安全性,所有对 String 字符串的修改都会构造出一个新的 String 对象,由于 String 的不可变性,不可变对象在拷贝时不需要额外的复制数据。
String 在 JDK1.6 之后提供了 intern() 方法,intern 方法是一个 native 方法,它底层由 C/C++ 实现,intern 方法的目的就是为了把字符串缓存起来,在 JDK1.6 中却不推荐使用 intern 方法,因为 JDK1.6 把方法区放到了永久代(Java 堆的一部分),永久代的空间是有限的,除了 Fullgc 外,其他收集并不会释放永久代的存储空间。JDK1.7 将字符串常量池移到了堆内存 中,
下面我们来看一段代码,来认识一下 intern 方法
String a = new String("ab"); String b = new String("ab"); String c = "ab"; String d = "a"; String e = new String("b"); String f = d + e;
System.out.println(a.intern() == b); System.out.println(a.intern() == b.intern()); System.out.println(a.intern() == c); System.out.println(a.intern() == f);
}
上述的执行结果是什么呢?我们先把答案贴出来,以防心急的同学想急于看到结果,他们的答案是
false
true
true
false
和你预想的一样吗?为什么会这样呢?我们先来看一下 intern 方法的官方解释

这里你需要知道 JVM 的内存模型
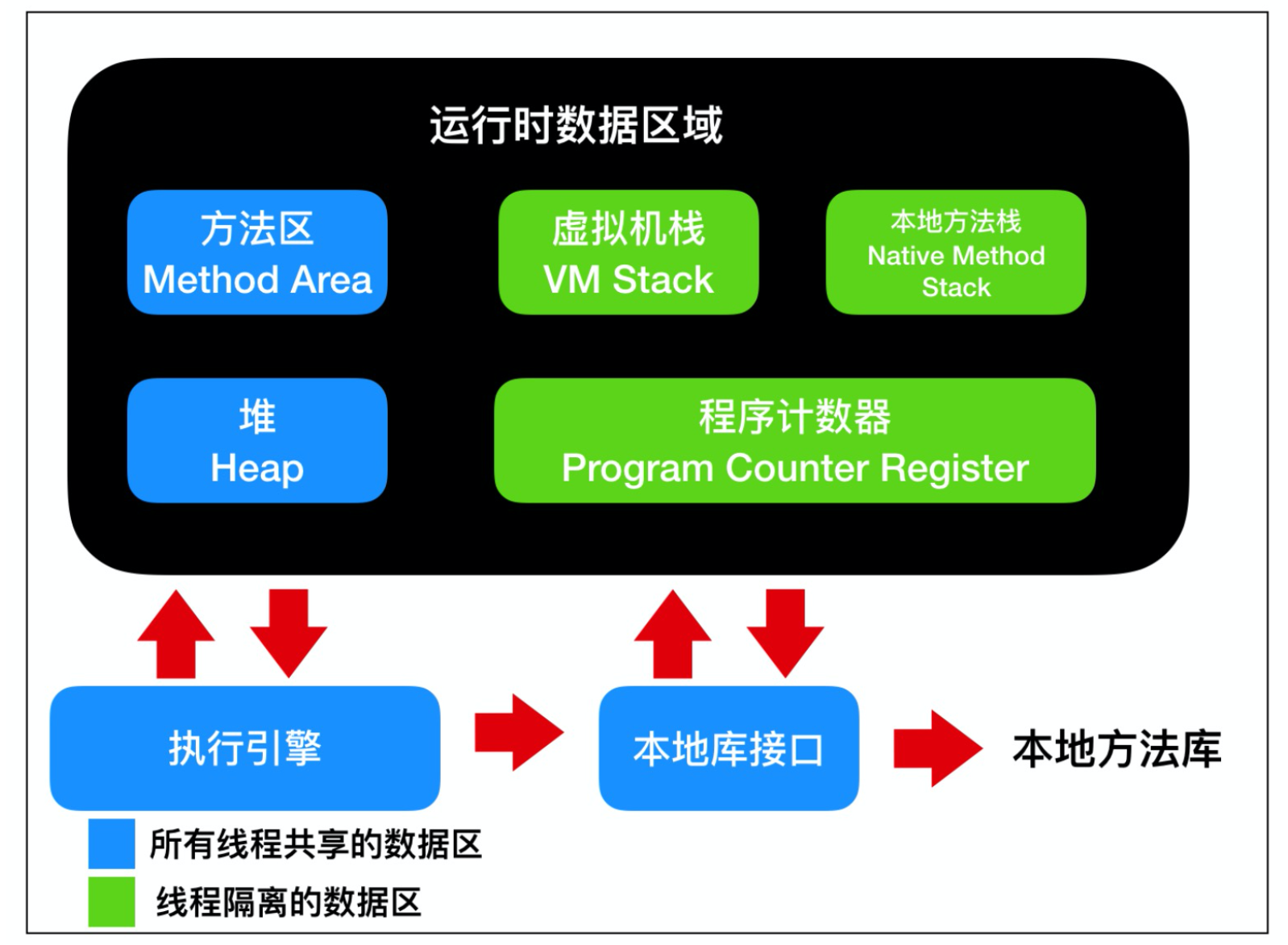
虚拟机栈: Java 虚拟机栈是线程私有的数据区,Java 虚拟机栈的生命周期与线程相同,虚拟机栈也是局部变量的存储位置。方法在执行过程中,会在虚拟机栈种创建一个栈帧(stack frame)。本地方法栈: 本地方法栈也是线程私有的数据区,本地方法栈存储的区域主要是 Java 中使用native关键字修饰的方法所存储的区域程序计数器:程序计数器也是线程私有的数据区,这部分区域用于存储线程的指令地址,用于判断线程的分支、循环、跳转、异常、线程切换和恢复等功能,这些都通过程序计数器来完成。方法区:方法区是各个线程共享的内存区域,它用于存储虚拟机加载的 类信息、常量、静态变量、即时编译器编译后的代码等数据。堆: 堆是线程共享的数据区,堆是 JVM 中最大的一块存储区域,所有的对象实例都会分配在堆上运行时常量池:运行时常量池又被称为Runtime Constant Pool,这块区域是方法区的一部分,它的名字非常有意思,它并不要求常量一定只有在编译期才能产生,也就是并非编译期间将常量放在常量池中,运行期间也可以将新的常量放入常量池中,String 的 intern 方法就是一个典型的例子。
在 JDK 1.6 及之前的版本中,常量池是分配在方法区中永久代(Parmanent Generation)内的,而永久代和 Java 堆是两个完全分开的区域。如果字符串常量池中已经包含一个等于此 String 对象的字符串,则返回常量池中这个字符串的 String 对象;否则,将此 String 对象包含的字符串添加到常量池中,并且返回此 String 对象的引用。
一些人把方法区称为永久代,这种说法不准确,仅仅是 Hotspot 虚拟机设计团队选择使用永久代来实现方法区而已。
从JDK 1.7开始去永久代,字符串常量池已经被转移至 Java 堆中,开发人员也对 intern 方法做了一些修改。因为字符串常量池和 new 的对象都存于 Java 堆中,为了优化性能和减少内存开销,当调用 intern 方法时,如果常量池中已经存在该字符串,则返回池中字符串;否则直接存储堆中的引用,也就是字符串常量池中存储的是指向堆里的对象。
所以我们对上面的结论进行分析
String a = new String("ab"); String b = new String("ab");System.out.println(a.intern() == b);
输出什么? false,为什么呢?画一张图你就明白了(图画的有些问题,栈应该是后入先出,所以 b 应该在 a 上面,不过不影响效果)
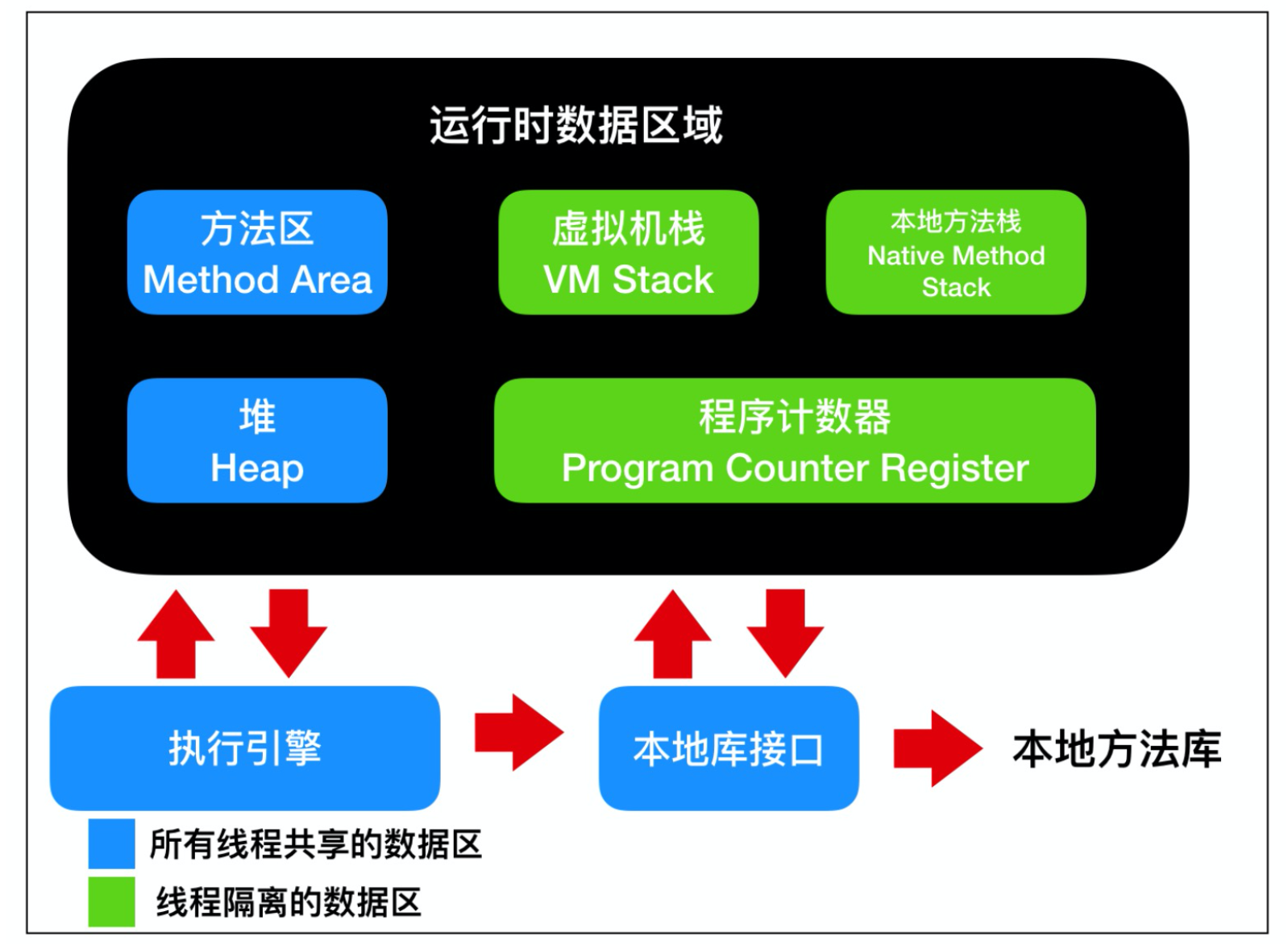
a.intern 返回的是常量池中的 ab,而 b 是直接返回的是堆中的 ab。地址不一样,肯定输出 false
所以第二个
System.out.println(a.intern() == b.intern());也就没问题了吧,它们都返回的是字符串常量池中的 ab,地址相同,所以输出 true
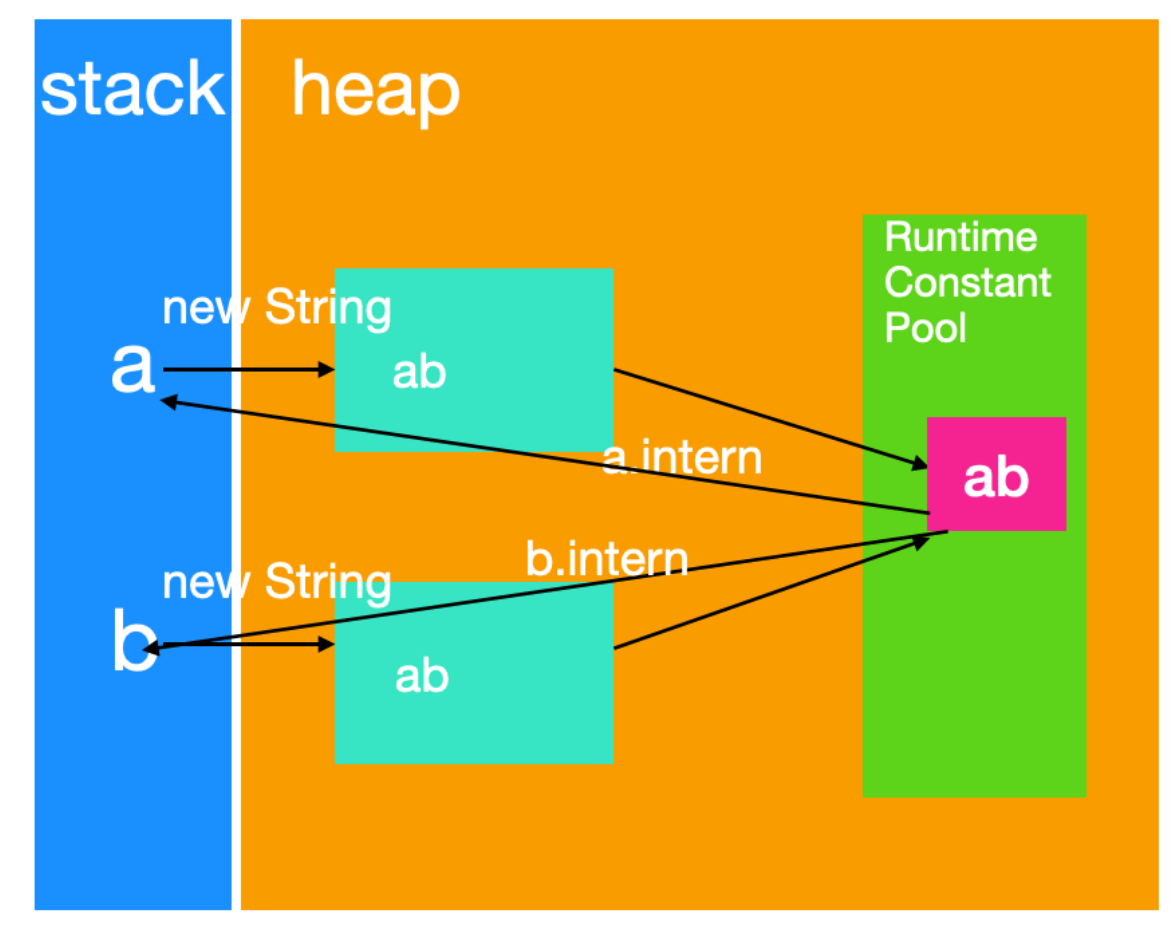
然后来看第三个
System.out.println(a.intern() == c);图示如下
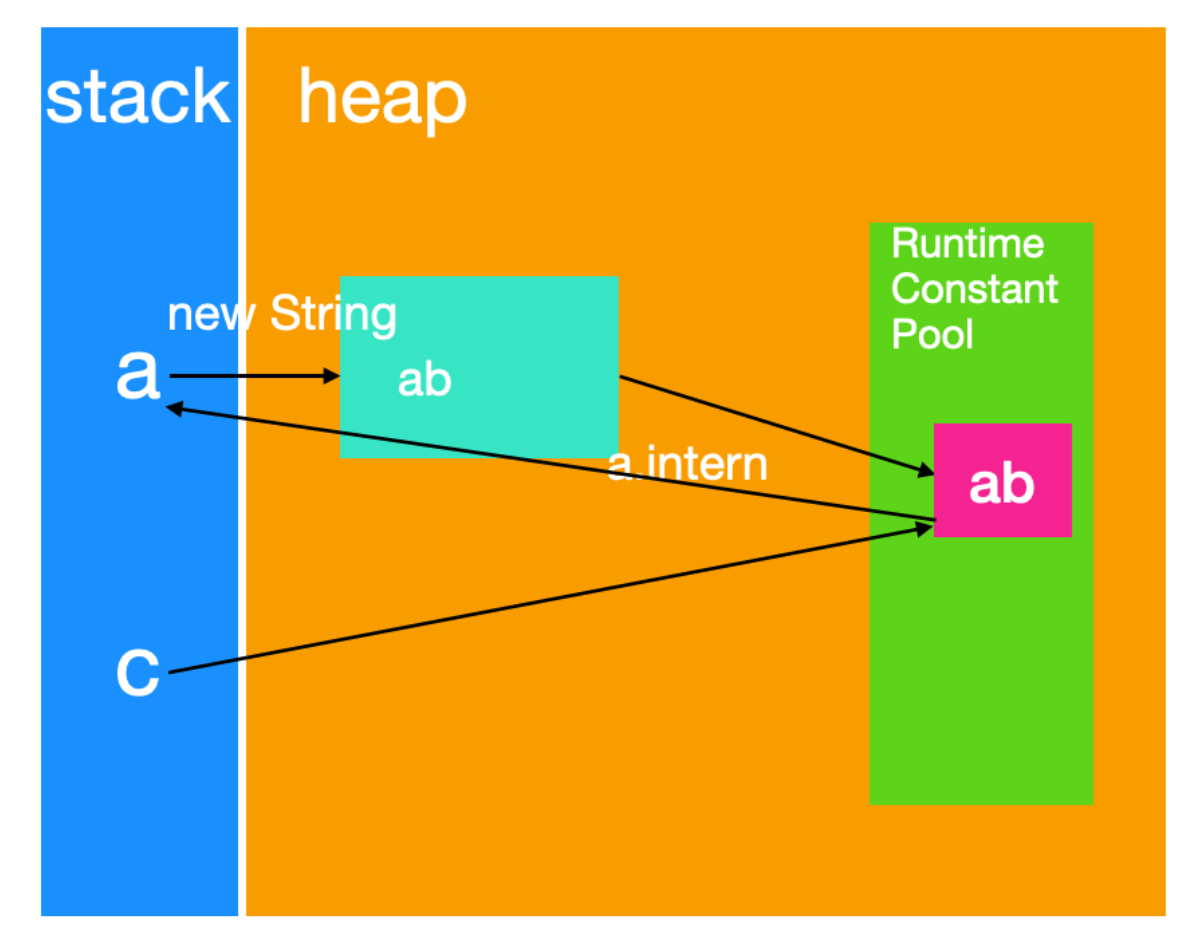
a 不会变,因为常量池中已经有了 ab ,所以 c 不会再创建一个 ab 字符串,这是编译器做的优化,为了提高效率。
下面来看最后一个
System.out.println(a.intern() == f);
String
首先来看一下 String 类在继承树的什么位置、实现了什么接口、父类是谁,这是源码分析的几大重要因素。
String 没有继承任何接口,不过实现了三个接口,分别是 Serializable、Comparable、CharSequence 接口
- Serializable :这个序列化接口没有任何方法和域,仅用于标识序列化的语意。
- Comparable:实现了 Comparable 的接口可用于内部比较两个对象的大小
- CharSequence:字符串序列接口,CharSequence 是一个可读的 char 值序列,提供了 length(), charAt(int index), subSequence(int start, int end) 等接口,StringBuilder 和 StringBuffer 也继承了这个接口
重要属性
字符串是什么,字!符!串! 你品,你细品。你会发现它就是一连串字符组成的串。
也就是说
String str = "abc";// ===
char data[] = {'a', 'b', 'c'}; String str = new String(data);
原来这么回事啊!

所以,String 中有一个用于存储字符的 char 数组 value[],这个数组存储了每个字符。另外一个就是 hash 属性,它用于缓存字符串的哈希码。因为 String 经常被用于比较,比如在 HashMap 中。如果每次进行比较都重新计算其 hashcode 的值的话,那无疑是比较麻烦的,而保存一个 hashcode 的缓存无疑能优化这样的操作。

String 可以通过许多途径创建,也可以根据 Stringbuffer 和 StringBuilder 进行创建。

毕竟我们本篇文章探讨的不是源码分析的文章,所以涉及到的源码不会很多。
除此之外,String 还提供了一些其他方法
charAt:返回指定位置上字符的值getChars: 复制 String 中的字符到指定的数组equals: 用于判断 String 对象的值是否相等indexOf: 用于检索字符串substring: 对字符串进行截取concat: 用于字符串拼接,效率高于 +replace:用于字符串替换match:正则表达式的字符串匹配contains: 是否包含指定字符序列split: 字符串分割join: 字符串拼接trim: 去掉多余空格toCharArray: 把 String 对象转换为字符数组valueOf: 把对象转换为字符串
StringBuilder
StringBuilder 类表示一个可变的字符序列,我们知道,StringBuilder 是非线程安全的容器,一般适用于单线程场景中的字符串拼接操作,下面我们就来从源码角度看一下 StringBuilder
首先我们来看一下 StringBuilder 的定义
public final class StringBuilder extends AbstractStringBuilder implements java.io.Serializable, CharSequence {...}StringBuilder 被 final 修饰,表示 StringBuilder 是不可被继承的,StringBuilder 类继承于 AbstractStringBuilder类。实际上,AbstractStringBuilder 类具体实现了可变字符序列的一系列操作,比如:append()、insert()、delete()、replace()、charAt() 方法等。
StringBuilder 实现了 2 个接口
- Serializable 序列化接口,表示对象可以被序列化。
- CharSequence 字符序列接口,提供了几个对字符序列进行只读访问的方法,例如 length()、charAt()、subSequence()、toString() 方法等。
StringBuilder 使用 AbstractStringBuilder 类中的两个变量作为元素
char[] value; // 存储字符数组int count; // 字符串使用的计数
StringBuffer
StringBuffer 也是继承于 AbstractStringBuilder ,使用 value 和 count 分别表示存储的字符数组和字符串使用的计数,StringBuffer 与 StringBuilder 最大的区别就是 StringBuffer 可以在多线程场景下使用,StringBuffer 内部有大部分方法都加了 synchronized 锁。在单线程场景下效率比较低,因为有锁的开销。
StringBuilder 和 StringBuffer 的扩容问题
我相信这个问题很多同学都没有注意到吧,其实 StringBuilder 和 StringBuffer 存在扩容问题,先从 StringBuilder 开始看起
首先先注意一下 StringBuilder 的初始容量
public StringBuilder() { super(16); }StringBuilder 的初始容量是 16,当然也可以指定 StringBuilder 的初始容量。
在调用 append 拼接字符串,会调用 AbstractStringBuilder 中的 append 方法
public AbstractStringBuilder append(String str) { if (str == null) return appendNull(); int len = str.length(); ensureCapacityInternal(count + len); str.getChars(0, len, value, count); count += len; return this; }上面代码中有一个 ensureCapacityInternal 方法,这个就是扩容方法,我们跟进去看一下
这个方法会进行判断,minimumCapacity 就是字符长度 + 要拼接的字符串长度,如果拼接后的字符串要比当前字符长度大的话,会进行数据的复制,真正扩容的方法是在 newCapacity 中
扩容后的字符串长度会是原字符串长度增加一倍 + 2,如果扩容后的长度还比拼接后的字符串长度小的话,那就直接扩容到它需要的长度 newCapacity = minCapacity,然后再进行数组的拷贝。
总结
本篇文章主要描述了 String 、StringBuilder 和 StringBuffer 的主要特性,String、StringBuilder 和 StringBuffer 的底层构造是怎样的,以及 String 常量池的优化、StringBuilder 和 StringBuffer 的扩容特性等。
如果有错误的地方,还请大佬们提出宝贵意见。
